
miércoles, 27 de febrero de 2008
 Sabemos que los patrones son plantillas reutilizables que podemos usar para solucionar problemas habituales en el proceso de desarrollo de software. Así, permiten utilizar soluciones fiables y bien conocidas a problemas concretos, aprovechando experiencias previas como base para la consecución de mejores resultados en los nuevos desarrollos.
Sabemos que los patrones son plantillas reutilizables que podemos usar para solucionar problemas habituales en el proceso de desarrollo de software. Así, permiten utilizar soluciones fiables y bien conocidas a problemas concretos, aprovechando experiencias previas como base para la consecución de mejores resultados en los nuevos desarrollos.Pues bien, justo en el lado opuesto se encuentran los antipatrones, que definen situaciones y comportamientos que, según experiencias anteriores, nos conducen al fracaso en proyectos de desarrollo de software, es decir, son soluciones o planteamientos que se han demostrado incorrectos.
Y es ahí donde radica su interés: la observación y conocimiento de los mismos puede evitarnos resultados desastrosos, o actuar como alertas tempranas ante decisiones o dinámicas incorrectas, permitiéndonos prevenir, evitar o recuperarnos de estos problemas.
Al igual que en los patrones, su descripción está relativamente formalizada y suele recoger los siguientes aspectos:
- nombre del antipatrón, así como su "alias"
- su tipología: organizacional, de análisis, desarrollo... (veremos esto más tarde)
- contexto y entorno en el que se aplica
- descripción del problema concreto
- síntomas, y consecuencias de la aplicación del antipatrón
- causas típicas y raíces del problema
- refactorización a aplicar, es decir, una descripción de cómo podríamos replantear el problema y conseguir una solución positiva.
- ejemplos y escenarios para su comprensión.
- soluciones relacionadas con la propuesta.
Por ejemplo, un resumen del clásico antipatrón que reconoceréis muy rápidamente, el llamado spaghetti code:
| Nombre: | Spaghetti Code |
| Tipología: | Desarrollo |
| Problema: | Existencia de una pieza de código compleja y sin apenas estructura que dificulta enormemente su mantenimiento posterior |
| Síntomas y consecuencias: |
|
| Causas: |
|
| Solución positiva: |
|
Según según la Wikipedia, los antipatrones se clasifican en los siguientes grupos, atendiendo a las áreas a las que afectan:
- Antipatrones Organizacionales, que incluyen prácticas nocivas a este nivel, como pueden ser, entre otros:
- Gestión de champiñones (Mushroom management), o mantener al equipo en la oscuridad, desinformado, y cubierto de porquería.
- Parálisis en análisis (Analysis paralysis), o quedar inmovilizado debido a un análisis o precaución excesiva, en contraposición a la siguiente:
- Extinción por intuición (Extint by instinct), llegar a la muerte por adelantarse demasiado y usar la intuición para la toma de decisiones.
- Antipatrones de Gestión de proyectos, describiendo problemas en la gestión de proyectos, como los célebres:
- Marcha de la muerte (Death march), que describe el avance de determinados proyectos hacia el fracaso aunque todo el personal, excepto los gerentes, saben que al final se darán el castañazo.
- Humo y espejos (Smoke and mirrors), o la demostración de funcionalidades o características no implementadas como si fueran reales, lo que siempre he llamado "enseñar cartón piedra".
- Antipatrones de Gestión de equipos, que recoge problemas relacionados con la relación con y de equipos de trabajo, como:
- Doble diabólico (traducción libre del término Doppelganger), personas que dependiendo del día pueden ser magníficos colaboradores o auténticos demonios.
- Gestor ausente (Absentee manager), describiendo situaciones en las que el director está invisible periodos prolongados
- Antipatrones de Análisis, categoría que engloba antipatrones relacionados con la fase analítica de los proyectos software, entre otros:
- Retroespecificación (Retro-specification), o lo que viene a ser la realización del análisis una vez implementada la solución.
- Especificación de servilleta (Napkin specification), también muy socorrida, que consiste en pasar al equipo de desarrollo las especificaciones del producto a crear descritas con muy poco detalle o informalmente.
- Antipatrones de Diseño, que incluye malas prácticas de diseño de software que dan lugar a aplicaciones y componentes estructuralmente incorrectos:
- Gran bola de lodo (Big ball of mud), realización de aplicaciones sin estructura reconocible.
- Factoría de gas (Gas factory), diseños innecesariamente complejos.
- Botón mágico (Magic Pushbutton), o implementación de funcionalidades directamente en los manejadores de evento (p.e., click) del interfaz.
- Antipatrones en Orientación a objetos, como una especialización del anterior, describe problemas frecuentes en los diseños creados bajo este paradigma, como:
- Llamar al super (Call super), obligar a las subclases a llamar a la clase de la que heredan.
- Singletonitis, abuso del patrón singleton.
- Orgía de objetos (Object orgy), o encapsulación incorrecta en clases que permite el acceso incontrolado a sus métodos y propiedades internas.
- Otra jodida capa más (YAFL, Yet another fucking layer), o la inclusión excesiva de capas en un sistema.
- Antipatrones de Programación, con un gran número de errores frecuentes a evitar, como:
- Spaghetti code, comentando anteriormente.
- Ravioli code, que consiste en la existencia de un gran número de objetos desconectados o débilmente acoplados entre sí.
- Ocultación de errores (Error hiding), o capturar errores antes de que lleguen usuario, mostrando mensajes incomprensibles o simplemente no mostrar nada.
- Números mágicos (Magic numbers), incluir números inexplicables en el código.
- Antipatrones Metodológicos, o formas de desarrollar que se han demostrado incorrectas a lo largo del tiempo, como pueden ser:
- Programación copy & paste, también llamada herencia de editor, consiste en copiar, pegar y modificar, en contraposición a la estritura de software reutilizable.
- Factor de improbabilidad (Improbability factor), asumir que un error conocido es improbable que ocurra.
- Optimización prematura (Premature optimization), según algunos la raíz de todos los males, consiste en sacrificar el buen diseño y mantebilidad de un software en benecificio de la eficiencia.
- Programación por permutación (Programming by permutation), o intentar dar con una solución modificando sucesivamente el código para ver si funciona.
- Antipatrones de Gestión de configuración, hace referencia a antipatrones relacionados con la gestión de los entornos de desarrollo y explotación del software, como las variantes del infierno de las dependencias (Dependency hell), o problemas de versionado de librerías y componentes:
- DLL's Hell, el conocido y traumático mundo de las librerías dinámicas en Windows.
- JAR's Hell, idem, pero relativo a las librerías Java.
Por no hacer el post eterno sólo he recogido unos cuantos, aunque existen cientos de ellos, y con una gran variedad temática: antipatrones para el desarrollo guiado por pruebas (TDD), antipatrones de manejo de excepciones, para el uso de arquitecturas orientadas al servicio (SOA), de rendimiento, de seguridad, centrados en tecnologías (p.e., J2EE antipatterns) o según el tipo de software (sistemas de gestión, tiempo real, videojuegos, etc.).
Y como conclusión personal, decir que me he visto reconocido en multitud de ellos, lo cual significa que muy descaminados no andan. Es más, si hiciera una lista con patrones y otra con los antipatrones que utilizo o he utilizado, la segunda tendría más elementos que la primera... ¿quizás es momento de reflexionar un poco?
Publicado en: http://www.variablenotfound.com/.
domingo, 24 de febrero de 2008
 Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático
Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático string.IsNullOrEmpty, sobre todo si podemos asegurar que no aparecerá el famoso bug del mismo (que al final no es para tanto, todo sea dicho).Los métodos de extensión nos brindan la posibilidad de hacer lo mismo pero de una forma más elegante e intuitiva, impensable hasta la llegada de C# 3.0: extendiendo la clase
string con un método que compruebe su contenido.La forma de conseguirlo es bien sencilla. Declaramos en una clase estática el método de extensión sobre el tipo
string:public static class MyExtensions
{
public static bool IsNullOrEmpty(this string s)
{
return s == null || s.Length == 0;
}
}Y listo, ya tenemos el nuevo método listo para ser utilizado:
string name = getCurrentUserName();
if (!name.IsNullOrEmpty())
...De todas formas, hay un par de reflexiones que considero interesante comentar.
En primer lugar, fijaos en el ejemplo anterior que aunque la variable
name contenga un nulo, se ejecutará la llamada a IsNullOrEmpty() sin provocar error, algo imposible si se tratara de un método de instancia. Obviamente, se debe a que en realidad se está enmascarando una llamada a un método estático al que le llegará como parámetro un null.Como consecuencia de lo anterior, y dado que no se puede distinguir a simple vista en una llamada a un método si éste es de instancia o de extensión, es posible que un desarrollador considerara esta invocación incorrecta. Esto forma parte de los inconvenientes de los métodos de extensión que ya cité en un post anterior.
En segundo lugar, visto lo visto cabría preguntarse, ¿por qué podemos extender una clase añadiéndole nuevos métodos pero no es posible incluir otro tipo de elementos, como eventos o propiedades? En el caso anterior podría quedar más fino que
IsNullOrEmpty fuera una propiedad de string, ¿no? Sin embargo, esto no es posible de momento. Según comentó ScottGu hace tiempo, se estaba considerando añadir la posibilidad de extender las clases también con nuevas propiedades. Supongo que el hecho de no haberla incluido en esta versión se deberá a que no era necesario para LINQ, la estrella de esta entrega... ¡y para dejar algo por hacer para C# 4.0, claro! ;-)
En cualquier caso, se trata principalmente de una cuestión de estética del código. Todo lo que conseguimos con las propiedades se puede realizar a base de métodos; de hecho, las propiedades no son sino interfaces más agradables a métodos getters y setters, al más puro estilo Java, subyacentes.
Por último, todo lo dicho es válido para VB.NET 9, salvo las obvias diferencias. El código equivalente al anterior sería:
Imports System.Runtime.CompilerServices
Module MyExtensions
<Extension()> _
Public Function IsNullOrEmtpy(ByVal s As String) As String
Return (s = Nothing) OrElse (s.Length = 0)
End Function
End Module
[...]
' Forma de invocar el método:
If s.IsNullOrEmtpy() Then
[...]
Publicado en: http://www.variablenotfound.com/.
martes, 19 de febrero de 2008

Después de pasar un buen rato entretenido con la recopilación de frases célebres relacionadas con el mundo de la informática y especialmente el desarrollo de software, "101 Great computer programming quotes", publicado en DevTopics hace unas semanas, no he podido resistir la tentación de traducirlo, previo contacto con su autor, el amabilísimo Timm Martin.
Este es el primer post de la serie compuesta por:
- 101 citas célebres del mundo de la informática (este post)
- Otras 101 citas célebres del mundo de la informática
- Y todavía otras 101 citas célebres del mundo de la informática
- 101 nuevas citas célebres del mundo de la informática (¡y van 404!)
domingo, 17 de febrero de 2008
 Encuentro en Apuntes de un Loco que hace un par de días Microsoft publicó las especificaciones de varios de sus formatos de archivo binario de Microsoft Office, así como otros de soporte, en el contexto del compromiso de apertura de especificaciones que mantiene desde algo más de un año.
Encuentro en Apuntes de un Loco que hace un par de días Microsoft publicó las especificaciones de varios de sus formatos de archivo binario de Microsoft Office, así como otros de soporte, en el contexto del compromiso de apertura de especificaciones que mantiene desde algo más de un año.Podemos encontrar (en inglés, por supuesto) la descripción detallada de los siguientes formatos de archivo:
- Word 97-2007 (.doc)
- Powerpoint 97-2007 (.ppt)
- Excel 97-2007 (.xls)
- Excel 2007 (.xlsb)
- Office Drawing 97-2007
- Compound file (OLE 2.0)
- Windows Metafile (.wmf)
- Ink Serialized Format (ISF)
Una iniciativa interesante derivada de esto ha sido la creación en SourceForge del proyecto "Office Binary Translador to Open XML", que pretende crear herramientas de conversión automática a este estándar ECMA. Supongo que en breve esta información se usará también para realizar conversiones fiables hacia y desde otros formatos, como los utilizados en otras suites ofimáticas como Open Office (Open Document).
Se trata sin duda de una buena noticia para facilitar la interoperabilidad entre aplicaciones.
Publicado en: http://www.variablenotfound.com/.
domingo, 10 de febrero de 2008
Existen muchos consejos para crear código mantenible, como los que ya cité cuando hablaba sobre comentar el código fuente, pero ninguno iguala a este:

Al parecer se trata de un leyenda urbana sobre Visual C++ 6.0, pero no deja de tener su razón...
Imagen: My Confined Space
Publicado en: http://www.variablenotfound.com/.
"Always code as if the person who will maintain your code is a maniac serial killer that knows where you live"
(Codifica siempre como si la persona que fuera a mantener tu código fuera un asesino en serie maníaco que sabe donde vives)
Al parecer se trata de un leyenda urbana sobre Visual C++ 6.0, pero no deja de tener su razón...
Imagen: My Confined Space
Publicado en: http://www.variablenotfound.com/.
martes, 5 de febrero de 2008
Hace sólo unos días alucinaba con la existencia y gran difusión del leet speak, y de nuevo vuelvo a asombrarme con la programación esotérica, otra prueba de que en este mundillo siempre hay algo sorprendente que descubrir.
Los lenguajes esotéricos, también llamados esolangs, son lenguajes de programación cuyo objetivo, al contrario que en los "tradicionales", no es ser útil, ni solucionar problemas concretos, ni ser especialmente práctico, ni siquiera incrementar la productividad del desarrollador. De hecho, lo normal es que atente contra todas estas características de forma contundente.
Aunque algunos se diseñan como pruebas de concepto de ideas para determinar su viabilidad en lenguajes reales, lo más frecuente es que sean creados por diversión y exclusivamente con objeto de entretener a sus posibles usuarios. Viendo esto, puede parecer que no existirán más de un par de lenguajes esotéricos, ¿no? Pues haciendo un recuento rápido en la lista de lenguajes de esolang.org he podido contar más de cuatrocientos, lo cual da una idea de la dimensión de la frikada de la que estamos hablando.
Pero no hay nada como unos ejemplos ilustrativos para que tomemos conciencia total de la cuestión.
Según la especificación oficial, la ejecución comienza en la esquina superior izquierda, donde la orden "j" hace que la dirección de la ejecución sea hacia abajo. La siguiente orden procesada, "l", modifica el sentido de la ejecución hacia la derecha. Una "p" hace que se envíe a la consola el carácter que se encuentra en la celda inmediatamente inferior, de la misma forma que las "P" lo hacen con los caracteres situados en las celdas superiores.
Para no extenderme demasiado, resumiré un poco. Una vez enviado el saludo, se imprime un retorno de carro utilizando la pila para restar del carácter "*" (ASCII 42) el espacio (ASCII 32), se envía a la consola y se finaliza el programa (orden "q").
Estas órdenes permiten desplazarse por las celdas hacia delante y hacia atrás ("<" y ">"), incrementar o disminuir el valor de la celda actual ("+" y "-"), escribir y leer caracteres hacia/desde consola ("." y ",") y hacer bucles simples ("[" y "]"). Como muestra, ahí va el "Hello world":
Gran muestra de código mantenible, sin duda.
Como curiosidad, añadir que existe un intérprete y compilador de Brainfucker para .NET en Google Code.

Es interesante saber que existen multitud de implementaciones de este lenguaje, una de ellas incluso en .NET, aún en versión alfa, con perfecta integración en Visual Studio.
En fin, que después nos quejamos de que los desarrolladores tenemos fama de rarillos... ;-)
Publicado en: http://www.variablenotfound.com/.
Los lenguajes esotéricos, también llamados esolangs, son lenguajes de programación cuyo objetivo, al contrario que en los "tradicionales", no es ser útil, ni solucionar problemas concretos, ni ser especialmente práctico, ni siquiera incrementar la productividad del desarrollador. De hecho, lo normal es que atente contra todas estas características de forma contundente.
Aunque algunos se diseñan como pruebas de concepto de ideas para determinar su viabilidad en lenguajes reales, lo más frecuente es que sean creados por diversión y exclusivamente con objeto de entretener a sus posibles usuarios. Viendo esto, puede parecer que no existirán más de un par de lenguajes esotéricos, ¿no? Pues haciendo un recuento rápido en la lista de lenguajes de esolang.org he podido contar más de cuatrocientos, lo cual da una idea de la dimensión de la frikada de la que estamos hablando.
Pero no hay nada como unos ejemplos ilustrativos para que tomemos conciencia total de la cuestión.
Ejemplo 1: "Hello World" en lenguaje Argh!
Este lenguaje utiliza una matriz de 80x40 caracteres, en cuyas celdas pueden aparecer tanto código como datos. La siguiente matriz codifica el tradicional "Hello World":
j world
lppppppPPPPPPsrfj
hello, * j
qPh
Según la especificación oficial, la ejecución comienza en la esquina superior izquierda, donde la orden "j" hace que la dirección de la ejecución sea hacia abajo. La siguiente orden procesada, "l", modifica el sentido de la ejecución hacia la derecha. Una "p" hace que se envíe a la consola el carácter que se encuentra en la celda inmediatamente inferior, de la misma forma que las "P" lo hacen con los caracteres situados en las celdas superiores.
Para no extenderme demasiado, resumiré un poco. Una vez enviado el saludo, se imprime un retorno de carro utilizando la pila para restar del carácter "*" (ASCII 42) el espacio (ASCII 32), se envía a la consola y se finaliza el programa (orden "q").
Ejemplo 2: "Hello World" en Brainfuck (jodecerebros)
Este lenguaje es un clásico en este mundillo debido a que ha servido como base para la creación de muchos otros lenguajes esotéricos. Se basa en la manipulación de un array de celdas utilizando tan solo 8 comandos, los siguientes caracteres: <, >, +, -, punto, coma, [, ].Estas órdenes permiten desplazarse por las celdas hacia delante y hacia atrás ("<" y ">"), incrementar o disminuir el valor de la celda actual ("+" y "-"), escribir y leer caracteres hacia/desde consola ("." y ",") y hacer bucles simples ("[" y "]"). Como muestra, ahí va el "Hello world":
>+++++++++[<++++++++>-]<.>
+++++++[<++++>-]<+.+++++++..+++.
>>>++++++++[<++++>-]
<.>>>++++++++++[<+++++++++
>-]<---.<<<<.+++.
------.--------.>>+.
Gran muestra de código mantenible, sin duda.
Como curiosidad, añadir que existe un intérprete y compilador de Brainfucker para .NET en Google Code.

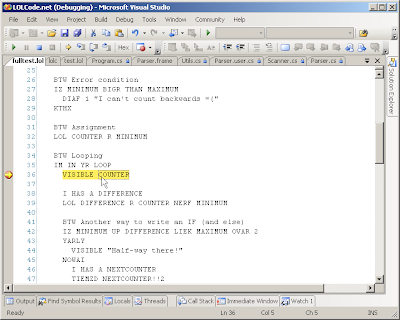
Ejemplo 3: "HAI WORLD" en LOLCODE
Lolcode es otro buen ejemplo de frikismo, aunque en este caso más orientado hacia la broma. Se trata de programar utilizando el peculiar lenguaje que usan unos populares gatitos, llamados lolcats, una mezcla entre la jerga de un bebé y el lenguaje habitual en los SMS.HAI
CAN HAS STDIO?
VISIBLE "HAI WORLD!"
KTHXBYE
Es interesante saber que existen multitud de implementaciones de este lenguaje, una de ellas incluso en .NET, aún en versión alfa, con perfecta integración en Visual Studio.

En fin, que después nos quejamos de que los desarrolladores tenemos fama de rarillos... ;-)
Publicado en: http://www.variablenotfound.com/.
domingo, 3 de febrero de 2008
 Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.
Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.Los, en inglés, extension methods, permiten añadir métodos a clases existentes sin necesidad de utilizar el mecanismo de la herencia. Aunque dicho así parezca ser una aberración y atente directamente contra una de las principales bases de la programación orientada a objetos, y de hecho están considerados por algunos como auténticos inventos diabólicos, la cosa tampoco es tan grave siempre que se mantenga cierto control y conocimiento de causa. Y es que, como muchas otras características aparecidas recientemente en estos lenguajes, no son sino una base sobre la que sustentar frameworks como Linq, y que de paso pueden ayudarnos a ser algo más productivos.
En realidad, y siendo prácticos, los métodos de extensión no aportan grandes novedades, casi nada que no pudiéramos hacer con la versión 1.0 del framework, simplemente nos facilitan nuevas vías sintácticamente más simples de hacerlo. Por ejemplo, seguro que alguna vez habéis querido dotar una clase X con nuevas funcionalidades y no habéis podido heredar de ella por estar sellada (sealed en C# o NotInheritable en VB)... ¿Qué es lo que habéis hecho? Pues probablemente crear en otra clase un método estático con un parámetro de tipo X que realizaba las funciones deseadas en alguna clase de utilidad. ¿Lo vemos mejor con un ejemplo?
Supongamos que deseamos añadir a la clase
string un método que nos retorne la cadena almacenada entre un tag (X)HTML strong. Como String no es heredable, la solución idónea sería crear una clase de utilidad donde codificar este métodos y otros similares que pudieran hacernos falta:public static class HtmlStringUtils
{
public static function string Negrita(string s)
{
return "<strong>" + s + "</strong>";
}
public static function string Cursiva(string s) {...}
public static function string Superindice(string s) {...}
[...]
}Su uso tendría que pasar necesariamente por la referencia a la clase estática y el paso del parámetro a convertir, así:
HtmlStringUtils.Negrita(currentUser.Name)
Esta técnica es correcta, aunque tiene un problema de visibilidad del código. Ningún desarrollador podría intuir la existencia de la clase HtmlStringUtils de forma natural; tampoco sería posible que un IDE sofisticado nos sugiriese el método
Negrita() como una posibilidad a la hora de manipular una cadena, como hace Intellisense con los métodos de instancia habituales.Los extension methods vienen a cubrir estos inconvenientes, creando una vía de alternativa para codificar el ejemplo anterior, facilitando después su uso de una forma más sencilla. Ojo al parámetro que recibe la función, que incluye la palabra reservada "this" por delante del mismo:
public static class HtmlStringUtils
{
public static function string Negrita(this string s)
{
return "<strong>" + s + "</strong>";
}
[...]
}De esta forma, incluyendo como primer parámetro el tipo precedido de la palabra "this", este método estático se convertirá automáticamente en un método de extensión de dicho tipo, y pueda ser utilizado como si fuera un método de instancia más del mismo:

return currentUser.Name.Negrita();
Y, por supuesto, tendríamos toda la potencia de nuestro querido Intellisense (en VS2008) a nuestra disposición.
Lo único a tener en cuenta es el primer parámetro, que debe ser del tipo a extender. En éste se introducirá la instancia de dicho tipo de forma automática, y el resto de parámetros serán enviados al método en el mismo orden, es decir:
// Método de extensión sobre un string
public static string Colorea(this string s, Color color)
{
[...]
}
// Forma de invocarlo:
string str = User.Name.Colorea(Color.Red);
Vemos que la utilización es mucho más natural y, aunque parezca que estamos rompiendo todas las bases del paradigma de la orientación a objetos, no es más que un atajo para incrementar productividad y facilitar la visión del código, además de servir como apoyo a tecnologías novedosas como Linq.
Sin embargo, no todo son ventajas. Es interesante añadir posibles problemas que pueden causar la utilización descontrolada de esta nueva característica.
En primer lugar, no olvidemos que a menos que Visual Studio (o cualquier entorno similar) nos eche una mano, al leer un código fuente será imposible saber si una llamada que estamos observando es un método de instancia o se trata de uno de extensión. Aunque no deja de ser una pequeña molestia, puede provocar una inquietante sensación de desconocimiento y dispersión del código fuente.
Otro motivo de dolor de cabeza puede ser el versionado de los métodos de extensión. Éstos pueden tener una vida completamente independiente de la clase a la que afectan, lo que puede provocar efectos no deseados ante la evolución de ésta.
Especialmente peligrosos pueden ser los relacionados con los nombres de métodos de extensión. Por ejemplo, la inclusión de un método en una clase podría hacer (de hecho, haría) que un método de extensión asociado a la misma y con un nombre similar no se ejecutara, pues el miembro de la instancia siempre tendría preferencia sobre éste. El problema es que el compilador no podría avisar de ningún problema, y es en ejecución donde podrían aparecer las incompatibilidades o diferencia de funcionalidades entre ambos métodos.
Veamos un ejemplo simple, siguiendo con el caso expuesto más atrás, ¿qué ocurriría si una vez en uso el método de extensión
Negrita() Microsoft decidiera añadir al tipo string un método de instancia llamado Negrita() en una versión posterior del framework, que retornara un tag HTML <b>? Pues que el compilador no sería capaz de detectar nada raro, por lo que no nos daríamos cuenta del cambio, y nuestra aplicación dejaría de validar XHTML.De la misma forma, también pueden causar problemas difíciles de detectar la especificación de namespaces incorrectos. Nada impide que un mismo método de extensión sea definido en dos espacios de nombres diferentes, lo cual hace que el namespace indicado en el using sea el que esté decidiendo el extension method a ejecutar, lo cual no resulta nada natural ni intuitivo en estos casos.
En conclusión: la recomendación es usar métodos de instancia, los habituales, siempre que se pueda, recurriendo a la herencia. Y para cuando no, contaremos con este valioso aliado.
Publicado en: http://www.variablenotfound.com/.









