
Mostrando entradas con la etiqueta c#. Mostrar todas las entradas
Mostrando entradas con la etiqueta c#. Mostrar todas las entradas
miércoles, 1 de abril de 2009
 Entre las múltiples novedades aparecidas con C# 3.0 y VB.NET 9.0, las expresiones lambda son sin duda una de las que en principio pueden parecer más complejas, probablemente por su relación con conceptos no demasiado asimilables como los delegados, inferencia de tipado, métodos anónimos, o tipos genéricos, entre otros.
Entre las múltiples novedades aparecidas con C# 3.0 y VB.NET 9.0, las expresiones lambda son sin duda una de las que en principio pueden parecer más complejas, probablemente por su relación con conceptos no demasiado asimilables como los delegados, inferencia de tipado, métodos anónimos, o tipos genéricos, entre otros.Sin embargo, esa aparente dificultad desaparece en cuanto se les presta un poco de atención, y una vez comprendidas aportan a los desarrolladores una potencia y agilidad difíciles de lograr con las herramientas disponibles hasta el momento. Sólo hay que ver su amplia utilización dentro del propio .NET framework, LINQ, y nuevas plataformas como ASP.NET MVC, para darse cuenta de su importancia. Y por si fuera poco, según cuentan los expertos, su uso "engancha".
A lo largo de esta serie de tres posts intentaré describir las expresiones lambda desde un punto de vista práctico, con la única pretensión de aportar algo de luz a los que todavía no han sucumbido a su poder. ;-)
El objetivo de este primer post es puramente introductorio, y trataré conceptos y nociones básicas para poder abordar los siguientes. En el segundo post de la serie trataremos las expresiones lambda como funciones anónimas, dejando para el tercero los misteriosos árboles de expresión.
Introducción a las lambda
Según la definición en la Referencia del lenguaje C# de MSDN:"Una expresión lambda es una función anónima que puede contener expresiones e instrucciones y se puede utilizar para crear delegados o tipos de árboles de expresión"En la Guía de programación de Visual Basic 9 encontramos otra definición, muy simple y pragmática:
"Una expresión lambda es una función sin nombre que calcula y devuelve un solo valor. Se pueden utilizar las expresiones lambda dondequiera que un tipo de delegado sea válido"ScottGu también aportó su granito de arena para hacer el concepto más cercano a los desarrolladores; como siempre, al grano:
"Las Expresiones Lambda aportan una sintaxis más concisa y funcional para escribir métodos anónimos."Partiendo de estas definiciones, y de otras muchas aportadas por Google ;-), está claro que las lambda son funciones, es decir, un conjunto de intrucciones capaces de retornar un valor partiendo de los parámetros que se les suministra, aunque en determinados casos es posible que no reciba ningún parámetro, o que realicen una acción sin retornar nada. Igual que una función tradicional, vaya. Y de hecho, en el cuerpo de una expresión lambda puede haber casi de todo: llamadas a otras funciones, expresiones, bucles, declaraciones de variables...
[...]
"La forma más sencilla para conceptualizar las expresiones lambda es pensar en ellas como formas de escribir métodos breves en una línea."
Sin embargo, a diferencia de los métodos o funciones habituales, las lambdas no necesitan de un identificador, puesto que se declaran in situ, justo en el momento en que van a asignarse a una variable o a utilizarse como parámetro de una función, pasando el destinatario de esta asignación a actuar como delegado, o puntero, hacia la misma, o a ser el contenedor del árbol de expresión que la representa. Ein? Chino, eh? No pasa nada, dentro de poco estudiaremos estos dos usos en profundidad, pero antes vamos a ver cómo se definen las expresiones lambda a nivel de código.
Forma de las expresiones lambda
Las expresiones lambda en C# se escriben según el patrón descrito a continuación, al que le siguen algunos ejemplos que lo ilustran e introducen algunas particularidades.Forma general: parámetros => expresión, donde:
- parámetros: lista de parámetros separados por comas
- "=>" : separador.
- expresión: implementación de las operaciones a realizar
num => num * 2 // Lambda con un parámetro que retorna
// el doble del valor que se le pasa.
(a, b) => a + b // Lambda con dos parámetros que retorna
// la suma de ambos.
num => { // Lambda con cuerpo que recibe un
int x = new Random().Next(); // entero, y retorna la suma de éste
return num+x; // con un número aleatorio.
}
() => DateTime.Now // Lambda que no recibe parámetros
// y retorna la fecha y hora del sistema.
msg => Console.WriteLine(msg); // Recibe un parámetro, realiza una
// acción y no retorna nada.
Como se puede observar, cuando sólo existe un parámetro no es necesario utilizar paréntesis en el lado izquierdo de la expresión, mientras que hay que hacerlo en todos los demás casos. También es interesante destacar que las lambda con cuerpo deben utilizar
return para retornar el valor deseado, cuando esto sea necesario.Y un último dato: fijaos que ni los parámetros ni el retorno de la función tienen indicado un tipo. Aunque puede hacerse, normalmente no será necesario puesto que el compilador podrá inferir (deducir) el tipo a partir de su contexto, más adelante veremos cómo es esto posible. Por tanto, no es necesario escribir código tan extenso como:
(int a, int b) => (int)(a+b)Y hasta aquí este primer post introductorio. En el siguiente trataremos de explicar el papel de las expresiones lambda como funciones anónimas y facilitadoras del trabajo con delegados.
Publicado en: www.variablenotfound.com.
domingo, 1 de marzo de 2009
 Es bastante habitual encontrar código que captura una excepción y la vuelve a relanzar tras realizar algún tipo de operación. Sin embargo, habréis observado que existen varias fórmulas para hacerlo, y no necesariamente equivalentes:
Es bastante habitual encontrar código que captura una excepción y la vuelve a relanzar tras realizar algún tipo de operación. Sin embargo, habréis observado que existen varias fórmulas para hacerlo, y no necesariamente equivalentes:- crear y lanzar una nueva excepción partiendo de la original
- relanzar la excepción original
- dejar que la excepción original siga su camino
catch instanciamos y lanzamos otra excepción distinta a la original. Esto permite elevar excepciones a niveles superiores del sistema con la abstracción que necesita, ocultando detalles innecesarios y con una semántica más apropiada para su dominio. El siguiente ejemplo muestra una porción de código donde se están controlando distintos errores que pueden darse a la hora de realizar una transmisión de datos. Por cada uno de ellos se llevan a cabo tareas específicas, pero se elevan al nivel superior de forma más genérica, como
TransmissionException, pues éste sólo necesita conocer que hubo un error en la transmisión, independientemente del problema concreto: ...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw new TransmissionException("Host no encontrado", ex);
}
catch (TimeOutException ex)
{
increaseTimeOutValue(); // Ajusta el timeout para próximos envíos
throw new TransmissionException("Fuera de tiempo", ex);
}
...
Es importante, en este caso, incluir la excepción original en la excepción lanzada, para lo que debemos llenar la propiedad
InnerException (en el ejemplo anterior es el segundo parámetro del constructor). De esta forma, si niveles superiores quieren indagar sobre el origen concreto del problema, podrán hacerlo a través de ella.Otra posibilidad que tenemos es relanzar la misma excepción que nos ha llegado. Se trata de un mecanismo de uso muy frecuente, utilizado cuando deseamos realizar ciertas tareas locales, y elevar a niveles superiores la misma excepción. Siguiendo con el ejemplo anterior sería algo como:
...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw ex;
}
...
Este modelo es conceptualmente correcto si la excepción que hemos capturado tiene sentido más allá del nivel actual, aunque estamos perdiendo una información que puede ser muy valiosa a la hora de depurar: la traza de ejecución, o lo que es lo mismo, información sobre el punto concreto donde se ha generado la excepción.
Si en otro nivel superior de la aplicación se capturara esta excepción, o se examina desde el depurador, la propiedad
StackTrace de la misma indicaría el punto donde ésta ha sido lanzada (el código anterior), pero no donde se ha producido el problema original, en el interior del método transmitir(). Además, a diferencia del primer caso tratado, como la propiedad InnerException no está establecida no será posible conocer el punto exacto donde se lanzó la excepción inicial, lo que seguramente hará la depuración algo más ardua.La forma de solucionar este inconveniente es utilizar el tercer método de los enumerados al principio del post: dejar que la excepción original siga su camino, conservando los valores originales de la traza:
...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw;// Eleva la excepción al siguiente nivel
}
...
En esta ocasión, si se produce la excepción
HostNotFoundException, los niveles superiores podrán examinar su propiedad StackTrace para conocer el origen concreto del problema.Publicado en: www.variablenotfound.com.
domingo, 22 de febrero de 2009
 La palabra reservada
La palabra reservada using tiene diversos usos en el lenguaje C#, y seguro que muchos la utilizamos exclusivamente para importar espacios de nombres (namespaces), ignorando el resto de posibilidades que nos ofrece:- Importación de espacios de nombres
- Definición de alias, tanto de espacios de nombres como de tipos.
- Adquisición y liberación de recursos
1. Importación de espacios de nombres
En este caso, la palabra reservadausing actúa como una directiva del compilador, haciendo que se puedan utilizar tipos definidos en el espacio de nombres importado sin necesidad de especificarlos de forma explícita en el código. using System;
using System.Collections;...Este es el
using más común y conocido, así que poco más hay que decir al respecto...2. Definición de alias
Otra forma de utilizarusing como directiva es crear alias, o nombres cortos alternativos, a namespaces o tipos de datos, que ayuden a evitar conflictos en nombres. Veamos cada uno de ellos.2.1. Alias de espacios de nombres
Puede ser útil cuando tenemos namespaces cuyos nombres coinciden con el de clases, o en situaciones similares que hacen que el compilador no tenga claro qué estamos intentando decirle. Por ejemplo, observad el siguiente código, que no compila, a pesar de ser aparentemente correcto: using System;
namespace Prueba
{
class Saludo
{
public static void Run()
{
Console.WriteLine("hola");
}
}
}
namespace OtroNS
{
class Prueba
{
public static void Main(string[] args)
{
Prueba.Saludo.Run(); // No compila
Console.ReadLine();
}
}
}El problema es que para acceder a clase que queremos utilizar (
Saludo) desde un namespace distinto a donde se encuentra definida debemos indicar su ruta completa, es decir, especificar en qué espacio de nombres la encontraremos. Sin embargo, en el ámbito de la clase Prueba, el compilador piensa que el código Prueba.Saludo.Run() está intentando acceder a una propiedad de dicha clase, y como no lo encuentra, revienta en compilación.La solución a esto es bien sencilla utilizando los alias, puesto que permiten hacer referencia a un espacio de nombres o un tipo utilizando una denominación diferente, lo que eliminará la ambigüedad. Podemos, por ejemplo, utilizar el alias predefinido
global, que representa al nivel raíz del árbol de namespaces: ...
public static void Main(string[] args)
{
global::Prueba.Saludo.Run();
Console.ReadLine();
}
...Otra posibilidad, usando
using, sería definir un alias personalizado que nos permitiera acceder al espacio de nombres conflictivo utilizando otro identificador: ...
using MiAlias = Prueba;
...
....
public static void Main(string[] args)
{
MiAlias::Prueba.Saludo.Run();
Console.ReadLine();
}
...
Observad el uso de los dos puntos (::) para indicar que el identificador que se encuentra a su izquierda es un alias. Esto puede ayudar a evitar conflictos cuando el nombre del alias coincida con el de una clase en el ámbito de visibilidad actual.
2.2. Alias a tipos
De la misma forma, podemos crear fácilmente alias a un tipo definido, bien para evitar conflictos en nombres como los descritos anteriormente, o bien para hacer más rápido el acceso a los mismos. En el siguiente ejemplo puede observarse su uso: using Strings = System.Collections.Specialized.StringCollection;
using Con = System.Console;
...
Strings s = new Strings(); // 's' es un StringCollection
Con.WriteLine("hola");
Habréis observado que en este caso no se utilizan los dos puntos (::) para separar el alias del resto, puesto que éste no representa a un namespace, sino a un tipo.
3. Adquisición y liberación de recursos
En este caso,using sirve para especificar bloques de código en los que se van a utilizar recursos que deben ser liberados obligatoriamente al finalizar, como podrían ser conexiones a base de datos, manejadores de ficheros, o recursos del propio sistema operativo. De hecho, salvo en contadas ocasiones, utilizar using es la forma más recomendable de tratar estos asuntos.En un bloque
using se definen una serie de recursos, siempre implementando la interfaz IDisposable, y se delimita un bloque de código en el que éstos serán válidos y visibles. Al salir la ejecución de dicho bloque, estos recursos serán automáticamente liberados llamando a sus respectivos métodos Dispose(). Y esto se hará siempre, independientemente de si la salida del bloque ha sido de forma natural, mediante una excepción o un salto. En otras palabras, el compilador nos asegura que siempre invocará el método Dispose() de todos los recursos comprometidos en la operación.Un ejemplo muy habitual lo vemos con las conexiones de bases de datos, recurso valioso donde los haya. La forma correcta de tratarlas sería:
using (SqlConnection conn = new SqlConnection(connectionString))
{
hacerAlgoConLosDatos(conn);
}
// Al llegar aquí, la conexión está liberada. Seguro.
// Además, la variable conn no es visible.Respecto a la liberación automática de recursos, no hay nada mágico en ello. Internamente, el compilador de C# está transformando el código anterior en:
SqlConnection conn = new SqlConnection(connectionString);
try
{
hacerAlgoConLosDatos(conn);
}
finally
{
if (conn != null)
((IDisposable)conn).Dispose();
}Además de asegurar que los recursos son liberados cuando ya no van a ser necesarios, tiene también un efecto positivo al hacer que centremos su uso en un bloque compacto, fuera del cual no se podrá acceder a los mismos; por ejemplo, en el caso anterior, dado que la variable
conn no es visible desde fuera del bloque using, evitaremos accesos a ella cuando haya sido liberada, que provocaría errores en tiempo de ejecución.Y por cierto, una posibilidad interesante y no demasiado conocida es que se pueden especificar varios recursos en el mismo bloque
using, de forma que todos ellos se liberen al salir, sin necesidad de tener que anidarlos, siempre que sean del mismo tipo, por ejemplo:
// Anidando usings
using (SqlConnection conn1 = new SqlConnection(connstr1))
{
using (SqlConnection conn2 = new SqlConnection(connstr2))
{
// hacer algo con las dos bases de datos
}
}
// Forma más compacta
using (SqlConnection conn1 = new SqlConnection(connstr1),
conn2 = new SqlConnection(connstr2))
{
// hacer algo con las dos bases de datos
}
Publicado en: www.variablenotfound.com.
domingo, 18 de enero de 2009
 Qué divertido es esto. Hoy he descubierto una nueva característica que se presentó con ASP.NET 2.0, hace ya algunos añitos: la posibilidad de crear nuestros propios atributos en las directivas de página y controles, es decir, utilizar las líneas
Qué divertido es esto. Hoy he descubierto una nueva característica que se presentó con ASP.NET 2.0, hace ya algunos añitos: la posibilidad de crear nuestros propios atributos en las directivas de página y controles, es decir, utilizar las líneas @Page y @Control que suelen encabezar nuestros archivos .Master, .aspx y .ascx para asignar valores a propiedades de nuestras clases, como en el siguiente ejemplo:<%@ Page Language="C#" MasterPageFile="~/Site1.Master"
AutoEventWireup="true"
CodeBehind="Noticias.aspx.cs"
Inherits="MiPortal.Noticias"
Title="Noticias"
CodigoSeguridad="CD001"
%>
Para conseguirlo, basta con que la página o control herede de una clase que incluya propiedades públicas con el mismo nombre de el atributo que queremos usar. Bueno, en realidad, por cortesía de la herencia, la propiedad podría estar definida en cualquiera de sus tipos antecesores. Gracias a ello, podemos establecer mecanismos de control fuertes para asegurar la presencia de estos atributos en las directivas de página, por ejemplo:
public class MyBasePage: System.Web.UI.Page
{
private string codigoSeguridad;
public string CodigoSeguridad
{
get { return codigoSeguridad; }
set { codigoSeguridad = value; }
}
protected override void OnPreInit(EventArgs e)
{
base.OnPreInit(e);
if (string.IsNullOrEmpty(this.CodigoSeguridad))
throw new ArgumentException("CodigoSeguridad no definido");
}
}
Si ahora hacemos que todas nuestras páginas hereden de esta clase sustituyendo a la
Page estándar, estaremos forzando a que se defina el atributo CodigoSeguridad en las directivas de todos los aspx (lo mismo es aplicable). Para ello, en el archivo CodeBehind(.cs ó .vb) de las páginas deberíamos sustituir la definición por defecto por algo parecido a
public partial class Noticias: MyPage
{
...
Como curiosidad, la propiedad se establece antes del evento
PreInit, por lo que a partir de este momento del ciclo de vida de la página, podemos usar su contenido de forma segura. Además, admite cualquier tipo de dato que el sistema sea capaz de convertir desde un string; podéis probar, por ejemplo, a crear una propiedad de tipo Color o IPAddress y la plataforma realizará la conversión de forma automática. Eso sí, para usar tipos valor (int, bool...) será conveniente hacer uso de los nullables para poder recoger de forma apropiada la ausencia de la asignación del atributo, preguntando por HasValue(), así:
private bool? mostrarBanner;
public bool? MostrarBanner
{
get { return mostrarBanner; }
set { mostrarBanner= value; }
}
protected override void OnPreInit(EventArgs e)
{
base.OnPreInit(e);
if (!mostrarBanner.HasValue)
throw new ArgumentException
("MostrarBanner no definido");
}
A nivel de diseño estos atributos no aparecerán como opciones disponibles, según intellisense, al teclear la directiva
@Page; además, si incluís un atributo personalizado de este tipo, el diseñador de Visual Studio 2008 generará un aviso indicando que no es válido; la versión 2005 os mostrará un error, pero podéis ignorarlos tranquilamente en ambos casos:Validación (ASP.Net): 'CodigoSeguridad' no es un atributo válido de elemento 'Page'Y para finalizar, todo lo dicho es válido para las directivas @Control de los controles de usuario, salvo en lo referente al evento
PreInit, pero podríamos usar Init en su lugar sin muchas contraindicaciones.Publicado en: http://www.variablenotfound.com/.
domingo, 30 de noviembre de 2008
 Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.
Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.Y en estos casos la inclusión de imágenes incrustadas suele ser un requisito fundamental cuando se trata de enviar contenidos con formato HTML, de forma que, aunque normalmente se incrementa de forma notable el tamaño del paquete a enviar, se evita que los clientes tengan que descargar estos recursos adicionales desde sus equipos, cosa que además suele estar bloqueada por defecto.
.NET framework nos ofrece varias vías para hacerlo usando las clases provistas en
System.Net.Mail, pero vamos a utilizar una que nos ofrece dos ventajas importantes. La primera es que las imágenes enviadas no se muestran como adjuntos (evitando, por ejemplo, el curioso efecto presente en Outlook Express, que repite las imágenes a continuación del texto del mensaje) y la segunda es que permite especificar distintas vistas dentro desde el mismo mensaje, para que el cliente de correo utilice la que sea más apropiada.El siguiente código muestra una forma de montar un mensaje con dos vistas: la primera será utilizada por aquellos agentes de usuario (clientes de correo) que únicamente pueden mostrar texto plano, mientras que en la segunda utilizará HTML para maquetar el contenido, incluyendo una imagen que aparecerá totalmente integrada en el cuerpo del mensaje, sin mostrarse como elemento adjunto del mismo.
Podréis observar que aunque en el ejemplo muestro un código muy rígido, es fácilmente generalizable para poder utilizarlo en cualquier escenario. Como en otras ocasiones, está en C#, mi lenguaje favorito, pero sería fácilmente portable a VB.NET, por ejemplo.
// Necesitaremos estos namespaces...
using System.Net.Mail;
using System.Net.Mime;
...
// Montamos la estructura básica del mensaje...
MailMessage mail = new MailMessage();
mail.From = new MailAddress("origen@miservidor.com");
mail.To.Add("destinatario@miservidor.com");
mail.Subject = "Mensaje con imagen";
// Creamos la vista para clientes que
// sólo pueden acceder a texto plano...
string text = "Hola, ayer estuve disfrutando de "+
"un paisaje estupendo.";
AlternateView plainView =
AlternateView.CreateAlternateViewFromString(text,
Encoding.UTF8,
MediaTypeNames.Text.Plain);
// Ahora creamos la vista para clientes que
// pueden mostrar contenido HTML...
string html = "<h2>Hola, mira dónde estuve ayer:</h2>" +
"<img src='cid:imagen' />";
AlternateView htmlView =
AlternateView.CreateAlternateViewFromString(html,
Encoding.UTF8,
MediaTypeNames.Text.Html);
// Creamos el recurso a incrustar. Observad
// que el ID que le asignamos (arbitrario) está
// referenciado desde el código HTML como origen
// de la imagen (resaltado en amarillo)...
LinkedResource img =
new LinkedResource(@"C:\paisaje.jpg",
MediaTypeNames.Image.Jpeg);
img.ContentId = "imagen";
// Lo incrustamos en la vista HTML...
htmlView.LinkedResources.Add(img);
// Por último, vinculamos ambas vistas al mensaje...
mail.AlternateViews.Add(plainView);
mail.AlternateViews.Add(htmlView);
// Y lo enviamos a través del servidor SMTP...
SmtpClient smtp = new SmtpClient("smtp.miservidor.com");
smtp.Send(mail);
La siguiente imagen muestra una captura de pantalla del mismo mensaje leído desde un cliente con capacidad HTML como Outlook Express y uno que no la tiene, en este caso basado en web:

Publicado en: www.variablenotfound.com.
martes, 18 de noviembre de 2008
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
martes, 4 de noviembre de 2008
 El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
[...] Me parece muy interesante crear diccionarios utilizando tipos anónimos, pues simplifica de una forma considerable la cantidad de código que hay que escribir para conseguir llenar una estructura de este tipo. De hecho, estoy pensando en utilizar esta técnica en una librería que estoy desarrollando, pero no veo claro cómo transformar después ese objeto anónimo en el diccionario equivalente [...]
Verás que la idea es muy simple. Sólo necesitamos encontrar una fórmula que nos permita recorrer las propiedades del objeto, y por cada una de ellas, añadir la entrada correspondiente en el diccionario, especificando como clave el nombre de la propiedad y como valor el que tenga establecido la misma.
Una posibilidad muy sencilla es usar la clase
TypeDescriptor, cuyo método GetProperties() nos devuelve una colección con los descriptores de las propiedades de la instancia que le pasemos como parámetro. Iterando sobre este conjunto, podremos ir llenando el diccionario con los elementos que nos interese, tal que así, dado un objeto llamado obj: Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
Pero vamos a dar una vuelta de tuerca más. Partiendo del código anterior, es muy fácil crear un método de extensión sobre la clase
object, de forma que podamos convertir en un diccionario cualquier objeto de nuestras aplicaciones, con toda la potencia y comodidad que nos aporta esta técnica.El código sería:
public static class Extensions
{
public static Dictionary<string, object> ToDictionary(this object obj)
{
Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
return dicc;
}
}
De esta forma, dispondremos de una potente forma de "diccionarizar" nuestras instancias, sean del tipo que sean, por ejemplo:
var juan = new { nombre = "Juan", edad = 23 };
Dictionary<string, object> dicc = juan.ToDictionary();
Console.WriteLine(dicc["nombre"]); // Escribe "Juan"
var dicc2 = "hola".ToDictionary();
Console.WriteLine(dicc2["Length"]); // Escribe 4
Espero que te sea de ayuda, Leo. ¡Y gracias por participar en Variable Not Found!
Publicado en: www.variablenotfound.com.
martes, 28 de octubre de 2008
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.
domingo, 26 de octubre de 2008
 Vamos a continuar desarrollando nuestro
Vamos a continuar desarrollando nuestro traceroute utilizando el framework .NET. En la primera parte del post ya describimos los fundamentos teóricos, y esbozamos el algoritmo a emplear para conseguir detectar la secuencia de nodos atravesados por los paquetes de datos que darían lugar a nuestra ruta.Continuamos ahora con la implementación de nuestro sistema de trazado de redes.
Lo primero: estructurar la solución
Vamos a desarrollar un componente independiente, empaquetado en una librería, que nos permita realizar trazados de rutas desde cualquier tipo de aplicación, y más aún, desde cualquier lenguaje soportado por la plataforma .NET. Atendiendo a eso, ya debemos tener claro que construiremos un ensamblado, al que vamos a llamar NTraceLib, que contendrá una clase (Tracer) que gestionará toda la lógica de obtención de la traza de la ruta.Dado que debe ser independiente del tipo de aplicación que lo utilice, no podrá incluir ningún tipo de interacción con el usuario, ni acceso a interfaz alguno. Serán las aplicaciones de mayor nivel las que solucionen este problema. La clase
Tracer se comunicará con ellas enviándole eventos cada vez que ocurra algo de interés, como puede ser la recepción de paquetes de datos con las respuestas. Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:
Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:- NTrace será una aplicación de consola escrita en C#.
- WebNTrace, también escrita en C#, permitirá trazar los paquetes enviados desde el servidor Web donde se esté ejecutando hasta el destino.
- WinNTrace será una herramienta de escritorio, esta vez escrita en VB.NET, que permitirá obtener los resultados de forma más visual.
Tracer: el trazador
La claseTracer será la encargada de realizar el trazado de la ruta hacia el destino indicado. De forma muy rápida, podríamos enumerar sus principales características:- Tiene una única propiedad pública,
Host, que contiene la dirección (nombre o IP) del equipo destino del trazado. Los comandostracertytraceourtetienen más opciones, pero no las vamos a implementar para simplificar el sistema. - Tiene definidas también dos constantes:
- MAX_HOPS, que define el máximo de saltos, o nodos intermedios que permitiremos atravesar a nuestros paquetes. Normalmente no se llegará a este valor.
- TIMEOUT, que definirá el tiempo máximo de espera de llegada de las respuestas.
- Publica dos eventos, que permitirán a las aplicaciones cliente procesar o realizar la representación visual de la información resultante de la ejecución del trazado:
- ErrorReceived, que notificará a la aplicación cliente del componente que se ha producido un error durante la obtención de la ruta. Ejemplos serían "red inalcanzable", o "timeout".
- EchoReceived, que permitirá notificar de la recepción de mensajes por parte de los nodos de la ruta.
- El método
Trace()ejecutará al ser invocado el procedimiento descrito en el post anterior, lanzando los eventos para indicar a las aplicaciones cliente que actualicen su estado o procesen la respuesta. A grandes rasgos, el procedimiento consistía en ir enviado mensaje ICMP ECHO (pings) al servidor de destino incrementando el TTL del paquete en cada iteración y esperar la respuesta, bien la respuesta al ping o bien mensajes "time exceeded" indicando la expiración del paquete durante la ruta hacia el destino.
Para conocer más detalles sobre la clase
Tracer, puedes descargar el proyecto desde el enlace que encontrarás al final del post.Enviar ICMP ECHOs, o cómo hacer un Ping desde .NET
La versión 2.0 de .NET framework nos lo puso realmente sencillo, al incorporar una clase específicamente diseñada para ello, Ping, incluida en el espacio de nombres System.Net.NetworkInformation. A continuación va un código que muestra el envío de una solicitud de eco al servidor www.google.es: Ping pingSender = new Ping ();
PingOptions options = new PingOptions ();
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("datos");
int timeout = 120;
PingReply reply = pingSender.Send ("www.google.es",
timeout, buffer, options);
if (reply.Status == IPStatus.Success)
{
Console.WriteLine ("Recibido: {0}",
reply.Address.ToString ());
}
De este código vale la pena destacar algunos detalles. Primero, como podemos observar, existe una clase
PingOptions que nos permite indicar las opciones con las que queremos enviar el paquete ICMP. En particular, podremos especificar si el paquete podrá ser fragmentado a lo largo de su recorrido, así como, aunque no aparece en el código anterior, el valor inicial del TTL (time to live) del mismo. Habréis adivinado que este último aspecto es especialmente importante para lograr nuestros objetivos.Segundo, es posible indicar en un buffer un conjunto de datos arbitrarios que viajarán en el mensaje, lo que podría permitirnos medir el tiempo de ida y vuelta de un paquete de un tamaño determinado. También se puede indicar el tiempo máximo en el que debemos recibir la respuesta antes de considerar que se trata de un timeout.
Por último, la respuesta a la llamada síncrona
pingSender.Send(...) obtiene un objeto del tipo PingReply, en el que encontraremos información detallada sobre el resultado de la operación.Implementación del trazador
Si unimos el procedimiento de trazado de una ruta, descrito ampliamente en el post anterior, al método de envío de pings recién comentado, casi obtenemos directamente el código del métodoTrace() de la clase Tracer, el responsable de realizar el seguimiento de la ruta:
PingReply reply;
Ping pinger = new Ping();
PingOptions options = new PingOptions();
options.Ttl = 1;
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("NTrace");
try
{
do
{
DateTime start = DateTime.Now;
reply = pinger.Send(host,
TIMEOUT,
buffer,
options);
long milliseconds = DateTime.Now.Subtract(start).Milliseconds;
if ((reply.Status == IPStatus.TtlExpired)
|| (reply.Status == IPStatus.Success))
{
OnEchoReceived(reply, milliseconds);
}
else
{
OnErrorReceived(reply, milliseconds);
}
options.Ttl++;
} while ((reply.Status != IPStatus.Success)
&& (options.Ttl < MAX_HOPS ));
}
catch (PingException pex)
{
throw pex.InnerException;
}
Como podemos observar, se repite el Ping dentro de un bucle en el que va incrementándose el TTL hasta llegar al objetivo (
reply.Status==IPStatus.Success) o hasta que se supere el máximo de saltos permitidos. Por cada ping realizado se llama al evento correspondiente en función del resultado del mismo, con objeto de notificar a las aplicaciones cliente de lo que va pasando. Además, se va tomando en cada llamada el tiempo que se tarda desde el momento del envío hasta la recepción de la respuesta. Podéis observar que llamamos al evento
EchoReceived siempre que recibamos algo de un nodo, sea intermediario (que recibiremos un error por expiración del TTL) o el destinatario final del paquete (que recibiremos la respuesta satisfactoria al ping), mientras que el evento ErrorReceived es invocado en todas las demás circunstancias. En cualquier caso, siempre enviaremos como parámetros el PingReply, que contiene información detallada de la respuesta, y el tiempo en milisegundos que ha tardado en obtenerse la misma.Ah, una nota importante respecto al tiempo de resolución de nombres. Dado que la clase
Ping funciona tanto si le especificamos como destino una dirección IP como si es un nombre de host, hay que tener en cuenta que el primer ping podrá verse penalizado por el tiempo de consulta al DNS si esto es necesario. Esto podría solventarse muy fácilmente, realizando la resolución de forma manual y pasando al ping siempre la dirección IP, pero he preferido mantenerlo así para mantener el código más sencillo.Cómo usar NTraceLib en aplicaciones
 Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:
Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:- Declaramos una variable del tipo
Trace. - Escribimos los manejadores que procesen las respuestas de
ErrorReceivedyEchoReceived, suscribiéndolos a los correspondientes eventos. - Establecemos el host y llamamos al método
Trace()del objeto de trazado.
Vamos a ver el ejemplo concreto de la aplicación WinNTrace, sistema de escritorio creado en Visual Basic .NET, que mostrará en un formulario el resultado del trazado. En primer lugar, tiene declarado un objeto
Tracer como sigue, lo que nos permitirá enlazarle el código a los eventos de forma muy sencilla: Private WithEvents tracer As New TracerCuando el usuario teclea un host en el cuadro de texto y pulsa el botón "Trazar", se ejecuta el siguiente código (he omitido ciertas líneas para facilitar su lectura); podréis comprobar que es bastante simple, pues incluye sólo la asignación del equipo de destino y la llamada a la realización de la traza:
tracer.Host = txtHost.Text
Try
tracer.Trace()
Catch ex As Exception
MessageBox.Show("Error: " + ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
Cuando se recibe información de un nodo, sea intermediario o el destino final de la traza, añadimos al
ListView un nuevo elemento con la dirección del mismo, así como los milisegundos transcurridos desde el envío de la petición: Private Sub tracer_EchoReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.EchoReceivedEventArgs) _
Handles tracer.EchoReceived
Dim items() As String = { _
args.Reply.Address.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
En el caso de recibir un error, como un timeout, añadiremos la línea, pero aportando mostrando el tipo de error producido y destacando la fila respecto al resto con un color de fondo. Este procedimiento podría haberlo trabajado un poco más, por ejemplo añadiendo textos descriptivos de los errores, pero eso os lo dejo de deberes.
Private Sub tracer_ErrorReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.ErrorReceivedEventArgs) _
Handles tracer.ErrorReceived
Dim items() As String = { _
"Error: " + args.Reply.Status.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
item.BackColor = Color.Yellow
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
Además de WinNTrace, en la descarga que encontraréis al final del post he incluido NTrace (la aplicación de consola) y WebNTrace (la aplicación web). Aunque cada una tiene en cuenta sus particularidades de interfaz, el comportamiento es idéntico al descrito para el sistema de escritorio, por lo que no los describiremos con mayor detalle.
Conclusiones
 A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.
A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.Dejamos para artículos posteriores la realización de funcionalidades no implementadas en esta versión, como la posibilidad de cancelar una traza una vez comenzada, la resolución inicial de nombres para que el tiempo de respuesta de la primera pasarela sea más correcto, o incluso la resolución inversa del nombre de los nodos de una ruta, es decir, la obtención del hostname de cada uno de ellos tal y como lo hacen las utilidades de línea comand
tracert o traceroute. También podríamos incluir funciones de geoposicionamiento de los mismos, para intentar obtener una aproximación la ruta física que siguen los paquetes a través de la red.Espero que os haya resultado interesante. Y por supuesto, para dudas, consultas o sugerencias, por aquí me tenéis.
Descargar NTrace (proyecto VS2005)
Publicado en: www.variablenotfound.com.
domingo, 19 de octubre de 2008
 Seguro que todos habéis utilizado en alguna ocasión el comando
Seguro que todos habéis utilizado en alguna ocasión el comando tracert (o traceroute en Linux) con objeto de conocer el camino que siguen los paquetes de información para llegar desde vuestro equipo a cualquier otro host de una red. Sin embargo, es posible que más de uno no haya tenido ocasión de ver lo sencillo que resulta desarrollar un componente que realice esta misma tarea usando tecnología .NET, y lo divertido que puede llegar a ser desarrollar utilidades de red de este tipo.En esta serie de posts vamos a desarrollar, utilizando C#, un componente simple de trazado de rutas de red. La elección del lenguaje es pura devoción personal, pero lo mismo podría desarrollarse sin problema utilizando Visual Basic .NET. En cualquier caso, el ensamblado resultante podrá ser utilizado desde cualquier tipo de aplicación soportado por el framework, es decir, sea escritorio, consola o web, y, como es obvio, independientemente del lenguaje utilizado para su creación.
Pero comencemos desde el principio...
Un poco de teoría: ¿cómo funciona un traceroute?
El objetivo de los trazadores de rutas es conocer el camino que siguen los paquetes desde un equipo origen hasta un host destino detectando los sistemas intermediarios (gateways) por los que va pasando. La enumeración ordenada de dichos sistemas es lo que llamamos ruta, y es el resultado de la ejecución del comandotracert o traceroute.Para conseguir obtener esta información, como veremos después, se utiliza de forma muy ingeniosa la capacidad ofrecida por el protocolo IP para definir el tiempo de vida de los paquetes. Profundizaremos un poco en este concepto.
El TTL (Time To Live) es un campo incluido en la cabecera de todos los datagramas IP que se mueven por la red, y es el encargado de evitar que éstos circulen de forma indefinida si no encuentran su destino.
Cuando una aplicación crea un paquete IP, se le asigna un valor inicial al TTL del encabezado del mismo. El valor puede venir definido por el sistema operativo en función del protocolo concreto (TCP, UDP...), o incluso ser asignado por el propio software que lo origine. En cualquier caso, el tiempo se indica en segundos de vida, aunque en la práctica indicará el número de veces que será procesado el paquete por los dispositivos de enrutado que atravesará durante su recorrido.
Cuando este paquete se envía hacia un destino, al llegar al primer gateway de la red, éste analizará su cabecera para determinar su ruta y encaminarlo apropiadamente, y a la misma vez decrementará el valor del TTL. De ahí atravesará otra red hasta llegar al siguiente gateway de su ruta, que volverá a hacer lo mismo. Eso sí, cuando un dispositivo encaminador de este tipo detecte un paquete con un TTL igual a cero, lo descartará y enviará a su emisor original un mensaje ICMP con un código 11 ("time exceed"), que significa que se ha excedido el tiempo de vida del paquete.
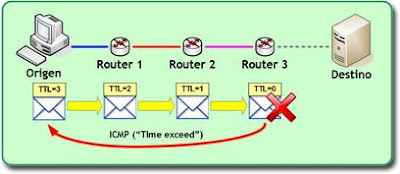
El siguiente diagrama muestra un escenario en el que un paquete es enviado con un TTL=3, y cómo es descartado antes de llegar a su destino:
Volviendo al tema del post y a algo que adelanté anteriormente, el
traceroute utiliza de forma muy ingeniosa el comportamiento descrito, siguiendo el procedimiento para averiguar la ruta de un paquete que se detalla a continuación:- Envía un paquete ICMP Echo al destino con un TTL=1. Este tipo de paquetes son los enviados normalmente al realizar un
pinga un equipo. - El primer dispositivo enrutador al que llega el paquete decrementa el TTL, y dado que es cero, descarta el paquete y envía el mensaje ICMP informando al emisor que el paquete ha sido eliminado.
- El emisor, al recibir este aviso, puede considerar que el remitente del mismo es el primer punto de la ruta que seguirá el paquete hasta su destino.
- A continuación, vuelve a intentarlo enviando de nuevo un ICMP Echo al destino, esta vez con un TTL=2.
- El paquete pasa por el primer enrutador, que transforma su TTL en 1 y lo envía a la red apropiada.
- El segundo enrutador detecta que debe encaminar el paquete y éste tiene un TTL=1 y al decrementarlo será cero, por lo que lo descarta, enviando de vuelta el mensaje "time exceed" al emisor original.
- Desde el origen, a la recepción de este mensaje ICMP, se almacena su remitente como segundo punto de la ruta.
- Y así sucesivamente, se realizan envíos con TTL=3, 4, ... hasta llegar al destino, momento en el que recibiremos la respuesta a la solicitud de eco enviada (un mensaje de tipo ICMP Echo Reply), o hasta superar el número máximo de saltos que se haya indicado (por ejemplo, usando la opción
tracert -h Nen Windows)
Función Trace(DEST)
Inicio
ttl = 1
Hacer
Enviar ICMP_ECHO_REQUEST al host DEST con TTL=ttl
Si recibimos un TIME_EXCEED desde el host X,
o bien recibimos un ICMP_ECHO_REPLY desde X, entonces
El host X forma parte de la ruta
Fin
Incrementa ttl
Mientras Respuesta <> ICMP_ECHO_REPLY Y ttl<MAXIMO
FinPublicado en: www.variablenotfound.com.
lunes, 30 de junio de 2008
 Los desplegables en cascada (también llamados cascading dropdowns o enlazados) son elementos muy frecuentes en todo tipo de aplicaciones, pues suponen una gran ayuda al usuario y dotan de mucho dinamismo al interfaz.
Los desplegables en cascada (también llamados cascading dropdowns o enlazados) son elementos muy frecuentes en todo tipo de aplicaciones, pues suponen una gran ayuda al usuario y dotan de mucho dinamismo al interfaz.En pocas palabras, consiste en llenar una lista desplegable con elementos elegidos en función de una decisión previa, como la selección en otra lista. El ejemplo típico lo encontramos en aplicaciones donde debemos introducir una dirección y nos ponen por delante un desplegable con las provincias y otro con los municipios, y en éste último sólo aparecen aquellos que pertenecen a la provincia seleccionada.
Esto, que en aplicaciones de escritorio no tiene dificultad alguna, en el entorno Web se complica un poco debido a la falta de comunicación entre la capa cliente (HTML, javascript) y servidor (ASP, .NET, JSP, PHP...), propia de un protocolo desconectado como HTTP.
Años atrás (e incluso todavía hoy) una forma de solucionar el problema es forzando un postback, es decir, una recarga de la página completa, con objeto de llenar el desplegable dependiente en función del valor seleccionado en el principal. Supongo que no es necesario detallar los inconvenientes: tiempos de espera, asombro del usuario ante el pantallazo, problemas asociados al mantenimiento del estado...
La aparición de Ajax (¡en minúsculas!) supuso una revolución para las aplicaciones Web, añadiendo a las amplias capacidades de Javascript para la manipulación del interfaz e información en cliente mecanismos ágiles para conseguir comunicación en tiempo real con el lado del servidor.
En este post explicaré cómo conseguir desplegables en cascada utilizando la plataforma ASP.NET MVC (Preview 3) en el lado servidor y Javascript en el lado cliente, apoyándome en la librería jQuery, que tanto juego da. Aprovecharé de paso para comentar algunos aspectos interesantes de la preview 3 del framework MVC, de jQuery y de novedades de C# 3.0. Tocho de post, por tanto ;-)
El resultado será un formulario como el mostrado en la siguiente imagen:

Antes de nada: estructurar la solución
Para lograr el objetivo pretendido respetando el patrón MVC, debemos contar con los siguientes elementos:- El modelo, que representará la información manejada por el sistema. Para no complicar el ejemplo (o complicarlo, según se mire ;-)), vamos a crear una colección en memoria sobre la que realizaremos las consultas.
- La vista, que será un formulario en el que colocaremos los dos desplegables. El primero de ellos permitirá seleccionar una categoría tomada del Modelo, y el segundo mostrará los elementos de dicha categoría de forma dinámica.
- El controlador, en el que incluiremos acciones, en primer lugar, para inicializar y mostrar el formulario y, en segundo lugar, para obtener la lista de elementos relacionados con la categoría seleccionada. Esta última acción será invocada por la vista cuando el primer desplegable cambie de valor.
Primero: el modelo
En escenarios reales será el conjunto de entidades que representen el modelo de datos del sistema. En este caso montaremos un ejemplo muy simple, basado en un diccionario en memoria, y un par de métodos de consulta de la información en él mantenida.public class Datos
{
private static Dictionary<string, string[]> datos =
new Dictionary<string, string[]>
{
{ "Animal", new[] { "Perro", "Gato", "Pez"} },
{ "Vegetal", new[] { "Flor", "Árbol", "Espárrago"} },
{ "Mineral", new[] { "Cuarzo", "Pirita", "Feldespato"} }
};
public static IEnumerable<string> GetCategories()
{
return datos.Keys;
}
public static IEnumerable<string> GetElementsForCategory(string category)
{
string[] els = null;
datos.TryGetValue(category, out els);
return els;
}
}Destacar del código anterior los siguientes aspectos:
- La información se almacenará en un
Dictionary<string,string[]>. Esto, por si no estás muy familiarizado con los generics o tipos genéricos, sólo quiere decir que se trata de un diccionario cuya clave será de tipo string (las categorías) y el valor será un array de strings (los elementos asociados a cada categoría).
De esta forma, podremos obtener fácilmente la lista de categorías simplemente enumerando las claves (Keys) del diccionario, y los elementos contenidos en una categoría sólo con devolver el valor asociado a la misma, como vemos en los métodosGetCategories()yGetElementsForCategories(). - Para inicializar el diccionario he utilizado un inicializador de colecciones, una característica de C# 3.0 ya comentada en un post anterior.
- Los dos métodos de consulta de datos retornan un
IEnumerable<string>(¡me encantan los generics!), flexibilizando el tipo devuelto. Así, podríamos devolver cualquier tipo de objeto que implemente este interfaz, prácticamente todas las listas, colecciones y arrays, siempre que contengan en su interior unstring.
Segundo: la vista
Para nuestro ejemplo sólo necesitamos una vista, el formulario con los desplegables, que crearemos en el archivo Index.aspx. Además de componer el interfaz, la vista gestionará la interacción con el usuario haciendo que ante la selección de una opción del desplegable de categorías se invoque al controlador para solicitarle la lista de elementos de la categoría seleccionada, y cargar con ella el segundo desplegable.El código fuente del proyecto completo lo podéis encontrar en un enlace al pie del post, pero incluiré aquí las porciones más importantes. En primer lugar, el formulario HTML se compone así:
<form method="post" action="#">
<fieldset><legend>Formulario</legend>
<label for="ddCategory">Categoría:</label>
<%= Html.DropDownList("ddCategory") %>
<label for="ddElement">Elemento:</label>
<%= Html.DropDownList("ddElement") %>
</fieldset>
</form>Fijaos un momento en el código. Los desplegables, en lugar de utilizar el tag HTML <select> se han definido utilizando los métodos de ayuda (Html helpers) incluidos en el framework MVC. Estos, además de generar las etiquetas apropiadas, realizan otra serie de tareas como establecer valores de la lista, que nos ahorrarán mucho tiempo. En el controlador veremos cómo se le inyectan los elementos (los distintos <option>) desde código de forma muy sencilla.
<script type="text/javascript">
// Inicialización
$(document).ready(function() {
$("#ddCategory").change(function() {
cambiaElementos($("#ddCategory").val());
});
cambiaElementos($("#ddCategory").val());
});
// Carga el desplegable de elementos en función
// de la categoría que le llega como parámetro.
function cambiaElementos(cat) {
var dd = document.getElementById("ddElement");
dd.options.length = 0;
dd.options[0] = new Option("Espere...");
dd.selectedIndex = 0;
dd.disabled = true;
// Control de errores
$("#ddElement").ajaxError(function(event, request, settings) {
dd.options[0] = new Option("Categoría incorrecta");
});
// Obtenemos los datos...
$.getJSON(
'<%= Url.Action("GetElements") %>', // URL a la acción
{ category: cat }, // Objeto JSON con parámetros
function(data) { // Función de retorno exitoso
$.each(data, function(i, item) {
dd.options[i] = new Option(item, item);
});
dd.disabled = false;
});
}
</script>
En la primera parte se utiliza el evento jQuery
ready, ejecutada cuando la página está lista para ser manipulada, para introducir código de inicialización. En este momento se asocia al evento change del desplegable de categorías la llamada apropiada a la función cambiaElementos(), pasándole la categoría seleccionada. También se aprovecha para realizar la primera carga de elementos. Seguidamente está la función
Seguidamente está la función cambiaElementos, que se encargará de actualizar el desplegable con los elementos asociados a la categoría seleccionada. Para ello, en primer lugar, se introduce en el dropdown un elemento con el texto "Espere...", que aparecerá mientras el sistema obtiene los datos desde el servidor, a la vez que se deshabilita el control para evitar manipulación del usuario.Después se define la función que se ejecutará si durante la llamada Ajax se produce un error. Para ello utilizamos el evento
ajaxError, al que asociamos una función anónima que, simplemente, cargará en el desplegable secundario el texto "Categoría incorrecta" y lo dejará deshabilitado.Por último, utilizamos el método
getJSON para efectuar la llamada al servidor y realizar la carga del desplegable con la información devuelta. Son tres los parámetros que se le envían al método: - La URL de la acción, obtenida utilizando el helper
Url.Actionque devuelve la dirección de la acción cuyo nombre le pasamos como parámetro. - El objeto, en formato JSON, uyas propiedades representan los parámetros a enviar al controlador.
- La función a ejecutar cuando se reciban datos del servidor. El parámetro de entrada
datacontendrá el array de string con el que tenemos que llenar el desplegable, enviado desde el servidor según la notación JSON.
Aunque el recorrido de este vector y la carga de opciones en el control podría haberse realizado de forma sencilla mediante un bucle, he utilizado el métodoeachpara ilustrar el uso de este tipo de iteradores, tan de moda y muy al estilo funcional empleado, por ejemplo, en las expresiones lambda. Este método recibe dos parámetros; el primero es la colección sobre la cual se va a iterar, y el segundo es una función que se ejecutará para cada uno de los elementos recorridos.
Tercero: el controlador
Es el intermediario en toda esta historia: recibe las peticiones del cliente a través la invocación de acciones, ejecuta las tareas apropiadas y provoca la aparición o actualización de las vistas, utilizando para ello las clases ofrecidas por el Modelo.El controlador define dos acciones: la primera de ellas (Index) es la encargada de cargar los valores iniciales de los desplegables y enviar al usuario la vista correspondiente (Index.aspx). La segunda es la responsable de devolver un objeto en notación JSON con los elementos de la categoría enviada como parámetro.
El código es el siguiente:
public class HomeController : Controller
{
public ActionResult Index()
{
ViewData["ddCategory"] = new SelectList( Datos.GetCategories() );
ViewData["ddElement"] = new SelectList( new [] {"(Selecciona)"} );
return View();
}
public ActionResult GetElements(string category)
{
IEnumerable<string> elements = Datos.GetElementsForCategory(category);
if (elements == null)
throw new ArgumentException("Categoría " + category +" no es correcta");
Thread.Sleep(1000); // Simulamos tiempo de proceso...
return Json(elements);
}
}
Hay varios puntos que me gustaría destacar en este código. En primer lugar, observad que ya las acciones siguen la nueva convención introducida en la preview 3, retornando objetos de tipo
ActionResult. En el primer método, el return View() (sin parámetros) hace que el sistema envíe al cliente la vista cuyo nombre coincide con la acción actual (es decir, Index.aspx); en el segundo método se retorna un objeto de tipo JSonResult que serializará la información suministrada en formato JSON.También es destacable la ayuda introducida en la tercera Preview para llenar listas de formularios utilizando la clase
SelectList. Como podéis ver, basta con crear en el diccionario ViewData un elemento con el mismo nombre que el del desplegable y asignarle una instancia del SelectList inicializada con una colección de elementos (cualquier tipo que implemente IEnumerable). Él se encargará, al renderizar la página, de iterar sobre la colección y crear las etiquetas <option> oportunas.Asimismo, se puede observar el uso del Modelo en ambos métodos para leer los datos. En este caso se utiliza una clase que encapsularía la lógica de obtención de información, pero nada impediría, por ejemplo, asumir que las clases del Modelo son las generadas desde el diseñador de Linq2Sql y utilizar consultas Linq desde el Controlador.
Observad también el lanzamiento de la excepción cuando la categoría especificada no existe. Lo que llega al navegador en este caso es un error HTTP que es capturado por la función que especificamos para el evento
ajaxError, haciendo que en el desplegable enlazado aparezca un mensaje de error.Por último, la inclusión de la orden
Thread.Sleep() es por pura estética, para que se vea lo bien que queda el mensaje "Espere..." en el desplegable mientras carga los datos. En un escenario real este tiempo sería consumido por las comunicaciones cliente-servidor y la obtención de datos desde el modelo, que habitualmente utilizará una base de datos u otro mecanismo de persistencia. Descargar proyecto (Visual Web Developer Express 2008 + SP1 + ASP.NET MVC Preview 3).
Descargar proyecto (Visual Web Developer Express 2008 + SP1 + ASP.NET MVC Preview 3).Publicado en: http://www.variablenotfound.com/.
sábado, 24 de mayo de 2008
 Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.
Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.Y aunque pueda parecer similar a FxCop, Microsoft Source Analysis for C# se centra en el análisis de código fuente y no en ensamblados, lo que hace que pueda afinar mucho más en las reglas de codificación.
Incluye sobre 200 buenas prácticas, cubriendo aspectos como:
- Layout (disposición) de elementos, instrucciones, expresiones y consultas
- Ubicación de llaves, paréntesis, corchetes, etc.
- Espaciado alrededor de palabras clave y operadores
- Espaciado entre líneas
- Ubicación de parámetros en llamadas y declaraciones de métodos
- Ordenación de elementos de una clase
- Formateo de documentación de elementos y archivos
- Nombrado de campos y variables
- Uso de tipos integrados
- Uso de modificadores de acceso
- Contenidos permitidos en archivos
- Texto de depuración

Tras su descarga e instalación, que puede realizarse desde esta dirección, la herramienta se integra en Visual Studio 2005 y 2008, aunque también puede utilizarse desde la línea de comandos o MSBuild.
Publicado en: www.variablenotfound.com.
domingo, 11 de mayo de 2008
 Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.
Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.Como recordaréis, hasta ese momento las acciones no tenían tipo de retorno, pero han replanteado el diseño para hacerlo más flexible, testable y potente. Así, pasamos de definir las acciones de esta forma:
public void Index()
{
RenderView("Index");
}a esta otra:
public ActionResult Index()
{
return RenderView();
}En el código anterior destacan dos aspectos. En primer lugar que la llamada a
RenderView() no tiene parámetros; el sistema mostrará la vista cuyo nombre coincida con el de la acción que se está ejecutando (Index, en este caso). En segundo lugar, que la llamada a RenderView() retorna un objeto ActionResult (o más concretamente un descendiente, RenderViewResult), que será el devuelto por la acción.De la misma forma, existen tipos de ActionResult concretos para retornar el resultado de las acciones más habituales:
RenderViewResult, retornado cuando se llama desde el controlador aRenderView().ActionRedirectResult, retornado al llamar aRedirectToAction()HttpRedirectResult, que será la respuesta a unRedirect()EmptyResult, que intuyo que será para casos en los que no hay que hacer nada (!), aunque todavía no le he visto mucho el sentido...
Además de las citadas anteriormente, una de las ventajas de retornar estos objetos desde los controladores es que podemos crear nuestra clase, siempre heredando de
ActionResult, e implementar comportamientos personalizados.Esto es lo que ha hecho el genial Phil Haack en dos ejemplos recientemente publicados en su blog.
El primero de ellos, publicado en el post "Writing A Custom File Download Action Result For ASP.NET MVC" muestra una implementación de una acción cuya invocación hace que el cliente descargue, mediante un download, el archivo indicado, en su ejemplo, el archivo CSS de su sitio web:
public ActionResult Download()
{
return new DownloadResult
{ VirtualPath="~/content/site.css",
FileDownloadName = "TheSiteCss.css"
};
}
La clase
DownloadResult una descendiente de ActionResult, en cuya implementación encontraremos, además de la definición de las propiedades VirtualPath y FileDownloadName, la implementación del método ExecuteResult, que será invocado por el framework al finalizar la ejecución de la acción, y donde realmente se realiza el envío al cliente del archivo, con parámetro content-disposition convenientemente establecido:public class DownloadResult : ActionResult
{
public DownloadResult()
{
}
public DownloadResult(string virtualPath)
{
this.VirtualPath = virtualPath;
}
public string VirtualPath { get; set; }
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (!String.IsNullOrEmpty(FileDownloadName)) {
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName)
}
string filePath = context.HttpContext.Server.MapPath(this.VirtualPath);
context.HttpContext.Response.TransmitFile(filePath);
}
}
El segundo ejemplo, publicado en el post "Delegating Action Result", vuelve a demostrar otro posible uso de los ActionResults creando un nuevo descendiente,
DelegatingResult, que puede ser retornado desde las acciones para indicar qué operaciones deben llevarse a cabo por el framework.El siguiente código muestra cómo retornamos un objeto de este tipo, inicializado con una lambda:
public ActionResult Hello()
{
return new DelegatingResult(context =>
{
context.HttpContext.Response.AddHeader("something", "something");
context.HttpContext.Response.Write("Hello World!");
});
}Como veremos a continuación, el constructor de este nuevo tipo recibe un parámetro de tipo
Action<ControllerContext> y lo almacenará de forma local en la propiedad Command, postergando su ejecución hasta más adelante; será la sobreescritura del método ExecuteResult la que ejecutará el comando:public class DelegatingResult : ActionResult
{
public Action<ControllerContext> Command { get; private set; }
public DelegatingResult(Action<ControllerContext> command)
{
this.Command = command;
}
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
throw new ArgumentNullException("context");
Command(context);
}
}
Puedes ver el código completo de ambos ejemplos, así como descargar proyectos de prueba en los artículos originales de Phil Haack:
Por último, recordar que todos estos detalles son relativos a la última actualización de la preview de esta tecnología y podrían variar en futuras revisiones.
Publicado en: www.variablenotfound.com.












