
Mostrando entradas con la etiqueta programación. Mostrar todas las entradas
Mostrando entradas con la etiqueta programación. Mostrar todas las entradas
martes, 22 de abril de 2008
Buscando información sobre los operadores estándar de consulta de Linq, me he topado en ASP.NET Resources con una chuleta (cheat sheet) que nos puede valer para tener siempre a mano una referencia rápida de los mismos, y de paso, adornar alguna pared que tengamos vacía ;-).
Puedes descargarla pulsando sobre la imagen:

Si quieres leer más sobre estos operadores, puedes probar también en la referencia oficial, The .Net Standard Query Operators [ING], a leer este artículo traducido por el maestro Octavio Hernández, profundizar en MSDN, o en otros de los muchos sitios con información relacionada, como la referencia de Hooked On Linq [ING].
Publicado en: http://www.variablenotfound.com/.
Puedes descargarla pulsando sobre la imagen:
Si quieres leer más sobre estos operadores, puedes probar también en la referencia oficial, The .Net Standard Query Operators [ING], a leer este artículo traducido por el maestro Octavio Hernández, profundizar en MSDN, o en otros de los muchos sitios con información relacionada, como la referencia de Hooked On Linq [ING].
Publicado en: http://www.variablenotfound.com/.
martes, 15 de abril de 2008
 Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".
Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".Recordemos que una parte de una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el compilador eliminará tanto la declaración del método como las llamadas que se hagan al mismo.
Sin embargo esta eliminación pueden causar efectos no deseados difíciles de detectar.
Veámoslo con un ejemplo. Supongamos una clase parcial como la siguiente, que representa a una variable de tipo entero que puede ser incrementada o decrementada a través de métodos:
public partial class Variable
{
partial void Log(string msg);
private int i = 0;
public void Inc()
{
i++;
Log("Incremento. I: " + i);
}
public void Dec()
{
Log("Decremento. I: " + (--i));
}
public int Value
{
get { return i; }
}
}
Creamos ahora un código que utiliza esta clase de forma muy simple: crea una variable, la incrementa dos veces, la decrementa una vez y muestra el resultado:
Variable v = new Variable();
v.Inc();
v.Inc();
v.Dec();
Console.WriteLine(v.Value);
Obviamente, tras la ejecución de este código la pantalla mostrará por consola un "1", ¿no? Claro, el resultado de realizar dos incrementos y un decremento sobre el cero.
Pues no necesariamente. De hecho, es imposible conocer, a la vista del código mostrado hasta ahora, cuál será el resultado mostrado por consola al finalizar la ejecución. Dependiendo de la existencia de la implementación del método parcial
Log(), declarado e invocado en la clase Variable anterior, puede ocurrir:- Si existe otra porción de la misma clase (otra
partial class Variable) donde se implemente el método, se ejecutará éste. El valor mostrado por consola, salvo que desde esta implementación se modificara el valor del campo privado, sería "1". - Si no existe una implementación del método
Log()en la clase, el compilador eliminará todas las llamadas al mismo. Pero si observáis, esto incluye el decremento del valor interno, que estaba en el interior de la llamada como un autodecremento:
Por tanto, en este caso, el compilador eliminará tanto la llamada aLog("Decremento. I: " + (--i));Log()como la operación que se realiza en el interior. Obviamente, el resultado de ejecución de la prueba anterior sería "2".
Lo mismo ocurriría si el resultado a mostrar fuera el valor de retorno de una llamada a otra función: esta no se ejecutaría, lo cual puede ser grave si en ella se realiza una operación importante, como por ejemplo:public function InicializaValores()
{
Log("Elementos reestablecidos: " + reseteaElementos() );
}
Por ejemplo, imaginad que el ejemplo anterior contiene una implementación de
Log(); la aplicación funcionaría correctamente. Sin embargo, si pasado un tiempo se decide eliminar esta implementación (por ejemplo, porque ya no es necesario registrar las operaciones realizadas), la operación de decremento (Dec()) dejaría de funcionar. Aunque, eso sí, no es nada que no se pueda solucionar con un buen juego de pruebas...
Publicado en: http://www.variablenotfound.com/.
domingo, 13 de abril de 2008
 Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.
Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.Estos métodos, declarados en el contexto de una clase parcial, permiten comunicar de forma segura los distintos fragmentos de dicha clase. De forma similar a los eventos, permiten que un código incluya una llamada a una función que puede (o no) haber sido implementada por un código cliente, aunque en este caso obligatoriamente la implementación se encontrará en uno de los fragmentos de la misma clase desde donde se realiza la llamada.
En la práctica significa que una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el código correspondiente a la llamada será eliminado en tiempo compilación para optimizar el resultado... ¡sí, eliminado!
Por ejemplo, el siguiente código muestra una declaración de un método parcial en el interior de una clase, y su utilización desde dentro de uno de sus métodos:
// C#
public partial class Ejemplo
{
// El método parcial se declara
// sin implementación...
partial void Log(string msg);
public void RealizarAlgo()
{
hacerAlgoComplejo();
Log("¡Ojo!"); // Usamos el método
// parcial declarado antes
}
[...] // Otros métodos y propiedades
}
' VB.NET
Partial Public Class Ejemplo
' El método parcial se declara, sin
' implementar nada en el cuerpo
Partial Private Sub Log(ByVal msg As String)
End Sub
Public Sub RealizarAlgo()
HacerAlgoComplejo()
Log("¡Ojo!") ' Usamos el método parcial
End Sub
[...] ' Otros métodos y propiedades
End Class
Y esta la parte realmente curiosa. Cuando el compilador detecta la invocación del método parcial
Log(), buscará en todos los fragmentos de la clase a ver si existe una implementación del mismo. Si no existe, eliminará del ensamblado resultante la llamada a dichos métodos, es decir, actuará como si éstas no existieran en el código fuente.En caso afirmativo, es decir, si existen implementaciones como las del siguiente ejemplo, todo se ejecutará conforme a lo previsto:
// C#
public partial class Ejemplo
{
partial void Log(string msg)
{
Console.WriteLine(msg);
}
}
' VB.Net
Partial Public Class Ejemplo
Private Sub Log(ByVal msg As String)
Console.WriteLine(msg)
End Sub
End Class
Antes comentaba que los métodos parciales son, en cierto sentido, similares a los eventos, pues conceptualmente permiten lo mismo: pasar el control a un código cliente en un momento dado, en el caso de que éste exista. De hecho, hay muchos desarrolladores que lo consideran como un sustituto ligero a los eventos, pues permite prácticamente lo mismo pero se implementan de forma más sencilla.
Existen, sin embargo, algunas diferencias entre ambos modelos, como:
- Los métodos parciales se implementan en la propia clase, mientras que los eventos pueden ser consumidos también desde cualquier otra
- El enlace, o la suscripción, a eventos es dinámica, se realiza en tiempo de ejecución, es necesario incluir código para ello; los métodos parciales, sin embargo, se vinculan en tiempo de compilación
- Los eventos permiten múltiples suscripciones, es decir, asociarles más de un código cliente
- Los eventos pueden presentar cualquier visibilidad (pública, privada...), mientras que los métodos parciales son obligatoriamente privados.
Por último, es conveniente citar algunas consideraciones sobre los métodos parciales:
- Deben ser siempre privados (ya lo había comentado antes)
- No deben devolver valores (en VB.Net serían
SUB, en C# serían de tipovoid) - Pueden ser estáticos (shared en VB)
- Pueden usar parámetros, acceder a los miembros privados de la clase... en definitiva, actuar como un método más de la misma
En resumen, los métodos parciales forman parte del conjunto de novedades de C# y VB.Net que no son absolutamente necesarias y que a veces pueden parecer incluso diabólicas, pues facilitan la dispersión de código y dificultan la legibilidad. Además, en breve publicaré un post comentando posibles efectos laterales a tener en cuenta cuando usemos los métodos parciales en nuestros desarrollos.
Sin embargo, es innegable que los métodos parciales nos facilitan enormemente la inclusión de código de usuario en el interior de clases generadas de forma automática. Por ejemplo, el diseñador visual del modelo de datos de LinqToSQL genera los
DataContext como clases parciales, en las que define un método parcial llamado OnCreated(). Si el usuario quiere incluir alguna inicialización personal al crear los DataContext, no tendrá que tocar el código generado de forma automática; simplemente creará otro fragmento de la clase parcial e implementará este método, de una forma mucho más natural y cómoda que si se tratara de un evento.Publicado en: http://www.variablenotfound.com/.
domingo, 6 de abril de 2008
 Semanas atrás publicaba el post "101 citas célebres del mundo de la informática", la traducción del post original de Timm Martin en Devtopics, "101 Great computer quotes". El tema me pareció tan divertivo e interesante que he realizado una nueva recopilación de otras tantas frases relacionadas con el mundo de la informática, y con especial énfasis en el desarrollo de software.
Semanas atrás publicaba el post "101 citas célebres del mundo de la informática", la traducción del post original de Timm Martin en Devtopics, "101 Great computer quotes". El tema me pareció tan divertivo e interesante que he realizado una nueva recopilación de otras tantas frases relacionadas con el mundo de la informática, y con especial énfasis en el desarrollo de software.Este es el segundo post de la serie compuesta por:
- 101 citas célebres del mundo de la informática
- Otras 101 citas célebres del mundo de la informática (este post)
- Y todavía otras 101 citas célebres del mundo de la informática
- 101 nuevas citas célebres del mundo de la informática (¡y van 404!)
miércoles, 2 de abril de 2008
Aunque las clases parciales aparecieron hace unos años, con la llegada de .Net 2.0 y Visual Studio 2005, vamos a hacer un breve repaso como preparación para un próximo post que trate los métodos parciales.Las clases parciales (llamados también tipos parciales) son una característica presente en algunos lenguajes de programación, como C# y VB.Net, que permiten que la declaración de una clase se realice en varios archivos de código fuente, rompiendo así la tradicional regla "una clase, un archivo". Será tarea del compilador tomar las porciones de los distintos archivos y fundirlas en una única entidad.
En VB.Net y C#, a diferencia de otros lenguajes, es necesario indicar explícitamente que una clase es parcial, es decir, que es posible que haya otros archivos donde se continúe la declaración de la misma, usando en ambos con la palabra clave
partial en la definición del tipo: ' VB.NET
Public Partial Class Persona
...
End Class
// C#
public partial class Persona
{
...
}
En este código hemos visto cómo se declara una clase parcial en ambos lenguajes, que es prácticamente idéntica salvo por los detalles sintácticos obvios. Por ello, a partir de este momento continuaré introduciendo los ejemplos sólo en C#.
Pero antes un inciso: la única diferencia entre ambos, estrictamente hablando, es que C# obliga a que todas las apariciones de la clase estén marcadas como parciales, mientras que en VB.Net puede dejarse una de ellas (llamémosla "declaración principal") sin indicar que es parcial, y especificarlo en el resto de apariciones. En mi opinión, esta no es una práctica recomendable, por lo que aconsejaría utilizar el modificador
partial siempre que la clase lo sea, e independientemente del lenguaje utilizado, pues contribuirá a la mantenibilidad del código.El número de partes en las que se divide una clase es indiferente, el compilador tomará todas ellas y generará en el ensamblado como si fuera una clase normal.
Para comprobarlo he creado un pequeño código con dos clases exactamente iguales, salvo en su nombre. Una de ellas se denomina
PersonaTotal, y está definida como siempre, en un único archivo; la otra, PersonaParcial, es parcial y la he troceado en tres archivos, como sigue: // *** Archivo PersonaParcial.Propiedades.cs ***
// Aquí definiremos todas las propiedades
partial class PersonaParcial
{
public string Nombre { get; set; }
public string Apellidos { get; set; }
}
// *** Archivo PersonaParcial.IEnumerable.cs ***
// Aquí implementaremos el interfaz IEnumerable
partial class PersonaParcial: IEnumerable
{
public IEnumerator GetEnumerator()
{
throw new NotImplementedException();
}
}
// *** Archivo PersonaParcial.Metodos.cs ***
// Aquí implementaremos los métodos que necesitemos
partial class PersonaParcial
{
public override string ToString()
{
return Nombre + " " + Apellidos;
}
}
Y efectivamente, el resultado de compilar ambas clases, según se puede observar con ILDASM es idéntico:

A la hora de crear clases parciales es conveniente tener los siguientes aspectos en cuenta:
- Los atributos de la clase resultante serán la combinación de los atributos definidos en cada una de las partes.
- El tipo base de los distintos fragmentos debe ser el mismo, o aparecer sólo en una de las declaraciones parciales.
- Si se trata de una clase genérica, los parámetros deben coincidir en todas las partes.
- Los interfaces que implemente la clase resultante será la unión de todos los implementados por las distintas secciones.
- De la misma forma, los miembros (métodos, propiedades, campos...) de la clase final será la unión de todos los definidos en las distintas partes.
Vale, ya hemos visto qué son y cómo se usan, pero, ¿para qué sirven? ¿cuándo es conveniente utilizarlas? Pues bien, son varios los motivos de su existencia, algunos discutibles y otros realmente interesantes.
En primer lugar, no era sencillo que varios desarrolladores trabajaran sobre una misma clase de forma concurrente. Incluso utilizando sistemas de control de versiones (como Sourcesafe o Subversion), la unidad mínima de trabajo es el archivo de código fuente, y la edición simultánea podía generar problemas a la hora de realizar fusiones de las porciones modificadas por cada usuario.
En segundo lugar, permite que clases realmente extensas puedan ser troceadas para facilitar su comprensión y mantenimiento. Igualmente, puede utilizarse para separar código en base a distintos criterios:
- por ejemplo, separar la interfaz (los miembros visibles desde el exterior de la clase) y por otra los miembros privados a la misma
- o bien separar las porciones que implementan interfaces, o sobreescriben miembros de clases antecesoras de los pertenecientes a la propia clase
- o separar temas concernientes a distintos dominios o aspectos
Así, es posible que un desarrollador y un generador estén introduciendo cambios sobre la misma clase sin molestarse, cada uno jugando con su propia porción de la clase; el primero puede introducir funcionalidades sin preocuparse de que una nueva generación automática de código pueda machacar su trabajo. Visual Studio y otros entornos de desarrollo hacen uso intensivo de esta capacidad, por ejemplo, en los diseñadores visuales de Windows Forms, WPF, ASP.Net e incluso el generador de modelos de LinqToSql.
Publicado en: http://www.variablenotfound.com/.
domingo, 30 de marzo de 2008
 Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.
Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.Google nos tiene acostumbrados a implementar APIs muy sencillas de usar, y en este caso no podía ser menos. Para demostrarlo, vamos a crear una página web con un sencillo traductor en Javascript, comentando paso por paso lo que hay que hacer para que podáis adaptarlo a vuestras necesidades.
Paso 1: Incluir el API
La inclusión de las funciones necesarias para realizar la traducción es muy sencilla. Basta con incluir el siguiente código, por ejemplo, en la sección HEAD de la página: <script type="text/javascript"
src="http://www.google.com/jsapi">
</script>
<script type="text/javascript">
google.load("language", "1");
</script>
El primer bloque descarga a cliente la librería javascript Ajax API Loader, el cargador genérico de librerías Ajax utilizado por Google. Éste se usa en el segundo bloque script para cargar, llamando a la función
google.load el API "language" (traductor), en su versión 1 (el segundo parámetro).Paso 2: Creamos el interfaz
Nuestro traductor será realmente simple. Además, vamos a contemplar un pequeño subconjunto de los idiomas permitidos para no complicar mucho el código, aunque podéis añadir todos los que consideréis necesarios.El resultado será como el mostrado en la siguiente imagen.

El código fuente completo lo encontraréis al final del post, por lo que no voy a repetirlo aquí. Simplemente indicar que tendremos un
TextArea donde el usuario introducirá el texto a traducir, dos desplegables con los idiomas origen y destino de la traducción, y un botón que iniciará la acción a través del evento onclick. Por último, se reservará una zona en la que insertaremos el resultado de la traducción.Ah, un detalle interesante: en el desplegable de idiomas de origen se ha creado un elemento en el desplegable "Auto", cuyo valor es un string vacío; esto indicará al motor de traducción que infiera el idioma a partir del texto enviado.
Paso 3: ¡Traducimos!
La pulsación del botón provocará la llamada a la funciónOnclick(), desde donde se realizará la traducción del texto introducido en el TextArea.Como podréis observar en el código, en primer lugar obtendremos los valores de los distintos parámetros, el texto a traducir y los idiomas origen y destino, y lo introducimos en variables para facilitar su tratamiento.
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
Acto seguido, realizamos la llamada al traductor. El primer parámetro será el texto a traducir, seguido de los idiomas (origen y destino), y por último se introduce la función callback que será invocada cuando finalice la operación; hay que tener en cuenta que la traducción es realizada a través de una llamada asíncrona a los servidores de Google:
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
Como podéis observar, y es quizás lo único extraño que tiene esta instrucción, el callback se ha definido como una función anónima definida en el espacio del mismo parámetro (podéis ver otro ejemplo de este tipo de funciones cuando explicaba cómo añadir funciones con parámetros al evento OnLoad).
Para los queráis jugar con esto directamente, ahí va el código listo para un copiar y pegar.
<html>
<head>
<title>Traductor</title>
<script type="text/javascript" src="http://www.google.com/jsapi"></script>
<script type="text/javascript">
google.load("language", "1");
</script>
</head>
<body>
<textarea id="text" rows="8" cols="40">Hi, how are you?</textarea>
<br />
<button onclick="onClick()">
Traducir</button>
Del idioma
<select id="srcLang">
<option value="">(Auto)</option>
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
Al
<select id="dstLang">
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
<h3>Traducción:</h3>
<div id="result">
(Introduce un texto)
</div>
</body>
<script type="text/javascript">
function onClick()
{
// obtenemos el texto y los idiomas origen y destino
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
// llamada al traductor
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
}
</script>
</html>
Enlaces: Página oficial de documentación del API
Publicado en: www.variablenotfound.com.
domingo, 16 de marzo de 2008
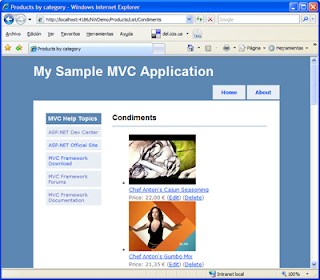 He adaptado para Visual Web Developer Express una de las aplicaciones de ejemplo para ASP.NET MVC que publicó hace unos días el gran Scott Hanselman en su blog, pues no hay nada como observar código y verlo funcionar para aprender y profundizar en esta nueva tecnología.
He adaptado para Visual Web Developer Express una de las aplicaciones de ejemplo para ASP.NET MVC que publicó hace unos días el gran Scott Hanselman en su blog, pues no hay nada como observar código y verlo funcionar para aprender y profundizar en esta nueva tecnología.Concretamente, se trata de una adaptación de Phil Haack para la CTP2 de una aplicación creada inicialmente por Brad Abrams que muestra un catálogo de productos categorizado, tomados de la clásica base de datos NorthWind (para SQLServer/Express), y permite la creación, edición y eliminación de los mismos (CRUD); en otras palabras, una mini-aplicación completa. El acceso a datos se realiza mediante Linq, y las clases del Modelo se han generado con el diseñador Linq2SQL.
Aparte de la adaptación, he aprovechado para retocarla un poco, y le he añadido algunas funcionalidades y detalles que no estaban implementados. Faltan algunos flequillos, como las validaciones de formularios que todavía no he visto cómo se resuelven en el framework, pero bueno, lo que hay es una base interesante para comenzar o seguir profundizando en esta tecnología.
Podéis descargar el proyecto desde el enlace que encontraréis más abajo. Una vez descomprimido el archivo, abrid la carpeta desde Visual Web Developer Express (opción "Abrir > Abrir sitio web" o "File > Open web site" si tenéis aún la versión en inglés) y listo, podéis pulsar F5 para ejecutar.
Por cierto, no sé si funcionará bien con las versiones "pro" de Visual Studio 2008. Agradecería que si alguien lo prueba en este entorno, me lo comentara.
Enlaces:
 Proyecto NorthWind Demo para ASP.NET MVC (~2MB)
Proyecto NorthWind Demo para ASP.NET MVC (~2MB)Publicado en: http://www.variablenotfound.com/.
domingo, 9 de marzo de 2008
 Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.
Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.Una unión es muy similar a una estructura de datos (
struct en C# o Structure en VB.Net), salvo en un detalle: sus componentes se almacenan sobre las mismas posiciones de memoria. O visto desde el ángulo opuesto, una unión podríamos definirla como una porción de memoria donde se guardan varias variables, habitualmente de tipos diferentes. Veamos un ejemplo clásico que nos ayudará a entender el concepto, en un lenguaje cualquiera:union Ejemplo
{
char caracter; // suponiendo char de 8 bits
byte octeto; // un byte ocupa 8 bits
};Si declaramos una variable x del tipo Ejemplo, estaremos reservando un espacio de 8 bits al que accederemos desde cualquiera de sus miembros, como vemos a continuación:
x.caracter = 'A';
x.octeto ++;
escribir_char (x.caracter); // mostraría 'B'
escribir_byte (x.octeto); // mostraría 66
Pero espera... ¿memoria?... ¿almacenamiento de variables?... ¿pero existe eso en .Net?... Pues sí, aunque lo más normal es que no nos tengamos que enfrentar nunca a ello pues el framework realiza estas tareas por nosotros, hay escenarios en los que es necesario controlar la forma en que la información es almacenada en memoria, como cuando se esté operando a bajo nivel, por ejemplo creando estructuras específicas para llamar al API de Windows, o para facilitar el acceso a posiciones concretas de la información.
Desde la versión 1.1 de la plataforma .Net, disponemos del atributo StructLayout, que nos permite indicar en estructuras y clases cómo queremos representar en memoria la información de sus miembros. Básicamente, podemos indicar que:
- la información se almacene como el framework considere oportuno (
LayoutKind.Auto) - que se almacene de forma secuencial, en el mismo orden en el que han sido declarados (
LayoutKind.Sequential). - que se almacene donde le indiquemos de forma explícita (
LayoutKind.Explicit). En este caso, necesitaremos especificar en cada miembro la posición exacta de memoria donde será guardado, utilizando el atributoFieldOffset.
Es este último método el que nos interesa para nuestros propósitos. Si adornamos una estructura con
StructLayout(LayoutKind.Explicit) e indicamos en cada uno de sus miembros su desplazamiento (en bytes) dentro del espacio de memoria asignado a la misma, podemos conseguir uniones haciendo que todos ellos comiencen en la misma dirección.Pasemos a vamos a verlo con un ejemplo en C#. Se trata de una unión a la que podemos acceder tratándola como un carácter unicode, o bien como un entero de 16 bits con signo. Los dos miembros, llamados
Caracter y Valor están definidos sobre la misma posición de memoria (desplazamiento cero) en el interior de la estructura:using System.Runtime.InteropServices;
using System;
namespace PruebaUniones
{
[StructLayout(LayoutKind.Explicit)]
public struct UnionTest
{
[FieldOffset(0)] public char Caracter;
[FieldOffset(0)] public short Valor;
}
class Program
{
public static void Main()
{
UnionTest ut = new UnionTest();
ut.Caracter = 'A';
ut.Valor ++;
Console.WriteLine(ut.Caracter); // Muestra "B"
Console.ReadKey();
return;
}
}
}Ahora usaremos VB.NET para mostrar otro ejemplo un poco más complejo que el anterior, donde usamos una unión para descomponer una palabra de 16 bits en los dos bytes que la componen, permitiendo la manipulación de forma directa e independiente de cada una de las dos visiones del valor almacenado en memoria. Para el ejemplo utilizo una unión dentro de otra, aunque no era estrictamente necesario, para que veáis que esto es posible.
Imports System.Runtime.InteropServices
<StructLayout(LayoutKind.Explicit)> _
Public Structure Union16
<FieldOffset(0)> Dim Word As Int16
<FieldOffset(0)> Dim Bytes As Bytes
End Structure
<StructLayout(LayoutKind.Explicit)> _
Public Structure Bytes
<FieldOffset(0)> Dim Bajo As Byte
<FieldOffset(1)> Dim Alto As Byte
End Structure
Public Class Program
Public Shared Sub main()
Dim u As New Union16
u.Word = 513 ' 513 = 256*1 (Byte alto) + 1 (byte bajo)
u.Bytes.Alto += 1
Console.WriteLine("Word: " & u.Word) ' Muestra 769 (3*256+1)
Console.WriteLine("Byte alto: " & u.Bytes.Alto) ' Muestra 3
Console.WriteLine("Byte bajo: " & u.Bytes.Bajo) ' Muestra 1
Console.ReadKey()
Console.ReadKey()
End Sub
End Class
He encontrado un uso muy interesante para esta técnica en Xtreme .Net Talk, donde se muestra un ejemplo de cómo acceder a los componentes de color de un pixel de forma muy eficiente a través de una unión entre el valor ARGB (32 bits) y cada uno de los bytes que lo componen (alfa, rojo, verde y azul).
En cualquier caso no se recomienda el uso de uniones salvo en casos muy concretos, y siempre conociendo bien las implicaciones que puede tener en la estabilidad y mantenibilidad del sistema.
Pero bueno, ¡está bien al menos saber que existen!
Publicado en: http://www.variablenotfound.com/.
jueves, 6 de marzo de 2008
Ayer se publicó la segunda preview del ASP.Net MVC Framework, la plataforma que sin duda será la revolución del año para los desarrolladores de aplicaciones basadas en web sobre tecnología .Net, y he pensado que ya era un buen momento para echarle un vistazo de cerca.
Una vez descargado el paquete (poca cosa, menos de un mega), procedí a instalarlo, apareciéndome la siguiente ventana de error:

Esto, además, se confirma en el documento de notas de la versión:
En otras palabras, que la segunda CTP, al igual que la primera, incluye plantillas que no son válidas para la versión Express de Visual Web Developer. Qué contrariedad.
Y es cierto que no está soportada, pero esto no implica que los que utilizamos las versiones light de los entornos de desarrollo estemos condenados a no probar esta nueva tecnología; de hecho es perfectamente posible, aunque no contaremos con todas las ayudas que sí vienen de serie para las versiones más "pro".
Una vez finalizada la instalación, encontré en Google varias páginas (por ejemplo aquí y aquí) donde se facilitaban plantillas, basadas en las originales, que nos permitirían probar la primera CTP sobre la versión express. Lamentablemente, los cambios realizados en la plataforma desde entonces hacen incompatibles estas plantillas con la CTP 2, aunque es posible hacerlas funcionar simplemente siguiendo los pasos detallados en esta página.
Para que no tengáis que perder el tiempo en ello, he creado una plantilla de proyecto Web (en C#) para Visual Web Developer Express 2008 que podéis descargar desde aquí.
Si queréis probar un poco esta tecnología, una vez instalada la segunda preview del ASP.Net MVC Framework, descargad la plantilla y guardarla, sin descomprimir, en la carpeta "Visual Studio 2008/Templates/ProjectTemplates". Lo habitual es que encontréis esta carpeta en "Mis documentos".
Iniciad Visual Web Developer 2008 Express, cread un nuevo sitio web en C# seleccionando la plantilla que habéis incluido, llamada "MVCWebSite", así:

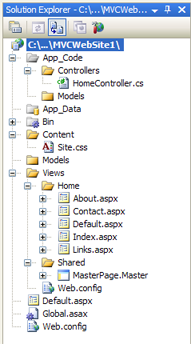 Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Y ya no hay nada más que hacer. Si pulsáis la tecla F5, se compilará y en pocos segundos tendréis funcionando un sitio web MVC, con un controlador y algunas vistas, las cuales usan una MasterPage para componer el esqueleto de las páginas. Además, una de ellas, "Links", muestra cómo obtener un parámetro (la lista de enlaces) desde el controlador.

¡Hala, a disfrutarlo!
Publicado en: http://www.variablenotfound.com/.
(Para el que todavía ande un poco despistado, puede leer una breve descripción del ASP.Net MVC Framework, convenientemente traducida, en Thinking in .Net).
Una vez descargado el paquete (poca cosa, menos de un mega), procedí a instalarlo, apareciéndome la siguiente ventana de error:

Esto, además, se confirma en el documento de notas de la versión:
“The new releases provide Visual Studio templates that are not supported in Visual Web Developer 2008 Express Edition. For example, you cannot create an MVC application or Silverlight .xap files by using Visual Web Developer 2008 Express Edition.”
En otras palabras, que la segunda CTP, al igual que la primera, incluye plantillas que no son válidas para la versión Express de Visual Web Developer. Qué contrariedad.
Y es cierto que no está soportada, pero esto no implica que los que utilizamos las versiones light de los entornos de desarrollo estemos condenados a no probar esta nueva tecnología; de hecho es perfectamente posible, aunque no contaremos con todas las ayudas que sí vienen de serie para las versiones más "pro".
Una vez finalizada la instalación, encontré en Google varias páginas (por ejemplo aquí y aquí) donde se facilitaban plantillas, basadas en las originales, que nos permitirían probar la primera CTP sobre la versión express. Lamentablemente, los cambios realizados en la plataforma desde entonces hacen incompatibles estas plantillas con la CTP 2, aunque es posible hacerlas funcionar simplemente siguiendo los pasos detallados en esta página.
Para que no tengáis que perder el tiempo en ello, he creado una plantilla de proyecto Web (en C#) para Visual Web Developer Express 2008 que podéis descargar desde aquí.
Si queréis probar un poco esta tecnología, una vez instalada la segunda preview del ASP.Net MVC Framework, descargad la plantilla y guardarla, sin descomprimir, en la carpeta "Visual Studio 2008/Templates/ProjectTemplates". Lo habitual es que encontréis esta carpeta en "Mis documentos".
Iniciad Visual Web Developer 2008 Express, cread un nuevo sitio web en C# seleccionando la plantilla que habéis incluido, llamada "MVCWebSite", así:

 Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"Y ya no hay nada más que hacer. Si pulsáis la tecla F5, se compilará y en pocos segundos tendréis funcionando un sitio web MVC, con un controlador y algunas vistas, las cuales usan una MasterPage para componer el esqueleto de las páginas. Además, una de ellas, "Links", muestra cómo obtener un parámetro (la lista de enlaces) desde el controlador.

¡Hala, a disfrutarlo!
Publicado en: http://www.variablenotfound.com/.
lunes, 3 de marzo de 2008
 Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.
Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.En esta ocasión vamos a centrarnos en los inicializadores de objetos, una nueva característica destinada, entre otras cosas, a ahorrarnos tiempo a la hora de establecer los valores iniciales de los objetos que creemos desde código.
Y es que, hasta ahora, podíamos utilizar dos patrones básicos de inicialización de propiedades al instanciar una clase:
- que fuera la clase la que realizara esta tarea, ofreciendo al usuario de la misma constructores con distintas sobrecargas cuyos parámetros corresponden con las propiedades a inicializar.
// Constructor de la clase Persona:
public Persona(string nombre, string apellidos, int edad, ...)
{
this.Nombre = nombre;
this.Apellidos = apellidos;
this.Edad = edad;
...
}
// Uso:
Persona p = new Persona("Juan", "López", 32, ...); - o bien dejar esta responsabilidad al usuario, permitiéndole el acceso directo a propiedades o campos del objeto creado.
// Uso:
Persona p = new Persona();
p.Nombre = "Juan";
p.Apellidos = "López";
p.Edad = 32;
...
Los inicializadores de objetos permiten, en C# y VB.Net, realizar esta tarea de forma más sencilla, indicando en la llamada al constructor el valor de las propiedades o campos que deseemos establecer:
// C#:
Persona p = new Persona { Nombre="Juan", Apellidos="López", Edad=32 };
' VB.NET:
Dim p = New Persona With {.Nombre="Luis", .Apellidos="López", .Edad=32 }
Los ejemplos anteriores son válidos para clases que admitan constructores sin parámetros, pero, ¿qué ocurre con los demás? Imaginando que el constructor de la clase
Persona recibe obligatoriamente dos parámetros, su nombre y apellidos, podríamos instanciar así:
// C#:
Persona p = new Persona ("Luis", "López") { Edad = 32 };
' VB.NET:
Dim p = New Persona ("Luis", "López") With { .Edad = 32 }
Aunque es obvio, es importante tener en cuenta que las inicializaciones (la porción de código entre llaves "{" y "}") se ejecutan después del constructor:
// C#:
Persona p = new Persona ("Juan", "Pérez") { Nombre="Luis" };
Console.WriteLine(p.Nombre); // Escribe "Luis"
' VB.NET:
Dim p = New Persona ("Juan", "Pérez") With { .Nombre="Luis" }
Console.WriteLine(p.Nombre); ' Escribe "Luis"
Y un último apunte: ¿cómo inicializaríamos propiedades de objetos que a su vez sean objetos que también queremos inicializar? Suponiendo que en nuestra clase
Persona hemos incluido una propiedad llamada Domicilio que de tipo Localizacion, podríamos inicializar el bloque completo así:
// C#:
// Se han cortado las líneas para facilitar la lectura
Persona p = new Persona()
{
Nombre = "Juan",
Apellidos = "López",
Edad = 55,
Domicilio = new Localizacion
{
Direccion = "Callejas, 34",
Localidad = "Sevilla",
Provincia = "Sevilla"
}
};
' VB.NET:
' Se han cortado las líneas para facilitar la lectura
Dim p = New Persona() With { _
.Nombre = "Juan", _
.Apellidos = "López", _
.Edad = 55, _
.Domicilio = New Localizacion With { _
.Direccion = "Callejas, 23", _
.Localidad = "Sevilla", _
.Provincia = "Sevilla" _
} _
}
En fin, que de nuevo tenemos ante nosotros una característica de estos lenguajes que resulta interesante por sí misma, aunque toda su potencia y utilidad podremos percibirla cuando profundicemos en otras novedades, como los tipos anónimos y Linq... aunque eso será otra historia.
Publicado en: http://www.variablenotfound.com/.
domingo, 24 de febrero de 2008
 Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático
Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático string.IsNullOrEmpty, sobre todo si podemos asegurar que no aparecerá el famoso bug del mismo (que al final no es para tanto, todo sea dicho).Los métodos de extensión nos brindan la posibilidad de hacer lo mismo pero de una forma más elegante e intuitiva, impensable hasta la llegada de C# 3.0: extendiendo la clase
string con un método que compruebe su contenido.La forma de conseguirlo es bien sencilla. Declaramos en una clase estática el método de extensión sobre el tipo
string:public static class MyExtensions
{
public static bool IsNullOrEmpty(this string s)
{
return s == null || s.Length == 0;
}
}Y listo, ya tenemos el nuevo método listo para ser utilizado:
string name = getCurrentUserName();
if (!name.IsNullOrEmpty())
...De todas formas, hay un par de reflexiones que considero interesante comentar.
En primer lugar, fijaos en el ejemplo anterior que aunque la variable
name contenga un nulo, se ejecutará la llamada a IsNullOrEmpty() sin provocar error, algo imposible si se tratara de un método de instancia. Obviamente, se debe a que en realidad se está enmascarando una llamada a un método estático al que le llegará como parámetro un null.Como consecuencia de lo anterior, y dado que no se puede distinguir a simple vista en una llamada a un método si éste es de instancia o de extensión, es posible que un desarrollador considerara esta invocación incorrecta. Esto forma parte de los inconvenientes de los métodos de extensión que ya cité en un post anterior.
En segundo lugar, visto lo visto cabría preguntarse, ¿por qué podemos extender una clase añadiéndole nuevos métodos pero no es posible incluir otro tipo de elementos, como eventos o propiedades? En el caso anterior podría quedar más fino que
IsNullOrEmpty fuera una propiedad de string, ¿no? Sin embargo, esto no es posible de momento. Según comentó ScottGu hace tiempo, se estaba considerando añadir la posibilidad de extender las clases también con nuevas propiedades. Supongo que el hecho de no haberla incluido en esta versión se deberá a que no era necesario para LINQ, la estrella de esta entrega... ¡y para dejar algo por hacer para C# 4.0, claro! ;-)
En cualquier caso, se trata principalmente de una cuestión de estética del código. Todo lo que conseguimos con las propiedades se puede realizar a base de métodos; de hecho, las propiedades no son sino interfaces más agradables a métodos getters y setters, al más puro estilo Java, subyacentes.
Por último, todo lo dicho es válido para VB.NET 9, salvo las obvias diferencias. El código equivalente al anterior sería:
Imports System.Runtime.CompilerServices
Module MyExtensions
<Extension()> _
Public Function IsNullOrEmtpy(ByVal s As String) As String
Return (s = Nothing) OrElse (s.Length = 0)
End Function
End Module
[...]
' Forma de invocar el método:
If s.IsNullOrEmtpy() Then
[...]
Publicado en: http://www.variablenotfound.com/.
martes, 19 de febrero de 2008

Después de pasar un buen rato entretenido con la recopilación de frases célebres relacionadas con el mundo de la informática y especialmente el desarrollo de software, "101 Great computer programming quotes", publicado en DevTopics hace unas semanas, no he podido resistir la tentación de traducirlo, previo contacto con su autor, el amabilísimo Timm Martin.
Este es el primer post de la serie compuesta por:
- 101 citas célebres del mundo de la informática (este post)
- Otras 101 citas célebres del mundo de la informática
- Y todavía otras 101 citas célebres del mundo de la informática
- 101 nuevas citas célebres del mundo de la informática (¡y van 404!)
domingo, 10 de febrero de 2008
Existen muchos consejos para crear código mantenible, como los que ya cité cuando hablaba sobre comentar el código fuente, pero ninguno iguala a este:

Al parecer se trata de un leyenda urbana sobre Visual C++ 6.0, pero no deja de tener su razón...
Imagen: My Confined Space
Publicado en: http://www.variablenotfound.com/.
"Always code as if the person who will maintain your code is a maniac serial killer that knows where you live"
(Codifica siempre como si la persona que fuera a mantener tu código fuera un asesino en serie maníaco que sabe donde vives)
Al parecer se trata de un leyenda urbana sobre Visual C++ 6.0, pero no deja de tener su razón...
Imagen: My Confined Space
Publicado en: http://www.variablenotfound.com/.
martes, 5 de febrero de 2008
Hace sólo unos días alucinaba con la existencia y gran difusión del leet speak, y de nuevo vuelvo a asombrarme con la programación esotérica, otra prueba de que en este mundillo siempre hay algo sorprendente que descubrir.
Los lenguajes esotéricos, también llamados esolangs, son lenguajes de programación cuyo objetivo, al contrario que en los "tradicionales", no es ser útil, ni solucionar problemas concretos, ni ser especialmente práctico, ni siquiera incrementar la productividad del desarrollador. De hecho, lo normal es que atente contra todas estas características de forma contundente.
Aunque algunos se diseñan como pruebas de concepto de ideas para determinar su viabilidad en lenguajes reales, lo más frecuente es que sean creados por diversión y exclusivamente con objeto de entretener a sus posibles usuarios. Viendo esto, puede parecer que no existirán más de un par de lenguajes esotéricos, ¿no? Pues haciendo un recuento rápido en la lista de lenguajes de esolang.org he podido contar más de cuatrocientos, lo cual da una idea de la dimensión de la frikada de la que estamos hablando.
Pero no hay nada como unos ejemplos ilustrativos para que tomemos conciencia total de la cuestión.
Según la especificación oficial, la ejecución comienza en la esquina superior izquierda, donde la orden "j" hace que la dirección de la ejecución sea hacia abajo. La siguiente orden procesada, "l", modifica el sentido de la ejecución hacia la derecha. Una "p" hace que se envíe a la consola el carácter que se encuentra en la celda inmediatamente inferior, de la misma forma que las "P" lo hacen con los caracteres situados en las celdas superiores.
Para no extenderme demasiado, resumiré un poco. Una vez enviado el saludo, se imprime un retorno de carro utilizando la pila para restar del carácter "*" (ASCII 42) el espacio (ASCII 32), se envía a la consola y se finaliza el programa (orden "q").
Estas órdenes permiten desplazarse por las celdas hacia delante y hacia atrás ("<" y ">"), incrementar o disminuir el valor de la celda actual ("+" y "-"), escribir y leer caracteres hacia/desde consola ("." y ",") y hacer bucles simples ("[" y "]"). Como muestra, ahí va el "Hello world":
Gran muestra de código mantenible, sin duda.
Como curiosidad, añadir que existe un intérprete y compilador de Brainfucker para .NET en Google Code.

Es interesante saber que existen multitud de implementaciones de este lenguaje, una de ellas incluso en .NET, aún en versión alfa, con perfecta integración en Visual Studio.
En fin, que después nos quejamos de que los desarrolladores tenemos fama de rarillos... ;-)
Publicado en: http://www.variablenotfound.com/.
Los lenguajes esotéricos, también llamados esolangs, son lenguajes de programación cuyo objetivo, al contrario que en los "tradicionales", no es ser útil, ni solucionar problemas concretos, ni ser especialmente práctico, ni siquiera incrementar la productividad del desarrollador. De hecho, lo normal es que atente contra todas estas características de forma contundente.
Aunque algunos se diseñan como pruebas de concepto de ideas para determinar su viabilidad en lenguajes reales, lo más frecuente es que sean creados por diversión y exclusivamente con objeto de entretener a sus posibles usuarios. Viendo esto, puede parecer que no existirán más de un par de lenguajes esotéricos, ¿no? Pues haciendo un recuento rápido en la lista de lenguajes de esolang.org he podido contar más de cuatrocientos, lo cual da una idea de la dimensión de la frikada de la que estamos hablando.
Pero no hay nada como unos ejemplos ilustrativos para que tomemos conciencia total de la cuestión.
Ejemplo 1: "Hello World" en lenguaje Argh!
Este lenguaje utiliza una matriz de 80x40 caracteres, en cuyas celdas pueden aparecer tanto código como datos. La siguiente matriz codifica el tradicional "Hello World":
j world
lppppppPPPPPPsrfj
hello, * j
qPh
Según la especificación oficial, la ejecución comienza en la esquina superior izquierda, donde la orden "j" hace que la dirección de la ejecución sea hacia abajo. La siguiente orden procesada, "l", modifica el sentido de la ejecución hacia la derecha. Una "p" hace que se envíe a la consola el carácter que se encuentra en la celda inmediatamente inferior, de la misma forma que las "P" lo hacen con los caracteres situados en las celdas superiores.
Para no extenderme demasiado, resumiré un poco. Una vez enviado el saludo, se imprime un retorno de carro utilizando la pila para restar del carácter "*" (ASCII 42) el espacio (ASCII 32), se envía a la consola y se finaliza el programa (orden "q").
Ejemplo 2: "Hello World" en Brainfuck (jodecerebros)
Este lenguaje es un clásico en este mundillo debido a que ha servido como base para la creación de muchos otros lenguajes esotéricos. Se basa en la manipulación de un array de celdas utilizando tan solo 8 comandos, los siguientes caracteres: <, >, +, -, punto, coma, [, ].Estas órdenes permiten desplazarse por las celdas hacia delante y hacia atrás ("<" y ">"), incrementar o disminuir el valor de la celda actual ("+" y "-"), escribir y leer caracteres hacia/desde consola ("." y ",") y hacer bucles simples ("[" y "]"). Como muestra, ahí va el "Hello world":
>+++++++++[<++++++++>-]<.>
+++++++[<++++>-]<+.+++++++..+++.
>>>++++++++[<++++>-]
<.>>>++++++++++[<+++++++++
>-]<---.<<<<.+++.
------.--------.>>+.
Gran muestra de código mantenible, sin duda.
Como curiosidad, añadir que existe un intérprete y compilador de Brainfucker para .NET en Google Code.

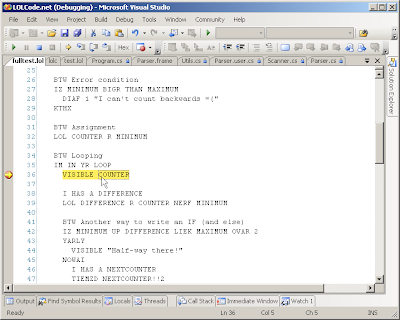
Ejemplo 3: "HAI WORLD" en LOLCODE
Lolcode es otro buen ejemplo de frikismo, aunque en este caso más orientado hacia la broma. Se trata de programar utilizando el peculiar lenguaje que usan unos populares gatitos, llamados lolcats, una mezcla entre la jerga de un bebé y el lenguaje habitual en los SMS.HAI
CAN HAS STDIO?
VISIBLE "HAI WORLD!"
KTHXBYE
Es interesante saber que existen multitud de implementaciones de este lenguaje, una de ellas incluso en .NET, aún en versión alfa, con perfecta integración en Visual Studio.

En fin, que después nos quejamos de que los desarrolladores tenemos fama de rarillos... ;-)
Publicado en: http://www.variablenotfound.com/.
domingo, 3 de febrero de 2008
 Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.
Los métodos de extensión son otra de las interesantes características que nos ofrecen las nuevas versiones de los lenguajes C# y VB que han sido publicados junto con la plataforma .NET v3.5 y Visual Studio 2008.Los, en inglés, extension methods, permiten añadir métodos a clases existentes sin necesidad de utilizar el mecanismo de la herencia. Aunque dicho así parezca ser una aberración y atente directamente contra una de las principales bases de la programación orientada a objetos, y de hecho están considerados por algunos como auténticos inventos diabólicos, la cosa tampoco es tan grave siempre que se mantenga cierto control y conocimiento de causa. Y es que, como muchas otras características aparecidas recientemente en estos lenguajes, no son sino una base sobre la que sustentar frameworks como Linq, y que de paso pueden ayudarnos a ser algo más productivos.
En realidad, y siendo prácticos, los métodos de extensión no aportan grandes novedades, casi nada que no pudiéramos hacer con la versión 1.0 del framework, simplemente nos facilitan nuevas vías sintácticamente más simples de hacerlo. Por ejemplo, seguro que alguna vez habéis querido dotar una clase X con nuevas funcionalidades y no habéis podido heredar de ella por estar sellada (sealed en C# o NotInheritable en VB)... ¿Qué es lo que habéis hecho? Pues probablemente crear en otra clase un método estático con un parámetro de tipo X que realizaba las funciones deseadas en alguna clase de utilidad. ¿Lo vemos mejor con un ejemplo?
Supongamos que deseamos añadir a la clase
string un método que nos retorne la cadena almacenada entre un tag (X)HTML strong. Como String no es heredable, la solución idónea sería crear una clase de utilidad donde codificar este métodos y otros similares que pudieran hacernos falta:public static class HtmlStringUtils
{
public static function string Negrita(string s)
{
return "<strong>" + s + "</strong>";
}
public static function string Cursiva(string s) {...}
public static function string Superindice(string s) {...}
[...]
}Su uso tendría que pasar necesariamente por la referencia a la clase estática y el paso del parámetro a convertir, así:
HtmlStringUtils.Negrita(currentUser.Name)
Esta técnica es correcta, aunque tiene un problema de visibilidad del código. Ningún desarrollador podría intuir la existencia de la clase HtmlStringUtils de forma natural; tampoco sería posible que un IDE sofisticado nos sugiriese el método
Negrita() como una posibilidad a la hora de manipular una cadena, como hace Intellisense con los métodos de instancia habituales.Los extension methods vienen a cubrir estos inconvenientes, creando una vía de alternativa para codificar el ejemplo anterior, facilitando después su uso de una forma más sencilla. Ojo al parámetro que recibe la función, que incluye la palabra reservada "this" por delante del mismo:
public static class HtmlStringUtils
{
public static function string Negrita(this string s)
{
return "<strong>" + s + "</strong>";
}
[...]
}De esta forma, incluyendo como primer parámetro el tipo precedido de la palabra "this", este método estático se convertirá automáticamente en un método de extensión de dicho tipo, y pueda ser utilizado como si fuera un método de instancia más del mismo:

return currentUser.Name.Negrita();
Y, por supuesto, tendríamos toda la potencia de nuestro querido Intellisense (en VS2008) a nuestra disposición.
Lo único a tener en cuenta es el primer parámetro, que debe ser del tipo a extender. En éste se introducirá la instancia de dicho tipo de forma automática, y el resto de parámetros serán enviados al método en el mismo orden, es decir:
// Método de extensión sobre un string
public static string Colorea(this string s, Color color)
{
[...]
}
// Forma de invocarlo:
string str = User.Name.Colorea(Color.Red);
Vemos que la utilización es mucho más natural y, aunque parezca que estamos rompiendo todas las bases del paradigma de la orientación a objetos, no es más que un atajo para incrementar productividad y facilitar la visión del código, además de servir como apoyo a tecnologías novedosas como Linq.
Sin embargo, no todo son ventajas. Es interesante añadir posibles problemas que pueden causar la utilización descontrolada de esta nueva característica.
En primer lugar, no olvidemos que a menos que Visual Studio (o cualquier entorno similar) nos eche una mano, al leer un código fuente será imposible saber si una llamada que estamos observando es un método de instancia o se trata de uno de extensión. Aunque no deja de ser una pequeña molestia, puede provocar una inquietante sensación de desconocimiento y dispersión del código fuente.
Otro motivo de dolor de cabeza puede ser el versionado de los métodos de extensión. Éstos pueden tener una vida completamente independiente de la clase a la que afectan, lo que puede provocar efectos no deseados ante la evolución de ésta.
Especialmente peligrosos pueden ser los relacionados con los nombres de métodos de extensión. Por ejemplo, la inclusión de un método en una clase podría hacer (de hecho, haría) que un método de extensión asociado a la misma y con un nombre similar no se ejecutara, pues el miembro de la instancia siempre tendría preferencia sobre éste. El problema es que el compilador no podría avisar de ningún problema, y es en ejecución donde podrían aparecer las incompatibilidades o diferencia de funcionalidades entre ambos métodos.
Veamos un ejemplo simple, siguiendo con el caso expuesto más atrás, ¿qué ocurriría si una vez en uso el método de extensión
Negrita() Microsoft decidiera añadir al tipo string un método de instancia llamado Negrita() en una versión posterior del framework, que retornara un tag HTML <b>? Pues que el compilador no sería capaz de detectar nada raro, por lo que no nos daríamos cuenta del cambio, y nuestra aplicación dejaría de validar XHTML.De la misma forma, también pueden causar problemas difíciles de detectar la especificación de namespaces incorrectos. Nada impide que un mismo método de extensión sea definido en dos espacios de nombres diferentes, lo cual hace que el namespace indicado en el using sea el que esté decidiendo el extension method a ejecutar, lo cual no resulta nada natural ni intuitivo en estos casos.
En conclusión: la recomendación es usar métodos de instancia, los habituales, siempre que se pueda, recurriendo a la herencia. Y para cuando no, contaremos con este valioso aliado.
Publicado en: http://www.variablenotfound.com/.
domingo, 20 de enero de 2008
FxCop es una herramienta que nos ayuda a mejorar la calidad de nuestras aplicaciones y librerías desarrolladas en cualquier versión de .Net, analizando de forma automática nuestros ensamblados desde distintas perspectivas y sugiriéndonos mejoras cuando detecta algún problema o incumplimiento de las pautas de diseño para desarrolladores de librerías para .Net Framework (Design Guidelines for Class Library Developers).
La versión actual (1.35) se puede descargar desde esta dirección, aunque ya existe una beta de la v1.36 en la web de Microsoft. Todos los comentarios que siguen se refieren a esta última versión, la 1.36 (beta), osado que es uno ;-), pero la mayor parte son válidos para la última revisión estable, la 1.35.
Una vez instalado tendremos a nuestra disposición dos aplicaciones: FxCop, que facilita el análisis y consulta de resultados a través de su propia GUI, y FxCopCmd, ideada para su utilización desde línea de comandos e integrarlo en otros sistemas, como Visual Studio, como parte del proceso de construcción (build) automatizado.
En cualquiera de los dos casos, el análisis de los ensamblados se realiza sometiéndolos a la comprobación de una serie de reglas basadas en buenas prácticas y consejos para asegurar la robustez y mantenibilidad de código. Del resultado del mismo obtendremos un informe con advertencias agrupadas en las siguientes categorías:
(Puedes ver la lista completa de comprobaciones, en inglés, aquí)
 Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
El tiempo dependerá del número y complejidad de los ensamblados a analizar, así como del conjunto de reglas (pestaña "rules") a aplicar, que por defecto serán todas. En cualquier caso, el proceso es rápido y finalizará con la presentación de una lista con el resumen de las anomalías detectadas, sobre la que podremos navegar y ampliar información.

Por cada anomalía, además, podremos acceder a una descripción completa de sus causas, origen en el código fuente, posibles soluciones, una URL para ampliar información, grado de certeza de existencia del problema, su gravedad y la categoría a la que pertenece. Con estos datos, sólo nos quedará acudir a nuestro código y corregir o mejorar los aspectos indicados.
En conclusión, se trata de una interesante herramienta que puede ayudarnos a mejorar la calidad del código que creamos. Aunque existen los "falsos positivos" y a veces no es todo lo precisa que debiera, la gran cantidad de comprobaciones que realiza, la posibilidad de añadir reglas personalizadas, así como el detalle de los informes de resultados hacen de ella una utilidad casi imprescindible para los desarrolladores .Net.
Publicado originalmente en: http://www.variablenotfound.com/.
La versión actual (1.35) se puede descargar desde esta dirección, aunque ya existe una beta de la v1.36 en la web de Microsoft. Todos los comentarios que siguen se refieren a esta última versión, la 1.36 (beta), osado que es uno ;-), pero la mayor parte son válidos para la última revisión estable, la 1.35.
Una vez instalado tendremos a nuestra disposición dos aplicaciones: FxCop, que facilita el análisis y consulta de resultados a través de su propia GUI, y FxCopCmd, ideada para su utilización desde línea de comandos e integrarlo en otros sistemas, como Visual Studio, como parte del proceso de construcción (build) automatizado.
En cualquiera de los dos casos, el análisis de los ensamblados se realiza sometiéndolos a la comprobación de una serie de reglas basadas en buenas prácticas y consejos para asegurar la robustez y mantenibilidad de código. Del resultado del mismo obtendremos un informe con advertencias agrupadas en las siguientes categorías:
- Advertencias de diseño, recoge avisos de incumplimientos de buenas prácticas de diseño para .Net Framework, como pueden uso de constructores públicos en tipos abstractos, interfaces o namespaces vacíos, uso de parámetros out, capturas de excepciones genéricas y un largo etcétera.
- Advertencias de globalización, que avisan de problemas relacionados con la globalización de aplicaciones y librerías, como pueden ser el uso de aceleradores de teclado duplicados, inclusión de rutas a carpetas de sistema dependientes del idioma ("archivos de programa"), etc.
- Advertencias de interoperabilidad, que analizan problemas relativos al soporte de interacción con clientes COM, como el uso de tipos auto layout visibles a COM, utilización de
System.Int64en argumentos (que no pueden ser usados por clientes VB6), o la sobrecarga de métodos. - Advertencias de movilidad, cuestionando el soporte eficiente de características de ahorro de energía, como uso de procesos con prioridad
ProcessPriorityClass.Idle., o inclusión deTimersque se repitan más de una vez por segundo. - Advertencias de nombrado, que detectan las faltas de cumplimiento de las guías y prácticas recomendadas en cuanto al nombrado de elementos (clases, métodos, variables, etc.), como uso de nombres de parámetros que coinciden con nombres de tipo, y más con los propios de un lenguaje concreto, mayúsculas y minúsculas no utilizadas correctamente, eventos que comiencen por "Before" o "After", puesto que deben nombrarse conjugando verbos en función del momento que se producen (p.e., Closing y Closed en lugar de BeforeClose y AfterClose), y un largo conjunto de comprobaciones.
- Advertencias de rendimiento, que ayudan a detectar problemas en el rendimiento de la aplicación o librería, comprobando puntos como el número de variables locales usadas, la existencia de miembros privados o internos (a nivel de ensamblado) no usados, creación de cadenas (strings) innecesarias, por llamadas múltiples a
ToLower()oToUpper()sobre la misma instancia, realización de conversiones (castings) innecesarios, concatenaciones de cadenas en bucles, etc. - Advertencias de portabilidad, que recoge observaciones interesantes para la portabilidad a distintas plataformas, como el uso de declaraciones PInvoke.
- Advertencias de seguridad, que se centran en analizar aspectos que podrían dar lugar a aplicaciones o librerías inseguras, avisando de problemas potenciales como la ausencia de directivas de seguridad, punteros visibles, o uso de arrays de sólo lectura, entre otros.
- Advertencias de uso, que analizan el uso apropiado del framework .Net realizando multitud de chequeos sobre el código, detectando aspectos como ausencia la liberación (dispose) explícita de tipos
IDisposable, resultados de métodos no usados, uso incorrecto de NaN, etc.
(Puedes ver la lista completa de comprobaciones, en inglés, aquí)
 Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.
Realizar un análisis de un ensamblado con FxCop resulta de lo más sencillo. Basta con crear un proyecto (al iniciar la aplicación aparecerá uno creado por defecto), añadir los ensamblados a analizar y pulsar el botón que iniciará el proceso.El tiempo dependerá del número y complejidad de los ensamblados a analizar, así como del conjunto de reglas (pestaña "rules") a aplicar, que por defecto serán todas. En cualquier caso, el proceso es rápido y finalizará con la presentación de una lista con el resumen de las anomalías detectadas, sobre la que podremos navegar y ampliar información.

Por cada anomalía, además, podremos acceder a una descripción completa de sus causas, origen en el código fuente, posibles soluciones, una URL para ampliar información, grado de certeza de existencia del problema, su gravedad y la categoría a la que pertenece. Con estos datos, sólo nos quedará acudir a nuestro código y corregir o mejorar los aspectos indicados.
En conclusión, se trata de una interesante herramienta que puede ayudarnos a mejorar la calidad del código que creamos. Aunque existen los "falsos positivos" y a veces no es todo lo precisa que debiera, la gran cantidad de comprobaciones que realiza, la posibilidad de añadir reglas personalizadas, así como el detalle de los informes de resultados hacen de ella una utilidad casi imprescindible para los desarrolladores .Net.
Publicado originalmente en: http://www.variablenotfound.com/.
domingo, 13 de enero de 2008
 Hace unos meses, el blog Inter-Sections publicó un interesante post donde el autor recogía las conclusiones obtenidas a partir de su experiencia desarrollando y seleccionando personal, respecto a cómo reconocer a los buenos desarrolladores.
Hace unos meses, el blog Inter-Sections publicó un interesante post donde el autor recogía las conclusiones obtenidas a partir de su experiencia desarrollando y seleccionando personal, respecto a cómo reconocer a los buenos desarrolladores.Esta información, además, ha sido complementada con decenas de comentarios de lectores a raíz de su reciente aparición en Slashdot, convirtiéndose en un artículo muy recomendable para los que estamos en el mundo del desarrollo de software y vemos lo complicado que resulta a veces dar con las personas apropiadas. Y es que la contratación del personal adecuado es un factor clave para el éxito (y a veces supervivencia) en una empresa de software, cuya actividad se basa en gran medida en el talento de sus desarrolladores.
Los indicadores clave que, según Daniel, nos pueden ayudar a detectar a los buenos desarrolladores de software se agrupan en los siguientes puntos:
- son apasionados por el desarrollo
- son autodidactas y les encanta aprender
- son inteligentes
- normalmente tienen experiencia oculta
- son conocedores de tecnologías variadas y punteras
- por último, aporta lo que en su opinión no es en absoluto determinante: la titulación.
Indicadores Positivos (propios de los buenos desarrolladores)
- Apasionado por la tecnología
- Programa por hobby
- Capaz de hablar durante horas sobre temas técnicos si se le anima
- Lleva (y ha llevado) a cabo proyectos personales
- Aprende nuevas tecnologías por su cuenta
- Opina sobre las tecnologías apropiadas en cada caso
- Se siente poco cómodo usando tecnologías que no considera correctas
- Es claramente inteligente, se puede conversar con él de muchos temas
- Comenzó a programar mucho antes de ir a la universidad o empezar a trabajar
- Tiene "icebergs" ocultos, grandes proyectos y actividades personales que no aparecen en el currículum.
- Conoce gran variedad de tecnologías, que pueden no encontrarse reflejadas en el CV.
Indicadores Negativos (propios de los no tan buenos desarrolladores)
- Ve la programación simplemente como su trabajo
- No habla de programación fuera del trabajo
- Aprende nuevas tecnologías exclusivamente en cursos ofrecidos por la empresa
- Se siente cómodo con la tecnología que se les imponga, piensa que cualquiera es buena
- No parece ser muy inteligente
- Comenzó a programar en la universidad
- Toda su experiencia en programación está en su currículum
- Está centrado exclusivamente en una o dos tecnologías
En mi opinión, aunque la lista incluye puntos interesantes y acertados, y puede sernos útil como base para la reflexión, el tema creo que es mucho más complejo. Seguro que cada uno de nosotros podría matizar los puntos, eliminarlos o ampliar las listas, tal y como se pone de manifiesto en los comentarios del post, partiendo de nuestras propias experiencias y convicciones.
Por ejemplo, desde mi punto de vista, los indicadores positivos podríamos ampliarlos mucho; los buenos desarrolladores deben mostrar, aparte de las habilidades y actitudes ya citadas, otras comentadas por aquí hace tiempo como capacidad de comunicación e integración en equipos de trabajo, responsabilidad, compromiso, interés y cariño por el resultado de los productos que uno genera, habilidades literarias, curiosidad y seguro que un larguísimo etcétera. Además, pueden producirse falsos positivos; como muestra, decir que es bueno ser un apasionado del desarrollo, pero este hecho no garantiza el ser un gran desarrollador.
En el grupo de los indicadores negativos podríamos añadir, por ejemplo, los inversos de las características anteriores (incapacidad de hacerse responsable de algo, falta de cuidado en los resultados...), o matizar las recogidas por Daniel. Por ejemplo, estar centrado exclusivamente en una o dos tecnologías puede ser indicador de una gran especialización, o tener intereses y hobbies ajenos a la programación puede ser muy beneficioso para los profesionales que nos dedicamos a esto.
Y es que también hay que tener en cuenta que no es lo mismo ser un gran desarrollador en tu casa, como hobby, que serlo en una empresa. He conocido magníficos desarrolladores que según estos indicadores no parecerían pasar de la mediocridad, al igual que otros que aún cumpliendo la mayoría de los puntos positivos adolece de otras características, como habilidades de trabajo en equipo o actitudes elitistas, que lo hacen absolutamente inútil en una compañía de producción de software en el que tendrá que trabajar codo con codo con sus compañeros.
En cualquier caso, se trata siempre de características difíciles de percibir por la empresa vía el tradicional currículum y de ahí la necesidad de contar con medios complementarios como los blogs (sabéis que tengo la certeza de que los blogs ayudan a encontrar empleo), o realizar entrevistas y pruebas de nivel cada vez más complejas.
Publicado en: http://www.variablenotfound.com/.
miércoles, 9 de enero de 2008
 Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil.
Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil. Una de ellas es la posibilidad de declarar variables sin necesidad de indicar de forma explícita su tipo, cediendo al compilador la tarea de determinar cuál es en función del tipo de dato obtenido al evaluar su expresión de inicialización. El tipado implícito o inferencia de tipos también existe en C# y ya escribí sobre ello hace unos días, pero me parecía interesante también publicar la visión para el programador Visual Basic y las particularidades que presenta.
Gracias a esta nueva característica, en lugar de escribir:
Dim x As XmlDateTimeSerializationMode = XmlDateTimeSerializationMode.Local
Dim i As Integer = 1
Dim d As Double = 1.8 Dim x = XmlDateTimeSerializationMode.Local
Dim i = 1
Dim d = 1.8El resultado en ambos casos será idéntico, ganando en comodidad y eficiencia a la hora de la codificación y sin sacrificar los beneficios propios del tipado fuerte.
Hay un detalle importante que los veteranos habrán observado: Visual Basic ya permitía (y de hecho permite) la declaración de variables sin especificar el tipo, de la forma
Dim i = 1 (con Option Strict Off), por lo que podría parecer que el tipado implícito no sería necesario. Sin embargo, en este caso los compiladores asumían que la variable era de tipo Object, por lo que nos veíamos obligados a realizar castings o conversiones en tiempo de ejecución, penalizando el rendimiento y aumentando el riesgo de aparición de errores imposibles de detectar en compilación. Tampoco tiene nada que ver con tipados dinámicos (como los presentes en javascript), o con el famoso tipo Variant que estaba presente en Visual Basic 6; el tipo asignado a la variable es fijo e inamovible, como si lo hubiésemos declarado explícitamente.En Visual Basic 9, siempre que no se desactive esta característica incluyendo la directiva
Option Infer Off en el código, el tipo de la variable será fijado justo en el momento de su declaración, deduciéndolo a partir del tipo devuelto por la expresión de inicialización. Por este motivo, la declaración y la inicialización deberán hacerse en el mismo momento:
Dim i = 1 ' La variable "i" es Integer desde este momento
Dim j ' La variable "j" es Object, como siempre,
j = 1 ' ... si Option Scrict está en Off.
' En caso contrario aparecerá un error de compilación.
El tipado implícito puede ser asimismo utilizado en las variables de control de bucles For o For Each, haciendo su escritura mucho más cómoda:
Dim suma = 0
For i = 1 To 10 ' i se está declarando ahí mismo como Integer,
suma += i ' no existía con anterioridad
Next
Dim str = "abcdefg"
For Each ch In str ' ch se declara automáticamente como char,
Console.Write(ch) ' que es el tipo de los elementos de "str"
Next
Y también puede resultar bastante útil a la hora de obtener objetos de tipos anónimos, es decir, aquellos cuya clase se define en el mismo momento de su instanciación, como en el siguiente ejemplo:
Dim point = New With {.X = 1, .Y = 5}
point.X += 1
point.Y += 1
Por último, es interesante comentar que, a diferencia de C#, Visual Basic permite declarar en la misma línea distintas variables de tipo implícito, por lo que es posible escribir
Dim k=1, j=4.8, str="Hola" sin temor a un error en compilación, asignándose a cada una de ellas el tipo apropiado en función de su inicialización (en el ejemplo, Integer, Double y String respectivamente).Coinciden, sin embargo, en que en ambos lenguajes esta forma de declaración de variables se aplica exclusivamente a las locales, es decir, aquellas cuyo ámbito es un método, función o bloque de código. No pueden ser propiedades ni variables de instancia; en el siguiente ejemplo, x será declarada de forma implícita como Object, mientras que el tipo de la variable y será inferido como Integer:
Public Class Class1
Dim x = 2 ' Es una variable de instancia
Public Sub New()
Dim y = 2 ' Es una variable local
End Sub
End ClassEn resumen, se trata de una característica muy útil que, además de permitirnos programar más rápidamente al ahorrarnos teclear los tipos de las variables locales, actúa como soporte de nuevas características del lenguaje y la plataforma .NET, como el interesantísimo Linq.
Es conveniente, sin embargo, utilizar esta característica con cordura y siendo siempre conscientes de que su uso puede dar lugar a un código menos legible y generar errores difíciles de depurar. De hecho, Microsoft recomienda usarlas "sólo cuando sea conveniente".
Publicado en: Variable Not Found.
martes, 18 de diciembre de 2007
Hace unos días Rosario C. realizaba, a través de un comentario en el post "Llamar a métodos estáticos con ASP.Net Ajax", una consulta sobre un problema con el se había topado al intentar retornar DataSets desde un método de página (PageMethod) de ASP.Net Ajax, un tema tan interesante que vale la pena escribir un post en exclusiva.
Recordemos que los métodos estáticos de página son una interesante capacidad que nos ofrece este framework para poder invocar desde cliente (javascript) funciones de servidor (codebehind) de una forma realmente sencilla. Además, gracias a los mecanismos de seriación incluidos, y como ya vimos en el post "Usando ASP.NET AJAX para el intercambio de entidades de datos", es perfectamente posible devolver desde servidor entidades o estructuras de datos complejas, y obtenerlas y procesarlas directamente desde cliente utilizando javascript, y viceversa.
Es es ahí donde reside el problema con los DataSets: precisamente este tipo de datos no está soportado directamente por el seriador JSON incorporado, que es el utilizado por defecto, de ahí que se genere una excepción como la que sigue:
Pero antes de nada, un inciso. Dado que la excepción se produce en el momento de la seriación, justo antes de enviar los datos de vuelta al cliente, debe ser capturada en cliente vía la función callback especificada como último parámetro en la llamada al método del servidor:
Aclarado esto, continuamos con el tema. La buena noticia es que el soporte para DataSets estará incluido en futuras versiones de la plataforma. De hecho, es perfectamente posible utilizar las librerías disponibles en previews disponibles en la actualidad. Existen multitud de ejemplos en la red sobre cómo es posible realizar esto, aunque será necesario instalar alguna CTP y referenciar librerías en el Web.config. Podéis echar un vistazo a lo descrito en este foro.
Esta solución sin embargo no es muy recomendable en estos momentos, puesto que estaríamos introduciendo en un proyecto librerías y componentes que, en primer lugar, están ideados sólo para probar y tomar contacto con las nuevas tecnologías, y, en segundo lugar, las características presentadas en ellos pueden modificarse o incluso eliminarse de las futuras versiones.
Existen otras formas de hacerlo, como la descrita en siderite, que consiste en crear un conversor justo a la medida de nuestras necesidades extendiendo la clase
Sin embargo, la solución que he visto más simple es utilizar XML para la seriación de estas entidades, lo que se puede lograr de una forma muy sencilla añadiendo al método a utilizar un atributo modificando el formato de respuesta utilizado por defecto, de JSON a XML.
He creado un proyecto de demostración para VS2005, esta vez en VB.NET aunque la traducción a C# es directa, con una página llamada DataSetPageMethods.aspx en el que se establece un PageMethod en el lado del servidor, con la siguiente signatura:
 Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.
Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.
Como podréis observar, el método está precedido por la declaración de dos atributos. El primero de ellos,
Desde cliente, al cargar la página rellenamos un desplegable con las distintas ciudades. Cuando el usuario selecciona un elemento y pulsa el botón "¡Pulsa!", se realizará una llamada asíncrona al PageMethod, según el código:
La función callback de notificación de finalización de la operación,
En el primer ejemplo, se crea en cliente una lista sin orden con los nombres de las personas de contacto de los clientes (valga la redundancia ;-)), donde muestro cómo es posible utilizar el DOM para realizar recorridos sobre el conjunto de datos:
En el segundo ejemplo se muestra otra posibilidad, la utilización de DOM para crear una función recursiva que recorra en profundidad la estructura XML mostrando la información contenida. La función javascript que realiza esta tarea se llama
Como se puede comprobar analizando el código, utilizar la información del
Una alternativa que además de resultar menos pesada en términos de ancho de banda y proceso requerido para su tratamiento es bastante más sencilla de implementar sería enviar a cliente la información incluida un un array, donde cada elemento sería del tipo de datos apropiado (por ejemplo, un array de Personas, Facturas, o lo que sea). La seriación será JSON, mucho más optimizada, además de resultar simplísimo su tratamiento en javascript.
El proyecto de demostración también incluye una página (ArrayPageMethods.aspx) donde está implementado un método que devuelve un array del tipo
Por último, comentar que el proyecto de ejemplo funciona también con VS2008 (Web Developer Express), aunque hay que abrirlo como una web existente.
Publicado en: www.variablenotfound.com.
Enlace: Descargar proyecto VS2005.
Recordemos que los métodos estáticos de página son una interesante capacidad que nos ofrece este framework para poder invocar desde cliente (javascript) funciones de servidor (codebehind) de una forma realmente sencilla. Además, gracias a los mecanismos de seriación incluidos, y como ya vimos en el post "Usando ASP.NET AJAX para el intercambio de entidades de datos", es perfectamente posible devolver desde servidor entidades o estructuras de datos complejas, y obtenerlas y procesarlas directamente desde cliente utilizando javascript, y viceversa.
Es es ahí donde reside el problema con los DataSets: precisamente este tipo de datos no está soportado directamente por el seriador JSON incorporado, que es el utilizado por defecto, de ahí que se genere una excepción como la que sigue:
System.InvalidOperationException
A circular reference was detected while serializing an object of type 'System.Globalization.CultureInfo'.
en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValueInternal(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat serializationFormat)\r\n en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValue(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat [...]
Pero antes de nada, un inciso. Dado que la excepción se produce en el momento de la seriación, justo antes de enviar los datos de vuelta al cliente, debe ser capturada en cliente vía la función callback especificada como último parámetro en la llamada al método del servidor:
// Llamada a nuestro PageMethod
PageMethods.GetData(param, OnOK, OnError);
[...]
function OnError(msg)
{
// msg es de la clase WebServiceError.
alert("Error: " + msg.get_message());
}
Aclarado esto, continuamos con el tema. La buena noticia es que el soporte para DataSets estará incluido en futuras versiones de la plataforma. De hecho, es perfectamente posible utilizar las librerías disponibles en previews disponibles en la actualidad. Existen multitud de ejemplos en la red sobre cómo es posible realizar esto, aunque será necesario instalar alguna CTP y referenciar librerías en el Web.config. Podéis echar un vistazo a lo descrito en este foro.
Esta solución sin embargo no es muy recomendable en estos momentos, puesto que estaríamos introduciendo en un proyecto librerías y componentes que, en primer lugar, están ideados sólo para probar y tomar contacto con las nuevas tecnologías, y, en segundo lugar, las características presentadas en ellos pueden modificarse o incluso eliminarse de las futuras versiones.
Existen otras formas de hacerlo, como la descrita en siderite, que consiste en crear un conversor justo a la medida de nuestras necesidades extendiendo la clase
JavaScriptConverter, aunque aún me parecía una salida demasiado compleja al problema.Sin embargo, la solución que he visto más simple es utilizar XML para la seriación de estas entidades, lo que se puede lograr de una forma muy sencilla añadiendo al método a utilizar un atributo modificando el formato de respuesta utilizado por defecto, de JSON a XML.
He creado un proyecto de demostración para VS2005, esta vez en VB.NET aunque la traducción a C# es directa, con una página llamada DataSetPageMethods.aspx en el que se establece un PageMethod en el lado del servidor, con la siguiente signatura:
<WebMethod()> _
<Script.Services.ScriptMethod(ResponseFormat:=ResponseFormat.Xml)> _
Public Shared Function ObtenerClientes(ByVal ciudad As String) As DataSet
 Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.
Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.Como podréis observar, el método está precedido por la declaración de dos atributos. El primero de ellos,
WebMethod(), lo define como un PageMethod y lo hará visible desde cliente de forma directa. El segundo de ellos redefine su mecanismo de seriación por defecto, pasándolo a XML. Si queréis ver el error al que hacía referencia al principio, podéis modificar el valor del ResponseFormat a JSON, su valor por defecto.Desde cliente, al cargar la página rellenamos un desplegable con las distintas ciudades. Cuando el usuario selecciona un elemento y pulsa el botón "¡Pulsa!", se realizará una llamada asíncrona al PageMethod, según el código:
function llamar()
{
PageMethods.ObtenerClientes($get("<%= DropDownList1.ClientID %>").value , OnOK, OnError);
}
La función callback de notificación de finalización de la operación,
OnOk, recibirá el DataSet del servidor y mostrará en la página dos resúmenes de los datos obtenidos que describiré a continuación. He querido hacerlo así para demostrar dos posibles alternativas a la hora de procesar desde cliente los datos recibidos, el DataSet, desde servidor.En el primer ejemplo, se crea en cliente una lista sin orden con los nombres de las personas de contacto de los clientes (valga la redundancia ;-)), donde muestro cómo es posible utilizar el DOM para realizar recorridos sobre el conjunto de datos:
var nds = data.documentElement.getElementsByTagName("NewDataSet");
var rows = nds[0].getElementsByTagName("Table");
var st = rows.length + " filas. Personas: br />";
st += "<ul>";
for(var i = 0; i < rows.length; i++)
{
st += "<li>" + getText(rows[i].getElementsByTagName("Contatto")[0])+ "</li>";
}
st += "</ul>";
etiqueta.innerHTML = st;
En el segundo ejemplo se muestra otra posibilidad, la utilización de DOM para crear una función recursiva que recorra en profundidad la estructura XML mostrando la información contenida. La función javascript que realiza esta tarea se llama
procesaXml.Como se puede comprobar analizando el código, utilizar la información del
DataSet en cliente es necesario, en cualquier caso, un conocimiento de la estructura interna de est tipo de datos, lo cual no es sencillo, por lo que recomendaría enviar y gestionar los DataSets en cliente sólo cuando no haya más remedio.Una alternativa que además de resultar menos pesada en términos de ancho de banda y proceso requerido para su tratamiento es bastante más sencilla de implementar sería enviar a cliente la información incluida un un array, donde cada elemento sería del tipo de datos apropiado (por ejemplo, un array de Personas, Facturas, o lo que sea). La seriación será JSON, mucho más optimizada, además de resultar simplísimo su tratamiento en javascript.
El proyecto de demostración también incluye una página (ArrayPageMethods.aspx) donde está implementado un método que devuelve un array del tipo
Datos, cuya representación se lleva también a cliente y hace muy sencillo su uso, como se puede observar en esta versión de la función de retorno OnOk:
function OnOK(datos)
{
var etiqueta = $get("lblMensajes");
var s = "<ul>";
for (var i = 0; i < datos.length; i++)
{
s += "<li>" + datos[i].Contacto;
s += ". Tel: " + datos[i].Telefono;
s += "</li>";
}
s += "</ul>";
etiqueta.innerHTML = s;
}
Por último, comentar que el proyecto de ejemplo funciona también con VS2008 (Web Developer Express), aunque hay que abrirlo como una web existente.
Publicado en: www.variablenotfound.com.
Enlace: Descargar proyecto VS2005.












