
Mostrando entradas con la etiqueta vs2008. Mostrar todas las entradas
Mostrando entradas con la etiqueta vs2008. Mostrar todas las entradas
martes, 18 de noviembre de 2008
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
domingo, 9 de noviembre de 2008
 Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.
Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.Por una parte, a finales del pasado mes de octubre se publicó en el sitio de descargas de jQuery, y apareció enlazado desde su propia web oficial, el archivo de anotaciones que permite el disfrute de la experiencia intellisense en todo su esplendor mientras utilizamos la librería desde Visual Studio 2008: información completa sobre los métodos que estamos usando, parámetros, valores de retorno, y autocompletado de escritura. Una gozada, vaya.
 Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.
Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.Por otra parte, sólo unos días después, Microsoft ha publicado el hotfix KB958502 para Visual Studio 2008 Service Pack 1 (y válido también para Visual Web Developer Express SP1) que hace que el entorno sea capaz de buscar automáticamente los archivos de documentación relativos a cada librería javascript que estemos utilizando, y tomar de ellos la información para activar intellisense. De hecho, por cada archivo javascript referenciado desde nuestro código con un nombre "xxx.js", el entorno buscará la documentación en el archivo "xxx-vsdocs.js"; si no la encuentra, probará con "xxx.debug.js", y si tampoco hay nada, dentro de la propia librería "xxx.js".
Por tanto, una vez instalado este parche, si estás utilizando jQuery directamente sobre una página .ASPX, algo muy habitual, basta con descargar el archivo de anotaciones e incluirlo en el directorio de scripts del proyecto para que la magia intellisense comience a funcionar en todas las páginas en las que exista una referencia hacia jQuery (un tag
<script src="...">), o que se basen en una página maestra que incluya dicha referencia.
Si estás editando un fichero javascript (.js) en Visual Studio y desde él quieres utilizar jQuery con intellisense, puedes utilizar un comentario con la etiqueta
Reference, que indica al entorno que puede tomar la documentación de los archivos indicados en la misma. Basta con encabezar el archivo .js así: /// <reference path="jquery-1.2.6-vsdoc.js">
El comentario, obviamente, no afecta a la ejecución, y sólo es interpretado por el IDE para buscar referencias a archivos de documentación.
Por último, como apunta Jeff King, Program Manager en el equipo de herramientas para la Web de Visual Studio, es conveniente aclarar que el objetivo de este parche no es únicamente dar soporte a jQuery; se trata de una solución general para facilitar la integración de documentación de librerías javascript en el entorno de desarrollo, y que seguro vamos a poder aprovechar en muchas otras ocasiones.
Publicado en: www.variablenotfound.com.
martes, 4 de noviembre de 2008
 El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
[...] Me parece muy interesante crear diccionarios utilizando tipos anónimos, pues simplifica de una forma considerable la cantidad de código que hay que escribir para conseguir llenar una estructura de este tipo. De hecho, estoy pensando en utilizar esta técnica en una librería que estoy desarrollando, pero no veo claro cómo transformar después ese objeto anónimo en el diccionario equivalente [...]
Verás que la idea es muy simple. Sólo necesitamos encontrar una fórmula que nos permita recorrer las propiedades del objeto, y por cada una de ellas, añadir la entrada correspondiente en el diccionario, especificando como clave el nombre de la propiedad y como valor el que tenga establecido la misma.
Una posibilidad muy sencilla es usar la clase
TypeDescriptor, cuyo método GetProperties() nos devuelve una colección con los descriptores de las propiedades de la instancia que le pasemos como parámetro. Iterando sobre este conjunto, podremos ir llenando el diccionario con los elementos que nos interese, tal que así, dado un objeto llamado obj: Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
Pero vamos a dar una vuelta de tuerca más. Partiendo del código anterior, es muy fácil crear un método de extensión sobre la clase
object, de forma que podamos convertir en un diccionario cualquier objeto de nuestras aplicaciones, con toda la potencia y comodidad que nos aporta esta técnica.El código sería:
public static class Extensions
{
public static Dictionary<string, object> ToDictionary(this object obj)
{
Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
return dicc;
}
}
De esta forma, dispondremos de una potente forma de "diccionarizar" nuestras instancias, sean del tipo que sean, por ejemplo:
var juan = new { nombre = "Juan", edad = 23 };
Dictionary<string, object> dicc = juan.ToDictionary();
Console.WriteLine(dicc["nombre"]); // Escribe "Juan"
var dicc2 = "hola".ToDictionary();
Console.WriteLine(dicc2["Length"]); // Escribe 4
Espero que te sea de ayuda, Leo. ¡Y gracias por participar en Variable Not Found!
Publicado en: www.variablenotfound.com.
martes, 28 de octubre de 2008
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.
lunes, 23 de junio de 2008
 La inclusión en el SP1 (Beta) de Visual Web Developer Express 2008 de soporte para librerías de clases y aplicaciones Web, abriendo el uso del framework MVC Preview 3 para los que estamos aprendiendo con esta herramienta, era sin duda una novedad sorprendente, pero no la única.
La inclusión en el SP1 (Beta) de Visual Web Developer Express 2008 de soporte para librerías de clases y aplicaciones Web, abriendo el uso del framework MVC Preview 3 para los que estamos aprendiendo con esta herramienta, era sin duda una novedad sorprendente, pero no la única. Joe Cartano comentaba hace unas semanas, en el blog oficial del equipo de Visual Web Developer , las nuevas mejoras de este IDE, y en especial las relativas al soporte para plantillas de terceros, y publicó de paso unas estupendas plantillas para la creación de tests unitarios basados en NUnit en aplicaciones ASP.NET MVC.
Para instalarlas, basta con descargar el archivo (con el enlace anterior), descomprimirlo sobre un directorio cualquiera y ejecutar el archivo .BAT correspondiente a la versión de Visual Studio que estemos utilizado, siempre con permisos de administrador. Si todo va bien y suponiendo además que tenemos NUnit instalado, al crear una nueva aplicación ASP.NET MVC en VWD Express aparecerá un cuadro de diálogo como el siguiente:
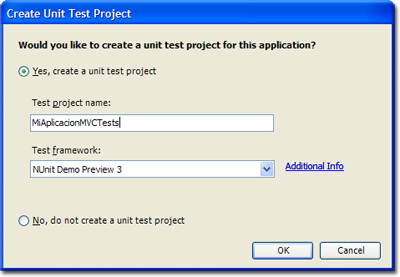
Esto va en la línea de lo comentado por ScottGu meses atrás, en sus primeros posts sobre el nuevo framework MVC, donde aseguraba que se podría utilizar cualquier framework de testing, citando algunos como NUnit y MBUnit. Y lo de permitir una cierta integración de estos frameworks ajenos a la casa en la versión Express es todo un detalle.
Si se acepta el diálogo, se creará dentro de la misma solución un proyecto de tipo librería que contendrá las referencias a ensamblados necesarios para su ejecución (NUnit, routing, Mvc, etc.) y con un par de métodos de prueba predefinidos. De esta forma, para comprobar el correcto funcionamiento de nuestras aplicaciones sólo tendremos que ejecutar los tests, aunque de momento, y a diferencia de las versiones superiores de Visual Studio 2008, tendrá que ser desde fuera del entorno, utilizando la consola de NUnit:

Publicado en: www.variablenotfound.com.
martes, 17 de junio de 2008

Cuando hace unas semanas ScottGu anunció la Preview 3 de ASP.NET MVC, quedé muy sorprendido de que al final no viniera con soporte para Visual Web Developer Express 2008, sobre todo teniendo en cuenta que un mes antes había adelantado este acontecimiento para los que estamos probando la plataforma MVC con esta herramienta.
Pero no, era una falsa alarma. Scott había olvidado comentarlo, y días más tarde rectificaba en un nuevo post en el que comunicaba que sí sería posible usar la Preview 3 desde la versión Express de Web Developer sin necesidad de usar plantillas específicas.
Desde entonces estaba deseando tener un ratillo para probarlo, y por fin ha llegado el momento.
En primer lugar, he de aclarar que, aunque pueda parecer lo contrario, no se trata de que el equipo de Microsoft haya introducido cambios en la plataforma MVC para hacerla compatible con la versión Express, sino al revés. Son los nuevos cambios introducidos en el IDE, y principalmente su recién estrenado soporte a proyectos de tipo Aplicación Web, los que hacen posible que funcione directamente sobre esta herramienta.
Y este es el motivo de que, antes que nada, sea necesario instalar el SP1 de .NET Framework 3.5 y de las herramientas Express (aún en Beta). Y si váis a hacerlo, mucho ojo, que todas las páginas donde aparece para descargar aparece llena de warnings; en otras palabras, no recomiendan su instalación en máquinas de verdad, sólo en entornos de prueba. Pero no os preocupéis, que para eso estoy yo ;-)
Después de un proceso algo lento y un par de reinicios del equipo, el Service Pack 1 Beta queda instalado sin problemas. Sólo falta descargar y montar la Preview 3 de ASP.NET MVC para que al ir a crear un nuevo proyecto desde Visual Web Developer aparezcan la plantilla MVC, entre otras novedades:

Y para probar, nada mejor que la aplicación de demostración sobre Northwind que preparó Phil Haack hace unas semanas. Salvo un ligero error de carga debido a que la versión Express no soporta la creación de proyectos de solución (no podremos probar los tests unitarios integrados en VS2008), todo funciona a la perfección.
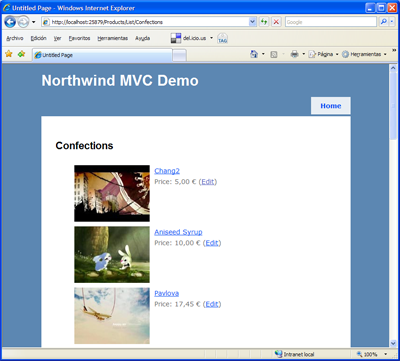
Sí señor. Ahora sí que podemos seguir jugando. :-)
Publicado en: www.variablenotfound.com.
sábado, 24 de mayo de 2008
 Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.
Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.Y aunque pueda parecer similar a FxCop, Microsoft Source Analysis for C# se centra en el análisis de código fuente y no en ensamblados, lo que hace que pueda afinar mucho más en las reglas de codificación.
Incluye sobre 200 buenas prácticas, cubriendo aspectos como:
- Layout (disposición) de elementos, instrucciones, expresiones y consultas
- Ubicación de llaves, paréntesis, corchetes, etc.
- Espaciado alrededor de palabras clave y operadores
- Espaciado entre líneas
- Ubicación de parámetros en llamadas y declaraciones de métodos
- Ordenación de elementos de una clase
- Formateo de documentación de elementos y archivos
- Nombrado de campos y variables
- Uso de tipos integrados
- Uso de modificadores de acceso
- Contenidos permitidos en archivos
- Texto de depuración

Tras su descarga e instalación, que puede realizarse desde esta dirección, la herramienta se integra en Visual Studio 2005 y 2008, aunque también puede utilizarse desde la línea de comandos o MSBuild.
Publicado en: www.variablenotfound.com.
domingo, 27 de abril de 2008
 Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.
Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.C# 3.0 nos trae otra sorpresa, también relacionada con el establecimiento de valores iniciales de elementos: los inicializadores de colecciones. Aunque esta característica también estaba prevista para VB.Net 9.0, al final fue desplazada a futuras versiones por problemas de tiempo.
Para inicializar una colección, hasta ahora era necesario en primer lugar crear la clase correspondiente para, a continuación, realizar sucesivas invocaciones al método
Add() con cada uno de los elementos a añadir: List<string> ls = new List<string>();
ls.Add("Uno");
ls.Add("Dos");
ls.Add("Tres");
C# 3.0 permite una alternativa mucho más elegante y rápida de codificar, simplemente se introducen los elementos a añadir a la colección entre llaves (como se hacía con los inicializadores de arrays o los nuevos inicializadores de objetos), separados por comas, como en el siguiente ejemplo:
List<string> ls =
new List<string>() { "Uno", "Dos", "Tres" };
Si desensamblamos el ejecutable resultante, podremos ver que es el compilador el que ha añadido por nosotros los
Add() de cada uno de los elementos después de instanciar la colección:
newobj instance void class
[mscorlib]System.Collections.Generic.List`1<string>::.ctor()
stloc.s '<>g__initLocal0'
ldloc.s '<>g__initLocal0'
ldstr "Uno"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
ldloc.s '<>g__initLocal0'
ldstr "Dos"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
ldloc.s '<>g__initLocal0'
ldstr "Tres"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
Uniendo esto ahora con los inicializadores de objetos que ya tratamos un post anterior, fijaos en la potencia del resultado:
List<Persona> lp = new List<Persona>
{
new Persona { Nombre="Juan", Edad=34 },
new Persona { Nombre="Luis", Edad=53 },
new Persona { Nombre="José", Edad=23 }
};
Efectivamente, cada elemento es una nueva instancia de la clase Persona, con las propiedades que nos interesan inicializadas de forma directa. De hacerlo con los métodos tradicionales, para conseguir el mismo resultado deberíamos utilizar muuuchas más líneas de código.
Otro ejemplo que demuestra aún más la potencia de esta característica:
var nums = new SortedList
{
{ 34, "Treinta y cuatro" },
{ 12, "Doce" },
{ 3, "Tres" }
};
foreach (var e in nums)
Console.WriteLine(e.Key + " " + e.Value);
En el código anterior podemos ver, primero, el uso de variables locales de tipo implícito, para ahorrarnos tener que escribir más de la cuenta. En segundo lugar, se muestra cómo se inicializa una colección cuyo método
Add() requiere dos parámetros. En el caso de un SortedList<TKey, TValue>, su método Add() requiere la clave de ordenación y el valor del elemento.(Obviamente, el resultado de la ejecución del código anterior será la lista ordenada por su valor numérico (Key))
En conclusión, se trata de otra de las innumerables ventajas que nos ofrece la nueva versión de C# destinadas a evitarnos pulsaciones innecesarias, y a la que seguro le daremos uso.
Publicado en: www.variablenotfound.com.
martes, 15 de abril de 2008
 Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".
Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".Recordemos que una parte de una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el compilador eliminará tanto la declaración del método como las llamadas que se hagan al mismo.
Sin embargo esta eliminación pueden causar efectos no deseados difíciles de detectar.
Veámoslo con un ejemplo. Supongamos una clase parcial como la siguiente, que representa a una variable de tipo entero que puede ser incrementada o decrementada a través de métodos:
public partial class Variable
{
partial void Log(string msg);
private int i = 0;
public void Inc()
{
i++;
Log("Incremento. I: " + i);
}
public void Dec()
{
Log("Decremento. I: " + (--i));
}
public int Value
{
get { return i; }
}
}
Creamos ahora un código que utiliza esta clase de forma muy simple: crea una variable, la incrementa dos veces, la decrementa una vez y muestra el resultado:
Variable v = new Variable();
v.Inc();
v.Inc();
v.Dec();
Console.WriteLine(v.Value);
Obviamente, tras la ejecución de este código la pantalla mostrará por consola un "1", ¿no? Claro, el resultado de realizar dos incrementos y un decremento sobre el cero.
Pues no necesariamente. De hecho, es imposible conocer, a la vista del código mostrado hasta ahora, cuál será el resultado mostrado por consola al finalizar la ejecución. Dependiendo de la existencia de la implementación del método parcial
Log(), declarado e invocado en la clase Variable anterior, puede ocurrir:- Si existe otra porción de la misma clase (otra
partial class Variable) donde se implemente el método, se ejecutará éste. El valor mostrado por consola, salvo que desde esta implementación se modificara el valor del campo privado, sería "1". - Si no existe una implementación del método
Log()en la clase, el compilador eliminará todas las llamadas al mismo. Pero si observáis, esto incluye el decremento del valor interno, que estaba en el interior de la llamada como un autodecremento:
Por tanto, en este caso, el compilador eliminará tanto la llamada aLog("Decremento. I: " + (--i));Log()como la operación que se realiza en el interior. Obviamente, el resultado de ejecución de la prueba anterior sería "2".
Lo mismo ocurriría si el resultado a mostrar fuera el valor de retorno de una llamada a otra función: esta no se ejecutaría, lo cual puede ser grave si en ella se realiza una operación importante, como por ejemplo:public function InicializaValores()
{
Log("Elementos reestablecidos: " + reseteaElementos() );
}
Por ejemplo, imaginad que el ejemplo anterior contiene una implementación de
Log(); la aplicación funcionaría correctamente. Sin embargo, si pasado un tiempo se decide eliminar esta implementación (por ejemplo, porque ya no es necesario registrar las operaciones realizadas), la operación de decremento (Dec()) dejaría de funcionar. Aunque, eso sí, no es nada que no se pueda solucionar con un buen juego de pruebas...
Publicado en: http://www.variablenotfound.com/.
domingo, 13 de abril de 2008
 Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.
Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.Estos métodos, declarados en el contexto de una clase parcial, permiten comunicar de forma segura los distintos fragmentos de dicha clase. De forma similar a los eventos, permiten que un código incluya una llamada a una función que puede (o no) haber sido implementada por un código cliente, aunque en este caso obligatoriamente la implementación se encontrará en uno de los fragmentos de la misma clase desde donde se realiza la llamada.
En la práctica significa que una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el código correspondiente a la llamada será eliminado en tiempo compilación para optimizar el resultado... ¡sí, eliminado!
Por ejemplo, el siguiente código muestra una declaración de un método parcial en el interior de una clase, y su utilización desde dentro de uno de sus métodos:
// C#
public partial class Ejemplo
{
// El método parcial se declara
// sin implementación...
partial void Log(string msg);
public void RealizarAlgo()
{
hacerAlgoComplejo();
Log("¡Ojo!"); // Usamos el método
// parcial declarado antes
}
[...] // Otros métodos y propiedades
}
' VB.NET
Partial Public Class Ejemplo
' El método parcial se declara, sin
' implementar nada en el cuerpo
Partial Private Sub Log(ByVal msg As String)
End Sub
Public Sub RealizarAlgo()
HacerAlgoComplejo()
Log("¡Ojo!") ' Usamos el método parcial
End Sub
[...] ' Otros métodos y propiedades
End Class
Y esta la parte realmente curiosa. Cuando el compilador detecta la invocación del método parcial
Log(), buscará en todos los fragmentos de la clase a ver si existe una implementación del mismo. Si no existe, eliminará del ensamblado resultante la llamada a dichos métodos, es decir, actuará como si éstas no existieran en el código fuente.En caso afirmativo, es decir, si existen implementaciones como las del siguiente ejemplo, todo se ejecutará conforme a lo previsto:
// C#
public partial class Ejemplo
{
partial void Log(string msg)
{
Console.WriteLine(msg);
}
}
' VB.Net
Partial Public Class Ejemplo
Private Sub Log(ByVal msg As String)
Console.WriteLine(msg)
End Sub
End Class
Antes comentaba que los métodos parciales son, en cierto sentido, similares a los eventos, pues conceptualmente permiten lo mismo: pasar el control a un código cliente en un momento dado, en el caso de que éste exista. De hecho, hay muchos desarrolladores que lo consideran como un sustituto ligero a los eventos, pues permite prácticamente lo mismo pero se implementan de forma más sencilla.
Existen, sin embargo, algunas diferencias entre ambos modelos, como:
- Los métodos parciales se implementan en la propia clase, mientras que los eventos pueden ser consumidos también desde cualquier otra
- El enlace, o la suscripción, a eventos es dinámica, se realiza en tiempo de ejecución, es necesario incluir código para ello; los métodos parciales, sin embargo, se vinculan en tiempo de compilación
- Los eventos permiten múltiples suscripciones, es decir, asociarles más de un código cliente
- Los eventos pueden presentar cualquier visibilidad (pública, privada...), mientras que los métodos parciales son obligatoriamente privados.
Por último, es conveniente citar algunas consideraciones sobre los métodos parciales:
- Deben ser siempre privados (ya lo había comentado antes)
- No deben devolver valores (en VB.Net serían
SUB, en C# serían de tipovoid) - Pueden ser estáticos (shared en VB)
- Pueden usar parámetros, acceder a los miembros privados de la clase... en definitiva, actuar como un método más de la misma
En resumen, los métodos parciales forman parte del conjunto de novedades de C# y VB.Net que no son absolutamente necesarias y que a veces pueden parecer incluso diabólicas, pues facilitan la dispersión de código y dificultan la legibilidad. Además, en breve publicaré un post comentando posibles efectos laterales a tener en cuenta cuando usemos los métodos parciales en nuestros desarrollos.
Sin embargo, es innegable que los métodos parciales nos facilitan enormemente la inclusión de código de usuario en el interior de clases generadas de forma automática. Por ejemplo, el diseñador visual del modelo de datos de LinqToSQL genera los
DataContext como clases parciales, en las que define un método parcial llamado OnCreated(). Si el usuario quiere incluir alguna inicialización personal al crear los DataContext, no tendrá que tocar el código generado de forma automática; simplemente creará otro fragmento de la clase parcial e implementará este método, de una forma mucho más natural y cómoda que si se tratara de un evento.Publicado en: http://www.variablenotfound.com/.
lunes, 3 de marzo de 2008
 Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.
Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.En esta ocasión vamos a centrarnos en los inicializadores de objetos, una nueva característica destinada, entre otras cosas, a ahorrarnos tiempo a la hora de establecer los valores iniciales de los objetos que creemos desde código.
Y es que, hasta ahora, podíamos utilizar dos patrones básicos de inicialización de propiedades al instanciar una clase:
- que fuera la clase la que realizara esta tarea, ofreciendo al usuario de la misma constructores con distintas sobrecargas cuyos parámetros corresponden con las propiedades a inicializar.
// Constructor de la clase Persona:
public Persona(string nombre, string apellidos, int edad, ...)
{
this.Nombre = nombre;
this.Apellidos = apellidos;
this.Edad = edad;
...
}
// Uso:
Persona p = new Persona("Juan", "López", 32, ...); - o bien dejar esta responsabilidad al usuario, permitiéndole el acceso directo a propiedades o campos del objeto creado.
// Uso:
Persona p = new Persona();
p.Nombre = "Juan";
p.Apellidos = "López";
p.Edad = 32;
...
Los inicializadores de objetos permiten, en C# y VB.Net, realizar esta tarea de forma más sencilla, indicando en la llamada al constructor el valor de las propiedades o campos que deseemos establecer:
// C#:
Persona p = new Persona { Nombre="Juan", Apellidos="López", Edad=32 };
' VB.NET:
Dim p = New Persona With {.Nombre="Luis", .Apellidos="López", .Edad=32 }
Los ejemplos anteriores son válidos para clases que admitan constructores sin parámetros, pero, ¿qué ocurre con los demás? Imaginando que el constructor de la clase
Persona recibe obligatoriamente dos parámetros, su nombre y apellidos, podríamos instanciar así:
// C#:
Persona p = new Persona ("Luis", "López") { Edad = 32 };
' VB.NET:
Dim p = New Persona ("Luis", "López") With { .Edad = 32 }
Aunque es obvio, es importante tener en cuenta que las inicializaciones (la porción de código entre llaves "{" y "}") se ejecutan después del constructor:
// C#:
Persona p = new Persona ("Juan", "Pérez") { Nombre="Luis" };
Console.WriteLine(p.Nombre); // Escribe "Luis"
' VB.NET:
Dim p = New Persona ("Juan", "Pérez") With { .Nombre="Luis" }
Console.WriteLine(p.Nombre); ' Escribe "Luis"
Y un último apunte: ¿cómo inicializaríamos propiedades de objetos que a su vez sean objetos que también queremos inicializar? Suponiendo que en nuestra clase
Persona hemos incluido una propiedad llamada Domicilio que de tipo Localizacion, podríamos inicializar el bloque completo así:
// C#:
// Se han cortado las líneas para facilitar la lectura
Persona p = new Persona()
{
Nombre = "Juan",
Apellidos = "López",
Edad = 55,
Domicilio = new Localizacion
{
Direccion = "Callejas, 34",
Localidad = "Sevilla",
Provincia = "Sevilla"
}
};
' VB.NET:
' Se han cortado las líneas para facilitar la lectura
Dim p = New Persona() With { _
.Nombre = "Juan", _
.Apellidos = "López", _
.Edad = 55, _
.Domicilio = New Localizacion With { _
.Direccion = "Callejas, 23", _
.Localidad = "Sevilla", _
.Provincia = "Sevilla" _
} _
}
En fin, que de nuevo tenemos ante nosotros una característica de estos lenguajes que resulta interesante por sí misma, aunque toda su potencia y utilidad podremos percibirla cuando profundicemos en otras novedades, como los tipos anónimos y Linq... aunque eso será otra historia.
Publicado en: http://www.variablenotfound.com/.
domingo, 24 de febrero de 2008
 Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático
Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático string.IsNullOrEmpty, sobre todo si podemos asegurar que no aparecerá el famoso bug del mismo (que al final no es para tanto, todo sea dicho).Los métodos de extensión nos brindan la posibilidad de hacer lo mismo pero de una forma más elegante e intuitiva, impensable hasta la llegada de C# 3.0: extendiendo la clase
string con un método que compruebe su contenido.La forma de conseguirlo es bien sencilla. Declaramos en una clase estática el método de extensión sobre el tipo
string:public static class MyExtensions
{
public static bool IsNullOrEmpty(this string s)
{
return s == null || s.Length == 0;
}
}Y listo, ya tenemos el nuevo método listo para ser utilizado:
string name = getCurrentUserName();
if (!name.IsNullOrEmpty())
...De todas formas, hay un par de reflexiones que considero interesante comentar.
En primer lugar, fijaos en el ejemplo anterior que aunque la variable
name contenga un nulo, se ejecutará la llamada a IsNullOrEmpty() sin provocar error, algo imposible si se tratara de un método de instancia. Obviamente, se debe a que en realidad se está enmascarando una llamada a un método estático al que le llegará como parámetro un null.Como consecuencia de lo anterior, y dado que no se puede distinguir a simple vista en una llamada a un método si éste es de instancia o de extensión, es posible que un desarrollador considerara esta invocación incorrecta. Esto forma parte de los inconvenientes de los métodos de extensión que ya cité en un post anterior.
En segundo lugar, visto lo visto cabría preguntarse, ¿por qué podemos extender una clase añadiéndole nuevos métodos pero no es posible incluir otro tipo de elementos, como eventos o propiedades? En el caso anterior podría quedar más fino que
IsNullOrEmpty fuera una propiedad de string, ¿no? Sin embargo, esto no es posible de momento. Según comentó ScottGu hace tiempo, se estaba considerando añadir la posibilidad de extender las clases también con nuevas propiedades. Supongo que el hecho de no haberla incluido en esta versión se deberá a que no era necesario para LINQ, la estrella de esta entrega... ¡y para dejar algo por hacer para C# 4.0, claro! ;-)
En cualquier caso, se trata principalmente de una cuestión de estética del código. Todo lo que conseguimos con las propiedades se puede realizar a base de métodos; de hecho, las propiedades no son sino interfaces más agradables a métodos getters y setters, al más puro estilo Java, subyacentes.
Por último, todo lo dicho es válido para VB.NET 9, salvo las obvias diferencias. El código equivalente al anterior sería:
Imports System.Runtime.CompilerServices
Module MyExtensions
<Extension()> _
Public Function IsNullOrEmtpy(ByVal s As String) As String
Return (s = Nothing) OrElse (s.Length = 0)
End Function
End Module
[...]
' Forma de invocar el método:
If s.IsNullOrEmtpy() Then
[...]
Publicado en: http://www.variablenotfound.com/.
domingo, 3 de febrero de 2008
 Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.
Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.Los, en inglés, extension methods, permiten añadir métodos a clases existentes sin necesidad de utilizar el mecanismo de la herencia. Aunque dicho así parezca ser una aberración y atente directamente contra una de las principales bases de la programación orientada a objetos, y de hecho están considerados por algunos como auténticos inventos diabólicos, la cosa tampoco es tan grave siempre que se mantenga cierto control y conocimiento de causa. Y es que, como muchas otras características aparecidas recientemente en estos lenguajes, no son sino una base sobre la que sustentar frameworks como Linq, y que de paso pueden ayudarnos a ser algo más productivos.
En realidad, y siendo prácticos, los métodos de extensión no aportan grandes novedades, casi nada que no pudiéramos hacer con la versión 1.0 del framework, simplemente nos facilitan nuevas vías sintácticamente más simples de hacerlo. Por ejemplo, seguro que alguna vez habéis querido dotar una clase X con nuevas funcionalidades y no habéis podido heredar de ella por estar sellada (sealed en C# o NotInheritable en VB)... ¿Qué es lo que habéis hecho? Pues probablemente crear en otra clase un método estático con un parámetro de tipo X que realizaba las funciones deseadas en alguna clase de utilidad. ¿Lo vemos mejor con un ejemplo?
Supongamos que deseamos añadir a la clase
string un método que nos retorne la cadena almacenada entre un tag (X)HTML strong. Como String no es heredable, la solución idónea sería crear una clase de utilidad donde codificar este métodos y otros similares que pudieran hacernos falta:public static class HtmlStringUtils
{
public static function string Negrita(string s)
{
return "<strong>" + s + "</strong>";
}
public static function string Cursiva(string s) {...}
public static function string Superindice(string s) {...}
[...]
}Su uso tendría que pasar necesariamente por la referencia a la clase estática y el paso del parámetro a convertir, así:
HtmlStringUtils.Negrita(currentUser.Name)
Esta técnica es correcta, aunque tiene un problema de visibilidad del código. Ningún desarrollador podría intuir la existencia de la clase HtmlStringUtils de forma natural; tampoco sería posible que un IDE sofisticado nos sugiriese el método
Negrita() como una posibilidad a la hora de manipular una cadena, como hace Intellisense con los métodos de instancia habituales.Los extension methods vienen a cubrir estos inconvenientes, creando una vía de alternativa para codificar el ejemplo anterior, facilitando después su uso de una forma más sencilla. Ojo al parámetro que recibe la función, que incluye la palabra reservada "this" por delante del mismo:
public static class HtmlStringUtils
{
public static function string Negrita(this string s)
{
return "<strong>" + s + "</strong>";
}
[...]
}De esta forma, incluyendo como primer parámetro el tipo precedido de la palabra "this", este método estático se convertirá automáticamente en un método de extensión de dicho tipo, y pueda ser utilizado como si fuera un método de instancia más del mismo:

return currentUser.Name.Negrita();
Y, por supuesto, tendríamos toda la potencia de nuestro querido Intellisense (en VS2008) a nuestra disposición.
Lo único a tener en cuenta es el primer parámetro, que debe ser del tipo a extender. En éste se introducirá la instancia de dicho tipo de forma automática, y el resto de parámetros serán enviados al método en el mismo orden, es decir:
// Método de extensión sobre un string
public static string Colorea(this string s, Color color)
{
[...]
}
// Forma de invocarlo:
string str = User.Name.Colorea(Color.Red);
Vemos que la utilización es mucho más natural y, aunque parezca que estamos rompiendo todas las bases del paradigma de la orientación a objetos, no es más que un atajo para incrementar productividad y facilitar la visión del código, además de servir como apoyo a tecnologías novedosas como Linq.
Sin embargo, no todo son ventajas. Es interesante añadir posibles problemas que pueden causar la utilización descontrolada de esta nueva característica.
En primer lugar, no olvidemos que a menos que Visual Studio (o cualquier entorno similar) nos eche una mano, al leer un código fuente será imposible saber si una llamada que estamos observando es un método de instancia o se trata de uno de extensión. Aunque no deja de ser una pequeña molestia, puede provocar una inquietante sensación de desconocimiento y dispersión del código fuente.
Otro motivo de dolor de cabeza puede ser el versionado de los métodos de extensión. Éstos pueden tener una vida completamente independiente de la clase a la que afectan, lo que puede provocar efectos no deseados ante la evolución de ésta.
Especialmente peligrosos pueden ser los relacionados con los nombres de métodos de extensión. Por ejemplo, la inclusión de un método en una clase podría hacer (de hecho, haría) que un método de extensión asociado a la misma y con un nombre similar no se ejecutara, pues el miembro de la instancia siempre tendría preferencia sobre éste. El problema es que el compilador no podría avisar de ningún problema, y es en ejecución donde podrían aparecer las incompatibilidades o diferencia de funcionalidades entre ambos métodos.
Veamos un ejemplo simple, siguiendo con el caso expuesto más atrás, ¿qué ocurriría si una vez en uso el método de extensión
Negrita() Microsoft decidiera añadir al tipo string un método de instancia llamado Negrita() en una versión posterior del framework, que retornara un tag HTML <b>? Pues que el compilador no sería capaz de detectar nada raro, por lo que no nos daríamos cuenta del cambio, y nuestra aplicación dejaría de validar XHTML.De la misma forma, también pueden causar problemas difíciles de detectar la especificación de namespaces incorrectos. Nada impide que un mismo método de extensión sea definido en dos espacios de nombres diferentes, lo cual hace que el namespace indicado en el using sea el que esté decidiendo el extension method a ejecutar, lo cual no resulta nada natural ni intuitivo en estos casos.
En conclusión: la recomendación es usar métodos de instancia, los habituales, siempre que se pueda, recurriendo a la herencia. Y para cuando no, contaremos con este valioso aliado.
Publicado en: http://www.variablenotfound.com/.
miércoles, 9 de enero de 2008
 Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil.
Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil. Una de ellas es la posibilidad de declarar variables sin necesidad de indicar de forma explícita su tipo, cediendo al compilador la tarea de determinar cuál es en función del tipo de dato obtenido al evaluar su expresión de inicialización. El tipado implícito o inferencia de tipos también existe en C# y ya escribí sobre ello hace unos días, pero me parecía interesante también publicar la visión para el programador Visual Basic y las particularidades que presenta.
Gracias a esta nueva característica, en lugar de escribir:
Dim x As XmlDateTimeSerializationMode = XmlDateTimeSerializationMode.Local
Dim i As Integer = 1
Dim d As Double = 1.8 Dim x = XmlDateTimeSerializationMode.Local
Dim i = 1
Dim d = 1.8El resultado en ambos casos será idéntico, ganando en comodidad y eficiencia a la hora de la codificación y sin sacrificar los beneficios propios del tipado fuerte.
Hay un detalle importante que los veteranos habrán observado: Visual Basic ya permitía (y de hecho permite) la declaración de variables sin especificar el tipo, de la forma
Dim i = 1 (con Option Strict Off), por lo que podría parecer que el tipado implícito no sería necesario. Sin embargo, en este caso los compiladores asumían que la variable era de tipo Object, por lo que nos veíamos obligados a realizar castings o conversiones en tiempo de ejecución, penalizando el rendimiento y aumentando el riesgo de aparición de errores imposibles de detectar en compilación. Tampoco tiene nada que ver con tipados dinámicos (como los presentes en javascript), o con el famoso tipo Variant que estaba presente en Visual Basic 6; el tipo asignado a la variable es fijo e inamovible, como si lo hubiésemos declarado explícitamente.En Visual Basic 9, siempre que no se desactive esta característica incluyendo la directiva
Option Infer Off en el código, el tipo de la variable será fijado justo en el momento de su declaración, deduciéndolo a partir del tipo devuelto por la expresión de inicialización. Por este motivo, la declaración y la inicialización deberán hacerse en el mismo momento:
Dim i = 1 ' La variable "i" es Integer desde este momento
Dim j ' La variable "j" es Object, como siempre,
j = 1 ' ... si Option Scrict está en Off.
' En caso contrario aparecerá un error de compilación.
El tipado implícito puede ser asimismo utilizado en las variables de control de bucles For o For Each, haciendo su escritura mucho más cómoda:
Dim suma = 0
For i = 1 To 10 ' i se está declarando ahí mismo como Integer,
suma += i ' no existía con anterioridad
Next
Dim str = "abcdefg"
For Each ch In str ' ch se declara automáticamente como char,
Console.Write(ch) ' que es el tipo de los elementos de "str"
Next
Y también puede resultar bastante útil a la hora de obtener objetos de tipos anónimos, es decir, aquellos cuya clase se define en el mismo momento de su instanciación, como en el siguiente ejemplo:
Dim point = New With {.X = 1, .Y = 5}
point.X += 1
point.Y += 1
Por último, es interesante comentar que, a diferencia de C#, Visual Basic permite declarar en la misma línea distintas variables de tipo implícito, por lo que es posible escribir
Dim k=1, j=4.8, str="Hola" sin temor a un error en compilación, asignándose a cada una de ellas el tipo apropiado en función de su inicialización (en el ejemplo, Integer, Double y String respectivamente).Coinciden, sin embargo, en que en ambos lenguajes esta forma de declaración de variables se aplica exclusivamente a las locales, es decir, aquellas cuyo ámbito es un método, función o bloque de código. No pueden ser propiedades ni variables de instancia; en el siguiente ejemplo, x será declarada de forma implícita como Object, mientras que el tipo de la variable y será inferido como Integer:
Public Class Class1
Dim x = 2 ' Es una variable de instancia
Public Sub New()
Dim y = 2 ' Es una variable local
End Sub
End ClassEn resumen, se trata de una característica muy útil que, además de permitirnos programar más rápidamente al ahorrarnos teclear los tipos de las variables locales, actúa como soporte de nuevas características del lenguaje y la plataforma .NET, como el interesantísimo Linq.
Es conveniente, sin embargo, utilizar esta característica con cordura y siendo siempre conscientes de que su uso puede dar lugar a un código menos legible y generar errores difíciles de depurar. De hecho, Microsoft recomienda usarlas "sólo cuando sea conveniente".
Publicado en: Variable Not Found.
lunes, 10 de diciembre de 2007
 Hasta la versión 3.0 de C#, la declaración de una variable se debía realizar indicando su tipo de datos antes del identificador elegido para la misma. También era muy frecuente definir en ese mismo momento su valor inicial, siguiendo un patrón similar al siguiente:
Hasta la versión 3.0 de C#, la declaración de una variable se debía realizar indicando su tipo de datos antes del identificador elegido para la misma. También era muy frecuente definir en ese mismo momento su valor inicial, siguiendo un patrón similar al siguiente: string s = "cadena";Las variables locales implícitamente tipadas permiten obviar en su declaración el tipo que tendrán, dejando al compilador la tarea de averiguar cuál será en función de las variables o constantes que se usen al inicializarlo. Por tanto, será posible escribir código como:
var x = XmlDateTimeSerializationMode.Local;
XmlDateTimeSerializationMode x = XmlDateTimeSerializationMode.Local;Creo que no hace falta decir cuál de ellas es más cómoda a la hora de programar, ¿no? Simplemente hemos indicado con la palabra var que preferimos que sea el compilador el que haga el trabajo sucio.
Otro contexto donde este tipo de variables pueden facilitarnos la vida de forma frecuente es en los bucles for, foreach y bloques using:
// Un ejemplo de bucle...
var chars = "Saludicos".ToCharArray();
foreach (var ch in chars)
{
Console.Write(ch); // ch es char
}
// Y ahora un bloque using...
using (var ctx = new AppContext())
{
// usamos ctx, que es de tipo AppContext
}
También es importante la existencia de esta nueva forma de declaración para posibilitar la creación de objetos de tipo anónimo, es decir, aquellos cuya especificación de clase se crea en el mismo momento de su definición. Por tanto, una declaración como la siguiente será válida:
var x = new { Nombre = "Juan", Edad = 23 };
class __Anonymous1
{
private string nombre ;
private int edad ;
public string Nombre { get { return nombre ; } }
public int Edad { get { return edad ; } }
public __Anonymous1(string nombre, int edad)
{
this.nombre = nombre;
this.edad = edad;
}
}
...
__Anonymous1 x = new __Anonymous1("Juan", 23);
Existen ciertas reglas de obligado cumplimiento para usar variables locales implícitamente tipadas:
- La declaración debe incluir un valor de inicialización. En otras palabras, no será posible usar en una línea
var i;, puesto que el compilador no podría inferir el tipo en este momento. - El valor de inicialización debe ser una expresión evaluable como clase en tiempo de compilación. Expresamente prohibido el valor null, es decir, nada de
var n = null;, puesto que el compilador no sabría de qué tipo se trata; eso sí, si fuera necesario, podría forzarse un castingvar str = null as string;. - La declaración no puede incluir más de una variable. Una línea como
var i = 1, s = "hola";generará un error en compilación. - El inicializador no puede referirse a la propia variable declarada, obviamente.
- Sólo pueden utilizarse como variables locales en bloques de código, en bucles for y foreach y como recurso de un bloque using.
Por último, me gustaría añadir un par de detalles que considero interesantes.
 Primero, el hecho de utilizar la palabra "var" y no indicar de forma explícita el tipo puede hacernos pensar que estamos utilizando tipado dinámico en tiempo de ejecución, como lo hacemos con Javascript, sin embargo esto no es así. Como he comentado anteriormente, el compilador toma el tipo del lado derecho de la asignación de inicialización, por lo que si la variable no es inicializada se produce un error de compilación:
Primero, el hecho de utilizar la palabra "var" y no indicar de forma explícita el tipo puede hacernos pensar que estamos utilizando tipado dinámico en tiempo de ejecución, como lo hacemos con Javascript, sin embargo esto no es así. Como he comentado anteriormente, el compilador toma el tipo del lado derecho de la asignación de inicialización, por lo que si la variable no es inicializada se produce un error de compilación:Implicitly-typed local variables must be initializedPor ello, un entorno como Visual Studio sabe en todo momento el tipo exacto de que se trata, y nos puede ofrecer las ayudas en la codificación, detección de errores sintáticos e intellisense, como se puede observar en la imagen.
(Las variables locales implícitamente tipadas deben ser inicializadas)
Segundo, y muy interesante. Como ya comenté en su momento, la nueva versión de Visual Studio permite la generación de ensamblados para versiones anteriores de la plataforma, es decir, que es posible escribir código C# 3.0 y generar un ensamblado para el framework 2.0. Esto, a efectos prácticos, implica que una vez demos el salto definitivo a VS2008 podremos usar las variables locales de tipo implícito, así como otras novedades del lenguaje, incluso en aplicaciones diseñadas para .NET 2.0.

Publicado en: Variable Not Found.
martes, 6 de noviembre de 2007
 Días atrás, Daniel Moth, desarrollador de Microsoft, publicaba un interesante post comentando 10 puntos importantes a saber sobre el nuevo Visual Studio 2008 y .NET framework 3.5 y la verdad es que no tienen desperdicio.
Días atrás, Daniel Moth, desarrollador de Microsoft, publicaba un interesante post comentando 10 puntos importantes a saber sobre el nuevo Visual Studio 2008 y .NET framework 3.5 y la verdad es que no tienen desperdicio.1. Lanzamiento
Visual Studio 2008 y .NET framework 3.5 serán lanzados oficialmente juntos el próximo febrero. Sin embargo, estará disponible para desarrolladores a finales de noviembre de 2007.
Afortunadamente, estarán disponibles las versiones Express de C#, VB, C++ y Web, así como las Profesionales (¡con soporte de testeos unitarios!), Estándar y ediciones de equipos de desarrollo. La novedad será Visual Studio 2008 Shell, de carácter gratuito, que permitirá crear lenguajes y herramientas de desarrollo más verticalizadas.
Daniel comenta también que bajo Windows Vista, VS2008 será espectacular, e incluirá mejoras para la depuración de múltiples hilos. Ya no hay excusa para quedarnos con WXP ;-P
2. Compatibilidad hacia atrás
.NET framework 3.5 continúa la línea iniciada por Fx3.0 en cuanto al mantenimiento del CLR. Por tanto, y dado que lo único que hace es añadir ensamblados a las librerías presentes con las versiones 2.0 y 3.0 del framework, las aplicaciones actuales no se verán afectadas. Eso sí, necesitará los Service Packs 1 de ambas plataformas.
3. Generación multiplataforma
Visual Studio 2008 incluye la capacidad de crear proyectos para múltiples plataformas .NET, es decir, la 2.0, 3.0 y 3.5, desde el mismo entorno. Por tanto, no será necesario tener VS2005 instalado para generar ensamblados para .NET 2.0.
4. Multitud de novedades en C# 3.0 y VB9
Propiedades automáticas, delegados "relajados", inicializadores de objetos, inferencia de tipos, tipos anónimos, métodos de extensión, funciones lambda y métodos parciales, entre otros.
Pero no sólo eso... dado el punto 3 (generación multiplataforma), podremos usar estas nuevas características de nuestros lenguajes favoritos y generar para .NET 2.0.
5. LINQ
Se trata de una de las grandes revoluciones que nos aportará este nuevo conjunto de herramientas. Language INtegrated Query es un nuevo método de acceso a datos totalmente integrado en nuestro lenguaje habitual y de una forma muy independiente de la fuente de donde provengan (colecciones, XML, motores de bases de datos, etc.).
6. Novedades para ASP.NET
Visual Studio, así como el nuevo framework, ya incluirán ASP.NET AJAX de serie, así como 3 nuevos controles (ListView, DataPager y LinqDataSource). Además, el IDE ha sido muy mejorado e incluye soporte para intellisense y depuración de Javascripts, ¡también para ASP.NET 2.0!, y un nuevo diseñador que permite anidar páginas maestras.
7. Para el desarrollo en cliente
VS2008 incluirá nuevas plantillas de proyectos, así como un diseñador para WPF integrado con soporte para la comunicación WPF-WinForms. También se ha añadido el soporte para Firefox de la tecnología ClickOnce y XBAP (XAML Browser Applications).
8. Para el desarrollador de Office
Se ofrece soporte total para la personalizaciones (customisations) de Office 2007, así como para las plantillas de Office 2003.
9. Para desarrollo en servidor
Se han incluido nuevas plantillas para WCF y WF, y se han introducido mejoras interesantes en el primero, como el modelo de programación HTTP (sin SOAP) o serialización JSON.
10. Para el desarrollo en dispositivos móviles
Hay decenas de nuevas características, como el soporte para las versiones compactas de LINQ y WPF, o, a nivel de IDE, Unit Testing for Devices.
11. (punto extra) Código del framework
Pues sí, como ya es sabido, podremos depurar nuestras aplicaciones siguiendo el rastro por el interior de las clases y métodos del framework
Más información en la fuente: The Moth.












