
domingo, 26 de octubre de 2008
 Vamos a continuar desarrollando nuestro
Vamos a continuar desarrollando nuestro traceroute utilizando el framework .NET. En la primera parte del post ya describimos los fundamentos teóricos, y esbozamos el algoritmo a emplear para conseguir detectar la secuencia de nodos atravesados por los paquetes de datos que darían lugar a nuestra ruta.Continuamos ahora con la implementación de nuestro sistema de trazado de redes.
Lo primero: estructurar la solución
Vamos a desarrollar un componente independiente, empaquetado en una librería, que nos permita realizar trazados de rutas desde cualquier tipo de aplicación, y más aún, desde cualquier lenguaje soportado por la plataforma .NET. Atendiendo a eso, ya debemos tener claro que construiremos un ensamblado, al que vamos a llamar NTraceLib, que contendrá una clase (Tracer) que gestionará toda la lógica de obtención de la traza de la ruta.Dado que debe ser independiente del tipo de aplicación que lo utilice, no podrá incluir ningún tipo de interacción con el usuario, ni acceso a interfaz alguno. Serán las aplicaciones de mayor nivel las que solucionen este problema. La clase
Tracer se comunicará con ellas enviándole eventos cada vez que ocurra algo de interés, como puede ser la recepción de paquetes de datos con las respuestas. Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:
Las distintas aplicaciones "cliente" de NTraceLib las crearemos como proyectos independientes:- NTrace será una aplicación de consola escrita en C#.
- WebNTrace, también escrita en C#, permitirá trazar los paquetes enviados desde el servidor Web donde se esté ejecutando hasta el destino.
- WinNTrace será una herramienta de escritorio, esta vez escrita en VB.NET, que permitirá obtener los resultados de forma más visual.
Tracer: el trazador
La claseTracer será la encargada de realizar el trazado de la ruta hacia el destino indicado. De forma muy rápida, podríamos enumerar sus principales características:- Tiene una única propiedad pública,
Host, que contiene la dirección (nombre o IP) del equipo destino del trazado. Los comandostracertytraceourtetienen más opciones, pero no las vamos a implementar para simplificar el sistema. - Tiene definidas también dos constantes:
- MAX_HOPS, que define el máximo de saltos, o nodos intermedios que permitiremos atravesar a nuestros paquetes. Normalmente no se llegará a este valor.
- TIMEOUT, que definirá el tiempo máximo de espera de llegada de las respuestas.
- Publica dos eventos, que permitirán a las aplicaciones cliente procesar o realizar la representación visual de la información resultante de la ejecución del trazado:
- ErrorReceived, que notificará a la aplicación cliente del componente que se ha producido un error durante la obtención de la ruta. Ejemplos serían "red inalcanzable", o "timeout".
- EchoReceived, que permitirá notificar de la recepción de mensajes por parte de los nodos de la ruta.
- El método
Trace()ejecutará al ser invocado el procedimiento descrito en el post anterior, lanzando los eventos para indicar a las aplicaciones cliente que actualicen su estado o procesen la respuesta. A grandes rasgos, el procedimiento consistía en ir enviado mensaje ICMP ECHO (pings) al servidor de destino incrementando el TTL del paquete en cada iteración y esperar la respuesta, bien la respuesta al ping o bien mensajes "time exceeded" indicando la expiración del paquete durante la ruta hacia el destino.
Para conocer más detalles sobre la clase
Tracer, puedes descargar el proyecto desde el enlace que encontrarás al final del post.Enviar ICMP ECHOs, o cómo hacer un Ping desde .NET
La versión 2.0 de .NET framework nos lo puso realmente sencillo, al incorporar una clase específicamente diseñada para ello, Ping, incluida en el espacio de nombres System.Net.NetworkInformation. A continuación va un código que muestra el envío de una solicitud de eco al servidor www.google.es: Ping pingSender = new Ping ();
PingOptions options = new PingOptions ();
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("datos");
int timeout = 120;
PingReply reply = pingSender.Send ("www.google.es",
timeout, buffer, options);
if (reply.Status == IPStatus.Success)
{
Console.WriteLine ("Recibido: {0}",
reply.Address.ToString ());
}
De este código vale la pena destacar algunos detalles. Primero, como podemos observar, existe una clase
PingOptions que nos permite indicar las opciones con las que queremos enviar el paquete ICMP. En particular, podremos especificar si el paquete podrá ser fragmentado a lo largo de su recorrido, así como, aunque no aparece en el código anterior, el valor inicial del TTL (time to live) del mismo. Habréis adivinado que este último aspecto es especialmente importante para lograr nuestros objetivos.Segundo, es posible indicar en un buffer un conjunto de datos arbitrarios que viajarán en el mensaje, lo que podría permitirnos medir el tiempo de ida y vuelta de un paquete de un tamaño determinado. También se puede indicar el tiempo máximo en el que debemos recibir la respuesta antes de considerar que se trata de un timeout.
Por último, la respuesta a la llamada síncrona
pingSender.Send(...) obtiene un objeto del tipo PingReply, en el que encontraremos información detallada sobre el resultado de la operación.Implementación del trazador
Si unimos el procedimiento de trazado de una ruta, descrito ampliamente en el post anterior, al método de envío de pings recién comentado, casi obtenemos directamente el código del métodoTrace() de la clase Tracer, el responsable de realizar el seguimiento de la ruta:
PingReply reply;
Ping pinger = new Ping();
PingOptions options = new PingOptions();
options.Ttl = 1;
options.DontFragment = true;
byte[] buffer = Encoding.ASCII.GetBytes("NTrace");
try
{
do
{
DateTime start = DateTime.Now;
reply = pinger.Send(host,
TIMEOUT,
buffer,
options);
long milliseconds = DateTime.Now.Subtract(start).Milliseconds;
if ((reply.Status == IPStatus.TtlExpired)
|| (reply.Status == IPStatus.Success))
{
OnEchoReceived(reply, milliseconds);
}
else
{
OnErrorReceived(reply, milliseconds);
}
options.Ttl++;
} while ((reply.Status != IPStatus.Success)
&& (options.Ttl < MAX_HOPS ));
}
catch (PingException pex)
{
throw pex.InnerException;
}
Como podemos observar, se repite el Ping dentro de un bucle en el que va incrementándose el TTL hasta llegar al objetivo (
reply.Status==IPStatus.Success) o hasta que se supere el máximo de saltos permitidos. Por cada ping realizado se llama al evento correspondiente en función del resultado del mismo, con objeto de notificar a las aplicaciones cliente de lo que va pasando. Además, se va tomando en cada llamada el tiempo que se tarda desde el momento del envío hasta la recepción de la respuesta. Podéis observar que llamamos al evento
EchoReceived siempre que recibamos algo de un nodo, sea intermediario (que recibiremos un error por expiración del TTL) o el destinatario final del paquete (que recibiremos la respuesta satisfactoria al ping), mientras que el evento ErrorReceived es invocado en todas las demás circunstancias. En cualquier caso, siempre enviaremos como parámetros el PingReply, que contiene información detallada de la respuesta, y el tiempo en milisegundos que ha tardado en obtenerse la misma.Ah, una nota importante respecto al tiempo de resolución de nombres. Dado que la clase
Ping funciona tanto si le especificamos como destino una dirección IP como si es un nombre de host, hay que tener en cuenta que el primer ping podrá verse penalizado por el tiempo de consulta al DNS si esto es necesario. Esto podría solventarse muy fácilmente, realizando la resolución de forma manual y pasando al ping siempre la dirección IP, pero he preferido mantenerlo así para mantener el código más sencillo.Cómo usar NTraceLib en aplicaciones
 Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:
Sea cual sea el tipo de aplicación que vaya a utilizar el componente de trazado, el patrón será siempre el mismo:- Declaramos una variable del tipo
Trace. - Escribimos los manejadores que procesen las respuestas de
ErrorReceivedyEchoReceived, suscribiéndolos a los correspondientes eventos. - Establecemos el host y llamamos al método
Trace()del objeto de trazado.
Vamos a ver el ejemplo concreto de la aplicación WinNTrace, sistema de escritorio creado en Visual Basic .NET, que mostrará en un formulario el resultado del trazado. En primer lugar, tiene declarado un objeto
Tracer como sigue, lo que nos permitirá enlazarle el código a los eventos de forma muy sencilla: Private WithEvents tracer As New TracerCuando el usuario teclea un host en el cuadro de texto y pulsa el botón "Trazar", se ejecuta el siguiente código (he omitido ciertas líneas para facilitar su lectura); podréis comprobar que es bastante simple, pues incluye sólo la asignación del equipo de destino y la llamada a la realización de la traza:
tracer.Host = txtHost.Text
Try
tracer.Trace()
Catch ex As Exception
MessageBox.Show("Error: " + ex.Message, "Error", _
MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
Cuando se recibe información de un nodo, sea intermediario o el destino final de la traza, añadimos al
ListView un nuevo elemento con la dirección del mismo, así como los milisegundos transcurridos desde el envío de la petición: Private Sub tracer_EchoReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.EchoReceivedEventArgs) _
Handles tracer.EchoReceived
Dim items() As String = { _
args.Reply.Address.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
En el caso de recibir un error, como un timeout, añadiremos la línea, pero aportando mostrando el tipo de error producido y destacando la fila respecto al resto con un color de fondo. Este procedimiento podría haberlo trabajado un poco más, por ejemplo añadiendo textos descriptivos de los errores, pero eso os lo dejo de deberes.
Private Sub tracer_ErrorReceived( _
ByVal sender As NTraceLib.Tracer, _
ByVal args As NTraceLib.ErrorReceivedEventArgs) _
Handles tracer.ErrorReceived
Dim items() As String = { _
"Error: " + args.Reply.Status.ToString(), _
args.Milliseconds.ToString()}
Dim item As New ListViewItem(items)
item.BackColor = Color.Yellow
lvResult.Items.Add(item)
Application.DoEvents()
End Sub
Además de WinNTrace, en la descarga que encontraréis al final del post he incluido NTrace (la aplicación de consola) y WebNTrace (la aplicación web). Aunque cada una tiene en cuenta sus particularidades de interfaz, el comportamiento es idéntico al descrito para el sistema de escritorio, por lo que no los describiremos con mayor detalle.
Conclusiones
 A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.
A lo largo de estos posts hemos desarrollado un componente de realización de trazados de rutas de red, y tres aplicaciones que lo utilizan. Hemos revisado los fundamentos teóricos en los que se sustenta, y su implementación utilizando .NET framework, siempre con un alcance relativamente simple para facilitar su comprensión.Dejamos para artículos posteriores la realización de funcionalidades no implementadas en esta versión, como la posibilidad de cancelar una traza una vez comenzada, la resolución inicial de nombres para que el tiempo de respuesta de la primera pasarela sea más correcto, o incluso la resolución inversa del nombre de los nodos de una ruta, es decir, la obtención del hostname de cada uno de ellos tal y como lo hacen las utilidades de línea comand
tracert o traceroute. También podríamos incluir funciones de geoposicionamiento de los mismos, para intentar obtener una aproximación la ruta física que siguen los paquetes a través de la red.Espero que os haya resultado interesante. Y por supuesto, para dudas, consultas o sugerencias, por aquí me tenéis.
Descargar NTrace (proyecto VS2005)
Publicado en: www.variablenotfound.com.
martes, 21 de octubre de 2008
 Saboreando los bocabits ofrecidos por Javier Babuglia encontré, hace ya algo de tiempo, una herramienta de prototipado de interfaces de usuario de lo más útil y simpática, Balsamiq Mockups, que combina la potencia y flexibilidad de un diseñador visual con los resultados del prototipado en papel.
Saboreando los bocabits ofrecidos por Javier Babuglia encontré, hace ya algo de tiempo, una herramienta de prototipado de interfaces de usuario de lo más útil y simpática, Balsamiq Mockups, que combina la potencia y flexibilidad de un diseñador visual con los resultados del prototipado en papel.El objetivo de este tipo de herramientas no es obtener el diseño gráfico final de los interfaces de un sistema, sea de escritorio o web, sino un esqueleto o esquema que muestre la disposición conceptual de los principales elementos en pantalla, sin entrar en detalles concretos más cercanos al mundo del diseño artístico.
Su utilización es sencillísima. Contamos con hasta 60 elementos prediseñados que cubren prácticamente todas las necesidades (cuadros, iconos, controles de formularios, textos, etc.) que podemos arrastrar y colocar sobre la superficie de diseño como con cualquier otra herramienta visual, modificando las propiedades (contenido textual, alineación, colores...) de forma directa. El resultado que podéis llegar a obtener es como el mostrado en la siguiente imagen, tomada de los Mockups de ejemplo de la web de sus autores.

Balsamiq Mockups es una aplicación multiplataforma creada con Adobe Flex, de la que existen tanto la versión on-line para usar desde la web, como off-line, para su uso estando desconectado, que se puede descargar de forma gratuita, aunque para acceder a alguna de sus funcionalidades será necesario obtener una clave de licencia, que puede ser gratis si programas por amor al arte (para ONGs, proyectos open source...), o si eres un blogger o escribes en sitios web. En cualquier caso, todo hay que decirlo, la licencia resulta muy económica, menos de 80$.
Y para terminar, ahí va un prototipo de Variable not found realizado en unos minutos:

Publicado en: www.variablenotfound.com.
domingo, 19 de octubre de 2008
 Seguro que todos habéis utilizado en alguna ocasión el comando
Seguro que todos habéis utilizado en alguna ocasión el comando tracert (o traceroute en Linux) con objeto de conocer el camino que siguen los paquetes de información para llegar desde vuestro equipo a cualquier otro host de una red. Sin embargo, es posible que más de uno no haya tenido ocasión de ver lo sencillo que resulta desarrollar un componente que realice esta misma tarea usando tecnología .NET, y lo divertido que puede llegar a ser desarrollar utilidades de red de este tipo.En esta serie de posts vamos a desarrollar, utilizando C#, un componente simple de trazado de rutas de red. La elección del lenguaje es pura devoción personal, pero lo mismo podría desarrollarse sin problema utilizando Visual Basic .NET. En cualquier caso, el ensamblado resultante podrá ser utilizado desde cualquier tipo de aplicación soportado por el framework, es decir, sea escritorio, consola o web, y, como es obvio, independientemente del lenguaje utilizado para su creación.
Pero comencemos desde el principio...
Un poco de teoría: ¿cómo funciona un traceroute?
El objetivo de los trazadores de rutas es conocer el camino que siguen los paquetes desde un equipo origen hasta un host destino detectando los sistemas intermediarios (gateways) por los que va pasando. La enumeración ordenada de dichos sistemas es lo que llamamos ruta, y es el resultado de la ejecución del comandotracert o traceroute.Para conseguir obtener esta información, como veremos después, se utiliza de forma muy ingeniosa la capacidad ofrecida por el protocolo IP para definir el tiempo de vida de los paquetes. Profundizaremos un poco en este concepto.
El TTL (Time To Live) es un campo incluido en la cabecera de todos los datagramas IP que se mueven por la red, y es el encargado de evitar que éstos circulen de forma indefinida si no encuentran su destino.
Cuando una aplicación crea un paquete IP, se le asigna un valor inicial al TTL del encabezado del mismo. El valor puede venir definido por el sistema operativo en función del protocolo concreto (TCP, UDP...), o incluso ser asignado por el propio software que lo origine. En cualquier caso, el tiempo se indica en segundos de vida, aunque en la práctica indicará el número de veces que será procesado el paquete por los dispositivos de enrutado que atravesará durante su recorrido.
Cuando este paquete se envía hacia un destino, al llegar al primer gateway de la red, éste analizará su cabecera para determinar su ruta y encaminarlo apropiadamente, y a la misma vez decrementará el valor del TTL. De ahí atravesará otra red hasta llegar al siguiente gateway de su ruta, que volverá a hacer lo mismo. Eso sí, cuando un dispositivo encaminador de este tipo detecte un paquete con un TTL igual a cero, lo descartará y enviará a su emisor original un mensaje ICMP con un código 11 ("time exceed"), que significa que se ha excedido el tiempo de vida del paquete.
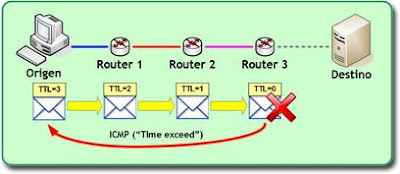
El siguiente diagrama muestra un escenario en el que un paquete es enviado con un TTL=3, y cómo es descartado antes de llegar a su destino:
Volviendo al tema del post y a algo que adelanté anteriormente, el
traceroute utiliza de forma muy ingeniosa el comportamiento descrito, siguiendo el procedimiento para averiguar la ruta de un paquete que se detalla a continuación:- Envía un paquete ICMP Echo al destino con un TTL=1. Este tipo de paquetes son los enviados normalmente al realizar un
pinga un equipo. - El primer dispositivo enrutador al que llega el paquete decrementa el TTL, y dado que es cero, descarta el paquete y envía el mensaje ICMP informando al emisor que el paquete ha sido eliminado.
- El emisor, al recibir este aviso, puede considerar que el remitente del mismo es el primer punto de la ruta que seguirá el paquete hasta su destino.
- A continuación, vuelve a intentarlo enviando de nuevo un ICMP Echo al destino, esta vez con un TTL=2.
- El paquete pasa por el primer enrutador, que transforma su TTL en 1 y lo envía a la red apropiada.
- El segundo enrutador detecta que debe encaminar el paquete y éste tiene un TTL=1 y al decrementarlo será cero, por lo que lo descarta, enviando de vuelta el mensaje "time exceed" al emisor original.
- Desde el origen, a la recepción de este mensaje ICMP, se almacena su remitente como segundo punto de la ruta.
- Y así sucesivamente, se realizan envíos con TTL=3, 4, ... hasta llegar al destino, momento en el que recibiremos la respuesta a la solicitud de eco enviada (un mensaje de tipo ICMP Echo Reply), o hasta superar el número máximo de saltos que se haya indicado (por ejemplo, usando la opción
tracert -h Nen Windows)
Función Trace(DEST)
Inicio
ttl = 1
Hacer
Enviar ICMP_ECHO_REQUEST al host DEST con TTL=ttl
Si recibimos un TIME_EXCEED desde el host X,
o bien recibimos un ICMP_ECHO_REPLY desde X, entonces
El host X forma parte de la ruta
Fin
Incrementa ttl
Mientras Respuesta <> ICMP_ECHO_REPLY Y ttl<MAXIMO
FinPublicado en: www.variablenotfound.com.
jueves, 16 de octubre de 2008
 Tras cinco previews, unas más oficiales y otras menos, por fin se ha publicado la primera Beta del framework ASP.NET MVC.
Tras cinco previews, unas más oficiales y otras menos, por fin se ha publicado la primera Beta del framework ASP.NET MVC.En un primer vistazo, parece haber pocas novedades importantes respecto a la Preview 5. Además de la corrección de bugs, el documento de notas de la revisión nos indica los siguientes cambios:
- Cambios en mensajes de validadores para hacerlos más amigables... en inglés, claro.
- Renombrado de algunos componentes, como
CompositeViewEngine - Nuevas propiedades que facilitan la composición de URLs desde los controladores.
- Creación de varias clases para permitir implementaciones personalizadas, como
ActionNameSelectorAttribute. - Adición de algunos métodos a clases existentes,
IViewEngine.ReleaseView. - Renombrado de métodos existentes (
ControllerBuilder.DisposeController) - Cambios de ubicación de la mayoría de métodos de la clase
HtmlHelper, que pasan a ser ahora extensiones de dicha clase. - Cambio del Model Binder por defecto.
- Adición de una enumeración con los verbos HTTP más comunes, para usarla en el atributo
AcceptVerbsAttribute. - Cambio en el método helper
RadioButtonpara permitir el envío de su valor. - Se han actualizado las plantillas de proyectos para VS2008.
- Se ha modificado la forma de seleccionar las acciones a ejecutar, de forma que si dos acciones encajan para ejecutar una petición, aquella que tenga definido un atributo heredando
ActionMethodSelectorAttribute, será la invocada. - Añadida una sobrecarga para
ViewDataDictionary.Eval. - Eliminada la propiedad
ViewNamede la claseViewContext. - Se ha añadido un interface
IValueProvidery una implementación por defecto enDefaultValueProvider.
 Está claro que el objetivo no ha sido ya la adición de nuevas funcionalidades, sino el testeo y revisión en profundidad de las características desarrolladas hasta el momento, que no son pocas.
Está claro que el objetivo no ha sido ya la adición de nuevas funcionalidades, sino el testeo y revisión en profundidad de las características desarrolladas hasta el momento, que no son pocas.Por cierto, y esto sí que representa la materialización de un giro en la política de Microsoft, algo que había comentado por aquí hace unas semanas... ¡ya viene con la librería jQuery incluida en las plantillas de Visual Studio! ASP.NET MVC es, por tanto, el primer producto de la casa que incluye de serie este software, tal y como había comentado Haack poco después de difundirse la noticia.
La instalación, como viene siendo costumbre, resulta de lo más sencilla; el típico siguiente-siguiente-siguiente-finalizar. Eso sí, es conveniente antes de comenzarla desinstalar las versiones anteriores, las previews, en caso de que las tengáis en vuestro equipo.
Publicado en: www.variablenotfound.com.
lunes, 13 de octubre de 2008
 Me ha parecido muy interesante y divertido el post de Kevin Pang, "Top 10 Things That Annoy Programmers", en el que obtiene los factores más irritantes para los desarrolladores combinando su propia experiencia con los resultados de una pregunta realizada en StackOverflow, la famosa comunidad de desarrolladores promovida por los populares Joel Spolsky y Jeff Atwood.
Me ha parecido muy interesante y divertido el post de Kevin Pang, "Top 10 Things That Annoy Programmers", en el que obtiene los factores más irritantes para los desarrolladores combinando su propia experiencia con los resultados de una pregunta realizada en StackOverflow, la famosa comunidad de desarrolladores promovida por los populares Joel Spolsky y Jeff Atwood.Además de estar casi totalmente de acuerdo con los puntos expuestos en su post, que enumero y comento a continuación, añadiré algunos más de propia cosecha de agentes irritantes.
- 10. Comentarios que explican el "cómo" y no el "qué". Tan importante es incluir comentarios en el código como hacerlo bien. Es terrible encontrar comentarios que son una simple traducción literal al español del código fuente, pues no aportan información extra, en lugar de una explicación de lo que se pretende hacer. Muy bueno el ejemplo de Kevin en el post original... ¿eres capaz de decir qué hace este código, por muy comentado que esté?
r = n / 2; // Set r to n divided by 2
// Loop while r - (n/r) is greater than t
while ( abs( r - (n/r) ) > t ) {
r = 0.5 * ( r + (n/r) ); // Set r to half of r + (n/r)
} - 9. Las interrupciones. Sin duda, el trabajo de desarrollador requiere concentración y continuidad, y las interrupciones son las grandes enemigas de estos dos aspectos. Una jornada de trabajo llena de llamadas, mensajes o consultas de clientes, proveedores, jefes o compañeros puede resultar realmente frustrante, a la vez que la distracción que introduce suele ser una fuente importante de errores en las aplicaciones.
- 8. Ampliación del ámbito. Una auténtica pesadilla, sobre todo cuando se produce durante el desarrollo, consistente en el aumento desproporcionado del alcance de determinadas funcionalidades o características del software a crear. Es especialmente desmotivador si, además, no viene acompañado por el aumento del tiempo o recursos necesarios para su realización.
Kevin incluye en su artículo un ejemplo, algo exagerado pero ilustrativo, de sucesivas ampliaciones de ámbito que convierten un requisito factible en un infierno para el desarrollador; seguro que os recuerda algún caso que habéis sufrido en vuestras propias carnes:- Versión 1: Mostrar un mapa de localización
-- Bah, fácil, sólo tengo que crear una imagen; incluso puedo basarme en algún mapa existente que encuentre por ahí - Versión 2: Mostrar un mapa 3D de localización
-- Uff, esto ya no es lo que hablamos; tendré que currarme bastante más el diseño, y ya no será tan fácil partir de alguno existente... - Versión 3: Mostrar un mapa 3D de localización, por el que el usuario pueda desplazarse volando
-- ¡!
- Versión 1: Mostrar un mapa de localización
- 7. Gestores que no entienden de programación. Otro motivo común de irritación entre los desarrolladores es la incapacidad de gestores para comprender las particularidades de la industria del software en la que trabajan. Este desconocimiento genera problemas de todo tipo en una empresa y suponen un estrés terrible para el desarrollador.
- 6. Documentar nuestras aplicaciones. Lamentablemente, en nuestro trabajo no todo es desarrollar utilizando lenguajes y tecnologías que nos divierten mucho. Una vez terminado un producto es necesario crear guías, manuales y, en general, documentación destinada al usuario final que, admitámoslo, nos fastidia bastante escribir.
- 5. Aplicaciones sin documentación. A pesar de que entendamos y compartamos el punto anterior, también nos fastidia enormemente tener que trabajar con componentes o librerías partiendo de una documentación escasa o nula. Si lo habéis sufrido, entenderéis lo desesperante que resulta ir aprendiendo el significado de las funciones de un API usando el método de prueba y error.
- 4. Hardware. Especialmente los errores de hardware que el usuario percibe como un fallo de la aplicación son normalmente muy difíciles de detectar: fallos de red, discos, problemas en la memoria... por desgracia, hay un amplio abanico de opciones. Y lo peor es que por ser desarrolladores de software se nos presupone el dominio y control absoluto en asuntos hardware, lo que no siempre es así.
- 3. Imprecisiones. Aunque Kevin lo orienta al soporte al usuario, el concepto es igualmente molesto en fases de diseño y desarrollo del software. Las descripciones vagas y confusas son una causa segura de problemas, sea en el momento que sea.
Son irritantes las especificaciones imprecisas, del tipo "esta calculadora permitirá al usuario realizar sumas, restas, multiplicaciones y otras operaciones"... ¿qué operaciones? ¿divisiones? ¿resolver ecuaciones diferenciales?
Tampoco es fácil encajar un mensaje de un usuario tal que "me falla el ERP, arréglalo pronto"... A ver. El ERP tiene cientos de módulos, ¿fallan todos? ¿podríamos ser más concretos? - 2. Otros programadores. Como comenta Kevin, el malestar que provoca a veces la relación entre programadores bien merecería un post independiente, pero ha adelantado aspectos que, en su opinión, hace que a veces el trato con los compañeros sea insoportable:
- Personalidad gruñona, hostilidad
- Problemas para comprender que hay que dejar de debatir la arquitectura del sistema y pasar a realizar las tareas
- Falta de habilidad para mantener una comunicación efectiva
- Falta de empuje
- Apatía hacia el código y el proyecto
- 1. Tu propio código, 6 meses después. Sí, es frustrante estar delante de un código aberrante y darte cuenta de que tú eres el autor de semejante desastre. Y tras ello llega la fase de flagelación: ¿en qué estaba pensando cuando hice esto? ¿cómo fui tan estúpido? uff...
Este hecho, sin embargo, forma parte de la evolución tecnológica, personal y profesional; todos estos factores están en continuo cambio, lo que hace que nuestra forma de atacar los problemas sea distinta casi cada día.
 Y hasta aquí la lista de Kevin en su post, ni que decir tiene que comparto sus reflexiones en la mayoría de los puntos. Por mi parte, añadiría los siguientes agentes irritantes que conozco por experiencia propia o de conocidos:
Y hasta aquí la lista de Kevin en su post, ni que decir tiene que comparto sus reflexiones en la mayoría de los puntos. Por mi parte, añadiría los siguientes agentes irritantes que conozco por experiencia propia o de conocidos:- Extra 1. Requisitos evolutivos, como una ampliación del ámbito del punto 8 ;-), que son aquellos que van cambiando conforme el desarrollo avanza y que obligan a realizar refactorizaciones, descartar código escrito, e introducir peligrosas modificaciones, afectando a veces por debajo de la línea de flotación del software. Más rabia produce, además, cuando se atribuyen una mala interpretación por parte del desarrollador de una especificación imprecisa.
- Extra 2. Problemas en el entorno. Nada más frustrante que cortes en el suministro eléctrico, cuelgues, problemas en el hardware, lentitud en los equipos de trabajo o de acceso a información... a veces parece que tenemos que construir software luchando contra los elementos.
- Extra 3. El "experto" en desarrollo de software. Clientes, gestores y otros individuos que utilizan frecuentemente, y sin conocimiento alguno de causa, expresiones como "Esto es fácil", "Una cosa muy sencilla", "¿Eso vas a tardar en hacer esta tontería?".... A veces no es fácil hacer entender que la percepción externa de la complejidad es absolutamente irreal, y suele ser una causa frecuente de desesperación para los desarrolladores.
- Extra 4. Usuarios corrosivos, que lejos de colaborar durante el desarrollo o la implantación de un sistema, aprovechan la ocasión para arremeter contra la aplicación, organización, jefes, compañeros, el gobierno, o lo que se ponga por delante. Es de justicia decir que muchas veces este comportamiento es debido a una mala gestión interna del proyecto, pero desde el punto de vista del profesional del sofware que sólo quiere realizar lo mejor posible su trabajo son una auténtica pesadilla.
En fin, que ya a estas alturas es fácil ver que hay bastantes cosas que fastidian a los desarrolladores, y seguro que podríamos añadir muchas más; algunas son evitables, otras son inherentes a la profesión y hay que aprender a convivir con ellas, pero en cualquier caso son un interesante motivo de reflexión.
¿Y a tí, qué es lo que más te fastidia?
Enlace: Top 10 Things That Annoy Programmers
Publicado en: www.variablenotfound.com.
martes, 7 de octubre de 2008
 A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.
A veces puede resultar interesante acceder desde una página de contenidos a propiedades de su página maestra. Hoy he encontrado un truco para conseguir este acceso con la seguridad que proporciona un tipado fuerte.Como sabemos, la propiedad
Master de las páginas de contenidos, a través de la cual es posible acceder a la página maestra, es por defecto del tipo MasterPage. Esto es así porque todas las masters que creamos heredan de esta clase, y es una abstracción bastante acertada la mayoría de las veces. De hecho, es perfectamente posible hacer un cast al tipo correcto desde el código de la página para acceder a alguna de las propiedades públicas que le hayamos definido, así:
protected void Page_Load(object sender, EventArgs e)
{
MaestraContenidos master = Master as MaestraContenidos;
master.Titulo = "Título";
}
Pues bien, mediante la directiva de página
MasterType es posible indicar de qué tipo será esta propiedad Master, de forma que no será necesario hacer el cast. En la práctica, en el ejemplo anterior, podríamos hacer directamente Master.Titulo="Título", sin realizar la conversión previa.La directiva podemos utilizarla en el archivo .ASPX, haciendo referencia al archivo donde está definida la página maestra cuyo tipo usaremos para la propiedad:
<%@ MasterType VirtualPath="~/site1.master" %>
O también podemos hacerlo indicando directamente el tipo (ojo, que hay que incluirlo con su espacio de nombres completo):
<%@ MasterType TypeName="ProyectoWeb.MaestraContenidos" %>
Por último, algunas contraindicaciones. Si váis a usar esta técnica, tened en cuenta que:
- si decidís cambiar la página maestra en tiempo de ejecución, en cuanto intentéis acceder a la propiedad Master, vuestra aplicación reventará debido a que el tipo no es el correcto.
- si cambiáis la maestra a la que está asociada una página de contenidos, tenéis que acordaros de cambiar también la directiva
MasterTypede la misma para que todo funcione bien.
Publicado en: www.variablenotfound.com.
domingo, 5 de octubre de 2008
Una prueba más de que los algoritmos de Google son inescrutables...

¡Gracias, Javi!
Publicado en: www.variablenotfound.com.

¡Gracias, Javi!
Publicado en: www.variablenotfound.com.
lunes, 29 de septiembre de 2008
 Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.
Ya lo comentaban Rodrigo Corral y algún otro amigo en geeks.ms después de leer el post sobre formas efectivas de ofuscar emails en páginas web: el siguiente paso era "empaquetar" en forma de componente las técnicas que, según se recogía en el post, eran las más seguras a la hora de ocultar las direcciones de correo de los spammers.Recapitulando, las técnicas de camuflaje de emails que habían aguantado el año y medio del experimento de Silvan Mühlemann, y por tanto se entendían más seguras que el resto de las empleadas en el mismo, fueron:
- Escribir la dirección al revés en el código fuente y cambiar desde CSS la dirección de presentación del texto.
- Introducir texto incorrecto en la dirección y ocultarlo después utilizando CSS.
- Generar el enlace desde javascript partiendo de una cadena codificada en ROT13.
En tiempo de ejecución, el control es capaz de generar código javascript que escribe en la página un enlace
mailto: completo, partiendo de una cadena previamente codificada creada desde el servidor. Dado que todavía no está generalizado entre los spambots la ejecución de javascript de las páginas debido al tiempo y capacidad de proceso necesario para realizarlo, podríamos considerar que esta es la opción más segura. Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.
Para codificar los textos en principio iba a utilizar ROT-13, pero ya que estaba en faena pensé que quizás sería mejor aplicar una componente aleatoria al algoritmo, por lo que al final implementé un ROT-N, siendo N asignado por el sistema cada vez que se genera el script.Pero, ah, malditos posyaques... la verdad es que con un poco de refactorización era posible generalizar el procedimiento de codificación y decodificación mediante el uso de clases específicas (Codecs), así que me puse manos a la obra. Liame incluye, de serie, cuatro algoritmos distintos de ofuscación para ilustrar sus posibilidades: ROT-N (el usado por defecto y más recomendable), Base64, codificación hexadecimal, y un codec nulo, que me ha sido muy útil para depurar y usar como punto de partida en la creación de nuevas formas de camuflaje. Algunos, además, aleatorizan los de nombres de funciones y variables para hacer que el código generado sea ligeramente distinto cada vez, de forma que un spammer no pueda romperlo por una simple localización de cadenas en posiciones determinadas; en fin, puede que sea una técnica un poco inocente, pero supongo que cualquier detalle que dificulte aunque sea mínimamente la tarea de los rastreadores, bueno será.
Incluso si así lo deseamos podremos generar, además del javascript de decodificación del enlace, el contenido de la etiqueta
<noscript>, en la que se incluirá el código HTML de la dirección a ocultar utilizando los dos trucos CSS descritos anteriormente y también considerados "seguros" por el experimento. De esta forma, aunque no estará disponible el enlace para este grupo de usuarios, podrán visualizar la dirección a la que podrán remitir sus mensajes. El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.
El control Liame es muy sencillo de utilizar. Una vez agregado a la barra de herramientas, bastará con arrastrarlo sobre la página (de contenidos o maestra) y establecer sus propiedades, como mínimo la dirección de email a ocultar. Opcionalmente, se puede añadir un mensaje para el enlace, su título, la clase CSS del mismo, etc., con objeto de personalizar aún más su comportamiento a la hora de generar el script, así como las técnicas CSS a utilizar como alternativa.Sin embargo, aún quedaba una cosa pendiente. El control de servidor está bien siempre usemos ASP.NET y que el rendimiento no sea un factor clave, puesto que al fin y al cabo estamos cargando de trabajo al servidor. Para el resto de los casos, Liame incluye en el proyecto de demostración un generador de javascript que, partiendo de los parámetros que le indiquemos, nos creará un script listo para copiar y pegar en nuestras páginas (X)HTML, PHP, Java, o lo que queramos. Como utiliza la base de Liame, cada script que generamos será distinto al anterior.
He publicado el proyecto en Google Code, desde donde se puede descargar tanto el ensamblado compilado como el código fuente del componente y del sitio de demostración. Esta vez he elegido la licencia BSD, no sé, por ir probando ;-)
La versión actual todavía tiene algunos detallitos por perfilar, como el control de la entrada en las propiedades (en especial las comillas y caracteres raros: ¡mejor que nos los uséis!), que podría dar lugar a un javascript sintácticamente incorrecto, pero en general creo que se trata de una versión muy estable. Ha sido probada con Internet Explorer 7, Firefox 3 y Chrome, los tres navegadores que tengo instalados.
También, por cortesía de Mergia, he colgado un proyecto de demostración para que pueda verse el funcionamiento en vivo y en directo, tanto del control de servidor como del generador de javascript.

Finalmente, algunos aspectos que creo interesante comentar. En primer lugar, me gustaría recordaros que las técnicas empleadas por Liame no aseguran, ni mucho menos, que los emails de las páginas van a estar a salvo de los del lado oscuro eternamente, aunque de momento así sea. Lo mejor es no confiarse.
En segundo lugar, es importante tener claro que todas las técnicas aquí descritas pueden resultar bastante nocivas para la accesibilidad de las páginas en las que las utilicéis. Tenedlo en cuenta, sobre todo, si tenéis requisitos estrictos en este sentido.
Y por último, añadir que estaré encantado de recibir vuestras aportaciones, sugerencias, colaboraciones o comentarios de cualquier tipo (sin insultar, eh?) que puedan ayudar a mejorar este software.
Enlaces
Publicado en: www.variablenotfound.com.
domingo, 28 de septiembre de 2008
Esto se traduce, en primer lugar, en que será distribuida con Visual Studio, pero eso sí, tal cual, sin modificaciones ni aditivos que puedan suponer la separación de las versiones oficiales de jQuery. Por ejemplo, ASP.NET MVC incluirá de serie la librería en las plantillas de los nuevos proyectos.
Pero no acaban ahí los compromisos. También facilitarán versiones con anotaciones que permitirán disfrutar totalmente de la experiencia intellisense mientras trabajemos con ella, que según comentan estará disponible como una descarga gratuita independiente en unas semanas. Incluso el soporte 24x7 para desarrolladores podrán abrir cuestiones relacionadas con esta librería.
Asimismo, se pretende darle uso para la implementación de controles para el ASP.NET AJAX Control Toolkit, para la construcción de helpers para el framework MVC, y, en general, integrarla con todas las nuevas características y desarrollos que vayan apareciendo.
Buena noticia, sin duda... :-)
Publicado en: www.variablenotfound.com.
martes, 23 de septiembre de 2008
 Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.
Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.Las demostraciones de este motor son ejecutables, por lo que hay que descargarlas y ejecutarlas en el equipo local. Si utilizáis Windows, os recomiendo echar un vistazo al paquete de demostraciones [~3MB], con el que se puede comprobar la potencia de la librería. No es necesario instalar nada, sólo descomprimir el contenido en una carpeta y ejecutar la demo.
La revisión actual, 2.71 se publicó hace tan sólo unos días. El código fuente del proyecto está alojado en Google Code, y su modelo de licencia (MIT) permite su utilización en proyectos comerciales.
Y por cierto, existe un port para Java, jBullet, cuyas demostraciones pueden descargarse y ejecutarse a través de Java Webstart, por lo que resulta mucho más cómodo. Incluso aunque el rendimiento es muy inferior al real al usar renderizado por software, puede ejecutarse en un applet, que incrusto a continuación.
Debéis elegir una demo en el desplegable (hay cinco disponibles, os recomiendo que comencéis por la primera), en las que podéis usar las teclas "Z" y "X" para acercaros y alejaros de la escena, las flechas de dirección para girar, y con el ratón podéis aplicar impulsos a los cubos (arrastrando con el botón izquierdo) y lanzar cubos (con el bótón derecho).
Como observaréis, dentro del mismo applet aparecen instrucciones de otras teclas, incluso algunas para demos concretas. Especialmente interesante e improductivo es lanzarle piezas al cubo gigante (basic demo), intentar hacer caminar la araña (dynamic control demo), o dedicarse a transportar mesas de un lado a otro con una carretilla (forklift demo).
Que lo disfrutéis.
Publicado en: www.variablenotfound.com.
domingo, 21 de septiembre de 2008
 Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.
Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.Lo que no conocía era la posibilidad de establecerlos por código desde la propia aplicación que estamos depurando, que puede resultar útil en momentos en que nos sea incómodo crearlos desde el entorno de desarrollo. Es tan sencillo como incluir el siguiente fragmento en el punto donde deseemos que la ejecución de detenga y salte el entorno:
// C#
if (System.Diagnostics.Debugger.IsAttached)
{
System.Diagnostics.Debugger.Break();
}
' VB.NET:
If System.Diagnostics.Debugger.IsAttached Then
System.Diagnostics.Debugger.Break()
End If
Como ya habréis adivinado, el
if lo único que hace es asegurar que la aplicación se esté ejecutando enlazada a un depurador, o lo que es lo mismo, desde dentro del entorno de desarrollo; si se ejecuta fuera del IDE no ocurrirá nada.Si eliminamos esta protección, la llamada a
Debugger.Break() desde fuera del entorno generará un cuadro de diálogo que dará la oportunidad al usuario de abrir el depurador:
De todas formas lo mejor es usarlo con precaución, que eso de dejar el código con residuos de la depuración no parece muy elegante...
Publicado en: www.variablenotfound.com.
lunes, 15 de septiembre de 2008
 Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como "las cinco fases del duelo".
Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como "las cinco fases del duelo".El genial Kevin Pang ha publicado un divertido artículo en Datamation, Debugging and The Five Stages of Grief, utilizándolas para describir los sentimientos del desarrollador ante la aparición de un bug en su aplicación:
- Negación. En esta fase, ante el descubrimiento de un posible fallo, nos ponemos en actitud defensiva e intentamos echarle la culpa a todo menos a nuestros desarrollos. Nosotros no fallamos nunca... ¿o tal vez sí?
- Ira. Acto seguido, una vez demostrado que existe un problema, comienzan los bufidos, resoplidos y voces airadas del tipo ¿cómo no se ha detectado esto antes?, ¡vaya mierda de aplicación!, o ¡¡joder, justo ahora, con lo ocupado que estoy!!
- Negociación. Vale, asumimos que hay un error y ya hemos despotricado durante un rato. El siguiente paso es negociar (habitualmente con nosotros mismos) sobre el tipo de solución a dar: ¿apuntalamos lo suficiente como para que siga funcionando, u optamos por solucionar de forma definitiva el problema? Difícil decisión a veces.
- Depresión. Ahora lo que toca es la depresiva tarea de la depuración. A nadie le gusta escudriñar en el código en busca de un error, ¡hemos nacido para crear software espectacular, no para corregirlo! Es un buen momento para compadecernos de nosotros mismos.
- Aceptación. Hemos asimilado la realidad de que nuestro código falla, hemos maldecido la situación, decidido que vamos a corregirlo como auténticos profesionales, e incluso hemos llorado un rato sobre nuestra mala suerte. Sin embargo, esto es así y hay que aceptarlo, forma parte de la pesada mochila que los desarrolladores llevamos a las espaldas. Eso sí, sólo otro desarrollador puede entenderlo, no intentes explicárselo a tu esposa, madre, jefe, o vecino.
Si tienes un rato, no te pierdas el artículo original.
Publicado en: www.variablenotfound.com.
domingo, 14 de septiembre de 2008
Hace unos días, el nueve de septiembre, se cumplían 61 años desde la primera aparición "documentada" de un bug informático. Y como en todos los cumpleaños, ahí va la foto del protagonista, literalmente:

Se trata de la polilla que provocó problemas de funcionamento en el primitivo ordenador Mark II el martes 9 de septiembre de 1947, al colarse y quedarse atrapada en el relé número 70 del Panel F (que debe venir a ser algo así como la línea X del archivo Y del código fuente de los de ahora). La incidencia fue reflejada en el cuaderno de bitácora (log) del sistema, al que pertenece la fotografía superior, adjuntando el insecto como prueba del delito.
El término "bug" ya se utilizaba entonces como sinónimo de error en otros ámbitos, como en telegrafía, telefonía o sistemas eléctricos, de ahí la frase que registró el operador debajo del animalito, haciendo referencia a que era la primera vez que se encontraba un auténtico bug (=bicho):
Fuente: The first computer bug
Publicado en: www.variablenotfound.com.

Se trata de la polilla que provocó problemas de funcionamento en el primitivo ordenador Mark II el martes 9 de septiembre de 1947, al colarse y quedarse atrapada en el relé número 70 del Panel F (que debe venir a ser algo así como la línea X del archivo Y del código fuente de los de ahora). La incidencia fue reflejada en el cuaderno de bitácora (log) del sistema, al que pertenece la fotografía superior, adjuntando el insecto como prueba del delito.
El término "bug" ya se utilizaba entonces como sinónimo de error en otros ámbitos, como en telegrafía, telefonía o sistemas eléctricos, de ahí la frase que registró el operador debajo del animalito, haciendo referencia a que era la primera vez que se encontraba un auténtico bug (=bicho):
"First actual case of bug being found"
Fuente: The first computer bug
Publicado en: www.variablenotfound.com.
miércoles, 10 de septiembre de 2008
 Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href="mailto:user@myserver.xx">email me</a> - Sustituyendo las arrobas por "AT" y los puntos por "DOT", de forma que una dirección queda de la forma:
<a href="mailto:userATserverDOTxx">email me</a> - Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href="mailto:user@server.xx">email me</a> - Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href="mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65">email me</a> - Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!-- -->@<!--- @ -->my<!-- -->server.<!--- . -->com - Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = "user";
var string2 = "@";
var string3 = "myserver.xx";
var string4 = string1 + string2 + string3;
document.write("<a href=" + "mail" + "to:" + string1 +
string2 + string3 + ">" + string4 + "</a>"); - Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type="text/css">
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class="codedirection">moc.revresym@resu</span> - Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type="text/css">
span.displaynone { display:none; }
</style>
Email me: user@<span class="displaynone">goaway</span>myserver.net - Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type="text/javascript">
document.write('<n uers=\"znvygb:fvyinasbbone10@gvyyyngr.pbz\" ery=\"absbyybj\">'.replace(/[a-zA-Z]/g, function(c){return String.fromCharCode((c<="Z"?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar's Mail</a>
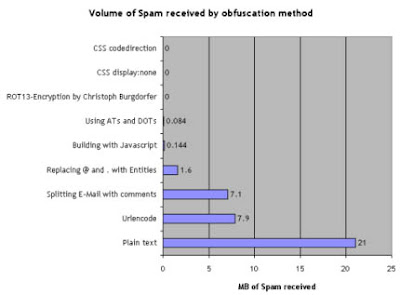 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces
mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href="mailto:loquesea">, incluidos los caracteres de inicio "<" y fin ">", pero sin introducir el texto del enlace ni el cierre </a> de la misma).También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace
mailto: completo en nuestras páginas.Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de "AT" y "DOT", o equivalentes en nuestro idioma como "EN" y "PUNTO", con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como "juanARROBICAservidorPUNTICOcom", o "juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom". Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Editado (03/10): Liame es un componente de código abierto para ASP.NET que genera direcciones de email ofuscadas con las técnicas descritas en este artículo. Y si no usas ASP.NET, también puedes generar código javascript listo para insertarlo en tus páginas.
Publicado en: www.variablenotfound.com.
domingo, 7 de septiembre de 2008
 A finales de Agosto se publicó en Codeplex, como viene siendo habitual, los instalables y código fuente de la quinta preview del framework MVC para ASP.NET en el que Microsoft lleva trabajando desde el año pasado y del que ya hemos hablado en varias ocasiones por aquí.
A finales de Agosto se publicó en Codeplex, como viene siendo habitual, los instalables y código fuente de la quinta preview del framework MVC para ASP.NET en el que Microsoft lleva trabajando desde el año pasado y del que ya hemos hablado en varias ocasiones por aquí.Muchas son las novedades que han introducido esta vez, y algunas realmente muy esperadas, como el sistema de validaciones de datos en formularios, nuevos atributos de nombrado y filtrado de acciones, o los ModelBinders, el mecanismo que permite utilizar parámetros de tipos complejos (es decir, no nativos) en las acciones de nuestros controladores. Richard Chamorro ha realizado un buen resumen de las novedades y cambios de esta entrega respecto a la preview 4, en las que ya iremos profundizando.
Y a propósito de la Preview 4, también introdujo bastantes novedades respecto a la anterior: nuevos atributos de filtros de ejecución de acciones y captura de errores de ejecución, control sobre el cacheado de respuestas, algunos helpers básicos destinados al intercambio de datos usando Microsoft Ajax, cambios en las plantillas para Visual Studio introduciendo controladores y vistas para un sistema simple de autenticación de usuarios y gestión de errores, y otras mejoras. Sin embargo, debido al cierre por vacaciones de Variable not found y a la aparición de la preview 5 no he tenido tiempo para ir revisándolas; ya iré comentando los que me resulten especialmente interesantes.
Por último, según indica el gran Phil Haack en su post "ASP.NET MVC Codeplex preview 5 released", no entra en sus planes que haya más previews. Lo próximo que tendremos entre las manos será ya una versión Beta, muy cercana al producto final que podremos disfrutar sobre finales de año ("en un mes que acabe en -bre", como bromeó hace poco Scott Hanselman). Eso sí, supongo que antes pasaremos por varias betas e incluso alguna versión candidata.
Parece que tenemos unos meses divertidos por delante...
Publicado en: www.variablenotfound.com.
martes, 2 de septiembre de 2008
 Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.
Utilizando apropiadamente (X)HTML y hojas de estilo CSS, se pueden conseguir un montón de efectos interesantes para nuestras webs, como la inclusión de imágenes de fondo en cuadros de texto de formularios que vimos hace algún tiempo. Hoy vamos a ver lo fácil que resulta destacar enlaces (links) a páginas en idiomas distintos al nuestro de forma muy gráfica, colocando a su lado una banderilla que indique la lengua de destino, sin apenas introducir código adicional.Para lograrlo, necesitamos solucionar dos problemas. El primero es cómo indicar en los enlaces (dentro de la etiqueta
<a> de nuestro código X/HTML) el idioma de la página a la que saltará el usuario; el segundo problema es el describir en la hoja de estilos (CSS) estos enlaces, de forma que se representen con la banderita correspondiente. Ambos tienen fácil solución gracias a los estándares de la W3C.Hace ya bastantes años, el estándar HTML definió el atributo
hreflang en los hipervínculos con objeto de indicar el idioma del recurso apuntado por el atributo href. En otras palabras, si estamos apuntando a una página debería contener el idioma de la misma, justo lo que necesitamos: <a href="http://www.csszengarden.com" hreflang="en">CSS Zen Garden</a>Por otra parte, el estándar CSS 2.1 define un gran número de selectores que podemos utilizar para identificar los elementos de nuestra página a los que queremos aplicar las reglas de estilo especificadas. El que nos interesa para lograr nuestro objetivo es el llamado selector de atributos, que aplicado a una etiqueta permite filtrar los elementos que presenten un valor concreto asociado a un atributo de la misma.
Así, en el siguiente código, que debemos incluir en la hoja de estilos del sitio web, buscamos los enlaces cuya página de destino sea en inglés (su
hreflag comience por "en"), introduciendo el efecto deseado:a[hreflang="en"]
{
padding-right: 19px;
background-image: url(img/bandera_ing.jpg);
background-position: right center;
background-repeat: no-repeat;
}
Observad que el
padding-right deja un espacio a la derecha del enlace con la anchura suficiente como para que se pueda ver la imagen de fondo, la banderilla, que aparecerá allí gracias a su alineación horizontal a la derecha definida con el background-position.Y, ahora sí, podemos recomendar visitas a páginas en inglés como CSS Zen Garden con fundamento.
Ah, un último detalle. Aunque hoy en día los navegadores tienden cada vez más a respetar los estándares, es posible que encontréis alguno con el que no funcione bien esta técnica principalmente por no soportar el selector de atributos (por ejemplo IE6 y anteriores, afortunadamente cada vez menos usados).
Publicado en: www.variablenotfound.com.
lunes, 1 de septiembre de 2008
 Pues sí, era sólo hace un
Pues sí, era sólo hace un Pero, como siempre, todo lo bueno se acaba y aquí estamos de nuevo, sin indicios de síndrome postvacacional, con las pilas bien cargadas y listos para iniciar una nueva temporada en Variable Not Found, donde espero contar, como hasta ahora, con vuestra participación y apoyo.
Gracias por seguir por aquí. Nos vemos pronto.
Publicado en: www.variablenotfound.com.
viernes, 1 de agosto de 2008
 Afortunadamente llegaron, un año más, las ansiadas vacaciones. Esta vez además he tenido una suerte especial, pues me voy luciendo un tipo espléndido por cortesía de una magnífica intoxicación alimentaria, concretamente Salmonelosis, que me ha tenido fuera de juego prácticamente una semana.
Afortunadamente llegaron, un año más, las ansiadas vacaciones. Esta vez además he tenido una suerte especial, pues me voy luciendo un tipo espléndido por cortesía de una magnífica intoxicación alimentaria, concretamente Salmonelosis, que me ha tenido fuera de juego prácticamente una semana.Pero reponerse es fácil si se tienen buenos planes para este mes de Agosto, como es el caso. Comenzaremos con unos días en Sanlúcar de Barrameda, localidad que ya nos fascinó cuando la conocimos el año pasado.
También vamos a poder disfrutar de un viaje familiar al paraíso canario, y más concretamente al Puerto de la Cruz, en Tenerife, donde esperamos pasárnoslo en grande.
Y entre una cosa y otra, paraditas en casa para descansar, y quizás alguna visita a playas de Huelva. No nos podemos quejar, desde luego.
Variable not found, como siempre por esta fecha, quedará a la deriva hasta primeros de Septiembre, momento en el que volveré a retomarlo todo con la energía convenientemente renovada.
Ah, voy a desactivar temporalmente los comentarios anónimos, para evitar que los spammers se ceben con el blog. Siento las molestias que pueda causar a los que sólo quieren dejar sus impresiones o cuestiones anotadas por aquí.
Feliz verano, amigos.
Publicado en: www.variablenotfound.com.
miércoles, 23 de julio de 2008
 Y es que va a ser verdad eso de que en internet hay de todo. No sé que estaba buscando cuando me he topado con FakeNameGenerator, una web en la que indicando el sexo, la nacionalidad y el idioma a utilizar nos genera una ficha personal completa, con datos aleatorios, como la siguiente:
Y es que va a ser verdad eso de que en internet hay de todo. No sé que estaba buscando cuando me he topado con FakeNameGenerator, una web en la que indicando el sexo, la nacionalidad y el idioma a utilizar nos genera una ficha personal completa, con datos aleatorios, como la siguiente:
Benicio Romero Santacruz
Padre Caro, 61
13592 Mestanza
Email Address: BenicioRomeroSantacruz@fontdrift.com
This is a real email address. Click here to use it!
Website: Demimba.com
It looks like Demimba.com is available! Click here to register it!
Birthday: June 17, 1980
Visa: 4929 7908 0245 3619
Expires: 6/2011
UPS Tracking Number: 1Z F00 647 14 8092 598 8
Como podéis ver, incluye un nombre, la dirección una cuenta de correo (tipo Mailinator) que podéis usar para recibir mensajes simplemente pulsando el enlace mostrado, fecha de nacimiento, datos de una tarjeta VISA (no válidos, claro), y un código de seguimiento de UPS.
Puedes generar tu identidad española siguiendo este enlace.
En fin, que no es algo especialmente útil, pero curioso lo es un rato...
Publicado en: http://www.variablenotfound.com/.
domingo, 20 de julio de 2008
 El hecho de que las acciones de los controladores de ASP.NET MVC retornen ActionResults abre un gran abanico de posibilidades para los desarrolladores de sistemas web.
El hecho de que las acciones de los controladores de ASP.NET MVC retornen ActionResults abre un gran abanico de posibilidades para los desarrolladores de sistemas web. Ya comenté en otra ocasión los distintos subtipos de
ActionResult incluidos en el framework, y la posibilidad de crear nuevos descendientes. También tratamos en otro post el retorno de JSON desde los controladores como una potente vía de devolución de datos estructurados a la capa cliente, tras una llamada Ajax.En esta ocasión vamos a profundizar un poco más, creando nuestro propia subclase de
ActionResult para crear acciones con resultados personalizados utilizando la Preview 3 de esta tecnología. Concretamente, crearemos la clase ImageResult, que permitirá a las acciones retornar imágenes JPEG como la mostrada en la siguiente captura:
Como se puede observar, aparece una imagen con la hora actual sobre un fondo degradado, que es generada en tiempo real desde el servidor al producirse una petición desde la vista mediante un tag <img> estándar:
<h3>La hora es:</h3>
<img src='<%= Url.Action("GetImage") %>' />
La llamada al método
Url.Action("GetImage") retorna una cadena con la dirección URL de la acción indicada en el parámetro, en este caso GetImage(). De esta forma, cuando el navegador necesite cargar la imagen para mostrarla, realizará una llamada a dicha acción, cuyo código aparece en el controlador de la siguiente forma: public ImageResult GetImage()
{
return new ImageResult
{
Width = 400,
Height = 100,
Text = DateTime.Now.ToLongTimeString()
};
}
Lo único que hace es retornar un objeto
ImageResult inicializado con el ancho y alto deseado, y el texto a escribir. Fijaos en el uso del inicializador de objetos.Veamos por último con la clase
ImageResult: public class ImageResult: ViewResult
{
public int Width { get; set; }
public int Height { get; set; }
public string Text { get; set; }
public override void ExecuteResult(ControllerContext context)
{
context.HttpContext.Response.ContentType = "image/jpeg";
Rectangle rect = new Rectangle(0, 0, Width, Height);
Bitmap bmp = new Bitmap(rect.Width, rect.Height);
Graphics g = Graphics.FromImage(bmp);
Font font = new Font("Arial", Height / 1.6f);
LinearGradientBrush brush =
new LinearGradientBrush(rect, Color.Blue, Color.Navy, 90f);
g.FillRectangle(brush, rect); // Pinta el degradado...
g.DrawString(Text, font, Brushes.Black, 2, 2); // ... la sombra del texto...
g.DrawString(Text, font, Brushes.White, 0, 0); // ... y el texto.
g.Dispose();
font.Dispose();
brush.Dispose();
bmp.Save(context.HttpContext.Response.OutputStream, ImageFormat.Jpeg);
bmp.Dispose();
}
}
Aparte de la definición de las propiedades necesarias para su funcionamiento, el único truco a la hora de devolver contenidos personalizados es sobrescribir el método
ExecuteResult de la clase base ViewResult. Ya en su implementación, a través del contexto que nos llega como parámetro podemos modificar el tipo de contenidos de la respuesta (Content-Type) y escribir a través del canal de salida lo que deseemos (en este caso utilizamos el método Save del bitmap para ello).El resto del código no tiene demasiado interés, es la creación de la imagen dinámica utilizando GDI+. Por cierto, no he realizado validaciones de las propiedades, os los dejo de deberes ;-); Tampoco sé si tantos Dispose() explícitos serán necesarios, supongo que no, pero me da algo de repelús no ponerlos... debe ser algo así como un trauma infantil adquirido años atrás usando el API de Windows...
 Descargar proyecto (Visual Web Developer 2008 + SP1 + ASP.NET MVC Preview 3).
Descargar proyecto (Visual Web Developer 2008 + SP1 + ASP.NET MVC Preview 3).Publicado en: www.variablenotfound.com.
domingo, 13 de julio de 2008
 Hace unos días Pedro dejaba una consulta en los comentarios del post "Usando ASP.NET Ajax para el intercambio de entidades de datos" sobre un problema que le había surgido a la hora de referenciar desde script, en el lado cliente, una clase propia que utilizaba para intercambiar datos entre éste y el servidor.
Hace unos días Pedro dejaba una consulta en los comentarios del post "Usando ASP.NET Ajax para el intercambio de entidades de datos" sobre un problema que le había surgido a la hora de referenciar desde script, en el lado cliente, una clase propia que utilizaba para intercambiar datos entre éste y el servidor.En dicho post se mostraba la forma en que era posible intercambiar información estructurada con Ajax, definiendo en el servidor una clase propia y viendo cómo el ScriptManager, mágicamente, creaba un proxy (o espejo) en cliente que permitía su manipulación de forma muy cómoda y transparente al otro lado de la red.
De hecho, partíamos de una definición en el servidor así:
public class Mensaje
{
public string Remitente;
public string Destinatario;
public DateTime Fecha;
public int Numero;
}
Y veíamos como desde cliente podíamos manipularla, en javascript, de la siguiente forma:
msg = new Mensaje();
msg.Remitente = $get("nombre").value;
msg.Numero = 1;
msg.Destinatario = "servidor";
msg.Fecha = new Date();
El problema que comentaba este lector es que, a diferencia del ejemplo, su entidad de datos se encontraba definida en un ensamblado y espacio de nombres diferente al del WebMethod que lo utilizaba, lo que provocaba la aparición de un error indicando que su clase no estaba definida.
Aunque al principio sospeché en que podía existir alguna limitación en la seriación JSON de los datos, después de indagar un poco dí con la solución. La lección que he aprendido es:
para usar desde cliente una clase generada de forma automática por el ScriptManager, es necesario referenciarla precedida del namespace en el que se encuentra definidaO en otras palabras, si la clase
Mensaje está definida dentro del espacio de nombres A.B, la referencia en cliente deberá ser: var x = new A.B.Mensaje();Mensaje no incluía su espacio de nombres? Pues debido a que estaba definida en el namespace por defecto del proyecto...¡Gracias, Pedro, por participar en Variable Not Found!
Publicado en: www.variablenotfound.com.
lunes, 7 de julio de 2008
Hace unos días descubrí un portal que considero muy interesante para todos los que estamos intentando seguir de cerca el nuevo framework ASP.NET MVC de Microsoft.
Se trata de un proyecto personal de Dan Hounshell que recopila de forma automática posts, noticias, rumores y vídeos de feeds RSS de diversas fuentes sobre ASP.NET MVC y tecnologías relacionadas. Ah, y todos estos contenidos los ofrece en RSS, por lo que es una fuente ideal para estar al día.

Que aproveche.
Publicado en: www.variablenotfound.com.
Se trata de un proyecto personal de Dan Hounshell que recopila de forma automática posts, noticias, rumores y vídeos de feeds RSS de diversas fuentes sobre ASP.NET MVC y tecnologías relacionadas. Ah, y todos estos contenidos los ofrece en RSS, por lo que es una fuente ideal para estar al día.
Que aproveche.
Publicado en: www.variablenotfound.com.












