
Mostrando entradas con la etiqueta .net. Mostrar todas las entradas
Mostrando entradas con la etiqueta .net. Mostrar todas las entradas
domingo, 2 de noviembre de 2008
 Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).
Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).Conozco sistemas ORM, y en especial NHibernate, que ayudan a aliviar en gran parte esta falta de concordancia, por lo que estaba deseando ver la gran apuesta de Microsoft en este ámbito, máxime después de juguetear con su hermano pequeño, y quizás ya difunto, Linq to SQL, y ver que se quedaba bastante corto en muchos aspectos.
El libro "ADO.NET Entity Framework. Aplicaciones y servicios centrados en datos" publicado por Krasis Press hace algo más de un mes, me ha parecido una lectura muy recomendable para acercarse a esta nueva tecnología de la mano de fenónemos como Unai Zorrilla, Octavio Hernández y Eduardo Quintás.
Comienza con una breve introducción en la que se explica la necesidad de tecnologías que ayuden a salvar la distancia entre el mundo relacional de las bases de datos y el mundo más conceptual, presentado como modelos de clases a nivel de diseño software, ofreciendo seguidamente una descripción general de este nuevo marco de trabajo. A partir de ahí, va profundizando en los distintos componentes de Entity Framework, siempre de forma muy práctica y basándose en ejemplos bastante cercanos a la realidad. Se recogen, entre otros, los siguientes contenidos:
- Creación de modelos conceptuales, usando tanto los diseñadores de Visual Studio como modificando a mano los archivos XML que describen el modelo, útil para acceder a características no soportadas por el IDE.
- Entity Client, el proveedor ADO.NET para acceso, aunque algo rudimentario, a datos del modelo
- eSQL, el lenguaje de consulta de Entity Framework.
- Implementación de consultas con
ObjectQuery<T>y Linq to Entities. - Mecanismos de actualización de datos, incluyendo las técnicas de seguimiento de cambios en objetos, transaccionalidad y concurrencia, entre otros aspectos.
- Ejemplos de uso de Entity Framework con WCF, enlaces a datos desde controles Windows Forms, WPF o ASP.NET.
- Servicios de datos de ADO.NET, el mecanismo de publicación de modelos de Entity Framework a través de HTTP.
En definitiva, se trata en mi opinión de un libro muy claro y didáctico, recomendable para desarrolladores que quieran obtener un buen nivel de conocimiento de esta nueva tecnología partiendo desde cero, y para tener siempre a mano cuando comencemos a practicar y utilizar Entity Framework.
Desde la web de la editorial se puede descargar el índice y varias páginas de la introducción en PDF, lo que os permitirá echarle un vistazo, así como realizar el pedido online.
Publicado en: www.variablenotfound.com.
martes, 28 de octubre de 2008
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.
domingo, 26 de octubre de 2008
 Vamos a continuar desarrollando nuestro
Vamos a continuar desarrollando nuestro traceroute utilizando el framework .NET. En la primera parte del post ya describimos los fundamentos teóricos, y esbozamos el algoritmo a emplear para conseguir detectar la secuencia de nodos atravesados por los paquetes de datos que darían lugar a nuestra ruta.Continuamos ahora con la implementación de nuestro sistema de trazado de redes.
Lo primero: estructurar la solución
Vamos a desarrollar un componente independiente, empaquetado en una librería, que nos permita realizar trazados de rutas desde cualquier tipo de aplicación, y más aún, desde cualquier lenguaje soportado por la plataforma .NET. Atendiendo a eso, ya debemos tener claro que construiremos un ensamblado, al que vamos a llamar NTraceLib, que contendrá una clase (Tracer) que gestionará toda la lógica de obtención de la traza de la ruta.Dado que debe ser independiente del tipo de aplicación que lo utilice, no podrá incluir ningún tipo de interacción con el usuario, ni acceso a interfaz alguno. Serán las aplicaciones de mayor nivel las que solucionen este problema. La clase
Tracer se comunicará con ellas enviándole eventos cada vez que ocurra algo de interés, como puede ser la recepción de paquetes de datos con las respuestas. Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:
Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:- NTrace será una aplicación de consola escrita en C#.
- WebNTrace, también escrita en C#, permitirá trazar los paquetes enviados desde el servidor Web donde se esté ejecutando hasta el destino.
- WinNTrace será una herramienta de escritorio, esta vez escrita en VB.NET, que permitirá obtener los resultados de forma más visual.
Tracer: el trazador
La claseTracer será la encargada de realizar el trazado de la ruta hacia el destino indicado. De forma muy rápida, podríamos enumerar sus principales características:- Tiene una única propiedad pública,
Host, que contiene la dirección (nombre o IP) del equipo destino del trazado. Los comandostracertytraceourtetienen más opciones, pero no las vamos a implementar para simplificar el sistema. - Tiene definidas también dos constantes:
- MAX_HOPS, que define el máximo de saltos, o nodos intermedios que permitiremos atravesar a nuestros paquetes. Normalmente no se llegará a este valor.
- TIMEOUT, que definirá el tiempo máximo de espera de llegada de las respuestas.
- Publica dos eventos, que permitirán a las aplicaciones cliente procesar o realizar la representación visual de la información resultante de la ejecución del trazado:
- ErrorReceived, que notificará a la aplicación cliente del componente que se ha producido un error durante la obtención de la ruta. Ejemplos serían "red inalcanzable", o "timeout".
- EchoReceived, que permitirá notificar de la recepción de mensajes por parte de los nodos de la ruta.
- El método
Trace()ejecutará al ser invocado el procedimiento descrito en el post anterior, lanzando los eventos para indicar a las aplicaciones cliente que actualicen su estado o procesen la respuesta. A grandes rasgos, el procedimiento consistía en ir enviado mensaje ICMP ECHO (pings) al servidor de destino incrementando el TTL del paquete en cada iteración y esperar la respuesta, bien la respuesta al ping o bien mensajes "time exceeded" indicando la expiración del paquete durante la ruta hacia el destino.
Para conocer más detalles sobre la clase
Tracer, puedes descargar el proyecto desde el enlace que encontrarás al final del post.Enviar ICMP ECHOs, o cómo hacer un Ping desde .NET
La versión 2.0 de .NET framework nos lo puso realmente sencillo, al incorporar una clase específicamente diseñada para ello, Ping, incluida en el espacio de nombres System.Net.NetworkInformation. A continuación va un código que muestra el envío de una solicitud de eco al servidor www.google.es: Ping pingSender = new Ping ();
PingOptions options = new PingOptions ();
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("datos");
int timeout = 120;
PingReply reply = pingSender.Send ("www.google.es",
timeout, buffer, options);
if (reply.Status == IPStatus.Success)
{
Console.WriteLine ("Recibido: {0}",
reply.Address.ToString ());
}
De este código vale la pena destacar algunos detalles. Primero, como podemos observar, existe una clase
PingOptions que nos permite indicar las opciones con las que queremos enviar el paquete ICMP. En particular, podremos especificar si el paquete podrá ser fragmentado a lo largo de su recorrido, así como, aunque no aparece en el código anterior, el valor inicial del TTL (time to live) del mismo. Habréis adivinado que este último aspecto es especialmente importante para lograr nuestros objetivos.Segundo, es posible indicar en un buffer un conjunto de datos arbitrarios que viajarán en el mensaje, lo que podría permitirnos medir el tiempo de ida y vuelta de un paquete de un tamaño determinado. También se puede indicar el tiempo máximo en el que debemos recibir la respuesta antes de considerar que se trata de un timeout.
Por último, la respuesta a la llamada síncrona
pingSender.Send(...) obtiene un objeto del tipo PingReply, en el que encontraremos información detallada sobre el resultado de la operación.Implementación del trazador
Si unimos el procedimiento de trazado de una ruta, descrito ampliamente en el post anterior, al método de envío de pings recién comentado, casi obtenemos directamente el código del métodoTrace() de la clase Tracer, el responsable de realizar el seguimiento de la ruta:
PingReply reply;
Ping pinger = new Ping();
PingOptions options = new PingOptions();
options.Ttl = 1;
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("NTrace");
try
{
do
{
DateTime start = DateTime.Now;
reply = pinger.Send(host,
TIMEOUT,
buffer,
options);
long milliseconds = DateTime.Now.Subtract(start).Milliseconds;
if ((reply.Status == IPStatus.TtlExpired)
|| (reply.Status == IPStatus.Success))
{
OnEchoReceived(reply, milliseconds);
}
else
{
OnErrorReceived(reply, milliseconds);
}
options.Ttl++;
} while ((reply.Status != IPStatus.Success)
&& (options.Ttl < MAX_HOPS ));
}
catch (PingException pex)
{
throw pex.InnerException;
}
Como podemos observar, se repite el Ping dentro de un bucle en el que va incrementándose el TTL hasta llegar al objetivo (
reply.Status==IPStatus.Success) o hasta que se supere el máximo de saltos permitidos. Por cada ping realizado se llama al evento correspondiente en función del resultado del mismo, con objeto de notificar a las aplicaciones cliente de lo que va pasando. Además, se va tomando en cada llamada el tiempo que se tarda desde el momento del envío hasta la recepción de la respuesta. Podéis observar que llamamos al evento
EchoReceived siempre que recibamos algo de un nodo, sea intermediario (que recibiremos un error por expiración del TTL) o el destinatario final del paquete (que recibiremos la respuesta satisfactoria al ping), mientras que el evento ErrorReceived es invocado en todas las demás circunstancias. En cualquier caso, siempre enviaremos como parámetros el PingReply, que contiene información detallada de la respuesta, y el tiempo en milisegundos que ha tardado en obtenerse la misma.Ah, una nota importante respecto al tiempo de resolución de nombres. Dado que la clase
Ping funciona tanto si le especificamos como destino una dirección IP como si es un nombre de host, hay que tener en cuenta que el primer ping podrá verse penalizado por el tiempo de consulta al DNS si esto es necesario. Esto podría solventarse muy fácilmente, realizando la resolución de forma manual y pasando al ping siempre la dirección IP, pero he preferido mantenerlo así para mantener el código más sencillo.Cómo usar NTraceLib en aplicaciones
 Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:
Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:- Declaramos una variable del tipo
Trace. - Escribimos los manejadores que procesen las respuestas de
ErrorReceivedyEchoReceived, suscribiéndolos a los correspondientes eventos. - Establecemos el host y llamamos al método
Trace()del objeto de trazado.
Vamos a ver el ejemplo concreto de la aplicación WinNTrace, sistema de escritorio creado en Visual Basic .NET, que mostrará en un formulario el resultado del trazado. En primer lugar, tiene declarado un objeto
Tracer como sigue, lo que nos permitirá enlazarle el código a los eventos de forma muy sencilla: Private WithEvents tracer As New TracerCuando el usuario teclea un host en el cuadro de texto y pulsa el botón "Trazar", se ejecuta el siguiente código (he omitido ciertas líneas para facilitar su lectura); podréis comprobar que es bastante simple, pues incluye sólo la asignación del equipo de destino y la llamada a la realización de la traza:
tracer.Host = txtHost.Text
Try
tracer.Trace()
Catch ex As Exception
MessageBox.Show("Error: " + ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
Cuando se recibe información de un nodo, sea intermediario o el destino final de la traza, añadimos al
ListView un nuevo elemento con la dirección del mismo, así como los milisegundos transcurridos desde el envío de la petición: Private Sub tracer_EchoReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.EchoReceivedEventArgs) _
Handles tracer.EchoReceived
Dim items() As String = { _
args.Reply.Address.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
En el caso de recibir un error, como un timeout, añadiremos la línea, pero aportando mostrando el tipo de error producido y destacando la fila respecto al resto con un color de fondo. Este procedimiento podría haberlo trabajado un poco más, por ejemplo añadiendo textos descriptivos de los errores, pero eso os lo dejo de deberes.
Private Sub tracer_ErrorReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.ErrorReceivedEventArgs) _
Handles tracer.ErrorReceived
Dim items() As String = { _
"Error: " + args.Reply.Status.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
item.BackColor = Color.Yellow
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
Además de WinNTrace, en la descarga que encontraréis al final del post he incluido NTrace (la aplicación de consola) y WebNTrace (la aplicación web). Aunque cada una tiene en cuenta sus particularidades de interfaz, el comportamiento es idéntico al descrito para el sistema de escritorio, por lo que no los describiremos con mayor detalle.
Conclusiones
 A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.
A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.Dejamos para artículos posteriores la realización de funcionalidades no implementadas en esta versión, como la posibilidad de cancelar una traza una vez comenzada, la resolución inicial de nombres para que el tiempo de respuesta de la primera pasarela sea más correcto, o incluso la resolución inversa del nombre de los nodos de una ruta, es decir, la obtención del hostname de cada uno de ellos tal y como lo hacen las utilidades de línea comand
tracert o traceroute. También podríamos incluir funciones de geoposicionamiento de los mismos, para intentar obtener una aproximación la ruta física que siguen los paquetes a través de la red.Espero que os haya resultado interesante. Y por supuesto, para dudas, consultas o sugerencias, por aquí me tenéis.
Descargar NTrace (proyecto VS2005)
Publicado en: www.variablenotfound.com.
domingo, 19 de octubre de 2008
 Seguro que todos habéis utilizado en alguna ocasión el comando
Seguro que todos habéis utilizado en alguna ocasión el comando tracert (o traceroute en Linux) con objeto de conocer el camino que siguen los paquetes de información para llegar desde vuestro equipo a cualquier otro host de una red. Sin embargo, es posible que más de uno no haya tenido ocasión de ver lo sencillo que resulta desarrollar un componente que realice esta misma tarea usando tecnología .NET, y lo divertido que puede llegar a ser desarrollar utilidades de red de este tipo.En esta serie de posts vamos a desarrollar, utilizando C#, un componente simple de trazado de rutas de red. La elección del lenguaje es pura devoción personal, pero lo mismo podría desarrollarse sin problema utilizando Visual Basic .NET. En cualquier caso, el ensamblado resultante podrá ser utilizado desde cualquier tipo de aplicación soportado por el framework, es decir, sea escritorio, consola o web, y, como es obvio, independientemente del lenguaje utilizado para su creación.
Pero comencemos desde el principio...
Un poco de teoría: ¿cómo funciona un traceroute?
El objetivo de los trazadores de rutas es conocer el camino que siguen los paquetes desde un equipo origen hasta un host destino detectando los sistemas intermediarios (gateways) por los que va pasando. La enumeración ordenada de dichos sistemas es lo que llamamos ruta, y es el resultado de la ejecución del comandotracert o traceroute.Para conseguir obtener esta información, como veremos después, se utiliza de forma muy ingeniosa la capacidad ofrecida por el protocolo IP para definir el tiempo de vida de los paquetes. Profundizaremos un poco en este concepto.
El TTL (Time To Live) es un campo incluido en la cabecera de todos los datagramas IP que se mueven por la red, y es el encargado de evitar que éstos circulen de forma indefinida si no encuentran su destino.
Cuando una aplicación crea un paquete IP, se le asigna un valor inicial al TTL del encabezado del mismo. El valor puede venir definido por el sistema operativo en función del protocolo concreto (TCP, UDP...), o incluso ser asignado por el propio software que lo origine. En cualquier caso, el tiempo se indica en segundos de vida, aunque en la práctica indicará el número de veces que será procesado el paquete por los dispositivos de enrutado que atravesará durante su recorrido.
Cuando este paquete se envía hacia un destino, al llegar al primer gateway de la red, éste analizará su cabecera para determinar su ruta y encaminarlo apropiadamente, y a la misma vez decrementará el valor del TTL. De ahí atravesará otra red hasta llegar al siguiente gateway de su ruta, que volverá a hacer lo mismo. Eso sí, cuando un dispositivo encaminador de este tipo detecte un paquete con un TTL igual a cero, lo descartará y enviará a su emisor original un mensaje ICMP con un código 11 ("time exceed"), que significa que se ha excedido el tiempo de vida del paquete.
El siguiente diagrama muestra un escenario en el que un paquete es enviado con un TTL=3, y cómo es descartado antes de llegar a su destino:
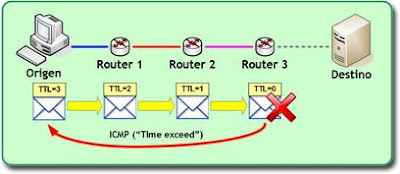
Volviendo al tema del post y a algo que adelanté anteriormente, el
traceroute utiliza de forma muy ingeniosa el comportamiento descrito, siguiendo el procedimiento para averiguar la ruta de un paquete que se detalla a continuación:- Envía un paquete ICMP Echo al destino con un TTL=1. Este tipo de paquetes son los enviados normalmente al realizar un
pinga un equipo. - El primer dispositivo enrutador al que llega el paquete decrementa el TTL, y dado que es cero, descarta el paquete y envía el mensaje ICMP informando al emisor que el paquete ha sido eliminado.
- El emisor, al recibir este aviso, puede considerar que el remitente del mismo es el primer punto de la ruta que seguirá el paquete hasta su destino.
- A continuación, vuelve a intentarlo enviando de nuevo un ICMP Echo al destino, esta vez con un TTL=2.
- El paquete pasa por el primer enrutador, que transforma su TTL en 1 y lo envía a la red apropiada.
- El segundo enrutador detecta que debe encaminar el paquete y éste tiene un TTL=1 y al decrementarlo será cero, por lo que lo descarta, enviando de vuelta el mensaje "time exceed" al emisor original.
- Desde el origen, a la recepción de este mensaje ICMP, se almacena su remitente como segundo punto de la ruta.
- Y así sucesivamente, se realizan envíos con TTL=3, 4, ... hasta llegar al destino, momento en el que recibiremos la respuesta a la solicitud de eco enviada (un mensaje de tipo ICMP Echo Reply), o hasta superar el número máximo de saltos que se haya indicado (por ejemplo, usando la opción
tracert -h Nen Windows)
Función Trace(DEST)
Inicio
ttl = 1
Hacer
Enviar ICMP_ECHO_REQUEST al host DEST con TTL=ttl
Si recibimos un TIME_EXCEED desde el host X,
o bien recibimos un ICMP_ECHO_REPLY desde X, entonces
El host X forma parte de la ruta
Fin
Incrementa ttl
Mientras Respuesta <> ICMP_ECHO_REPLY Y ttl<MAXIMO
FinPublicado en: www.variablenotfound.com.
martes, 7 de octubre de 2008
 A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.
A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.Como sabemos, la propiedad
Master de las páginas de contenidos, a través de la cual es posible acceder a la página maestra, es por defecto del tipo MasterPage. Esto es así porque todas las masters que creamos heredan de esta clase, y es una abstracción bastante acertada la mayoría de las veces. De hecho, es perfectamente posible hacer un cast al tipo correcto desde el código de la página para acceder a alguna de las propiedades públicas que le hayamos definido, así:
protected void Page_Load(object sender, EventArgs e)
{
MaestraContenidos master = Master as MaestraContenidos;
master.Titulo = "Título";
}
Pues bien, mediante la directiva de página
MasterType es posible indicar de qué tipo será esta propiedad Master, de forma que no será necesario hacer el cast. En la práctica, en el ejemplo anterior, podríamos hacer directamente Master.Titulo="Título", sin realizar la conversión previa.La directiva podemos utilizarla en el archivo .ASPX, haciendo referencia al archivo donde está definida la página maestra cuyo tipo usaremos para la propiedad:
<%@ MasterType VirtualPath="~/site1.master" %>
O también podemos hacerlo indicando directamente el tipo (ojo, que hay que incluirlo con su espacio de nombres completo):
<%@ MasterType TypeName="ProyectoWeb.MaestraContenidos" %>
Por último, algunas contraindicaciones. Si váis a usar esta técnica, tened en cuenta que:
- si decidís cambiar la página maestra en tiempo de ejecución, en cuanto intentéis acceder a la propiedad Master, vuestra aplicación reventará debido a que el tipo no es el correcto.
- si cambiáis la maestra a la que está asociada una página de contenidos, tenéis que acordaros de cambiar también la directiva
MasterTypede la misma para que todo funcione bien.
Publicado en: www.variablenotfound.com.
miércoles, 2 de julio de 2008
 Mucho se ha hablado (por ejemplo aquí, aquí, aquí, aquí...) acerca de lo terrible que puede resultar para el rendimiento de nuestro sitio web el dejar la directiva
Mucho se ha hablado (por ejemplo aquí, aquí, aquí, aquí...) acerca de lo terrible que puede resultar para el rendimiento de nuestro sitio web el dejar la directiva debug=true en el Web.config de servidores en producción debido a la sobrecarga que implica que la compilación de las páginas se realice con el modo de depuración activo.El problema es, primero, que hay que acordarse de cambiarlo antes de subir el sitio al servidor de producción y, segundo, que a los despistados nos suele ocurrir que tras subir una nueva versión de la aplicación podemos volver a dejarlo como estaba de forma involuntaria.
Supongo que habrá otras formas para controlarlo, pero hoy me he encontrado con una muy sencilla que nos permite averiguar en tiempo de ejecución si el sitio web está funcionando con la depuración activa o no:
IsDebuggingEnabled, una propiedad de la clase HttpContext.Así, podemos introducir un código como el siguiente en el Global.asax, que provocará la parada de la aplicación cuando intentemos iniciarla, desde un equipo remoto, si la directiva debug está establecida a true en el archivo de configuración.
public class Global : System.Web.HttpApplication
{
protected void Application_Start(object sender, EventArgs e)
{
if (HttpContext.Current.IsDebuggingEnabled
&& !HttpContext.Current.Request.IsLocal)
{
throw new Exception("¡Depuración habilitada!");
}
}
}Otro ejemplo menos violento podría ser la inclusión de un mensaje de alerta en el pie todas las páginas mostradas cuando se estén ejecutando en modo depuración, para lo que habría que escribir el siguiente método en la clase
Global del Global.asax:protected void Application_EndRequest(object sender, EventArgs e)
{
if (HttpContext.Current.IsDebuggingEnabled)
HttpContext.Current.Response.Write(
"<div style='background: red; color: white'>Sitio en depuración</div>"
);
}
Pero ojo, que esta propiedad sólo detecta el valor presente en el Web.config, no tiene en cuenta si a una página se le ha establecido Debug=true en sus directivas @Page, o si los ensamblados usados se compilaron en modo release o depuración.
Publicado en: www.variablenotfound.com.
lunes, 2 de junio de 2008
Eilon Lipton, miembro del equipo de desarrollo de ASP.NET e involucrado en la actualidad en la creación del framework ASP.NET MVC, publicó hace unos meses en su post ASP.NET MVC Design Philosophy "la serpiente MVC", un nombre muy gráfico para el diagrama que utilizó en la presentación realizada en el evento DevConnections junto a Scott Hanselman para explicar el ciclo de vida de una petición bajo este nuevo marco de trabajo:
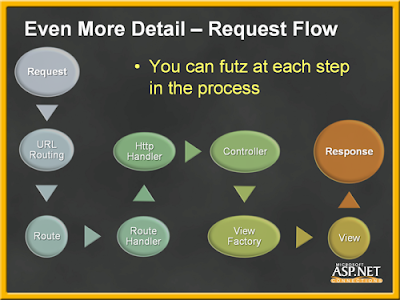
![[ING] ASP.NET Page Life Cycle en blog de Kris Van Der Mast](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgT5f1ddJsQrs3L6f6WkA0piXPTgq-nmnSEi1vOjm4ICrWJpFQVEbH-Qb050rcuvTn9Q_711qoUE7YLLj78DghBPF40_BJjx1qA8R2A8w1roSidzUwUl1CVw_kOk3zzxsO90sFTmg/s400/aspnetpagelifecycle.png) Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.
Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.
Entre otras cosas, se pone de manifiesto la simplicidad de este modelo frente al complejo ciclo de vida de una página utilizando la tecnología Webforms.
Y por cierto, podéis descargar la presentación completa que realizaron en el DevConnections, aunque eso sí, en inglés.
Publicado en: www.variablenotfound.com.
 Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.
Como se puede observar, el recorrido que sigue una petición desde que se produce hasta que se envía la respuesta de vuelta es bastante simple, aunque como comenta Eilon, hay algunas (pocas) fases más que no se han mostrado por claridad del diagrama.Entre otras cosas, se pone de manifiesto la simplicidad de este modelo frente al complejo ciclo de vida de una página utilizando la tecnología Webforms.
Y por cierto, podéis descargar la presentación completa que realizaron en el DevConnections, aunque eso sí, en inglés.
Publicado en: www.variablenotfound.com.
domingo, 11 de mayo de 2008
 Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.
Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.Como recordaréis, hasta ese momento las acciones no tenían tipo de retorno, pero han replanteado el diseño para hacerlo más flexible, testable y potente. Así, pasamos de definir las acciones de esta forma:
public void Index()
{
RenderView("Index");
}a esta otra:
public ActionResult Index()
{
return RenderView();
}En el código anterior destacan dos aspectos. En primer lugar que la llamada a
RenderView() no tiene parámetros; el sistema mostrará la vista cuyo nombre coincida con el de la acción que se está ejecutando (Index, en este caso). En segundo lugar, que la llamada a RenderView() retorna un objeto ActionResult (o más concretamente un descendiente, RenderViewResult), que será el devuelto por la acción.De la misma forma, existen tipos de ActionResult concretos para retornar el resultado de las acciones más habituales:
RenderViewResult, retornado cuando se llama desde el controlador aRenderView().ActionRedirectResult, retornado al llamar aRedirectToAction()HttpRedirectResult, que será la respuesta a unRedirect()EmptyResult, que intuyo que será para casos en los que no hay que hacer nada (!), aunque todavía no le he visto mucho el sentido...
Además de las citadas anteriormente, una de las ventajas de retornar estos objetos desde los controladores es que podemos crear nuestra clase, siempre heredando de
ActionResult, e implementar comportamientos personalizados.Esto es lo que ha hecho el genial Phil Haack en dos ejemplos recientemente publicados en su blog.
El primero de ellos, publicado en el post "Writing A Custom File Download Action Result For ASP.NET MVC" muestra una implementación de una acción cuya invocación hace que el cliente descargue, mediante un download, el archivo indicado, en su ejemplo, el archivo CSS de su sitio web:
public ActionResult Download()
{
return new DownloadResult
{ VirtualPath="~/content/site.css",
FileDownloadName = "TheSiteCss.css"
};
}
La clase
DownloadResult una descendiente de ActionResult, en cuya implementación encontraremos, además de la definición de las propiedades VirtualPath y FileDownloadName, la implementación del método ExecuteResult, que será invocado por el framework al finalizar la ejecución de la acción, y donde realmente se realiza el envío al cliente del archivo, con parámetro content-disposition convenientemente establecido:public class DownloadResult : ActionResult
{
public DownloadResult()
{
}
public DownloadResult(string virtualPath)
{
this.VirtualPath = virtualPath;
}
public string VirtualPath { get; set; }
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (!String.IsNullOrEmpty(FileDownloadName)) {
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName)
}
string filePath = context.HttpContext.Server.MapPath(this.VirtualPath);
context.HttpContext.Response.TransmitFile(filePath);
}
}
El segundo ejemplo, publicado en el post "Delegating Action Result", vuelve a demostrar otro posible uso de los ActionResults creando un nuevo descendiente,
DelegatingResult, que puede ser retornado desde las acciones para indicar qué operaciones deben llevarse a cabo por el framework.El siguiente código muestra cómo retornamos un objeto de este tipo, inicializado con una lambda:
public ActionResult Hello()
{
return new DelegatingResult(context =>
{
context.HttpContext.Response.AddHeader("something", "something");
context.HttpContext.Response.Write("Hello World!");
});
}Como veremos a continuación, el constructor de este nuevo tipo recibe un parámetro de tipo
Action<ControllerContext> y lo almacenará de forma local en la propiedad Command, postergando su ejecución hasta más adelante; será la sobreescritura del método ExecuteResult la que ejecutará el comando:public class DelegatingResult : ActionResult
{
public Action<ControllerContext> Command { get; private set; }
public DelegatingResult(Action<ControllerContext> command)
{
this.Command = command;
}
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
throw new ArgumentNullException("context");
Command(context);
}
}
Puedes ver el código completo de ambos ejemplos, así como descargar proyectos de prueba en los artículos originales de Phil Haack:
Por último, recordar que todos estos detalles son relativos a la última actualización de la preview de esta tecnología y podrían variar en futuras revisiones.
Publicado en: www.variablenotfound.com.
domingo, 4 de mayo de 2008
 Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.
Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.Como sabemos, si desde una aplicación queremos obtener una descripción comprensible de un elemento de una enumeración, normalmente no podemos realizar una conversión directa (
elemento.ToString()) del mismo, pues obtenemos los nombres de los identificadores usados a nivel de código. La solución habitual, hasta la llegada de C# 3.0 consistía en incluir dentro de alguna clase de utilidad un conversor estático que recibiera como parámetro en elemento de la enumeración y retornara un string, algo así como:
public static string EstadoProyecto2String(EstadoProyecto e)
{
switch (e)
{
case EstadoProyecto.PendienteDeAceptacion:
return "Pendiente de aceptación";
case EstadoProyecto.EnRealizacion:
return "En realización";
case EstadoProyecto.Finalizado:
return "Finalizado";
default:
throw
new ArgumentOutOfRangeException("Error: " + e);
}
}
Este método, sin embargo, presenta algunos inconvenientes. En primer lugar, dado el tipado fuerte del parámetro de entrada del método, es necesario crear una función similar para cada enumeración sobre la que queramos realizar la operación.
También puede resultar peligroso separar la definición de la enumeración del método que transforma sus elementos a cadena de caracteres, puesto que puede perderse la sincronización entre ambos cuando, por ejemplo, se introduzca un nuevo elemento en ella y no se actualice el método con la descripción asociada.
La solución, que como he comentado me pareció muy interesante, consiste en decorar cada elemento de la enumeración con un atributo que describa al mismo, e implementar un método de extensión sobre la clase base
System.Enum para obtener estos valores. Veamos cómo.Ah, una cosa más. Aunque los ejemplos están escritos en C#, se puede conseguir exactamente el mismo resultado en VB.NET simplemente realizando las correspondientes adaptaciones sintácticas. Podrás encontrarlo al final del post.
1. Declaración de la enumeración
Vamos a usar el atributoSystem.ComponentModel.DescriptionAttribute, aunque podríamos usar cualquier otro que nos interese, o incluso crear nuestro propio atributo personalizado. El código de definición de la enumeración sería así:
using System.ComponentModel;
public enum EstadoProyecto
{
[Description("Pendiente de aceptación")] PendienteDeAceptacion,
[Description("En realización")] EnRealizacion,
[Description("Finalizado")] Finalizado,
[Description("Facturado y cerrado")] FacturadoYCerrado
}
2. Implementación del método de extensión
Ahora vamos a crear el método de extensión (¿qué son los métodos de extensión?) que se aplicará a todas las enumeraciones.Fijaos que el parámetro de entrada del método está precedido por la palabra reservada
this y el tipo es System.Enum, por lo que será aplicable a cualquier enumeración.
using System;
using System.ComponentModel;
using System.Reflection;
public static class Utils
{
public static string GetDescription(this Enum e)
{
FieldInfo field = e.GetType().GetField(e.ToString());
if (field != null)
{
object[] attribs =
field.GetCustomAttributes(typeof(DescriptionAttribute), false);
if (attribs.Length > 0)
return (attribs[0] as DescriptionAttribute).Description;
}
return e.ToString();
}
}
 Y voila! A partir de este momento tendremos a nuestra disposición el método
Y voila! A partir de este momento tendremos a nuestra disposición el método GetDescription(), que nos devolverá el texto asociado al elemento de la enumeración; si éste no existe, es decir, si no se ha decorado el elemento con el atributo apropiado, nos devolverá el identificador utilizado.De esta forma eliminamos de un plumazo los dos inconvenientes citados anteriormente: la separación entre la definición de la enumeración y los textos descriptivos, y la necesidad de crear un conversor a texto por cada enumeración que usemos en nuestra aplicación.
Y por cierto, el equivalente en VB.NET completo sería:
Imports System.ComponentModel
Imports System.Reflection
Imports System.Runtime.CompilerServices
Module Module1
Public Enum EstadoProyecto
<Description("Pendiente de aceptación")> PendienteDeAceptacion
<Description("En realización")> EnRealizacion
<Description("Finalizado")> Finalizado
<Description("Facturado y cerrado")> FacturadoYCerrado
End Enum
<Extension()> _
Public Function GetDescription(ByVal e As System.Enum) As String
Dim field As FieldInfo = e.GetType().GetField(e.ToString())
If Not (field Is Nothing) Then
Dim attribs() As Object = _
field.GetCustomAttributes(GetType(DescriptionAttribute), False)
If attribs.Length > 0 Then
Return CType(attribs(0), DescriptionAttribute).Description
End If
End If
Return e.ToString()
End Function
End Module
Publicado en: www.variablenotfound.com.
martes, 15 de abril de 2008
 Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".
Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".Recordemos que una parte de una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el compilador eliminará tanto la declaración del método como las llamadas que se hagan al mismo.
Sin embargo esta eliminación pueden causar efectos no deseados difíciles de detectar.
Veámoslo con un ejemplo. Supongamos una clase parcial como la siguiente, que representa a una variable de tipo entero que puede ser incrementada o decrementada a través de métodos:
public partial class Variable
{
partial void Log(string msg);
private int i = 0;
public void Inc()
{
i++;
Log("Incremento. I: " + i);
}
public void Dec()
{
Log("Decremento. I: " + (--i));
}
public int Value
{
get { return i; }
}
}
Creamos ahora un código que utiliza esta clase de forma muy simple: crea una variable, la incrementa dos veces, la decrementa una vez y muestra el resultado:
Variable v = new Variable();
v.Inc();
v.Inc();
v.Dec();
Console.WriteLine(v.Value);
Obviamente, tras la ejecución de este código la pantalla mostrará por consola un "1", ¿no? Claro, el resultado de realizar dos incrementos y un decremento sobre el cero.
Pues no necesariamente. De hecho, es imposible conocer, a la vista del código mostrado hasta ahora, cuál será el resultado mostrado por consola al finalizar la ejecución. Dependiendo de la existencia de la implementación del método parcial
Log(), declarado e invocado en la clase Variable anterior, puede ocurrir:- Si existe otra porción de la misma clase (otra
partial class Variable) donde se implemente el método, se ejecutará éste. El valor mostrado por consola, salvo que desde esta implementación se modificara el valor del campo privado, sería "1". - Si no existe una implementación del método
Log()en la clase, el compilador eliminará todas las llamadas al mismo. Pero si observáis, esto incluye el decremento del valor interno, que estaba en el interior de la llamada como un autodecremento:
Por tanto, en este caso, el compilador eliminará tanto la llamada aLog("Decremento. I: " + (--i));Log()como la operación que se realiza en el interior. Obviamente, el resultado de ejecución de la prueba anterior sería "2".
Lo mismo ocurriría si el resultado a mostrar fuera el valor de retorno de una llamada a otra función: esta no se ejecutaría, lo cual puede ser grave si en ella se realiza una operación importante, como por ejemplo:public function InicializaValores()
{
Log("Elementos reestablecidos: " + reseteaElementos() );
}
Por ejemplo, imaginad que el ejemplo anterior contiene una implementación de
Log(); la aplicación funcionaría correctamente. Sin embargo, si pasado un tiempo se decide eliminar esta implementación (por ejemplo, porque ya no es necesario registrar las operaciones realizadas), la operación de decremento (Dec()) dejaría de funcionar. Aunque, eso sí, no es nada que no se pueda solucionar con un buen juego de pruebas...
Publicado en: http://www.variablenotfound.com/.
domingo, 13 de abril de 2008
 Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.
Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.Estos métodos, declarados en el contexto de una clase parcial, permiten comunicar de forma segura los distintos fragmentos de dicha clase. De forma similar a los eventos, permiten que un código incluya una llamada a una función que puede (o no) haber sido implementada por un código cliente, aunque en este caso obligatoriamente la implementación se encontrará en uno de los fragmentos de la misma clase desde donde se realiza la llamada.
En la práctica significa que una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el código correspondiente a la llamada será eliminado en tiempo compilación para optimizar el resultado... ¡sí, eliminado!
Por ejemplo, el siguiente código muestra una declaración de un método parcial en el interior de una clase, y su utilización desde dentro de uno de sus métodos:
// C#
public partial class Ejemplo
{
// El método parcial se declara
// sin implementación...
partial void Log(string msg);
public void RealizarAlgo()
{
hacerAlgoComplejo();
Log("¡Ojo!"); // Usamos el método
// parcial declarado antes
}
[...] // Otros métodos y propiedades
}
' VB.NET
Partial Public Class Ejemplo
' El método parcial se declara, sin
' implementar nada en el cuerpo
Partial Private Sub Log(ByVal msg As String)
End Sub
Public Sub RealizarAlgo()
HacerAlgoComplejo()
Log("¡Ojo!") ' Usamos el método parcial
End Sub
[...] ' Otros métodos y propiedades
End Class
Y esta la parte realmente curiosa. Cuando el compilador detecta la invocación del método parcial
Log(), buscará en todos los fragmentos de la clase a ver si existe una implementación del mismo. Si no existe, eliminará del ensamblado resultante la llamada a dichos métodos, es decir, actuará como si éstas no existieran en el código fuente.En caso afirmativo, es decir, si existen implementaciones como las del siguiente ejemplo, todo se ejecutará conforme a lo previsto:
// C#
public partial class Variable
{
partial void Log(string msg)
{
Console.WriteLine(msg);
}
}
' VB.Net
Partial Public Class Variable
Private Sub Log(ByVal msg As String)
Console.WriteLine(msg)
End Sub
End Class
Antes comentaba que los métodos parciales son, en cierto sentido, similares a los eventos, pues conceptualmente permiten lo mismo: pasar el control a un código cliente en un momento dado, en el caso de que éste exista. De hecho, hay muchos desarrolladores que lo consideran como un sustituto ligero a los eventos, pues permite prácticamente lo mismo pero se implementan de forma más sencilla.
Existen, sin embargo, algunas diferencias entre ambos modelos, como:
- Los métodos parciales se implementan en la propia clase, mientras que los eventos pueden ser consumidos también desde cualquier otra
- El enlace, o la suscripción, a eventos es dinámica, se realiza en tiempo de ejecución, es necesario incluir código para ello; los métodos parciales, sin embargo, se vinculan en tiempo de compilación
- Los eventos permiten múltiples suscripciones, es decir, asociarles más de un código cliente
- Los eventos pueden presentar cualquier visibilidad (pública, privada...), mientras que los métodos parciales son obligatoriamente privados.
Por último, es conveniente citar algunas consideraciones sobre los métodos parciales:
- Deben ser siempre privados (ya lo había comentado antes)
- No deben devolver valores (en VB.Net serían
SUB, en C# serían de tipovoid) - Pueden ser estáticos (shared en VB)
- Pueden usar parámetros, acceder a los miembros privados de la clase... en definitiva, actuar como un método más de la misma
En resumen, los métodos parciales forman parte del conjunto de novedades de C# y VB.Net que no son absolutamente necesarias y que a veces pueden parecer incluso diabólicas, pues facilitan la dispersión de código y dificultan la legibilidad. Además, en breve publicaré un post comentando posibles efectos laterales a tener en cuenta cuando usemos los métodos parciales en nuestros desarrollos.
Sin embargo, es innegable que los métodos parciales nos facilitan enormemente la inclusión de código de usuario en el interior de clases generadas de forma automática. Por ejemplo, el diseñador visual del modelo de datos de LinqToSQL genera los
DataContext como clases parciales, en las que define un método parcial llamado OnCreated(). Si el usuario quiere incluir alguna inicialización personal al crear los DataContext, no tendrá que tocar el código generado de forma automática; simplemente creará otro fragmento de la clase parcial e implementará este método, de una forma mucho más natural y cómoda que si se tratara de un evento.Publicado en: http://www.variablenotfound.com/.
miércoles, 2 de abril de 2008
Aunque las clases parciales aparecieron hace unos años, con la llegada de .Net 2.0 y Visual Studio 2005, vamos a hacer un breve repaso como preparación para un próximo post que trate los métodos parciales.Las clases parciales (llamados también tipos parciales) son una característica presente en algunos lenguajes de programación, como C# y VB.Net, que permiten que la declaración de una clase se realice en varios archivos de código fuente, rompiendo así la tradicional regla "una clase, un archivo". Será tarea del compilador tomar las porciones de los distintos archivos y fundirlas en una única entidad.
En VB.Net y C#, a diferencia de otros lenguajes, es necesario indicar explícitamente que una clase es parcial, es decir, que es posible que haya otros archivos donde se continúe la declaración de la misma, usando en ambos con la palabra clave
partial en la definición del tipo: ' VB.NET
Public Partial Class Persona
...
End Class
// C#
public partial class Persona
{
...
}
En este código hemos visto cómo se declara una clase parcial en ambos lenguajes, que es prácticamente idéntica salvo por los detalles sintácticos obvios. Por ello, a partir de este momento continuaré introduciendo los ejemplos sólo en C#.
Pero antes un inciso: la única diferencia entre ambos, estrictamente hablando, es que C# obliga a que todas las apariciones de la clase estén marcadas como parciales, mientras que en VB.Net puede dejarse una de ellas (llamémosla "declaración principal") sin indicar que es parcial, y especificarlo en el resto de apariciones. En mi opinión, esta no es una práctica recomendable, por lo que aconsejaría utilizar el modificador
partial siempre que la clase lo sea, e independientemente del lenguaje utilizado, pues contribuirá a la mantenibilidad del código.El número de partes en las que se divide una clase es indiferente, el compilador tomará todas ellas y generará en el ensamblado como si fuera una clase normal.
Para comprobarlo he creado un pequeño código con dos clases exactamente iguales, salvo en su nombre. Una de ellas se denomina
PersonaTotal, y está definida como siempre, en un único archivo; la otra, PersonaParcial, es parcial y la he troceado en tres archivos, como sigue: // *** Archivo PersonaParcial.Propiedades.cs ***
// Aquí definiremos todas las propiedades
partial class PersonaParcial
{
public string Nombre { get; set; }
public string Apellidos { get; set; }
}
// *** Archivo PersonaParcial.IEnumerable.cs ***
// Aquí implementaremos el interfaz IEnumerable
partial class PersonaParcial: IEnumerable
{
public IEnumerator GetEnumerator()
{
throw new NotImplementedException();
}
}
// *** Archivo PersonaParcial.Metodos.cs ***
// Aquí implementaremos los métodos que necesitemos
partial class PersonaParcial
{
public override string ToString()
{
return Nombre + " " + Apellidos;
}
}
Y efectivamente, el resultado de compilar ambas clases, según se puede observar con ILDASM es idéntico:

A la hora de crear clases parciales es conveniente tener los siguientes aspectos en cuenta:
- Los atributos de la clase resultante serán la combinación de los atributos definidos en cada una de las partes.
- El tipo base de los distintos fragmentos debe ser el mismo, o aparecer sólo en una de las declaraciones parciales.
- Si se trata de una clase genérica, los parámetros deben coincidir en todas las partes.
- Los interfaces que implemente la clase resultante será la unión de todos los implementados por las distintas secciones.
- De la misma forma, los miembros (métodos, propiedades, campos...) de la clase final será la unión de todos los definidos en las distintas partes.
Vale, ya hemos visto qué son y cómo se usan, pero, ¿para qué sirven? ¿cuándo es conveniente utilizarlas? Pues bien, son varios los motivos de su existencia, algunos discutibles y otros realmente interesantes.
En primer lugar, no era sencillo que varios desarrolladores trabajaran sobre una misma clase de forma concurrente. Incluso utilizando sistemas de control de versiones (como Sourcesafe o Subversion), la unidad mínima de trabajo es el archivo de código fuente, y la edición simultánea podía generar problemas a la hora de realizar fusiones de las porciones modificadas por cada usuario.
En segundo lugar, permite que clases realmente extensas puedan ser troceadas para facilitar su comprensión y mantenimiento. Igualmente, puede utilizarse para separar código en base a distintos criterios:
- por ejemplo, separar la interfaz (los miembros visibles desde el exterior de la clase) y por otra los miembros privados a la misma
- o bien separar las porciones que implementan interfaces, o sobreescriben miembros de clases antecesoras de los pertenecientes a la propia clase
- o separar temas concernientes a distintos dominios o aspectos
Así, es posible que un desarrollador y un generador estén introduciendo cambios sobre la misma clase sin molestarse, cada uno jugando con su propia porción de la clase; el primero puede introducir funcionalidades sin preocuparse de que una nueva generación automática de código pueda machacar su trabajo. Visual Studio y otros entornos de desarrollo hacen uso intensivo de esta capacidad, por ejemplo, en los diseñadores visuales de Windows Forms, WPF, ASP.Net e incluso el generador de modelos de LinqToSql.
Publicado en: http://www.variablenotfound.com/.
viernes, 21 de marzo de 2008
 Como ya delantó Scottgu hace unas semanas mientras actualizaba el roadmap de este nuevo producto, desde hace unas horas es posible descargar el código fuente del ASP.Net Preview 2 a través de CodePlex. La descarga es una solución para Visual Studio 2008, desde la que se pueden generar los ensamblados de forma directa.
Como ya delantó Scottgu hace unas semanas mientras actualizaba el roadmap de este nuevo producto, desde hace unas horas es posible descargar el código fuente del ASP.Net Preview 2 a través de CodePlex. La descarga es una solución para Visual Studio 2008, desde la que se pueden generar los ensamblados de forma directa.Aunque su licencia no permite redistribuir los binarios resultantes para evitar que posibles versiones alternativas del framework circulen por ahí, es muy interesante, sin duda, ver las "tripas" de esta nueva criatura.
Y, por cierto, también carga en Visual C# 2008 Express Edition...
Publicado en: http://www.variablenotfound.com/.
sábado, 15 de marzo de 2008
 Ayer se anunció oficialmente la aparición de la versión 1.0 a través de la web del Proyecto Mono, en el blog de Miguel de Icaza y por supuesto, en la web del equipo de desarrollo de MonoDevelop.
Ayer se anunció oficialmente la aparición de la versión 1.0 a través de la web del Proyecto Mono, en el blog de Miguel de Icaza y por supuesto, en la web del equipo de desarrollo de MonoDevelop.Se trata de un entorno de desarrollo integrado (IDE) para la plataforma .NET en el que el equipo del proyecto Mono anda trabajando desde hace varios años. Su objetivo inicial era facilitar una herramienta libre y gratuita para Linux, MacOS e incluso Windows, que permita la creación de aplicaciones en C# y otros lenguajes .NET, aunque después ha evolucionado hasta convertirse en una plataforma extensible sobre la que podría encajar cualquier tipo de herramienta de desarrollo.
Las principales características de la herramienta son:
- Se trata de un entorno muy personalizable, permitiendo la creación de atajos de teclado, la redistribución de elementos en pantalla o inclusión de herramientas externas.
- Soporta varios lenguajes, como C#, VB.Net o C/C++ o incluso Boo y Java (IKVM) a través de plugins externos.
- Ayuda en la escritura del código (auto-completar, información de parámetros... al más puro estilo intellisense).
- Incluye herramientas de refactorización, como renombrado de tipos y miembros, encapsulación de campos, sobreescritura de métodos o autoimplementación de interfaces.
- Ayudas en la navegación a través del código, como saltar a las declaraciones de variables, o búsquedas de clases derivadas.
- Diseñador de interfaces para aplicaciones GTK# y soporte para librerías de widgets.
- Control de versiones integrado, con soporte para Subversion.
- Pruebas unitarias integradas, utilizando NUnit.
- Soporte para proyectos ASP.Net.
- Servidor web integrado (XSP) para pruebas.
- Explorador y editor de bases de datos integrados (aún en beta).
- Integración con Monodoc, para la documentación de clases.
- Soporte para makefiles, tanto para generación como para sincronización.
- Soporte para formatos de proyecto Visual Studio 2005.
- Sistema de empaquetado que genera tarballs, código fuente y binarios.
- Línea de comandos para generar y gestionar proyectos.
- Soporte para proyectos de localización.
- Arquitectura extensible a través de plugins.
Información mucho más detallada, eso sí, en inglés, en la web del proyecto.
Publicado en: http://www.variablenotfound.com/.
domingo, 9 de marzo de 2008
 Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.
Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.Una unión es muy similar a una estructura de datos (
struct en C# o Structure en VB.Net), salvo en un detalle: sus componentes se almacenan sobre las mismas posiciones de memoria. O visto desde el ángulo opuesto, una unión podríamos definirla como una porción de memoria donde se guardan varias variables, habitualmente de tipos diferentes. Veamos un ejemplo clásico que nos ayudará a entender el concepto, en un lenguaje cualquiera:union Ejemplo
{
char caracter; // suponiendo char de 8 bits
byte octeto; // un byte ocupa 8 bits
};Si declaramos una variable x del tipo Ejemplo, estaremos reservando un espacio de 8 bits al que accederemos desde cualquiera de sus miembros, como vemos a continuación:
x.caracter = 'A';
x.octeto ++;
escribir_char (x.caracter); // mostraría 'B'
escribir_byte (x.octeto); // mostraría 66
Pero espera... ¿memoria?... ¿almacenamiento de variables?... ¿pero existe eso en .Net?... Pues sí, aunque lo más normal es que no nos tengamos que enfrentar nunca a ello pues el framework realiza estas tareas por nosotros, hay escenarios en los que es necesario controlar la forma en que la información es almacenada en memoria, como cuando se esté operando a bajo nivel, por ejemplo creando estructuras específicas para llamar al API de Windows, o para facilitar el acceso a posiciones concretas de la información.
Desde la versión 1.1 de la plataforma .Net, disponemos del atributo StructLayout, que nos permite indicar en estructuras y clases cómo queremos representar en memoria la información de sus miembros. Básicamente, podemos indicar que:
- la información se almacene como el framework considere oportuno (
LayoutKind.Auto) - que se almacene de forma secuencial, en el mismo orden en el que han sido declarados (
LayoutKind.Sequential). - que se almacene donde le indiquemos de forma explícita (
LayoutKind.Explicit). En este caso, necesitaremos especificar en cada miembro la posición exacta de memoria donde será guardado, utilizando el atributoFieldOffset.
Es este último método el que nos interesa para nuestros propósitos. Si adornamos una estructura con
StructLayout(LayoutKind.Explicit) e indicamos en cada uno de sus miembros su desplazamiento (en bytes) dentro del espacio de memoria asignado a la misma, podemos conseguir uniones haciendo que todos ellos comiencen en la misma dirección.Pasemos a vamos a verlo con un ejemplo en C#. Se trata de una unión a la que podemos acceder tratándola como un carácter unicode, o bien como un entero de 16 bits con signo. Los dos miembros, llamados
Caracter y Valor están definidos sobre la misma posición de memoria (desplazamiento cero) en el interior de la estructura:using System.Runtime.InteropServices;
using System;
namespace PruebaUniones
{
[StructLayout(LayoutKind.Explicit)]
public struct UnionTest
{
[FieldOffset(0)] public char Caracter;
[FieldOffset(0)] public short Valor;
}
class Program
{
public static void Main()
{
UnionTest ut = new UnionTest();
ut.Caracter = 'A';
ut.Valor ++;
Console.WriteLine(ut.Caracter); // Muestra "B"
Console.ReadKey();
return;
}
}
}Ahora usaremos VB.NET para mostrar otro ejemplo un poco más complejo que el anterior, donde usamos una unión para descomponer una palabra de 16 bits en los dos bytes que la componen, permitiendo la manipulación de forma directa e independiente de cada una de las dos visiones del valor almacenado en memoria. Para el ejemplo utilizo una unión dentro de otra, aunque no era estrictamente necesario, para que veáis que esto es posible.
Imports System.Runtime.InteropServices
<StructLayout(LayoutKind.Explicit)> _
Public Structure Union16
<FieldOffset(0)> Dim Word As Int16
<FieldOffset(0)> Dim Bytes As Bytes
End Structure
<StructLayout(LayoutKind.Explicit)> _
Public Structure Bytes
<FieldOffset(0)> Dim Bajo As Byte
<FieldOffset(1)> Dim Alto As Byte
End Structure
Public Class Program
Public Shared Sub main()
Dim u As New Union16
u.Word = 513 ' 513 = 256*1 (Byte alto) + 1 (byte bajo)
u.Bytes.Alto += 1
Console.WriteLine("Word: " & u.Word) ' Muestra 769 (3*256+1)
Console.WriteLine("Byte alto: " & u.Bytes.Alto) ' Muestra 3
Console.WriteLine("Byte bajo: " & u.Bytes.Bajo) ' Muestra 1
Console.ReadKey()
Console.ReadKey()
End Sub
End Class
He encontrado un uso muy interesante para esta técnica en Xtreme .Net Talk, donde se muestra un ejemplo de cómo acceder a los componentes de color de un pixel de forma muy eficiente a través de una unión entre el valor ARGB (32 bits) y cada uno de los bytes que lo componen (alfa, rojo, verde y azul).
En cualquier caso no se recomienda el uso de uniones salvo en casos muy concretos, y siempre conociendo bien las implicaciones que puede tener en la estabilidad y mantenibilidad del sistema.
Pero bueno, ¡está bien al menos saber que existen!
Publicado en: http://www.variablenotfound.com/.
lunes, 3 de marzo de 2008
 Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.
Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.En esta ocasión vamos a centrarnos en los inicializadores de objetos, una nueva característica destinada, entre otras cosas, a ahorrarnos tiempo a la hora de establecer los valores iniciales de los objetos que creemos desde código.
Y es que, hasta ahora, podíamos utilizar dos patrones básicos de inicialización de propiedades al instanciar una clase:
- que fuera la clase la que realizara esta tarea, ofreciendo al usuario de la misma constructores con distintas sobrecargas cuyos parámetros corresponden con las propiedades a inicializar.
// Constructor de la clase Persona:
public Persona(string nombre, string apellidos, int edad, ...)
{
this.Nombre = nombre;
this.Apellidos = apellidos;
this.Edad = edad;
...
}
// Uso:
Persona p = new Persona("Juan", "López", 32, ...); - o bien dejar esta responsabilidad al usuario, permitiéndole el acceso directo a propiedades o campos del objeto creado.
// Uso:
Persona p = new Persona();
p.Nombre = "Juan";
p.Apellidos = "López";
p.Edad = 32;
...
Los inicializadores de objetos permiten, en C# y VB.Net, realizar esta tarea de forma más sencilla, indicando en la llamada al constructor el valor de las propiedades o campos que deseemos establecer:
// C#:
Persona p = new Persona { Nombre="Juan", Apellidos="López", Edad=32 };
' VB.NET:
Dim p = New Persona With {.Nombre="Luis", .Apellidos="López", .Edad=32 }
Los ejemplos anteriores son válidos para clases que admitan constructores sin parámetros, pero, ¿qué ocurre con los demás? Imaginando que el constructor de la clase
Persona recibe obligatoriamente dos parámetros, su nombre y apellidos, podríamos instanciar así:
// C#:
Persona p = new Persona ("Luis", "López") { Edad = 32 };
' VB.NET:
Dim p = New Persona ("Luis", "López") With { .Edad = 32 }
Aunque es obvio, es importante tener en cuenta que las inicializaciones (la porción de código entre llaves "{" y "}") se ejecutan después del constructor:
// C#:
Persona p = new Persona ("Juan", "Pérez") { Nombre="Luis" };
Console.WriteLine(p.Nombre); // Escribe "Luis"
' VB.NET:
Dim p = New Persona ("Juan", "Pérez") With { .Nombre="Luis" }
Console.WriteLine(p.Nombre); ' Escribe "Luis"
Y un último apunte: ¿cómo inicializaríamos propiedades de objetos que a su vez sean objetos que también queremos inicializar? Suponiendo que en nuestra clase
Persona hemos incluido una propiedad llamada Domicilio que de tipo Localizacion, podríamos inicializar el bloque completo así:
// C#:
// Se han cortado las líneas para facilitar la lectura
Persona p = new Persona()
{
Nombre = "Juan",
Apellidos = "López",
Edad = 55,
Domicilio = new Localizacion
{
Direccion = "Callejas, 34",
Localidad = "Sevilla",
Provincia = "Sevilla"
}
};
' VB.NET:
' Se han cortado las líneas para facilitar la lectura
Dim p = New Persona() With { _
.Nombre = "Juan", _
.Apellidos = "López", _
.Edad = 55, _
.Domicilio = New Localizacion With { _
.Direccion = "Callejas, 23", _
.Localidad = "Sevilla", _
.Provincia = "Sevilla" _
} _
}
En fin, que de nuevo tenemos ante nosotros una característica de estos lenguajes que resulta interesante por sí misma, aunque toda su potencia y utilidad podremos percibirla cuando profundicemos en otras novedades, como los tipos anónimos y Linq... aunque eso será otra historia.
Publicado en: http://www.variablenotfound.com/.
domingo, 20 de enero de 2008
FxCop es una herramienta que nos ayuda a mejorar la calidad de nuestras aplicaciones y librerías desarrolladas en cualquier versión de .Net, analizando de forma automática nuestros ensamblados desde distintas perspectivas y sugiriéndonos mejoras cuando detecta algún problema o incumplimiento de las pautas de diseño para desarrolladores de librerías para .Net Framework (Design Guidelines for Class Library Developers).
La versión actual (1.35) se puede descargar desde esta dirección, aunque ya existe una beta de la v1.36 en la web de Microsoft. Todos los comentarios que siguen se refieren a esta última versión, la 1.36 (beta), osado que es uno ;-), pero la mayor parte son válidos para la última revisión estable, la 1.35.
Una vez instalado tendremos a nuestra disposición dos aplicaciones: FxCop, que facilita el análisis y consulta de resultados a través de su propia GUI, y FxCopCmd, ideada para su utilización desde línea de comandos e integrarlo en otros sistemas, como Visual Studio, como parte del proceso de construcción (build) automatizado.
En cualquiera de los dos casos, el análisis de los ensamblados se realiza sometiéndolos a la comprobación de una serie de reglas basadas en buenas prácticas y consejos para asegurar la robustez y mantenibilidad de código. Del resultado del mismo obtendremos un informe con advertencias agrupadas en las siguientes categorías:
(Puedes ver la lista completa de comprobaciones, en inglés, aquí)
 Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
El tiempo dependerá del número y complejidad de los ensamblados a analizar, así como del conjunto de reglas (pestaña "rules") a aplicar, que por defecto serán todas. En cualquier caso, el proceso es rápido y finalizará con la presentación de una lista con el resumen de las anomalías detectadas, sobre la que podremos navegar y ampliar información.

Por cada anomalía, además, podremos acceder a una descripción completa de sus causas, origen en el código fuente, posibles soluciones, una URL para ampliar información, grado de certeza de existencia del problema, su gravedad y la categoría a la que pertenece. Con estos datos, sólo nos quedará acudir a nuestro código y corregir o mejorar los aspectos indicados.
En conclusión, se trata de una interesante herramienta que puede ayudarnos a mejorar la calidad del código que creamos. Aunque existen los "falsos positivos" y a veces no es todo lo precisa que debiera, la gran cantidad de comprobaciones que realiza, la posibilidad de añadir reglas personalizadas, así como el detalle de los informes de resultados hacen de ella una utilidad casi imprescindible para los desarrolladores .Net.
Publicado originalmente en: http://www.variablenotfound.com/.
La versión actual (1.35) se puede descargar desde esta dirección, aunque ya existe una beta de la v1.36 en la web de Microsoft. Todos los comentarios que siguen se refieren a esta última versión, la 1.36 (beta), osado que es uno ;-), pero la mayor parte son válidos para la última revisión estable, la 1.35.
Una vez instalado tendremos a nuestra disposición dos aplicaciones: FxCop, que facilita el análisis y consulta de resultados a través de su propia GUI, y FxCopCmd, ideada para su utilización desde línea de comandos e integrarlo en otros sistemas, como Visual Studio, como parte del proceso de construcción (build) automatizado.
En cualquiera de los dos casos, el análisis de los ensamblados se realiza sometiéndolos a la comprobación de una serie de reglas basadas en buenas prácticas y consejos para asegurar la robustez y mantenibilidad de código. Del resultado del mismo obtendremos un informe con advertencias agrupadas en las siguientes categorías:
- Advertencias de diseño, recoge avisos de incumplimientos de buenas prácticas de diseño para .Net Framework, como pueden uso de constructores públicos en tipos abstractos, interfaces o namespaces vacíos, uso de parámetros out, capturas de excepciones genéricas y un largo etcétera.
- Advertencias de globalización, que avisan de problemas relacionados con la globalización de aplicaciones y librerías, como pueden ser el uso de aceleradores de teclado duplicados, inclusión de rutas a carpetas de sistema dependientes del idioma ("archivos de programa"), etc.
- Advertencias de interoperabilidad, que analizan problemas relativos al soporte de interacción con clientes COM, como el uso de tipos auto layout visibles a COM, utilización de
System.Int64en argumentos (que no pueden ser usados por clientes VB6), o la sobrecarga de métodos. - Advertencias de movilidad, cuestionando el soporte eficiente de características de ahorro de energía, como uso de procesos con prioridad
ProcessPriorityClass.Idle., o inclusión deTimersque se repitan más de una vez por segundo. - Advertencias de nombrado, que detectan las faltas de cumplimiento de las guías y prácticas recomendadas en cuanto al nombrado de elementos (clases, métodos, variables, etc.), como uso de nombres de parámetros que coinciden con nombres de tipo, y más con los propios de un lenguaje concreto, mayúsculas y minúsculas no utilizadas correctamente, eventos que comiencen por "Before" o "After", puesto que deben nombrarse conjugando verbos en función del momento que se producen (p.e., Closing y Closed en lugar de BeforeClose y AfterClose), y un largo conjunto de comprobaciones.
- Advertencias de rendimiento, que ayudan a detectar problemas en el rendimiento de la aplicación o librería, comprobando puntos como el número de variables locales usadas, la existencia de miembros privados o internos (a nivel de ensamblado) no usados, creación de cadenas (strings) innecesarias, por llamadas múltiples a
ToLower()oToUpper()sobre la misma instancia, realización de conversiones (castings) innecesarios, concatenaciones de cadenas en bucles, etc. - Advertencias de portabilidad, que recoge observaciones interesantes para la portabilidad a distintas plataformas, como el uso de declaraciones PInvoke.
- Advertencias de seguridad, que se centran en analizar aspectos que podrían dar lugar a aplicaciones o librerías inseguras, avisando de problemas potenciales como la ausencia de directivas de seguridad, punteros visibles, o uso de arrays de sólo lectura, entre otros.
- Advertencias de uso, que analizan el uso apropiado del framework .Net realizando multitud de chequeos sobre el código, detectando aspectos como ausencia la liberación (dispose) explícita de tipos
IDisposable, resultados de métodos no usados, uso incorrecto de NaN, etc.
(Puedes ver la lista completa de comprobaciones, en inglés, aquí)
 Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.El tiempo dependerá del número y complejidad de los ensamblados a analizar, así como del conjunto de reglas (pestaña "rules") a aplicar, que por defecto serán todas. En cualquier caso, el proceso es rápido y finalizará con la presentación de una lista con el resumen de las anomalías detectadas, sobre la que podremos navegar y ampliar información.

Por cada anomalía, además, podremos acceder a una descripción completa de sus causas, origen en el código fuente, posibles soluciones, una URL para ampliar información, grado de certeza de existencia del problema, su gravedad y la categoría a la que pertenece. Con estos datos, sólo nos quedará acudir a nuestro código y corregir o mejorar los aspectos indicados.
En conclusión, se trata de una interesante herramienta que puede ayudarnos a mejorar la calidad del código que creamos. Aunque existen los "falsos positivos" y a veces no es todo lo precisa que debiera, la gran cantidad de comprobaciones que realiza, la posibilidad de añadir reglas personalizadas, así como el detalle de los informes de resultados hacen de ella una utilidad casi imprescindible para los desarrolladores .Net.
Publicado originalmente en: http://www.variablenotfound.com/.





