
El progresivo acercamiento de ASP.NET al mundo del open source es algo que llevamos observando bastante tiempo. Desde hace unos años es posible acceder al código fuente de muchos productos, y también hemos visto cómo determinados proyectos puramente libres como jQuery eran incluidos con todos los honores en el conjunto de tecnologías de desarrollo oficiales de Microsoft. Ahora vamos un paso más allá.
A finales del agosto, James Gregory anunció la publicación de la versión 1.0 de Fluent NHibernate, una librería que ofrece una ágil alternativa a los espesos archivos de configuración de NHibernate.
Su API permite configurar desde el código de una aplicación, de forma fluida la mayoría de las veces, los mapeos entre la estructura de una base de datos relacional y el modelo de objetos que utiliza. Así, evitaremos la manipulación de grandes archivos XML, a la vez que podremos beneficiarnos de la validación en tiempo de compilación y, por supuesto, de posibilidades como la refactorización y el intellisense durante el desarrollo.
El siguiente código muestra el mapeo de la entidad Cat con sus propiedades, algunas de ellas con restricciones, y relaciones con otras entidades a uno (References) y a varios (HasMany); el nombre de la tabla y campos en el modelo relacional es el mismo que el de las propiedades, gracias a la convención sobre configuración, lo que permite simplificar código respecto a su equivalente XML:
public class CatMap : ClassMap<Cat>
{ public CatMap() { Id(x => x.Id);
Map(x => x.Name)
.Length(16)
.Not.Nullable();
Map(x => x.Sex);
References(x => x.Mate);
HasMany(x => x.Kittens);
}
}
Como podemos observar, el equivalente XML es mucho más verboso:
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
namespace="QuickStart" assembly="QuickStart">
<class name="Cat" table="Cat">
<id name="Id">
<generator class="identity" />
</id>
<property name="Name">
<column name="Name" length="16" not-null="true" />
</property>
<property name="Sex" />
<many-to-one name="Mate" />
<bag name="Kittens">
<key column="mother_id" />
<one-to-many class="Cat" />
</bag>
</class>
</hibernate-mapping>
Otra de las ventajas que aporta es el auto-mapping, que hace utilización intensiva del principio de convención sobre configuración para generar de forma automática mapeos de aquellas entidades que atiendan a unas normas preestablecidas (aunque modificables). El siguiente código muestra la forma tan sencilla de crear los mapeos de todas las entidades definidas en el espacio de nombres MiApp.Entidades, dentro del ensamblado donde se definió la entidad Producto:
var autoMappings = AutoMap.AssemblyOf<Producto>()
.Where(t => t.Namespace == "MiApp.Entidades");Además del mapeo objeto-relacional, el software abarca también la configuración del acceso a datos de NHibernate a través de su interfaz de programación. El siguiente código muestra la inicialización de la conexión a una base de datos SQL Server 2005, tomando la cadena de conexión del
AppSettings y mapeando automáticamente las entidades que se encuentren definidas en un namespace concreto:var sessionFactory = Fluently.Configure()
.Database(MsSqlConfiguration.MsSql2005
.ConnectionString(c => c.FromAppSetting("connectionString")) .Mappings(m => m.AutoMappings.Add(
AutoMap.AssemblyOf<Producto>(type => type.Namspace.EndsWith("Entidades")))) .BuildSessionFactory();
Y por último, hay otra característica muy interesante vistas a la realización de pruebas unitarias sobre los mecanismos de persistencia. El código mostrado a continuación crea una instancia de la clase Empleado, la inserta en la base de datos, realiza una lectura de la entidad y la compara con la original, de forma automática:
[Test]
public void EmpleadoMapeaCorrectamente()
{ new PersistenceSpecification<Empleado>(session) .CheckProperty(emp => emp.Id, 1)
.CheckProperty(emp => emp.Nombre, "José") .CheckProperty(emp => emp.Apellidos, "Aguilar") .VerifyTheMappings();
}
Más información en la wiki del proyecto. Y las descargas, desde aquí.
Publicado en: Variable not found.
Desde hace unos meses estoy escribiendo las entradas de Variable Not Found desde Windows Live Writer, y la verdad es que estoy encantado con esta herramienta. Pero como nadie es perfecto, me he encontrado con ocasiones en las que tengo que acceder y retocar a mano el código fuente de la página para que el resultado sea el que pretendo.
Me suele ocurrir, por ejemplo, cuando inserto pequeñas porciones de código fuente en mitad de una frase, pues siempre me ha gustado rodear este tipo de textos por las correspondientes etiquetas <code> y </code>. Esto, además de ser un marcado semánticamente más correcto, me permite modificar la forma en que se muestra desde CSS, estableciéndole, por ejemplo, una tipografía de ancho fijo.
Para no tener que hacerlo más a mano, he creado un pequeño plugin para Live Writer que permite seleccionar un texto y envolverlo automáticamente por dichas etiquetas, y he pensado que quizás pueda serle útil a alguien más.

Plugins dentro del directorio donde hayáis instalado la herramienta (en mi caso, la ruta completa es C:\Archivos de programa\Windows Live\Writer\Plugins).
Seguidamente, reiniciáis Live Writer y listo, veréis que en la barra lateral y el menú “insertar” ha aparecido la opción “Etiqueta <code>”, que os permitirá realizar el proceso descrito anteriormente.
En breve publicaré un post describiendo paso a paso cómo se crea un plugin para Live Writer, y veréis lo sencillo que resulta hacer estas pequeñas herramientas de productividad.
Publicado en: Variable not found

Aunque el código fuente de la plataforma estaba disponible en CodePlex prácticamente desde que empezaron a publicarse las primeras previews de la plataforma, es ahora cuando, en palabras de Scott Hanselman, ha pasado de ser “source opened” a “open source”.
Muchas de las grandes figuras implicadas en el proyecto han publicado ya en sus respectivos blogs el esperado anuncio, felicitándose por el logro conseguido, una nueva demostración del cambio de rumbo de Microsoft respecto al código abierto.
También Miguel de Icaza, quien por cierto recientemente anunciaba la disponibilidad de Mono 2.4 y MonoDevelop 2.0, ya ha comentado que se trata de una magnífica noticia no sólo para el equipo del Proyecto Mono, sino para toda la comunidad de desarrolladores ASP.NET.
Enlaces (en inglés):
- ASP.NET MVC 1.0 (ScottGu)
- Microsoft ASP.NET MVC 1.0 is now Open Source MS-PL (Hanselman)
- Open Source License For System.Web.Mvc (Haack)
- Rolling a Bubble – ASP.NET MVC is Ms-PL (Connery)
- Microsoft releases ASP.NET under the MS-PL License (Miguel de Icaza)
- Download ASP.NET MVC 1.0
Publicado en: www.variablenotfound.com
 Vamos a continuar desarrollando nuestro
Vamos a continuar desarrollando nuestro traceroute utilizando el framework .NET. En la primera parte del post ya describimos los fundamentos teóricos, y esbozamos el algoritmo a emplear para conseguir detectar la secuencia de nodos atravesados por los paquetes de datos que darían lugar a nuestra ruta.Continuamos ahora con la implementación de nuestro sistema de trazado de redes.
Lo primero: estructurar la solución
Vamos a desarrollar un componente independiente, empaquetado en una librería, que nos permita realizar trazados de rutas desde cualquier tipo de aplicación, y más aún, desde cualquier lenguaje soportado por la plataforma .NET. Atendiendo a eso, ya debemos tener claro que construiremos un ensamblado, al que vamos a llamar NTraceLib, que contendrá una clase (Tracer) que gestionará toda la lógica de obtención de la traza de la ruta.Dado que debe ser independiente del tipo de aplicación que lo utilice, no podrá incluir ningún tipo de interacción con el usuario, ni acceso a interfaz alguno. Serán las aplicaciones de mayor nivel las que solucionen este problema. La clase
Tracer se comunicará con ellas enviándole eventos cada vez que ocurra algo de interés, como puede ser la recepción de paquetes de datos con las respuestas.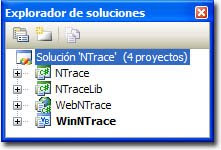 Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:
Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:- NTrace será una aplicación de consola escrita en C#.
- WebNTrace, también escrita en C#, permitirá trazar los paquetes enviados desde el servidor Web donde se esté ejecutando hasta el destino.
- WinNTrace será una herramienta de escritorio, esta vez escrita en VB.NET, que permitirá obtener los resultados de forma más visual.
Tracer: el trazador
La claseTracer será la encargada de realizar el trazado de la ruta hacia el destino indicado. De forma muy rápida, podríamos enumerar sus principales características:- Tiene una única propiedad pública,
Host, que contiene la dirección (nombre o IP) del equipo destino del trazado. Los comandostracertytraceourtetienen más opciones, pero no las vamos a implementar para simplificar el sistema. - Tiene definidas también dos constantes:
- MAX_HOPS, que define el máximo de saltos, o nodos intermedios que permitiremos atravesar a nuestros paquetes. Normalmente no se llegará a este valor.
- TIMEOUT, que definirá el tiempo máximo de espera de llegada de las respuestas.
- Publica dos eventos, que permitirán a las aplicaciones cliente procesar o realizar la representación visual de la información resultante de la ejecución del trazado:
- ErrorReceived, que notificará a la aplicación cliente del componente que se ha producido un error durante la obtención de la ruta. Ejemplos serían "red inalcanzable", o "timeout".
- EchoReceived, que permitirá notificar de la recepción de mensajes por parte de los nodos de la ruta.
- El método
Trace()ejecutará al ser invocado el procedimiento descrito en el post anterior, lanzando los eventos para indicar a las aplicaciones cliente que actualicen su estado o procesen la respuesta. A grandes rasgos, el procedimiento consistía en ir enviado mensaje ICMP ECHO (pings) al servidor de destino incrementando el TTL del paquete en cada iteración y esperar la respuesta, bien la respuesta al ping o bien mensajes "time exceeded" indicando la expiración del paquete durante la ruta hacia el destino.
Para conocer más detalles sobre la clase
Tracer, puedes descargar el proyecto desde el enlace que encontrarás al final del post.Enviar ICMP ECHOs, o cómo hacer un Ping desde .NET
La versión 2.0 de .NET framework nos lo puso realmente sencillo, al incorporar una clase específicamente diseñada para ello, Ping, incluida en el espacio de nombres System.Net.NetworkInformation. A continuación va un código que muestra el envío de una solicitud de eco al servidor www.google.es: Ping pingSender = new Ping ();
PingOptions options = new PingOptions ();
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("datos");
int timeout = 120;
PingReply reply = pingSender.Send ("www.google.es",
timeout, buffer, options);
if (reply.Status == IPStatus.Success)
{
Console.WriteLine ("Recibido: {0}",
reply.Address.ToString ());
}
De este código vale la pena destacar algunos detalles. Primero, como podemos observar, existe una clase
PingOptions que nos permite indicar las opciones con las que queremos enviar el paquete ICMP. En particular, podremos especificar si el paquete podrá ser fragmentado a lo largo de su recorrido, así como, aunque no aparece en el código anterior, el valor inicial del TTL (time to live) del mismo. Habréis adivinado que este último aspecto es especialmente importante para lograr nuestros objetivos.Segundo, es posible indicar en un buffer un conjunto de datos arbitrarios que viajarán en el mensaje, lo que podría permitirnos medir el tiempo de ida y vuelta de un paquete de un tamaño determinado. También se puede indicar el tiempo máximo en el que debemos recibir la respuesta antes de considerar que se trata de un timeout.
Por último, la respuesta a la llamada síncrona
pingSender.Send(...) obtiene un objeto del tipo PingReply, en el que encontraremos información detallada sobre el resultado de la operación.Implementación del trazador
Si unimos el procedimiento de trazado de una ruta, descrito ampliamente en el post anterior, al método de envío de pings recién comentado, casi obtenemos directamente el código del métodoTrace() de la clase Tracer, el responsable de realizar el seguimiento de la ruta:
PingReply reply;
Ping pinger = new Ping();
PingOptions options = new PingOptions();
options.Ttl = 1;
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("NTrace");
try
{
do
{
DateTime start = DateTime.Now;
reply = pinger.Send(host,
TIMEOUT,
buffer,
options);
long milliseconds = DateTime.Now.Subtract(start).Milliseconds;
if ((reply.Status == IPStatus.TtlExpired)
|| (reply.Status == IPStatus.Success))
{
OnEchoReceived(reply, milliseconds);
}
else
{
OnErrorReceived(reply, milliseconds);
}
options.Ttl++;
} while ((reply.Status != IPStatus.Success)
&& (options.Ttl < MAX_HOPS ));
}
catch (PingException pex)
{
throw pex.InnerException;
}
Como podemos observar, se repite el Ping dentro de un bucle en el que va incrementándose el TTL hasta llegar al objetivo (
reply.Status==IPStatus.Success) o hasta que se supere el máximo de saltos permitidos. Por cada ping realizado se llama al evento correspondiente en función del resultado del mismo, con objeto de notificar a las aplicaciones cliente de lo que va pasando. Además, se va tomando en cada llamada el tiempo que se tarda desde el momento del envío hasta la recepción de la respuesta. Podéis observar que llamamos al evento
EchoReceived siempre que recibamos algo de un nodo, sea intermediario (que recibiremos un error por expiración del TTL) o el destinatario final del paquete (que recibiremos la respuesta satisfactoria al ping), mientras que el evento ErrorReceived es invocado en todas las demás circunstancias. En cualquier caso, siempre enviaremos como parámetros el PingReply, que contiene información detallada de la respuesta, y el tiempo en milisegundos que ha tardado en obtenerse la misma.Ah, una nota importante respecto al tiempo de resolución de nombres. Dado que la clase
Ping funciona tanto si le especificamos como destino una dirección IP como si es un nombre de host, hay que tener en cuenta que el primer ping podrá verse penalizado por el tiempo de consulta al DNS si esto es necesario. Esto podría solventarse muy fácilmente, realizando la resolución de forma manual y pasando al ping siempre la dirección IP, pero he preferido mantenerlo así para mantener el código más sencillo.Cómo usar NTraceLib en aplicaciones
 Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:
Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:- Declaramos una variable del tipo
Trace. - Escribimos los manejadores que procesen las respuestas de
ErrorReceivedyEchoReceived, suscribiéndolos a los correspondientes eventos. - Establecemos el host y llamamos al método
Trace()del objeto de trazado.
Vamos a ver el ejemplo concreto de la aplicación WinNTrace, sistema de escritorio creado en Visual Basic .NET, que mostrará en un formulario el resultado del trazado. En primer lugar, tiene declarado un objeto
Tracer como sigue, lo que nos permitirá enlazarle el código a los eventos de forma muy sencilla: Private WithEvents tracer As New TracerCuando el usuario teclea un host en el cuadro de texto y pulsa el botón "Trazar", se ejecuta el siguiente código (he omitido ciertas líneas para facilitar su lectura); podréis comprobar que es bastante simple, pues incluye sólo la asignación del equipo de destino y la llamada a la realización de la traza:
tracer.Host = txtHost.Text
Try
tracer.Trace()
Catch ex As Exception
MessageBox.Show("Error: " + ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
Cuando se recibe información de un nodo, sea intermediario o el destino final de la traza, añadimos al
ListView un nuevo elemento con la dirección del mismo, así como los milisegundos transcurridos desde el envío de la petición: Private Sub tracer_EchoReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.EchoReceivedEventArgs) _
Handles tracer.EchoReceived
Dim items() As String = { _
args.Reply.Address.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
En el caso de recibir un error, como un timeout, añadiremos la línea, pero aportando mostrando el tipo de error producido y destacando la fila respecto al resto con un color de fondo. Este procedimiento podría haberlo trabajado un poco más, por ejemplo añadiendo textos descriptivos de los errores, pero eso os lo dejo de deberes.
Private Sub tracer_ErrorReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.ErrorReceivedEventArgs) _
Handles tracer.ErrorReceived
Dim items() As String = { _
"Error: " + args.Reply.Status.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
item.BackColor = Color.Yellow
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
Además de WinNTrace, en la descarga que encontraréis al final del post he incluido NTrace (la aplicación de consola) y WebNTrace (la aplicación web). Aunque cada una tiene en cuenta sus particularidades de interfaz, el comportamiento es idéntico al descrito para el sistema de escritorio, por lo que no los describiremos con mayor detalle.
Conclusiones
 A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.
A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.Dejamos para artículos posteriores la realización de funcionalidades no implementadas en esta versión, como la posibilidad de cancelar una traza una vez comenzada, la resolución inicial de nombres para que el tiempo de respuesta de la primera pasarela sea más correcto, o incluso la resolución inversa del nombre de los nodos de una ruta, es decir, la obtención del hostname de cada uno de ellos tal y como lo hacen las utilidades de línea comand
tracert o traceroute. También podríamos incluir funciones de geoposicionamiento de los mismos, para intentar obtener una aproximación la ruta física que siguen los paquetes a través de la red.Espero que os haya resultado interesante. Y por supuesto, para dudas, consultas o sugerencias, por aquí me tenéis.
Descargar NTrace (proyecto VS2005)
Publicado en: www.variablenotfound.com.
 Seguro que todos habéis utilizado en alguna ocasión el comando
Seguro que todos habéis utilizado en alguna ocasión el comando tracert (o traceroute en Linux) con objeto de conocer el camino que siguen los paquetes de información para llegar desde vuestro equipo a cualquier otro host de una red. Sin embargo, es posible que más de uno no haya tenido ocasión de ver lo sencillo que resulta desarrollar un componente que realice esta misma tarea usando tecnología .NET, y lo divertido que puede llegar a ser desarrollar utilidades de red de este tipo.En esta serie de posts vamos a desarrollar, utilizando C#, un componente simple de trazado de rutas de red. La elección del lenguaje es pura devoción personal, pero lo mismo podría desarrollarse sin problema utilizando Visual Basic .NET. En cualquier caso, el ensamblado resultante podrá ser utilizado desde cualquier tipo de aplicación soportado por el framework, es decir, sea escritorio, consola o web, y, como es obvio, independientemente del lenguaje utilizado para su creación.
Pero comencemos desde el principio...
Un poco de teoría: ¿cómo funciona un traceroute?
El objetivo de los trazadores de rutas es conocer el camino que siguen los paquetes desde un equipo origen hasta un host destino detectando los sistemas intermediarios (gateways) por los que va pasando. La enumeración ordenada de dichos sistemas es lo que llamamos ruta, y es el resultado de la ejecución del comandotracert o traceroute.Para conseguir obtener esta información, como veremos después, se utiliza de forma muy ingeniosa la capacidad ofrecida por el protocolo IP para definir el tiempo de vida de los paquetes. Profundizaremos un poco en este concepto.
El TTL (Time To Live) es un campo incluido en la cabecera de todos los datagramas IP que se mueven por la red, y es el encargado de evitar que éstos circulen de forma indefinida si no encuentran su destino.
Cuando una aplicación crea un paquete IP, se le asigna un valor inicial al TTL del encabezado del mismo. El valor puede venir definido por el sistema operativo en función del protocolo concreto (TCP, UDP...), o incluso ser asignado por el propio software que lo origine. En cualquier caso, el tiempo se indica en segundos de vida, aunque en la práctica indicará el número de veces que será procesado el paquete por los dispositivos de enrutado que atravesará durante su recorrido.
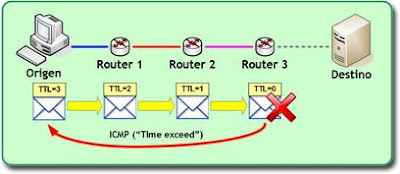
Cuando este paquete se envía hacia un destino, al llegar al primer gateway de la red, éste analizará su cabecera para determinar su ruta y encaminarlo apropiadamente, y a la misma vez decrementará el valor del TTL. De ahí atravesará otra red hasta llegar al siguiente gateway de su ruta, que volverá a hacer lo mismo. Eso sí, cuando un dispositivo encaminador de este tipo detecte un paquete con un TTL igual a cero, lo descartará y enviará a su emisor original un mensaje ICMP con un código 11 ("time exceed"), que significa que se ha excedido el tiempo de vida del paquete.
El siguiente diagrama muestra un escenario en el que un paquete es enviado con un TTL=3, y cómo es descartado antes de llegar a su destino:
Volviendo al tema del post y a algo que adelanté anteriormente, el
traceroute utiliza de forma muy ingeniosa el comportamiento descrito, siguiendo el procedimiento para averiguar la ruta de un paquete que se detalla a continuación:- Envía un paquete ICMP Echo al destino con un TTL=1. Este tipo de paquetes son los enviados normalmente al realizar un
pinga un equipo. - El primer dispositivo enrutador al que llega el paquete decrementa el TTL, y dado que es cero, descarta el paquete y envía el mensaje ICMP informando al emisor que el paquete ha sido eliminado.
- El emisor, al recibir este aviso, puede considerar que el remitente del mismo es el primer punto de la ruta que seguirá el paquete hasta su destino.
- A continuación, vuelve a intentarlo enviando de nuevo un ICMP Echo al destino, esta vez con un TTL=2.
- El paquete pasa por el primer enrutador, que transforma su TTL en 1 y lo envía a la red apropiada.
- El segundo enrutador detecta que debe encaminar el paquete y éste tiene un TTL=1 y al decrementarlo será cero, por lo que lo descarta, enviando de vuelta el mensaje "time exceed" al emisor original.
- Desde el origen, a la recepción de este mensaje ICMP, se almacena su remitente como segundo punto de la ruta.
- Y así sucesivamente, se realizan envíos con TTL=3, 4, ... hasta llegar al destino, momento en el que recibiremos la respuesta a la solicitud de eco enviada (un mensaje de tipo ICMP Echo Reply), o hasta superar el número máximo de saltos que se haya indicado (por ejemplo, usando la opción
tracert -h Nen Windows)
Función Trace(DEST)
Inicio
ttl = 1
Hacer
Enviar ICMP_ECHO_REQUEST al host DEST con TTL=ttl
Si recibimos un TIME_EXCEED desde el host X,
o bien recibimos un ICMP_ECHO_REPLY desde X, entonces
El host X forma parte de la ruta
Fin
Incrementa ttl
Mientras Respuesta <> ICMP_ECHO_REPLY Y ttl<MAXIMO
FinPublicado en: www.variablenotfound.com.
 Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.
Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.Recapitulando, las técnicas de camuflaje de emails que habían aguantado el año y medio del experimento de Silvan Mühlemann, y por tanto se entendían más seguras que el resto de las empleadas en el mismo, fueron:
- Escribir la dirección al revés en el código fuente y cambiar desde CSS la dirección de presentación del texto.
- Introducir texto incorrecto en la dirección y ocultarlo después utilizando CSS.
- Generar el enlace desde javascript partiendo de una cadena codificada en ROT13.
En tiempo de ejecución, el control es capaz de generar código javascript que escribe en la página un enlace
mailto: completo, partiendo de una cadena previamente codificada creada desde el servidor. Dado que todavía no está generalizado entre los spambots la ejecución de javascript de las páginas debido al tiempo y capacidad de proceso necesario para realizarlo, podríamos considerar que esta es la opción más segura. Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.
Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.Pero, ah, malditos posyaques... la verdad es que con un poco de refactorización era posible generalizar el procedimiento de codificación y decodificación mediante el uso de clases específicas (Codecs), así que me puse manos a la obra. Liame incluye, de serie, cuatro algoritmos distintos de ofuscación para ilustrar sus posibilidades: ROT-N (el usado por defecto y más recomendable), Base64, codificación hexadecimal, y un codec nulo, que me ha sido muy útil para depurar y usar como punto de partida en la creación de nuevas formas de camuflaje. Algunos, además, aleatorizan los de nombres de funciones y variables para hacer que el código generado sea ligeramente distinto cada vez, de forma que un spammer no pueda romperlo por una simple localización de cadenas en posiciones determinadas; en fin, puede que sea una técnica un poco inocente, pero supongo que cualquier detalle que dificulte aunque sea mínimamente la tarea de los rastreadores, bueno será.
Incluso si así lo deseamos podremos generar, además del javascript de decodificación del enlace, el contenido de la etiqueta
<noscript>, en la que se incluirá el código HTML de la dirección a ocultar utilizando los dos trucos CSS descritos anteriormente y también considerados "seguros" por el experimento. De esta forma, aunque no estará disponible el enlace para este grupo de usuarios, podrán visualizar la dirección a la que podrán remitir sus mensajes. El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.
El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.Sin embargo, aún quedaba una cosa pendiente. El control de servidor está bien siempre usemos ASP.NET y que el rendimiento no sea un factor clave, puesto que al fin y al cabo estamos cargando de trabajo al servidor. Para el resto de los casos, Liame incluye en el proyecto de demostración un generador de javascript que, partiendo de los parámetros que le indiquemos, nos creará un script listo para copiar y pegar en nuestras páginas (X)HTML, PHP, Java, o lo que queramos. Como utiliza la base de Liame, cada script que generamos será distinto al anterior.
He publicado el proyecto en Google Code, desde donde se puede descargar tanto el ensamblado compilado como el código fuente del componente y del sitio de demostración. Esta vez he elegido la licencia BSD, no sé, por ir probando ;-)
La versión actual todavía tiene algunos detallitos por perfilar, como el control de la entrada en las propiedades (en especial las comillas y caracteres raros: ¡mejor que nos los uséis!), que podría dar lugar a un javascript sintácticamente incorrecto, pero en general creo que se trata de una versión muy estable. Ha sido probada con Internet Explorer 7, Firefox 3 y Chrome, los tres navegadores que tengo instalados.
También, por cortesía de Mergia, he colgado un proyecto de demostración para que pueda verse el funcionamiento en vivo y en directo, tanto del control de servidor como del generador de javascript.

Finalmente, algunos aspectos que creo interesante comentar. En primer lugar, me gustaría recordaros que las técnicas empleadas por Liame no aseguran, ni mucho menos, que los emails de las páginas van a estar a salvo de los del lado oscuro eternamente, aunque de momento así sea. Lo mejor es no confiarse.
En segundo lugar, es importante tener claro que todas las técnicas aquí descritas pueden resultar bastante nocivas para la accesibilidad de las páginas en las que las utilicéis. Tenedlo en cuenta, sobre todo, si tenéis requisitos estrictos en este sentido.
Y por último, añadir que estaré encantado de recibir vuestras aportaciones, sugerencias, colaboraciones o comentarios de cualquier tipo (sin insultar, eh?) que puedan ayudar a mejorar este software.
Enlaces
Publicado en: www.variablenotfound.com.
 Aunque hace varias semanas que el rumor saltó a la blogosfera, hoy han confirmado la noticia en una rueda de prensa conjunta: a partir del próximo 1 de enero Stallman formará parte de la plantilla de Microsoft en Redmond.
Aunque hace varias semanas que el rumor saltó a la blogosfera, hoy han confirmado la noticia en una rueda de prensa conjunta: a partir del próximo 1 de enero Stallman formará parte de la plantilla de Microsoft en Redmond.La nota de prensa publicada por Microsoft recoge, textualmente, los siguientes párrafos:
"Microsoft siempre apuesta por el talento, y Richard Stallman es uno de los más reputados ideólogos del mundo del desarrollo del software."Por su parte, Richard Stallman, que nunca ha destacado por su aprecio a la multinacional, justifica la decisión en su blog:
[...]
"Sin duda, se trata de una de las incorporaciones más importantes a la compañía de los últimos años, por lo que no hemos escatimado en recursos. Las negociaciones las han llevado a cabo directamente Gates y Ballmer, los dos máximos directivos, lo que demuestra la magnitud de la apuesta estratégica que se está llevando a cabo"
"En realidad nuestras posturas nunca han estado muy alejadas, aunque veíamos las cosas desde perspectivas diferentes. Microsoft, al igual que GNU y el conjunto del movimiento Open Source, pretende hacer llegar el software a todo el mundo y hacer que sea un bien universal."
[...]
"Hay más puntos en común que diferencias, sólo era cuestión de sentarnos y dialogar sobre hacia dónde podíamos caminar juntos"
 En principio Stallman encabezará una nueva división en Microsoft destinada al análisis y evaluación de soluciones de software libre para el segmento SOHO (Small Office, Home Office) y grandes corporaciones, así como a dirigir la adaptación de ciertos componentes del microkernel de Linux a Windows Server 2012 (codename "MindBreaker"), que se lanzará al mercado en unos años y del que ya están disponibles vía MSDN algunos whitepapers y documentos muy muy preliminares.
En principio Stallman encabezará una nueva división en Microsoft destinada al análisis y evaluación de soluciones de software libre para el segmento SOHO (Small Office, Home Office) y grandes corporaciones, así como a dirigir la adaptación de ciertos componentes del microkernel de Linux a Windows Server 2012 (codename "MindBreaker"), que se lanzará al mercado en unos años y del que ya están disponibles vía MSDN algunos whitepapers y documentos muy muy preliminares.Este movimiento forma parte de la estrategia de acercamiento de Microsoft al mundo del software libre, como se lleva viendo algún tiempo. Los acuerdos entre Microsft y Novell, la publicación del código fuente de .NET Framework y la gran cantidad de líneas de actuación que están promoviendo así lo demuestran.
Y por cierto, se dice que el próximo en la lista de Most Wanted People de Microsoft y con el que hay conversaciones bastante avanzadas (de nuevo, pues ya las hubo hace tiempo) es Miguel de Icaza, líder del proyecto Mono, aunque él todavía no ha declarado nada al respecto. Otros en la lista son el mismísimo Linus Torvalds, creador del primer núcleo de Linux, firme candidato a liderar el área de arquitectura de servidores y servicios, y Vinton Cerf, considerado el padre de internet, para el puesto de Technical Chief Developer de la línea de productos Internet Explorer.
Habrá que esperar para ver a qué conduce esta reorientación en la estrategia que se viene observando desde hace unos meses, y sobre todo en qué se traduce la fiebre por los fichajes de figuras del mundillo. El tiempo lo dirá.
Nota para despistados, que haberlos, haylos: obviamente la noticia no es real, se trata de una broma del día de los inocentes.
Por cierto, hay muchos comentarios simpáticos en mi blog en geeks.ms.
Publicado en: www.variablenotfound.com.
NiftyDotNet, para el que no lo conozca, es un componente ASP.Net para las plataformas Mono y Microsoft, que encapsula la librería javascript Nifty Corners Cube para conseguir redondear las esquinas de elementos de una página web de una forma realmente sencilla. Basta con arrastrar los controles sobre un Webform, indicarles los elementos que se verán afectados y listo.

Publicado en: Variable Not Found.
Nada más sencillo. Suponiendo que partimos de un linux basado en Debian, como Ubuntu, basta con descargar e instalar nmap:
apt-get install nmapUna vez contando con esta herramienta, para realizar un escaneo al host [victima] a través del zombie [zombie] la instrucción sería la siguiente:
nmap –sI [zombie] –P0 [victima]Donde:
- "-sI" indica que se debe realizar el idle scan.
- [zombie] es la dirección, en forma de IP o nombre, del equipo elegido como zombie.
- "-P0" indica que no se debe realizar un ping directo para comprobar si la víctima está activo.
- [victima] es la dirección, IP o nombre, de la misma.
- opcionalmente, puede indicarse el parámetro "-p" seguido de los números de puerto a escanear, por defecto nmap hará un barrido bastante completo y puede tardar un poco. Ante la duda, un "man nmap" puede venir bien.
Pero ojo, no es fácil dar con servidores que cumplan los requisitos necesarios para ser considerados buenos zombies, puesto que en la mayoría se usan IPIDs aleatorizados, fijos o secuencias por cliente.
Además, recordad que debéis ser root (o ejecutar las órdenes con sudo) para que todo funcione correctamente.
Se trata de idle scan, una ocurrente forma para detectar los puertos abiertos en una máquina remota sin poner al descubierto al atacante, es decir, al equipo que realiza el escaneo. Para ello, se vale de una máquina intermedia, llamada zombie o dumb, que ejerce como intermediario en la comunicación y hace que en ningún caso la víctima reciba paquetes directamente desde el atacante, quedando éste en el más absoluto anonimato.
Bueno, he de decir que si no tienes claro el funcionamiento del protocolo TCP y el establecimiento de conexiones, es probable que debas pegar un repaso antes de seguir leyendo el post. En todo caso será una lectura aconsejable para todo humano interesado en saber qué está ocurriendo por debajo cuando estamos utilizando servicios en una red como Internet.
Ahora vamos al lío. La cuestión es que todo intrépido pirata sabe que antes de iniciar el ataque a una ciudad costera es conveniente ver los puertos en los que se puede atracar para hacer el desembarco, ¿no? Pues en Internet ocurre lo mismo, un puerto abierto en un equipo conectado a la red es siempre una posible vía de entrada al mismo; indica que hay una aplicación escuchando en la máquina, y habitualmente puede averiguarse cuál es y explotar sus debilidades.
Por tanto, un ataque tipo debería ir precedido de un escaneo de los puertos abiertos, es decir, recorrer los 65535 puertos posibles (o al menos el subconjunto de uso más habitual) a ver cuáles están en uso. La pega es que esto suele ser demasiado ruidoso, no son pocos los sistemas de detección de intrusos y filtros que detectan peticiones sucesivas desde una misma dirección y las clasifican de inmediato como sospechosas pudiendo llegar a banear (prohibir) la conexión desde la IP que está haciendo el barrido, o incluso a registrar la dirección para más adelante poder tomar medidas legales si procede.
Esta es la razón que hacen de Idle Scan una técnica interesante, puesto que, como he comentado antes, en ningún momento el atacado es consciente de la dirección del atacante.
Para ello se aprovecha, en primer lugar, el funcionamiento del three way handshake, el protocolo estándar utilizado para el establecimiento de conexiones TCP, donde de forma habitual:
- El procedimiento se inicia cuando el cliente envía un paquete SYN al servidor. Si es posible realizar una conexión, éste responde con un SYN + ACK, y el cliente debe confirmar enviando de nuevo un ACK al servidor. En caso contrario, es decir, si no es posible realizar la conexión porque el puerto esté cerrado, el servidor responde con un RST y se da por finalizada la secuencia.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de confirmación de conexión SYN+ACK de otro, responde con un RST con objeto de informarle de que no va a establecerse conexión alguna.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de reseteo (RST), lo ignora.
Para detectar si un puerto está abierto o cerrado, es necesario primero observar el IPID del zombie, enviar paquetes a la víctima haciéndole ver que realmente se los está enviando éste y, posteriormente, observar de nuevo el IPID utilizado por el incauto intermediario. En función de los valores iniciales y finales obtenidos, se puede inferir el estado del puerto destino.
A continuación se exponen dos escenarios distintos de escaneo; en el primero de ellos se muestra lo que ocurre cuando el puerto objeto de la detección está abierto, mientras que en el segundo se supone que está cerrado.
Escenario 1: Víctima con el puerto abierto
El primer paso es enviar al zombie un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente, del cual tomaremos el IPID.Acto seguido, se realiza una solicitud de conexión a la víctima, previa manipulación del paquete para que sea el zombie el que figure como origen del mismo. Al recibirlo, dado que estamos asumiendo que el puerto está abierto (escenario 1), la víctima envía de vuelta la confirmación de la conexión al que cree que es el solicitante, el zombie.
El zombie recibe la confirmación de la conexión, pero como no es él el que la ha generado, responde a la víctima con una señal de reseteo (RST), incrementando su IPID.
De nuevo, pasado unos segundos, desde el atacante se vuelve a obtener el IPID del zombie de la misma forma que al comienzo, comprobando que ha sido incrementado en 2 unidades. De esta forma, se determina que el puerto destino del escaneo estaba abierto.
El siguiente diagrama muestra la secuencia forma gráfica:

Escenario 2: Víctima con el puerto cerrado
Como en el escenario anterior, el primer paso siempre es obtener el IPID del zombie, enviándole un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente.
De la misma forma, se envía a la víctima el paquete de solicitud de conexión, indicando en las cabeceras que el origen del mismo es el host zombie. Dado que el puerto está cerrado (escenario 2), la víctima devuelve al aparente emisor un paquete RST indicándole que no será posible establecer la conexión solicitada. El zombie recibe el paquete RST y lo ignora.
El atacante, siguiendo la misma técnica que en otras ocasiones, obtiene el IPID del zombie, y dado que es el número siguiente al recibido al iniciar el procedimiento, puede determinar que no ha realizado ningún envío entre ambos, y que, por tanto, el puerto de destino estaba cerrado.

Desde el punto de vista del atacante las ventajas son, fundamentalmente:
- El anonimato, puesto que desde la víctima todas las conexiones provienen virtualmente del zombie, y en ningún momento se envía información directamente desde el atacante.
- El alcance, es decir, esta técnica permite escanear puertos de máquinas a las que directamente no se tendría acceso debido a la acción de filtros (como firewalls) intermedios. Dado que las conexiones provienen del zombie, sólo habría que tener acceso a éste para realizar el escaneo.
- La visión de red que aporta, en otras palabras, permite determinar las relaciones de confianza existentes entre el zombie y la víctima. Si, por ejemplo, un intento directo de conexión a un puerto de la víctima es rechazado y, sin embargo, es posible acceder a él desde un intermediario, es porque existe algún tipo de relación de confianza entre ambos, lo cual puede ser utilizado en ataques posteriores.
En la actualidad, el principal inconveniente es la dificultad de localizar un zombie apropiado para realizar los ataques, tanto por las condiciones software que debe cumplir (sistemas operativos, kernels, etc.), el escaso tráfico de red que debe tener en el momento del escaneo (necesarios para que los IPID no se incrementen por otras conexiones) y, sobre todo, las medidas de seguridad de que disponga, puesto que desde él sería posible detectar al atacante.











