
domingo, 20 de abril de 2008
jQuery, para que el no haya oído hablar de ella, es una librería Javascript destinada a facilitar enormemente la vida a los desarrolladores simplificando y unificando el manejo de eventos, la manipulación del contenido (DOM), estilos, el uso de Ajax, la creación de animaciones y efectos gráficos, y un larguísimo etcétera propiciado por la facilidad para añadirle plugins que extienden sus funcionalidades iniciales. Y todo ello de forma muy rápida, sin excesivas complicaciones, y sin añadir demasiado peso a las páginas.
En este post vamos a ver un ejemplo de integración de jQuery con ASP.NET MVC framework realizando una aplicación muy sencilla e ilustrativa que nos enseñará cómo enviar información desde el cliente al servidor y actualizar porciones de página completas con el retorno de éste, respetando en todo momento la filosofía MVC.
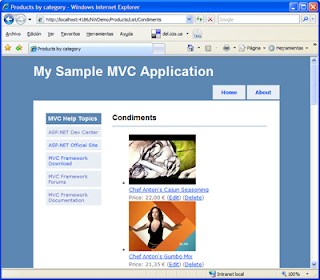
El funcionamiento será realmente simple: el usuario introduce su nombre y edad, y al pulsar el botón se enviará esta información al servidor, que la utiliza para componer una respuesta y mandarla de vuelta al cliente. Cuando éste la recibe, la mostrará (con un poco de 'magia' visual de jQuery) y transcurridos unos segundos, desaparecerá de forma automática. La siguiente captura muestra el sistema que vamos a construir en ejecución:

Pero antes de entrar en faena, unos comentarios. En primer lugar, sólo voy a explicar los aspectos de interés para la realización del ejemplo, partiendo de las plantillas adaptadas para Web Developer Express 2008. Si prefieres antes una introducción sobre el framework, puedes visitar las magníficas traducciones de Thinking in .Net de los tutoriales de Scott Guthrië sobre MVC. Se refieren a la primera preview, pero los fundamentos son igualmente válidos.
Segundo, supongo que funcionará con versiones superiores de Visual Studio, pero no he podido comprobarlo. Está creado y comprobado con Visual Web Developer Express, y la Preview 2 del framework MVC.
Y por último, decir que el ejemplo completo podrás descargarlo usando el enlace que encontrarás al final del post. :-)
Primero: Estructuramos la solución
En líneas generales, nuestra aplicación tendrá los siguientes componentes:- Tendremos un controlador principal, llamado Home. En él crearemos dos acciones, las dos únicas que permite nuestra aplicación: una, llamada Index, que se encargará de mostrar la página inicial del sistema, y otra llamada Welcome, que a partir de los datos introducidos por el usuario maquetará el interfaz del mensaje de saludo.
- Como consecuencia del punto anterior, dispondremos de dos vistas. La primera, Index compondrá la interfaz principal con el formulario, y la segunda, que llamaremos Welcome, que define la interfaz del saludo al usuario (el recuadro de color amarillo chillón ;-)).
Esta última vista necesitará los datos de la persona (nombre y edad) para poder mostrar correctamente su mensaje, por lo que el controlador deberá enviárselos después de obtenerlos de los parámetros de la petición.
Fijaos que respetamos en todo momento el patrón MVC haciendo que el cliente invoque a la acción Welcome del controlador usando Ajax, y que la composición del interfaz (HTML) se realice a través de la vista correspondiente. Utilizaremos, por tanto, toda la infraestructura del framework MVC, sin modificaciones. - También, para añadir algo de emoción, he incluido una página maestra, que definirá el interfaz general de las páginas del sistema y realizará la inclusión de los archivos adicionales necesarios, como las hojas de estilo y scripts como jQuery.
Segundo: implementamos el controlador
El controlador de nuestra aplicación va a ser bien simple. Lo vemos y comentamos seguidamente:public class HomeController : Controller
{
public void Index()
{
RenderView("Index");
}
public void Welcome(string name, int age)
{
Person person =
new Person { Age = age, Name = name };
RenderView("Welcome", person);
}
}
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}Podemos observar la clase
HomeController que implementa las acciones del controlador Home. La acción Index provoca la visualización de la vista de su mismo nombre. La acción Welcome, es algo más compleja; en primer lugar, se observa que recibe dos parámetros, en nombre y edad del usuario, que utiliza para montar un objeto de tipo
Person, definido algo más abajo, que posteriormente envía a la vista a la hora de renderizarla. Habréis observado aquí la utilización de inicializadores de objetos en la instanciación, y de propiedades automáticas en la definición del tipo.Tercero: implementamos las vistas
Recordemos que vamos a implementar dos vistas, una para la página principal (llamada Index), que mostrará el formulario de entrada de datos, y otra (que llamaremos Welcome) que definirá el interfaz de la respuesta del servidor. Comenzaremos describiendo cómo incluir jQuery en nuestras páginas, y pasaremos después a ellas.3.1. Inclusión de jQuery
Para implementar las vistas necesitamos antes preparar la infraestructura. En primer lugar, descargamos jQuery desde la web oficial del proyecto, y la introducimos en nuestro proyecto. Si vas a descargar la solución completa desde aquí, en ella ya viene incluido el archivo.A continuación, es un buen momento para modificar la página maestra e incluir en ella la referencia a esta librería:
<script type="text/javascript"
src="/scripts/jquery-1.2.3.min.js">
</script>Un inciso importante aquí. Hace unas semanas se publicó un HotFix para Visual Studio 2008 y Web Developer Express que corrije, entre otras, deficiencias en el intellisense y hacen posible el uso de esta magnífica ayuda cuando escribimos código jQuery. Altamente recomendable, pues, instalarse esta actualización.
Sin embargo, el hecho de introducir en la página maestra la referencia a la librería jQuery hace que el intellisense no funcione como debe. Por tanto, aunque no es la opción que he elegido en este proyecto, podríais incluir el script directamente en la vista Index en lugar de en la Master, y así disfrutaréis del soporte a la codificación.
3.2. La vista "Index"
Esta vista será la encargada de mostrar el formulario e implementar la lógica de cliente necesaria para obtener los datos del usuario, enviarlos al servidor y actualizar el interfaz con el retorno. Su implementación se encuentra en el archivo Index.aspx.Desde el punto de vista del interfaz de usuario es bastante simple, lo justo para mostrar un par de inputs con sus correspondientes etiquetas y el botón que iniciará la fiesta llamando a la función
send():<form action="" id="myForm">
<label for="name">Name: </label><input type="text" id="name" />
<br />
<label for="age">Age: </label><input type="text" id="age" size="2" />
<br />
<button id="btn" onclick="send(); return false;">Send!</button>
</form>
<hr />
<div id="result" style="display: none; width: 400px"></div>Observad que no es necesario establecer un action en el formulario, ni otros de los atributos habituales, pues éste no se enviará (de hecho, el formulario incluso sería innecesario). Fijaos también que el evento
onclick del botón retorna false, para evitar que se produzca un postback (¡aaargh, palabra maldita! ;-)) del formulario completo.Puede verse también un
div llamado "result", inicialmente invisible, que se utilizará de contenedor para mostrar las respuestas obtenidas desde el servidor.Pasemos ahora al script. La función
send() invocada como consecuencia de la pulsación del botón pinta así: function send()
{
var name = document.getElementById("name").value;
var age = document.getElementById("age").value;
updateServerText(name, age);
}En realidad no hace gran cosa: obtiene el valor de los textboxes y llama a la función que realmente hace el trabajo duro. Este hubiera sido un buen sitio para poner validadores, pero eso os lo dejo de deberes ;-).
El código de la función
updateServerText() es el siguiente: function updateServerText(name, age)
{
document.getElementById("btn").disabled = true;
$.ajax({
cache: false,
url: '<%= Url.Action("Welcome", "Home") %>',
data: {
Name: name,
Age: age
},
success: function(msg) {
$("#result").html(msg).show("slow");
},
error: function(msg) {
$("#result").html("Bad parameters!").show("slow");
}
});
setTimeout(function () {
document.getElementById("btn").disabled = false;
$("#result").hide("slow");
}, 3000);
}En primer lugar, se desactiva el botón de envío para evitar nuevas pulsaciones hasta que nos interese. He utilizado un método habitual del DOM,
getElementById() para conseguirlo, no encontré una alternativa mejor en jQuery.A continuación se utiliza el método
ajax de jQuery para realizar la llamada al servidor. Aunque existen otras alternativas de más alto nivel y por tanto más fáciles de utilizar, elegí esta para tener más control sobre lo que envío, la forma de hacerlo y la respuesta. Los parámetros utilizados en la llamada a
$.ajax son:cache, con el que forzamos la anulación de caché, obligando a que cada llamada se ejecute totalmente, sin utilizar el contenido almacenado en cliente. Internamente, jQuery añade al querystring un parámetro aleatorio, con lo que consigue que cada llamada sea única.url, la dirección de invocación de la acción, que se genera utilizando el método de ayudaUrl.Action(), pasándole como parámetros el controlador y la acción, lo que retornará la URL asociada en el sistema de rutas definido. En condiciones normales, si la aplicación se ejecuta sobre el raíz del servidor web, se traducirá por '/Home/Welcome'.data, los datos a enviar, que se establecen en formato JSON, donde cada propiedad va seguida de su valor. jQuery tomará estos valores y los transformará en los parámetros que necesita la acción Welcome, por lo que el nombre de las propiedades deberá corresponder con los parámetros que espera esta acción (Name y Age).sucessdefine la función de retorno exitoso, que mostrará los datos recibidos del servidor introduciéndolos en el contenedor "result". Y ya que estamos, gracias a la magia de jQuery, se mostrará con un efecto visual muy majo.error, define una función de captura de errores para casos extraños, por si todo falla. Por ejemplo, dado que no estamos validando la entrada del usuario, si éste introduce texto en la edad, el framework no será capaz de realizar la conversión para pasarle los parámetros al controlador y fallará estrepitosamente; en este caso simplemente mostraremos un mensaje de error en cliente.
Fijaos que la llamada a la acción (Welcome) del controlador (Home) es capturada por el framework y dirigida al método correspondiente sin necesidad de hacer nada más, dado que se trata de una llamada HTTP normal. De hecho, si sobre el navegador se introduce la dirección "http://localhost:[tupuerto]/Home/Welcome?Name=Peter&Age=12" podremos ver en pantalla el mismo resultado que recibirá la llamada Ajax.

Obviamente, este efecto podría ser controlado y hacer que sólo se respondieran peticiones originadas a través de Ajax y similares.
Por último, continando con el código anterior, dejamos programado un timer para que unos segundos más tarde, el mensaje mostrado, sea cual sea el resultado de la llamada Ajax, desaparezca lentamente y, de paso, se active de nuevo el botón de envío. El efecto, ya lo veréis si ejecutáis la solución, es de lo más vistoso, creando una sensación de interactividad y dinamismo muy a lo 2.0 que está tan de moda.
3.3. La vista "Welcome"
En esta vista definiremos el interfaz del mensaje que mostraremos al usuario cuando introduzca su información y pulse el botón de envío. Dado que estamos usando MVC, la llamada Ajax descrita anteriormente llegará al controlador y éste hará que la vista cree el interfaz que será devuelto al cliente.La vista, por tanto, es como cualquier otra, salvo algunas diferencias interesantes. Por ejemplo, no tiene página maestra, no la necesita; de hecho ni siquiera tiene la estructura de una página HTML completa, sólo de la porción que necesita para montar su representación. El código de Welcome.aspx, salvo las obligatorias directivas iniciales, es:
<div style="background-color: Yellow; border: 1px solid black;">
<em>Message from server (<%=DateTime.Now %>):</em><br />
Hi, <%= ViewData.Name %>, your age is <%= ViewData.Age %>
</div>Pero aún queda un detalle que afinar. En el archivo code-behind (o codefile) donde se define la clase
Welcome hay que indicar expresamente que la clase es una vista de un tipo concreto de la siguiente forma: public partial class Views_WebParts_Welcome : ViewPage<Person>
{
}De esta forma indicamos que los datos de la vista son del tipo
Person, lo que nos permite beneficiarnos del tipado fuerte en la composición de la misma; de hecho, esto es lo que permite que podamos usar tan alegremente una expresión como ViewData.Age a la hora de componer el interfaz.Fijaos que aunque en este ejemplo no hemos hecho ninguna composición compleja y los datos que hemos usado, contenidos en
ViewData, han sido obtenidos por el Controlador directamente de la vista, sería exactamente igual si se tratara de algo menos simple, como una página concreta de datos obtenidos desde el Modelo, por ejemplo con Linq, y mostrados en forma de grid. Cuarto: recapitulamos
Hemos visto, paso a paso, un ejemplo de cómo podemos utilizar el framework MVC de Microsoft para el desarrollo de aplicaciones web que hacen uso de Ajax, utilizando para ello la excelente librería de scripting jQuery.Para ello hemos creado una vista que es la página Web con el formulario principal, y otra vista parcial con el fragmento compuesto por el servidor con la información recibida. El controlador, por su parte, incluye acciones para responder a las peticiones del cliente independientemente de si se originan a través de Ajax o mediante la navegación del usuario, mostrando la vista oportuna.
La modificación dinámica del interfaz, así como las llamadas asíncronas al servidor, encajan perfectamente en la filosofía MVC teniendo en cuenta algunas reglas básicas, como el respeto a las responsabilidades de cada capa.
Y ahora, lo prometido:
 Descargar proyecto (Visual Web Developer Express 2008).
Descargar proyecto (Visual Web Developer Express 2008).Publicado en: www.variablenotfound.com.
martes, 15 de abril de 2008
 Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".
Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".Recordemos que una parte de una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el compilador eliminará tanto la declaración del método como las llamadas que se hagan al mismo.
Sin embargo esta eliminación pueden causar efectos no deseados difíciles de detectar.
Veámoslo con un ejemplo. Supongamos una clase parcial como la siguiente, que representa a una variable de tipo entero que puede ser incrementada o decrementada a través de métodos:
public partial class Variable
{
partial void Log(string msg);
private int i = 0;
public void Inc()
{
i++;
Log("Incremento. I: " + i);
}
public void Dec()
{
Log("Decremento. I: " + (--i));
}
public int Value
{
get { return i; }
}
}
Creamos ahora un código que utiliza esta clase de forma muy simple: crea una variable, la incrementa dos veces, la decrementa una vez y muestra el resultado:
Variable v = new Variable();
v.Inc();
v.Inc();
v.Dec();
Console.WriteLine(v.Value);
Obviamente, tras la ejecución de este código la pantalla mostrará por consola un "1", ¿no? Claro, el resultado de realizar dos incrementos y un decremento sobre el cero.
Pues no necesariamente. De hecho, es imposible conocer, a la vista del código mostrado hasta ahora, cuál será el resultado mostrado por consola al finalizar la ejecución. Dependiendo de la existencia de la implementación del método parcial
Log(), declarado e invocado en la clase Variable anterior, puede ocurrir:- Si existe otra porción de la misma clase (otra
partial class Variable) donde se implemente el método, se ejecutará éste. El valor mostrado por consola, salvo que desde esta implementación se modificara el valor del campo privado, sería "1". - Si no existe una implementación del método
Log()en la clase, el compilador eliminará todas las llamadas al mismo. Pero si observáis, esto incluye el decremento del valor interno, que estaba en el interior de la llamada como un autodecremento:
Por tanto, en este caso, el compilador eliminará tanto la llamada aLog("Decremento. I: " + (--i));Log()como la operación que se realiza en el interior. Obviamente, el resultado de ejecución de la prueba anterior sería "2".
Lo mismo ocurriría si el resultado a mostrar fuera el valor de retorno de una llamada a otra función: esta no se ejecutaría, lo cual puede ser grave si en ella se realiza una operación importante, como por ejemplo:public function InicializaValores()
{
Log("Elementos reestablecidos: " + reseteaElementos() );
}
Por ejemplo, imaginad que el ejemplo anterior contiene una implementación de
Log(); la aplicación funcionaría correctamente. Sin embargo, si pasado un tiempo se decide eliminar esta implementación (por ejemplo, porque ya no es necesario registrar las operaciones realizadas), la operación de decremento (Dec()) dejaría de funcionar. Aunque, eso sí, no es nada que no se pueda solucionar con un buen juego de pruebas...
Publicado en: http://www.variablenotfound.com/.
domingo, 13 de abril de 2008
 Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.
Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.Estos métodos, declarados en el contexto de una clase parcial, permiten comunicar de forma segura los distintos fragmentos de dicha clase. De forma similar a los eventos, permiten que un código incluya una llamada a una función que puede (o no) haber sido implementada por un código cliente, aunque en este caso obligatoriamente la implementación se encontrará en uno de los fragmentos de la misma clase desde donde se realiza la llamada.
En la práctica significa que una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el código correspondiente a la llamada será eliminado en tiempo compilación para optimizar el resultado... ¡sí, eliminado!
Por ejemplo, el siguiente código muestra una declaración de un método parcial en el interior de una clase, y su utilización desde dentro de uno de sus métodos:
// C#
public partial class Ejemplo
{
// El método parcial se declara
// sin implementación...
partial void Log(string msg);
public void RealizarAlgo()
{
hacerAlgoComplejo();
Log("¡Ojo!"); // Usamos el método
// parcial declarado antes
}
[...] // Otros métodos y propiedades
}
' VB.NET
Partial Public Class Ejemplo
' El método parcial se declara, sin
' implementar nada en el cuerpo
Partial Private Sub Log(ByVal msg As String)
End Sub
Public Sub RealizarAlgo()
HacerAlgoComplejo()
Log("¡Ojo!") ' Usamos el método parcial
End Sub
[...] ' Otros métodos y propiedades
End Class
Y esta la parte realmente curiosa. Cuando el compilador detecta la invocación del método parcial
Log(), buscará en todos los fragmentos de la clase a ver si existe una implementación del mismo. Si no existe, eliminará del ensamblado resultante la llamada a dichos métodos, es decir, actuará como si éstas no existieran en el código fuente.En caso afirmativo, es decir, si existen implementaciones como las del siguiente ejemplo, todo se ejecutará conforme a lo previsto:
// C#
public partial class Ejemplo
{
partial void Log(string msg)
{
Console.WriteLine(msg);
}
}
' VB.Net
Partial Public Class Ejemplo
Private Sub Log(ByVal msg As String)
Console.WriteLine(msg)
End Sub
End Class
Antes comentaba que los métodos parciales son, en cierto sentido, similares a los eventos, pues conceptualmente permiten lo mismo: pasar el control a un código cliente en un momento dado, en el caso de que éste exista. De hecho, hay muchos desarrolladores que lo consideran como un sustituto ligero a los eventos, pues permite prácticamente lo mismo pero se implementan de forma más sencilla.
Existen, sin embargo, algunas diferencias entre ambos modelos, como:
- Los métodos parciales se implementan en la propia clase, mientras que los eventos pueden ser consumidos también desde cualquier otra
- El enlace, o la suscripción, a eventos es dinámica, se realiza en tiempo de ejecución, es necesario incluir código para ello; los métodos parciales, sin embargo, se vinculan en tiempo de compilación
- Los eventos permiten múltiples suscripciones, es decir, asociarles más de un código cliente
- Los eventos pueden presentar cualquier visibilidad (pública, privada...), mientras que los métodos parciales son obligatoriamente privados.
Por último, es conveniente citar algunas consideraciones sobre los métodos parciales:
- Deben ser siempre privados (ya lo había comentado antes)
- No deben devolver valores (en VB.Net serían
SUB, en C# serían de tipovoid) - Pueden ser estáticos (shared en VB)
- Pueden usar parámetros, acceder a los miembros privados de la clase... en definitiva, actuar como un método más de la misma
En resumen, los métodos parciales forman parte del conjunto de novedades de C# y VB.Net que no son absolutamente necesarias y que a veces pueden parecer incluso diabólicas, pues facilitan la dispersión de código y dificultan la legibilidad. Además, en breve publicaré un post comentando posibles efectos laterales a tener en cuenta cuando usemos los métodos parciales en nuestros desarrollos.
Sin embargo, es innegable que los métodos parciales nos facilitan enormemente la inclusión de código de usuario en el interior de clases generadas de forma automática. Por ejemplo, el diseñador visual del modelo de datos de LinqToSQL genera los
DataContext como clases parciales, en las que define un método parcial llamado OnCreated(). Si el usuario quiere incluir alguna inicialización personal al crear los DataContext, no tendrá que tocar el código generado de forma automática; simplemente creará otro fragmento de la clase parcial e implementará este método, de una forma mucho más natural y cómoda que si se tratara de un evento.Publicado en: http://www.variablenotfound.com/.
jueves, 10 de abril de 2008
 Pablo ha lanzado una pregunta en el post Deshabilitar y habilitar un validador ASP.Net desde Javascript publicado hace unos meses, que creo interesante responder en una entrada en exclusiva, por si puede ayudar a alguien más.
Pablo ha lanzado una pregunta en el post Deshabilitar y habilitar un validador ASP.Net desde Javascript publicado hace unos meses, que creo interesante responder en una entrada en exclusiva, por si puede ayudar a alguien más."Al utilizar la funcion ValidatorEnable para habilitar un validador, me activa automaticamente la validacion, y me muestra el texto que pongo para cuando la validacion no se cumpla, como puedo evitar esto"
Recordemos que el post trataba sobre cómo conseguir, desde Javascript, habilitar o deshabilitar validadores de controles incluidos en un webform utilizando la función
ValidatorEnable(), que pone a nuestra disposición ASP.Net.El problema, como comenta Pablo, es que al habilitar la validación desde script se muestran de forma automática los mensajes de error en todos aquellos controles que no sean válidos, provocando un efecto que puede resultar desconcertante para el usuario.
Indagando un poco, he comprobado que el problema se debe a que
ValidatorEnable(), después de habilitar el validator, comprueba si los valores del control son correctos, mostrando el error en caso contrario.Existen al menos dos formas de solucionar este problema.
La primera consiste en jugar con la visibilidad del mensaje de error. Como se observa en el siguiente código, al llamar a la función
HabilitaValidador(), ésta llamará a ValidatorEnable y acto seguido, si el control no es válido, oculta el mensaje de error:
function HabilitaValidador(validator, habilitar)
{
ValidatorEnable(validator, habilitar);
if (habilitar && !validator.isvalid)
validator.style.visibility = "hidden";
}
La segunda forma consiste en simular el comportamiento interno de
ValidatorEnable, pero eliminando la llamada a la comprobación de la validez del control.
function HabilitaValidador(validator, habilitar)
{
validator.enabled = habilitar;
}
Como se puede ver, simplemente se está estableciendo la propiedad
enabled del validador, sin realizar ninguna comprobación posterior.En ambos casos, la forma de utilizar esta función desde script sería la misma:
function activar()
{
HabilitaValidador("<%= RequiredFieldValidator1.ClientID %>", true);
}
Para mi gusto la opción más limpia, aunque sea jugando con la visibilidad de los elementos, es la primera de las mostradas, pues se respeta el ciclo completo de validación. En el segundo método nos estamos saltando las validaciones y el seguimiento de la validez global de la página, que la función original
ValidatorEnable sí contempla.Espero que esto resuelva la duda.
Publicado en: www.variablenotfound.com.
domingo, 6 de abril de 2008
 Semanas atrás publicaba el post "101 citas célebres del mundo de la informática", la traducción del post original de Timm Martin en Devtopics, "101 Great computer quotes". El tema me pareció tan divertivo e interesante que he realizado una nueva recopilación de otras tantas frases relacionadas con el mundo de la informática, y con especial énfasis en el desarrollo de software.
Semanas atrás publicaba el post "101 citas célebres del mundo de la informática", la traducción del post original de Timm Martin en Devtopics, "101 Great computer quotes". El tema me pareció tan divertivo e interesante que he realizado una nueva recopilación de otras tantas frases relacionadas con el mundo de la informática, y con especial énfasis en el desarrollo de software.Este es el segundo post de la serie compuesta por:
- 101 citas célebres del mundo de la informática
- Otras 101 citas célebres del mundo de la informática (este post)
- Y todavía otras 101 citas célebres del mundo de la informática
- 101 nuevas citas célebres del mundo de la informática (¡y van 404!)
miércoles, 2 de abril de 2008
Aunque las clases parciales aparecieron hace unos años, con la llegada de .Net 2.0 y Visual Studio 2005, vamos a hacer un breve repaso como preparación para un próximo post que trate los métodos parciales.Las clases parciales (llamados también tipos parciales) son una característica presente en algunos lenguajes de programación, como C# y VB.Net, que permiten que la declaración de una clase se realice en varios archivos de código fuente, rompiendo así la tradicional regla "una clase, un archivo". Será tarea del compilador tomar las porciones de los distintos archivos y fundirlas en una única entidad.
En VB.Net y C#, a diferencia de otros lenguajes, es necesario indicar explícitamente que una clase es parcial, es decir, que es posible que haya otros archivos donde se continúe la declaración de la misma, usando en ambos con la palabra clave
partial en la definición del tipo: ' VB.NET
Public Partial Class Persona
...
End Class
// C#
public partial class Persona
{
...
}
En este código hemos visto cómo se declara una clase parcial en ambos lenguajes, que es prácticamente idéntica salvo por los detalles sintácticos obvios. Por ello, a partir de este momento continuaré introduciendo los ejemplos sólo en C#.
Pero antes un inciso: la única diferencia entre ambos, estrictamente hablando, es que C# obliga a que todas las apariciones de la clase estén marcadas como parciales, mientras que en VB.Net puede dejarse una de ellas (llamémosla "declaración principal") sin indicar que es parcial, y especificarlo en el resto de apariciones. En mi opinión, esta no es una práctica recomendable, por lo que aconsejaría utilizar el modificador
partial siempre que la clase lo sea, e independientemente del lenguaje utilizado, pues contribuirá a la mantenibilidad del código.El número de partes en las que se divide una clase es indiferente, el compilador tomará todas ellas y generará en el ensamblado como si fuera una clase normal.
Para comprobarlo he creado un pequeño código con dos clases exactamente iguales, salvo en su nombre. Una de ellas se denomina
PersonaTotal, y está definida como siempre, en un único archivo; la otra, PersonaParcial, es parcial y la he troceado en tres archivos, como sigue: // *** Archivo PersonaParcial.Propiedades.cs ***
// Aquí definiremos todas las propiedades
partial class PersonaParcial
{
public string Nombre { get; set; }
public string Apellidos { get; set; }
}
// *** Archivo PersonaParcial.IEnumerable.cs ***
// Aquí implementaremos el interfaz IEnumerable
partial class PersonaParcial: IEnumerable
{
public IEnumerator GetEnumerator()
{
throw new NotImplementedException();
}
}
// *** Archivo PersonaParcial.Metodos.cs ***
// Aquí implementaremos los métodos que necesitemos
partial class PersonaParcial
{
public override string ToString()
{
return Nombre + " " + Apellidos;
}
}
Y efectivamente, el resultado de compilar ambas clases, según se puede observar con ILDASM es idéntico:

A la hora de crear clases parciales es conveniente tener los siguientes aspectos en cuenta:
- Los atributos de la clase resultante serán la combinación de los atributos definidos en cada una de las partes.
- El tipo base de los distintos fragmentos debe ser el mismo, o aparecer sólo en una de las declaraciones parciales.
- Si se trata de una clase genérica, los parámetros deben coincidir en todas las partes.
- Los interfaces que implemente la clase resultante será la unión de todos los implementados por las distintas secciones.
- De la misma forma, los miembros (métodos, propiedades, campos...) de la clase final será la unión de todos los definidos en las distintas partes.
Vale, ya hemos visto qué son y cómo se usan, pero, ¿para qué sirven? ¿cuándo es conveniente utilizarlas? Pues bien, son varios los motivos de su existencia, algunos discutibles y otros realmente interesantes.
En primer lugar, no era sencillo que varios desarrolladores trabajaran sobre una misma clase de forma concurrente. Incluso utilizando sistemas de control de versiones (como Sourcesafe o Subversion), la unidad mínima de trabajo es el archivo de código fuente, y la edición simultánea podía generar problemas a la hora de realizar fusiones de las porciones modificadas por cada usuario.
En segundo lugar, permite que clases realmente extensas puedan ser troceadas para facilitar su comprensión y mantenimiento. Igualmente, puede utilizarse para separar código en base a distintos criterios:
- por ejemplo, separar la interfaz (los miembros visibles desde el exterior de la clase) y por otra los miembros privados a la misma
- o bien separar las porciones que implementan interfaces, o sobreescriben miembros de clases antecesoras de los pertenecientes a la propia clase
- o separar temas concernientes a distintos dominios o aspectos
Así, es posible que un desarrollador y un generador estén introduciendo cambios sobre la misma clase sin molestarse, cada uno jugando con su propia porción de la clase; el primero puede introducir funcionalidades sin preocuparse de que una nueva generación automática de código pueda machacar su trabajo. Visual Studio y otros entornos de desarrollo hacen uso intensivo de esta capacidad, por ejemplo, en los diseñadores visuales de Windows Forms, WPF, ASP.Net e incluso el generador de modelos de LinqToSql.
Publicado en: http://www.variablenotfound.com/.
domingo, 30 de marzo de 2008
 Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.
Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.Google nos tiene acostumbrados a implementar APIs muy sencillas de usar, y en este caso no podía ser menos. Para demostrarlo, vamos a crear una página web con un sencillo traductor en Javascript, comentando paso por paso lo que hay que hacer para que podáis adaptarlo a vuestras necesidades.
Paso 1: Incluir el API
La inclusión de las funciones necesarias para realizar la traducción es muy sencilla. Basta con incluir el siguiente código, por ejemplo, en la sección HEAD de la página: <script type="text/javascript"
src="http://www.google.com/jsapi">
</script>
<script type="text/javascript">
google.load("language", "1");
</script>
El primer bloque descarga a cliente la librería javascript Ajax API Loader, el cargador genérico de librerías Ajax utilizado por Google. Éste se usa en el segundo bloque script para cargar, llamando a la función
google.load el API "language" (traductor), en su versión 1 (el segundo parámetro).Paso 2: Creamos el interfaz
Nuestro traductor será realmente simple. Además, vamos a contemplar un pequeño subconjunto de los idiomas permitidos para no complicar mucho el código, aunque podéis añadir todos los que consideréis necesarios.El resultado será como el mostrado en la siguiente imagen.

El código fuente completo lo encontraréis al final del post, por lo que no voy a repetirlo aquí. Simplemente indicar que tendremos un
TextArea donde el usuario introducirá el texto a traducir, dos desplegables con los idiomas origen y destino de la traducción, y un botón que iniciará la acción a través del evento onclick. Por último, se reservará una zona en la que insertaremos el resultado de la traducción.Ah, un detalle interesante: en el desplegable de idiomas de origen se ha creado un elemento en el desplegable "Auto", cuyo valor es un string vacío; esto indicará al motor de traducción que infiera el idioma a partir del texto enviado.
Paso 3: ¡Traducimos!
La pulsación del botón provocará la llamada a la funciónOnclick(), desde donde se realizará la traducción del texto introducido en el TextArea.Como podréis observar en el código, en primer lugar obtendremos los valores de los distintos parámetros, el texto a traducir y los idiomas origen y destino, y lo introducimos en variables para facilitar su tratamiento.
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
Acto seguido, realizamos la llamada al traductor. El primer parámetro será el texto a traducir, seguido de los idiomas (origen y destino), y por último se introduce la función callback que será invocada cuando finalice la operación; hay que tener en cuenta que la traducción es realizada a través de una llamada asíncrona a los servidores de Google:
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
Como podéis observar, y es quizás lo único extraño que tiene esta instrucción, el callback se ha definido como una función anónima definida en el espacio del mismo parámetro (podéis ver otro ejemplo de este tipo de funciones cuando explicaba cómo añadir funciones con parámetros al evento OnLoad).
Para los queráis jugar con esto directamente, ahí va el código listo para un copiar y pegar.
<html>
<head>
<title>Traductor</title>
<script type="text/javascript" src="http://www.google.com/jsapi"></script>
<script type="text/javascript">
google.load("language", "1");
</script>
</head>
<body>
<textarea id="text" rows="8" cols="40">Hi, how are you?</textarea>
<br />
<button onclick="onClick()">
Traducir</button>
Del idioma
<select id="srcLang">
<option value="">(Auto)</option>
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
Al
<select id="dstLang">
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
<h3>Traducción:</h3>
<div id="result">
(Introduce un texto)
</div>
</body>
<script type="text/javascript">
function onClick()
{
// obtenemos el texto y los idiomas origen y destino
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
// llamada al traductor
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
}
</script>
</html>
Enlaces: Página oficial de documentación del API
Publicado en: www.variablenotfound.com.
lunes, 24 de marzo de 2008
Actualizado el 25/4/09:
Existe una versión de este post ampliada y actualizada a la versión 1.0 de ASP.NET MVC: ASP.NET MVC: trece preguntas básicas
Existe una versión de este post ampliada y actualizada a la versión 1.0 de ASP.NET MVC: ASP.NET MVC: trece preguntas básicas
 Varios lectores y amigos me han hecho llegar algunas cuestiones sobre el nuevo ASP.Net MVC Framework, y en vez de responder de forma individual, creo que es más interesante realizar un post recopilatorio e intentar que las respuestas puedan ayudar a más desarrolladores. Aprovecho para añadir cuestiones de mi propia cosecha, esperando que también puedan aclarar algo.
Varios lectores y amigos me han hecho llegar algunas cuestiones sobre el nuevo ASP.Net MVC Framework, y en vez de responder de forma individual, creo que es más interesante realizar un post recopilatorio e intentar que las respuestas puedan ayudar a más desarrolladores. Aprovecho para añadir cuestiones de mi propia cosecha, esperando que también puedan aclarar algo.<disclaimer>
Algunas de las respuestas podríamos considerarlas como beta, y pueden variar con el tiempo. Son opiniones, ideas y conjeturas sobre un producto nuevo y que todavía está en desarrollo, así que usadlas con precaución. ;-)</disclaimer>
1. Empecemos desde el principio, ¿qué es MVC?
Aunque de forma algo simplista, podríamos definir MVC como un patrón arquitectural que describe una forma de desarrollar aplicaciones software separando los componentes en tres grupos (o capas):- El Modelo que contiene una representación de los datos que maneja el sistema, su lógica de negocio, y sus mecanismos de persistencia.
- La Vista, o interfaz de usuario, que compone la información que se envía al cliente y los mecanismos interacción con éste.
- El Controlador, que actúa como intermediario entre el Modelo y la Vista, gestionando el flujo de información entre ellos y las transformaciones para adaptar los datos a las necesidades de cada uno.
Puedes encontrar más información en:
- Wikipedia, Modelo-Vista-Controlador
- Documentos originales de definición de MVC, de Trygve M. H. Reenskaug, en Xerox (¡año 1978!)
- Tutorial de Java, Arquitectura MVC
- Model-View-Controller Web presentation pattern en MSDN
2. ¿Qué ventajas tiene el uso del patrón MVC?
Como siempre, esto de enumerar ventajas es algo subjetivo, por lo que puede que pienses que falta o sobra alguna (¡dímelo!). En un primer asalto, podríamos aportar las siguientes:- Clara separación entre interfaz, lógica de negocio y de presentación, que además provoca parte de las ventajas siguientes.
- Sencillez para crear distintas representaciones de los mismos datos.
- Facilidad para la realización de pruebas unitarias de los componentes, así como de aplicar desarrollo guiado por pruebas (TDD).
- Reutilización de los componentes.
- Simplicidad en el mantenimiento de los sistemas.
- Facilidad para desarrollar prototipos rápidos.
- Los desarrollos suelen ser más escalables.
- Tener que ceñirse a una estructura predefinida, lo que a veces puede incrementar la complejidad del sistema. Hay problemas que son más difíciles de resolver respetando el patrón MVC.
- La curva de aprendizaje para los nuevos desarrolladores se estima mayor que la de modelos más simples como Webforms.
- La distribución de componentes obliga a crear y mantener un mayor número de ficheros.
3. ¿Qué es ASP.Net MVC Framework?
Es un framework, un entorno de trabajo que está creando Microsoft, que nos ayudará a desarrollar aplicaciones que sigan la filosofía MVC sobre ASP.Net. Su versión final incluirá librerías (ensamblados), plantillas y herramientas que se integrarán en Visual Studio 2008. ScottGu, en su presentación del framework el pasado Octubre en las conferencias Alt.Net, ya adelantó las principales características, y puedes ampliar información en la página oficial.Actualmente (marzo 2008) puede descargarse la Preview 2 del framework, e incluso su código fuente ha sido publicado en CodePlex. Aunque "de fábrica" no soporta las versiones Express de Visual Studio, en este mismo blog puedes encontrar algunas plantillas y ejemplos de ASP.NET MVC. También hay quien la ha echado a andar en Mono.
4. ¿Es el primer framework MVC creado para .Net?
No, ni el único. Existen multitud de frameworks MVC para ASP.Net, como MonoRail, Maverick.Net, ProMesh.Net y muchos otros.5. Como desarrollador de aplicaciones web con ASP.Net, ¿me afectará la llegada de este framework?
No necesariamente. Puedes seguir desarrollando aplicaciones como hasta ahora, con Webforms. Si así lo decides, este nuevo framework no te afectará nada; simplemente, ignóralo.De todas formas, ya que has leído hasta aquí, permíteme un consejo: aprende MVC framework. Después podrás decidir con conocimiento de causa si te conviene o no.
6. ¿Significa la aparición del framework MVC la muerte próxima de los Webforms de ASP.Net?
En absoluto. Son simplemente dos filosofías diferentes para conseguir lo mismo, ¡páginas web!.La tecnología de Webforms es muy útil para asemejar el desarrollo de aplicaciones web a las de escritorio, ocultando la complejidad derivada del entorno desconectado y stateless (sin conservación de estado) del protocolo HTTP a base de complejos roundtrips, postbacks y viewstates, lo que nos permite crear de forma muy productiva formularios impresionantes y que el funcionamiento de nuestra aplicación esté guiado por eventos, como si estuvieramos programando Winforms.
Sin embargo, esta misma potencia a veces hace que las páginas sean pesadas y difícilmente mantenibles, y además se dificultan enormemente la realización de pruebas. Y por no hablar de comportamientos extraños cuando intentamos intervenir en el ciclo de vida de las páginas, por ejemplo para la carga y descarga de controles dinámicos.
ASP.Net MVC propone una forma distinta de trabajar, más cercana a la realidad del protocolo y, curiosamente, más parecida a cómo se hacía unos años atrás, cuando controlábamos cada byte que se enviaba al cliente. No existen, por tanto, conceptos como el mantenimiento del estado en el viewstate, ni el postback, ni nos valdrán los controles de servidor basados en estas características, la mayoría. Sin embargo, dado que el framework está creado sobre ASP.Net, será posible utilizar páginas maestras, codificar las vistas en un .aspx utilizando C# o VB.Net, usar los mecanismos de seguridad internos, control de caché, gestión de sesiones, localización, etc; además, seguro que en un futuro no demasiado lejano comenzarán a surgir miles de componentes o controles reutilizables que nos ayudarán a mejorar la productividad.
7. ¿Vale la pena pasarse a ASP.Net MVC o sigo usando Webforms?
Todavía lo estoy estudiando ;-). Hay muchos aspectos a valorar.No hay que olvidar que los Webforms son una buena opción, tanto como lo han sido hasta ahora. Sobre todo si el equipo de desarrollo tiene ya experiencia creando aplicaciones con esta tecnología y se dispone de controles reutilizables propios o ajenos, deberíamos pensárnoslo antes de dar el salto a ASP.Net MVC. Tened en cuenta que la productividad, al menos inicialmente, va a caer.
Sin embargo, las ventajas de la arquitectura MVC y del propio framework descritas anteriormente son un buen aliciente para comenzar: testing, URLs amigables, separación de aspectos, mantenibilidad... Por otra parte, todavía es pronto para conocer el nivel de las herramientas de desarrollo (a nivel de IDE, librerías de controles, helpers) que aparecerán con la versión final, y las que surgirán desde la propia comunidad de desarrolladores, por lo que no es posible evaluar el impacto en la productividad que tendrá la adopción de esta nueva forma de trabajar.
Y, por cierto, si te preocupa el futuro de los Webforms, has de saber que Microsoft va a seguir dándoles soporte y mejorándolos, como no podía ser de otra forma. Por tanto, de momento no es necesario que bases tu decisión en esto.
8. ¿Se puede utilizar el ASP.Net Ajax con el framework MVC?
De momento parece que no, o al menos no de la forma en que se hace actualmente, dado que los controles de servidor (runat="server"), como el UpdatePanel, no están integrados en este modelo. De hecho, ya ni siquiera tienen sentido los formularios runat="server", por lo que menos aún los controles que dependían de éstos.Se prevé que se creará un API específico para permitir desde cliente, mediante scripting, hacer llamadas a los controladores, y actualizar porciones de contenido de la página con el marcado que nos envíe la vista correspondiente. Pero esto son sólo conjeturas de momento, ya se irá aclarando conforme el producto se acerque a su versión final.
9. ¿Puedo usar Linq desarrollando aplicaciones con ASP.Net MVC framework?
Sí, de hecho se complementan a la perfección.Por ejemplo, las clases del modelo podrán generarse de forma automática (y completa para aplicaciones relativamente simples) con los diseñadores visuales de LinqToSQL o LinqToEntities desde Visual Studio 2008 o de forma externa con herramientas como SQLMetal. Además, el controlador podrán utilizar expresiones de consulta para solicitar datos desde el modelo, o enviar datos actualizados usando las capacidades ORM de estas tecnologías.
10. ¿Será ASP.Net MVC framework software libre?
Pues claro que no ;-). Se podrá acceder al código fuente (de hecho, ya se puede), que será distribuido de la misma forma que el de .Net framework, pero no será software libre. Si buscas una solución open source, revisa la pregunta número 4.Publicado en: http://www.variablenotfound.com/.
domingo, 23 de marzo de 2008
 De todos es conocida la afición de Microsoft por poner nombres clave a sus productos durante la etapa de conceptualización y desarrollo, y la verdad es que tiene su gracia. Pero la verdad, a veces es difícil seguirle la pista a posts o conversaciones en foros donde hacen uso intensivo de ellas.
De todos es conocida la afición de Microsoft por poner nombres clave a sus productos durante la etapa de conceptualización y desarrollo, y la verdad es que tiene su gracia. Pero la verdad, a veces es difícil seguirle la pista a posts o conversaciones en foros donde hacen uso intensivo de ellas.Por ejemplo, ¿recuerdas el nombre en clave de ASP.NET Ajax? ¿Y de Windows 95? ¿Y sabes que tecnología se esconde detrás de Whistler o de Avalon?
Por suerte, en la Wikipedia, que hay de todo, alguien se ha encargado de recoger, si no todos los Codenames, al menos muchos de ellos.
Enlace: List of Microsoft codenames
Publicado en: http://www.variablenotfound.com/.
viernes, 21 de marzo de 2008
 Como ya delantó Scottgu hace unas semanas mientras actualizaba el roadmap de este nuevo producto, desde hace unas horas es posible descargar el código fuente del ASP.Net Preview 2 a través de CodePlex. La descarga es una solución para Visual Studio 2008, desde la que se pueden generar los ensamblados de forma directa.
Como ya delantó Scottgu hace unas semanas mientras actualizaba el roadmap de este nuevo producto, desde hace unas horas es posible descargar el código fuente del ASP.Net Preview 2 a través de CodePlex. La descarga es una solución para Visual Studio 2008, desde la que se pueden generar los ensamblados de forma directa.Aunque su licencia no permite redistribuir los binarios resultantes para evitar que posibles versiones alternativas del framework circulen por ahí, es muy interesante, sin duda, ver las "tripas" de esta nueva criatura.
Y, por cierto, también carga en Visual C# 2008 Express Edition...
Publicado en: http://www.variablenotfound.com/.
domingo, 16 de marzo de 2008
 He adaptado para Visual Web Developer Express una de las aplicaciones de ejemplo para ASP.NET MVC que publicó hace unos días el gran Scott Hanselman en su blog, pues no hay nada como observar código y verlo funcionar para aprender y profundizar en esta nueva tecnología.
He adaptado para Visual Web Developer Express una de las aplicaciones de ejemplo para ASP.NET MVC que publicó hace unos días el gran Scott Hanselman en su blog, pues no hay nada como observar código y verlo funcionar para aprender y profundizar en esta nueva tecnología.Concretamente, se trata de una adaptación de Phil Haack para la CTP2 de una aplicación creada inicialmente por Brad Abrams que muestra un catálogo de productos categorizado, tomados de la clásica base de datos NorthWind (para SQLServer/Express), y permite la creación, edición y eliminación de los mismos (CRUD); en otras palabras, una mini-aplicación completa. El acceso a datos se realiza mediante Linq, y las clases del Modelo se han generado con el diseñador Linq2SQL.
Aparte de la adaptación, he aprovechado para retocarla un poco, y le he añadido algunas funcionalidades y detalles que no estaban implementados. Faltan algunos flequillos, como las validaciones de formularios que todavía no he visto cómo se resuelven en el framework, pero bueno, lo que hay es una base interesante para comenzar o seguir profundizando en esta tecnología.
Podéis descargar el proyecto desde el enlace que encontraréis más abajo. Una vez descomprimido el archivo, abrid la carpeta desde Visual Web Developer Express (opción "Abrir > Abrir sitio web" o "File > Open web site" si tenéis aún la versión en inglés) y listo, podéis pulsar F5 para ejecutar.
Por cierto, no sé si funcionará bien con las versiones "pro" de Visual Studio 2008. Agradecería que si alguien lo prueba en este entorno, me lo comentara.
Enlaces:
Proyecto NorthWind Demo para ASP.NET MVC (~2MB)Publicado en: http://www.variablenotfound.com/.
sábado, 15 de marzo de 2008
 Ayer se anunció oficialmente la aparición de la versión 1.0 a través de la web del Proyecto Mono, en el blog de Miguel de Icaza y por supuesto, en la web del equipo de desarrollo de MonoDevelop.
Ayer se anunció oficialmente la aparición de la versión 1.0 a través de la web del Proyecto Mono, en el blog de Miguel de Icaza y por supuesto, en la web del equipo de desarrollo de MonoDevelop.Se trata de un entorno de desarrollo integrado (IDE) para la plataforma .NET en el que el equipo del proyecto Mono anda trabajando desde hace varios años. Su objetivo inicial era facilitar una herramienta libre y gratuita para Linux, MacOS e incluso Windows, que permita la creación de aplicaciones en C# y otros lenguajes .NET, aunque después ha evolucionado hasta convertirse en una plataforma extensible sobre la que podría encajar cualquier tipo de herramienta de desarrollo.
Las principales características de la herramienta son:
- Se trata de un entorno muy personalizable, permitiendo la creación de atajos de teclado, la redistribución de elementos en pantalla o inclusión de herramientas externas.
- Soporta varios lenguajes, como C#, VB.Net o C/C++ o incluso Boo y Java (IKVM) a través de plugins externos.
- Ayuda en la escritura del código (auto-completar, información de parámetros... al más puro estilo intellisense).
- Incluye herramientas de refactorización, como renombrado de tipos y miembros, encapsulación de campos, sobreescritura de métodos o autoimplementación de interfaces.
- Ayudas en la navegación a través del código, como saltar a las declaraciones de variables, o búsquedas de clases derivadas.
- Diseñador de interfaces para aplicaciones GTK# y soporte para librerías de widgets.
- Control de versiones integrado, con soporte para Subversion.
- Pruebas unitarias integradas, utilizando NUnit.
- Soporte para proyectos ASP.Net.
- Servidor web integrado (XSP) para pruebas.
- Explorador y editor de bases de datos integrados (aún en beta).
- Integración con Monodoc, para la documentación de clases.
- Soporte para makefiles, tanto para generación como para sincronización.
- Soporte para formatos de proyecto Visual Studio 2005.
- Sistema de empaquetado que genera tarballs, código fuente y binarios.
- Línea de comandos para generar y gestionar proyectos.
- Soporte para proyectos de localización.
- Arquitectura extensible a través de plugins.
Información mucho más detallada, eso sí, en inglés, en la web del proyecto.
Publicado en: http://www.variablenotfound.com/.
domingo, 9 de marzo de 2008
 Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.
Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.Una unión es muy similar a una estructura de datos (
struct en C# o Structure en VB.Net), salvo en un detalle: sus componentes se almacenan sobre las mismas posiciones de memoria. O visto desde el ángulo opuesto, una unión podríamos definirla como una porción de memoria donde se guardan varias variables, habitualmente de tipos diferentes. Veamos un ejemplo clásico que nos ayudará a entender el concepto, en un lenguaje cualquiera:union Ejemplo
{
char caracter; // suponiendo char de 8 bits
byte octeto; // un byte ocupa 8 bits
};Si declaramos una variable x del tipo Ejemplo, estaremos reservando un espacio de 8 bits al que accederemos desde cualquiera de sus miembros, como vemos a continuación:
x.caracter = 'A';
x.octeto ++;
escribir_char (x.caracter); // mostraría 'B'
escribir_byte (x.octeto); // mostraría 66
Pero espera... ¿memoria?... ¿almacenamiento de variables?... ¿pero existe eso en .Net?... Pues sí, aunque lo más normal es que no nos tengamos que enfrentar nunca a ello pues el framework realiza estas tareas por nosotros, hay escenarios en los que es necesario controlar la forma en que la información es almacenada en memoria, como cuando se esté operando a bajo nivel, por ejemplo creando estructuras específicas para llamar al API de Windows, o para facilitar el acceso a posiciones concretas de la información.
Desde la versión 1.1 de la plataforma .Net, disponemos del atributo StructLayout, que nos permite indicar en estructuras y clases cómo queremos representar en memoria la información de sus miembros. Básicamente, podemos indicar que:
- la información se almacene como el framework considere oportuno (
LayoutKind.Auto) - que se almacene de forma secuencial, en el mismo orden en el que han sido declarados (
LayoutKind.Sequential). - que se almacene donde le indiquemos de forma explícita (
LayoutKind.Explicit). En este caso, necesitaremos especificar en cada miembro la posición exacta de memoria donde será guardado, utilizando el atributoFieldOffset.
Es este último método el que nos interesa para nuestros propósitos. Si adornamos una estructura con
StructLayout(LayoutKind.Explicit) e indicamos en cada uno de sus miembros su desplazamiento (en bytes) dentro del espacio de memoria asignado a la misma, podemos conseguir uniones haciendo que todos ellos comiencen en la misma dirección.Pasemos a vamos a verlo con un ejemplo en C#. Se trata de una unión a la que podemos acceder tratándola como un carácter unicode, o bien como un entero de 16 bits con signo. Los dos miembros, llamados
Caracter y Valor están definidos sobre la misma posición de memoria (desplazamiento cero) en el interior de la estructura:using System.Runtime.InteropServices;
using System;
namespace PruebaUniones
{
[StructLayout(LayoutKind.Explicit)]
public struct UnionTest
{
[FieldOffset(0)] public char Caracter;
[FieldOffset(0)] public short Valor;
}
class Program
{
public static void Main()
{
UnionTest ut = new UnionTest();
ut.Caracter = 'A';
ut.Valor ++;
Console.WriteLine(ut.Caracter); // Muestra "B"
Console.ReadKey();
return;
}
}
}Ahora usaremos VB.NET para mostrar otro ejemplo un poco más complejo que el anterior, donde usamos una unión para descomponer una palabra de 16 bits en los dos bytes que la componen, permitiendo la manipulación de forma directa e independiente de cada una de las dos visiones del valor almacenado en memoria. Para el ejemplo utilizo una unión dentro de otra, aunque no era estrictamente necesario, para que veáis que esto es posible.
Imports System.Runtime.InteropServices
<StructLayout(LayoutKind.Explicit)> _
Public Structure Union16
<FieldOffset(0)> Dim Word As Int16
<FieldOffset(0)> Dim Bytes As Bytes
End Structure
<StructLayout(LayoutKind.Explicit)> _
Public Structure Bytes
<FieldOffset(0)> Dim Bajo As Byte
<FieldOffset(1)> Dim Alto As Byte
End Structure
Public Class Program
Public Shared Sub main()
Dim u As New Union16
u.Word = 513 ' 513 = 256*1 (Byte alto) + 1 (byte bajo)
u.Bytes.Alto += 1
Console.WriteLine("Word: " & u.Word) ' Muestra 769 (3*256+1)
Console.WriteLine("Byte alto: " & u.Bytes.Alto) ' Muestra 3
Console.WriteLine("Byte bajo: " & u.Bytes.Bajo) ' Muestra 1
Console.ReadKey()
Console.ReadKey()
End Sub
End Class
He encontrado un uso muy interesante para esta técnica en Xtreme .Net Talk, donde se muestra un ejemplo de cómo acceder a los componentes de color de un pixel de forma muy eficiente a través de una unión entre el valor ARGB (32 bits) y cada uno de los bytes que lo componen (alfa, rojo, verde y azul).
En cualquier caso no se recomienda el uso de uniones salvo en casos muy concretos, y siempre conociendo bien las implicaciones que puede tener en la estabilidad y mantenibilidad del sistema.
Pero bueno, ¡está bien al menos saber que existen!
Publicado en: http://www.variablenotfound.com/.
jueves, 6 de marzo de 2008
Ayer se publicó la segunda preview del ASP.Net MVC Framework, la plataforma que sin duda será la revolución del año para los desarrolladores de aplicaciones basadas en web sobre tecnología .Net, y he pensado que ya era un buen momento para echarle un vistazo de cerca.
Una vez descargado el paquete (poca cosa, menos de un mega), procedí a instalarlo, apareciéndome la siguiente ventana de error:

Esto, además, se confirma en el documento de notas de la versión:
En otras palabras, que la segunda CTP, al igual que la primera, incluye plantillas que no son válidas para la versión Express de Visual Web Developer. Qué contrariedad.
Y es cierto que no está soportada, pero esto no implica que los que utilizamos las versiones light de los entornos de desarrollo estemos condenados a no probar esta nueva tecnología; de hecho es perfectamente posible, aunque no contaremos con todas las ayudas que sí vienen de serie para las versiones más "pro".
Una vez finalizada la instalación, encontré en Google varias páginas (por ejemplo aquí y aquí) donde se facilitaban plantillas, basadas en las originales, que nos permitirían probar la primera CTP sobre la versión express. Lamentablemente, los cambios realizados en la plataforma desde entonces hacen incompatibles estas plantillas con la CTP 2, aunque es posible hacerlas funcionar simplemente siguiendo los pasos detallados en esta página.
Para que no tengáis que perder el tiempo en ello, he creado una plantilla de proyecto Web (en C#) para Visual Web Developer Express 2008 que podéis descargar desde aquí.
Si queréis probar un poco esta tecnología, una vez instalada la segunda preview del ASP.Net MVC Framework, descargad la plantilla y guardarla, sin descomprimir, en la carpeta "Visual Studio 2008/Templates/ProjectTemplates". Lo habitual es que encontréis esta carpeta en "Mis documentos".
Iniciad Visual Web Developer 2008 Express, cread un nuevo sitio web en C# seleccionando la plantilla que habéis incluido, llamada "MVCWebSite", así:

 Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Y ya no hay nada más que hacer. Si pulsáis la tecla F5, se compilará y en pocos segundos tendréis funcionando un sitio web MVC, con un controlador y algunas vistas, las cuales usan una MasterPage para componer el esqueleto de las páginas. Además, una de ellas, "Links", muestra cómo obtener un parámetro (la lista de enlaces) desde el controlador.

¡Hala, a disfrutarlo!
Publicado en: http://www.variablenotfound.com/.
(Para el que todavía ande un poco despistado, puede leer una breve descripción del ASP.Net MVC Framework, convenientemente traducida, en Thinking in .Net).
Una vez descargado el paquete (poca cosa, menos de un mega), procedí a instalarlo, apareciéndome la siguiente ventana de error:

Esto, además, se confirma en el documento de notas de la versión:
“The new releases provide Visual Studio templates that are not supported in Visual Web Developer 2008 Express Edition. For example, you cannot create an MVC application or Silverlight .xap files by using Visual Web Developer 2008 Express Edition.”
En otras palabras, que la segunda CTP, al igual que la primera, incluye plantillas que no son válidas para la versión Express de Visual Web Developer. Qué contrariedad.
Y es cierto que no está soportada, pero esto no implica que los que utilizamos las versiones light de los entornos de desarrollo estemos condenados a no probar esta nueva tecnología; de hecho es perfectamente posible, aunque no contaremos con todas las ayudas que sí vienen de serie para las versiones más "pro".
Una vez finalizada la instalación, encontré en Google varias páginas (por ejemplo aquí y aquí) donde se facilitaban plantillas, basadas en las originales, que nos permitirían probar la primera CTP sobre la versión express. Lamentablemente, los cambios realizados en la plataforma desde entonces hacen incompatibles estas plantillas con la CTP 2, aunque es posible hacerlas funcionar simplemente siguiendo los pasos detallados en esta página.
Para que no tengáis que perder el tiempo en ello, he creado una plantilla de proyecto Web (en C#) para Visual Web Developer Express 2008 que podéis descargar desde aquí.
Si queréis probar un poco esta tecnología, una vez instalada la segunda preview del ASP.Net MVC Framework, descargad la plantilla y guardarla, sin descomprimir, en la carpeta "Visual Studio 2008/Templates/ProjectTemplates". Lo habitual es que encontréis esta carpeta en "Mis documentos".
Iniciad Visual Web Developer 2008 Express, cread un nuevo sitio web en C# seleccionando la plantilla que habéis incluido, llamada "MVCWebSite", así:

 Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"
Esto creará un proyecto con el web.config correctamente configurado y la estructura de carpetas ideal para una aplicación web de este tipo, lista para salir andando. Por cierto, si al compilar el proyecto os aparece algún problema de referencias a ensamblados de la Preview, sólo debéis añadir a mano (botón derecho sobre el proyecto, añadir referencias) las DLL's que encontraréis en la carpeta donde se haya instalado la CTP, que en mi caso es "C:/Archivos de programa/Microsoft ASP.NET MVC Preview 2/Assemblies"Y ya no hay nada más que hacer. Si pulsáis la tecla F5, se compilará y en pocos segundos tendréis funcionando un sitio web MVC, con un controlador y algunas vistas, las cuales usan una MasterPage para componer el esqueleto de las páginas. Además, una de ellas, "Links", muestra cómo obtener un parámetro (la lista de enlaces) desde el controlador.

¡Hala, a disfrutarlo!
Publicado en: http://www.variablenotfound.com/.
miércoles, 5 de marzo de 2008
 Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?
Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?Por ejemplo, dado el siguiente código en el interior de una página ASP.NET, ¿cuál sería la forma correcta de comentarlo?
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
Una primera opción podría ser utilizar la sintaxis Javascript de la siguiente forma:
<script>
/*
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
*/
</script>
Sin embargo, aunque podría valer en muchas ocasiones, también puede introducir unos efectos laterales considerables. Nótese que aunque el código Javascript (cliente) esté comentado, la función
borrarRegistros() sería invocada en el lado del servidor, y su retorno introducido dentro del comentario. De hecho, la página enviada a cliente mostraría un código fuente similar al siguiente (imaginando que el retorno de la función fuera el valor 99):<script>
/*
var count = 99;
alert("Borrados: " + count + " registros");
*/
</script>
Tampoco valdría para nada incluir todo el bloque de script dentro de un comentario HTML (<!-- y -->), por la misma razón que antes. Además, en cualquiera de estos dos casos, estaríamos enviando al cliente la información aunque sea éste el que la ignora a la hora de mostrarla o ejecutarla y, por supuesto, estaríamos ejecutando la función en servidor, lo cual podría causar otros efectos no deseados, como, en nuestro ejemplo, eliminar los registros de una base de datos.
Afortunadamente, ASP.NET dispone de un mecanismo, denominado Server Side Comments (comentarios en el lado del servidor), que permite marcar zonas y hacer que se ignore todo su contenido, sea del tipo que sea, a la hora de procesar la página:
<%--
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
--%>
En este caso ni sería ejecutada la función del servidor ni tampoco enviado a cliente el código HTML/Script incluido.
Publicado en: http://www.variablenotfound.com/.
lunes, 3 de marzo de 2008
 Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.
Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.En esta ocasión vamos a centrarnos en los inicializadores de objetos, una nueva característica destinada, entre otras cosas, a ahorrarnos tiempo a la hora de establecer los valores iniciales de los objetos que creemos desde código.
Y es que, hasta ahora, podíamos utilizar dos patrones básicos de inicialización de propiedades al instanciar una clase:
- que fuera la clase la que realizara esta tarea, ofreciendo al usuario de la misma constructores con distintas sobrecargas cuyos parámetros corresponden con las propiedades a inicializar.
// Constructor de la clase Persona:
public Persona(string nombre, string apellidos, int edad, ...)
{
this.Nombre = nombre;
this.Apellidos = apellidos;
this.Edad = edad;
...
}
// Uso:
Persona p = new Persona("Juan", "López", 32, ...); - o bien dejar esta responsabilidad al usuario, permitiéndole el acceso directo a propiedades o campos del objeto creado.
// Uso:
Persona p = new Persona();
p.Nombre = "Juan";
p.Apellidos = "López";
p.Edad = 32;
...
Los inicializadores de objetos permiten, en C# y VB.Net, realizar esta tarea de forma más sencilla, indicando en la llamada al constructor el valor de las propiedades o campos que deseemos establecer:
// C#:
Persona p = new Persona { Nombre="Juan", Apellidos="López", Edad=32 };
' VB.NET:
Dim p = New Persona With {.Nombre="Luis", .Apellidos="López", .Edad=32 }
Los ejemplos anteriores son válidos para clases que admitan constructores sin parámetros, pero, ¿qué ocurre con los demás? Imaginando que el constructor de la clase
Persona recibe obligatoriamente dos parámetros, su nombre y apellidos, podríamos instanciar así:
// C#:
Persona p = new Persona ("Luis", "López") { Edad = 32 };
' VB.NET:
Dim p = New Persona ("Luis", "López") With { .Edad = 32 }
Aunque es obvio, es importante tener en cuenta que las inicializaciones (la porción de código entre llaves "{" y "}") se ejecutan después del constructor:
// C#:
Persona p = new Persona ("Juan", "Pérez") { Nombre="Luis" };
Console.WriteLine(p.Nombre); // Escribe "Luis"
' VB.NET:
Dim p = New Persona ("Juan", "Pérez") With { .Nombre="Luis" }
Console.WriteLine(p.Nombre); ' Escribe "Luis"
Y un último apunte: ¿cómo inicializaríamos propiedades de objetos que a su vez sean objetos que también queremos inicializar? Suponiendo que en nuestra clase
Persona hemos incluido una propiedad llamada Domicilio que de tipo Localizacion, podríamos inicializar el bloque completo así:
// C#:
// Se han cortado las líneas para facilitar la lectura
Persona p = new Persona()
{
Nombre = "Juan",
Apellidos = "López",
Edad = 55,
Domicilio = new Localizacion
{
Direccion = "Callejas, 34",
Localidad = "Sevilla",
Provincia = "Sevilla"
}
};
' VB.NET:
' Se han cortado las líneas para facilitar la lectura
Dim p = New Persona() With { _
.Nombre = "Juan", _
.Apellidos = "López", _
.Edad = 55, _
.Domicilio = New Localizacion With { _
.Direccion = "Callejas, 23", _
.Localidad = "Sevilla", _
.Provincia = "Sevilla" _
} _
}
En fin, que de nuevo tenemos ante nosotros una característica de estos lenguajes que resulta interesante por sí misma, aunque toda su potencia y utilidad podremos percibirla cuando profundicemos en otras novedades, como los tipos anónimos y Linq... aunque eso será otra historia.
Publicado en: http://www.variablenotfound.com/.
miércoles, 27 de febrero de 2008
 Sabemos que los patrones son plantillas reutilizables que podemos usar para solucionar problemas habituales en el proceso de desarrollo de software. Así, permiten utilizar soluciones fiables y bien conocidas a problemas concretos, aprovechando experiencias previas como base para la consecución de mejores resultados en los nuevos desarrollos.
Sabemos que los patrones son plantillas reutilizables que podemos usar para solucionar problemas habituales en el proceso de desarrollo de software. Así, permiten utilizar soluciones fiables y bien conocidas a problemas concretos, aprovechando experiencias previas como base para la consecución de mejores resultados en los nuevos desarrollos.Pues bien, justo en el lado opuesto se encuentran los antipatrones, que definen situaciones y comportamientos que, según experiencias anteriores, nos conducen al fracaso en proyectos de desarrollo de software, es decir, son soluciones o planteamientos que se han demostrado incorrectos.
Y es ahí donde radica su interés: la observación y conocimiento de los mismos puede evitarnos resultados desastrosos, o actuar como alertas tempranas ante decisiones o dinámicas incorrectas, permitiéndonos prevenir, evitar o recuperarnos de estos problemas.
Al igual que en los patrones, su descripción está relativamente formalizada y suele recoger los siguientes aspectos:
- nombre del antipatrón, así como su "alias"
- su tipología: organizacional, de análisis, desarrollo... (veremos esto más tarde)
- contexto y entorno en el que se aplica
- descripción del problema concreto
- síntomas, y consecuencias de la aplicación del antipatrón
- causas típicas y raíces del problema
- refactorización a aplicar, es decir, una descripción de cómo podríamos replantear el problema y conseguir una solución positiva.
- ejemplos y escenarios para su comprensión.
- soluciones relacionadas con la propuesta.
Por ejemplo, un resumen del clásico antipatrón que reconoceréis muy rápidamente, el llamado spaghetti code:
| Nombre: | Spaghetti Code |
| Tipología: | Desarrollo |
| Problema: | Existencia de una pieza de código compleja y sin apenas estructura que dificulta enormemente su mantenimiento posterior |
| Síntomas y consecuencias: |
|
| Causas: |
|
| Solución positiva: |
|
Según según la Wikipedia, los antipatrones se clasifican en los siguientes grupos, atendiendo a las áreas a las que afectan:
- Antipatrones Organizacionales, que incluyen prácticas nocivas a este nivel, como pueden ser, entre otros:
- Gestión de champiñones (Mushroom management), o mantener al equipo en la oscuridad, desinformado, y cubierto de porquería.
- Parálisis en análisis (Analysis paralysis), o quedar inmovilizado debido a un análisis o precaución excesiva, en contraposición a la siguiente:
- Extinción por intuición (Extint by instinct), llegar a la muerte por adelantarse demasiado y usar la intuición para la toma de decisiones.
- Antipatrones de Gestión de proyectos, describiendo problemas en la gestión de proyectos, como los célebres:
- Marcha de la muerte (Death march), que describe el avance de determinados proyectos hacia el fracaso aunque todo el personal, excepto los gerentes, saben que al final se darán el castañazo.
- Humo y espejos (Smoke and mirrors), o la demostración de funcionalidades o características no implementadas como si fueran reales, lo que siempre he llamado "enseñar cartón piedra".
- Antipatrones de Gestión de equipos, que recoge problemas relacionados con la relación con y de equipos de trabajo, como:
- Doble diabólico (traducción libre del término Doppelganger), personas que dependiendo del día pueden ser magníficos colaboradores o auténticos demonios.
- Gestor ausente (Absentee manager), describiendo situaciones en las que el director está invisible periodos prolongados
- Antipatrones de Análisis, categoría que engloba antipatrones relacionados con la fase analítica de los proyectos software, entre otros:
- Retroespecificación (Retro-specification), o lo que viene a ser la realización del análisis una vez implementada la solución.
- Especificación de servilleta (Napkin specification), también muy socorrida, que consiste en pasar al equipo de desarrollo las especificaciones del producto a crear descritas con muy poco detalle o informalmente.
- Antipatrones de Diseño, que incluye malas prácticas de diseño de software que dan lugar a aplicaciones y componentes estructuralmente incorrectos:
- Gran bola de lodo (Big ball of mud), realización de aplicaciones sin estructura reconocible.
- Factoría de gas (Gas factory), diseños innecesariamente complejos.
- Botón mágico (Magic Pushbutton), o implementación de funcionalidades directamente en los manejadores de evento (p.e., click) del interfaz.
- Antipatrones en Orientación a objetos, como una especialización del anterior, describe problemas frecuentes en los diseños creados bajo este paradigma, como:
- Llamar al super (Call super), obligar a las subclases a llamar a la clase de la que heredan.
- Singletonitis, abuso del patrón singleton.
- Orgía de objetos (Object orgy), o encapsulación incorrecta en clases que permite el acceso incontrolado a sus métodos y propiedades internas.
- Otra jodida capa más (YAFL, Yet another fucking layer), o la inclusión excesiva de capas en un sistema.
- Antipatrones de Programación, con un gran número de errores frecuentes a evitar, como:
- Spaghetti code, comentando anteriormente.
- Ravioli code, que consiste en la existencia de un gran número de objetos desconectados o débilmente acoplados entre sí.
- Ocultación de errores (Error hiding), o capturar errores antes de que lleguen usuario, mostrando mensajes incomprensibles o simplemente no mostrar nada.
- Números mágicos (Magic numbers), incluir números inexplicables en el código.
- Antipatrones Metodológicos, o formas de desarrollar que se han demostrado incorrectas a lo largo del tiempo, como pueden ser:
- Programación copy & paste, también llamada herencia de editor, consiste en copiar, pegar y modificar, en contraposición a la estritura de software reutilizable.
- Factor de improbabilidad (Improbability factor), asumir que un error conocido es improbable que ocurra.
- Optimización prematura (Premature optimization), según algunos la raíz de todos los males, consiste en sacrificar el buen diseño y mantebilidad de un software en benecificio de la eficiencia.
- Programación por permutación (Programming by permutation), o intentar dar con una solución modificando sucesivamente el código para ver si funciona.
- Antipatrones de Gestión de configuración, hace referencia a antipatrones relacionados con la gestión de los entornos de desarrollo y explotación del software, como las variantes del infierno de las dependencias (Dependency hell), o problemas de versionado de librerías y componentes:
- DLL's Hell, el conocido y traumático mundo de las librerías dinámicas en Windows.
- JAR's Hell, idem, pero relativo a las librerías Java.
Por no hacer el post eterno sólo he recogido unos cuantos, aunque existen cientos de ellos, y con una gran variedad temática: antipatrones para el desarrollo guiado por pruebas (TDD), antipatrones de manejo de excepciones, para el uso de arquitecturas orientadas al servicio (SOA), de rendimiento, de seguridad, centrados en tecnologías (p.e., J2EE antipatterns) o según el tipo de software (sistemas de gestión, tiempo real, videojuegos, etc.).
Y como conclusión personal, decir que me he visto reconocido en multitud de ellos, lo cual significa que muy descaminados no andan. Es más, si hiciera una lista con patrones y otra con los antipatrones que utilizo o he utilizado, la segunda tendría más elementos que la primera... ¿quizás es momento de reflexionar un poco?
Publicado en: http://www.variablenotfound.com/.












