
martes, 18 de noviembre de 2008
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
domingo, 16 de noviembre de 2008
 En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.
En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.Durante el año que ha transcurrido desde entonces los archivos de NiftyDotNet han sido descargados 1000 veces (bueno, exactamente 998), he recibido muchos mensajes con cuestiones, sugerencias, y algunos bugs que he aprovechado para corregir en esta nueva revisión, que he creído conveniente ya numerarla como 1.0, para no seguir la estrategia de Google de la eterna beta ;-)
Además de algún cambio menor en el proyecto de demostración, han sido corregidos los siguiente problemas:
- Un error de Javascript que aparecía cuando el control no encontraba ningún elemento en la página que correspondiera con los selectores indicados y había sido especificada además la propiedad Fixed-Height.
- En páginas cuya sección HEAD no incluía el atributo RUNAT="SERVER" se mostraban caracteres extraños en pantalla, y no se redondeaban los elementos de la página.
Enlaces:
Publicado en: www.variablenotfound.com.
domingo, 9 de noviembre de 2008
 Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.
Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.Por una parte, a finales del pasado mes de octubre se publicó en el sitio de descargas de jQuery, y apareció enlazado desde su propia web oficial, el archivo de anotaciones que permite el disfrute de la experiencia intellisense en todo su esplendor mientras utilizamos la librería desde Visual Studio 2008: información completa sobre los métodos que estamos usando, parámetros, valores de retorno, y autocompletado de escritura. Una gozada, vaya.
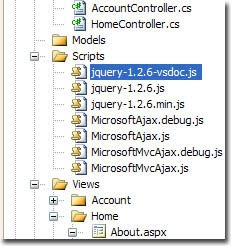 Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.
Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.Por otra parte, sólo unos días después, Microsoft ha publicado el hotfix KB958502 para Visual Studio 2008 Service Pack 1 (y válido también para Visual Web Developer Express SP1) que hace que el entorno sea capaz de buscar automáticamente los archivos de documentación relativos a cada librería javascript que estemos utilizando, y tomar de ellos la información para activar intellisense. De hecho, por cada archivo javascript referenciado desde nuestro código con un nombre "xxx.js", el entorno buscará la documentación en el archivo "xxx-vsdocs.js"; si no la encuentra, probará con "xxx.debug.js", y si tampoco hay nada, dentro de la propia librería "xxx.js".
Por tanto, una vez instalado este parche, si estás utilizando jQuery directamente sobre una página .ASPX, algo muy habitual, basta con descargar el archivo de anotaciones e incluirlo en el directorio de scripts del proyecto para que la magia intellisense comience a funcionar en todas las páginas en las que exista una referencia hacia jQuery (un tag
<script src="...">), o que se basen en una página maestra que incluya dicha referencia.
Si estás editando un fichero javascript (.js) en Visual Studio y desde él quieres utilizar jQuery con intellisense, puedes utilizar un comentario con la etiqueta
Reference, que indica al entorno que puede tomar la documentación de los archivos indicados en la misma. Basta con encabezar el archivo .js así: /// <reference path="jquery-1.2.6-vsdoc.js">
El comentario, obviamente, no afecta a la ejecución, y sólo es interpretado por el IDE para buscar referencias a archivos de documentación.
Por último, como apunta Jeff King, Program Manager en el equipo de herramientas para la Web de Visual Studio, es conveniente aclarar que el objetivo de este parche no es únicamente dar soporte a jQuery; se trata de una solución general para facilitar la integración de documentación de librerías javascript en el entorno de desarrollo, y que seguro vamos a poder aprovechar en muchas otras ocasiones.
Publicado en: www.variablenotfound.com.
martes, 4 de noviembre de 2008
 El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
[...] Me parece muy interesante crear diccionarios utilizando tipos anónimos, pues simplifica de una forma considerable la cantidad de código que hay que escribir para conseguir llenar una estructura de este tipo. De hecho, estoy pensando en utilizar esta técnica en una librería que estoy desarrollando, pero no veo claro cómo transformar después ese objeto anónimo en el diccionario equivalente [...]
Verás que la idea es muy simple. Sólo necesitamos encontrar una fórmula que nos permita recorrer las propiedades del objeto, y por cada una de ellas, añadir la entrada correspondiente en el diccionario, especificando como clave el nombre de la propiedad y como valor el que tenga establecido la misma.
Una posibilidad muy sencilla es usar la clase
TypeDescriptor, cuyo método GetProperties() nos devuelve una colección con los descriptores de las propiedades de la instancia que le pasemos como parámetro. Iterando sobre este conjunto, podremos ir llenando el diccionario con los elementos que nos interese, tal que así, dado un objeto llamado obj: Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
Pero vamos a dar una vuelta de tuerca más. Partiendo del código anterior, es muy fácil crear un método de extensión sobre la clase
object, de forma que podamos convertir en un diccionario cualquier objeto de nuestras aplicaciones, con toda la potencia y comodidad que nos aporta esta técnica.El código sería:
public static class Extensions
{
public static Dictionary<string, object> ToDictionary(this object obj)
{
Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
return dicc;
}
}
De esta forma, dispondremos de una potente forma de "diccionarizar" nuestras instancias, sean del tipo que sean, por ejemplo:
var juan = new { nombre = "Juan", edad = 23 };
Dictionary<string, object> dicc = juan.ToDictionary();
Console.WriteLine(dicc["nombre"]); // Escribe "Juan"
var dicc2 = "hola".ToDictionary();
Console.WriteLine(dicc2["Length"]); // Escribe 4
Espero que te sea de ayuda, Leo. ¡Y gracias por participar en Variable Not Found!
Publicado en: www.variablenotfound.com.
domingo, 2 de noviembre de 2008
 Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).
Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).Conozco sistemas ORM, y en especial NHibernate, que ayudan a aliviar en gran parte esta falta de concordancia, por lo que estaba deseando ver la gran apuesta de Microsoft en este ámbito, máxime después de juguetear con su hermano pequeño, y quizás ya difunto, Linq to SQL, y ver que se quedaba bastante corto en muchos aspectos.
El libro "ADO.NET Entity Framework. Aplicaciones y servicios centrados en datos" publicado por Krasis Press hace algo más de un mes, me ha parecido una lectura muy recomendable para acercarse a esta nueva tecnología de la mano de fenónemos como Unai Zorrilla, Octavio Hernández y Eduardo Quintás.
Comienza con una breve introducción en la que se explica la necesidad de tecnologías que ayuden a salvar la distancia entre el mundo relacional de las bases de datos y el mundo más conceptual, presentado como modelos de clases a nivel de diseño software, ofreciendo seguidamente una descripción general de este nuevo marco de trabajo. A partir de ahí, va profundizando en los distintos componentes de Entity Framework, siempre de forma muy práctica y basándose en ejemplos bastante cercanos a la realidad. Se recogen, entre otros, los siguientes contenidos:
- Creación de modelos conceptuales, usando tanto los diseñadores de Visual Studio como modificando a mano los archivos XML que describen el modelo, útil para acceder a características no soportadas por el IDE.
- Entity Client, el proveedor ADO.NET para acceso, aunque algo rudimentario, a datos del modelo
- eSQL, el lenguaje de consulta de Entity Framework.
- Implementación de consultas con
ObjectQuery<T>y Linq to Entities. - Mecanismos de actualización de datos, incluyendo las técnicas de seguimiento de cambios en objetos, transaccionalidad y concurrencia, entre otros aspectos.
- Ejemplos de uso de Entity Framework con WCF, enlaces a datos desde controles Windows Forms, WPF o ASP.NET.
- Servicios de datos de ADO.NET, el mecanismo de publicación de modelos de Entity Framework a través de HTTP.
En definitiva, se trata en mi opinión de un libro muy claro y didáctico, recomendable para desarrolladores que quieran obtener un buen nivel de conocimiento de esta nueva tecnología partiendo desde cero, y para tener siempre a mano cuando comencemos a practicar y utilizar Entity Framework.
Desde la web de la editorial se puede descargar el índice y varias páginas de la introducción en PDF, lo que os permitirá echarle un vistazo, así como realizar el pedido online.
Publicado en: www.variablenotfound.com.
martes, 28 de octubre de 2008
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.





