
 Una novedad que descubro en los tutoriales preliminares de la segunda versión de WebPages, y que por tanto tendremos disponible en las futuras versiones de WebMatrix y ASP.NET MVC 4, es la posibilidad de registrar los scripts y estilos que necesitan nuestros componentes visuales (sean layouts, vistas completas, parciales o helpers), centralizando su carga y evitando duplicidades.
Una novedad que descubro en los tutoriales preliminares de la segunda versión de WebPages, y que por tanto tendremos disponible en las futuras versiones de WebMatrix y ASP.NET MVC 4, es la posibilidad de registrar los scripts y estilos que necesitan nuestros componentes visuales (sean layouts, vistas completas, parciales o helpers), centralizando su carga y evitando duplicidades. El sistema de validación en cliente de ASP.NET MVC, como sabemos basado en jQuery validate, es el encargado de mostrar u ocultar los mensajes de error asociados a cada campo conforme va comprobando su validez.
El sistema de validación en cliente de ASP.NET MVC, como sabemos basado en jQuery validate, es el encargado de mostrar u ocultar los mensajes de error asociados a cada campo conforme va comprobando su validez. Los mensajes de error asociados a cada validador son almacenados inicialmente en atributos
data-val-* sobre el control a comprobar, y cuando se detecta un problema de validación, son mostrados copiando su contenido al interior de la etiqueta <span> que el helper Html.ValidationMessage() habrá generado sobre la página.Sin embargo, al hilo de una consulta reciente en los foros de ASP.NET MVC en MSDN, perfectamente contestada por el amigo Eduard Tomás, pensé que realmente tenemos poco control sobre cómo se muestran estos errores, así que me he puesto un rato a ver cómo podíamos conseguir introducir lógica personalizada en este punto aprovechando la flexibilidad que ofrece jQuery validate 1.9.
Salvo por la escasez de documentación de este componente, tomar el control en el momento de mostrar los mensajes de error es bastante sencillo. Basta con establecer una función en la propiedad
showErrors de los settings del plugin, cosa que podemos hacer con el siguiente script de inicialización:<script type="text/javascript">
$(function () {
var settings = $.data($('form')[0], 'validator').settings;
settings.showErrors = function (errorMap, errorList) {
// Aquí el código personalizado:
[...]
// Y si nos interesa, finalmente podemos
// ejecutar el comportamiento por defecto
this.defaultShowErrors();
};
});
</script>
(Por simplificar, estamos asumiendo que en el formulario hay un único tag <form>, que es el que capturamos con el selector).La función
showErrors() recibe dos parámetros. El primero es un “mapa” donde asociamos a cada clave (nombre del campo) el mensaje de error que tenga asociado. Así, por ejemplo, el valor de errorMap.Nombre será nulo si el campo “Nombre” del formulario no tiene ningún error (ha validado correctamente), o el texto del error en caso contrario.En el segundo parámetro de la función encontraremos un array con los errores a mostrar. En cada elemento tendremos disponible la propiedad
element, desde la que podemos acceder al control que ha generado el error, y message, donde podemos consultar o establecer la descripción del mismo.Es importante tener en cuenta que la función
showErrors() es invocada con mucha frecuencia durante el proceso de edición (pérdida de foco, obtención de foco, pulsación de teclas…), por lo que desde el punto de vista de la usabilidad no tiene demasiado sentido introducir en ella procesos bloqueantes (como puede ser un alert()) o demasiado largos en el tiempo, para evitar que se solapen.Por ejemplo, en el siguiente código utilizamos el efecto “highlight” de jQuery UI para resaltar con un rápido destello el elemento en el que se ha detectado un error:
settings.showErrors = function (errorMap, errorList) {
for (var i = 0; i < errorList.length; i++) {
var error = errorList[i];
// error.element es el elemento que ha provocado el error
$(error.element).effect("highlight", { times: 1 }, 100);
}
this.defaultShowErrors();
};
En fin, algo no demasiado útil ;-P, pero interesante en cualquier caso para profundizar un poco en los misterios e interioridades de jQuery validate.Publicado en Variable not found.
 El HTTP Referer es una variable que nos envían los navegadores en cada petición, permitiéndonos conocer de dónde viene el usuario, es decir, la página donde se encontraba el enlace, botón o formulario cuya activación ha provocado el salto a nuestro sitio.
El HTTP Referer es una variable que nos envían los navegadores en cada petición, permitiéndonos conocer de dónde viene el usuario, es decir, la página donde se encontraba el enlace, botón o formulario cuya activación ha provocado el salto a nuestro sitio.Por ejemplo, si un servidor recibe esta solicitud:
GET / HTTP/1.1
Accept: image/gif, image/jpeg, image/pjpeg, image/pjpeg, (...omitido...), */*
Referer: http://www.google.es/search?hl=es&rls=ig&q=variable&btnG=Buscar&meta=&aq=f&oq=User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; (...omitido...) )
Accept-Language: es
Accept-Encoding: gzip, deflate
Host: www.variablenotfound.com
Connection: Keep-Alive
analizando el campo Referer se puede determinar de forma muy sencilla que se trata de un usuario que proviene de Google, y que estaba buscando el término “variable”. Esta característica aporta una información, que aunque no es demasiado fiable (se puede alterar y desactivar muy fácilmente), se utiliza con mucha frecuencia con fines estadísticos, o para adecuar el contenido de la página a las intenciones del usuario.
Sin embargo, como se trata de una característica manejada directamente por el navegador, podemos encontrarnos con que no todos actúan de la misma manera... o en otras palabras, es Internet Explorer es el que actúa de forma diferente al resto ;-)
Si la visita a nuestra página se produce como consecuencia de la ejecución de un script que ha modificado dinámicamente el
location.href, o ha invocado a location.replace, Internet Explorer saltará a la nueva dirección, pero no enviará el Referer en los encabezados de la petición, por lo que en el punto de destino no se podrá conocer el origen de la misma.Por tanto, un código como el siguiente hará que la página editar.asp no pueda conocer desde dónde se le ha referenciado:
<input type="button" value="editar" onclick="location.href='editar.asp';">
Dado que Microsoft todavía está considerando modificar este comportamiento, hay que darle un poco las vueltas para conseguirlo provocando el salto hacia la página de destino sin utilizar los mecanismos citados anteriormente.
Una forma muy ingeniosa que he encontrado se basa en crear dinámicamente un tag
<a> con su correspondiente href establecido, y simular la pulsación del mismo invocando al evento click:function navigateWithReferrer(url) {var fakeLink = document.createElement("a");
if (typeof (fakeLink.click) == 'undefined')
location.href = url;
else {fakeLink.href = url;
document.body.appendChild(fakeLink);
fakeLink.click();
}
}
Visto en: Velocity Reviews
Publicado en: Variable not found

O en otras palabras, que podemos hacer uso de forma gratuita de estas librerías, sin limitación de ancho de banda e independientemente de si es para fines comerciales o no. Basta con referenciarlas desde nuestro código:
<script src="http://ajax.microsoft.com/ajax/jquery-1.3.2.min.js"
type="text/javascript"></script>
La principal ventaja que ofrece este método es la velocidad con la que estos archivos serán servidos, puesto que se usa la infraestructura del gigante de Redmon, a la vez que se comparte la caché con otros sitios web que también las estén utilizando. También brinda la posibilidad de utilizar scripting a sitios web que no disponen de permisos para subir archivos (como la plataforma blogger)
A diferencia del servicio de Google, desde esta CDN sólo podemos encontrar de momento las librerías que oficialmente forman parte de la plataforma de desarrollo de Microsoft, como las propias de ASP.NET Ajax, jQuery y aquellos plugins que vayan añadiéndose. En la dirección http://www.asp.net/ajax/cdn/ pueden consultarse la lista completa de librerías, con sus correspondientes direcciones de descarga.

Adicionalmente, Scott Guthrie comentaba en su blog que el nuevo control ScriptManager que vendrá con ASP.NET 4.0 incluye una propiedad llamada EnableCdn que permitirá activar la descarga de las librerías Ajax y todas aquellas necesarias para el funcionamiento de controles, directamente desde sus servidores.
Los inconvenientes, pues los mismos que los del servicio de Google: si no disponemos de conexión a la red en tiempo de desarrollo, podemos tenerlo realmente crudo.
Más información en: www.asp.net/ajax/cdn
Publicado en: Variable not found.
 Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.
Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.Esto aporta varias ventajas nada despreciables:
- primero, la descarga de estas librerías será, para el cliente, probablemente más rápida que si las tiene que obtener desde tu servidor a través de internet. Se trata de infraestructura de red de Google, y eso implica unas garantías.
- segundo, y relacionada con la anterior, si se trata de un sitio web de alto tráfico, la concurrencia permitida seguramente será infinitamente mayor que la que puedas ofrecer en otro servidor.
- tercero, si el usuario ha visitado previamente otro sitio web que use también la misma librería, se beneficiará del cacheado local de la misma, puesto que su navegador no la descargaría de nuevo. Y en cualquier caso, se estarían aprovechando las optimizaciones de caché de Google.
- cuarto, no consumes ancho de banda de tu proveedor, aunque éste sea despreciable. Y con despreciable me refiero al ancho de banda, no al proveedor ;-)
- quinto, puedes utilizar las librerías desde webs alojadas en algún sitio donde no se pueda, o no sea sencillo, subir archivos de scripts, como la plataforma Blogger desde la que escribo.
En este momento se contemplan los siguientes frameworks, en todas las versiones disponibles:
- jQuery
- jQuery UI
- Prototype
- script_aculo_us
- MooTools
- Dojo
- SWFObject
- Yahoo! User Interface Library (YUI)
Si ya estás utilizando librerías Ajax de Google (como el API de visualización, o el de Google Maps), y las obtienes mediante el cargador google.load(), también puedes utilizarlo para descargar estos frameworks. Asimismo, puedes hacerlo mediante una referencia directa, del tipo:
<script
src="http://ajax.googleapis.com/ajax/libs/prototype/1.6.0.2/prototype.js">
</script>
Ah, y no hay que preocuparse por los cambios de versiones, ni nada parecido. Google se compromete a alojar indefinidamente todas las distribuciones que vayan publicando, así como de incluir actualizaciones conforme aparezcan.
Por último, y para aportar una visión negativa, hay quien opina que se trata de una estrategia más de Google para obtener información sobre la navegación de los usuarios; la ejecución de código procedente de sus servidores posibilitaría la lectura de cookies y datos que podrían ser utilizados para fines distintos de los previstos en tu web. También hay quienes piensan que podría ser una fuente de difusión de código malicioso si alguien consiguiera hackear estos repositorios. Obviamente, tampoco es buena idea utilizar esta opción si vas a trabajar en modo local, sin conexión.
Para más información sobre las formas de descarga y las librerías disponibles, puedes visitar la guía del desarrollador de las Ajax libraries API.
Publicado en: www.variablenotfound.com.
 Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.
Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.Recapitulando, las técnicas de camuflaje de emails que habían aguantado el año y medio del experimento de Silvan Mühlemann, y por tanto se entendían más seguras que el resto de las empleadas en el mismo, fueron:
- Escribir la dirección al revés en el código fuente y cambiar desde CSS la dirección de presentación del texto.
- Introducir texto incorrecto en la dirección y ocultarlo después utilizando CSS.
- Generar el enlace desde javascript partiendo de una cadena codificada en ROT13.
En tiempo de ejecución, el control es capaz de generar código javascript que escribe en la página un enlace
mailto: completo, partiendo de una cadena previamente codificada creada desde el servidor. Dado que todavía no está generalizado entre los spambots la ejecución de javascript de las páginas debido al tiempo y capacidad de proceso necesario para realizarlo, podríamos considerar que esta es la opción más segura. Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.
Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.Pero, ah, malditos posyaques... la verdad es que con un poco de refactorización era posible generalizar el procedimiento de codificación y decodificación mediante el uso de clases específicas (Codecs), así que me puse manos a la obra. Liame incluye, de serie, cuatro algoritmos distintos de ofuscación para ilustrar sus posibilidades: ROT-N (el usado por defecto y más recomendable), Base64, codificación hexadecimal, y un codec nulo, que me ha sido muy útil para depurar y usar como punto de partida en la creación de nuevas formas de camuflaje. Algunos, además, aleatorizan los de nombres de funciones y variables para hacer que el código generado sea ligeramente distinto cada vez, de forma que un spammer no pueda romperlo por una simple localización de cadenas en posiciones determinadas; en fin, puede que sea una técnica un poco inocente, pero supongo que cualquier detalle que dificulte aunque sea mínimamente la tarea de los rastreadores, bueno será.
Incluso si así lo deseamos podremos generar, además del javascript de decodificación del enlace, el contenido de la etiqueta
<noscript>, en la que se incluirá el código HTML de la dirección a ocultar utilizando los dos trucos CSS descritos anteriormente y también considerados "seguros" por el experimento. De esta forma, aunque no estará disponible el enlace para este grupo de usuarios, podrán visualizar la dirección a la que podrán remitir sus mensajes. El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.
El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.Sin embargo, aún quedaba una cosa pendiente. El control de servidor está bien siempre usemos ASP.NET y que el rendimiento no sea un factor clave, puesto que al fin y al cabo estamos cargando de trabajo al servidor. Para el resto de los casos, Liame incluye en el proyecto de demostración un generador de javascript que, partiendo de los parámetros que le indiquemos, nos creará un script listo para copiar y pegar en nuestras páginas (X)HTML, PHP, Java, o lo que queramos. Como utiliza la base de Liame, cada script que generamos será distinto al anterior.
He publicado el proyecto en Google Code, desde donde se puede descargar tanto el ensamblado compilado como el código fuente del componente y del sitio de demostración. Esta vez he elegido la licencia BSD, no sé, por ir probando ;-)
La versión actual todavía tiene algunos detallitos por perfilar, como el control de la entrada en las propiedades (en especial las comillas y caracteres raros: ¡mejor que nos los uséis!), que podría dar lugar a un javascript sintácticamente incorrecto, pero en general creo que se trata de una versión muy estable. Ha sido probada con Internet Explorer 7, Firefox 3 y Chrome, los tres navegadores que tengo instalados.
También, por cortesía de Mergia, he colgado un proyecto de demostración para que pueda verse el funcionamiento en vivo y en directo, tanto del control de servidor como del generador de javascript.

Finalmente, algunos aspectos que creo interesante comentar. En primer lugar, me gustaría recordaros que las técnicas empleadas por Liame no aseguran, ni mucho menos, que los emails de las páginas van a estar a salvo de los del lado oscuro eternamente, aunque de momento así sea. Lo mejor es no confiarse.
En segundo lugar, es importante tener claro que todas las técnicas aquí descritas pueden resultar bastante nocivas para la accesibilidad de las páginas en las que las utilicéis. Tenedlo en cuenta, sobre todo, si tenéis requisitos estrictos en este sentido.
Y por último, añadir que estaré encantado de recibir vuestras aportaciones, sugerencias, colaboraciones o comentarios de cualquier tipo (sin insultar, eh?) que puedan ayudar a mejorar este software.
Enlaces
Publicado en: www.variablenotfound.com.
 Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href="mailto:user@myserver.xx">email me</a> - Sustituyendo las arrobas por "AT" y los puntos por "DOT", de forma que una dirección queda de la forma:
<a href="mailto:userATserverDOTxx">email me</a> - Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href="mailto:user@server.xx">email me</a> - Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href="mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65">email me</a> - Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!-- -->@<!--- @ -->my<!-- -->server.<!--- . -->com - Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = "user";
var string2 = "@";
var string3 = "myserver.xx";
var string4 = string1 + string2 + string3;
document.write("<a href=" + "mail" + "to:" + string1 +
string2 + string3 + ">" + string4 + "</a>"); - Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type="text/css">
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class="codedirection">moc.revresym@resu</span> - Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type="text/css">
span.displaynone { display:none; }
</style>
Email me: user@<span class="displaynone">goaway</span>myserver.net - Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type="text/javascript">
document.write('<n uers=\"znvygb:fvyinasbbone10@gvyyyngr.pbz\" ery=\"absbyybj\">'.replace(/[a-zA-Z]/g, function(c){return String.fromCharCode((c<="Z"?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar's Mail</a>
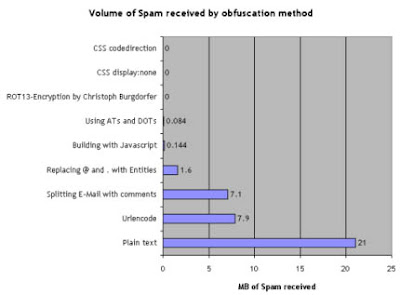 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces
mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href="mailto:loquesea">, incluidos los caracteres de inicio "<" y fin ">", pero sin introducir el texto del enlace ni el cierre </a> de la misma).También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace
mailto: completo en nuestras páginas.Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de "AT" y "DOT", o equivalentes en nuestro idioma como "EN" y "PUNTO", con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como "juanARROBICAservidorPUNTICOcom", o "juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom". Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Publicado en: www.variablenotfound.com.
 Aunque es lo que más mola, los desarrolladores no siempre podemos trabajar con los últimos lenguajes y tecnologías. De hecho, solemos pasar gran parte de nuestro tiempo manteniendo y mejorando sistemas basados en plataformas que consideramos obsoletas o de menor potencia que las habituales, lo que nos lleva a tener que dar respuesta "artesana" a problemas que usando tecnologías más apropiadas estarían solucionados.
Aunque es lo que más mola, los desarrolladores no siempre podemos trabajar con los últimos lenguajes y tecnologías. De hecho, solemos pasar gran parte de nuestro tiempo manteniendo y mejorando sistemas basados en plataformas que consideramos obsoletas o de menor potencia que las habituales, lo que nos lleva a tener que dar respuesta "artesana" a problemas que usando tecnologías más apropiadas estarían solucionados.Hoy por ejemplo, desarrollando con VbScript en un entorno propietario embebido en un sistema de gestión empresarial hemos necesitado crear GUIDs y hemos visto que el lenguaje no dispone de esta capacidad, a diferencia de .Net o Java, que proporcionan vías para conseguirlo de forma muy sencilla.
Preguntándole a Google, que todo lo sabe, he encontrado varias soluciones aplicables de forma directa.
La primera, es usar funciones propias del motor de base de datos. En nuestro caso concreto, la solución está conectada a un SQL Server, que afortunadamente dispone desde la versión 2000 de una función integrada de generación de GUIDs. Así pues, podríamos utilizar un código como el siguiente:
' Obtiene un nuevo GUID
' Parámetro: una conexión abierta
function ObtenerGUID(conn)
dim rs
set rs = conn.Execute("Select NEWID()")
if (not rs.eof) then
ObtenerGUID = rs(0)
end if
end functionPero, ¿y si no usas SQL Server? No pasa nada, prácticamente todos los motores de bases de datos incorporan algún mecanismo equivalente, como MySQL ("
UUID()") y Oracle ("SYS_GUID()").En este momento podríamos decir que tenemos una buena solución... siempre que tengamos a mano una conexión a una base de datos capaz de generar un GUID. ¿Y si no fuera este el caso? Aquí va otro código que utilizando un objeto
Scriptlet.TypeLib, utilizado por Windows como soporte a los lenguajes de scripting:' Obtiene un nuevo GUID
Function ObtenerGUID()
dim typeLib, guid
set typeLib = CreateObject("Scriptlet.TypeLib")
guid = typeLib.Guid
ObtenerGUID= left(guid, len(guid)-2)
set typeLib = Nothing
End FunctionTambién hay quien utiliza llamadas a UUIDGEN.EXE, una utilidad proporcionada normalmente con kits de desarrollo de .NET y los entornos Visual Studio, generando el GUID sobre un archivo de texto para más tarde leerlo desde el script, pero me ha parecido una solución demasiado compleja para el problema.
Por último he encontrado unos ejemplos de código en el centro de soporte de Microsoft que muestran varias maneras de crear identificadores únicos, aunque me quedo con la más completa, consistente en generar la secuencia de caracteres aleatorios:
' Obtiene un GUID tipo Windows
' 8+4+4+4+12 caracteres A-Z y 0-9
Function CreateWindowsGUID()
CreateWindowsGUID = CreateGUID(8) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(12)
End Function
' Obtiene un GUID del tamaño indicado
' Parámetro: longitud del GUID
Function CreateGUID(tmpLength)
Randomize Timer
Dim tmpCounter,tmpGUID
Const strValid = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"
For tmpCounter = 1 To tmpLength
tmpGUID = tmpGUID & Mid(strValid, Int(Rnd(1) * Len(strValid)) + 1, 1)
Next
CreateGUID = tmpGUID
End FunctionPublicado en: www.variablenotfound.com.
Recordemos que los métodos estáticos de página son una interesante capacidad que nos ofrece este framework para poder invocar desde cliente (javascript) funciones de servidor (codebehind) de una forma realmente sencilla. Además, gracias a los mecanismos de seriación incluidos, y como ya vimos en el post "Usando ASP.NET AJAX para el intercambio de entidades de datos", es perfectamente posible devolver desde servidor entidades o estructuras de datos complejas, y obtenerlas y procesarlas directamente desde cliente utilizando javascript, y viceversa.
Es es ahí donde reside el problema con los DataSets: precisamente este tipo de datos no está soportado directamente por el seriador JSON incorporado, que es el utilizado por defecto, de ahí que se genere una excepción como la que sigue:
System.InvalidOperationException
A circular reference was detected while serializing an object of type 'System.Globalization.CultureInfo'.
en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValueInternal(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat serializationFormat)\r\n en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValue(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat [...]
Pero antes de nada, un inciso. Dado que la excepción se produce en el momento de la seriación, justo antes de enviar los datos de vuelta al cliente, debe ser capturada en cliente vía la función callback especificada como último parámetro en la llamada al método del servidor:
// Llamada a nuestro PageMethod
PageMethods.GetData(param, OnOK, OnError);
[...]
function OnError(msg)
{
// msg es de la clase WebServiceError.
alert("Error: " + msg.get_message());
}
Aclarado esto, continuamos con el tema. La buena noticia es que el soporte para DataSets estará incluido en futuras versiones de la plataforma. De hecho, es perfectamente posible utilizar las librerías disponibles en previews disponibles en la actualidad. Existen multitud de ejemplos en la red sobre cómo es posible realizar esto, aunque será necesario instalar alguna CTP y referenciar librerías en el Web.config. Podéis echar un vistazo a lo descrito en este foro.
Esta solución sin embargo no es muy recomendable en estos momentos, puesto que estaríamos introduciendo en un proyecto librerías y componentes que, en primer lugar, están ideados sólo para probar y tomar contacto con las nuevas tecnologías, y, en segundo lugar, las características presentadas en ellos pueden modificarse o incluso eliminarse de las futuras versiones.
Existen otras formas de hacerlo, como la descrita en siderite, que consiste en crear un conversor justo a la medida de nuestras necesidades extendiendo la clase
JavaScriptConverter, aunque aún me parecía una salida demasiado compleja al problema.Sin embargo, la solución que he visto más simple es utilizar XML para la seriación de estas entidades, lo que se puede lograr de una forma muy sencilla añadiendo al método a utilizar un atributo modificando el formato de respuesta utilizado por defecto, de JSON a XML.
He creado un proyecto de demostración para VS2005, esta vez en VB.NET aunque la traducción a C# es directa, con una página llamada DataSetPageMethods.aspx en el que se establece un PageMethod en el lado del servidor, con la siguiente signatura:
<WebMethod()> _
<Script.Services.ScriptMethod(ResponseFormat:=ResponseFormat.Xml)> _
Public Shared Function ObtenerClientes(ByVal ciudad As String) As DataSet
 Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.
Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.Como podréis observar, el método está precedido por la declaración de dos atributos. El primero de ellos,
WebMethod(), lo define como un PageMethod y lo hará visible desde cliente de forma directa. El segundo de ellos redefine su mecanismo de seriación por defecto, pasándolo a XML. Si queréis ver el error al que hacía referencia al principio, podéis modificar el valor del ResponseFormat a JSON, su valor por defecto.Desde cliente, al cargar la página rellenamos un desplegable con las distintas ciudades. Cuando el usuario selecciona un elemento y pulsa el botón "¡Pulsa!", se realizará una llamada asíncrona al PageMethod, según el código:
function llamar()
{
PageMethods.ObtenerClientes($get("<%= DropDownList1.ClientID %>").value , OnOK, OnError);
}
La función callback de notificación de finalización de la operación,
OnOk, recibirá el DataSet del servidor y mostrará en la página dos resúmenes de los datos obtenidos que describiré a continuación. He querido hacerlo así para demostrar dos posibles alternativas a la hora de procesar desde cliente los datos recibidos, el DataSet, desde servidor.En el primer ejemplo, se crea en cliente una lista sin orden con los nombres de las personas de contacto de los clientes (valga la redundancia ;-)), donde muestro cómo es posible utilizar el DOM para realizar recorridos sobre el conjunto de datos:
var nds = data.documentElement.getElementsByTagName("NewDataSet");
var rows = nds[0].getElementsByTagName("Table");
var st = rows.length + " filas. Personas: br />";
st += "<ul>";
for(var i = 0; i < rows.length; i++)
{
st += "<li>" + getText(rows[i].getElementsByTagName("Contatto")[0])+ "</li>";
}
st += "</ul>";
etiqueta.innerHTML = st;
En el segundo ejemplo se muestra otra posibilidad, la utilización de DOM para crear una función recursiva que recorra en profundidad la estructura XML mostrando la información contenida. La función javascript que realiza esta tarea se llama
procesaXml.Como se puede comprobar analizando el código, utilizar la información del
DataSet en cliente es necesario, en cualquier caso, un conocimiento de la estructura interna de est tipo de datos, lo cual no es sencillo, por lo que recomendaría enviar y gestionar los DataSets en cliente sólo cuando no haya más remedio.Una alternativa que además de resultar menos pesada en términos de ancho de banda y proceso requerido para su tratamiento es bastante más sencilla de implementar sería enviar a cliente la información incluida un un array, donde cada elemento sería del tipo de datos apropiado (por ejemplo, un array de Personas, Facturas, o lo que sea). La seriación será JSON, mucho más optimizada, además de resultar simplísimo su tratamiento en javascript.
El proyecto de demostración también incluye una página (ArrayPageMethods.aspx) donde está implementado un método que devuelve un array del tipo
Datos, cuya representación se lleva también a cliente y hace muy sencillo su uso, como se puede observar en esta versión de la función de retorno OnOk:
function OnOK(datos)
{
var etiqueta = $get("lblMensajes");
var s = "<ul>";
for (var i = 0; i < datos.length; i++)
{
s += "<li>" + datos[i].Contacto;
s += ". Tel: " + datos[i].Telefono;
s += "</li>";
}
s += "</ul>";
etiqueta.innerHTML = s;
}
Por último, comentar que el proyecto de ejemplo funciona también con VS2008 (Web Developer Express), aunque hay que abrirlo como una web existente.
Publicado en: www.variablenotfound.com.
Enlace: Descargar proyecto VS2005.
Concretamente, gerardo pregunta cómo podría añadir varios controladores con parámetros al evento OnLoad de la página, como él mismo dice,
La funcion de script que usas para añadir varias funciones al evento onload esta bien si son llamadas sin parametros. La duda es cómo podría hacer lo mismo si la función que tiene que correr en el inicio recibiera un parametro de entrada.Siguiendo tu ejemplo, me gustaria usar algo como:
addOnLoad(init1(3));
addOnLoad(init2(4));
Efectivamente, la fórmula que propone este amigo no es válida; de hecho, estaríamos añadiendo al evento OnLoad el retorno de la llamada a
init1(3), lo cual sólo funcionaría si esta función devolviera una referencia a una función capaz de ser invocada por el sistema.Para hacerlo de forma correcta, como casi siempre en este mundo, hay varias formas. Comentaré algunas de ellas.
La obvia
Ni que decir tiene que el método más sencillo es sin duda introducir las llamadas en el atributo onload del elemento body de la página, es decir,
<body onload="alert('hola 1'); alert('hola 2');">
Por desgracia no siempre es posible modificar el atributo onload del cuerpo de la página, así que lo mejor será estudiar otras maneras.
La fácil
También podríamos utilizar un modelo bastante parecido al indicado en el post inicial, vinculando al OnLoad una función que, a su vez, llamará a las distintas funciones (con los parámetros oportunos) de forma secuencial:
// Asociamos las funciones al
// evento OnLoad:
addOnLoad(miFuncion1);
addOnLoad(miFuncion2);
function miFuncion1() {
alert('hola 11');
alert('hola 12');
}
function miFuncion2() {
alert('hola 2');
}
La "pro"
Aunque cualquiera de los dos métodos comentados hasta el momento son válidos y funcionan perfectamente, vamos a ver otra en la que se utiliza una característica de javascript (y otros lenguajes, of course), las funciones anónimas.Las funciones anónimas son como las de toda la vida, pero con un detalle que la diferencia de éstas: no tienen nombre. Se definen sus parámetros y su cuerpo de forma directa en un contexto en el que pueden ser utilizados sin necesidad de indicar qué nombre vamos a darle.
En el caso que nos ocupa, y tomando como base el ejemplo anterior, en vez de invocar a la función addOnLoad() pasándole como parámetro el nombre de la función que contiene lo que queremos hacer, le enviaríamos una función anónima indicando exactamente lo que queremos hacer:
// En este código se hace lo mismo que
// el ejemplo anterior:
addOnLoad(
function() {
alert('hola 11');
alert('hola 12');
}
);
addOnLoad( function() { alert('hola 2'); } );
De esta forma la llamada a la función addOnLoad se realiza utilizando como parámetro la referencia a la función anónima, y todo puede funcionar correctamente.
 Inicializaciones de librerías, llamadas a servidor mediante Ajax para obtener datos o porciones de la página, efectos gráficos... son sólo algunos de los escenarios donde resulta interesante utilizar scripts de arranque o (startup scripts), que se ejecuten en cliente en cuanto le llegue la página web.
Inicializaciones de librerías, llamadas a servidor mediante Ajax para obtener datos o porciones de la página, efectos gráficos... son sólo algunos de los escenarios donde resulta interesante utilizar scripts de arranque o (startup scripts), que se ejecuten en cliente en cuanto le llegue la página web.Esto hay al menos dos formas de hacerlo: llamar a la función deseada desde el evento
onload() del cuerpo de la página o bien hacerlo en un bloque de scripts fuera de cualquier función, bien sea dentro del propio (X)HTML o bien en un recurso .js externo. Pero hace tiempo que tenía una curiosidad: ¿qué diferencia hay entre una u otra? ¿cuándo deben usarse? ¿tienen contraindicaciones?Para averiguarlo, he creado la siguiente página:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head>
<title>Prueba de scripting</title>
</head>
<body onload="alert('OnLoad()');">
<h1>Prueba Scripting</h1>
</body>
<script type="text/javascript">
alert('Script en HTML');
</script>
<script type="text/javascript" src="script.js"></script>
</html>Como se puede observar:
- en el elemento <body> he incluido un atributo onload="alert('onload');".
- he añadido un bloque script con una única instrucción alert('script HTML');
- he añadido también una referencia a un archivo script externo, en el que sólo hay una instrucción alert('archivo .js');
- Se ejecuta en primer lugar el código incluido en los bloques <script> .
- Si hay varios bloques de script, se ejecuta el código incluido en cada uno de ellos, siguiendo del orden en el que están declarados.
- No importa si son scripts incrustados en la página o si se encuentran en un archivo .js externo, se ejecutan cuando le llega el turno según el orden en el que han sido definidos en la página, es decir, la posición del tag <script> correspondiente.
- Por último, se ejecuta el código del evento onload del cuerpo de la página. De hecho, este evento se ejecuta una vez se ha cargado y mostrado la página al usuario, es el último en tomar el control.
Debemos usar onload() si queremos que nuestro código se ejecute al final, cuando podemos asegurar que todo lo que tenía que pasar ya ha pasado; eso sí, mucho ojo, que onload() es un recurso limitado (de hecho, sólo hay uno ;-)), y si no se tiene cuidado podemos hacer que una asignación nuestra haga que no se ejecute la función anteriormente definida para el evento. Esto se evita normalmente incluyendo en el atributo onload de la etiqueda body las sucesivas llamadas a las distintas funciones de inicialización requeridas (
<body onload="init1(); init2();"...), o bien desde script utilizando el siguiente código, todo un clásico:
function addOnLoad(nuevoOnLoad) {
var prevOnload = window.onload;
if (typeof window.onload != 'function') {
window.onload = nuevoOnLoad;
}
else {
window.onload = function() {
prevOnload();
nuevoOnLoad();
}
}
}
// Las siguientes llamadas enlazan las
// funciones init1() e init2() al evento
// OnLoad:
addOnLoad(init1);
addOnLoad(init2);
En cambio, la introducción de código de inicialización directamente en scripts se ejecutará al principio, incluso antes de renderizar el contenido de la página en el navegador, por lo que es bastante apropiada para realizar modificaciones del propio marcado (por ejemplo a través del DOM) o realizar operaciones muy independientes del estado de carga de la página. Como ventaja adicional, destacar su facilidad para convivir con otros scripts similares o asociados al evento OnLoad().











