
Mostrando entradas con la etiqueta servicios on-line. Mostrar todas las entradas
Mostrando entradas con la etiqueta servicios on-line. Mostrar todas las entradas
lunes, 7 de julio de 2008
Hace unos días descubrí un portal que considero muy interesante para todos los que estamos intentando seguir de cerca el nuevo framework ASP.NET MVC de Microsoft.
Se trata de un proyecto personal de Dan Hounshell que recopila de forma automática posts, noticias, rumores y vídeos de feeds RSS de diversas fuentes sobre ASP.NET MVC y tecnologías relacionadas. Ah, y todos estos contenidos los ofrece en RSS, por lo que es una fuente ideal para estar al día.

Que aproveche.
Publicado en: www.variablenotfound.com.
Se trata de un proyecto personal de Dan Hounshell que recopila de forma automática posts, noticias, rumores y vídeos de feeds RSS de diversas fuentes sobre ASP.NET MVC y tecnologías relacionadas. Ah, y todos estos contenidos los ofrece en RSS, por lo que es una fuente ideal para estar al día.
Que aproveche.
Publicado en: www.variablenotfound.com.
martes, 20 de mayo de 2008
 Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.
Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.4. Emoticonos corporales y otras extensiones
Aunque en su nacimiento los emoticonos sólo intentaban simular gestos faciales, existen una interesante variedad de ellos que simulan cuerpos completos y posturas que, de la misma manera, transmiten contenido de tipo emocional.Por ejemplo, los siguientes emoticonos representan a una persona arrodillada o haciendo reverencias en esta postura. Siempre la letra "o" aparece como cabeza, le sigue el tronco y un brazo en el suelo y finalmente las piernas flexionadas:
orz, _| ̄|○, OTL Or2, Orz, On_, OTZ, O7Z, Sto, Jto, _no
Estos emoticonos suelen representar ideas distintas en función de la cultura. En Japón, se interpreta como fracaso y desesperación; los usuarios Chinos, en cambio, lo usan más frecuentemente para expresar admiración a la consecución de un objetivo. Hay también quien lo utiliza para mostrar una risa extrema ("retorcerse de risa").
Otros de este tipo podrían ser:
| O-&-< | Persona con los brazos cruzados |
| ~~~~\0/~~~~ | Ahogándose |
Pero hay muchos más, y algunos son obras de arte: posturas, retratos de celebridades, objetos... De hecho, algunos de ellos podrían describirse mejor como arte ASCII que como emoticonos, pues no llevan asociadas emociones y se trata simplemente de adornos textuales:
| Cuerpos... | |
| (:-))-|-< | Cuerpo completo |
| X=(;-))-|8-<= | Novia |
| Celebridades... | |
| ( 8^(l) | Homer Simpson |
| =:o] | Bill Clinton |
| @:-() | Elvis Presley |
| Objetos... | |
| @>+-+-- | Una rosa |
| <')))))><< | Un pez |
| ... | |
En Canonical Smiley List hay 2227 emoticonos de este tipo.
5. Emoticonos zurdos
 Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:
Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:No suelen utilizarse demasiado dado que suelen provocar confusión en los lectores, acostumbrados a la orientación habitual.

6. Emoticonos asiáticos
En 1986 surgieron en Japón una nueva familia de emoticonos, que se popularizaron muy rápidamente entre los países de Asia del este. Las dos diferencias principales respecto a los habituales en el mundo occidental son, en primer lugar, que pueden entenderse fácilmente sin necesidad de tumbar la cabeza hacia un lado y, en segundo lugar, que la expresión o emoción suele representarse eligiendo caracteres diversos para los ojos, en lugar de la boca. Algunos ejemplos simples:| (^_^) | Sonrisa |
| (T_T) | Llorando |
| (o_#) | Magullado |
| (O_O) | Sorprendido |
| (~o~) | Un bostezo |
(Puedes encontrar más aquí)
Existen también otros emoticonos que hacen uso de los juegos de caracteres especiales que es necesario tener instalados en el ordenador:
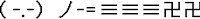 | Lanzando un suriken |
 | Escribiendo |
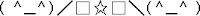 | ¡Salud! |
(Aquí hay muchos más, pero para verlos necesitarás instalar el paquete de idioma japonés en tu máquina)
7. Emoticonos... ¿patentados?
 En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.
En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.Poco después, el 2 de enero de 2001, lanzaron una nota de prensa anunciando que emprenderían acciones legales contra los usuarios de Internet que utilizaran este símbolo en sus mensajes de correo electrónico, y que ya habían cursado un total de 7 millones de denuncias individuales.
En realidad, no se trataba más que de una broma, una forma de llamar la atención y dar a conocer su compañía, dedicada a la comercialización de material gráfico con mensajes humorísticos. Incluso el director de la compañía, Edward Lawrence Kersten, indicó que estaba considerando cambiar su propio nombre a :-( pues "le apetecía que su nombre simbolizara la infelicidad".
Sin embargo, no todo el mundo entendió la broma, y se generó un inmenso revuelo a nivel mundial, acusando a la compañía de querer apropiarse de un bien universal. Tanto fue así que un mes más tarde publicaron otra nota de prensa, en la que, también en tono jocoso, la empresa se comprometía con la comunidad global de internet a permitir el uso legal del emoticono en el email, vendiéndolos a través de su propia web bajo el nombre comercial Frownies™ y siempre que los usuarios se comprometieran en el cumplimiento de una desmadrada licencia de usuario final.
 Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.
Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.También es conocido que los emoticonos :-) y :) están registrados en Finlandia. Igualmente han sido polémicos otros registros y patentes relacionadas, como las efectuadas por Cingular en 2006 relativo a su uso en teléfonos móviles, o la solicitud de patente de Microsoft sobre la forma de crear y trasmitir emoticonos personalizados.
8. Emoticonos y accesibilidad
Desde el punto de vista de la accesibilidad un emoticono es exactamente igual que cualquier otro elemento no textual, por lo que debe prestársele especial atención para asegurar el acceso universal a la información.Las WCAG 1.0 (Pautas de Accesibilidad al Contenido Web) recoge como prioridad de nivel 1 proporcionar un texto equivalente para todo contenido no textual, incluyendo, expresamente, a los smileys o emoticonos entre ellos, a los que considera como arte ASCII.
Por ejemplo, el test automatizado Web Accessibility Checker incluye como problema el uso excesivo de emoticonos, o el hecho de no rodear éstos entre etiquetas como sigue:
<abbr title="emoticono de sonrisa">:-)</abbr>Punto extra: ¿y el futuro?
Hoy en día los emoticonos basados en texto están siendo sustituidos por versiones gráficas, con efectos y animaciones e incluso sonidos. Aplicaciones de uso muy común, como procesadores de texto o clientes de mensajería instantánea realizan la conversión al modelo gráfico de forma automática, e incluyen atajos o botones en sus interfaces para incluirlos, por lo que es probable que en unos años los iconos textuales pasen a ser historias de veteranos nostálgicos, como muchas otras.Lo que sin duda perdudará será el concepto, la necesidad de añadir el contenido emocional a los mensajes escritos, sea cual sea su forma.
¡Larga vida al emoticono!
Fuentes:
- Language Logs, the prehistory of emoticons
- Wikipedia: Emoticons
- Emoticonos en Wikipedia
- El País: 25 años guiñando
- Internet Movie Database (IMDb)
- Web Accessibility Initiative (WAI)
Publicado en: http://www.variablenotfound.com/.
 Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.
Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.Y probablemente debido a su cotidianeidad, hasta ahora no les había prestado demasiada atención. Sin embargo, cuando he buscado un poco de información sobre ellos, he encontrado algunas curiosidades que creo que vale la pena conocer.
1. Sobre el término emoticono
El término emoticono es la traducción del portmanteau inglés "emoticon", fusión de "emotion" + "icon", en clara referencia a que se trata de un icono para representar emociones. Fue introducido por David W. Sanderson en su libro "Smileys" publicado en 1993, años después de la popularización de los mismos.Aunque se suele utilizar como sinónimo "smiley", estrictamente hablando no es lo mismo. Un smiley es una representación esquemática de una cara sonriente, por lo que sólo algunos emoticonos lo son. Hay muchos que no son caras, o que éstas no presentan precisamente una sonrisa. Eso sí, el típico smiley redondo y amarillo, creado por el diseñador Harvey Ball en 1963, inspiró con su simplista representación los emoticonos gráficos que conocemos hoy.La 22ª edición del Diccionario de la Real Academia Española, del año 2001, definió el término emoticono como:
"Símbolo gráfico que se utiliza en las comunicaciones a través del correo electrónico y sirve para expresar el estado de ánimo del remitente"Accediendo a la definición, sin embargo, se puede comprobar que ésta ha sido enmendada y la próxima edición contará con una más acorde con la realidad, donde se deja notar el avance tecnológico producido desde entonces:
"Representación de una expresión facial que se utiliza en mensajes electrónicos para aludir al estado de ánimo del remitente"De la misma forma, en la actualidad se acepta el término emoticón (con plural emoticones), pero parece ser que puede ser eliminado en futuras ediciones del diccionario.
2. Antecedentes históricos
La necesidad de asociar sentimientos y emociones a textos escritos existía mucho antes de la creación de los emoticonos y de la aparición de las redes de ordenadores. De hecho, se conocen apariciones anteriores de conceptos similares, aunque adaptados al medio del momento.Está documentado el uso, en abril de 1857, del código numérico "73" como una forma de añadir a un mensaje escrito en código Morse un afectuoso "love and kisses", que más adelante pasó a formalizarse como "best regards". Ya más adelante, a principios del siglo XX, se volvió a añadir este amoroso sentimiento, codificándolo como "88".
 Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos.
Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos. Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.
Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.Este mismo signo fue descrito también por Vladimir Nabovok, escritor de origen ruso conocido, sobre todo, por ser el autor de la famosa novela Lolita, en una entrevista realizada por el New York Times en abril de 1969, donde respondía a una cuestión sobre su valoración respecto a otros escritores de la época y anteriores:
I often think there should exist a special typographical sign for a smile -- some sort of concave mark, a supine round bracket which I would now like to trace in reply to your question.
_______________________________________
A menudo pienso que debería existir un símbolo tipográfico especial para una sonrisa -- algo parecido a una marca cóncava, un paréntesis tendido que me gustaría registrar como respuesta a su pregunta.
 El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:
El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:Today You'll laugh :-) You'll cry :-( You'll love <3 'Lili'
_______________________________________
Hoy reirás :-) Llorarás :-( Amarás <3 'Lili'
 Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.
Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.3. El origen de los emoticonos en comunicaciones digitales
En abril de 1979, Kevin MacKenzie sugirió a los suscriptores de MsgGroup, una de las primeras listas de distribución de ARPANET, el origen de la Internet de hoy en día, la utilización de algún mecanismo para indicar emociones en el inexpresivo correo electrónico. Concretamente, se le atribuye el uso del símbolo "-)" para indicar contenidos irónicos en su mensaje:Perhaps we could extend the set of punctuation we use, i.e.: If I wish to indicate that a particular sentence is meant with tongue-in-cheek, I would write it so:Aunque su propuesta concreta no fue acogida con especial entusiasmo, los pioneros de las redes de comunicación comenzaron a utilizar variantes de estas expresiones en sus mensajes, la mayoría de las cuales no ha trascendido hasta la actualidad.
"Of course you know I agree with all the current administration's policies -)."
The "-)" indicates tongue-in-cheek.
_______________________________________
Quizás deberíamos extender el conjunto de signos de puntuación que utilizamos, por ejemplo: si quiero indicar que una frase en particular debe ser entendida como una ironía, la escribiría así:
"Por supuesto, sabes que estoy de acuerdo con todas las políticas actuales de la administración -)"
El "-)" indica que el mensaje es irónico.
Más tarde, en septiembre de 1982, Scott Fahlman envió el siguiente mensaje a un tablón de la BBS de la Universidad Carnegie Melon:
19-Sep-82 11:44 Scott E Fahlman :-)
From: Scott E Fahlman
I propose that the following character sequence for joke markers:
:-)
Read it sideways. Actually, it is probably more economical to mark
things that are NOT jokes, given current trends. For this, use
:-(
_______________________________________
Propongo la siguiente secuencia de caracteres para marcar las bromas:
:-)
Leedlo inclinando la cabeza. En realidad, probablemente sea más económico marcar lo que NO sea broma, dada la tendencia actual. En este caso, usad
:-(
 En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.
En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.Estos emoticonos sí fueron aceptados, y a partir de ese momento comenzó su utilización de forma masiva. Por esta razón, se considera a Fahlman como el padre de los emoticonos tal y como hoy los conocemos, aunque no todo el mundo está de acuerdo con ello.
Él mismo afirma en un artículo que es el inventor del emoticono lateral... o al menos uno de ellos. Pero sí está seguro de haber sido el primero en utilizar la secuencia :-) para indicar una broma en el medio digital.
4. Emoticonos corporales y otras extensiones
Continuar leyendo en 8 curiosidades que quizás no conocías sobre los emoticonos, segunda parte.
domingo, 30 de marzo de 2008
 Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.
Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.Google nos tiene acostumbrados a implementar APIs muy sencillas de usar, y en este caso no podía ser menos. Para demostrarlo, vamos a crear una página web con un sencillo traductor en Javascript, comentando paso por paso lo que hay que hacer para que podáis adaptarlo a vuestras necesidades.
Paso 1: Incluir el API
La inclusión de las funciones necesarias para realizar la traducción es muy sencilla. Basta con incluir el siguiente código, por ejemplo, en la sección HEAD de la página: <script type="text/javascript"
src="http://www.google.com/jsapi">
</script>
<script type="text/javascript">
google.load("language", "1");
</script>
El primer bloque descarga a cliente la librería javascript Ajax API Loader, el cargador genérico de librerías Ajax utilizado por Google. Éste se usa en el segundo bloque script para cargar, llamando a la función
google.load el API "language" (traductor), en su versión 1 (el segundo parámetro).Paso 2: Creamos el interfaz
Nuestro traductor será realmente simple. Además, vamos a contemplar un pequeño subconjunto de los idiomas permitidos para no complicar mucho el código, aunque podéis añadir todos los que consideréis necesarios.El resultado será como el mostrado en la siguiente imagen.

El código fuente completo lo encontraréis al final del post, por lo que no voy a repetirlo aquí. Simplemente indicar que tendremos un
TextArea donde el usuario introducirá el texto a traducir, dos desplegables con los idiomas origen y destino de la traducción, y un botón que iniciará la acción a través del evento onclick. Por último, se reservará una zona en la que insertaremos el resultado de la traducción.Ah, un detalle interesante: en el desplegable de idiomas de origen se ha creado un elemento en el desplegable "Auto", cuyo valor es un string vacío; esto indicará al motor de traducción que infiera el idioma a partir del texto enviado.
Paso 3: ¡Traducimos!
La pulsación del botón provocará la llamada a la funciónOnclick(), desde donde se realizará la traducción del texto introducido en el TextArea.Como podréis observar en el código, en primer lugar obtendremos los valores de los distintos parámetros, el texto a traducir y los idiomas origen y destino, y lo introducimos en variables para facilitar su tratamiento.
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
Acto seguido, realizamos la llamada al traductor. El primer parámetro será el texto a traducir, seguido de los idiomas (origen y destino), y por último se introduce la función callback que será invocada cuando finalice la operación; hay que tener en cuenta que la traducción es realizada a través de una llamada asíncrona a los servidores de Google:
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
Como podéis observar, y es quizás lo único extraño que tiene esta instrucción, el callback se ha definido como una función anónima definida en el espacio del mismo parámetro (podéis ver otro ejemplo de este tipo de funciones cuando explicaba cómo añadir funciones con parámetros al evento OnLoad).
Para los queráis jugar con esto directamente, ahí va el código listo para un copiar y pegar.
<html>
<head>
<title>Traductor</title>
<script type="text/javascript" src="http://www.google.com/jsapi"></script>
<script type="text/javascript">
google.load("language", "1");
</script>
</head>
<body>
<textarea id="text" rows="8" cols="40">Hi, how are you?</textarea>
<br />
<button onclick="onClick()">
Traducir</button>
Del idioma
<select id="srcLang">
<option value="">(Auto)</option>
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
Al
<select id="dstLang">
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
<h3>Traducción:</h3>
<div id="result">
(Introduce un texto)
</div>
</body>
<script type="text/javascript">
function onClick()
{
// obtenemos el texto y los idiomas origen y destino
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
// llamada al traductor
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
}
</script>
</html>
Enlaces: Página oficial de documentación del API
Publicado en: www.variablenotfound.com.
domingo, 23 de marzo de 2008
 De todos es conocida la afición de Microsoft por poner nombres clave a sus productos durante la etapa de conceptualización y desarrollo, y la verdad es que tiene su gracia. Pero la verdad, a veces es difícil seguirle la pista a posts o conversaciones en foros donde hacen uso intensivo de ellas.
De todos es conocida la afición de Microsoft por poner nombres clave a sus productos durante la etapa de conceptualización y desarrollo, y la verdad es que tiene su gracia. Pero la verdad, a veces es difícil seguirle la pista a posts o conversaciones en foros donde hacen uso intensivo de ellas.Por ejemplo, ¿recuerdas el nombre en clave de ASP.NET Ajax? ¿Y de Windows 95? ¿Y sabes que tecnología se esconde detrás de Whistler o de Avalon?
Por suerte, en la Wikipedia, que hay de todo, alguien se ha encargado de recoger, si no todos los Codenames, al menos muchos de ellos.
Enlace: List of Microsoft codenames
Publicado en: http://www.variablenotfound.com/.
domingo, 9 de diciembre de 2007
Browsershots.org es un servicio dedicado a realizar capturas de pantalla de una página web utilizando distintos navegadores y sistemas operativos, y gratis... siempre que no tengas mucha prisa.
El invento utiliza un sistema en el que las solicitudes de captura de pantalla se distribuyen entre "factorías", máquinas de los propios usuarios de la comunidad, que prestan parte del ancho banda y capacidad de sus equipos para realizar estas tareas. De hecho, hay unas sencillas instrucciones para crear una nueva factoría de capturas de pantalla y apoyar así el proyecto.
Para enviar la solicitud de captura es necesario indicar la URL a comprobar, así como los navegadores y características de la captura, combinando entre los siguientes elementos:

Una vez enviado el formulario con las características deseadas, el trabajo pasará a la cola de cada una de las factorías desde se generarán las capturas de pantalla. El tiempo de espera dependerá del número de solicitudes pendientes, pero podremos conocer una estimación global y detallada desde la misma página:

Conforme las factorías van terminando su trabajo, enviarán una copia de la captura al servidor central, que publicará en la misma página web las imágenes obtenidas. Simplemente recargando la página obtendremos información actualizada del proceso y podremos ampliar las imágenes obtenidas hasta el momento pulsando sobre ellas:

Es importante destacar que la solicitud que enviamos tiene una validez de 30 minutos. Si en ese tiempo no hemos obtenido los resultados deseados, debemos extender (hay un botón para ello en la página) este tiempo, pues de lo contrario expirará. De esta forma, los señores de ScreenShots.org pueden asegurar que estamos todavía en la página y que seguimos interesados en las capturas de pantalla que hemos solicitado previamente.
Las capturas generadas son de un tamaño y calidad excelente, suficientes para detectar problemas en el diseño o las habituales incompatibilidades entre los motores de renderizado de páginas web de los navegadores.
El único problema es el tiempo que puede llegar a tardar la realización de un conjunto completo de capturas. En distintas pruebas me he encontrado con colas de más de una hora, aunque, también he de decirlo, la mayoría de las capturas se han generado en los primeros diez minutos. Además, por una módica cantidad mensual (10€/15$) puedes adquirir un mes de prioridad en el servicio, por lo que, según aseguran, obtendrás todas las pantallas en menos de 3 minutos.
Publicado en: Variable Not Found.
El invento utiliza un sistema en el que las solicitudes de captura de pantalla se distribuyen entre "factorías", máquinas de los propios usuarios de la comunidad, que prestan parte del ancho banda y capacidad de sus equipos para realizar estas tareas. De hecho, hay unas sencillas instrucciones para crear una nueva factoría de capturas de pantalla y apoyar así el proyecto.
Para enviar la solicitud de captura es necesario indicar la URL a comprobar, así como los navegadores y características de la captura, combinando entre los siguientes elementos:
- Navegadores:
- para Linux: Epiphany 2.14, Firefox 1.5, Firefox 2.0, Galeon 2.0, Iceweasel 2.0, Konqueror 3.5, NetFront 3.2, Opera 9.24, Opera 9.5
- para Windows: Firefox 1.5, Firefox 2.0, MSIE 5.5, MSIE 6.0, MSIE 7.0, Opera 9.24, Safari 3.0.
- para Mac OS: Firefox 2.0, Safari 1.3, Safari 2.0, Safari 3.0
- Anchos de pantalla: 640, 800, 1024, 1280, 1400 y 1600 pixels.
- Profundidad de color: 8, 16, 24 y 32 bits por pixel.
- Javascript: deshabilitado, habilitado, v1.3, v1.5, v1.6, v1.7, v2.0
- Java: deshabilitado o habilitado.
- Flash: deshabilitado o habilitado.

Una vez enviado el formulario con las características deseadas, el trabajo pasará a la cola de cada una de las factorías desde se generarán las capturas de pantalla. El tiempo de espera dependerá del número de solicitudes pendientes, pero podremos conocer una estimación global y detallada desde la misma página:

Conforme las factorías van terminando su trabajo, enviarán una copia de la captura al servidor central, que publicará en la misma página web las imágenes obtenidas. Simplemente recargando la página obtendremos información actualizada del proceso y podremos ampliar las imágenes obtenidas hasta el momento pulsando sobre ellas:

Es importante destacar que la solicitud que enviamos tiene una validez de 30 minutos. Si en ese tiempo no hemos obtenido los resultados deseados, debemos extender (hay un botón para ello en la página) este tiempo, pues de lo contrario expirará. De esta forma, los señores de ScreenShots.org pueden asegurar que estamos todavía en la página y que seguimos interesados en las capturas de pantalla que hemos solicitado previamente.
Las capturas generadas son de un tamaño y calidad excelente, suficientes para detectar problemas en el diseño o las habituales incompatibilidades entre los motores de renderizado de páginas web de los navegadores.
El único problema es el tiempo que puede llegar a tardar la realización de un conjunto completo de capturas. En distintas pruebas me he encontrado con colas de más de una hora, aunque, también he de decirlo, la mayoría de las capturas se han generado en los primeros diez minutos. Además, por una módica cantidad mensual (10€/15$) puedes adquirir un mes de prioridad en el servicio, por lo que, según aseguran, obtendrás todas las pantallas en menos de 3 minutos.
Publicado en: Variable Not Found.
martes, 17 de julio de 2007
Como en internet hay de todo, a alguien se le ha ocurrido desarrollar una bonita web en Flash con un curioso jueguecillo: se nos van mostrando consecutivamente fotografías de personajes (concretamente diez), y debemos identificar cuál de ellos es un inventor de lenguajes de programación y cuál es un asesino en serie (!).
 Y es que es verdad que algunos tienen unas pintas... Pero bueno, seguro que si en vez de hacerlo con informáticos lo hacen con cualquier otro tipo de profesionales les habría quedado igual de bien, aunque probablemente perdería el morbo que tienen los programadores y su fama de ser gente rara, muy rara, y con un físico acompañando a su presunta personalidad.
Y es que es verdad que algunos tienen unas pintas... Pero bueno, seguro que si en vez de hacerlo con informáticos lo hacen con cualquier otro tipo de profesionales les habría quedado igual de bien, aunque probablemente perdería el morbo que tienen los programadores y su fama de ser gente rara, muy rara, y con un físico acompañando a su presunta personalidad.
La dirección es: http://www.malevole.com/mv/misc/killerquiz.
He acertado 9 sobre 10, se ve que identifico bien a mis colegas... (me refiero a los programadores, claro ;-)). ¿Y tú? ¿Qué nota has conseguido?
Y es que es verdad que algunos tienen unas pintas... Pero bueno, seguro que si en vez de hacerlo con informáticos lo hacen con cualquier otro tipo de profesionales les habría quedado igual de bien, aunque probablemente perdería el morbo que tienen los programadores y su fama de ser gente rara, muy rara, y con un físico acompañando a su presunta personalidad.La dirección es: http://www.malevole.com/mv/misc/killerquiz.
He acertado 9 sobre 10, se ve que identifico bien a mis colegas... (me refiero a los programadores, claro ;-)). ¿Y tú? ¿Qué nota has conseguido?
viernes, 13 de julio de 2007
 A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.
A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.Por citar sólo a algunos, podemos encontrar a Anieto2k, Javier Pérez, InKiLiNo, Boja, Xavier, y así hasta 30 figuras de este mundillo.
Espero contribuir desde Variable not found a difundir información y compartir conocimientos y experiencias sobre esta profesión que tanto nos apasiona.
lunes, 9 de julio de 2007
Después de celebrar el primer año de vida del blog le debía un regalito: tener su propio nombre de dominio, que no podía ser otro que http://www.variablenotfound.com/.
Y ya que estaba de obras, he aprovechado para incluir utilidades para feeds de mano de Feedburner, con un interesante conjunto de herramientas para la suscripción que espero faciliten la vida a más de uno.
En ambos casos el cambio ha resultado sencillísimo. Ha bastado la inclusión de un registro CNAME en el panel de control DNS del dominio para declararlo como alias de un servidor Google y la modificación en un parámetro de la configuración Blogger para que el servidor comenzara a responder al nuevo nombre. El procedimiento viene muy bien descrito, aunque en inglés, en la dirección http://help.blogger.com/bin/answer.py?answer=55373&hl=en&ctx=rosetta.
Feedburner, como servicio con solera en este mundillo, ofrece también una instalación de lo más sencilla. Una vez completado el registro como usuario, dispone de un generador de código HTML a través del cual podremos ir añadiendo los enlaces a los distintos tipos de suscripción disponibles. Por tanto, como viene siendo habitual en estos servicios, todo se reduce, a lo sumo, a una secuencia de copiar y pegar.
De todas formas estaré durante un tiempo alerta por si detecto algo que funcione mal; confío que me aviséis si véis algo raro, eh?
 He dejado para más adelante otros cambios que tengo en mente, como pegar el salto a WordPress, o modificar totalmente el aspecto de la página. Pero esto será ya otra historia...
He dejado para más adelante otros cambios que tengo en mente, como pegar el salto a WordPress, o modificar totalmente el aspecto de la página. Pero esto será ya otra historia...
Y ya que estaba de obras, he aprovechado para incluir utilidades para feeds de mano de Feedburner, con un interesante conjunto de herramientas para la suscripción que espero faciliten la vida a más de uno.
En ambos casos el cambio ha resultado sencillísimo. Ha bastado la inclusión de un registro CNAME en el panel de control DNS del dominio para declararlo como alias de un servidor Google y la modificación en un parámetro de la configuración Blogger para que el servidor comenzara a responder al nuevo nombre. El procedimiento viene muy bien descrito, aunque en inglés, en la dirección http://help.blogger.com/bin/answer.py?answer=55373&hl=en&ctx=rosetta.
Feedburner, como servicio con solera en este mundillo, ofrece también una instalación de lo más sencilla. Una vez completado el registro como usuario, dispone de un generador de código HTML a través del cual podremos ir añadiendo los enlaces a los distintos tipos de suscripción disponibles. Por tanto, como viene siendo habitual en estos servicios, todo se reduce, a lo sumo, a una secuencia de copiar y pegar.
De todas formas estaré durante un tiempo alerta por si detecto algo que funcione mal; confío que me aviséis si véis algo raro, eh?
 He dejado para más adelante otros cambios que tengo en mente, como pegar el salto a WordPress, o modificar totalmente el aspecto de la página. Pero esto será ya otra historia...
He dejado para más adelante otros cambios que tengo en mente, como pegar el salto a WordPress, o modificar totalmente el aspecto de la página. Pero esto será ya otra historia...
jueves, 14 de junio de 2007
Hay veces que encuentras por internet herramientas que no tienen una utilidad demasiado grande pero resultan curiosas. Este es uno de esos casos.
Se trata de SelectOracle (algo así como Selectoráculo), una herramienta on-line que traduce cadenas de selectores, indicados según el estándar CSS 3.0, al español, inglés y, de forma aún incompleta, al alemán y búlgaro.
¿Y qué signica esto? Para que os hagáis una idea, reproduzco una serie de selectores que le he enviado y la respuesta que me ha devuelto la herramienta:
Selector: *
Traducción: Selecciona cualquier elemento.
Selector: p a
Traducción: Selecciona cualquier elemento a que es descendiente de un elemento p.
Selector: div#main > p + a[title]
Traducción: Selecciona cualquier elemento a con un atributo title que sigue inmediatamente a un elemento p que es hijo de un elemento div con un atributo id que equivale a main.
Como se puede ver, es en casos con cierta complejidad como este último donde la herramienta puede sernos de ayuda.
Una prueba más de que en internet hay de todo, sólo hace falta buscar un poco.
Se trata de SelectOracle (algo así como Selectoráculo), una herramienta on-line que traduce cadenas de selectores, indicados según el estándar CSS 3.0, al español, inglés y, de forma aún incompleta, al alemán y búlgaro.
¿Y qué signica esto? Para que os hagáis una idea, reproduzco una serie de selectores que le he enviado y la respuesta que me ha devuelto la herramienta:
Selector: *
Traducción: Selecciona cualquier elemento.
Selector: p a
Traducción: Selecciona cualquier elemento a que es descendiente de un elemento p.
Selector: div#main > p + a[title]
Traducción: Selecciona cualquier elemento a con un atributo title que sigue inmediatamente a un elemento p que es hijo de un elemento div con un atributo id que equivale a main.
Como se puede ver, es en casos con cierta complejidad como este último donde la herramienta puede sernos de ayuda.
Una prueba más de que en internet hay de todo, sólo hace falta buscar un poco.
viernes, 25 de mayo de 2007
El pasado 22 de mayo, la IETF aprobó y publicó la propuesta del estándar DKIM en la RFC 4871. ¡Diantres, ahora que se había puesto de acuerdo mucha gente para usar SPF!
DKIM pretende controlar los mensajes haciendo que el servidor de correo del que proceden firme digitalmente los envíos. De esta forma se consigue, en primer lugar, poder verificar el dominio al que pertenece el remitente de un mensaje y, en segundo lugar, asegurar la integridad del mismo permitiendo detectar si el contenido de éste ha sido alterado durante su tiempo de tránsito por el ciberespacio.
Según proponen, para echar a andar DKIM en un servidor de mensajes SMTP, deberían generarse un par de claves, pública y privada. La primera de ellas sería publicada a través del servicio estándar DNS, mientras que la segunda sería utilizada internamente para firmar digitalmente los mensajes.
Cuando un usuario autorizado envía un correo, el servidor generaría la firma del contenido en tiempo real y la añadiría a los encabezados del mensaje. El servidor del destinatario extraería la firma del mensaje y, mediante una consulta al DNS del origen, obtendría su clave pública, con lo que podría verificar la validez de la firma.
De esta forma, en función del resultado de la comprobación, el destinatario podría aplicar políticas locales de filtrado. Por ejemplo, si el dominio origen del mensaje existe y la firma es válida, es probable que se trate de un mensaje que debe ser entregado al destinatario, pero se le podrían pasar filtros basados en contenido para una mayor seguridad. Si la firma no es correcta o no aparece, podrían tomarse medidas de descarte o marcado del mensaje.
DKIM pretende controlar los mensajes haciendo que el servidor de correo del que proceden firme digitalmente los envíos. De esta forma se consigue, en primer lugar, poder verificar el dominio al que pertenece el remitente de un mensaje y, en segundo lugar, asegurar la integridad del mismo permitiendo detectar si el contenido de éste ha sido alterado durante su tiempo de tránsito por el ciberespacio.
Según proponen, para echar a andar DKIM en un servidor de mensajes SMTP, deberían generarse un par de claves, pública y privada. La primera de ellas sería publicada a través del servicio estándar DNS, mientras que la segunda sería utilizada internamente para firmar digitalmente los mensajes.
Cuando un usuario autorizado envía un correo, el servidor generaría la firma del contenido en tiempo real y la añadiría a los encabezados del mensaje. El servidor del destinatario extraería la firma del mensaje y, mediante una consulta al DNS del origen, obtendría su clave pública, con lo que podría verificar la validez de la firma.
De esta forma, en función del resultado de la comprobación, el destinatario podría aplicar políticas locales de filtrado. Por ejemplo, si el dominio origen del mensaje existe y la firma es válida, es probable que se trate de un mensaje que debe ser entregado al destinatario, pero se le podrían pasar filtros basados en contenido para una mayor seguridad. Si la firma no es correcta o no aparece, podrían tomarse medidas de descarte o marcado del mensaje.
El siguiente diagrama muestra esquemáticamente el funcionamiento de DKIM:

¿Y quién anda detrás de este invento? Pues ni más ni menos que Yahoo! (iniciadores del proyecto), Cisco, PGP y Sendmail, y según comenta su inventor, Mark Delany, también han contado con la colaboración de IBM, Earthlink, Microsoft, Spamhaus, Google, PayPal y Alt-N, entre otros.
En resumen, se trata de un nuevo intento para acabar con el envío de mensajes desde destinatarios incorrectos o servidores "no creíbles", basándose esta vez en la utilización de criptografía de clave pública. Si bien no es de por sí una tecnología que resuelva el problema al 100%, sí que podría colaborar mucho. Además, lo más probable es que la solución final sea una combinación de distintas técnicas, así que bienvenida sea.
Particularmente me convence la idea de aplicar técnicas criptográficas para asegurar el correo, así como la utilización de estándares y soluciones colaborativas consensuada entre proveedores. Sin embargo, este último aspecto es su punto más débil: necesita una adopción global para que su efectividad pueda ser razonable.
En cualquier caso, todo esto forma parte de la lógica y necesaria evolución de tecnologías que tiene que acontecer hasta que la humanidad consiga dar con la forma para la eliminación definitiva del spam, phishing, spoofing y otras lindezas virtuales.
domingo, 29 de octubre de 2006
Hoy he encontrado otro buscador de esos que parecen ir evolucionando hacia la humanización del servicio, Ms. Dewey.
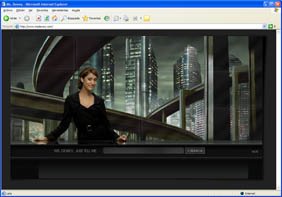 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
viernes, 6 de octubre de 2006
Pues sí, he decidido dar el salto.
Ya llevaban tiempo recordándome que podía unirme a Blogger Beta y comenzar a disfrutar de sus innumerables ventajas, así que, en un alarde de osadía, me he lanzado.
Y viendo el resultado, parece que ha merecido la pena. Os comento por qué.
Desde el punto de vista visual, es una pasada: las plantillas son mucho más completas, y su contenido fácilmente modificable, aspecto éste bastante complejo en la versión anterior. Incluso hay disponible una opción mediante la cual se accede a una vista de diseño del blog, en la que podemos mover cosas de sitio simplemente arrastrándolas, o modificar su contenido con formularios específicos para cada sección de contenido. De la misma forma, se incluyen utilidades para la selección visual de colores de las distintas áreas, que facilita enormemente esta tarea.
Los post se realizan de la misma forma, si bien se ha incorporado la posibilidad de añadir al mismo la lista de tags (separados por comas) que lo categorizan. Conclusión inmediata: a la m*erda los technorati tags que comencé a introducir hace algunas semanas.
Los post que tenía archivados han pasado sin problema al nuevo formato. Sí es cierto que los comentarios, para los que había incluido recientemente Haloscan, no ha sido capaz de migrarlo (lógico, por otra parte), ni el Blogroll recién estrenado de mi columna derecha. Ya veré cómo vuelvo a poner eso en pie, aunque es posible que, dada las nuevas facilidades, mantenga la lista de enlaces a mano, sin necesidad de utilizar el servicio Bloglines, como venía haciendo.
Nada, que ya soy un Blogger Beta ;-)
Ya llevaban tiempo recordándome que podía unirme a Blogger Beta y comenzar a disfrutar de sus innumerables ventajas, así que, en un alarde de osadía, me he lanzado.
Y viendo el resultado, parece que ha merecido la pena. Os comento por qué.
Desde el punto de vista visual, es una pasada: las plantillas son mucho más completas, y su contenido fácilmente modificable, aspecto éste bastante complejo en la versión anterior. Incluso hay disponible una opción mediante la cual se accede a una vista de diseño del blog, en la que podemos mover cosas de sitio simplemente arrastrándolas, o modificar su contenido con formularios específicos para cada sección de contenido. De la misma forma, se incluyen utilidades para la selección visual de colores de las distintas áreas, que facilita enormemente esta tarea.
Los post se realizan de la misma forma, si bien se ha incorporado la posibilidad de añadir al mismo la lista de tags (separados por comas) que lo categorizan. Conclusión inmediata: a la m*erda los technorati tags que comencé a introducir hace algunas semanas.
Los post que tenía archivados han pasado sin problema al nuevo formato. Sí es cierto que los comentarios, para los que había incluido recientemente Haloscan, no ha sido capaz de migrarlo (lógico, por otra parte), ni el Blogroll recién estrenado de mi columna derecha. Ya veré cómo vuelvo a poner eso en pie, aunque es posible que, dada las nuevas facilidades, mantenga la lista de enlaces a mano, sin necesidad de utilizar el servicio Bloglines, como venía haciendo.
Nada, que ya soy un Blogger Beta ;-)
domingo, 17 de septiembre de 2006
Si hay sistemas que vistas al usuario parecen no evolucionar con el tiempo, éstos son, sin duda, los buscadores. Hace años estamos viendo sus pobres interfaces, normalmente basados en un cuadro de texto y un botón "Enviar" o, a lo más, una lista de categorías de enlaces; introduciendo el término a localizar, aparecen ante nuestros ojos una lista de sitios web recomendados, a veces con más y otras con menos tino. Y es que la evolución de los motores de búsqueda está normalmente por dentro, en forma de nuevos algoritmos, rankings, sugerencias, tipos de contenidos, y otros aspectos, normalmente invisibles para el usuario.
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
miércoles, 6 de septiembre de 2006
Estoy estrenando Haloscan, un sistema on-line de gestión de comentarios y trackbacks para blogs. Se ha instalado él solito, sólo he tenido que indicarle mi usuario y contraseña de Blogger y él mismo ha insertado los cambios en la plantilla e incluso un post diciendo esto:
Haloscan commenting and trackback
have been added to this blog.
En fin, a ver si alguien se anima y estrena el nuevo sistema haciendo un comentario, un trackback o lo que sea. Bueno, o mejor, para no esperar, los haré yo mismo.
La pena es que los comentarios que tenía hasta el momento, aunque eran escasos, todavía no sé muy bien dónde han ido a parar... tendré que investigar un poco.
martes, 5 de septiembre de 2006
Leyendo el blog http://google.dirson.com/index.php sobre noticias de Google en español, llego a una curiosa aplicación que esta compañía ha puesto en marcha, como otras, en fase beta: Google Image Labeler.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.
viernes, 9 de junio de 2006
Esta mañana he recibido un correo electrónico invitándome a probar Google SpreadSheets, el último invento de los laboratorios de esta compañía. Como Googligan convencido, en cuanto he tenido ocasión, he saltado a comprobar cuánto de cierto hay en lo que se ha estado comentando en Internet durante los últimos días.
En la actualidad Google SpreadSheets se publica en forma de test limitado, es decir, se trata de una versión beta (bastante avanzada, todo sea dicho) a la que no se puede acceder sin disponer de una invitación, la cual es posible solicitar desde la misma Web. A mí me ha tardado tres o cuatro días desde el momento en que rellené el formulario de solicitud.
Vale, pero comencemos por el principio: ¿qué es Google Spreadsheets? Podríamos definirlo como una hoja de cálculo completamente on-line, una especie de Excel preparada para funcionar en un navegador, sin necesidad de descargar ni instalar software alguno, y, en principio, de uso gratuito. Pinta bien, ¿eh?
Desde el punto de vista de un usuario habitual de la hoja de cálculo de Microsoft, el primer contacto con la herramienta es impresionante. Estéticamente, muy limpio (se nota que usa Ajax, permítaseme el chiste fácil ;-). El manejo, sencillísimo, y más aún si se ha utilizado Excel, puesto que los mecanismos de interacción son muy similares a los de esta popular aplicación. La velocidad, bastante buena; en las pruebas que he realizado, con hojas de cerca de 2.500 celdas con fórmulas enrevesadillas encadenadas unas a otras, en ningún momento he notado retrasos que pudieran impedir el trabajo con ellas de forma fluida.
En cuanto a las funcionalidades, salvando la ausencia de gráficas, no he echado en falta nada de lo que utiliza habitualmente un usuario de nivel bajo y medio de Excel, entre los que nos encontramos la mayoría: fórmulas, formatos, ordenaciones, e incluso operaciones con archivos. Bien es cierto que no alcanza la gran cantidad de opciones que tiene Excel, pero desde luego, las principales sí que las incorpora.
El almacenamiento se soluciona completamente en el servidor. El usuario no tiene por qué guardar nada en su disco duro, todo quedará almacenado en su carpeta de las máquinas de Google. Respecto a esto, habrá que ver si los usuarios nos podemos acostumbrar a que nuestros archivos se encuentren guardados en Internet, lo que, para un mortal, equivale a decir "no tengo ni idea de dónde están mis ficheros". Por ello, es importante destacar que importa y exporta archivos XLS directamente y, por lo que he podido comprobar, no lo hace nada mal, incluso con fórmulas y formatos relativamente complejos.
Otro detalle que muestra el nivel del producto es su implementación de la idea de trabajo colaborativo, aspecto éste donde destaca sobre sus competidores tradicionales, al menos hasta el próximo movimiento de ficha de Microsoft. Lejos de montar una infraestructura de checkin/checkout o control de versiones, han optado por la comunicación asíncrona. En otras palabras, es perfectamente posible que varias personas se encuentren a un mismo tiempo tocando la misma hoja de cálculo, a la vez que pueden estar comentando la jugada en un pequeño chat integrado en el mismo entorno. De hecho, si una de ellas modifica el contenido de una celda, el resto de participantes verán, en pocos segundos, este cambio reflejado en la hoja sobre la que están trabajando.
Esto, que puede parecer relativamente sencillo en aplicaciones de escritorio, se complica bastante en un entorno desconectado como es la web. Es curioso, mientras se está usando mantiene una conexión activa con un servidor de Google, entiendo que será el canal de recepción de datos y notificaciones:
C:\>netstat find "google"
TCP JMA:2678 05178618550233449.spreadsheets.google.com:http ESTABLISHED
Para los ases del botón derecho del ratón, y más concretamente de la opción "Ver código fuente", sin duda es una decepción. Una página web simple, de unos 3K, que no hace más que referenciar una librería javascript almacenada en un archivo externo de unos 170k, que es en realidad la que hace la magia. Las fuentes están ahí, aunque a la vista de su contenido, deduzco que han sido 'ofuscadas' para dificultar su comprensión, y que gran parte de los procesos se llevan a cabo en servidor, que devuelve el HTML de la porción a actualizar en cada momento.
En fin, en mi opinión, una auténtica maravilla, y una nueva prueba de que Google apuesta por una nueva forma de trabajar, totalmente on-line y basada en Web, como ya lleva demostrando desde hace bastante tiempo.
Y por cierto, dado que uno de los fuertes de Google es el análisis de contenidos para la presentación de publicidad altamente dirigida, ¿aplicarán esta idea a SpreadSheets? Por ejemplo, ¿nos aconsejará entidades bancarias si estamos introduciendo en la hoja de cálculo un plan de tesorería en el que aparecen números rojos? Si estamos consultando un presupuesto de hardware recibido en formato de hoja de cálculo, ¿será capaz de recomendarnos productos similares, o incluso más económicos, que los que estén reflejados en él? La verdad es que las posibilidades son infinitas, tantas como utilidades damos a las hojas de cálculo.
En la actualidad Google SpreadSheets se publica en forma de test limitado, es decir, se trata de una versión beta (bastante avanzada, todo sea dicho) a la que no se puede acceder sin disponer de una invitación, la cual es posible solicitar desde la misma Web. A mí me ha tardado tres o cuatro días desde el momento en que rellené el formulario de solicitud.
Vale, pero comencemos por el principio: ¿qué es Google Spreadsheets? Podríamos definirlo como una hoja de cálculo completamente on-line, una especie de Excel preparada para funcionar en un navegador, sin necesidad de descargar ni instalar software alguno, y, en principio, de uso gratuito. Pinta bien, ¿eh?
Desde el punto de vista de un usuario habitual de la hoja de cálculo de Microsoft, el primer contacto con la herramienta es impresionante. Estéticamente, muy limpio (se nota que usa Ajax, permítaseme el chiste fácil ;-). El manejo, sencillísimo, y más aún si se ha utilizado Excel, puesto que los mecanismos de interacción son muy similares a los de esta popular aplicación. La velocidad, bastante buena; en las pruebas que he realizado, con hojas de cerca de 2.500 celdas con fórmulas enrevesadillas encadenadas unas a otras, en ningún momento he notado retrasos que pudieran impedir el trabajo con ellas de forma fluida.
En cuanto a las funcionalidades, salvando la ausencia de gráficas, no he echado en falta nada de lo que utiliza habitualmente un usuario de nivel bajo y medio de Excel, entre los que nos encontramos la mayoría: fórmulas, formatos, ordenaciones, e incluso operaciones con archivos. Bien es cierto que no alcanza la gran cantidad de opciones que tiene Excel, pero desde luego, las principales sí que las incorpora.
El almacenamiento se soluciona completamente en el servidor. El usuario no tiene por qué guardar nada en su disco duro, todo quedará almacenado en su carpeta de las máquinas de Google. Respecto a esto, habrá que ver si los usuarios nos podemos acostumbrar a que nuestros archivos se encuentren guardados en Internet, lo que, para un mortal, equivale a decir "no tengo ni idea de dónde están mis ficheros". Por ello, es importante destacar que importa y exporta archivos XLS directamente y, por lo que he podido comprobar, no lo hace nada mal, incluso con fórmulas y formatos relativamente complejos.
Otro detalle que muestra el nivel del producto es su implementación de la idea de trabajo colaborativo, aspecto éste donde destaca sobre sus competidores tradicionales, al menos hasta el próximo movimiento de ficha de Microsoft. Lejos de montar una infraestructura de checkin/checkout o control de versiones, han optado por la comunicación asíncrona. En otras palabras, es perfectamente posible que varias personas se encuentren a un mismo tiempo tocando la misma hoja de cálculo, a la vez que pueden estar comentando la jugada en un pequeño chat integrado en el mismo entorno. De hecho, si una de ellas modifica el contenido de una celda, el resto de participantes verán, en pocos segundos, este cambio reflejado en la hoja sobre la que están trabajando.
Esto, que puede parecer relativamente sencillo en aplicaciones de escritorio, se complica bastante en un entorno desconectado como es la web. Es curioso, mientras se está usando mantiene una conexión activa con un servidor de Google, entiendo que será el canal de recepción de datos y notificaciones:
C:\>netstat find "google"
TCP JMA:2678 05178618550233449.spreadsheets.google.com:http ESTABLISHED
Para los ases del botón derecho del ratón, y más concretamente de la opción "Ver código fuente", sin duda es una decepción. Una página web simple, de unos 3K, que no hace más que referenciar una librería javascript almacenada en un archivo externo de unos 170k, que es en realidad la que hace la magia. Las fuentes están ahí, aunque a la vista de su contenido, deduzco que han sido 'ofuscadas' para dificultar su comprensión, y que gran parte de los procesos se llevan a cabo en servidor, que devuelve el HTML de la porción a actualizar en cada momento.
En fin, en mi opinión, una auténtica maravilla, y una nueva prueba de que Google apuesta por una nueva forma de trabajar, totalmente on-line y basada en Web, como ya lleva demostrando desde hace bastante tiempo.
Y por cierto, dado que uno de los fuertes de Google es el análisis de contenidos para la presentación de publicidad altamente dirigida, ¿aplicarán esta idea a SpreadSheets? Por ejemplo, ¿nos aconsejará entidades bancarias si estamos introduciendo en la hoja de cálculo un plan de tesorería en el que aparecen números rojos? Si estamos consultando un presupuesto de hardware recibido en formato de hoja de cálculo, ¿será capaz de recomendarnos productos similares, o incluso más económicos, que los que estén reflejados en él? La verdad es que las posibilidades son infinitas, tantas como utilidades damos a las hojas de cálculo.
martes, 30 de mayo de 2006
A los que nos atrae la idea de probar nuevos sistemas operativos, plataformas o entornos de desarrollo, a veces nos supone un gran impedimento el no disponer de una máquina de pruebas que poder destrozar instalando-desinstalando-reinstalando aplicaciones, módulos, librerías, parches y todo tipo de artilugios software, que normalmente tienden a llenar los equipos de basura digital.
Hace tiempo encontré algunos productos basados en web como gestores de contenidos (CMS) y similares que se podían probar on-line, corriendo en servidores de los propios desarrolladores. La idea me pareció tan fantástica como osada: "si quieres probar mi producto, toma, ahí tienes las claves de superadministrador, entra y juega con él". Efectivamente, se podía entrar, crear usuarios, eliminarlos, modificar los contenidos y hacer todo tipo de operaciones (¿perrerías?), aunque cada media hora el sistema volvía a su estado inicial, eliminando todas las barbaridades introducidas por gente que, como el menda, no tenía otra cosa mejor que hacer.
De esta forma es posible probar un sistema completo sin necesidad de descargar ni instalar nada. Podemos olvidarnos de instalar un entorno LAMP (Linux+Apache+MySQL+PHP), algo bastante complejo para neófitos, para probar tal o cual plataforma de creación de Portales, Blogs (como WordPress, del que ya hablé hace un tiempo), u otros. Toda una idea feliz.
A modo de ejemplo, si os interesa ver el efecto sobre una plataforma eLearning, existe una demo on-line de Moodle, un famoso LMS (Learning Management System o Sistema de Gestión de Aprendizaje) Open source.
Pero, ¿y qué ocurre cuando lo que quiero probar no es una plataforma Web? ¿Y si se trata de un complejo y pesado entorno de desarrollo, o un gestor de bases de datos?
Eso mismo han debido preguntarse los tecnólogos de Microsoft, que desde hace ya algunos meses han puesto a disposición del público sus Laboratorios Virtuales. Un laboratorio virtual es un ordenador que es posible controlar de forma remota de la misma forma en que lo haríamos si estuviésemos sentados encima. Y como no podía ser de otra forma, este ordenador viene con todo el software que podamos necesitar para probar o aprender a manejar los productos que pretendemos. La captura de pantalla que adjunto muestra el armamento que trae de serie el Windows 2003 Server virtual que he estado probando un rato: Biztalk Server 2006, Visual Studio 2005, SQL Server 2005, .Net 2.0... vamos, una bonita colección.

Microsoft ofrece este servicio en dos modalidades. A una la llaman "express", cuyas sesiones de control de la máquina remota son de 30 minutos y simplemente es necesario suministrar el correo electrónico y algún dato básico sobre nuestro trabajo. La otra modalidad, con accesos de 90 minutos, sí requiere introducir más información personal, por lo que de momento voy a obviarla convenientemente. ;-)
Existen distintos laboratorios, en función del producto o tecnología que queremos probar: Visual Studio Team system, SQL Server 2005, Biztalk Server y ASP.NET 2.0. Al iniciar cualquiera de ellos, se creará el entorno software apropiado, y se nos facilitará un manual que nos servirá de guía de aprendizaje para que lo tengamos más fácil al principio.
En resumen, esta tecnología permite, en menos de un minuto, disponer de un sistema con software que tardaríamos varias horas en instalar en nuestros equipos, suponiendo, además, que pudiésemos conseguir estas aplicaciones.
Por poner alguna pega, el entorno, manuales, e incluso el software de la máquina remota está en inglés; pero no pasa nada, eso seguro que cambia en un futuro próximo. También puede resultar algo lento a veces, aunque la verdad es que, en general, funciona bastante bien.
Hace tiempo encontré algunos productos basados en web como gestores de contenidos (CMS) y similares que se podían probar on-line, corriendo en servidores de los propios desarrolladores. La idea me pareció tan fantástica como osada: "si quieres probar mi producto, toma, ahí tienes las claves de superadministrador, entra y juega con él". Efectivamente, se podía entrar, crear usuarios, eliminarlos, modificar los contenidos y hacer todo tipo de operaciones (¿perrerías?), aunque cada media hora el sistema volvía a su estado inicial, eliminando todas las barbaridades introducidas por gente que, como el menda, no tenía otra cosa mejor que hacer.
De esta forma es posible probar un sistema completo sin necesidad de descargar ni instalar nada. Podemos olvidarnos de instalar un entorno LAMP (Linux+Apache+MySQL+PHP), algo bastante complejo para neófitos, para probar tal o cual plataforma de creación de Portales, Blogs (como WordPress, del que ya hablé hace un tiempo), u otros. Toda una idea feliz.
A modo de ejemplo, si os interesa ver el efecto sobre una plataforma eLearning, existe una demo on-line de Moodle, un famoso LMS (Learning Management System o Sistema de Gestión de Aprendizaje) Open source.
Pero, ¿y qué ocurre cuando lo que quiero probar no es una plataforma Web? ¿Y si se trata de un complejo y pesado entorno de desarrollo, o un gestor de bases de datos?
Eso mismo han debido preguntarse los tecnólogos de Microsoft, que desde hace ya algunos meses han puesto a disposición del público sus Laboratorios Virtuales. Un laboratorio virtual es un ordenador que es posible controlar de forma remota de la misma forma en que lo haríamos si estuviésemos sentados encima. Y como no podía ser de otra forma, este ordenador viene con todo el software que podamos necesitar para probar o aprender a manejar los productos que pretendemos. La captura de pantalla que adjunto muestra el armamento que trae de serie el Windows 2003 Server virtual que he estado probando un rato: Biztalk Server 2006, Visual Studio 2005, SQL Server 2005, .Net 2.0... vamos, una bonita colección.

Microsoft ofrece este servicio en dos modalidades. A una la llaman "express", cuyas sesiones de control de la máquina remota son de 30 minutos y simplemente es necesario suministrar el correo electrónico y algún dato básico sobre nuestro trabajo. La otra modalidad, con accesos de 90 minutos, sí requiere introducir más información personal, por lo que de momento voy a obviarla convenientemente. ;-)
Existen distintos laboratorios, en función del producto o tecnología que queremos probar: Visual Studio Team system, SQL Server 2005, Biztalk Server y ASP.NET 2.0. Al iniciar cualquiera de ellos, se creará el entorno software apropiado, y se nos facilitará un manual que nos servirá de guía de aprendizaje para que lo tengamos más fácil al principio.
En resumen, esta tecnología permite, en menos de un minuto, disponer de un sistema con software que tardaríamos varias horas en instalar en nuestros equipos, suponiendo, además, que pudiésemos conseguir estas aplicaciones.
Por poner alguna pega, el entorno, manuales, e incluso el software de la máquina remota está en inglés; pero no pasa nada, eso seguro que cambia en un futuro próximo. También puede resultar algo lento a veces, aunque la verdad es que, en general, funciona bastante bien.
lunes, 22 de mayo de 2006
Según la Wikipedia, el término Phishing viene del inglés Fish (pescar), debido a que precisamente se trata de las técnicas que usan los pobladores del lado oscuro de la red para pescar datos personales y confidenciales de incautos navegantes utilizando señuelos y trampas, a veces sofisticadas, a veces bastante inocentes.
Este es el mensaje que he recibido hoy de la dirección (falsa, por supuesto) support@cajamadrid.es, no os lo perdáis porque no tiene desperdicio:
Bueno, si partimos de que Luis Perez Monreal (nombre inventado, con toda seguridad) no maneja muy bien el castellano, podremos entender cómo un señor designado por una prestigiosa institución financiera para informarnos sobre nuevas medidas de seguridad es capaz de cometer tal cantidad de atropellos a esta lengua en tan poco espacio. En cualquier caso, se trata de un experto en seguridad, no de García Márquez. ;-)
¿Y qué me dicen de basar el acceso a los datos, cuentas y fondos personales en una pregunta personal del tipo "Nombre de su primer colegio"? ¿Eso es lo que da de sí el departamento antifraude? :-D Es simplemente ridículo.
Desde luego esto debería ser suficiente para no creérselo. Si, además, sumamos la gran cantidad de apariciones en los medios y la propia difusión que hacen desde estas entidades de que no deben prestar atención a este tipo de mensajes, parece asombroso que todavía haya usuarios que piquen el anzuelo.
Pero no podía resistirme: cual cándido pececillo, he picado el enlace del mensaje y me he encontrado con una página impecablemente copiada de la original de Caja Madrid. Sólo he echado en falta el candado en el pie del navegador indicando que se trata de una página web segura. Por lo demás, tanto el interfaz visual como los mecanismos de interacción son idénticos (de hecho, copiados a nivel de código HTML) del original.
Una vez allí, el usuario es guiado por un asistente en el que se solicitan distintos datos de acceso: DNI, número de contrato, claves de acceso, y algunos datos más, aunque aparentemente inofensivos. Al finalizar, nos obsequian con un texto de agradecimiento (sincero, eso sí) y nos redireccionan a la página, esta vez real, de la Caja. Buen trabajo, sí señor.
Uno, que es curioso por naturaleza, ha ido a consultar el whois en un registrador de dominios, a ver qué se conoce de los propietarios de bancamadrid.com, al que hace referencia el mensaje, obteniendo:
Obviamente, los datos de registro también son falsos... La empresa MapInfo existe, tiene una sede en Windsor, incluso Iain Daws es uno de sus directivos. Ahora bien, dudo mucho que se dedique a hacer estas cosas.
Destaca, además, la fecha de creación del dominio, el 21 de mayo, ¡ayer! Se ve que el organizador de esta fiesta no tenía otra cosa mejor que hacer un domingo por la tarde que registrar un dominio con un nombre comercial atractivo, bastante similar al de la entidad financiera, y ponerse a enviar correos a diestro y siniestro.
Como último dato, buscando la dirección IP en la que está montado el servicio web (69.248.133.121) en varios localizadores geográficos gratuitos, resulta que está en Estados Unidos, más concretamente en New Jersey o Virginia, según la fuente que consultemos. Como para ir a buscarlos, vaya.
En fin, valga todo esto para, una vez más, recordar que nunca debe prestársele atención a un correo procedente de una entidad bancaria que le solicite introducción o envío de datos personales o claves, por mucho que parezca haber sido remitido desde las mismas.
Este es el mensaje que he recibido hoy de la dirección (falsa, por supuesto) support@cajamadrid.es, no os lo perdáis porque no tiene desperdicio:
Apreciado Cliente de Banca en Linea,
Caja Madrid siempre trata de encontrar sus expectativas mas altas. Por eso usamos la ultima tecnologia en seguridad para nuestros clientes.
Por lo tanto nuestro departamento de antifraude ha desarrollado un nuevo sistema de seguridad que elimine cualquier posibilidad del acceso de la tercera persona a sus datos, cuentas ni fondos.
Este sistema esta construido en la utilizacion de una pregunta secreta y respuesta.
Su respuesta secreta seria usada para confirmar su identidad cuando haga una operacion de pagos.
Es obligatorio para todos los clientes de Caja Madrid Banca en Linea usar este sistema de seguridad.
Nosotros consejo para usted es que introduzca su pregunta secreta y su respuesta de su cuenta cuanto antes.
Si el registro no es realizado dentro de 14 dias su cuenta sera suspendida temporalmente hasta que su registro sea completado.
Esto solo le va a costar unos minutos de su tiempo y va a tener una seguridad mucho mas elevadar.
Para comenzar el registro por favor pinche aqui : http://oi.bancamadrid.com/
Atentamente,
Luis Perez Monreal.
Departamento de seguridad y
asistencia al cliente.
Caja Madrid.
Bueno, si partimos de que Luis Perez Monreal (nombre inventado, con toda seguridad) no maneja muy bien el castellano, podremos entender cómo un señor designado por una prestigiosa institución financiera para informarnos sobre nuevas medidas de seguridad es capaz de cometer tal cantidad de atropellos a esta lengua en tan poco espacio. En cualquier caso, se trata de un experto en seguridad, no de García Márquez. ;-)
¿Y qué me dicen de basar el acceso a los datos, cuentas y fondos personales en una pregunta personal del tipo "Nombre de su primer colegio"? ¿Eso es lo que da de sí el departamento antifraude? :-D Es simplemente ridículo.
Desde luego esto debería ser suficiente para no creérselo. Si, además, sumamos la gran cantidad de apariciones en los medios y la propia difusión que hacen desde estas entidades de que no deben prestar atención a este tipo de mensajes, parece asombroso que todavía haya usuarios que piquen el anzuelo.
Pero no podía resistirme: cual cándido pececillo, he picado el enlace del mensaje y me he encontrado con una página impecablemente copiada de la original de Caja Madrid. Sólo he echado en falta el candado en el pie del navegador indicando que se trata de una página web segura. Por lo demás, tanto el interfaz visual como los mecanismos de interacción son idénticos (de hecho, copiados a nivel de código HTML) del original.
Una vez allí, el usuario es guiado por un asistente en el que se solicitan distintos datos de acceso: DNI, número de contrato, claves de acceso, y algunos datos más, aunque aparentemente inofensivos. Al finalizar, nos obsequian con un texto de agradecimiento (sincero, eso sí) y nos redireccionan a la página, esta vez real, de la Caja. Buen trabajo, sí señor.
Uno, que es curioso por naturaleza, ha ido a consultar el whois en un registrador de dominios, a ver qué se conoce de los propietarios de bancamadrid.com, al que hace referencia el mensaje, obteniendo:
domain: bancamadrid.com
owner: Iain Daws
organization: MapInfo Ltd
email: xprojectp6@yahoo.com
address: Minton Place
city: Windsor
state: --
postal-code: SL4 1EG
country: GB
phone: 01753848240
created: 2006-05-21 19:24:10
modified: 2006-05-21 21:35:04
expires: 2007-05-21 15:24:10
Obviamente, los datos de registro también son falsos... La empresa MapInfo existe, tiene una sede en Windsor, incluso Iain Daws es uno de sus directivos. Ahora bien, dudo mucho que se dedique a hacer estas cosas.
Destaca, además, la fecha de creación del dominio, el 21 de mayo, ¡ayer! Se ve que el organizador de esta fiesta no tenía otra cosa mejor que hacer un domingo por la tarde que registrar un dominio con un nombre comercial atractivo, bastante similar al de la entidad financiera, y ponerse a enviar correos a diestro y siniestro.
Como último dato, buscando la dirección IP en la que está montado el servicio web (69.248.133.121) en varios localizadores geográficos gratuitos, resulta que está en Estados Unidos, más concretamente en New Jersey o Virginia, según la fuente que consultemos. Como para ir a buscarlos, vaya.
En fin, valga todo esto para, una vez más, recordar que nunca debe prestársele atención a un correo procedente de una entidad bancaria que le solicite introducción o envío de datos personales o claves, por mucho que parezca haber sido remitido desde las mismas.
sábado, 13 de mayo de 2006
No puede negarse que el spam es una lacra. Los que tenemos la misma dirección de correo desde hace algunos años sufrimos diariamente la recepción de decenas de mensajes publicitarios que nos hace perder tiempo y espacio de almacenamiento para nada.
Está claro, nuestras direcciones de e-mail forman parte de enormes listas que son compartidas (o vendidas) entre los spammers, y difícilmente podemos salir de ellas. O mejor dicho, es imposible salir de ellas.
Desde luego, de nada vale devolverles el mensaje escribiéndoles inocentemente "Porfa, no me envíes más correos". Peor aún, de esta forma estamos confirmándoles que la dirección que tienen es buena, y podrán ponerle una marca como indicando "dirección pata negra". Y eso suponiendo que el mensaje les llegara, puesto que normalmente los envían desde direcciones inexistentes, debido a la falta de seguridad inherente al protocolo SMTP.
Hay sistemas, a veces implementados en los clientes de correo y otras en los servidores, que son capaces de analizar los mensajes entrantes y, a base de reglas, listas negras y reconocimiento de palabras o patrones, pueden apartar (o marcar) mensajes que consideran spam, de forma que molesten algo menos. Otro día, si me acuerdo, comentaré distintas técnicas que he visto que usan los spammers para evitar ser detectados.
Aparte de utilizar estas herramientas, he encontrado algo que, aunque no ayuda a evitarlo, por lo menos puede contribuir a que no siga creciendo.
Se trata de servicios gratuitos de buzones temporales, como el disponible en esta dirección. Se trata de buzones que se generan de forma automática al recibir un mensaje y que es posible consultar desde la propia web sin necesidad de clave ni nada parecido. Por ejemplo, en el caso del servicio Mailinator, puedo asumir que dispongo de un buzón llamado loqueyoquiera@mailinator.com y consultar si tiene mensajes en cualquier momento. Por ejemplo, si pulsas aquí, tú mismo podrás ver si ese buzón ha recibido algún e-mail.
Obviamente, no es conveniente utilizarlo para recibir secretos de estado, pues cualquiera puede verlos. Sin embargo, lo he visto muy útil para registrarse en páginas web y probar servicios on-line a los que hay que suministrar una dirección de correo (por ejemplo para recibir las claves).
Está claro, nuestras direcciones de e-mail forman parte de enormes listas que son compartidas (o vendidas) entre los spammers, y difícilmente podemos salir de ellas. O mejor dicho, es imposible salir de ellas.
Desde luego, de nada vale devolverles el mensaje escribiéndoles inocentemente "Porfa, no me envíes más correos". Peor aún, de esta forma estamos confirmándoles que la dirección que tienen es buena, y podrán ponerle una marca como indicando "dirección pata negra". Y eso suponiendo que el mensaje les llegara, puesto que normalmente los envían desde direcciones inexistentes, debido a la falta de seguridad inherente al protocolo SMTP.
Hay sistemas, a veces implementados en los clientes de correo y otras en los servidores, que son capaces de analizar los mensajes entrantes y, a base de reglas, listas negras y reconocimiento de palabras o patrones, pueden apartar (o marcar) mensajes que consideran spam, de forma que molesten algo menos. Otro día, si me acuerdo, comentaré distintas técnicas que he visto que usan los spammers para evitar ser detectados.
Aparte de utilizar estas herramientas, he encontrado algo que, aunque no ayuda a evitarlo, por lo menos puede contribuir a que no siga creciendo.
Se trata de servicios gratuitos de buzones temporales, como el disponible en esta dirección. Se trata de buzones que se generan de forma automática al recibir un mensaje y que es posible consultar desde la propia web sin necesidad de clave ni nada parecido. Por ejemplo, en el caso del servicio Mailinator, puedo asumir que dispongo de un buzón llamado loqueyoquiera@mailinator.com y consultar si tiene mensajes en cualquier momento. Por ejemplo, si pulsas aquí, tú mismo podrás ver si ese buzón ha recibido algún e-mail.
Obviamente, no es conveniente utilizarlo para recibir secretos de estado, pues cualquiera puede verlos. Sin embargo, lo he visto muy útil para registrarse en páginas web y probar servicios on-line a los que hay que suministrar una dirección de correo (por ejemplo para recibir las claves).












