

Tras un tiempo de respuestas, ideas y debates, otro usuario ha realizado una recopilación de los aspectos y sugerencias más votadas y los ha publicado en forma de lista categorizada, donde podemos encontrar muy buenas ideas a tener en cuenta en nuestros propios desarrollos, y que me he permitido traducir.
Muchos de los puntos son obvios y seguro que ya los estáis teniendo en cuenta, quizás otros son demasiado exagerados, y seguro que alguno de ellos ni siquiera os los habíais planteado. En cualquier caso el resultado es una relación interesante y muy a tener en cuenta para mejorar nuestros sitios web.
Interfaz y experiencia de usuario
- Ser consciente de que los navegadores implementan los estándares de forma diferente y asegurarse de que el sitio web funciona razonablemente bien en la mayoría de los principales navegadores. Como mínimo, sería necesario probarlo con un navegador que utilice un motor reciente Gecko (Firefox), Webkit (Safari, Chrome y algunos navegadores móviles), las versiones soportadas de Internet Explorer, y Opera.
- Tener en cuenta que el sitio web puede ser visitado utilizando medios distintos a los navegadores habituales, como por ejemplo teléfonos móviles, lectores de pantalla, o motores de búsqueda. Usar estándares de accesibilidad como WAI o Section508.
- Considerar los mecanismos de actualización del sitio web para que estos procesos no afecten a los usuarios una vez que el sistema está en marcha y puedan producirse de forma suave y transparente. Por ejemplo, puede ayudar el mantener entornos de prueba paralelos, el uso de herramientas de control del código fuente, o mecanismos de builds automatizados.
- No mostrar errores directamente al usuario.
- No incluir en las páginas direcciones de correo de usuarios en texto plano, para evitar que sean bombardeados por los spammers.
- Incluir límites razonables de utilización del sitio para evitar malos usos por parte de usuarios o procesos automáticos (como puede ser los virus). Por ejemplo, es razonable que un sistema de correo electrónico gratuito limite el número de mensajes diarios que puede enviar un usuario, aunque el número máximo sea muy alto; otro ejemplo podemos verlo en Google, que muestra un mensaje de error cuando detecta demasiado tráfico hacia sus servidores desde una única dirección IP.
Seguridad
- Conocer la amplia guía de desarrollo OWASP, que cubre la seguridad de sitios web de forma muy completa.
- Conocer el fundamento de los ataques de inyección SQL y cómo prevenirlos.
- Jamás confiar en los datos introducidos por los usuarios.
- Evitar el almacenamiento de contraseñas en texto plano utilizando técnicas criptográficas como hashes y salts.
- No intentes utilizar tu magnífico y elaborado sistema de autenticación; es bastante probable que existan fallos impredecibles de los que sólo te darás cuenta después de haber sido hackeado.
- Usar SSL/HTTPS en las páginas de identificación de usuarios y, en general, en todas aquellas páginas donde sea introducida información sensible, como datos personales o bancarios.
- Evitar el secuestro de sesiones (session hijacking).
- Evitar los ataques XSS (Cross Site Scripting).
- Evitar los ataques XSRF (Cross Site Request Forgeries).
- Mantener tus sistemas actualizados con los últimos parches disponibles.
- Asegurarse de que la información de conexión a la base de datos está almacenada en un lugar lo suficientemente seguro.
- Mantener informado sobre las últimas técnicas de ataque y vulnerabilidades que afecten a la plataforma sobre la que trabajas.
- Conocer el manual The Google Browser Security Handbook.
Rendimiento
- Implementar el cacheado de páginas cuando sea necesario. Comprender y usar apropiadamente los mecanismos de cacheo HTTP.
- Optimizar las imágenes. Por ejemplo, no utilizar una imagen de 20 Kb. como mosaico de fondo.
- Conocer cómo comprimir el contenido de las páginas con gzip.
- Echar un vistazo al sitio Yahoo Exceptional Performance, donde se muestran directrices y buenas prácticas para mejorar el rendimiento de sitios web. Utilizar herramientas como YSlow.
- Utilizar la técnica de CSS Sprites para las pequeñas imágenes (como las que encontramos en las barras de herramientas), con objeto de minimizar el número de peticiones HTTP.
- Los sitios web de alto tráfico deberían considerar el despliegue de componentes en distintos dominios para optimizar la descarga en paralelo de los mismos.
- En general, minimizar el número total de peticiones HTTP necesarias para que el navegador muestre las páginas.
SEO
- Utilizar direcciones URL amigables para los buscadores. Por ejemplo, utilizar direcciones del tipo "ejemplo.com/paginas/titulo-del-articulo" en lugar de "ejemplo.com/index.php?page=45".
- No utilizar enlaces que digan "pulse aquí". Estarías creando sitio web poco optimizado para buscadores, a la vez que complicando las cosas para los usuarios que utilizan lectores de pantalla.
- Crear un mapa del sitio en XML (sitemap).
- Utilizar
<link rel="canonical" ... />Cuando tengas múltiples URLs que apunten a un mismo contenido. - Utilizar las herramientas disponibles en www.google.com/webmasters.
- Instalar Google Analytics desde el principio.
- Conocer cómo funcionan los rastreadores de los buscadores y el archivo robots.txt.
- No maquetar con tablas; Google generalmente valorará positivamente el marcado HTML semántico y la maquetación con CSS.
- Si tienes contenido no textual en la página, utiliza en el sitemap las extensiones de Google para audio, video, etc. Hay alguna información sobre ello en la respuesta de Tim Farley.
Tecnología
- Entender el protocolo HTTP; conocer cosas como GET, POST, sesiones, cookies, y saber lo que significa e implica su naturaleza "sin estado" (stateless).
- Escribir el código (X)HTML y CSS conformes a las especificaciones de la W3C, y asegurarse de que validan. El objetivo es evitar las particularidades de los navegadores, a la vez que se facilita enormemente la navegación utilizando browsers no estándar como lectores de pantalla o dispositivos móviles.
- Comprender cómo se procesa el código javascript en los navegadores. Mover los scripts al final de las páginas.
- Comprender cómo funciona el sandbox de javascript, especialmente si pretendes utilizar iframes.
- Asegurarse de que javascript puede ser deshabilitado sin que la página deje de funcionar. AJAX debe ser una extensión, y no la base sobre la que se construya un sitio. Aunque la mayoría de usuarios lo tengan activado, recordar que existen muchos y muy populares dispositivos en los que no funcionará correctamente.
- Entender la diferencia entre las reflexiones 301 y 302 (esto también es un aspecto SEO).
- Aprender tanto como sea posible sobre la plataforma en la que será desplegado el sitio web en producción.
- Considerar el uso de un reseteador de CSS.
- Considerar herramientas como jQuery, que oculta muchas de las particularidades de los distintos navegadores utilizando javascript para la manipulación del DOM.
Corrección de errores
- Entender que pasarás el 20% del tiempo codificando y el 80% restante manteniéndolo, por tanto codifica apropiadamente.
- Configurar un buen sistema de notificación y gestión de errores.
- Habilitar sistemas para que los usuarios puedan contactar contigo y trasladarte críticas y sugerencias.
- Documentar cómo funciona la aplicación para facilitar el futuro soporte y mantenimiento del sistema.
- Poner a funcionar el sistema primero en Firefox y después en Internet Explorer.
- Hacer copias de seguridad frecuentes.
Publicado en: Variable not found.

El framework ASP.NET MVC nos ofrece mecanismos de control de errores muy potentes basada en la utilización del atributo HandleError, el cual definirá la vista que será mostrada al usuario cuando se produzca alguna excepción no controlada en el código de los controladores, siempre que en el web.config se haya activado el uso de errores personalizados mediante la propiedad CustomErrors.
En este post vamos a profundizar en el uso del atributo HandleError, comentando cómo se implementa en el controlador, su ámbito de actuación, los parámetros que ofrece y la forma de crear las vistas para mostrar los errores de forma amigable.
El controlador
HandleError puede ser declarado tanto a nivel de clase (controlador) como a nivel de acción. En el primer caso, se establecerá el comportamiento general para todas las acciones del controlador, mientras que en el segundo será aplicable sólo a la acción a la que se asocie el atributo:
// Control de errores a nivel de clase de controlador,
// que será aplicado a todas las acciones del mismo.
[HandleError()]
public class HomeController : Controller
{
...
}
// Control de errores a nivel de acción concreta...
[HandleError(ExceptionType=typeof(ArgumentException), View="ArgumentError")]
public ActionResult Calculate(int a, int b)
{
ViewData["results"] = calculateSomething();
return View();
}
En realidad, el comportamiento definido en el atributo HandleError a nivel de clase también se aplicará a los errores generados por las vistas u otros resultados (ActionResult) retornados por los controladores. Es decir, sobre el segundo de los ejemplos anteriores, la vista “ArgumentError” (que existirá en un archivo llamado ArgumentError.aspx) será invocada cuando la excepción ArgumentException sea lanzada bien por el propio controlador, o bien por la vista “Calculate” que retorna por defecto.
Un último detalle sobre esto: el atributo HandleError puede ser especificado tantas veces como necesitemos sobre la misma acción o controlador, indicando comportamientos para distintos tipos de excepción. El atributo que se tendrá en cuenta cuando se produzca un error será el primero que se encuentre cuyo tipo de excepción (parámetro ExceptionType) sea compatible con la excepción lanzada.
El manejador de errores que se empleará en una acción será el primero que corresponda al tipo de excepción producida, teniendo en cuenta tanto los atributos que adornan la acción como los que acompañan a su controlador, y siempre según un orden preestablecido.
Veamos con más detenimiento los parámetros que admite la declaración del atributo.
Parámetros de HandleError
[HandleError(
ExceptionType=typeof(DivisionByZero),
View="ErrorPersonalizado",
Master="MaestraErrores",
Order = 0)
]
public ActionResult Index()
...
- ExceptionType permite indicar el tipo de excepción que se pretende controlar. Por defecto, el sistema entenderá que la regla se refiere al tipo base
Exception, por lo que se aplicará a todos los errores que se generen, pues todas las excepciones heredan de esta clase. - View, el nombre de la vista que será mostrada al usuario. Por defecto se tomará el valor “Error”, por eso en la plantilla de proyectos ASP.NET MVC ya existe una vista con este nombre.
- Master, la página maestra con la que será renderizada la vista, independientemente de lo que tenga declarado ésta.
- Order, un valor numérico (por defecto –1, el más prioritario) que indica la prioridad de aplicación de esta regla cuando el sistema encuentre varios atributos
HandleErroraplicables al mismo elemento y que puedan presentar conflictos. Los valores más pequeños, Por ejemplo, si no se indicara este parámetro en el siguiente caso, el resultado dependería del orden de declaración, lo cual no es demasiado recomendable:
[HandleError(Order=10, View="ErrorGenerico")]
public class HomeController : Controller
{
...
[HandleError (ExceptionType=typeof(DivisionByZero),
View="OperacionIncorrecta", Order=1)]
public ActionResult Calculate()
...
Como puede intuirse, esto hará que en caso de producirse una división por cero, se muestre la vista “OperacionIncorrecta” y no la “ErrorGenerico”.
Cada vez que utilicemos HandleError es conveniente tener muy en cuenta la prioridad (definida en la propiedad Order), el alcance (las excepciones a tratar, definidas en la propiedad ExceptionType), así como los valores por defecto en cada caso. Esto evitará comportamientos misteriosos del sistema una vez se produzcan errores en tiempo de ejecución.
Acceso desde la vista a la información del error
Ya hemos comentado anteriormente que la vista que será mostrada a los usuarios cuando se produzca un error será la indicada en el parámetro View del atributo HandleError, o la vista "Error", si este parámetro no es informado. Sea cual sea, el archivo nombredevista.aspx deberá estar localizable por el motor de vistas en el momento de su lanzamiento (por cierto, si no te gustan las ubicaciones por defecto, puedes ver cómo modificar la forma en la que se buscan las vistas en este post).
La vista de un error es una página .aspx normal, como una vista más de la web, pero con la particularidad de que puede recibir información sobre el error que ha provocado su presentación. De hecho, se trata de una vista tipada que hereda de ViewPage<System.Web.Mvc.HandleErrorInfo>, de forma que la propiedad Model será del tipo HandleErrorInfo, clase que nos ofrece completa información sobre el origen del problema:
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<System.Web.Mvc.HandleErrorInfo>" %>
<asp:Content ID="errorTitle" ContentPlaceHolderID="TitleContent" runat="server">
Error en el sistema
</asp:Content>
<asp:Content ID="errorContent" ContentPlaceHolderID="MainContent" runat="server">
<h2>
Ups, se ha producido un ligero inconveniente...
</h2>
<p>
La acción <%= Model.ActionName %>
del controlador <%= Model.ControllerName %>
ha lanzado la excepción <%= Model.Exception.GetType().Name %> con
el mensaje "<%= Model.Exception.Message %>".
</p>
</asp:Content>
A pesar de no ser un buen ejemplo como pantalla del error amigable para el usuario ;-), el código anterior ilustra cómo es posible acceder desde la vista a los datos del contexto del error proporcionados por el entorno, y cómo la clase HandleErrorInfo nos ofrece una información sobre la acción en la que se ha lanzado la excepción, el controlador en el que se encuentra la misma, y lo más interesante, nos ofrece en la propiedad Exception la excepción producida, por lo que tendremos acceso a su tipo, descripción e incluso al estado de la pila de llamadas en el momento de producirse el error.
Publicado en: www.variablenotfound.com

Como comenta el autor, la mayoría de los problemas con jQuery se deben a un uso incorrecto de los potentes selectores, así que lo que propone es el uso de la consola javascript incluida en algunas herramientas como Firebug (para Firefox) o las propias herramientas de desarrollo incluidas en Internet Explorer 8 (geniales, por cierto).

En la imagen adjunta se ve cómo podemos ir realizando consultas con selectores e ir observando sus resultados con Firebug. Hay que tener en cuenta que la mayoría de operaciones de selección con jQuery retornan una colección con los elementos encontrados, por eso podemos utilizar length para obtener el número de coincidencias. Pero no sólo eso, podríamos utilizar expresiones como la siguiente para mostrar por consola el texto contenido en las etiquetas que cumplan el criterio:
$("div > a").each(function() { console.log($(this).text()) })Y más aún, si lo que queremos es obtener una representación visual sobre la propia página, podemos alterar los elementos o destacarlos con cualquiera de los métodos de manipulación disponibles en jQuery, por ejemplo:
$("a:contains['sex']").css("background-color", "yellow")
La siguiente captura muestra el resultado de una consulta realizada con las herramientas de desarrollo incluidas en Internet Explorer 8:

En fin, un pequeño truco para facilitarnos un poco la vida.
 Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.
Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.Esto aporta varias ventajas nada despreciables:
- primero, la descarga de estas librerías será, para el cliente, probablemente más rápida que si las tiene que obtener desde tu servidor a través de internet. Se trata de infraestructura de red de Google, y eso implica unas garantías.
- segundo, y relacionada con la anterior, si se trata de un sitio web de alto tráfico, la concurrencia permitida seguramente será infinitamente mayor que la que puedas ofrecer en otro servidor.
- tercero, si el usuario ha visitado previamente otro sitio web que use también la misma librería, se beneficiará del cacheado local de la misma, puesto que su navegador no la descargaría de nuevo. Y en cualquier caso, se estarían aprovechando las optimizaciones de caché de Google.
- cuarto, no consumes ancho de banda de tu proveedor, aunque éste sea despreciable. Y con despreciable me refiero al ancho de banda, no al proveedor ;-)
- quinto, puedes utilizar las librerías desde webs alojadas en algún sitio donde no se pueda, o no sea sencillo, subir archivos de scripts, como la plataforma Blogger desde la que escribo.
En este momento se contemplan los siguientes frameworks, en todas las versiones disponibles:
- jQuery
- jQuery UI
- Prototype
- script_aculo_us
- MooTools
- Dojo
- SWFObject
- Yahoo! User Interface Library (YUI)
Si ya estás utilizando librerías Ajax de Google (como el API de visualización, o el de Google Maps), y las obtienes mediante el cargador google.load(), también puedes utilizarlo para descargar estos frameworks. Asimismo, puedes hacerlo mediante una referencia directa, del tipo:
<script
src="http://ajax.googleapis.com/ajax/libs/prototype/1.6.0.2/prototype.js">
</script>
Ah, y no hay que preocuparse por los cambios de versiones, ni nada parecido. Google se compromete a alojar indefinidamente todas las distribuciones que vayan publicando, así como de incluir actualizaciones conforme aparezcan.
Por último, y para aportar una visión negativa, hay quien opina que se trata de una estrategia más de Google para obtener información sobre la navegación de los usuarios; la ejecución de código procedente de sus servidores posibilitaría la lectura de cookies y datos que podrían ser utilizados para fines distintos de los previstos en tu web. También hay quienes piensan que podría ser una fuente de difusión de código malicioso si alguien consiguiera hackear estos repositorios. Obviamente, tampoco es buena idea utilizar esta opción si vas a trabajar en modo local, sin conexión.
Para más información sobre las formas de descarga y las librerías disponibles, puedes visitar la guía del desarrollador de las Ajax libraries API.
Publicado en: www.variablenotfound.com.
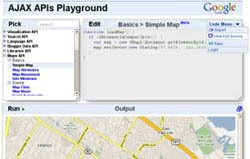 El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.
El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.Se trata de un sitio web interactivo en el que se encuentran un total de 170 ejemplos de uso de las siguientes API de Google:
- API de visualización, que permite a los desarrolladores acceder a datos estructurados y mostrarlos en una gran variedad de formatos, como tablas o gráficos estadísticos.
- API Ajax para búsquedas, que facilita la incorporación de capacidades de búsqueda de cualquier tipo (páginas, direcciones, multimedia, etc.) en sitios web utilizando javascript.
- API Ajax de idioma, que nos permite acceder mediante javascript a las herramientas de detección de idioma, traducción y transliteración de Google.
- API de datos de Blogger, que permite el acceso con Ajax a información sobre blogs, posts y comentarios de esta plataforma de publicación.
- API de bibliotecas Ajax, la red de distribución de librerías estándar como jQuery, jQuery UI, Prototype, script.aculo.us, MooTools o Dojo.
- API de Google Maps, con el que podremos integrar Google Maps en nuestras webs y utilizar los servicios de localización y posicionamiento que nos ofrece.
- API de Google Earth, el cual nos facilita la inclusión del sistema Google Earth en webs, así como la interacción con ellos vía javascript.
- API Ajax para feeds, un conjunto de funciones que nos permiten obtener feeds de otras páginas sin necesidad de crear proxies de servidor.
- API de Google Calendar, el interfaz a través del cual podemos crear aplicaciones totalmente integradas con Google Calendar.
Pero, al menos para mí, lo mejor viene ahora: dispone de un editor de código fuente en el que podemos modificar dichos ejemplos, ejecutarlos sobre la marcha e incluso guardar o exportar los cambios que realicemos, por lo que resulta de lo más didáctico y efectivo para hacernos con el manejo de estas potentes herramientas.
Enlace: Ajax API Playground.
Publicado en: www.variablenotfound.com.
 El otro día me topé, casi por casualidad, con una forma para crear imágenes con esquinas redondeadas sin necesidad de recurrir a Photoshop ni manipularlas desde la aplicación, simplemente usando NiftyDotNet.
El otro día me topé, casi por casualidad, con una forma para crear imágenes con esquinas redondeadas sin necesidad de recurrir a Photoshop ni manipularlas desde la aplicación, simplemente usando NiftyDotNet.La forma de conseguirlo es muy sencilla, y básicamente aprovecha la técnica utilizada por Nifty Corners Cube, la librería javascript encapsulada por NiftyDotNet, para crear el efecto de redondeo de los ángulos de elementos de bloque de una página Web.
Lo primero que debemos hacer es incluir la imagen en nuestra página dentro de la habitual etiqueta
<img>, pero eso sí, dentro de un elemento contenedor, que es al que aplicaremos el efecto de redondeo:
<div class="fotonifty"
style="background: url(images/paisaje1.jpg) no-repeat top left;" >
<img src="images/paisaje1.jpg" alt="Magnífico paisaje" />
</div>
[...]
/* Estilos de la página */
<style type="text/css">
.fotonifty
{
width: 150px;
height: 150px;
margin: 10px;
}
.fotonifty img
{
display: none;
}
</style>Fijaos que la etiqueta
<img> sigue existiendo, conservando la semántica y características de accesibilidad del marcado, pero la estamos ocultando desde CSS definiéndole un display: none. La que se verá en la web es la definida como fondo del <div> en el estilo.Observad también que hemos tenido que indicar el ancho y alto del
<div>. Esto es absolutamente necesario para que éste tome el tamaño necesario para mostrar la imagen completa.Ya sólo nos falta aplicar el efecto de redondeo deseado a los elementos
<div class="fotonifty">. Con NiftyDotNet, basta con arrastrar y soltar el componente sobre nuestro formulario web, o bien introducir a mano el control, y establecer sus propiedades correctamente: <cc1:Nifty ID="Nifty1" runat="server"
Selectors="div.fotonifty"
CornerSize="Big"
FixedHeight="true" />La propiedad
Selectors se ha establecido con el selector CSS que identifica los bloques a redondear, y CornerSize define el tamaño del borde. FixedHeight es necesaria, e indica que el proceso Nifty no debe modificar el alto del elemento, pues está definido a nivel de estilos.En fin, un truco que puede ser especialmente interesante en contextos donde las imágenes que queremos mostrar redondeadas no forman parte del diseño base de una aplicación web, sino de los contenidos gestionados por los usuarios.

 Pues tiene una pinta excelente el control para la generación de gráficas estadísticas Chart Control para ASP.NET 3.5, recientemente presentado en sociedad por Scottgu (con la habitual traducción en Thinking in .net).
Pues tiene una pinta excelente el control para la generación de gráficas estadísticas Chart Control para ASP.NET 3.5, recientemente presentado en sociedad por Scottgu (con la habitual traducción en Thinking in .net).Se trata de un componente con una versión específica para ASP.NET, válida para WebForms y MVC framework, y otra para Windows Forms, que permite generar gráficas estadísticas prácticamente de cualquier tipo, visualmente muy atractivas, realmente fáciles de utilizar en nuestas aplicaciones y, además, de forma gratuita.
Enumero características interesantes, o que me han llamado la atención (ambas cosas no están necesariamente unidas ;-)), del control para ASP.NET:
- El control se renderiza en cliente con una etiqueta
<img>. - Se puede forzar al control a generar las imágenes al vuelo o a almacenarlas físicamente en una carpeta.
- Las imágenes generadas pueden ser cacheadas para mejorar el rendimiento.
- Genera BMPs, JPGs, PNGs o EMFs.
- Permite también usarlo con aplicaciones no ASP.NET 3.5 a través del modo "binary streaming", que fuerza a que el control elimine toda la salida HTML de la página donde se encuentra y retorne únicamente la imagen como resultado, de forma dicha página puede ser utilizada como source de un tag
<img>en otro sitio. - Soporta eventos del tipo "PrePaint" y "PostPaint" para poder hacer retoques a mano sobre los resultados, como:
void Chart1_PostPaint(object sender, ChartPaintEventArgs e)
{
e.ChartGraphics.Graphics.DrawString("Hola",
new Font("Arial", 12f),
Brushes.Black, 10, 10);
} - 25 tipos de gráficas, muchas de ellas con vistas en tres dimensiones, en las que se puede modificar prácticamente todo: rotación, inclinación, sombras, etc.
- Podemos crear imágenes con múltiples gráficas distintas, utilizar en ellas todas las series de datos que deseemos, con un número ilimitado de puntos.
- Control total sobre los ejes en cuanto a escalado, visualización o etiquetado.
- Posibilidad de añadir anotaciones, leyendas y otros elementos "extra".
- Permite establecer datos enlazando el control a fuentes (binding), o de forma manual sobre el mismo utilizando los diseñadores o etiquetas ASP.NET.
- Soporta mapeo de imágenes, posibilidad de capturar clicks sobre áreas para establecer comportamientos personalizados, o combinarlo con Ajax para enriquecer la experiencia de usuario.
Instalación
Antes de instalar, asegúrate que cumples el requisito previo básico, tener instalado Microsoft .NET Framework 3.5 SP1. Si no lo has hecho antes, ya sabes por dónde empezar ;-)Una vez asegurado este punto, el siguiente paso es descargar Microsoft Chart Control, que incluye controles tanto para ASP.NET como para Windows Forms. Existe también, como descarga opcional, el paquete de idioma para Microsoft Chart Control, que contiene la localización del producto para otros idiomas.
Después, es una buena idea instalar el Add-on para Visual Studio 2008 que os facilitará el trabajo con el control desde este entorno de desarrollo, a base de diseñadores integrados. No olvidéis también bajaros también la documentación si váis a necesitar información detallada de las librerías incluidas.
Y, por último, para tomar conciencia del tipo de resultados que se pueden obtener con este control, el ideal es descargar los proyectos de demostración, que os permitirán ver y tocar una auténtica batería de ejemplos seguro muy útiles a la hora de usarlo en vuestros desarrollos, tanto ASP.NET como Winforms.

Publicado en: www.variablenotfound.com.
 En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.
En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.Durante el año que ha transcurrido desde entonces los archivos de NiftyDotNet han sido descargados 1000 veces (bueno, exactamente 998), he recibido muchos mensajes con cuestiones, sugerencias, y algunos bugs que he aprovechado para corregir en esta nueva revisión, que he creído conveniente ya numerarla como 1.0, para no seguir la estrategia de Google de la eterna beta ;-)
Además de algún cambio menor en el proyecto de demostración, han sido corregidos los siguiente problemas:
- Un error de Javascript que aparecía cuando el control no encontraba ningún elemento en la página que correspondiera con los selectores indicados y había sido especificada además la propiedad Fixed-Height.
- En páginas cuya sección HEAD no incluía el atributo RUNAT="SERVER" se mostraban caracteres extraños en pantalla, y no se redondeaban los elementos de la página.
Enlaces:
Publicado en: www.variablenotfound.com.
 A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.
A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.Como sabemos, la propiedad
Master de las páginas de contenidos, a través de la cual es posible acceder a la página maestra, es por defecto del tipo MasterPage. Esto es así porque todas las masters que creamos heredan de esta clase, y es una abstracción bastante acertada la mayoría de las veces. De hecho, es perfectamente posible hacer un cast al tipo correcto desde el código de la página para acceder a alguna de las propiedades públicas que le hayamos definido, así:
protected void Page_Load(object sender, EventArgs e)
{
MaestraContenidos master = Master as MaestraContenidos;
master.Titulo = "Título";
}
Pues bien, mediante la directiva de página
MasterType es posible indicar de qué tipo será esta propiedad Master, de forma que no será necesario hacer el cast. En la práctica, en el ejemplo anterior, podríamos hacer directamente Master.Titulo="Título", sin realizar la conversión previa.La directiva podemos utilizarla en el archivo .ASPX, haciendo referencia al archivo donde está definida la página maestra cuyo tipo usaremos para la propiedad:
<%@ MasterType VirtualPath="~/site1.master" %>
O también podemos hacerlo indicando directamente el tipo (ojo, que hay que incluirlo con su espacio de nombres completo):
<%@ MasterType TypeName="ProyectoWeb.MaestraContenidos" %>
Por último, algunas contraindicaciones. Si váis a usar esta técnica, tened en cuenta que:
- si decidís cambiar la página maestra en tiempo de ejecución, en cuanto intentéis acceder a la propiedad Master, vuestra aplicación reventará debido a que el tipo no es el correcto.
- si cambiáis la maestra a la que está asociada una página de contenidos, tenéis que acordaros de cambiar también la directiva
MasterTypede la misma para que todo funcione bien.
Publicado en: www.variablenotfound.com.
 Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href="mailto:user@myserver.xx">email me</a> - Sustituyendo las arrobas por "AT" y los puntos por "DOT", de forma que una dirección queda de la forma:
<a href="mailto:userATserverDOTxx">email me</a> - Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href="mailto:user@server.xx">email me</a> - Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href="mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65">email me</a> - Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!-- -->@<!--- @ -->my<!-- -->server.<!--- . -->com - Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = "user";
var string2 = "@";
var string3 = "myserver.xx";
var string4 = string1 + string2 + string3;
document.write("<a href=" + "mail" + "to:" + string1 +
string2 + string3 + ">" + string4 + "</a>"); - Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type="text/css">
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class="codedirection">moc.revresym@resu</span> - Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type="text/css">
span.displaynone { display:none; }
</style>
Email me: user@<span class="displaynone">goaway</span>myserver.net - Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type="text/javascript">
document.write('<n uers=\"znvygb:fvyinasbbone10@gvyyyngr.pbz\" ery=\"absbyybj\">'.replace(/[a-zA-Z]/g, function(c){return String.fromCharCode((c<="Z"?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar's Mail</a>
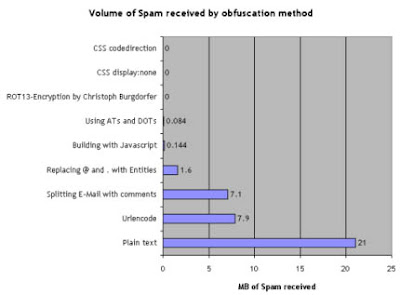 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces
mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href="mailto:loquesea">, incluidos los caracteres de inicio "<" y fin ">", pero sin introducir el texto del enlace ni el cierre </a> de la misma).También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace
mailto: completo en nuestras páginas.Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de "AT" y "DOT", o equivalentes en nuestro idioma como "EN" y "PUNTO", con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como "juanARROBICAservidorPUNTICOcom", o "juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom". Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Publicado en: www.variablenotfound.com.
 Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.
Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.Para lograrlo, necesitamos solucionar dos problemas. El primero es cómo indicar en los enlaces (dentro de la etiqueta
<a> de nuestro código X/HTML) el idioma de la página a la que saltará el usuario; el segundo problema es el describir en la hoja de estilos (CSS) estos enlaces, de forma que se representen con la banderita correspondiente. Ambos tienen fácil solución gracias a los estándares de la W3C.Hace ya bastantes años, el estándar HTML definió el atributo
hreflang en los hipervínculos con objeto de indicar el idioma del recurso apuntado por el atributo href. En otras palabras, si estamos apuntando a una página debería contener el idioma de la misma, justo lo que necesitamos: <a href="http://www.csszengarden.com" hreflang="en">CSS Zen Garden</a>Por otra parte, el estándar CSS 2.1 define un gran número de selectores que podemos utilizar para identificar los elementos de nuestra página a los que queremos aplicar las reglas de estilo especificadas. El que nos interesa para lograr nuestro objetivo es el llamado selector de atributos, que aplicado a una etiqueta permite filtrar los elementos que presenten un valor concreto asociado a un atributo de la misma.
Así, en el siguiente código, que debemos incluir en la hoja de estilos del sitio web, buscamos los enlaces cuya página de destino sea en inglés (su
hreflag comience por "en"), introduciendo el efecto deseado:a[hreflang="en"]
{
padding-right: 19px;
background-image: url(img/bandera_ing.jpg);
background-position: right center;
background-repeat: no-repeat;
}
Observad que el
padding-right deja un espacio a la derecha del enlace con la anchura suficiente como para que se pueda ver la imagen de fondo, la banderilla, que aparecerá allí gracias a su alineación horizontal a la derecha definida con el background-position.Y, ahora sí, podemos recomendar visitas a páginas en inglés como CSS Zen Garden con fundamento.
Ah, un último detalle. Aunque hoy en día los navegadores tienden cada vez más a respetar los estándares, es posible que encontréis alguno con el que no funcione bien esta técnica principalmente por no soportar el selector de atributos (por ejemplo IE6 y anteriores, afortunadamente cada vez menos usados).
Publicado en: www.variablenotfound.com.
Se trata de un proyecto personal de Dan Hounshell que recopila de forma automática posts, noticias, rumores y vídeos de feeds RSS de diversas fuentes sobre ASP.NET MVC y tecnologías relacionadas. Ah, y todos estos contenidos los ofrece en RSS, por lo que es una fuente ideal para estar al día.

Que aproveche.
Publicado en: www.variablenotfound.com.
 Los desplegables en cascada (también llamados cascading dropdowns o enlazados) son elementos muy frecuentes en todo tipo de aplicaciones, pues suponen una gran ayuda al usuario y dotan de mucho dinamismo al interfaz.
Los desplegables en cascada (también llamados cascading dropdowns o enlazados) son elementos muy frecuentes en todo tipo de aplicaciones, pues suponen una gran ayuda al usuario y dotan de mucho dinamismo al interfaz.En pocas palabras, consiste en llenar una lista desplegable con elementos elegidos en función de una decisión previa, como la selección en otra lista. El ejemplo típico lo encontramos en aplicaciones donde debemos introducir una dirección y nos ponen por delante un desplegable con las provincias y otro con los municipios, y en éste último sólo aparecen aquellos que pertenecen a la provincia seleccionada.
Esto, que en aplicaciones de escritorio no tiene dificultad alguna, en el entorno Web se complica un poco debido a la falta de comunicación entre la capa cliente (HTML, javascript) y servidor (ASP, .NET, JSP, PHP...), propia de un protocolo desconectado como HTTP.
Años atrás (e incluso todavía hoy) una forma de solucionar el problema es forzando un postback, es decir, una recarga de la página completa, con objeto de llenar el desplegable dependiente en función del valor seleccionado en el principal. Supongo que no es necesario detallar los inconvenientes: tiempos de espera, asombro del usuario ante el pantallazo, problemas asociados al mantenimiento del estado...
La aparición de Ajax (¡en minúsculas!) supuso una revolución para las aplicaciones Web, añadiendo a las amplias capacidades de Javascript para la manipulación del interfaz e información en cliente mecanismos ágiles para conseguir comunicación en tiempo real con el lado del servidor.
En este post explicaré cómo conseguir desplegables en cascada utilizando la plataforma ASP.NET MVC (Preview 3) en el lado servidor y Javascript en el lado cliente, apoyándome en la librería jQuery, que tanto juego da. Aprovecharé de paso para comentar algunos aspectos interesantes de la preview 3 del framework MVC, de jQuery y de novedades de C# 3.0. Tocho de post, por tanto ;-)
El resultado será un formulario como el mostrado en la siguiente imagen:

Antes de nada: estructurar la solución
Para lograr el objetivo pretendido respetando el patrón MVC, debemos contar con los siguientes elementos:- El modelo, que representará la información manejada por el sistema. Para no complicar el ejemplo (o complicarlo, según se mire ;-)), vamos a crear una colección en memoria sobre la que realizaremos las consultas.
- La vista, que será un formulario en el que colocaremos los dos desplegables. El primero de ellos permitirá seleccionar una categoría tomada del Modelo, y el segundo mostrará los elementos de dicha categoría de forma dinámica.
- El controlador, en el que incluiremos acciones, en primer lugar, para inicializar y mostrar el formulario y, en segundo lugar, para obtener la lista de elementos relacionados con la categoría seleccionada. Esta última acción será invocada por la vista cuando el primer desplegable cambie de valor.
Primero: el modelo
En escenarios reales será el conjunto de entidades que representen el modelo de datos del sistema. En este caso montaremos un ejemplo muy simple, basado en un diccionario en memoria, y un par de métodos de consulta de la información en él mantenida.public class Datos
{
private static Dictionary<string, string[]> datos =
new Dictionary<string, string[]>
{
{ "Animal", new[] { "Perro", "Gato", "Pez"} },
{ "Vegetal", new[] { "Flor", "Árbol", "Espárrago"} },
{ "Mineral", new[] { "Cuarzo", "Pirita", "Feldespato"} }
};
public static IEnumerable<string> GetCategories()
{
return datos.Keys;
}
public static IEnumerable<string> GetElementsForCategory(string category)
{
string[] els = null;
datos.TryGetValue(category, out els);
return els;
}
}Destacar del código anterior los siguientes aspectos:
- La información se almacenará en un
Dictionary<string,string[]>. Esto, por si no estás muy familiarizado con los generics o tipos genéricos, sólo quiere decir que se trata de un diccionario cuya clave será de tipo string (las categorías) y el valor será un array de strings (los elementos asociados a cada categoría).
De esta forma, podremos obtener fácilmente la lista de categorías simplemente enumerando las claves (Keys) del diccionario, y los elementos contenidos en una categoría sólo con devolver el valor asociado a la misma, como vemos en los métodosGetCategories()yGetElementsForCategories(). - Para inicializar el diccionario he utilizado un inicializador de colecciones, una característica de C# 3.0 ya comentada en un post anterior.
- Los dos métodos de consulta de datos retornan un
IEnumerable<string>(¡me encantan los generics!), flexibilizando el tipo devuelto. Así, podríamos devolver cualquier tipo de objeto que implemente este interfaz, prácticamente todas las listas, colecciones y arrays, siempre que contengan en su interior unstring.
Segundo: la vista
Para nuestro ejemplo sólo necesitamos una vista, el formulario con los desplegables, que crearemos en el archivo Index.aspx. Además de componer el interfaz, la vista gestionará la interacción con el usuario haciendo que ante la selección de una opción del desplegable de categorías se invoque al controlador para solicitarle la lista de elementos de la categoría seleccionada, y cargar con ella el segundo desplegable.El código fuente del proyecto completo lo podéis encontrar en un enlace al pie del post, pero incluiré aquí las porciones más importantes. En primer lugar, el formulario HTML se compone así:
<form method="post" action="#">
<fieldset><legend>Formulario</legend>
<label for="ddCategory">Categoría:</label>
<%= Html.DropDownList("ddCategory") %>
<label for="ddElement">Elemento:</label>
<%= Html.DropDownList("ddElement") %>
</fieldset>
</form>Fijaos un momento en el código. Los desplegables, en lugar de utilizar el tag HTML <select> se han definido utilizando los métodos de ayuda (Html helpers) incluidos en el framework MVC. Estos, además de generar las etiquetas apropiadas, realizan otra serie de tareas como establecer valores de la lista, que nos ahorrarán mucho tiempo. En el controlador veremos cómo se le inyectan los elementos (los distintos <option>) desde código de forma muy sencilla.
<script type="text/javascript">
// Inicialización
$(document).ready(function() {
$("#ddCategory").change(function() {
cambiaElementos($("#ddCategory").val());
});
cambiaElementos($("#ddCategory").val());
});
// Carga el desplegable de elementos en función
// de la categoría que le llega como parámetro.
function cambiaElementos(cat) {
var dd = document.getElementById("ddElement");
dd.options.length = 0;
dd.options[0] = new Option("Espere...");
dd.selectedIndex = 0;
dd.disabled = true;
// Control de errores
$("#ddElement").ajaxError(function(event, request, settings) {
dd.options[0] = new Option("Categoría incorrecta");
});
// Obtenemos los datos...
$.getJSON(
'<%= Url.Action("GetElements") %>', // URL a la acción
{ category: cat }, // Objeto JSON con parámetros
function(data) { // Función de retorno exitoso
$.each(data, function(i, item) {
dd.options[i] = new Option(item, item);
});
dd.disabled = false;
});
}
</script>
En la primera parte se utiliza el evento jQuery
ready, ejecutada cuando la página está lista para ser manipulada, para introducir código de inicialización. En este momento se asocia al evento change del desplegable de categorías la llamada apropiada a la función cambiaElementos(), pasándole la categoría seleccionada. También se aprovecha para realizar la primera carga de elementos. Seguidamente está la función
Seguidamente está la función cambiaElementos, que se encargará de actualizar el desplegable con los elementos asociados a la categoría seleccionada. Para ello, en primer lugar, se introduce en el dropdown un elemento con el texto "Espere...", que aparecerá mientras el sistema obtiene los datos desde el servidor, a la vez que se deshabilita el control para evitar manipulación del usuario.Después se define la función que se ejecutará si durante la llamada Ajax se produce un error. Para ello utilizamos el evento
ajaxError, al que asociamos una función anónima que, simplemente, cargará en el desplegable secundario el texto "Categoría incorrecta" y lo dejará deshabilitado.Por último, utilizamos el método
getJSON para efectuar la llamada al servidor y realizar la carga del desplegable con la información devuelta. Son tres los parámetros que se le envían al método: - La URL de la acción, obtenida utilizando el helper
Url.Actionque devuelve la dirección de la acción cuyo nombre le pasamos como parámetro. - El objeto, en formato JSON, uyas propiedades representan los parámetros a enviar al controlador.
- La función a ejecutar cuando se reciban datos del servidor. El parámetro de entrada
datacontendrá el array de string con el que tenemos que llenar el desplegable, enviado desde el servidor según la notación JSON.
Aunque el recorrido de este vector y la carga de opciones en el control podría haberse realizado de forma sencilla mediante un bucle, he utilizado el métodoeachpara ilustrar el uso de este tipo de iteradores, tan de moda y muy al estilo funcional empleado, por ejemplo, en las expresiones lambda. Este método recibe dos parámetros; el primero es la colección sobre la cual se va a iterar, y el segundo es una función que se ejecutará para cada uno de los elementos recorridos.
Tercero: el controlador
Es el intermediario en toda esta historia: recibe las peticiones del cliente a través la invocación de acciones, ejecuta las tareas apropiadas y provoca la aparición o actualización de las vistas, utilizando para ello las clases ofrecidas por el Modelo.El controlador define dos acciones: la primera de ellas (Index) es la encargada de cargar los valores iniciales de los desplegables y enviar al usuario la vista correspondiente (Index.aspx). La segunda es la responsable de devolver un objeto en notación JSON con los elementos de la categoría enviada como parámetro.
El código es el siguiente:
public class HomeController : Controller
{
public ActionResult Index()
{
ViewData["ddCategory"] = new SelectList( Datos.GetCategories() );
ViewData["ddElement"] = new SelectList( new [] {"(Selecciona)"} );
return View();
}
public ActionResult GetElements(string category)
{
IEnumerable<string> elements = Datos.GetElementsForCategory(category);
if (elements == null)
throw new ArgumentException("Categoría " + category +" no es correcta");
Thread.Sleep(1000); // Simulamos tiempo de proceso...
return Json(elements);
}
}
Hay varios puntos que me gustaría destacar en este código. En primer lugar, observad que ya las acciones siguen la nueva convención introducida en la preview 3, retornando objetos de tipo
ActionResult. En el primer método, el return View() (sin parámetros) hace que el sistema envíe al cliente la vista cuyo nombre coincide con la acción actual (es decir, Index.aspx); en el segundo método se retorna un objeto de tipo JSonResult que serializará la información suministrada en formato JSON.También es destacable la ayuda introducida en la tercera Preview para llenar listas de formularios utilizando la clase
SelectList. Como podéis ver, basta con crear en el diccionario ViewData un elemento con el mismo nombre que el del desplegable y asignarle una instancia del SelectList inicializada con una colección de elementos (cualquier tipo que implemente IEnumerable). Él se encargará, al renderizar la página, de iterar sobre la colección y crear las etiquetas <option> oportunas.Asimismo, se puede observar el uso del Modelo en ambos métodos para leer los datos. En este caso se utiliza una clase que encapsularía la lógica de obtención de información, pero nada impediría, por ejemplo, asumir que las clases del Modelo son las generadas desde el diseñador de Linq2Sql y utilizar consultas Linq desde el Controlador.
Observad también el lanzamiento de la excepción cuando la categoría especificada no existe. Lo que llega al navegador en este caso es un error HTTP que es capturado por la función que especificamos para el evento
ajaxError, haciendo que en el desplegable enlazado aparezca un mensaje de error.Por último, la inclusión de la orden
Thread.Sleep() es por pura estética, para que se vea lo bien que queda el mensaje "Espere..." en el desplegable mientras carga los datos. En un escenario real este tiempo sería consumido por las comunicaciones cliente-servidor y la obtención de datos desde el modelo, que habitualmente utilizará una base de datos u otro mecanismo de persistencia. Descargar proyecto (Visual Web Developer Express 2008 + SP1 + ASP.NET MVC Preview 3).
Descargar proyecto (Visual Web Developer Express 2008 + SP1 + ASP.NET MVC Preview 3).Publicado en: http://www.variablenotfound.com/.

Cuando hace unas semanas ScottGu anunció la Preview 3 de ASP.NET MVC, quedé muy sorprendido de que al final no viniera con soporte para Visual Web Developer Express 2008, sobre todo teniendo en cuenta que un mes antes había adelantado este acontecimiento para los que estamos probando la plataforma MVC con esta herramienta.
Pero no, era una falsa alarma. Scott había olvidado comentarlo, y días más tarde rectificaba en un nuevo post en el que comunicaba que sí sería posible usar la Preview 3 desde la versión Express de Web Developer sin necesidad de usar plantillas específicas.
Desde entonces estaba deseando tener un ratillo para probarlo, y por fin ha llegado el momento.
En primer lugar, he de aclarar que, aunque pueda parecer lo contrario, no se trata de que el equipo de Microsoft haya introducido cambios en la plataforma MVC para hacerla compatible con la versión Express, sino al revés. Son los nuevos cambios introducidos en el IDE, y principalmente su recién estrenado soporte a proyectos de tipo Aplicación Web, los que hacen posible que funcione directamente sobre esta herramienta.
Y este es el motivo de que, antes que nada, sea necesario instalar el SP1 de .NET Framework 3.5 y de las herramientas Express (aún en Beta). Y si váis a hacerlo, mucho ojo, que todas las páginas donde aparece para descargar aparece llena de warnings; en otras palabras, no recomiendan su instalación en máquinas de verdad, sólo en entornos de prueba. Pero no os preocupéis, que para eso estoy yo ;-)
Después de un proceso algo lento y un par de reinicios del equipo, el Service Pack 1 Beta queda instalado sin problemas. Sólo falta descargar y montar la Preview 3 de ASP.NET MVC para que al ir a crear un nuevo proyecto desde Visual Web Developer aparezcan la plantilla MVC, entre otras novedades:

Y para probar, nada mejor que la aplicación de demostración sobre Northwind que preparó Phil Haack hace unas semanas. Salvo un ligero error de carga debido a que la versión Express no soporta la creación de proyectos de solución (no podremos probar los tests unitarios integrados en VS2008), todo funciona a la perfección.
Sí señor. Ahora sí que podemos seguir jugando. :-)
Publicado en: www.variablenotfound.com.
 Respondiendo a una consulta que hacía Joaquín hace un par de días, hoy describiremos una forma de hacer más atractivos los cuadros de edición de nuestros formularios web, introduciéndoles iconos o imágenes que, a la vez que adornan bastante, pueden ayudar al usuario a saber qué información debe introducir.
Respondiendo a una consulta que hacía Joaquín hace un par de días, hoy describiremos una forma de hacer más atractivos los cuadros de edición de nuestros formularios web, introduciéndoles iconos o imágenes que, a la vez que adornan bastante, pueden ayudar al usuario a saber qué información debe introducir.Pero para que quede claro lo que pretendemos, primero un ejemplo del resultado que vamos a conseguir:
La forma de conseguirlo es bastante sencilla. Basta con establecer, en las propiedades de estilo de los cuadros de edición una imagen de fondo con el icono que queremos incluir, y dejar un espaciado por la izquierda (padding-left) equivalente al ancho del mismo para que la introducción del texto comience a partir de ese punto.
Por ejemplo, si definimos las siguientes clases en el CSS de nuestra página (y suponiendo que la ruta de las imágenes sea correcta, claro):
.lupa
{
background: white url(icono_lupa.gif) no-repeat 2px center;
padding: 2px 2px 2px 18px;
}
.telefono
{
background: white url(icono_telefono.gif) no-repeat 2px center;
padding: 2px 2px 2px 18px;
}
Como se puede observar, se establece un fondo blanco con una imagen cuya URL se especifica (icono_xxxx.gif), mostrada sin repetición (no-repeat), posicionada en coordenada horizontal 2px y centrada verticalmente. El padding izquierdo será de 18px para que comience ahí el área de edición, a la derecha de la imagen.
Podremos utilizar después en nuestro HTML un código como el siguiente para conseguir que los cuadros de edición apararezcan "adornados" como nos interese en cada momento eligiendo para cada uno de ellos la clase CSS apropiada:
<input type="text" class="lupa" />
<input type="text" class="telefono" />
Espero que esto responda la duda, Joaquín.
Y por cierto, he utilizado esta técnica en el buscador del encabezado del blog, que lo tenía un poco soso...
Publicado en: www.variablenotfound.com.












