
domingo, 25 de mayo de 2008
 Algunos dirán que a nada, como las nubes ;-) Sin embargo, el olor que desprende tu código, el llamado "code smell", término acuñado por Kent Beck (uno de los padres del Extreme Programming), puede darte pistas sobre problemas existentes en el mismo y alertarte ante situaciones no deseadas.
Algunos dirán que a nada, como las nubes ;-) Sin embargo, el olor que desprende tu código, el llamado "code smell", término acuñado por Kent Beck (uno de los padres del Extreme Programming), puede darte pistas sobre problemas existentes en el mismo y alertarte ante situaciones no deseadas.El concepto es parecido a los antipatrones de programación, aunque funcionan a un nivel todavía más sutil, pues no describe situaciones completas sino indicios. De hecho, el uso de esta metáfora sensorial respecto a un código, es decir, que éste desprenda cierto tufillo, indica que sería conveniente realizar una revisión en profundidad para ver si hay que refactorizar, pero no implica que necesariamente haya algo incorrecto. Además, dado que trata de algo tan personal y específico como el código fuente, a veces las señales son bastante subjetivas y dependientes de lenguajes y tecnologías concretas.
Existen multitud de listas y clasificaciones, aunque es muy interesante la realizada por Mika Mäntylä, investigador de la universidad de Helsinki, ha creado una taxonomía que agrupa code smells relacionados en cinco categorías en función del efecto que pueden provocar:
- The bloaters (los infladores), que agrupa 'aromas' que indican el crecimiento excesivo de algún aspecto que hacen incontrolable el código.
- Long method (método extenso) que precisa de su reducción para ser más legible y mantenible.
- Large class (clase larga), con síntomas y consecuencias muy similares al caso anterior.
- Primitive obsession (obsesión por tipos primitivos), cuyo síntoma es la utilización de tipos primitivos para almacenar datos de entidades pequeñas (por ejemplo, usar un long para guardar un número de teléfono).
- Long parameter list (lista de parámetros larga), que incrementan la complejidad de un método de forma considerable.
- Dataclumps (grupos de datos), o uso de un cunjunto de variables o propiedades de tipos primitivos en lugar de crear una clase apropiada para almacenar los datos, lo que a su vez provoca el incremento de parámetros en métodos y clases.
- The Object-Orientation Abusers (los maltratadores de la orientación a objetos), que aglutina code smells que indican que no se está aprovechando la potencia de este paradigma:
- Switch statements (sentencias Switch), que podrían indicar una falta de utilización de mecanismos de herencia.
- Temporary field (campo temporal), que se salta el principio de encapsulamiento y ocultación de variables haciendo que éstas pertenezcan a la clase cuando su ámbito debería ser exclusivamente el método que las usa.
- Refused bequest (rechazo del legado), cuando una subclase 'rechaza' métodos o propiedades heredadas, atentando directamente contra uno de los principales pilares de la OOP.
- Alternative Classes with Different Interfaces (clases alternativas con distintos interfaces) indica la ausencia de interfaces comunes entre clases similares.
- The change preventers (los impedidores de cambios)
- Divergent Change (cambio divergente), que hace que sean implementadas dentro de la misma clase funcionalidades sin ninguna relación entre ellas, lo que sugiere extraerlas a una nueva clase.
- Shotgun surgery (cirujía de escopeta), ocurre cuando un cambio en una clase implica modificar varias clases relacionadas.
- Parallel Inheritance Hierarchies (jerarquías de herencia paralelas), paralelismo que aparece cuando cada vez que se crea una instancia de una clase es necesario crear una instancia de otra clase, evitable uniendo ambas en una úncia clase final.
- The Dispensables (los prescindibles), pistas aportadas por porciones de código innecesarias que podrían y deberían ser eliminadas:
- Lazy class (clase holgazana), una clase sin apenas responsabilidades que hay que dotar de sentido, o bien eliminar.
- Data class (clase de datos), cuando una clase sólo se utiliza para almacenar datos, pero no dispone de métodos asociados a éstos.
- Duplicate code (código duplicado), presencia de código duplicado que dificulta enormemente el mantenimiento.
- Dead code (código muerto), aparición de código que no se utiliza, probablemente procedente de versiones anteriores, prototipos o pruebas.
- Speculative generality (generalización especulativa), ocurre cuando un código intenta solucionar problemas más allá de sus necesidades actuales.
- The couplers (Los emparejadores), son code smells que alertan sobre problemas de acoplamiento componentes, a veces excesivo y otras demasiado escaso.
- Features envy (envidia de características), que aparece cuando existe un método de una clase que utiliza extensivamente métodos de otra clase y podría sugerir la necesidad de moverlo a ésta.
- Inappropriate intimacy (intimidad inapropiada), ocurre cuando dos clases de conocen demasiado y usan con demasiada confianza, y a veces de forma inapropiada, sus miembros (en la acepción POO del término ;-))
- Message Chains (cadenas de mensajes), aroma desprendido por código que realiza una cadena de llamadas a métodos de clases distintas utilizando como parámetros el retorno de las llamadas anteriores, como
A.getB().getC().getD().getTheNeededData(), que dejan entrever un acoplamiento excesivo de la primera clase con la última. - Middle man (intermediario), que cuestiona la necesidad de tener clases cuyo único objetivo es actuar de intermediaria entre otras dos clases.
Aunque agrupadas bajo otros criterios, existe una interesante relación de code smells y la refactorización a aplicar en cada caso, que ayuda a determinar las acciones correctivas oportunas una vez se haya comprobado que hay algo que no va bien.
Y ahora, ¿piensas que tu código no huele a nada? ;-P
Publicado en: http://www.variablenotfound.com/.
sábado, 24 de mayo de 2008
 Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.
Jason Allor anunciaba ayer mismo el lanzamiento de una nueva herramienta, Microsoft Source Analysis for C#, cuyo objetivo es ayudar a los desarrolladores a producir código elegante, legible, mantenible y consistente entre los miembros de un equipo de trabajo. De hecho, era conocida como StyleCop en Microsoft, donde llevan utilizándola ya varios años.Y aunque pueda parecer similar a FxCop, Microsoft Source Analysis for C# se centra en el análisis de código fuente y no en ensamblados, lo que hace que pueda afinar mucho más en las reglas de codificación.
Incluye sobre 200 buenas prácticas, cubriendo aspectos como:
- Layout (disposición) de elementos, instrucciones, expresiones y consultas
- Ubicación de llaves, paréntesis, corchetes, etc.
- Espaciado alrededor de palabras clave y operadores
- Espaciado entre líneas
- Ubicación de parámetros en llamadas y declaraciones de métodos
- Ordenación de elementos de una clase
- Formateo de documentación de elementos y archivos
- Nombrado de campos y variables
- Uso de tipos integrados
- Uso de modificadores de acceso
- Contenidos permitidos en archivos
- Texto de depuración

Tras su descarga e instalación, que puede realizarse desde esta dirección, la herramienta se integra en Visual Studio 2005 y 2008, aunque también puede utilizarse desde la línea de comandos o MSBuild.
Publicado en: www.variablenotfound.com.
martes, 20 de mayo de 2008
 Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.
Este post es una continuación de 8 curiosidades que quizás no conocías sobre los emoticonos.4. Emoticonos corporales y otras extensiones
Aunque en su nacimiento los emoticonos sólo intentaban simular gestos faciales, existen una interesante variedad de ellos que simulan cuerpos completos y posturas que, de la misma manera, transmiten contenido de tipo emocional.Por ejemplo, los siguientes emoticonos representan a una persona arrodillada o haciendo reverencias en esta postura. Siempre la letra "o" aparece como cabeza, le sigue el tronco y un brazo en el suelo y finalmente las piernas flexionadas:
orz, _| ̄|○, OTL Or2, Orz, On_, OTZ, O7Z, Sto, Jto, _no
Estos emoticonos suelen representar ideas distintas en función de la cultura. En Japón, se interpreta como fracaso y desesperación; los usuarios Chinos, en cambio, lo usan más frecuentemente para expresar admiración a la consecución de un objetivo. Hay también quien lo utiliza para mostrar una risa extrema ("retorcerse de risa").
Otros de este tipo podrían ser:
| O-&-< | Persona con los brazos cruzados |
| ~~~~\0/~~~~ | Ahogándose |
Pero hay muchos más, y algunos son obras de arte: posturas, retratos de celebridades, objetos... De hecho, algunos de ellos podrían describirse mejor como arte ASCII que como emoticonos, pues no llevan asociadas emociones y se trata simplemente de adornos textuales:
| Cuerpos... | |
| (:-))-|-< | Cuerpo completo |
| X=(;-))-|8-<= | Novia |
| Celebridades... | |
| ( 8^(l) | Homer Simpson |
| =:o] | Bill Clinton |
| @:-() | Elvis Presley |
| Objetos... | |
| @>+-+-- | Una rosa |
| <')))))><< | Un pez |
| ... | |
En Canonical Smiley List hay 2227 emoticonos de este tipo.
5. Emoticonos zurdos
 Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:
Aunque lo habitual para leer emoticonos en el mundo occidental es girar la cabeza hacia la izquierda, también circula una variación inversa, es decir, versiones de los iconos que se visualizan girando la cabeza hacia la derecha (-:No suelen utilizarse demasiado dado que suelen provocar confusión en los lectores, acostumbrados a la orientación habitual.

6. Emoticonos asiáticos
En 1986 surgieron en Japón una nueva familia de emoticonos, que se popularizaron muy rápidamente entre los países de Asia del este. Las dos diferencias principales respecto a los habituales en el mundo occidental son, en primer lugar, que pueden entenderse fácilmente sin necesidad de tumbar la cabeza hacia un lado y, en segundo lugar, que la expresión o emoción suele representarse eligiendo caracteres diversos para los ojos, en lugar de la boca. Algunos ejemplos simples:| (^_^) | Sonrisa |
| (T_T) | Llorando |
| (o_#) | Magullado |
| (O_O) | Sorprendido |
| (~o~) | Un bostezo |
(Puedes encontrar más aquí)
Existen también otros emoticonos que hacen uso de los juegos de caracteres especiales que es necesario tener instalados en el ordenador:
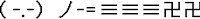 | Lanzando un suriken |
 | Escribiendo |
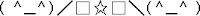 | ¡Salud! |
(Aquí hay muchos más, pero para verlos necesitarás instalar el paquete de idioma japonés en tu máquina)
7. Emoticonos... ¿patentados?
 En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.
En el año 2000, la compañía Despair consiguió registrar el emoticono que solemos utilizar habitualmente para mostrar desacuerdo o enfado, :-(, en la oficina de patentes y marcas de los Estados Unidos.Poco después, el 2 de enero de 2001, lanzaron una nota de prensa anunciando que emprenderían acciones legales contra los usuarios de Internet que utilizaran este símbolo en sus mensajes de correo electrónico, y que ya habían cursado un total de 7 millones de denuncias individuales.
En realidad, no se trataba más que de una broma, una forma de llamar la atención y dar a conocer su compañía, dedicada a la comercialización de material gráfico con mensajes humorísticos. Incluso el director de la compañía, Edward Lawrence Kersten, indicó que estaba considerando cambiar su propio nombre a :-( pues "le apetecía que su nombre simbolizara la infelicidad".
Sin embargo, no todo el mundo entendió la broma, y se generó un inmenso revuelo a nivel mundial, acusando a la compañía de querer apropiarse de un bien universal. Tanto fue así que un mes más tarde publicaron otra nota de prensa, en la que, también en tono jocoso, la empresa se comprometía con la comunidad global de internet a permitir el uso legal del emoticono en el email, vendiéndolos a través de su propia web bajo el nombre comercial Frownies™ y siempre que los usuarios se comprometieran en el cumplimiento de una desmadrada licencia de usuario final.
 Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.
Y desde luego, lo que no se puede negar es el sentido del humor de la gente de Despair. Desde la web de venta online de los Frownies es posible, por tiempo limitado, adquirir originales manufacturados de uno de los modelos previstos (el classic edition) por cero dólares, una oferta inmejorable ;-)) Y por cierto, vale la pena leer en su última nota de prensa los problemas de fabricación a los que debían enfrentarse ante este nuevo reto, desde su única copia legal de Microsoft Word hasta la acentuada dislexia del empleado encargado de su fabricación.También es conocido que los emoticonos :-) y :) están registrados en Finlandia. Igualmente han sido polémicos otros registros y patentes relacionadas, como las efectuadas por Cingular en 2006 relativo a su uso en teléfonos móviles, o la solicitud de patente de Microsoft sobre la forma de crear y trasmitir emoticonos personalizados.
8. Emoticonos y accesibilidad
Desde el punto de vista de la accesibilidad un emoticono es exactamente igual que cualquier otro elemento no textual, por lo que debe prestársele especial atención para asegurar el acceso universal a la información.Las WCAG 1.0 (Pautas de Accesibilidad al Contenido Web) recoge como prioridad de nivel 1 proporcionar un texto equivalente para todo contenido no textual, incluyendo, expresamente, a los smileys o emoticonos entre ellos, a los que considera como arte ASCII.
Por ejemplo, el test automatizado Web Accessibility Checker incluye como problema el uso excesivo de emoticonos, o el hecho de no rodear éstos entre etiquetas como sigue:
<abbr title="emoticono de sonrisa">:-)</abbr>Punto extra: ¿y el futuro?
Hoy en día los emoticonos basados en texto están siendo sustituidos por versiones gráficas, con efectos y animaciones e incluso sonidos. Aplicaciones de uso muy común, como procesadores de texto o clientes de mensajería instantánea realizan la conversión al modelo gráfico de forma automática, e incluyen atajos o botones en sus interfaces para incluirlos, por lo que es probable que en unos años los iconos textuales pasen a ser historias de veteranos nostálgicos, como muchas otras.Lo que sin duda perdudará será el concepto, la necesidad de añadir el contenido emocional a los mensajes escritos, sea cual sea su forma.
¡Larga vida al emoticono!
Fuentes:
- Language Logs, the prehistory of emoticons
- Wikipedia: Emoticons
- Emoticonos en Wikipedia
- El País: 25 años guiñando
- Internet Movie Database (IMDb)
- Web Accessibility Initiative (WAI)
Publicado en: http://www.variablenotfound.com/.
 Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.
Utilizo los emoticonos muy frecuentemente, desde que los descubrí en aquellos tiempos en los que Fidonet dominaba el mundo de las comunicaciones digitales entre mortales.Y probablemente debido a su cotidianeidad, hasta ahora no les había prestado demasiada atención. Sin embargo, cuando he buscado un poco de información sobre ellos, he encontrado algunas curiosidades que creo que vale la pena conocer.
1. Sobre el término emoticono
El término emoticono es la traducción del portmanteau inglés "emoticon", fusión de "emotion" + "icon", en clara referencia a que se trata de un icono para representar emociones. Fue introducido por David W. Sanderson en su libro "Smileys" publicado en 1993, años después de la popularización de los mismos.Aunque se suele utilizar como sinónimo "smiley", estrictamente hablando no es lo mismo. Un smiley es una representación esquemática de una cara sonriente, por lo que sólo algunos emoticonos lo son. Hay muchos que no son caras, o que éstas no presentan precisamente una sonrisa. Eso sí, el típico smiley redondo y amarillo, creado por el diseñador Harvey Ball en 1963, inspiró con su simplista representación los emoticonos gráficos que conocemos hoy.La 22ª edición del Diccionario de la Real Academia Española, del año 2001, definió el término emoticono como:
"Símbolo gráfico que se utiliza en las comunicaciones a través del correo electrónico y sirve para expresar el estado de ánimo del remitente"Accediendo a la definición, sin embargo, se puede comprobar que ésta ha sido enmendada y la próxima edición contará con una más acorde con la realidad, donde se deja notar el avance tecnológico producido desde entonces:
"Representación de una expresión facial que se utiliza en mensajes electrónicos para aludir al estado de ánimo del remitente"De la misma forma, en la actualidad se acepta el término emoticón (con plural emoticones), pero parece ser que puede ser eliminado en futuras ediciones del diccionario.
2. Antecedentes históricos
La necesidad de asociar sentimientos y emociones a textos escritos existía mucho antes de la creación de los emoticonos y de la aparición de las redes de ordenadores. De hecho, se conocen apariciones anteriores de conceptos similares, aunque adaptados al medio del momento.Está documentado el uso, en abril de 1857, del código numérico "73" como una forma de añadir a un mensaje escrito en código Morse un afectuoso "love and kisses", que más adelante pasó a formalizarse como "best regards". Ya más adelante, a principios del siglo XX, se volvió a añadir este amoroso sentimiento, codificándolo como "88".
 Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos.
Sin embargo, aunque esta técnica permitía incluir una componente emocional en los mensajes, no se había hecho utilizando iconos. En marzo de 1881, Puck, una revista satírica de gran éxito del momento, utilizó por primera vez representaciones gráficas para asociar emociones a los textos. Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.
Algo más adelante, sobre 1912, el jornalista y escritor Ambrose Bierce propuso la mejora de la puntuación utilizando un nuevo signo, parecido a una U aplanada o a un paréntesis tumbado, a modo de labios sonrientes para remarcar cualquier frase jocosa o irónica.Este mismo signo fue descrito también por Vladimir Nabovok, escritor de origen ruso conocido, sobre todo, por ser el autor de la famosa novela Lolita, en una entrevista realizada por el New York Times en abril de 1969, donde respondía a una cuestión sobre su valoración respecto a otros escritores de la época y anteriores:
I often think there should exist a special typographical sign for a smile -- some sort of concave mark, a supine round bracket which I would now like to trace in reply to your question.
_______________________________________
A menudo pienso que debería existir un símbolo tipográfico especial para una sonrisa -- algo parecido a una marca cóncava, un paréntesis tendido que me gustaría registrar como respuesta a su pregunta.
 El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:
El 10 de marzo de 1953, el periódico New York Herald Tribune publicó, entre otros medios de la época, un anuncio de la recién estrenada película Lili, en el que aparecen por primera vez dos de los emoticonos más conocidos:Today You'll laugh :-) You'll cry :-( You'll love <3 'Lili'
_______________________________________
Hoy reirás :-) Llorarás :-( Amarás <3 'Lili'
 Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.
Ya en el ámbito electrónico, los usuarios del sistema PLATO, considerado una de las primeras comunidades virtuales, comenzaban en la década de los 60 y 70 a diseñar iconos a base de superponer en pantalla varios caracteres estándar. Por ejemplo, como aparece en la ilustración, superponiendo en la misma posición los caracteres V, I, C, T, O, R e Y, era posible obtener una figura donde fácilmente podía reconocerse una cara muy sonriente.3. El origen de los emoticonos en comunicaciones digitales
En abril de 1979, Kevin MacKenzie sugirió a los suscriptores de MsgGroup, una de las primeras listas de distribución de ARPANET, el origen de la Internet de hoy en día, la utilización de algún mecanismo para indicar emociones en el inexpresivo correo electrónico. Concretamente, se le atribuye el uso del símbolo "-)" para indicar contenidos irónicos en su mensaje:Perhaps we could extend the set of punctuation we use, i.e.: If I wish to indicate that a particular sentence is meant with tongue-in-cheek, I would write it so:Aunque su propuesta concreta no fue acogida con especial entusiasmo, los pioneros de las redes de comunicación comenzaron a utilizar variantes de estas expresiones en sus mensajes, la mayoría de las cuales no ha trascendido hasta la actualidad.
"Of course you know I agree with all the current administration's policies -)."
The "-)" indicates tongue-in-cheek.
_______________________________________
Quizás deberíamos extender el conjunto de signos de puntuación que utilizamos, por ejemplo: si quiero indicar que una frase en particular debe ser entendida como una ironía, la escribiría así:
"Por supuesto, sabes que estoy de acuerdo con todas las políticas actuales de la administración -)"
El "-)" indica que el mensaje es irónico.
Más tarde, en septiembre de 1982, Scott Fahlman envió el siguiente mensaje a un tablón de la BBS de la Universidad Carnegie Melon:
19-Sep-82 11:44 Scott E Fahlman :-)
From: Scott E Fahlman
I propose that the following character sequence for joke markers:
:-)
Read it sideways. Actually, it is probably more economical to mark
things that are NOT jokes, given current trends. For this, use
:-(
_______________________________________
Propongo la siguiente secuencia de caracteres para marcar las bromas:
:-)
Leedlo inclinando la cabeza. En realidad, probablemente sea más económico marcar lo que NO sea broma, dada la tendencia actual. En este caso, usad
:-(
 En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.
En este mensaje, Fahlman proponía la utilización de los emoticonos :-) y :-( para expresar emociones relacionadas con un mensaje escrito, y más concretamente para que el lector pudiera identificar cuándo un texto debía ser entendido como una broma y cuándo no. Es curioso que el mensaje original, al que pertenece el extracto anterior, fue recuperado de viejas cintas de backup de la universidad veinte años después de su publicación por un investigador de Microsoft, Mike Jones.Estos emoticonos sí fueron aceptados, y a partir de ese momento comenzó su utilización de forma masiva. Por esta razón, se considera a Fahlman como el padre de los emoticonos tal y como hoy los conocemos, aunque no todo el mundo está de acuerdo con ello.
Él mismo afirma en un artículo que es el inventor del emoticono lateral... o al menos uno de ellos. Pero sí está seguro de haber sido el primero en utilizar la secuencia :-) para indicar una broma en el medio digital.
4. Emoticonos corporales y otras extensiones
Continuar leyendo en 8 curiosidades que quizás no conocías sobre los emoticonos, segunda parte.
domingo, 18 de mayo de 2008
 El año pasado, en un insólito derroche de precisión, fui capaz de publicar un post celebrando el primer año de Variable not found justo el mismo día de su cumpleaños. Lamentablemente no he podido repetir esta hazaña, y hoy me he dado cuenta de que hace diez días este blog cumplió su segundo aniversario.
El año pasado, en un insólito derroche de precisión, fui capaz de publicar un post celebrando el primer año de Variable not found justo el mismo día de su cumpleaños. Lamentablemente no he podido repetir esta hazaña, y hoy me he dado cuenta de que hace diez días este blog cumplió su segundo aniversario.Bueno, en cualquier caso, es buen momento para recapitular un poco y reflexionar sobre el camino recorrido desde mayo de 2006, cuando con cierto recato publicaba mi post inaugural en la dirección de Blogger jmaguilar.blogspot.com.
Hasta el momento podríamos hablar de dos periodos:
 Año 1: la travesía del desierto (mayo 2006 - mayo 2007). Supongo que todos los que mantenéis un blog entenderéis esta expresión (bueno, quizás salvo los propiciados por las grandes productoras o personal especialmente mediático).
Año 1: la travesía del desierto (mayo 2006 - mayo 2007). Supongo que todos los que mantenéis un blog entenderéis esta expresión (bueno, quizás salvo los propiciados por las grandes productoras o personal especialmente mediático).
La principal característica de este periodo fue la ausencia casi total de lectores. Salvo algún inexplicable pico puntual de visitas como el obtenido por el post sobre Google Image Labeler, durante nueve meses estuve prácticamente escribiendo para mí.
Tampoco tenía demasiado tiempo para dedicarle, pero de vez en cuando lo daba de alta en buscadores y sitios de referencia para lograr una mayor difusión, aunque lo cierto es que estas acciones no resultaban demasiado efectivas.
Fue a finales de marzo de 2007, casi cumpliendo ya el primer año, cuando el maestro Juanjo Navarro (¡gracias, Juanjo!) me incluyó en el agregador Planeta Código e hizo referencia en su blog Más que código a mi serie de posts sobre técnicas de spam, lo que supuso un fuerte empujón para dar a conocer el blog y difundir un poco sus contenidos. Año 2: el despegue (mayo 2007 - mayo 2008). Coincidiendo con un aumento de disponibilidad de tiempo libre, comenzamos el segundo año de vida adquiriendo el nombre de dominio variablenotfound.com y activando Feedburner para la gestión de feeds, pues hasta ese momento no había prestado demasiada atención a los suscriptores (!).
Año 2: el despegue (mayo 2007 - mayo 2008). Coincidiendo con un aumento de disponibilidad de tiempo libre, comenzamos el segundo año de vida adquiriendo el nombre de dominio variablenotfound.com y activando Feedburner para la gestión de feeds, pues hasta ese momento no había prestado demasiada atención a los suscriptores (!).
Pero no quedaron ahí los cambios. A finales de 2007, por cortesía de Javier Cantos (¡gracias, Javi!), por fin pude dejar atrás el diseño basado en una plantilla estándar de Blogger y, tras encarnizada batalla, conseguí que el blog luciera así de bien.
También resultó decisiva la inclusión del blog en otros agregadores como Planet WebDev (¡gracias, Héctor!) o crosspostear en Geeks.ms (¡gracias, Rodrigo!).
Como consecuencia de todo esto, este año se ha producido un incremento brutal del número de visitas(es obvio, partía de cero ;-D)), rozando en la actualidad la cifra de 10.000 al mes, sólo a variablenotfound.com. Aunque no sé si es causa o consecuencia de lo anterior, durante este año he sufrido también varios meneos que bien podría calificar de terremotos, y muchos enlaces, algunos desde fuentes de gran relevancia como Microsiervos, Genbeta, o Error500.
En cuanto a los suscriptores de feeds, la siguiente gráfica muestra el estado a día de hoy, y cómo nos vamos acercando a los 400, una cifra impensable ni en mis aspiraciones más optimistas, y a mi entender impresionante dada la temática tan específica del blog.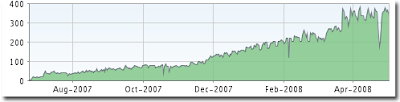
Pero, ¿vale la pena esto? Haciendo un cálculo rápido y tirando muy por lo bajo, si hubiera necesitado sólo un par de horas por cada uno de los 158 posts que he publicado hasta el momento (os aseguro que la media es mucho más alta, sumando el tiempo de escribir, estudiar, maquetar, comprobar, buscar fuentes...), llevaría dedicadas al blog más de 300 horas; en el mundo laboral, supondría un par de meses a jornada completa. Fuerte, ¿eh?
Menos mal que desde el punto de vista económico el blog es todo un éxito. De hecho, acabo de cambiar de coche gracias a los ingresos generados por AdSense, y espero en breve adquirir un apartamentito en la playa a cargo los importantes beneficios que me reporta Amazon.
 .. mmm... ¡Despierta! Siendo realistas, cuando dentro de cinco años, según la tendencia actual, consiga reunir los 100 dólares mínimos necesarios para que me hagan un ingreso, probablemente no tendré ni para invitar a mi familia a comer un par de pizzas.
.. mmm... ¡Despierta! Siendo realistas, cuando dentro de cinco años, según la tendencia actual, consiga reunir los 100 dólares mínimos necesarios para que me hagan un ingreso, probablemente no tendré ni para invitar a mi familia a comer un par de pizzas.Obviamente a nadie le amarga un dulce, y ya que se dedica tiempo a ello no estaría mal rentabilizarlo un poco, pero está claro que si merece o no la pena seguir con Variable not found no depende de los ingresos económicos generados, sino de otros factores.
Durante este tiempo he aprendido como nunca lo había hecho. La escritura de un post con un contenido técnico medianamente complejo requiere una asimilación mucho más profunda de la que se consigue con una simple lectura; también la creación de ejemplos, comprobaciones, o la búsqueda de información, resulta muy enriquecedora. Si a esto, además, se une las aportaciones y retroalimentación de los lectores vía comentarios o contacto directo, os puedo asegurar que la experiencia es alucinante.
Y es precisamente en esto último donde se encuentra la mayor recompensa, en los cientos de lectores que visitan Variable not found cada día, vía web o lector RSS, y animan a continuar en la brecha.
Gracias a todos, y espero que sigáis por aquí, buscando la variable.
Publicado en: www.variablenotfound.com.
miércoles, 14 de mayo de 2008
He descubierto una nueva chuleta, esta vez de la mano del diseñador y desarrollador web G. Scott Olson, que publicó hace unos meses la jQuery 1.2 Cheat Sheet.
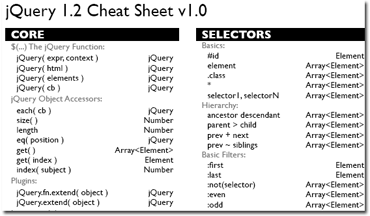
Además de seguir tapando huecos en la pared, nos valdrá para tener a mano una referencia rápida (muy rápida) de jQuery, donde encontraremos funciones, selectores, eventos, métodos de manipulación, efectos y utilidades de esta magnífica librería javascript.
Publicado en: www.variablenotfound.com.
Además de seguir tapando huecos en la pared, nos valdrá para tener a mano una referencia rápida (muy rápida) de jQuery, donde encontraremos funciones, selectores, eventos, métodos de manipulación, efectos y utilidades de esta magnífica librería javascript.
Publicado en: www.variablenotfound.com.
domingo, 11 de mayo de 2008
 Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.
Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.Como recordaréis, hasta ese momento las acciones no tenían tipo de retorno, pero han replanteado el diseño para hacerlo más flexible, testable y potente. Así, pasamos de definir las acciones de esta forma:
public void Index()
{
RenderView("Index");
}a esta otra:
public ActionResult Index()
{
return RenderView();
}En el código anterior destacan dos aspectos. En primer lugar que la llamada a
RenderView() no tiene parámetros; el sistema mostrará la vista cuyo nombre coincida con el de la acción que se está ejecutando (Index, en este caso). En segundo lugar, que la llamada a RenderView() retorna un objeto ActionResult (o más concretamente un descendiente, RenderViewResult), que será el devuelto por la acción.De la misma forma, existen tipos de ActionResult concretos para retornar el resultado de las acciones más habituales:
RenderViewResult, retornado cuando se llama desde el controlador aRenderView().ActionRedirectResult, retornado al llamar aRedirectToAction()HttpRedirectResult, que será la respuesta a unRedirect()EmptyResult, que intuyo que será para casos en los que no hay que hacer nada (!), aunque todavía no le he visto mucho el sentido...
Además de las citadas anteriormente, una de las ventajas de retornar estos objetos desde los controladores es que podemos crear nuestra clase, siempre heredando de
ActionResult, e implementar comportamientos personalizados.Esto es lo que ha hecho el genial Phil Haack en dos ejemplos recientemente publicados en su blog.
El primero de ellos, publicado en el post "Writing A Custom File Download Action Result For ASP.NET MVC" muestra una implementación de una acción cuya invocación hace que el cliente descargue, mediante un download, el archivo indicado, en su ejemplo, el archivo CSS de su sitio web:
public ActionResult Download()
{
return new DownloadResult
{ VirtualPath="~/content/site.css",
FileDownloadName = "TheSiteCss.css"
};
}
La clase
DownloadResult una descendiente de ActionResult, en cuya implementación encontraremos, además de la definición de las propiedades VirtualPath y FileDownloadName, la implementación del método ExecuteResult, que será invocado por el framework al finalizar la ejecución de la acción, y donde realmente se realiza el envío al cliente del archivo, con parámetro content-disposition convenientemente establecido:public class DownloadResult : ActionResult
{
public DownloadResult()
{
}
public DownloadResult(string virtualPath)
{
this.VirtualPath = virtualPath;
}
public string VirtualPath { get; set; }
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (!String.IsNullOrEmpty(FileDownloadName)) {
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName)
}
string filePath = context.HttpContext.Server.MapPath(this.VirtualPath);
context.HttpContext.Response.TransmitFile(filePath);
}
}
El segundo ejemplo, publicado en el post "Delegating Action Result", vuelve a demostrar otro posible uso de los ActionResults creando un nuevo descendiente,
DelegatingResult, que puede ser retornado desde las acciones para indicar qué operaciones deben llevarse a cabo por el framework.El siguiente código muestra cómo retornamos un objeto de este tipo, inicializado con una lambda:
public ActionResult Hello()
{
return new DelegatingResult(context =>
{
context.HttpContext.Response.AddHeader("something", "something");
context.HttpContext.Response.Write("Hello World!");
});
}Como veremos a continuación, el constructor de este nuevo tipo recibe un parámetro de tipo
Action<ControllerContext> y lo almacenará de forma local en la propiedad Command, postergando su ejecución hasta más adelante; será la sobreescritura del método ExecuteResult la que ejecutará el comando:public class DelegatingResult : ActionResult
{
public Action<ControllerContext> Command { get; private set; }
public DelegatingResult(Action<ControllerContext> command)
{
this.Command = command;
}
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
throw new ArgumentNullException("context");
Command(context);
}
}
Puedes ver el código completo de ambos ejemplos, así como descargar proyectos de prueba en los artículos originales de Phil Haack:
Por último, recordar que todos estos detalles son relativos a la última actualización de la preview de esta tecnología y podrían variar en futuras revisiones.
Publicado en: www.variablenotfound.com.
martes, 6 de mayo de 2008
Desde siempre me han fascinado los motores de física en tiempo real, probablemente debido a mi absoluta ignorancia en el tema. De hecho, cada vez que me topo con alguna demostración de uno de ellos, no puedo evitar pasar un buen rato jugando y observando los efectos que de forma tan asombrosa simulan la realidad.
Fisix, por ejemplo, es un motor de física en 2 dimensiones desarrollado en ActionScript 3.0 para desarrolladores de juegos o simuladores en Flash. Aunque en su web podéis encontrar más demos, incrusto una aquí para que os hagáis a la idea de lo que puede llegar a conseguirse con esta librería (podéis probar a arrastrar la muñeca por la pantalla o interactuar con los objetos).
Actualmente se encuentra en su versión alfa 0.5, y puede ser utilizado sin coste exclusivamente en proyectos no comerciales; para otros usos hay que contactar con el autor. En cualquier caso, por el tiempo que ha pasado desde su última actualización, parece que no está muy al día.
Publicado en: www.variablenotfound.com.
Fisix, por ejemplo, es un motor de física en 2 dimensiones desarrollado en ActionScript 3.0 para desarrolladores de juegos o simuladores en Flash. Aunque en su web podéis encontrar más demos, incrusto una aquí para que os hagáis a la idea de lo que puede llegar a conseguirse con esta librería (podéis probar a arrastrar la muñeca por la pantalla o interactuar con los objetos).
Actualmente se encuentra en su versión alfa 0.5, y puede ser utilizado sin coste exclusivamente en proyectos no comerciales; para otros usos hay que contactar con el autor. En cualquier caso, por el tiempo que ha pasado desde su última actualización, parece que no está muy al día.
Publicado en: www.variablenotfound.com.
domingo, 4 de mayo de 2008
 Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.
Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.Como sabemos, si desde una aplicación queremos obtener una descripción comprensible de un elemento de una enumeración, normalmente no podemos realizar una conversión directa (
elemento.ToString()) del mismo, pues obtenemos los nombres de los identificadores usados a nivel de código. La solución habitual, hasta la llegada de C# 3.0 consistía en incluir dentro de alguna clase de utilidad un conversor estático que recibiera como parámetro en elemento de la enumeración y retornara un string, algo así como:
public static string EstadoProyecto2String(EstadoProyecto e)
{
switch (e)
{
case EstadoProyecto.PendienteDeAceptacion:
return "Pendiente de aceptación";
case EstadoProyecto.EnRealizacion:
return "En realización";
case EstadoProyecto.Finalizado:
return "Finalizado";
default:
throw
new ArgumentOutOfRangeException("Error: " + e);
}
}
Este método, sin embargo, presenta algunos inconvenientes. En primer lugar, dado el tipado fuerte del parámetro de entrada del método, es necesario crear una función similar para cada enumeración sobre la que queramos realizar la operación.
También puede resultar peligroso separar la definición de la enumeración del método que transforma sus elementos a cadena de caracteres, puesto que puede perderse la sincronización entre ambos cuando, por ejemplo, se introduzca un nuevo elemento en ella y no se actualice el método con la descripción asociada.
La solución, que como he comentado me pareció muy interesante, consiste en decorar cada elemento de la enumeración con un atributo que describa al mismo, e implementar un método de extensión sobre la clase base
System.Enum para obtener estos valores. Veamos cómo.Ah, una cosa más. Aunque los ejemplos están escritos en C#, se puede conseguir exactamente el mismo resultado en VB.NET simplemente realizando las correspondientes adaptaciones sintácticas. Podrás encontrarlo al final del post.
1. Declaración de la enumeración
Vamos a usar el atributoSystem.ComponentModel.DescriptionAttribute, aunque podríamos usar cualquier otro que nos interese, o incluso crear nuestro propio atributo personalizado. El código de definición de la enumeración sería así:
using System.ComponentModel;
public enum EstadoProyecto
{
[Description("Pendiente de aceptación")] PendienteDeAceptacion,
[Description("En realización")] EnRealizacion,
[Description("Finalizado")] Finalizado,
[Description("Facturado y cerrado")] FacturadoYCerrado
}
2. Implementación del método de extensión
Ahora vamos a crear el método de extensión (¿qué son los métodos de extensión?) que se aplicará a todas las enumeraciones.Fijaos que el parámetro de entrada del método está precedido por la palabra reservada
this y el tipo es System.Enum, por lo que será aplicable a cualquier enumeración.
using System;
using System.ComponentModel;
using System.Reflection;
public static class Utils
{
public static string GetDescription(this Enum e)
{
FieldInfo field = e.GetType().GetField(e.ToString());
if (field != null)
{
object[] attribs =
field.GetCustomAttributes(typeof(DescriptionAttribute), false);
if (attribs.Length > 0)
return (attribs[0] as DescriptionAttribute).Description;
}
return e.ToString();
}
}
 Y voila! A partir de este momento tendremos a nuestra disposición el método
Y voila! A partir de este momento tendremos a nuestra disposición el método GetDescription(), que nos devolverá el texto asociado al elemento de la enumeración; si éste no existe, es decir, si no se ha decorado el elemento con el atributo apropiado, nos devolverá el identificador utilizado.De esta forma eliminamos de un plumazo los dos inconvenientes citados anteriormente: la separación entre la definición de la enumeración y los textos descriptivos, y la necesidad de crear un conversor a texto por cada enumeración que usemos en nuestra aplicación.
Y por cierto, el equivalente en VB.NET completo sería:
Imports System.ComponentModel
Imports System.Reflection
Imports System.Runtime.CompilerServices
Module Module1
Public Enum EstadoProyecto
<Description("Pendiente de aceptación")> PendienteDeAceptacion
<Description("En realización")> EnRealizacion
<Description("Finalizado")> Finalizado
<Description("Facturado y cerrado")> FacturadoYCerrado
End Enum
<Extension()> _
Public Function GetDescription(ByVal e As System.Enum) As String
Dim field As FieldInfo = e.GetType().GetField(e.ToString())
If Not (field Is Nothing) Then
Dim attribs() As Object = _
field.GetCustomAttributes(GetType(DescriptionAttribute), False)
If attribs.Length > 0 Then
Return CType(attribs(0), DescriptionAttribute).Description
End If
End If
Return e.ToString()
End Function
End Module
Publicado en: www.variablenotfound.com.










