
Joe Cartano, perteneciente al Visual Web Development Team de Microsoft, ha publicado en el blog oficial (Visual Web Developer Team Blog) un post anunciando que ha actualizado la plantilla que permite crear directamente proyectos ASP.NET MVC con tests unitarios NUnit.
Así, una vez instalado, al crear un proyecto de tipo ASP.NET MVC nos aparecerá un cuadro de diálogo como el siguiente, en el que se nos brindará la oportunidad de crear en la solución un proyecto de pruebas unitarias utilizando NUnit:

Para los poseedores de algunas de las versiones profesionales de Visual Studio 2008, esta ventana no es nueva, puesto que por defecto ya se incluyen los proyectos de tests propios de Microsoft, pero sí lo es para la versión express del IDE, que no incluye el framework de pruebas y en el que había que crear el proyecto a mano.
El proyecto, que se crea automáticamente, realiza 27 tests sobre la plantilla original de proyectos ASP.NET MVC, y pueden servir como base para seguir creando nuestro propio conjunto de pruebas:

La plantilla se instala descargando el archivo .zip cuyo enlace encontraréis en el post original y ejecutando, si es necesario con un usuario con privilegios de administrador, el script installNUnit.cmd disponible en el raíz del directorio donde lo hayáis descomprimido.
Para que todo vaya bien, debéis contar con NUnit previamente instalado en vuestro equipo. Pero ojo, las plantillas están preparadas para la versión 2.4.8.0 y la versión actual es la 2.5.0.9122, por lo que puede que no os funcionen bien si estáis a la última.
En este caso, es necesario tocar a mano los archivos de plantillas. Podéis seguir estos pasos:
- Descargad el archivo de plantillas desde el blog del Visual Web Developer Team.
- Descomprimidlo sobre cualquier carpeta.
- En los subdirectorios CSharp y Visual Basic encontraréis un archivo llamado
MvcApplication.NUnit.Tests.zip. Son las plantillas para cada uno de esos lenguajes. - El interior de dicho zip está el archivo de proyecto (
MvcApplication.NUnit.Test.vbprojen el caso de Visual Basic,MvcApplication.NUnit.Test.csprojen C#). Descomprimid sólo estos archivos y buscar en ambos la cadena “2.4.8.0” y sustituirla por la versión de NUnit que tengáis instalada (en mi caso, “2.5.0.9122”). Al acabar, actualizad de nuevo el .zip con el archivo que acabáis de editar. - Ejecutad el script de instalación
installNUnit.cmd.
Publicado en: Variable not found.
Existen numerosas aplicaciones que permiten analizar nuestros desarrollos con el objetivo final de incrementar la calidad de los mismos. FxCop, por ejemplo, es capaz de analizar los ensamblados y avisarnos cuando se encuentra con incumplimientos de las pautas de diseño para desarrolladores de librerías para .Net Framework (Design Guidelines for Class Library Developers). También hace tiempo comenté por aquí la disponibilidad de Microsoft Source Analysis for C#, una herramienta que se centra en el código fuente y el cumplimiento de reglas de codificación.
Ahora, gracias al ofrecimiento de Patrick Smacchia, lead developer del producto, he podido probar NDepend, una herramienta de análisis de código de la que había oído hablar y que va mucho más allá que las citadas anteriormente.
La principal misión de NDepend es ayudarnos a incrementar la calidad de nuestros sistemas desarrollados con .NET mediante el análisis de sus ensamblados y código fuente desde distintas perspectivas, como la complejidad de sus módulos, el tamaño de los mismos, las interdependencias entre ellos, etc. Es decir, a diferencia de otros analizadores, su objetivo no es avisarnos de aspectos como la utilización de convenciones de codificación (aunque también puede hacerlo), o el uso de buenas prácticas de diseño, sino ayudarnos a determinar, por ejemplo, cuándo ponemos en peligro la mantenibilidad y evolución de un sistema debido a la complejidad o al fuerte acoplamiento de algunos de sus componentes, por citar sólo algunos criterios.
El entorno gráfico
VisualNDepend es el entorno gráfico de la herramienta, y nos ofrece un entorno de trabajo muy potente e intuitivo, aunque durante los primeros minutos pueda resultar algo complejo debido a la cantidad de información mostrada.
Iniciar el análisis de un sistema es muy sencillo; una vez seleccionado el ensamblado, conjunto de ensamblados o proyecto a estudiar, el sistema realiza el análisis, del cual se obtiene un informe bastante completo, basado en web, sobre el mismo (podéis ver un ejemplo de informe en la página del producto). En él se recogen:
- métricas de la aplicación, entre las que encontramos el número de líneas de código, comentarios, número de clases, métodos, etc., así como datos estadísticos relativos a la complejidad, extensión y estructura del código.
- métricas por ensamblado, donde se refleja, por cada uno de los ensamblados que componen la solución, datos sobre su tamaño, grados de cohesión, acoplamiento, y otros aspectos relativos a su complejidad e interdependencia.
 vista de estructura (captura de la derecha) que muestra la distribución de componentes, la granularidad y su complejidad relativa según el tamaño de los bloques visualizados.
vista de estructura (captura de la derecha) que muestra la distribución de componentes, la granularidad y su complejidad relativa según el tamaño de los bloques visualizados. - diagrama de abstracción e inestabilidad, que posiciona cada ensamblado en función del número de clases abstractas e interfaces que presenta y su dependencia del resto de elementos.
- relación entre ensamblados, que detalla las interdependencias entre ensamblados del proyecto, los posibles ciclos, así como un posible orden de generación.
- consultas y restricciones CQL, que realiza una serie de consultas predefinidas sobre los ensamblados y el código que nos ayuda a detectar una infinidad de problemas en nuestros desarrollos, desde aspectos relativamente simples como el exceso de métodos en clases o el incumplimiento de ciertas convenciones de nombrado, hasta problemas en la cobertura de los tests generados con NCover o Visual Studio Team System.
 vista de estructura (captura de la derecha) que muestra la distribución de componentes, la granularidad y su complejidad relativa según el tamaño de los bloques visualizados.
vista de estructura (captura de la derecha) que muestra la distribución de componentes, la granularidad y su complejidad relativa según el tamaño de los bloques visualizados. Pero lo mejor del entorno gráfico no es poder generar un análisis en formato web para poder consultarlo más adelante, de hecho esto puede conseguir también con la aplicación de consola que incluye NDepend. Lo mejor son las fantásticas herramientas interactivas que nos permiten navegar a través de nuestras aplicaciones, cambiar de vista, ampliar información sobre cualquier elemento, y realizar consultas en tiempo real, siempre ofreciendo unos resultados muy claros y visuales, como:

- diagrama de dependencias entre todo tipo de elementos, como clases, espacios de nombres, o ensamblados. Resulta muy útil, además, configurar el tamaño de los bloques, el grosor del borde y el de las flechas de unión para que sean proporcionales a la complejidad, tamaño y una larga lista de criterios.
 matriz de dependencias, que muestra de forma visual las relaciones de utilización entre espacios de nombres, tipos, métodos o propiedades, con posibilidad de ir ampliando información.
matriz de dependencias, que muestra de forma visual las relaciones de utilización entre espacios de nombres, tipos, métodos o propiedades, con posibilidad de ir ampliando información. - comparación entre ensamblados, mostrándonos los cambios producidos entre, por ejemplo, dos versiones de una misma librería o aplicación.
- navegación avanzada por el código a través del uso del menú contextual que facilita la rápida localización de referencias, directas e indirectas, hacia y desde un método, propiedad o tipo existente.
- enlace con Reflector, una herramienta indispensable, con la que se integra perfectamente gracias a su plugin.
 matriz de dependencias, que muestra de forma visual las relaciones de utilización entre espacios de nombres, tipos, métodos o propiedades, con posibilidad de ir ampliando información.
matriz de dependencias, que muestra de forma visual las relaciones de utilización entre espacios de nombres, tipos, métodos o propiedades, con posibilidad de ir ampliando información.
CQL (Code Query Language)
Sin duda, una de las características más interesante que tiene NDepend es el soporte del lenguaje de consulta CQL (Code Query Language), que nos ofrece la posibilidad de tratar nuestro código y ensamblados como si fuesen una gigantesca base de datos sobre la que podemos realizar consultas de forma muy natural. Las posibilidades que esto ofrece son tan amplias que prácticamente todas las funcionalidades de la aplicación están basadas en órdenes CQL prediseñadas que acompañan al producto, aunque podemos crear todas las consultas personalizadas que necesitemos, como por ejemplo:
/* Obtiene los métodos que escriben una propiedad */
SELECT METHODS WHERE IsDirectlyWritingField "Model.Cliente.Nombre"
/* Obtiene métodos que acceden incorrectamente a los
datos desde la capa de interfaz
*/
SELECT METHODS FROM NAMESPACES "Interfaz" WHERE IsDirectlyUsing "MySql.Data"
/* Obtiene los 10 métodos con más líneas de código */
SELECT TOP 10 METHODS ORDER BY NbLinesOfCode DESC
/* Obtiene los métodos considerados "peligrosos" según su complejidad ciclomática */
SELECT METHODS WHERE CyclomaticComplexity > 20

WARN IF Count > 0 IN SELECT METHODS WHERE NbParameters > 10
Estas consultas pueden ser añadidas (en la versión Pro) e integradas en los análisis, así como modificar las existentes, de forma que el producto puede ser personalizado a nuestras convenciones o necesidades específicas.
Otra posibilidad es incluir dentro del código de un ensamblado las restricciones que deseamos que se cumplan, expresándolas en lenguaje CQL embebido en un atributo de tipo CQLConstraint aplicado a sus elementos:

Afortunadamente existe mucha información disponible en la web sobre el lenguaje CQL, y consultas que nos muestran cómo sacarle el máximo partido.
Instalación e integraciones
NDepend se distribuye en formato .zip, y que puede ejecutarse directamente una vez descomprimido el contenido sobre una carpeta. La licencia, una vez obtenida, es un archivo XML firmado digitalmente que debemos colocar en el directorio de la aplicación, y listo.

Ya en ejecución, desde el menú “options” es posible configurarlo para que se integre con Visual Studio 2005, 2008 y como he comentado anteriormente, con el magnífico Reflector, con el que hace una excelente pareja.
Asimismo, es posible utilizarlo en sistemas como MSBuild y NAnt, facilitando así su uso en entornos de integración continua y montaje automatizado, para los que ofrece librerías
Finalmente, he de aclarar que NDepend es una aplicación comercial, aunque dispone de una versión limitada gratuita utilizable por universidades, desarrolladores open source e incluso, durante un tiempo determinado, de prueba en proyectos comerciales.
En cualquier caso, no dudéis en probarlo: os dará un control sobre vuestro código difícil de conseguir con otras herramientas.
Publicado en: www.variablenotfound.com
 Al escribir el post "Métodos genéricos en C#", estuve pensando en tratar este tema también en VB.NET de forma simultánea, pero al final preferí limitarme a C# para no hacer la entrada más extensa de lo que ya iba a resultar de por sí.
Al escribir el post "Métodos genéricos en C#", estuve pensando en tratar este tema también en VB.NET de forma simultánea, pero al final preferí limitarme a C# para no hacer la entrada más extensa de lo que ya iba a resultar de por sí.Esto, unido a un comentario de Julio sobre el propio post en el que preguntaba si existía algo parecido en Visual Basic .NET, ha hecho que reedite el mismo, pero centrándome esta vez en dicho lenguaje.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores Integer y retorna un valor del mismo tipo: Function Maximo(ByVal uno As Integer, ByVal otro As Integer) _
As Integer
If uno > otro Then Return uno
Return otro
End FunctionHasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
Function Maximo(ByVal uno As Integer, ByVal otro As Integer) _
As Integer
' ...
End Function
Function Maximo(ByVal uno As Long, ByVal otro As Long) _
As Long
' ...
End Function
Function Maximo(ByVal uno As Decimal, ByVal otro As Decimal) _
As Decimal
' ...
End Function
' Y así hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
Object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos Object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: Function Maximo(ByVal uno As IComparable, ByVal otro As Object) As Object
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionPero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
Object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un String y un Integer, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: Function Maximo(Of T As IComparable) _
(ByVal uno As T, ByVal otro As T) As T
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionEn el código anterior, podemos distinguir una porción de código que aparece resaltada justo después del nombre del método, y antes de comenzar a definir sus parámetros. Es la forma de indicar que
Maximo es un método genérico y operará sobre un tipo cualquiera al que llamaremos T, y mediante una restricción estamos indicando que deberá implementar obligatoriamenter el interfaz IComparable (más adelante trataremos esto en profundidad).A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
Integer (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo. Observad que la palabra clave
Of sólo se indica al principio: Function MiMetodo(Of T1, T2, TResult) _
(ByVal par1 As T1, ByVal par2 As T2) As TResult
Y una aclaración antes de continuar: lo de usar la letra
T para identificar el tipo es pura convención, podríamos llamarlo de cualquier forma (por ejemplo Maximo(Of MiTipo)(ByVal uno as MiTipo, ByVal otro as MiTipo) As MiTipo), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genérico: Function Maximo(Of T As IComparable) _
(ByVal uno As T, ByVal otro As T) As T
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionAntes había comentado que en este caso estabamos creando un método que podría actuar sobre cualquier tipo, aunque mediante una restricción forzábamos a que éste implementara, obligatoriamente, el interfaz
IComparable, lo que nos permitiría realizar la operación de comparación que necesitamos.Obviamente, las restricciones no son obligatorias; de hecho, sólo debemos utilizarlas cuando necesitemos limitar de alguna forma los tipos permitidos como parámetros genéricos, como en el ejemplo anterior. Está permitida la utilización de las siguientes reglas:
As Structure, indica que el argumento debe ser un tipo valor.As Class, indica que T debe ser un tipo referencia.As New, fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.As nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.As nombredeinterfaz, el argumento deberá implementar el interfaz indicado.As nombredetipogenérico, indica que el argumento al que se aplica debe ser igual o heredar del tipo, también argumento del método, indicado por nombredetipogenérico (observad en el siguiente ejemplo el parámetro T2).
Function MiMetodo(Of T1 As {Class, IEnumerable}, _
T2 As {T1, New}, _
TResult As New) _
(ByVal par1 As T1, ByVal par2 As T2) As TResult
' ... Cuerpo del método
End Function
Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: Dim mazinger As String = Maximo(Of String)("Mazinger", "Afrodita")
Dim i99 As Integer = Maximo(Of Integer)(2, 99)
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
Dim mazinger As String = Maximo("Mazinger", "Afrodita")
Dim i99 As Integer = Maximo(2, 99)
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
String, puede llegar a la conclusión de que el método tiene una signatura que coincide con la definición del genérico, utilizando String como tipo parametrizado.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List(Of T)) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: Function CreaLista(Of T)(ByVal ParamArray pars() As T) As List(Of T)
Dim list As New List(Of T)
For Each elem As T In pars
list.Add(elem)
Next
Return list
End Function
' ...
' Uso:
Dim nums = CreaLista(Of Integer)(1, 2, 3, 4, 5, 6, 7)
Dim noms = CreaLista(Of String)("Pepe", "Juan", "Luis")Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
Dim nums = CreaLista(1, 2, 3, 4, 5, 6, 7)
Dim noms = CreaLista("Pepe", "Juan", "Luis")
' Incluso con tipos anónimos de VB.NET 9
Dim v = CreaLista( _
New With {.X = 1, .Y = 2}, _
New With {.X = 3, .Y = 4} _
)
Console.WriteLine(v(1).Y) ' Muestra "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
 Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.
Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.Y en estos casos la inclusión de imágenes incrustadas suele ser un requisito fundamental cuando se trata de enviar contenidos con formato HTML, de forma que, aunque normalmente se incrementa de forma notable el tamaño del paquete a enviar, se evita que los clientes tengan que descargar estos recursos adicionales desde sus equipos, cosa que además suele estar bloqueada por defecto.
.NET framework nos ofrece varias vías para hacerlo usando las clases provistas en
System.Net.Mail, pero vamos a utilizar una que nos ofrece dos ventajas importantes. La primera es que las imágenes enviadas no se muestran como adjuntos (evitando, por ejemplo, el curioso efecto presente en Outlook Express, que repite las imágenes a continuación del texto del mensaje) y la segunda es que permite especificar distintas vistas dentro desde el mismo mensaje, para que el cliente de correo utilice la que sea más apropiada.El siguiente código muestra una forma de montar un mensaje con dos vistas: la primera será utilizada por aquellos agentes de usuario (clientes de correo) que únicamente pueden mostrar texto plano, mientras que en la segunda utilizará HTML para maquetar el contenido, incluyendo una imagen que aparecerá totalmente integrada en el cuerpo del mensaje, sin mostrarse como elemento adjunto del mismo.
Podréis observar que aunque en el ejemplo muestro un código muy rígido, es fácilmente generalizable para poder utilizarlo en cualquier escenario. Como en otras ocasiones, está en C#, mi lenguaje favorito, pero sería fácilmente portable a VB.NET, por ejemplo.
// Necesitaremos estos namespaces...
using System.Net.Mail;
using System.Net.Mime;
...
// Montamos la estructura básica del mensaje...
MailMessage mail = new MailMessage();
mail.From = new MailAddress("origen@miservidor.com");
mail.To.Add("destinatario@miservidor.com");
mail.Subject = "Mensaje con imagen";
// Creamos la vista para clientes que
// sólo pueden acceder a texto plano...
string text = "Hola, ayer estuve disfrutando de "+
"un paisaje estupendo.";
AlternateView plainView =
AlternateView.CreateAlternateViewFromString(text,
Encoding.UTF8,
MediaTypeNames.Text.Plain);
// Ahora creamos la vista para clientes que
// pueden mostrar contenido HTML...
string html = "<h2>Hola, mira dónde estuve ayer:</h2>" +
"<img src='cid:imagen' />";
AlternateView htmlView =
AlternateView.CreateAlternateViewFromString(html,
Encoding.UTF8,
MediaTypeNames.Text.Html);
// Creamos el recurso a incrustar. Observad
// que el ID que le asignamos (arbitrario) está
// referenciado desde el código HTML como origen
// de la imagen (resaltado en amarillo)...
LinkedResource img =
new LinkedResource(@"C:\paisaje.jpg",
MediaTypeNames.Image.Jpeg);
img.ContentId = "imagen";
// Lo incrustamos en la vista HTML...
htmlView.LinkedResources.Add(img);
// Por último, vinculamos ambas vistas al mensaje...
mail.AlternateViews.Add(plainView);
mail.AlternateViews.Add(htmlView);
// Y lo enviamos a través del servidor SMTP...
SmtpClient smtp = new SmtpClient("smtp.miservidor.com");
smtp.Send(mail);
La siguiente imagen muestra una captura de pantalla del mismo mensaje leído desde un cliente con capacidad HTML como Outlook Express y uno que no la tiene, en este caso basado en web:

Publicado en: www.variablenotfound.com.
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
 Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).
Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).Conozco sistemas ORM, y en especial NHibernate, que ayudan a aliviar en gran parte esta falta de concordancia, por lo que estaba deseando ver la gran apuesta de Microsoft en este ámbito, máxime después de juguetear con su hermano pequeño, y quizás ya difunto, Linq to SQL, y ver que se quedaba bastante corto en muchos aspectos.
El libro "ADO.NET Entity Framework. Aplicaciones y servicios centrados en datos" publicado por Krasis Press hace algo más de un mes, me ha parecido una lectura muy recomendable para acercarse a esta nueva tecnología de la mano de fenónemos como Unai Zorrilla, Octavio Hernández y Eduardo Quintás.
Comienza con una breve introducción en la que se explica la necesidad de tecnologías que ayuden a salvar la distancia entre el mundo relacional de las bases de datos y el mundo más conceptual, presentado como modelos de clases a nivel de diseño software, ofreciendo seguidamente una descripción general de este nuevo marco de trabajo. A partir de ahí, va profundizando en los distintos componentes de Entity Framework, siempre de forma muy práctica y basándose en ejemplos bastante cercanos a la realidad. Se recogen, entre otros, los siguientes contenidos:
- Creación de modelos conceptuales, usando tanto los diseñadores de Visual Studio como modificando a mano los archivos XML que describen el modelo, útil para acceder a características no soportadas por el IDE.
- Entity Client, el proveedor ADO.NET para acceso, aunque algo rudimentario, a datos del modelo
- eSQL, el lenguaje de consulta de Entity Framework.
- Implementación de consultas con
ObjectQuery<T>y Linq to Entities. - Mecanismos de actualización de datos, incluyendo las técnicas de seguimiento de cambios en objetos, transaccionalidad y concurrencia, entre otros aspectos.
- Ejemplos de uso de Entity Framework con WCF, enlaces a datos desde controles Windows Forms, WPF o ASP.NET.
- Servicios de datos de ADO.NET, el mecanismo de publicación de modelos de Entity Framework a través de HTTP.
En definitiva, se trata en mi opinión de un libro muy claro y didáctico, recomendable para desarrolladores que quieran obtener un buen nivel de conocimiento de esta nueva tecnología partiendo desde cero, y para tener siempre a mano cuando comencemos a practicar y utilizar Entity Framework.
Desde la web de la editorial se puede descargar el índice y varias páginas de la introducción en PDF, lo que os permitirá echarle un vistazo, así como realizar el pedido online.
Publicado en: www.variablenotfound.com.
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.
 Vamos a continuar desarrollando nuestro
Vamos a continuar desarrollando nuestro traceroute utilizando el framework .NET. En la primera parte del post ya describimos los fundamentos teóricos, y esbozamos el algoritmo a emplear para conseguir detectar la secuencia de nodos atravesados por los paquetes de datos que darían lugar a nuestra ruta.Continuamos ahora con la implementación de nuestro sistema de trazado de redes.
Lo primero: estructurar la solución
Vamos a desarrollar un componente independiente, empaquetado en una librería, que nos permita realizar trazados de rutas desde cualquier tipo de aplicación, y más aún, desde cualquier lenguaje soportado por la plataforma .NET. Atendiendo a eso, ya debemos tener claro que construiremos un ensamblado, al que vamos a llamar NTraceLib, que contendrá una clase (Tracer) que gestionará toda la lógica de obtención de la traza de la ruta.Dado que debe ser independiente del tipo de aplicación que lo utilice, no podrá incluir ningún tipo de interacción con el usuario, ni acceso a interfaz alguno. Serán las aplicaciones de mayor nivel las que solucionen este problema. La clase
Tracer se comunicará con ellas enviándole eventos cada vez que ocurra algo de interés, como puede ser la recepción de paquetes de datos con las respuestas.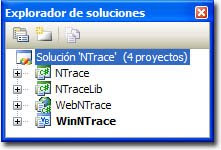 Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:
Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:- NTrace será una aplicación de consola escrita en C#.
- WebNTrace, también escrita en C#, permitirá trazar los paquetes enviados desde el servidor Web donde se esté ejecutando hasta el destino.
- WinNTrace será una herramienta de escritorio, esta vez escrita en VB.NET, que permitirá obtener los resultados de forma más visual.
Tracer: el trazador
La claseTracer será la encargada de realizar el trazado de la ruta hacia el destino indicado. De forma muy rápida, podríamos enumerar sus principales características:- Tiene una única propiedad pública,
Host, que contiene la dirección (nombre o IP) del equipo destino del trazado. Los comandostracertytraceourtetienen más opciones, pero no las vamos a implementar para simplificar el sistema. - Tiene definidas también dos constantes:
- MAX_HOPS, que define el máximo de saltos, o nodos intermedios que permitiremos atravesar a nuestros paquetes. Normalmente no se llegará a este valor.
- TIMEOUT, que definirá el tiempo máximo de espera de llegada de las respuestas.
- Publica dos eventos, que permitirán a las aplicaciones cliente procesar o realizar la representación visual de la información resultante de la ejecución del trazado:
- ErrorReceived, que notificará a la aplicación cliente del componente que se ha producido un error durante la obtención de la ruta. Ejemplos serían "red inalcanzable", o "timeout".
- EchoReceived, que permitirá notificar de la recepción de mensajes por parte de los nodos de la ruta.
- El método
Trace()ejecutará al ser invocado el procedimiento descrito en el post anterior, lanzando los eventos para indicar a las aplicaciones cliente que actualicen su estado o procesen la respuesta. A grandes rasgos, el procedimiento consistía en ir enviado mensaje ICMP ECHO (pings) al servidor de destino incrementando el TTL del paquete en cada iteración y esperar la respuesta, bien la respuesta al ping o bien mensajes "time exceeded" indicando la expiración del paquete durante la ruta hacia el destino.
Para conocer más detalles sobre la clase
Tracer, puedes descargar el proyecto desde el enlace que encontrarás al final del post.Enviar ICMP ECHOs, o cómo hacer un Ping desde .NET
La versión 2.0 de .NET framework nos lo puso realmente sencillo, al incorporar una clase específicamente diseñada para ello, Ping, incluida en el espacio de nombres System.Net.NetworkInformation. A continuación va un código que muestra el envío de una solicitud de eco al servidor www.google.es: Ping pingSender = new Ping ();
PingOptions options = new PingOptions ();
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("datos");
int timeout = 120;
PingReply reply = pingSender.Send ("www.google.es",
timeout, buffer, options);
if (reply.Status == IPStatus.Success)
{
Console.WriteLine ("Recibido: {0}",
reply.Address.ToString ());
}
De este código vale la pena destacar algunos detalles. Primero, como podemos observar, existe una clase
PingOptions que nos permite indicar las opciones con las que queremos enviar el paquete ICMP. En particular, podremos especificar si el paquete podrá ser fragmentado a lo largo de su recorrido, así como, aunque no aparece en el código anterior, el valor inicial del TTL (time to live) del mismo. Habréis adivinado que este último aspecto es especialmente importante para lograr nuestros objetivos.Segundo, es posible indicar en un buffer un conjunto de datos arbitrarios que viajarán en el mensaje, lo que podría permitirnos medir el tiempo de ida y vuelta de un paquete de un tamaño determinado. También se puede indicar el tiempo máximo en el que debemos recibir la respuesta antes de considerar que se trata de un timeout.
Por último, la respuesta a la llamada síncrona
pingSender.Send(...) obtiene un objeto del tipo PingReply, en el que encontraremos información detallada sobre el resultado de la operación.Implementación del trazador
Si unimos el procedimiento de trazado de una ruta, descrito ampliamente en el post anterior, al método de envío de pings recién comentado, casi obtenemos directamente el código del métodoTrace() de la clase Tracer, el responsable de realizar el seguimiento de la ruta:
PingReply reply;
Ping pinger = new Ping();
PingOptions options = new PingOptions();
options.Ttl = 1;
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("NTrace");
try
{
do
{
DateTime start = DateTime.Now;
reply = pinger.Send(host,
TIMEOUT,
buffer,
options);
long milliseconds = DateTime.Now.Subtract(start).Milliseconds;
if ((reply.Status == IPStatus.TtlExpired)
|| (reply.Status == IPStatus.Success))
{
OnEchoReceived(reply, milliseconds);
}
else
{
OnErrorReceived(reply, milliseconds);
}
options.Ttl++;
} while ((reply.Status != IPStatus.Success)
&& (options.Ttl < MAX_HOPS ));
}
catch (PingException pex)
{
throw pex.InnerException;
}
Como podemos observar, se repite el Ping dentro de un bucle en el que va incrementándose el TTL hasta llegar al objetivo (
reply.Status==IPStatus.Success) o hasta que se supere el máximo de saltos permitidos. Por cada ping realizado se llama al evento correspondiente en función del resultado del mismo, con objeto de notificar a las aplicaciones cliente de lo que va pasando. Además, se va tomando en cada llamada el tiempo que se tarda desde el momento del envío hasta la recepción de la respuesta. Podéis observar que llamamos al evento
EchoReceived siempre que recibamos algo de un nodo, sea intermediario (que recibiremos un error por expiración del TTL) o el destinatario final del paquete (que recibiremos la respuesta satisfactoria al ping), mientras que el evento ErrorReceived es invocado en todas las demás circunstancias. En cualquier caso, siempre enviaremos como parámetros el PingReply, que contiene información detallada de la respuesta, y el tiempo en milisegundos que ha tardado en obtenerse la misma.Ah, una nota importante respecto al tiempo de resolución de nombres. Dado que la clase
Ping funciona tanto si le especificamos como destino una dirección IP como si es un nombre de host, hay que tener en cuenta que el primer ping podrá verse penalizado por el tiempo de consulta al DNS si esto es necesario. Esto podría solventarse muy fácilmente, realizando la resolución de forma manual y pasando al ping siempre la dirección IP, pero he preferido mantenerlo así para mantener el código más sencillo.Cómo usar NTraceLib en aplicaciones
 Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:
Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:- Declaramos una variable del tipo
Trace. - Escribimos los manejadores que procesen las respuestas de
ErrorReceivedyEchoReceived, suscribiéndolos a los correspondientes eventos. - Establecemos el host y llamamos al método
Trace()del objeto de trazado.
Vamos a ver el ejemplo concreto de la aplicación WinNTrace, sistema de escritorio creado en Visual Basic .NET, que mostrará en un formulario el resultado del trazado. En primer lugar, tiene declarado un objeto
Tracer como sigue, lo que nos permitirá enlazarle el código a los eventos de forma muy sencilla: Private WithEvents tracer As New TracerCuando el usuario teclea un host en el cuadro de texto y pulsa el botón "Trazar", se ejecuta el siguiente código (he omitido ciertas líneas para facilitar su lectura); podréis comprobar que es bastante simple, pues incluye sólo la asignación del equipo de destino y la llamada a la realización de la traza:
tracer.Host = txtHost.Text
Try
tracer.Trace()
Catch ex As Exception
MessageBox.Show("Error: " + ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
Cuando se recibe información de un nodo, sea intermediario o el destino final de la traza, añadimos al
ListView un nuevo elemento con la dirección del mismo, así como los milisegundos transcurridos desde el envío de la petición: Private Sub tracer_EchoReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.EchoReceivedEventArgs) _
Handles tracer.EchoReceived
Dim items() As String = { _
args.Reply.Address.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
En el caso de recibir un error, como un timeout, añadiremos la línea, pero aportando mostrando el tipo de error producido y destacando la fila respecto al resto con un color de fondo. Este procedimiento podría haberlo trabajado un poco más, por ejemplo añadiendo textos descriptivos de los errores, pero eso os lo dejo de deberes.
Private Sub tracer_ErrorReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.ErrorReceivedEventArgs) _
Handles tracer.ErrorReceived
Dim items() As String = { _
"Error: " + args.Reply.Status.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
item.BackColor = Color.Yellow
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
Además de WinNTrace, en la descarga que encontraréis al final del post he incluido NTrace (la aplicación de consola) y WebNTrace (la aplicación web). Aunque cada una tiene en cuenta sus particularidades de interfaz, el comportamiento es idéntico al descrito para el sistema de escritorio, por lo que no los describiremos con mayor detalle.
Conclusiones
 A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.
A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.Dejamos para artículos posteriores la realización de funcionalidades no implementadas en esta versión, como la posibilidad de cancelar una traza una vez comenzada, la resolución inicial de nombres para que el tiempo de respuesta de la primera pasarela sea más correcto, o incluso la resolución inversa del nombre de los nodos de una ruta, es decir, la obtención del hostname de cada uno de ellos tal y como lo hacen las utilidades de línea comand
tracert o traceroute. También podríamos incluir funciones de geoposicionamiento de los mismos, para intentar obtener una aproximación la ruta física que siguen los paquetes a través de la red.Espero que os haya resultado interesante. Y por supuesto, para dudas, consultas o sugerencias, por aquí me tenéis.
Descargar NTrace (proyecto VS2005)
Publicado en: www.variablenotfound.com.
 Seguro que todos habéis utilizado en alguna ocasión el comando
Seguro que todos habéis utilizado en alguna ocasión el comando tracert (o traceroute en Linux) con objeto de conocer el camino que siguen los paquetes de información para llegar desde vuestro equipo a cualquier otro host de una red. Sin embargo, es posible que más de uno no haya tenido ocasión de ver lo sencillo que resulta desarrollar un componente que realice esta misma tarea usando tecnología .NET, y lo divertido que puede llegar a ser desarrollar utilidades de red de este tipo.En esta serie de posts vamos a desarrollar, utilizando C#, un componente simple de trazado de rutas de red. La elección del lenguaje es pura devoción personal, pero lo mismo podría desarrollarse sin problema utilizando Visual Basic .NET. En cualquier caso, el ensamblado resultante podrá ser utilizado desde cualquier tipo de aplicación soportado por el framework, es decir, sea escritorio, consola o web, y, como es obvio, independientemente del lenguaje utilizado para su creación.
Pero comencemos desde el principio...
Un poco de teoría: ¿cómo funciona un traceroute?
El objetivo de los trazadores de rutas es conocer el camino que siguen los paquetes desde un equipo origen hasta un host destino detectando los sistemas intermediarios (gateways) por los que va pasando. La enumeración ordenada de dichos sistemas es lo que llamamos ruta, y es el resultado de la ejecución del comandotracert o traceroute.Para conseguir obtener esta información, como veremos después, se utiliza de forma muy ingeniosa la capacidad ofrecida por el protocolo IP para definir el tiempo de vida de los paquetes. Profundizaremos un poco en este concepto.
El TTL (Time To Live) es un campo incluido en la cabecera de todos los datagramas IP que se mueven por la red, y es el encargado de evitar que éstos circulen de forma indefinida si no encuentran su destino.
Cuando una aplicación crea un paquete IP, se le asigna un valor inicial al TTL del encabezado del mismo. El valor puede venir definido por el sistema operativo en función del protocolo concreto (TCP, UDP...), o incluso ser asignado por el propio software que lo origine. En cualquier caso, el tiempo se indica en segundos de vida, aunque en la práctica indicará el número de veces que será procesado el paquete por los dispositivos de enrutado que atravesará durante su recorrido.
Cuando este paquete se envía hacia un destino, al llegar al primer gateway de la red, éste analizará su cabecera para determinar su ruta y encaminarlo apropiadamente, y a la misma vez decrementará el valor del TTL. De ahí atravesará otra red hasta llegar al siguiente gateway de su ruta, que volverá a hacer lo mismo. Eso sí, cuando un dispositivo encaminador de este tipo detecte un paquete con un TTL igual a cero, lo descartará y enviará a su emisor original un mensaje ICMP con un código 11 ("time exceed"), que significa que se ha excedido el tiempo de vida del paquete.
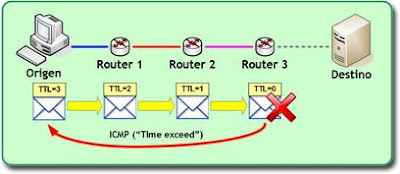
El siguiente diagrama muestra un escenario en el que un paquete es enviado con un TTL=3, y cómo es descartado antes de llegar a su destino:
Volviendo al tema del post y a algo que adelanté anteriormente, el
traceroute utiliza de forma muy ingeniosa el comportamiento descrito, siguiendo el procedimiento para averiguar la ruta de un paquete que se detalla a continuación:- Envía un paquete ICMP Echo al destino con un TTL=1. Este tipo de paquetes son los enviados normalmente al realizar un
pinga un equipo. - El primer dispositivo enrutador al que llega el paquete decrementa el TTL, y dado que es cero, descarta el paquete y envía el mensaje ICMP informando al emisor que el paquete ha sido eliminado.
- El emisor, al recibir este aviso, puede considerar que el remitente del mismo es el primer punto de la ruta que seguirá el paquete hasta su destino.
- A continuación, vuelve a intentarlo enviando de nuevo un ICMP Echo al destino, esta vez con un TTL=2.
- El paquete pasa por el primer enrutador, que transforma su TTL en 1 y lo envía a la red apropiada.
- El segundo enrutador detecta que debe encaminar el paquete y éste tiene un TTL=1 y al decrementarlo será cero, por lo que lo descarta, enviando de vuelta el mensaje "time exceed" al emisor original.
- Desde el origen, a la recepción de este mensaje ICMP, se almacena su remitente como segundo punto de la ruta.
- Y así sucesivamente, se realizan envíos con TTL=3, 4, ... hasta llegar al destino, momento en el que recibiremos la respuesta a la solicitud de eco enviada (un mensaje de tipo ICMP Echo Reply), o hasta superar el número máximo de saltos que se haya indicado (por ejemplo, usando la opción
tracert -h Nen Windows)
Función Trace(DEST)
Inicio
ttl = 1
Hacer
Enviar ICMP_ECHO_REQUEST al host DEST con TTL=ttl
Si recibimos un TIME_EXCEED desde el host X,
o bien recibimos un ICMP_ECHO_REPLY desde X, entonces
El host X forma parte de la ruta
Fin
Incrementa ttl
Mientras Respuesta <> ICMP_ECHO_REPLY Y ttl<MAXIMO
FinPublicado en: www.variablenotfound.com.
 A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.
A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.Como sabemos, la propiedad
Master de las páginas de contenidos, a través de la cual es posible acceder a la página maestra, es por defecto del tipo MasterPage. Esto es así porque todas las masters que creamos heredan de esta clase, y es una abstracción bastante acertada la mayoría de las veces. De hecho, es perfectamente posible hacer un cast al tipo correcto desde el código de la página para acceder a alguna de las propiedades públicas que le hayamos definido, así:
protected void Page_Load(object sender, EventArgs e)
{
MaestraContenidos master = Master as MaestraContenidos;
master.Titulo = "Título";
}
Pues bien, mediante la directiva de página
MasterType es posible indicar de qué tipo será esta propiedad Master, de forma que no será necesario hacer el cast. En la práctica, en el ejemplo anterior, podríamos hacer directamente Master.Titulo="Título", sin realizar la conversión previa.La directiva podemos utilizarla en el archivo .ASPX, haciendo referencia al archivo donde está definida la página maestra cuyo tipo usaremos para la propiedad:
<%@ MasterType VirtualPath="~/site1.master" %>
O también podemos hacerlo indicando directamente el tipo (ojo, que hay que incluirlo con su espacio de nombres completo):
<%@ MasterType TypeName="ProyectoWeb.MaestraContenidos" %>
Por último, algunas contraindicaciones. Si váis a usar esta técnica, tened en cuenta que:
- si decidís cambiar la página maestra en tiempo de ejecución, en cuanto intentéis acceder a la propiedad Master, vuestra aplicación reventará debido a que el tipo no es el correcto.
- si cambiáis la maestra a la que está asociada una página de contenidos, tenéis que acordaros de cambiar también la directiva
MasterTypede la misma para que todo funcione bien.
Publicado en: www.variablenotfound.com.
 Mucho se ha hablado (por ejemplo aquí, aquí, aquí, aquí...) acerca de lo terrible que puede resultar para el rendimiento de nuestro sitio web el dejar la directiva
Mucho se ha hablado (por ejemplo aquí, aquí, aquí, aquí...) acerca de lo terrible que puede resultar para el rendimiento de nuestro sitio web el dejar la directiva debug=true en el Web.config de servidores en producción debido a la sobrecarga que implica que la compilación de las páginas se realice con el modo de depuración activo.El problema es, primero, que hay que acordarse de cambiarlo antes de subir el sitio al servidor de producción y, segundo, que a los despistados nos suele ocurrir que tras subir una nueva versión de la aplicación podemos volver a dejarlo como estaba de forma involuntaria.
Supongo que habrá otras formas para controlarlo, pero hoy me he encontrado con una muy sencilla que nos permite averiguar en tiempo de ejecución si el sitio web está funcionando con la depuración activa o no:
IsDebuggingEnabled, una propiedad de la clase HttpContext.Así, podemos introducir un código como el siguiente en el Global.asax, que provocará la parada de la aplicación cuando intentemos iniciarla, desde un equipo remoto, si la directiva debug está establecida a true en el archivo de configuración.
public class Global : System.Web.HttpApplication
{
protected void Application_Start(object sender, EventArgs e)
{
if (HttpContext.Current.IsDebuggingEnabled
&& !HttpContext.Current.Request.IsLocal)
{
throw new Exception("¡Depuración habilitada!");
}
}
}Otro ejemplo menos violento podría ser la inclusión de un mensaje de alerta en el pie todas las páginas mostradas cuando se estén ejecutando en modo depuración, para lo que habría que escribir el siguiente método en la clase
Global del Global.asax:protected void Application_EndRequest(object sender, EventArgs e)
{
if (HttpContext.Current.IsDebuggingEnabled)
HttpContext.Current.Response.Write(
"<div style='background: red; color: white'>Sitio en depuración</div>"
);
}
Pero ojo, que esta propiedad sólo detecta el valor presente en el Web.config, no tiene en cuenta si a una página se le ha establecido Debug=true en sus directivas @Page, o si los ensamblados usados se compilaron en modo release o depuración.
Publicado en: www.variablenotfound.com.

![[ING] ASP.NET Page Life Cycle en blog de Kris Van Der Mast](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgT5f1ddJsQrs3L6f6WkA0piXPTgq-nmnSEi1vOjm4ICrWJpFQVEbH-Qb050rcuvTn9Q_711qoUE7YLLj78DghBPF40_BJjx1qA8R2A8w1roSidzUwUl1CVw_kOk3zzxsO90sFTmg/s400/aspnetpagelifecycle.png) Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.
Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.Entre otras cosas, se pone de manifiesto la simplicidad de este modelo frente al complejo ciclo de vida de una página utilizando la tecnología Webforms.
Y por cierto, podéis descargar la presentación completa que realizaron en el DevConnections, aunque eso sí, en inglés.
Publicado en: www.variablenotfound.com.
 Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.
Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.Como recordaréis, hasta ese momento las acciones no tenían tipo de retorno, pero han replanteado el diseño para hacerlo más flexible, testable y potente. Así, pasamos de definir las acciones de esta forma:
public void Index()
{
RenderView("Index");
}a esta otra:
public ActionResult Index()
{
return RenderView();
}En el código anterior destacan dos aspectos. En primer lugar que la llamada a
RenderView() no tiene parámetros; el sistema mostrará la vista cuyo nombre coincida con el de la acción que se está ejecutando (Index, en este caso). En segundo lugar, que la llamada a RenderView() retorna un objeto ActionResult (o más concretamente un descendiente, RenderViewResult), que será el devuelto por la acción.De la misma forma, existen tipos de ActionResult concretos para retornar el resultado de las acciones más habituales:
RenderViewResult, retornado cuando se llama desde el controlador aRenderView().ActionRedirectResult, retornado al llamar aRedirectToAction()HttpRedirectResult, que será la respuesta a unRedirect()EmptyResult, que intuyo que será para casos en los que no hay que hacer nada (!), aunque todavía no le he visto mucho el sentido...
Además de las citadas anteriormente, una de las ventajas de retornar estos objetos desde los controladores es que podemos crear nuestra clase, siempre heredando de
ActionResult, e implementar comportamientos personalizados.Esto es lo que ha hecho el genial Phil Haack en dos ejemplos recientemente publicados en su blog.
El primero de ellos, publicado en el post "Writing A Custom File Download Action Result For ASP.NET MVC" muestra una implementación de una acción cuya invocación hace que el cliente descargue, mediante un download, el archivo indicado, en su ejemplo, el archivo CSS de su sitio web:
public ActionResult Download()
{
return new DownloadResult
{ VirtualPath="~/content/site.css",
FileDownloadName = "TheSiteCss.css"
};
}
La clase
DownloadResult una descendiente de ActionResult, en cuya implementación encontraremos, además de la definición de las propiedades VirtualPath y FileDownloadName, la implementación del método ExecuteResult, que será invocado por el framework al finalizar la ejecución de la acción, y donde realmente se realiza el envío al cliente del archivo, con parámetro content-disposition convenientemente establecido:public class DownloadResult : ActionResult
{
public DownloadResult()
{
}
public DownloadResult(string virtualPath)
{
this.VirtualPath = virtualPath;
}
public string VirtualPath { get; set; }
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (!String.IsNullOrEmpty(FileDownloadName)) {
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName)
}
string filePath = context.HttpContext.Server.MapPath(this.VirtualPath);
context.HttpContext.Response.TransmitFile(filePath);
}
}
El segundo ejemplo, publicado en el post "Delegating Action Result", vuelve a demostrar otro posible uso de los ActionResults creando un nuevo descendiente,
DelegatingResult, que puede ser retornado desde las acciones para indicar qué operaciones deben llevarse a cabo por el framework.El siguiente código muestra cómo retornamos un objeto de este tipo, inicializado con una lambda:
public ActionResult Hello()
{
return new DelegatingResult(context =>
{
context.HttpContext.Response.AddHeader("something", "something");
context.HttpContext.Response.Write("Hello World!");
});
}Como veremos a continuación, el constructor de este nuevo tipo recibe un parámetro de tipo
Action<ControllerContext> y lo almacenará de forma local en la propiedad Command, postergando su ejecución hasta más adelante; será la sobreescritura del método ExecuteResult la que ejecutará el comando:public class DelegatingResult : ActionResult
{
public Action<ControllerContext> Command { get; private set; }
public DelegatingResult(Action<ControllerContext> command)
{
this.Command = command;
}
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
throw new ArgumentNullException("context");
Command(context);
}
}
Puedes ver el código completo de ambos ejemplos, así como descargar proyectos de prueba en los artículos originales de Phil Haack:
Por último, recordar que todos estos detalles son relativos a la última actualización de la preview de esta tecnología y podrían variar en futuras revisiones.
Publicado en: www.variablenotfound.com.





