
Esto, unido a la posibilidad de incluir mensajes publicitarios mucho más espectaculares que llamaran la atención a potenciales clientes de los servicios o productos ofertados, hizo que pronto comenzaran a proliferar los mensajes con imágenes, que enviaban o bien incrustadas en el contenido del mensaje (cortesía del estándar MIME) o bien a través de un mensaje HTML en el que se introducía una imagen externa (con el tag IMG).
En cualquier caso, hace tiempo que las imágenes forman parte del fenómeno spam. Próximos posts irán dedicados a analizar distintas técnicas aplicadas para hacer más efectivos y menos detectables por herramientas automáticas los mensajes no deseados.
Vía Coding Horror he encontrado un interesante ejemplo de lo que ocurre cuando "se permite a los desarrolladores diseñar el interfaz de usuario de una aplicación".

Obviamente, el ejemplo está tomado de un extremo; de la misma forma, hay desarrolladores que son capaces de crear auténticas maravillas funcionales sobre interfaces exquisitos.
En fin, el que esté libre de pecado que tire la primera piedra. ;-)
Un ejemplo:
.ed$$$$$eec.
.e$$$$$$$$$$$$$$$$$$eeeee$$$$$c
d$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$c
.$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$b.
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$ $b
d$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$F
.$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
.$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$**$ ^$$$$
4 $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$*" 4$$F
4 '$$$$$$$$$$$$$$$$$$$$$$$$$$$" 4$$
4 $$$$$$$$$$$$$$$$$$$$$$$$$$$ .$$%
d $$$$$ $$$$$*$$$$$$c ..e$$"
- 4$$$$ ^$$$$ *$$$$$F ^"""
4$$$$ 4$$$$ z$$$$$"
4$$$$ 4$$$$ ^$$$P
^$$$$b '$$$$e "F
El inocente elefantito podría ser el logotipo del producto que nos itentan vender, y un mensaje con este contenido pasaría absolutamente desapercibido para los sistemas automáticos de detección de spam.
Ahí va otro, este de creación propia, con un mensaje más directo:
## ## ## ###### ###### ##### ######
## ## ## # # # # # # #
## ## ## ###### # ## ##### ######
### ## # # ###### # # # #
Este último ejemplo se aproxima bastante a la realidad de este tipo de mensajes; lo habitual es que se envíen textos cortos, mensajes directos con publicidad explícita, dibujados a base de incluir cientos de caracteres. Se puede ver un ejemplo en la siguiente captura de pantalla.
¿Y cómo se combate esto? Probablemente, el mejor
 método sea, de nuevo, el análisis estadístico de la información contenida en el mensaje, teniendo en cuenta tanto los caracteres que aparecen como los espacios. Sin embargo, no parece muy sencillo determinar unas reglas que indiquen, sin riesgo a equivocación, que se trata de un mensaje de correo basura, por lo que sería un buen candidato a ser detectado por sistemas de aprendizaje automático y reconocimiento de patrones.
método sea, de nuevo, el análisis estadístico de la información contenida en el mensaje, teniendo en cuenta tanto los caracteres que aparecen como los espacios. Sin embargo, no parece muy sencillo determinar unas reglas que indiquen, sin riesgo a equivocación, que se trata de un mensaje de correo basura, por lo que sería un buen candidato a ser detectado por sistemas de aprendizaje automático y reconocimiento de patrones.Quizás la suerte que tengamos los sufridos usuarios sea que los mensajes a transmitir por esta vía deben ser bastante cortos ("Viagra $2,5" o similares) por limitaciones lógicas de espacio, lo cual, sin duda, repercutirá en una utilización muy baja por parte de los spammers, que seguro prefieren la espectacularidad de otros medios.
Desde el punto de vista profesional, un éxito. Se han cerrado aspectos de vital importancia para el proyecto, y se han creado nuevos vínculos con el personal "de allí", fundamental para poder continuar trabajando juntos y de forma coordinada.
Durante estos cinco días hemos estado en Casablanca, Kenitra, y Tánger. Las jornadas de reuniones eran amplias, lo cual no ha permitido dedicar mucho tiempo a hacer turismo, sólo una tarde-noche, que nos hemos acercado a un mercado (zoco) en Rabat, la capital del reino, donde hemos podido disfrutar el ambiente mercantil de estos lugares y comprar algunos detallitos.
La opinión del país con la que me he ido es diferente a la que tenía antes de visitarlo, formada únicamente por tópicos y comentarios puntuales de conocidos que habían pasado allí algunos días de vacaciones. Aunque sí, es cierto que las diarreas han tenido su protagonismo en la visita, que hay mucha pobreza y se persigue bastante al forastero con objeto de sacarte algunas perrillas, y que la conducción es en general muy temeraria, pero no es menos cierto es que los marroquíes resultan muy acogedores, con una gran simpatía y educación, y se esfuerzan enormemente en agradar al visitante, que la comida es muy buena, y que las ciudades (al menos las grandes) son muy parecidas a las occidentales.
En fin, ahora toca dormir como un oso, que el fin de semana es corto.
Nos vemos.
Un ejemplo simplista: en un mensaje con el texto "Vendo Viagra Barato, Paisa", el 25% del contenido hace referencia al conocido medicamento, un 50% contiene palabras relacionadas con la venta, y un 25% restante no está claramente clasificado. Con estas proporciones, podemos asegurar que se trata de un mensaje intentando comercializar este producto.
Sin embargo, si al mensaje anterior le anexamos un capítulo del Quijote, los porcentajes anteriormente obtenidos caerían hasta ser prácticamente nulos, de forma que no podría determinarse con claridad el sentido del mensaje, justo al contrario que antes.
Esto está bien, pero, siguiendo con el ejemplo, ¿cómo colocan un capítulo del Quijote en un mensaje? He observado varias técnicas:
- la primera, anexándolo sin más. Es decir, después del contenido que pretenden enviar al usuario, algunos retornos de carro, y seguidamente, el capítulo del libro de Cervantes.
- otra, utilizando texto con el mismo color que el fondo del mensaje. Por ejemplo, texto blanco sobre fondo blanco, De esta forma, el usuario no es consciente ni siquiera de la existencia del mensaje.
- más, cambiando el tamaño de letra a tamaños de pixel. Así, el usuario puede, a lo sumo, divisar unas leves líneas al final del mensaje publicitario.
- una combinación de las dos anteriores. Esto no hay quien lo vea.
Ea, seguimos en el próximo post, que ya será después del viaje.
Sólo me falta por cerrar el transporte desde casa hasta el punto donde estoy citado con el resto de componentes de la visita, que habrá de ser en taxi, y tendré que llamarlo mañana un rato antes de salir.
Nos vemos a la vuelta (¿esto no lo he dicho ya antes?)
De momento acabo de librarme de atravesar el estrecho con un temporal de narices, climatológicamente hablando. Todo un alivio para alguien al que no suelen sentar demasiado bien los viajes movidos.
En los pronósticos para el lunes hay diversidad de opiniones, aunque parece que son más los que estiman que será un día nuboso, aunque no apunta lluvia. Todo se verá.
Asistiré a una serie de reuniones técnicas donde se decidirá el juego de datos, los procedimientos y los formatos de intercambio de información entre dos sistemas informáticos que están siendo desarrollados, uno por parte del cliente al que representaré en las reuniones y otro por parte de las autoridades Marroquíes. Seguro que va a ser divertido: no hablo nada de Francés y supongo que ellos tampoco hablarán castellano, así que tendremos que recurrir a intérpretes (humanos) o, si se dejan, intentaremos comunicarnos en inglés, en c#, java o como sea.
En cuanto al viaje en sí, la verdad es que a priori no es un lugar por el que sienta especial interés. De hecho, ni siquiera aparecería en mi imaginaria lista de sitios a los que querría ir en vacaciones. Esto hace que sienta cierta inquietud ante la excursión, que supongo que estará motivada por mi desconocimiento total sobre la zona. En otras ocasiones en las que, también por trabajo, he salido del país a Portugal, Holanda o el Reino Unido, más o menos sabía a donde me dirigía; en este caso, sin embargo, no tengo ni idea de cómo será aquello.
En fin, vamos a darle una oportunidad al reino vecino. A la vuelta contaré lo que me ha parecido.
Hasta entonces.
Es decir, la V mayúscula sería sustituída por V, dado que el 86 es el código ASCII de este carácter. Aplicando esta técnica a la palabra VIAGRA, cuya secuencia ASCII equivalente es {82, 73, 65, 71, 82, 65}, obtendríamos en el cuerpo del mensaje:
VIAGRA
Lo cual es algo más difícil de detectar (aunque no mucho, todo sea dicho de paso) por parte de las herramientas de filtrado.
 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
Conceptualmente es bastante simple: si en el cuerpo de un mensaje aparece la palabra "viagra", ya hay bastantes probabilidades de que se trate de un correo basura; si, además, en el cuerpo aparecen otras expresiones ("barato", "compre ahora", etc.), las probabilidades crecen bastante, ¿está claro, no?
Obviamente, los spammers debieron darse cuenta de este detalle, así que rápidamente dieron con una técnica, simple donde las haya, para esquivar este contratiempo: separar las letras que componen las palabras conflictivas con espacios o caracteres invisibles, de forma que los parsers no pudieran encontrar esas cadenas en el cuerpo de los mensajes.
Así, he encontrado distintas variantes de esta técnica; la primera de ellas se utiliza tanto en mensajes HTML como en texto plano, mientras que las dos siguientes son propias de los mensajes enriquecidos:
- separar con espacios, es decir, utilizar "V I A G R A" en vez de "viagra", por ejemplo.
- separar con entidades, como , que generará en pantalla el mismo efecto que el punto anterior, pero con la diferencia de que no puede ser eliminado realizando trimming a los textos. El ejemplo anterior quedaría codificado como "V I A G R A". Obviamente, es bastante más difícil encontrar así un texto que si está incluido directamente en el contenido. Existen gran cantidad de entidades a utilizar cuya visualización no afecta a la lectura del texto, por lo que las posibilidades son muchas.
- separar con tags, aprovechando que los navegadores o visores de HTML ignorarán las etiquetas desconocidas. Por ejemplo, podríamos usar "V<xx />I<xx />A<xx />G<xx />R<xx />A", lo que complica un poco su detección.
- separar con otros caracteres, que aunque dificultan algo la lectura por parte del cliente potencial, más la complican para los sistemas de búsqueda de cadenas de texto. Supongamos algo así: V-I-A-G-R-A. Seguimos leyendo Viagra, ¿verdad? ¿Y si decimos V_I_A_G_R_A? ¿O V.I.A.G.R.A? ¿A que hay cientos (miles) de combinaciones?
Por ello, estamos contemplando una auténtica competición entre ambos bandos, similar a la existente entre los creadores de virus y los fabricantes de antivirus. Si el spammer utiliza una técnica X para colar los mensajes, la técnica Y de los filtradores la contrarresta, lo que hace que los primeros desarrollen el método X+1, que a su vez, será compensado por la tecnología Y+1 de los segundos, y así sucesivamente.
En esta primera entrega veremos la forma más simple de evitar la detección, que, como en la vida misma, es tirar la piedra y esconder la mano.
Desde el principio de los tiempos, el correo basura se envía falseando las direcciones de correo del remitente y la razón es obvia: no descubrir a quien realmente envía los mensajes, acto que, en determinados países, incluso es constitutivo de delito.
¿Y es esto evitable? Difícilmente.
Gracias a la inocencia con que fue diseñado el protocolo SMTP, es perfectamente posible la suplantación del remitente de una forma increíblemente sencilla. Esto es fácilmente comprobable simplemente modificando las propiedades de la cuenta de correo de nuestro cliente favorito (Outlook, Thunderbird...).
Esta característica es aprovechada por los spammers para evitar ser detectados por filtros de tipo 'lista negra', utilizando orígenes de lo más pintorescos: remitentes en blanco, nombres y dominios generados de forma aleatoria, nombres reales pertenecientes a dominios inexistentes, o nombres auténticos dentro de dominios existentes. De esta forma, es absolutamente inviable determinar si un mensaje es spam o no a partir del remitente.
Una variante curiosa es el uso de direcciones pertenecientes al mismo dominio en el que nos encontramos. De hecho, de vez en cuando me llega un email publicitario de uno de mis compañeros de trabajo. En otras palabras, si mi buzón de correo es xxx@yyy.com, puedo recibir spam con un remitente del tipo zzz@yyy.com. Ahora bien, el nombre zzz puede ser real y pertenecer a un usuario que también tienen en sus listas de destinatarios, o bien ser totalmente falso. Hace unos años este pequeño truco hacía que los filtros fueran más compasivos con estos mensajes, sin embargo, hoy en día, que el remitente sea del propio dominio no es tomado como un criterio de veracidad.
Todo eso hace que en los sistemas actuales de filtrado el remitente se tome como un criterio de rechazo, pero nunca de aceptación incondicional de un mensaje.
Por tanto, los métodos actuales de detección de spam están basados, fundamentalmente, en el contenido de los mensajes. El próximo día que postee comentaré unas técnicas básicas para evitar ser detectados.
Ya llevaban tiempo recordándome que podía unirme a Blogger Beta y comenzar a disfrutar de sus innumerables ventajas, así que, en un alarde de osadía, me he lanzado.
Y viendo el resultado, parece que ha merecido la pena. Os comento por qué.
Desde el punto de vista visual, es una pasada: las plantillas son mucho más completas, y su contenido fácilmente modificable, aspecto éste bastante complejo en la versión anterior. Incluso hay disponible una opción mediante la cual se accede a una vista de diseño del blog, en la que podemos mover cosas de sitio simplemente arrastrándolas, o modificar su contenido con formularios específicos para cada sección de contenido. De la misma forma, se incluyen utilidades para la selección visual de colores de las distintas áreas, que facilita enormemente esta tarea.
Los post se realizan de la misma forma, si bien se ha incorporado la posibilidad de añadir al mismo la lista de tags (separados por comas) que lo categorizan. Conclusión inmediata: a la m*erda los technorati tags que comencé a introducir hace algunas semanas.
Los post que tenía archivados han pasado sin problema al nuevo formato. Sí es cierto que los comentarios, para los que había incluido recientemente Haloscan, no ha sido capaz de migrarlo (lógico, por otra parte), ni el Blogroll recién estrenado de mi columna derecha. Ya veré cómo vuelvo a poner eso en pie, aunque es posible que, dada las nuevas facilidades, mantenga la lista de enlaces a mano, sin necesidad de utilizar el servicio Bloglines, como venía haciendo.
Nada, que ya soy un Blogger Beta ;-)
De esta forma sería posible volver a ponerse a los mandos de todo un ZX de los de entonces, sin necesidad de descargas, instalaciones ni ocupación de disco duro.
Y efectivamente, como en Internet hay de todo, he encontrado un par de ellos reseñables. Probadlos, que no tienen desperdicio:
- http://www.spectrum.lovely.net/, al final de la página se puede elegir un juego con el que iniciar el emulador.
- http://www.ciunga.it/jxspeccy/gamesfull.html, con un visualizador más amplio, permite seleccionar en un desplegable el juego a cargar, de una lista de los 32 más populares. La lista completa está en http://www.ciunga.it/jxspeccy/arc.html.
Interesante para quitarse años de encima, como si fuera una crema correctora. ;-)
 Hoy he visto en The Inquirer un post sobre la informática de hace ¡20! años. En 1986 algunos andábamos ya peleando con Basic y ensamblador con el Spectrum, esa pequeña maravilla gracias a la cual entramos en el mundo de la informática.
Hoy he visto en The Inquirer un post sobre la informática de hace ¡20! años. En 1986 algunos andábamos ya peleando con Basic y ensamblador con el Spectrum, esa pequeña maravilla gracias a la cual entramos en el mundo de la informática.Resalta, también, el importante papel de la revista MicroHobby, que aunque a los más jóvenes n
 i siquiera les sonará el nombre, a los veteranos del Sinclair hace que se nos caiga un lagrimón nostálgico. Pues se recoge en el citado post, a través del proyecto MHF (MicroHobby Forever), un grupo de entusiastas ha digitalizado todos los números de esta revista y los han colocado en esta dirección: www.microhobby.org. También podremos encontrar un buscador de contenidos (MHoogle) e incluso descargar el contenido de las cintas que venían con la revista.
i siquiera les sonará el nombre, a los veteranos del Sinclair hace que se nos caiga un lagrimón nostálgico. Pues se recoge en el citado post, a través del proyecto MHF (MicroHobby Forever), un grupo de entusiastas ha digitalizado todos los números de esta revista y los han colocado en esta dirección: www.microhobby.org. También podremos encontrar un buscador de contenidos (MHoogle) e incluso descargar el contenido de las cintas que venían con la revista.Desde luego, Internet no deja de sorprenderme cada día.
Etiquetado como: Micro Hobby::spectrum::mhf
Estas barreras, ciertamente frenan un 90% de los mensajes basura que recibo, esto es un hecho. Pero no es menos cierto que, a pesar de ello, una vez al día tengo que perder mi
Seguro que a todos los tenemos direcciones de correo algo añejas nos ocurre lo mismo. Como en otros aspectos de la vida, a principios de los noventa podíamos relacionarnos con otros sin precauciones. Recuerdo cómo podía participar alegremente en foros utilizando mi nombre y dirección email habitual. Eso en la actualidad esto es impensable, y seguro que todos tomamos precauciones; en general, la mejor opción es la difusión racional de las direcciones de correo, y para ello se pueden encontrar algunas ayudas, como la que ya comenté hace algún tiempo, el uso de buzones temporales.
A pesar de todo, es interesante observar el talento y la creatividad que existe a veces detrás de estos mensajes. Como en el caso de los creadores de virus, troyanos y similares, me resulta admirable cómo los creadores de estos engendros evolucionan con el tiempo, adaptándose a los cambios y modificando su forma de actuar para estar siempre por delante de aquellos que intentan detenerlos.
Por ello, me he decidido a iniciar esta serie de artículos en los que iré comentando distintas técnicas que emplean estos individuos para conseguir transmitirnos un mensaje sin ser detectados por los complejos sistemas de filtro existentes en la actualidad.
Y sí, la verdad es que llevo tiempo viéndolos, pero hasta este momento no me he preguntado para qué servían. ¡Cómo se nota que todavía soy muy nuevo en esto!
Como no podía ser de otra forma, he acudido raudo a ver de qué se trataba y, efectivamente, he encontrado descrito, en un correcto inglés, qué son, para qué sirven y cómo se usan.
En pocas palabras, los tags se usan en los blogs para "etiquetar" el contenido, de forma que puedan ser indexados de forma correcta por motores de búsqueda especializados (como el propio technorati). Al etiquetar una página, aseguramos que cuando sea visitada por los robots de estos sistemas, será catalogada justo donde creamos que debe serlo.
Bueno, pues decidido está. A partir de ahora, para no ser menos que nadie, yo también usaré el tagging. Además, voy a actualizar algunos posts anteriores para incluírselos, aunque después de ser publicados no sé si servirá para algo.
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
Una opción bastante razonable es, sin duda, OpenCMS. Este veterano gestor de contenidos está basado en Java y XML, utilizando como almacén de datos el celebérrimo MySQL, lo cual contribuye al carácter multiplataforma del producto. Por cambiar un poco, vamos a instalarlo sobre un Windows XP Professional limpio, a ver qué tal resulta la experiencia, y en este post iré reflejando cada paso a dar hasta ponerlo en marcha.
Antes de comenzar: cumplir los requisitos
Es una buena costumbre antes de iniciar una instalación de este tipo repasar la lista de requisitos, normalmente disponible en el sitio web de los desarrolladores del producto. En este caso encontramos que OpenCMS necesita:- Java 2 SDK. Curiosamente, no es suficiente con la JRE, es necesario instalar el kit de desarrollo completo, señal de que se realizarán compilaciones al vuelo. Las notas de revisión recomiendan la versión 1.4 o superior; para ir a la última nos decantaremos por la 1.5, la más reciente, disponible para descargar en http://java.sun.com/javase/downloads.
- Contenedor de servlets que responda a los estándares Servlet 2.3 / JSP 1.2. Vamos a instalar Tomcat, que es la implementación de referencia oficial para dichas tecnologías. La descarga de la versión 5.5 podemos realizarla desde la dirección http://tomcat.apache.org/download-55.cgi.
- MySQL como sistema gestor de bases de datos, que podemos obtener desde http://dev.mysql.com/downloads/index.html.
La instalación de Java no supone ninguna dificultad, simplemente la habitual serie de clics sobre el botón "Aceptar" en un asistente de instalación típico.
Tomcat, por su parte, ofrece también un sencillo asistente que nos permitirá poner en funcionamiento este software en pocos segundos. He dejado todos los parámetros como aparecen en el instalador (concretamente el directorio de instalación, puerto de acceso http, y el nombre de usuario y contraseña del administrador), y tras el par de clics de rigor, podemos observar en el área de notificación el icono indicando que Tomcat está en ejecución.
MySQL, como no podía ser de otra forma, proporciona también un instalador que hace que su puesta en marcha sea un juego de niños. Tras finalizar la copia de archivos, se inicia de forma automática el "Instance Configuration Wizard", que permite realizar ajustes en la instancia de la base de datos antes de ponerla en marcha. Existen multitud de opciones a elegir, sin embargo, en este caso, he seleccionado las propuestas por el sistema salvo en el juego de caracteres, donde he optado por UTF-8, para dar soporte a lenguas no occidentales. Dado que esto es una máquina para hacer pruebas, no he tenido en cuenta nada relacionado con la optimización del espacio a ocupar, el rendimiento o aspectos parecidos. Eso lo dejamos para máquinas que vayan a entrar en producción, que no es nuestro caso. 
Para comprobar que el motor está instalado y en funcionamiento, podemos ejecutar el cliente de línea de comandos que podemos encontrar en el menú Inicio > Programas > MySQL. Una vez introducida la contraseña de administrador que le hemos suministrado con anterioridad, estaremos conectados al SGBD.
Pero ojo, según recomiendan, es conveniente modificar el archivo de configuración, "My.ini", disponible en el directorio donde se haya instalado MySQL y modificar el parámetro max_allowed_packet asignándole el valor "16M". Sin embargo, en instalaciones simples del motor de datos, esta variable ni siquiera existe, por lo que es necesario crearla a mano en el fichero de configuración. Es sencillo, basta con localizar la sección [mysqld] (en mi caso se encuentra sobre la línea 75) y añadir una nueva línea tal y como se recoge en el siguiente recorte:
[...]
# SERVER SECTION
# -----------------------------------------------
# The following options will be read by the MySQL
# Server. Make sure that you have installed the
# server correctly (see above) so it reads this
# file.
#
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
max_allowed_packet = 16M # Nueva línea !!!!
#Path to installation directory. All paths
# are usually resolved relative to this.
[...]
Al grano: instalando OpenCMS.
Ya tenemos la infraestructura necesaria para comenzar la instalación de OpenCMS. En primer lugar, descargamos la versión más reciente del software, dispensada en un archivo .zip descargable desde la web oficial. La actual, numerada como 6.2.2, pesa unos 27Mb.En su interior podremos encontrar un archivo llamado "opencms.war" que debe ser copiado la carpeta "Webapps" existente en el directorio donde se haya instalado Tomcat. En mi caso la ruta completa es C:\Archivos de programa\Apache Software Foundation\Tomcat 5.5\webapps.
Acto seguido, reiniciamos Tomcat. Esto puede hacerse de varias formas, pero lo recomendable en este momento es pulsar con el botón derecho del ratón sobre el icono del servicio (junto al reloj), deterner el servicio y volver a iniciarlo. Esto provocará que OpenCms entre a formar parte de las aplicaciones instaladas en Tomcat y podamos acceder con el navegador al asistente de instalación utilizando la url http://localhost:8080/opencms/setup.
Una vez aceptado el texto de licencia, que por otra parte no recuerdo haber leído nunca ;-P, el asistente mostrará el resultado de una evaluación del equipo. Como hemos hecho perfectamente los deberes, todos los indicadores aparecen en verde indicando que cumplimos con los requisitos exigidos para correr OpenCms.
Acto seguido, el sistema nos preguntará sobre aspectos relacionados con la base de datos: motor y versión instalado, datos del usuario de acceso general, usuario de acceso para OpenCms y nombre de la BD a crear. En mi caso sólo ha sido necesario retocar los passwords de acceso para los usuarios, el resto lo he dejado todo con los valores por defecto.
El resto de pasos del asistente consisten en la consabida serie de clics siguiente... siguiente... siguiente..., mientras vamos desfilando por pantallas donde se nos pregunta qué módulos queremos instalar (¡vaya pregunta! ¡pues todos, por supuesto! ;-D) o el nombre del servidor, entre otros detalles.
Tras una espera de varios minutos mientras se instalan los módulos
A partir de este momento, podemos acceder al portal OpenCms a través del enlace que el propio asistente de instalación nos muestra, donde aparecerá una página inicial de bienvenida, así como información para acceder al Workplace, o en otras palabras, a la aplicación de administración de la plataforma, también basada en Web y que tiene muy buena pinta.

Ea, pues misión cumplida, esto está en funcionamiento.
Etiquetado como: opencms::cms::portal::instalación
Haloscan commenting and trackback
have been added to this blog.
En fin, a ver si alguien se anima y estrena el nuevo sistema haciendo un comentario, un trackback o lo que sea. Bueno, o mejor, para no esperar, los haré yo mismo.
La pena es que los comentarios que tenía hasta el momento, aunque eran escasos, todavía no sé muy bien dónde han ido a parar... tendré que investigar un poco.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.
Joomla es uno de los CMS open source más usados en la actualidad debido a su sencillez y potencia para la creación de portales, sitios web dinámicos o aplicaciones basadas en Internet. En este post iré recogiendo "en tiempo real" los pasos que voy siguiendo para montar en un servidor un sitio basado en este gestor, de forma que pueda servir como guía para posteriores instalaciones.
Partimos de una distribución basada en Debian (Ubuntu), con Apache 2, PHP y MySQL instalados y funcionando de forma correcta.
25 de Agosto de 2006.
Diario de una instalación de Joomla.
16:39 - Inicio de actividades
Sin duda, lo primero que hay que hacer es documentarse. Pienso que no vendría mal una visita por el sitio web oficial de Joomla para ir tomando contacto. Un poco de lectura del típico qué es, para qué sirve, modelos de licencia, quiénes lo soportan, aunque la verdad es que me aburro pronto y prefiero pasar a la demo on-line donde se puede probar un portal entrando como usuario administrador (admin/admin). También es posible acceder a la parametrización y configuración de la plataforma añadiendo a la URL la ruta /administrator o pulsando sobre la correspondiente opción del menú.
En esta demo, salvo algunas limitaciones lógicas por motivos de seguridad, se permite tocar todo, y permite obtener una buena visión del potencial y capacidades de la herramienta.
17:18 - Comienzo de la instalación
Después del paseo anterior he decidido que, definitivamente, me lo voy a instalar. Google, que todo lo sabe, me dijo hace un rato que existe una comunidad hispana de Joomla! y allí he visto un enlace para descargar una versión de la plataforma localizada en español. Allá voy.
Se trata de un archivo .zip de poco menos de tres de megas, por lo que la descarga es prácticamente instantánea. Al abrir el archivo con FileRoller (el gestor de archivos comprimidos de Gnome) veo que se trata de una carpeta principal con archivos .php y varios subdirectorios. Uno de ellos, INSTALL.php me hace pensar que la instalación se realizará desde entorno web, una técnica muy de moda actualmente.
El servidor apache, según su instalación por defecto, asume que el directorio raíz del sitio http://localhost se en cuentra en la ruta física /var/www. No tengo intención de modificar la configuración de Apache, así que decido que mi portal Joomla se encontrará en un subdirectorio del raíz, por ejemplo, http://localhost/joomla. Debo crear, pues, este directorio dentro de la carpeta /var/www citada anteriormente.
Descomprimo los ficheros sobre mi flamante nueva carpeta con FileRoller (aunque también podría haberlo hecho desde un shell, ejecutando unzip [ruta del archivo .zip] desde el directorio destino). Justo después de terminar, ya es posible acceder a la URL local elegida para comenzar el proceso de instalación.
17:32 - Asistente de instalación, comprobaciones iniciales
La pantalla que aparece al acceder por primera vez con el navegador (recordemos: http://locahost/joomla) es el resultado de un análisis automático de los prerequisitos para la instalación del sistema, divididos en tres grupos:
- Pre-instalación, que comprueba que la versión de PHP es correcta y dispone de soporte para ciertas tecnologías utilizadas, así como los permisos de escritura de datos de sesión y el archivo de configuración (configuration.php). En mi caso el archivo de configuración no puede ser escrito, lo cual debe ser un problema, dado el color rojo chillón elegido para informar de ello, aunque también indica que todavía la instalación puede continuar; sigamos, pues.
- Ajustes recomendados, que hace referencia a la configuración de PHP. Como me aparece todo correcto, no le presto más atención.
- Permisos de carpetas, donde tengo un pleno. Todo rojo. El instalador, además, indica que es necesario modificar los permisos de estas carpetas para que todo funcione bien, así que desde un shell hago un chmod 777 [carpeta] para cada una de ellas, con lo que otorgo permisos generales de lectura, escritura y ejecución. Uff, supongo que un experto en seguridad premiaría con algunas collejas esta falta de celo, pero bueno, qué diantres, estoy en mi casa (servidor) y hago lo que quiero ;-). Para los perezosos, ahí van los comandos empleados; he preferido hacerlo uno a uno para evitar una llamada a chmod de forma recursiva e indiscriminada.
chmod 777 administrator/backups/
chmod 777 administrator/components/
chmod 777 administrator/modules/
chmod 777 administrator/templates/
chmod 777 cache/
chmod 777 components/
chmod 777 images/
chmod 777 images/banners/
chmod 777 images/stories/
chmod 777 language/
chmod 777 mambots/
chmod 777 mambots/content/
chmod 777 mambots/editors
chmod 777 mambots/editors-xtd/
chmod 777 mambots/search/
chmod 777 mambots/system/
chmod 777 media
chmod 777 modules
chmod 777 templates
Una pulsación sobre el botón "comprobar de nuevo", situado en la zona superior de la página, hace que se refresque el resultado del análisis, y se puede comprobar que todo está ya correcto, salvo el problema (obviable, de momento) del primer bloque de comprobaciones.
17:48 - Asistente de instalación, Licencia
Pulsando "Siguiente" pasamos a una página cuyo único objetivo es mostrar el texto de licencia GNU/GPL. Vaya, interesante es un rato, pero en estos momentos prefiero seguir instalando el software. Este tipo de contenidos, que estamos acostumbrados a encontrar cada vez que montamos un nuevo software, libre o propietario, son bastante largos y densos, y supongo que pocos son los que se paran ante ellos. En cualquier caso, seguro que todos conocemos el modelo GPL y estamos completamente de acuerdo con él, así que continuamos.
17:51 - Asistente de instalación, Paso 1 (MySQL)
Bueno, pues se va poniendo cada vez más interesante... Ha llegado el momento de indicar dónde y cómo se accede al servidor MySQL sobre el que recaerá la responsabilidad de almacenamiento de datos.
En el formulario que tenemos que rellear, dado que tenemos nuestra propia copia de MySQL en la máquina local, indicaremos que el servidor es "localhost". El nombre de usuario y contraseña no los he cambiado desde la instalación del motor, por lo que será "root" con clave en blanco (nueva colleja). Como nombre de la base de datos elegimos Joomla, por ser originales, y el resto de datos los dejamos como están.
Pulsando "siguiente" y aceptando una ventanilla de confirmación, el sistema creará la estructura sobre MySQL y mostrará el siguiente paso del asistente.
17:55 - Asistente de instalación, Paso 2 (Nombre)
Este es de los fáciles. Pongamos un nombre a nuestro sitio web... ummm... esto es siempre lo más difícil... además, seguro que todos nos preguntamos ¿se podrá cambiar más adelante?... estoooo.... venga, adjudicado, creatividad al poder, "Pruebas Joomla". :-D
17:58 - Asistente de instalación, Paso 3, (URL, administrador y otros)
Es momento de confirmar al sistema lo que él ya sabe, la URL de acceso y la ruta física de los archivos Joomla. Los dejamos tal y como están, introducimos el email y contraseña del administrador y seguimos adelante.17:58 - Asistente de instalación, Paso 4 (Fin)
¡Parece que hemos acabado! El sistema nos felicita por la gran instalación realizada, nos recuerda que el usuario de acceso será "admin", y la contraseña la elegida en el paso anterior, y nos pide que realicemos las siguientes operaciones:
- Eliminar de forma manual el directorio de instalación. Como supongo que se refiere a la carpeta /var/www/joomla/installation, así lo hago.
- Crear un archivo llamado "configuration.php" e introduzca en él el texto que nos suministra en un cuadro. Ahora entiendo lo que significa la alerta del paso de pre-instalación. Cojo mi editor favorito, pego el texto indicado, y lo salvo en la carpeta raíz de Joomla.
Voilá. Esto está listo. En la parte superior hay dos enlaces: web y administración. El primero de ellos nos llevará a la parte pública del portal, mientras que el segundo nos permitirá acceder a la administración y configuración. Así, podremos ver que la instalación ha creado por nosotros una web con contenidos de ejemplo, que nos ayudará a hacernos con el entorno más rápidamente.
A partir de aquí, queda pelear con el área de administración y las plantillas (templates) hasta tener la versión definitiva de lo que será nuestro sitio web basado en este magnífico gestor de contenidos.
Feliz Joomling.
Pero en fin, como es sabido que todo lo bueno acaba, lo mejor es tomarlo con filosofía y prepararnos para un año que seguro será duro, pero traerá alegrías personales y profesionales. Las pilas están cargadas, y preparadas para ello.
Nos vemos por aquí.
En primer lugar he descargado la imagen ISO desde la dirección http://releases.ubuntu.com/6.06/ubuntu-6.06-desktop-i386.iso; en mi primer intento lo descargué con eMule, aunque simplemente pude obtener una copia defectuosa que me llevó a desperdiciar tiempo, amén de algún CD tostado en vano. El único problema que trae de serie esta imagen es que el software que instala (p.e., OpenOffice) es inicialmente en inglés, aunque el sistema operativo venga en la lengua de Cervantes; supongo que en breve aparecerán distribuciones alternativas, donde todos los paquetes vendrán ya en nuestro idioma, pero mientras debemos instalar a posteriori las versiones localizadas de los mismos.
Una vez con la imagen ISO correcta grabada a fuego, ha sido introducirla en el lector del portátil, arrancar seleccionándolo como unidad inicial, y listo, todo sobre la seda. En pocos segundos ha aparecido un menú con varias opciones, inicialmente en inglés, aunque es posible cambiar esto pulsando la tecla F2 y cambiando a español. Seleccionando la opción "Iniciar Ubuntu" y esperando unos tres minutos, se cargará el sistema operativo, como es habitual montado sobre un disco RAM, apareciendo el escritorio Gnome.
Esta versión "live" ha sabido detectar perfectamente la placa madre, los dispositivos integrados (como el puerto de infrarrojos, la tarjeta de red Ethernet, o la de sonido), la tarjeta de red inalámbrica y hasta una llave USB que tenía introducida accidentalmente en uno de los puertos USB del equipo. A nivel de detección de hardware, simplemente perfecto. Ni un detalle a echarle en cara.
Para iniciar la instalación al disco duro, simplemente hay que pulsar un acceso directo que encontraremos en el escritorio, que iniciará el asistente. Tras algunas preguntas simples, como el
 idioma, la configuración de teclado y la zona horaria, y otras más complejas, como la distribución de particiones del disco, se inicia la instalación, propiamente dicha, del sistema. Ojo con el tema de las particiones, sobre todo si el ordenador tiene otro sistema operativo instalado, pues puede dar lugar a una pérdida irrecuperable de la información almacenada.
idioma, la configuración de teclado y la zona horaria, y otras más complejas, como la distribución de particiones del disco, se inicia la instalación, propiamente dicha, del sistema. Ojo con el tema de las particiones, sobre todo si el ordenador tiene otro sistema operativo instalado, pues puede dar lugar a una pérdida irrecuperable de la información almacenada.Unos quince minutos más tarde, y tras el necesario reinicio tenemos un Ubuntu en su punto, listo para ser degustado. Y de guarnición, decenas de aplicaciones de uso cotidiano, que harán que podamos podemos a trabajar de inmediato (navegación por internet, correo electrónico, mensajería instantánea, procesador de textos, hoja de cálculo, creador de presentaciones, editor gráfico, visores multimedia, grabadores de cd, juegos...).
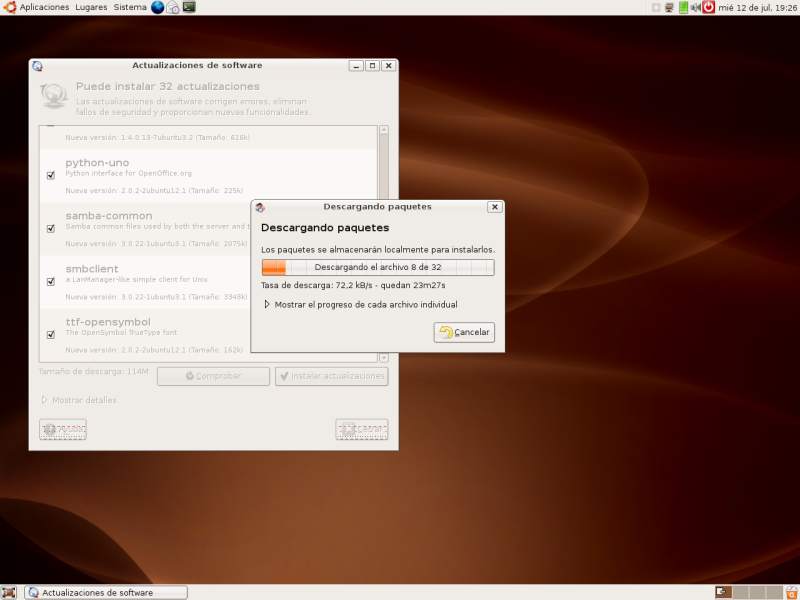 ¡Muy bien, sí señor! Si seguimos así, sin duda el software libre puede ser una alternativa al omnipotente y ubicuo (en sus respectivas primeras acepciones del diccionario de la Real Academia) Windows.
¡Muy bien, sí señor! Si seguimos así, sin duda el software libre puede ser una alternativa al omnipotente y ubicuo (en sus respectivas primeras acepciones del diccionario de la Real Academia) Windows.Y por cierto, (este párrafo ya lo estoy escribiendo desde mi nuevo Ubuntu :-)), es una maravilla, aunque esto esté ya inventado desde hace tiempo, ver cómo se actualiza muy frecuentemente de forma totalmente automática. De hecho, estas actualizaciones están aseguradas para esta versión durante tres y cinco años para las versiones desktop y servidor, respectivamente, de ahí las siglas LTS (Long Time Support) del nombre del producto.
Para finalizar, simplemente decir que hoy comienzo mis (esperadas) vacaciones. Estaré unos días en la costa de Málaga, otros en Huelva y algunos también me quedaré en casa. Eso sí, siempre con mi portátil y mi nuevo sistema operativo. A ver qué tal.
Felices vacaciones.
En esta última entrega completaremos la referencia completa de etiquetas XHTML.
Creación de tablas
A diferencia de lo que ocurre con HTML, en XHTML es una mala idea utilizar tablas para maquetar presentaciones. No olvidemos que en este punto nos encontramos describiendo el contenido, no cómo debe visualizarse en pantalla. De hecho, deberíamos acostumbrarnos a pensar en las tablas como una forma de mostrar exclusivamente datos tabulares, como puede ser la tabla de clasificación de la liga de fútbol, o un listado de movimientos bancarios.
Para ello, XHTML nos brinda los siguientes tags, de los cuales algunos son ya bastante habituales:
- caption permite definir el título de la tabla, un pequeño texto sobre su contenido.
- col define atributos de una columna contenida en un grupo creado mediante el tag <colgroup>.
- colgroup está pensado para definir grupos de columnas sobre los que se podrán aplicar atributos de forma conjunta. En su interior deberá existir un elemento <col> por cada columna que lo componga.
- table, que indica el comienzo y fin de la tabla.
- tbody, permite marcar el cuerpo de la tabla, es decir, indicar dónde se encuentran los datos de sus filas.
- td es el tag clásico de definición de una celda de la tabla.
- tfoot como en el caso de tbody, indica la sección del pie de la tabla.
- th es como td, pero se utiliza en las celdas que son encabezado de columnas.
- thead contiene el encabezado de la tabla.
- tr permite señalar el comienzo y fin de cada fila. En su interior habrá tantos <td> como columnas tenga la tabla.
Inserción de imágenes y mapas de imagen
- img permite la inserción de imágenes, como en HTML tradicional. Ojo con el cierre del tag, que es necesario como en todo documento XML.
- map y area permiten, respectivamente, la inserción de imágenes mapeadas, y la definición de áreas sensibles.
Metainformación
En algún otro post he comentado que la metainformación se define como "información sobre la información". En el contexto que nos ocupa, se trata de la información introducida en la página web que describe el contenido que podremos encontrar en ésta. Por ejemplo, esta información es extremadamente útil para las técnicas SEO, pues permiten que los buscadores conozcan de qué trata el contenido, las palabras clave, el autor, etc. El único tag disponible es bien conocido por todos:
- meta, define información sobre los contenidos de la página.
Scripting
Con XHTML también es posible utilizar scripts. De hecho, es un entorno perfecto para el desarrollo de aplicaciones AJAX. Encontramos en esta categoría dos etiquetas:
- script que permite alojar código de script en el interior de una página XHTML.
- noscript se utiliza para definir qué contenidos se utilizarán o visualizarán cuando el dispositivo cliente no disponga de capacidades de ejecución de estos elementos.
Hojas de estilo en cascada
- style permite definir en el encabezado del documento (<head>) las pautas de estilo que serán utilizadas para representar visualmente el contenido de la página.
Relación con otros documentos
- link relaciona el documento XHTML actual con otros. Es habitual utilizarlo para cargar hojas de estilo externas de la siguiente forma:
<link rel="stylesheet" type="text/css" href="theme.css" />
Base del documento
- base indica al cliente la dirección base que deberá ser aplicada para todos los enlaces relativos del documento. Y cuando digo todos, digo todos. Ojo a esto, que si se cambia la base de una página XHTML es posible que haya que revisar todas las rutas que se hayan utilizado (hojas de estilo, links, scripts, imágenes...)
Bueno, con esto ya hay suficiente para ponerse a trabajar. Seguiremos informando.
Hoy vamos a continuar en esta línea.
Enlaces hipertexto
- a, el tag de toda la vida, que ha sufrido pocas variaciones, aparte del consabido cierre obligatorio de la etiqueta en todos los casos, hasta en el establecimiento de anclas.
Composición de listas
- dl indica una lista de definiciones. En su interior habrá un par dt y dd por cada término a definir, el primero para el término y el segundo para su definición.
- dd indica la definición del término apuntado por el <dt> correspondiente.
- dt, que refleja el término a ser definido en el siguiente <dt>
- ol (ordered list) permite especificar que su contenido estará compuesto por líneas (creadas mediante el tag <li>) que serán numeradas y ordenadas conforme se vayan añadiendo a la lista.
- ul se usa para incluir listas desordenadas. Una lista desordenada es una serie de elementos consecutivos entre los que no se establece ningún tipo de relación de dependencia en función de su posición.
- li, que se utiliza para indicar cada elemento de las listas, sean ordenadas o desordenadas.
Inclusión de objetos
- object permite incluir objetos o plugins en las páginas, como pueden ser applets o animaciones Flash.
- param, se utiliza para especificar los parámetros a enviar al objeto.
Etiquetas de presentación
Hace ya algunos posts, hacía hincapié en la absoluta separación de contenidos y visualización en una página XHTML. Aunque esto es cierto, existen una serie de tags que permiten modificar ligeramente la presentación desde XHTML sin tener que recurrir a CSS:
- b, como siempre, para poner en negrilla.
- big, hace que el texto sea presentado en un tamaño de fuente mayor que el utilizado en ese momento.
- hr, que permite incluir una separación vertical en el documento, normalmente con una línea horizontal de lado a lado, aunque este comportamiento puede modificarse mediante las hojas de estilo.
- i, para que el contenido sea formateado en itálica o cursiva.
- small, reduce el tamaño de la fuente utilizada para representar su contenido.
- sub, permite incluir subíndices.
- sup, lo mismo, pero con superíndices.
- tt fuerza la utilización de caracteres en modo teletipo, con caracteres de ancho fijo.
Etiquetas de edición
Estos tags permiten enriquecer el contenido con marcas relativas a la supresión o inserción de información. Por ejemplo, serían útiles para indicar, tras una revisión, qué partes del texto han sido eliminadas o cuáles han sido insertadas por el revisor. Las etiquetas son las siguientes:
- del, que marca el texto eliminado o a eliminar.
- ins, que indica el texto nuevo.
Texto bidireccional
La inclusión de bidireccionalidad hace posible que una página pueda ser visualizada correctamente por personas cuya escritura se realiza en un sentido distinto a nuestro sistema habitual (por ejemplo, en países árabes, se lee de derecha a izquierda).
- bdo permite indicar el comienzo y finalización de un bloque de texto que podrá ser representado usando una direccionalidad distinta a la establecida en el momento.
Por ejemplo, podemos ver cómo queda un famoso palíndromo de Julio Cortázar "Átale, demoníaco Caín, o me delata" al presentarlo modificando la direccionalidad:
"Átale, demoníaco Caín, o me delata"
¡Pues era verdad esto de los palíndromos, se lee igual al derecho y al revés! El código fuente para conseguir esto ha sido:
<bdo dir="rtl"><em>"Átale, demoníaco Caín, o me delata"</em></bdo>
Formularios
- button, que permite incluir un botón.
- fieldset permite agrupar un conjunto de campos de un formulario bajo un título común, especificado mediante el tag <legend>.
- form, es el elemento raíz de todo formulario.
- input permite incluir distintos tipos de control de entrada datos. Cuidado con los cierres, que no estamos acostumbrados a hacerlo aquí.
- label es útil para asociar descripciones textuales a cada control de entrada.
- legend, se utiliza para dar un título a un fieldset.
- select permite crear un control de selección basado en desplegable o lista de selección.
- option indica cada elemento disponible en un control de tipo select, descrito anteriormente.
- optgroup, facilita la agrupación de elementos <option> para crear efectos como el siguiente:
- textarea, que, como el de toda la vida, permite la entrada de textos multilínea.
El próximo día continuaremos con los elementos de tabla, imágenes y algunas cosillas más.
A pesar de haberse reducido en número respecto a HTML4, siguen siendo bastantes, por lo que las dividiré en varios posts. En este sólo trataremos las estructurales, que componen el esqueleto básico de un documento XHTML y definen algunas de sus propiedades, y las de texto, que permiten adornar el contenido de un documento con información semántica.
Etiquetas estructurales
- body, que indica el comienzo del cuerpo de la página.
- head, que contiene la sección de encabezado de la página XHTML. Su contenido no será mostrado, y se utiliza principalmente para recoger aspectos genéricos, como el título y metainformación sobre el documento.
- html, la etiqueta raíz del documento XHTML. Antes de ella sólo existirán las destinadas a indicar los tipos de documento.
- title, que permitirá indicar el título de la página.
Estiquetas de texto
- abbr, que permite señalar las abreviaturas e indicar su significado.
- acronym, idem, con los acrónimos.
- address, utilizado para indicar localizaciones o direcciones de contacto.
- blockquote, marca una cita textual de otro documento, destacada como un bloque independiente.
- br, que fuerza la ruptura de una línea en un texto. Es importante destacar que, a diferencia de HTML, este tag debe ir cerrado, es decir, escribirse como <br />
- cite, también indicado para recoger citas, pero en la misma línea, sin necesidad de iniciar un nuevo párrafo.
- code, ideal para incluir código fuente de programas, ejemplos, etc. Cuidado al mostrar código HTML, que los caracteres < y > no pueden ser incluidos directamente, sino a través de las correspondientes entidades, < y >.
- dfn, que permite definir términos cuando, por ejemplo, aparecen por primera vez en un documento.
- div, una de las principales herramientas disponibles para estructuración de bloques que componen un documento. Todo lo que se incluya entre la etiqueta de apertura y de cierre será tratado como un bloque, al que se podrán aplicar atributos de forma conjunta. Por ello, en la práctica, cada área o grupo de elementos estructuralmente importante irá incluido en su propio div (p.e.: el menú de la web, el encabezado, el pie...).
- em, que permite destacar (emfatizar) partes del texto. Normalmente es un énfasis light, y habitualmente es representado en cursiva; para destacar de forma más violenta, es conveniente usar el tag <strong>.
- h1, h2... h6, indican que un texto es un encabezado de una sección posterior. Hay seis niveles de encabezado posibles.
- kbd, utilizado para marcar texto que debe ser introducido por el usuario mediante teclado. Puede ser interesante en documentos técnicos o manuales on-line.
- p, este sí que es el de siempre. Permite indicar el inicio y fin de los párrafos que componen un texto. Importante: debemos cerrarlo siempre, aunque HTML no nos obligara a ello.
- pre, que indica que su contenido está preformateado; a efectos prácticos, todo lo incluido entre el <pre> y el </pre> será visualizado incluyendo los espacios, tabulaciones y rupturas de línea literalmente, tal y como hayan sido incluidas en el código.
- q, otro tag que posibilita la inclusión de citas. La verdad es que, existiendo cite y blockquote, este resulta algo obviable.
- samp, que permite incluir ejemplos de resultados o salida de procesos y programas.
- span, que, como ocurría con la etiqueta <div>, se utiliza para delimitar porciones de contenido que pueden ser manipuladas, a nivel de presentación, conjuntamente. En cambio, <span> no fuerza el salto de línea, ni las separaciones presentes en el citado anteriormente, todo se realiza en la misma línea donde se encuentra.
- strong, utilizado para resaltar su contenido, de forma "fuerte". En la práctica, es habitual que la representación visual se realice en negrilla.
- var, usado para indicar que su contenido es un nombre de variable o de componente de un sistema software.
En el próximo post seguiremos enumerando y describiendo brevemente más tags pertenecientes al estándar XHTML 1.1., que nos permitirán definir enlaces hipertexto, listas, incluir objetos y muchas cosas más.
Comenzando por donde hay que hacerlo normalmente, por el principio: ¿qué es XHTML? Así al vuelo, podríamos definir el eXtensible HyperText Markup Languaje es una reformulación de HTML en XML. Es decir, una formalización del habitual lenguaje de marcas, utilizando unas normas sintácticas más estrictas, e introduciendo al mismo tiempo una fuerte separación entre los aspectos semánticos de una página Web, que será lo que recojan las páginas, y su presentación, descritas mediante CSS.
Recordemos que la semántica hace referencia al significado del contenido, independientemente del formato en que esté presentado. Esto implica, por ejemplo, que en XHTML no podremos utilizar la etiqueta <font color="blue"> para poner en azul un texto (¡esto es presentación!); sí podremos, por ejemplo, indicar que una porción del texto es importante con la etiqueta <em> o <strong> y más tarde, en la hoja de estilos, indicar que las cosas importantes queremos que aparezcan en negrita, en azul, o como sea. La buena noticia es que, dado que no se pueden usar las etiquetas habituales de formato, el conjunto de éstas se reduce considerablemente.
En cuanto a la sintaxis, deberemos acostumbrarnos a escribir siempre los tags en minúsculas; XHTML, como XML que es, es sensible á este aspecto del código. Los que estábamos acostumbrados a escribir las etiquetas siempre en mayúsculas para distinguirlas del resto, vamos a tener que ir cambiando de hábitos.
También es imperativo el cierre de todas las etiquetas; como en XML, toda etiqueta de apertura tiene que tener su correspondiente etiqueta de cierre. Es decir, nada de:
<img src='zxc.gif'>
Esto deberá convertirse, a partir de ahora en:
<img src='zxc.gif'></img>
Por suerte, los señores que inventaron el XML debían sufrir dolores en las articulaciones, por lo que decidieron que esto podría simplificarse así:
<img src='zxc.gif' />
(El espacio justo delante de la barra de cierre es a propósito, parece ser que hacerlo de otra forma causa problemas en navegadores antiguos).
Hay algún otro aspecto sintáctico adicional, como la conveniencia de sustituir caracteres especiales por su entidad correspondiente (como el ">", que debe ser sustituida por ">"), el uso obligatorio de comillas para los valores asignados a los atributos, y algún otro, pero, en general, lo dicho hasta el momento es lo más importante (aparentemente al menos).
El siguiente ejemplo muestra un documento XHTML válido completo:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="es">
<head>
<title>El saludo habitual</title>
</head>
<body>
<p>¡Hola, mundo!</p> </body></html>
Destacan los siguientes detalles:
- Tal y como se define en la primera línea, se trata de un documento XML. Esto quiere decir que deberá ser bien formado según las reglas generales de este lenguaje. Si, por ejemplo, olvidamos cerrar un tag, el documento no será válido y, por tanto, podría no ser representado.
- A continuación se define el tipo de documento, XHTML 1.1 en este caso, y la DTD o definición del tipo de documento que permitirá detectar su validez respecto a ésta; por ejemplo, un documento no sería válido XHTML 1.1 si introdujéramos un tag <img> dentro de otro, lo cual no tiene sentido. Por cierto, se está trabajando en la versión 2.0, pero se prevé que no estará lista hasta 2007.
- La siguiente línea define el elemento raíz del documento, con la etiqueta <html>. Se incluyen, además, referencias al espacio de nombres (xmlns) e idioma (xml:lang) utilizado. El primero de ellos debe tener fijo el valor http://www.w3.org/1999/xhtml, cualquier intento de modificarlo causará un error de validación; el segundo, podrá, obviamente, variarse en función del idioma del contenido.
- Las siguientes son ya bastante habituales, definiendo el contenido del documento.
El próximo día iré incorporando las etiquetas disponibles y comentando su utilidad. Hasta entonces.
Hasta el momento, para el desarrollo de sistemas web orientados a entornos locales (Intranets) con agentes de usuario controlados, me ha bastado con el conocimiento de HTML y Javascript. Sin embargo, desde hace ya algún tiempo, vengo siguiendo con mucho interés la fuerte (y lógica) acogida de los estándares W3C en este campo, debida a la necesidad evidente de evitar tecnologías (sean lenguajes o de cualquier otro tipo) propietarias, demasiado sujetas al dictado de sus titulares, y que han sido propiciados sin duda por la gran acogida y expansión de navegadores alternativos a IE provenientes del mundo del software libre, así como de dispositivos desde los que se puede acceder a la red, y la gran conciencia existente respecto a la accesibilidad de sitios webs, promovida también por la W3C a través de WAI (Web Accesibility Initiative).
Y ha llegado el momento. Está claro que después de tantos años trabajando deaquellamanera, estandarizarme un poco va a costar algo de trabajo, pero, ¿quién dijo miedo? Como de costumbre, utilizaré este espacio para recoger lo que vaya aprendiendo sobre el tema, y las conclusiones a las que vaya llegando. Mi objetivo será, en un breve periodo de tiempo, disponer de soltura suficiente como para poder desarrollar sistemas web completamente acogidos al estándar, utilizando XHTML para recoger el contenido de las páginas y CSS para la definir presentación.
En la actualidad Google SpreadSheets se publica en forma de test limitado, es decir, se trata de una versión beta (bastante avanzada, todo sea dicho) a la que no se puede acceder sin disponer de una invitación, la cual es posible solicitar desde la misma Web. A mí me ha tardado tres o cuatro días desde el momento en que rellené el formulario de solicitud.
Vale, pero comencemos por el principio: ¿qué es Google Spreadsheets? Podríamos definirlo como una hoja de cálculo completamente on-line, una especie de Excel preparada para funcionar en un navegador, sin necesidad de descargar ni instalar software alguno, y, en principio, de uso gratuito. Pinta bien, ¿eh?
Desde el punto de vista de un usuario habitual de la hoja de cálculo de Microsoft, el primer contacto con la herramienta es impresionante. Estéticamente, muy limpio (se nota que usa Ajax, permítaseme el chiste fácil ;-). El manejo, sencillísimo, y más aún si se ha utilizado Excel, puesto que los mecanismos de interacción son muy similares a los de esta popular aplicación. La velocidad, bastante buena; en las pruebas que he realizado, con hojas de cerca de 2.500 celdas con fórmulas enrevesadillas encadenadas unas a otras, en ningún momento he notado retrasos que pudieran impedir el trabajo con ellas de forma fluida.
En cuanto a las funcionalidades, salvando la ausencia de gráficas, no he echado en falta nada de lo que utiliza habitualmente un usuario de nivel bajo y medio de Excel, entre los que nos encontramos la mayoría: fórmulas, formatos, ordenaciones, e incluso operaciones con archivos. Bien es cierto que no alcanza la gran cantidad de opciones que tiene Excel, pero desde luego, las principales sí que las incorpora.
El almacenamiento se soluciona completamente en el servidor. El usuario no tiene por qué guardar nada en su disco duro, todo quedará almacenado en su carpeta de las máquinas de Google. Respecto a esto, habrá que ver si los usuarios nos podemos acostumbrar a que nuestros archivos se encuentren guardados en Internet, lo que, para un mortal, equivale a decir "no tengo ni idea de dónde están mis ficheros". Por ello, es importante destacar que importa y exporta archivos XLS directamente y, por lo que he podido comprobar, no lo hace nada mal, incluso con fórmulas y formatos relativamente complejos.
Otro detalle que muestra el nivel del producto es su implementación de la idea de trabajo colaborativo, aspecto éste donde destaca sobre sus competidores tradicionales, al menos hasta el próximo movimiento de ficha de Microsoft. Lejos de montar una infraestructura de checkin/checkout o control de versiones, han optado por la comunicación asíncrona. En otras palabras, es perfectamente posible que varias personas se encuentren a un mismo tiempo tocando la misma hoja de cálculo, a la vez que pueden estar comentando la jugada en un pequeño chat integrado en el mismo entorno. De hecho, si una de ellas modifica el contenido de una celda, el resto de participantes verán, en pocos segundos, este cambio reflejado en la hoja sobre la que están trabajando.
Esto, que puede parecer relativamente sencillo en aplicaciones de escritorio, se complica bastante en un entorno desconectado como es la web. Es curioso, mientras se está usando mantiene una conexión activa con un servidor de Google, entiendo que será el canal de recepción de datos y notificaciones:
C:\>netstat find "google"
TCP JMA:2678 05178618550233449.spreadsheets.google.com:http ESTABLISHED
Para los ases del botón derecho del ratón, y más concretamente de la opción "Ver código fuente", sin duda es una decepción. Una página web simple, de unos 3K, que no hace más que referenciar una librería javascript almacenada en un archivo externo de unos 170k, que es en realidad la que hace la magia. Las fuentes están ahí, aunque a la vista de su contenido, deduzco que han sido 'ofuscadas' para dificultar su comprensión, y que gran parte de los procesos se llevan a cabo en servidor, que devuelve el HTML de la porción a actualizar en cada momento.
En fin, en mi opinión, una auténtica maravilla, y una nueva prueba de que Google apuesta por una nueva forma de trabajar, totalmente on-line y basada en Web, como ya lleva demostrando desde hace bastante tiempo.
Y por cierto, dado que uno de los fuertes de Google es el análisis de contenidos para la presentación de publicidad altamente dirigida, ¿aplicarán esta idea a SpreadSheets? Por ejemplo, ¿nos aconsejará entidades bancarias si estamos introduciendo en la hoja de cálculo un plan de tesorería en el que aparecen números rojos? Si estamos consultando un presupuesto de hardware recibido en formato de hoja de cálculo, ¿será capaz de recomendarnos productos similares, o incluso más económicos, que los que estén reflejados en él? La verdad es que las posibilidades son infinitas, tantas como utilidades damos a las hojas de cálculo.
Hace poco, en casa de un familiar, convocado al grito de "ven a ver el ordenador que le pasa algo raro", me encontré con un panorama genial. Se trataba de un troyano (una pena, no recuerdo el nombre) descargado de algún sitio web de oscuras intenciones que se le había colado hasta el mismísimo tuétano.
"Estos malditos troyanos han secuestrado a Helena.
Visto el panorama, puse a funcionar la artillería que muy prudentemente tenía instalada la máquina: Ad-Aware, Microsoft Antispyware (beta por entonces), Norton Antivirus, y Spybot.
Nada, como si le hubiera leído algo de Homero, ni puñetera cuenta. "¡Enhorabuena, tienes un último modelo", le dije a mi pariente.
"Los griegos reunieron cien mil hombres,
Era el momento de ponerse el casco, agarrar el escudo y lanzarse al campo de batalla cual griego micénico furibundo, contra todo troyano viviente. Aunque no hay que precipitarse: lo primero, observar al enemigo.
Lo que me llamó la atención en primer lugar era que estaba bastante bien hecho, lo que que me hizo reflexionar sobre el desperdicio de habilidades de determinados individuos. Deberían dedicar su tiempo y conocimientos a creaciones más útiles y menos nocivas.
El bichillo, como es habitual, se escondía en el registro de aplicaciones de arranque, es decir, se cargaba con el sistema operativo y consistía en tres ejecutables, con nombres similares a los procesos propios de Windows (como svchost.exe, winlogon.exe, spoolsv.exe...) a los que cambiaba la denominación levemente (scvhost.exe, winlogon.dll, spoolsvc.exe...) para que pasaran desapercibidos.
Estos tres ejecutables se encontraban en el disco duro, en el directorio Windows\System32, lo cual dificultaba aún más su localización, pero lo peor de todo es que no se podían eliminar: al estar cargados en memoria, los archivos siempre se encontraban en uso. Además, funcionaban de la siguiente forma:
- se protegían entre sí: si alguno de ellos dejaba de funcionar (por ejemplo, matando el proceso), uno de los otros dos volvía a lanzarlo. Supongo que cada proceso vigilaba a los otros dos, formando así una cadena difícil de romper.
- protegían las entradas el registro del sistema mediante las cuales se lanzaban al iniciar Windows. Era curioso: tal y como las cambiaba en el registro, ellos volvían a dejarlas como estaban en pocos segundos.
- protegían la página de inicio del navegador, así como la de búsqueda. Al modificarlas ocurría como en el caso anterior, raudos acudían a restituir los valores oportunos.
- protegían la desinstalación de complementos del navegador. La criatura también se instalaba aquí, tomando el control en el momento de abrir el Internet Explorer.
"Troya tenía unos muros inexpugnables"
Durante la primera fase, realicé varios intentos de anulación básicos, que más que nada fueron útiles para poder conocer mejor a mi contendiente. De hecho, todas las características que he comentado en la lista anterior las fui descubriendo conforme intentaba anular sus funcionalidades. Digamos que durante esta fase, siempre ganó él.
"Durante el tiempo del asedio, los bandos rivales
se hostigaban continua y salvajemente"
Estaba claro que había que recurrir a herramientas más sofisticadas. Dado que que era imposible utilizar software de eliminación de engendros de este tipo puesto que era demasiado reciente y aún no existían soluciones (vacunas) específicas, opté por descargar dos magníficas herramientas de Sysinternals: Process Explorer y Autoruns. La primera de ellas permite visualizar los procesos activos en la máquina con un nivel de detalle muy superior al provisto por el Administrador de Tareas de Windows. La segunda, permite acceder de forma muy sencilla a las zonas del registro del sistema donde se definen las aplicaciones que cargan de forma automática al iniciar el sistema operativo.
Después llegué a la obvia conclusión de que la clave estaba en anular los tres procesos centrales. Si conseguía pararlos, podría quitarlos tranquilamente del registro e incluso eliminar los archivos del disco duro. Pero claro, debía parar los procesos, tarea difícil por la protección a tres bandas que tenían implementada.
Dado que el programador del invento detectaba cuándo determinado módulo dejaba de estar en memoria para volver a lanzarlo, pensé que sería una buena idea probar a suspenderlos, es decir, paralizar su ejecución. Efectivamente, era el camino hacia la solución: al suspender el proceso, éste seguía estando en memoria, y por tanto los otros dos no detectaban nada anormal. Así, una vez estaban los dos primeros congelados, el tercer módulo pudo ser matado sin oponer resistencia alguna. Y después, a matar los otros dos. Ya tenía la memoria limpia.
"Ulises tuvo una gran idea. Construir un caballo de madera,
en cuyo interior se escondían varias decenas de soldados griegos"
A partir de ahí, todo fue mucho más sencillo. Con ayuda del software Autoruns limpié el registro de entradas en las secciones oportunas, haciendo que no se intentara ejecutar nada al arrancar, eliminé el complemento cargado en Internet Explorer y, por último, hice desaparecer para siempre los archivos del disco duro.
"Una vez llegó la noche, los soldados salieron del caballo y
abrieron las puertas a sus tropas, que invadieron y saquearon la ciudad"











{kind=link}
{kind=link}