
Mostrando entradas con la etiqueta buscadores. Mostrar todas las entradas
Mostrando entradas con la etiqueta buscadores. Mostrar todas las entradas
domingo, 5 de octubre de 2008
Una prueba más de que los algoritmos de Google son inescrutables...

¡Gracias, Javi!
Publicado en: www.variablenotfound.com.

¡Gracias, Javi!
Publicado en: www.variablenotfound.com.
viernes, 13 de julio de 2007
 A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.
A partir de ayer mismo, por cortesía de Armonth (fundador de SigT), tengo el honor de compartir cartel con los grandes maestros en Planet Webdev, un agregador de blogs sobre programación e internet de lo más recomendable por la cantidad, y sobre todo la calidad, de los autores que colaboran en el proyecto.Por citar sólo a algunos, podemos encontrar a Anieto2k, Javier Pérez, InKiLiNo, Boja, Xavier, y así hasta 30 figuras de este mundillo.
Espero contribuir desde Variable not found a difundir información y compartir conocimientos y experiencias sobre esta profesión que tanto nos apasiona.
domingo, 29 de octubre de 2006
Hoy he encontrado otro buscador de esos que parecen ir evolucionando hacia la humanización del servicio, Ms. Dewey.
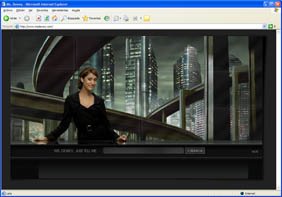 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
domingo, 17 de septiembre de 2006
Si hay sistemas que vistas al usuario parecen no evolucionar con el tiempo, éstos son, sin duda, los buscadores. Hace años estamos viendo sus pobres interfaces, normalmente basados en un cuadro de texto y un botón "Enviar" o, a lo más, una lista de categorías de enlaces; introduciendo el término a localizar, aparecen ante nuestros ojos una lista de sitios web recomendados, a veces con más y otras con menos tino. Y es que la evolución de los motores de búsqueda está normalmente por dentro, en forma de nuevos algoritmos, rankings, sugerencias, tipos de contenidos, y otros aspectos, normalmente invisibles para el usuario.
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
martes, 5 de septiembre de 2006
Leyendo el blog http://google.dirson.com/index.php sobre noticias de Google en español, llego a una curiosa aplicación que esta compañía ha puesto en marcha, como otras, en fase beta: Google Image Labeler.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.











