
Mostrando entradas con la etiqueta vb.net. Mostrar todas las entradas
Mostrando entradas con la etiqueta vb.net. Mostrar todas las entradas
martes, 28 de octubre de 2008
 Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.
Tanto la guía de programación del lenguaje C# 3.0 como la de Visual Basic .NET 9 hablan de que ambos compiladores pueden agilizar la instanciación de tipos anónimos, permitiendo escribir instrucciones realmente concisas, gracias a su capacidad para deducir los nombres de las propiedades a partir de su contexto. Sin embargo son ese tipo de detalles que, al menos un servidor, había pasado por alto a pesar de haberlo visto utilizado más de una vez.Como sabemos, la creación "normal" de un objeto de tipo anónimo es como sigue, si lo que queremos es inicializar sus propiedades con valores constantes:
// C#
var o = new { Nombre="Juan", Edad=23 };
' VB.NET
Dim o = New With { .Nombre="Juan", .Edad=23 }
Sin embargo, muchas veces vamos a inicializar sus miembros con valores tomados de variables o parámetros visibles en el lugar de la instanciación, por ejemplo:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre=nombre, edad=edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {.nombre = nombre, .edad = edad}
...
End Sub
Pues bien, es justo en estos casos cuando podemos utilizar una sintaxis más compacta, basada en la capacidad de los compiladores de inferir el nombre de las propiedades del tipo anónimo partiendo de los identificadores de las variables que utilicemos en su inicialización. O en otras palabras, el siguiente código es equivalente al anterior:
// C#
public void hacerAlgo(string nombre, int edad)
{
var o = new { nombre, edad };
...
}
' VB.NET
Public Sub HacerAlgo(ByVal nombre As String, _
ByVal edad As Integer)
Dim o = New With {nombre, edad}
...
End Sub
Brad Wilson, un desarrollador del equipo ASP.NET de Microsoft, nos ha recordado hace unos días lo bien que viene este atajo para la instanciación de tipos anónimos utilizados para almacenar diccionarios clave/valor, como los usados en el framework ASP.NET MVC. También es una característica muy utilizada en Linq para el retorno de tipos anónimos que contienen un subconjunto de propiedades de las entidades recuperadas en una consulta.
Publicado en: www.variablenotfound.com.
domingo, 4 de mayo de 2008
 Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.
Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.Como sabemos, si desde una aplicación queremos obtener una descripción comprensible de un elemento de una enumeración, normalmente no podemos realizar una conversión directa (
elemento.ToString()) del mismo, pues obtenemos los nombres de los identificadores usados a nivel de código. La solución habitual, hasta la llegada de C# 3.0 consistía en incluir dentro de alguna clase de utilidad un conversor estático que recibiera como parámetro en elemento de la enumeración y retornara un string, algo así como:
public static string EstadoProyecto2String(EstadoProyecto e)
{
switch (e)
{
case EstadoProyecto.PendienteDeAceptacion:
return "Pendiente de aceptación";
case EstadoProyecto.EnRealizacion:
return "En realización";
case EstadoProyecto.Finalizado:
return "Finalizado";
default:
throw
new ArgumentOutOfRangeException("Error: " + e);
}
}
Este método, sin embargo, presenta algunos inconvenientes. En primer lugar, dado el tipado fuerte del parámetro de entrada del método, es necesario crear una función similar para cada enumeración sobre la que queramos realizar la operación.
También puede resultar peligroso separar la definición de la enumeración del método que transforma sus elementos a cadena de caracteres, puesto que puede perderse la sincronización entre ambos cuando, por ejemplo, se introduzca un nuevo elemento en ella y no se actualice el método con la descripción asociada.
La solución, que como he comentado me pareció muy interesante, consiste en decorar cada elemento de la enumeración con un atributo que describa al mismo, e implementar un método de extensión sobre la clase base
System.Enum para obtener estos valores. Veamos cómo.Ah, una cosa más. Aunque los ejemplos están escritos en C#, se puede conseguir exactamente el mismo resultado en VB.NET simplemente realizando las correspondientes adaptaciones sintácticas. Podrás encontrarlo al final del post.
1. Declaración de la enumeración
Vamos a usar el atributoSystem.ComponentModel.DescriptionAttribute, aunque podríamos usar cualquier otro que nos interese, o incluso crear nuestro propio atributo personalizado. El código de definición de la enumeración sería así:
using System.ComponentModel;
public enum EstadoProyecto
{
[Description("Pendiente de aceptación")] PendienteDeAceptacion,
[Description("En realización")] EnRealizacion,
[Description("Finalizado")] Finalizado,
[Description("Facturado y cerrado")] FacturadoYCerrado
}
2. Implementación del método de extensión
Ahora vamos a crear el método de extensión (¿qué son los métodos de extensión?) que se aplicará a todas las enumeraciones.Fijaos que el parámetro de entrada del método está precedido por la palabra reservada
this y el tipo es System.Enum, por lo que será aplicable a cualquier enumeración.
using System;
using System.ComponentModel;
using System.Reflection;
public static class Utils
{
public static string GetDescription(this Enum e)
{
FieldInfo field = e.GetType().GetField(e.ToString());
if (field != null)
{
object[] attribs =
field.GetCustomAttributes(typeof(DescriptionAttribute), false);
if (attribs.Length > 0)
return (attribs[0] as DescriptionAttribute).Description;
}
return e.ToString();
}
}
 Y voila! A partir de este momento tendremos a nuestra disposición el método
Y voila! A partir de este momento tendremos a nuestra disposición el método GetDescription(), que nos devolverá el texto asociado al elemento de la enumeración; si éste no existe, es decir, si no se ha decorado el elemento con el atributo apropiado, nos devolverá el identificador utilizado.De esta forma eliminamos de un plumazo los dos inconvenientes citados anteriormente: la separación entre la definición de la enumeración y los textos descriptivos, y la necesidad de crear un conversor a texto por cada enumeración que usemos en nuestra aplicación.
Y por cierto, el equivalente en VB.NET completo sería:
Imports System.ComponentModel
Imports System.Reflection
Imports System.Runtime.CompilerServices
Module Module1
Public Enum EstadoProyecto
<Description("Pendiente de aceptación")> PendienteDeAceptacion
<Description("En realización")> EnRealizacion
<Description("Finalizado")> Finalizado
<Description("Facturado y cerrado")> FacturadoYCerrado
End Enum
<Extension()> _
Public Function GetDescription(ByVal e As System.Enum) As String
Dim field As FieldInfo = e.GetType().GetField(e.ToString())
If Not (field Is Nothing) Then
Dim attribs() As Object = _
field.GetCustomAttributes(GetType(DescriptionAttribute), False)
If attribs.Length > 0 Then
Return CType(attribs(0), DescriptionAttribute).Description
End If
End If
Return e.ToString()
End Function
End Module
Publicado en: www.variablenotfound.com.
martes, 15 de abril de 2008
 Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".
Hace unos días comentaba que el uso de métodos parciales puede causar algunos problemas en la ejecución de nuestras aplicaciones que podríamos calificar, cuanto menos, de "incómodos".Recordemos que una parte de una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el compilador eliminará tanto la declaración del método como las llamadas que se hagan al mismo.
Sin embargo esta eliminación pueden causar efectos no deseados difíciles de detectar.
Veámoslo con un ejemplo. Supongamos una clase parcial como la siguiente, que representa a una variable de tipo entero que puede ser incrementada o decrementada a través de métodos:
public partial class Variable
{
partial void Log(string msg);
private int i = 0;
public void Inc()
{
i++;
Log("Incremento. I: " + i);
}
public void Dec()
{
Log("Decremento. I: " + (--i));
}
public int Value
{
get { return i; }
}
}
Creamos ahora un código que utiliza esta clase de forma muy simple: crea una variable, la incrementa dos veces, la decrementa una vez y muestra el resultado:
Variable v = new Variable();
v.Inc();
v.Inc();
v.Dec();
Console.WriteLine(v.Value);
Obviamente, tras la ejecución de este código la pantalla mostrará por consola un "1", ¿no? Claro, el resultado de realizar dos incrementos y un decremento sobre el cero.
Pues no necesariamente. De hecho, es imposible conocer, a la vista del código mostrado hasta ahora, cuál será el resultado mostrado por consola al finalizar la ejecución. Dependiendo de la existencia de la implementación del método parcial
Log(), declarado e invocado en la clase Variable anterior, puede ocurrir:- Si existe otra porción de la misma clase (otra
partial class Variable) donde se implemente el método, se ejecutará éste. El valor mostrado por consola, salvo que desde esta implementación se modificara el valor del campo privado, sería "1". - Si no existe una implementación del método
Log()en la clase, el compilador eliminará todas las llamadas al mismo. Pero si observáis, esto incluye el decremento del valor interno, que estaba en el interior de la llamada como un autodecremento:
Por tanto, en este caso, el compilador eliminará tanto la llamada aLog("Decremento. I: " + (--i));Log()como la operación que se realiza en el interior. Obviamente, el resultado de ejecución de la prueba anterior sería "2".
Lo mismo ocurriría si el resultado a mostrar fuera el valor de retorno de una llamada a otra función: esta no se ejecutaría, lo cual puede ser grave si en ella se realiza una operación importante, como por ejemplo:public function InicializaValores()
{
Log("Elementos reestablecidos: " + reseteaElementos() );
}
Por ejemplo, imaginad que el ejemplo anterior contiene una implementación de
Log(); la aplicación funcionaría correctamente. Sin embargo, si pasado un tiempo se decide eliminar esta implementación (por ejemplo, porque ya no es necesario registrar las operaciones realizadas), la operación de decremento (Dec()) dejaría de funcionar. Aunque, eso sí, no es nada que no se pueda solucionar con un buen juego de pruebas...
Publicado en: http://www.variablenotfound.com/.
domingo, 13 de abril de 2008
 Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.
Una vez visto el concepto de las clases parciales, ya es posible profundizar en los métodos parciales, una característica aparecida en las nuevas versiones de los lenguajes estrella de Microsoft, C# y VB.Net.Estos métodos, declarados en el contexto de una clase parcial, permiten comunicar de forma segura los distintos fragmentos de dicha clase. De forma similar a los eventos, permiten que un código incluya una llamada a una función que puede (o no) haber sido implementada por un código cliente, aunque en este caso obligatoriamente la implementación se encontrará en uno de los fragmentos de la misma clase desde donde se realiza la llamada.
En la práctica significa que una clase parcial puede declarar un método y utilizarlo (invocarlo) dentro de su código; si el método está implementado en otro fragmento de la clase, se ejecutará como siempre, pero si no ha sido implementado, el código correspondiente a la llamada será eliminado en tiempo compilación para optimizar el resultado... ¡sí, eliminado!
Por ejemplo, el siguiente código muestra una declaración de un método parcial en el interior de una clase, y su utilización desde dentro de uno de sus métodos:
// C#
public partial class Ejemplo
{
// El método parcial se declara
// sin implementación...
partial void Log(string msg);
public void RealizarAlgo()
{
hacerAlgoComplejo();
Log("¡Ojo!"); // Usamos el método
// parcial declarado antes
}
[...] // Otros métodos y propiedades
}
' VB.NET
Partial Public Class Ejemplo
' El método parcial se declara, sin
' implementar nada en el cuerpo
Partial Private Sub Log(ByVal msg As String)
End Sub
Public Sub RealizarAlgo()
HacerAlgoComplejo()
Log("¡Ojo!") ' Usamos el método parcial
End Sub
[...] ' Otros métodos y propiedades
End Class
Y esta la parte realmente curiosa. Cuando el compilador detecta la invocación del método parcial
Log(), buscará en todos los fragmentos de la clase a ver si existe una implementación del mismo. Si no existe, eliminará del ensamblado resultante la llamada a dichos métodos, es decir, actuará como si éstas no existieran en el código fuente.En caso afirmativo, es decir, si existen implementaciones como las del siguiente ejemplo, todo se ejecutará conforme a lo previsto:
// C#
public partial class Ejemplo
{
partial void Log(string msg)
{
Console.WriteLine(msg);
}
}
' VB.Net
Partial Public Class Ejemplo
Private Sub Log(ByVal msg As String)
Console.WriteLine(msg)
End Sub
End Class
Antes comentaba que los métodos parciales son, en cierto sentido, similares a los eventos, pues conceptualmente permiten lo mismo: pasar el control a un código cliente en un momento dado, en el caso de que éste exista. De hecho, hay muchos desarrolladores que lo consideran como un sustituto ligero a los eventos, pues permite prácticamente lo mismo pero se implementan de forma más sencilla.
Existen, sin embargo, algunas diferencias entre ambos modelos, como:
- Los métodos parciales se implementan en la propia clase, mientras que los eventos pueden ser consumidos también desde cualquier otra
- El enlace, o la suscripción, a eventos es dinámica, se realiza en tiempo de ejecución, es necesario incluir código para ello; los métodos parciales, sin embargo, se vinculan en tiempo de compilación
- Los eventos permiten múltiples suscripciones, es decir, asociarles más de un código cliente
- Los eventos pueden presentar cualquier visibilidad (pública, privada...), mientras que los métodos parciales son obligatoriamente privados.
Por último, es conveniente citar algunas consideraciones sobre los métodos parciales:
- Deben ser siempre privados (ya lo había comentado antes)
- No deben devolver valores (en VB.Net serían
SUB, en C# serían de tipovoid) - Pueden ser estáticos (shared en VB)
- Pueden usar parámetros, acceder a los miembros privados de la clase... en definitiva, actuar como un método más de la misma
En resumen, los métodos parciales forman parte del conjunto de novedades de C# y VB.Net que no son absolutamente necesarias y que a veces pueden parecer incluso diabólicas, pues facilitan la dispersión de código y dificultan la legibilidad. Además, en breve publicaré un post comentando posibles efectos laterales a tener en cuenta cuando usemos los métodos parciales en nuestros desarrollos.
Sin embargo, es innegable que los métodos parciales nos facilitan enormemente la inclusión de código de usuario en el interior de clases generadas de forma automática. Por ejemplo, el diseñador visual del modelo de datos de LinqToSQL genera los
DataContext como clases parciales, en las que define un método parcial llamado OnCreated(). Si el usuario quiere incluir alguna inicialización personal al crear los DataContext, no tendrá que tocar el código generado de forma automática; simplemente creará otro fragmento de la clase parcial e implementará este método, de una forma mucho más natural y cómoda que si se tratara de un evento.Publicado en: http://www.variablenotfound.com/.
miércoles, 2 de abril de 2008
Aunque las clases parciales aparecieron hace unos años, con la llegada de .Net 2.0 y Visual Studio 2005, vamos a hacer un breve repaso como preparación para un próximo post que trate los métodos parciales.Las clases parciales (llamados también tipos parciales) son una característica presente en algunos lenguajes de programación, como C# y VB.Net, que permiten que la declaración de una clase se realice en varios archivos de código fuente, rompiendo así la tradicional regla "una clase, un archivo". Será tarea del compilador tomar las porciones de los distintos archivos y fundirlas en una única entidad.
En VB.Net y C#, a diferencia de otros lenguajes, es necesario indicar explícitamente que una clase es parcial, es decir, que es posible que haya otros archivos donde se continúe la declaración de la misma, usando en ambos con la palabra clave
partial en la definición del tipo: ' VB.NET
Public Partial Class Persona
...
End Class
// C#
public partial class Persona
{
...
}
En este código hemos visto cómo se declara una clase parcial en ambos lenguajes, que es prácticamente idéntica salvo por los detalles sintácticos obvios. Por ello, a partir de este momento continuaré introduciendo los ejemplos sólo en C#.
Pero antes un inciso: la única diferencia entre ambos, estrictamente hablando, es que C# obliga a que todas las apariciones de la clase estén marcadas como parciales, mientras que en VB.Net puede dejarse una de ellas (llamémosla "declaración principal") sin indicar que es parcial, y especificarlo en el resto de apariciones. En mi opinión, esta no es una práctica recomendable, por lo que aconsejaría utilizar el modificador
partial siempre que la clase lo sea, e independientemente del lenguaje utilizado, pues contribuirá a la mantenibilidad del código.El número de partes en las que se divide una clase es indiferente, el compilador tomará todas ellas y generará en el ensamblado como si fuera una clase normal.
Para comprobarlo he creado un pequeño código con dos clases exactamente iguales, salvo en su nombre. Una de ellas se denomina
PersonaTotal, y está definida como siempre, en un único archivo; la otra, PersonaParcial, es parcial y la he troceado en tres archivos, como sigue: // *** Archivo PersonaParcial.Propiedades.cs ***
// Aquí definiremos todas las propiedades
partial class PersonaParcial
{
public string Nombre { get; set; }
public string Apellidos { get; set; }
}
// *** Archivo PersonaParcial.IEnumerable.cs ***
// Aquí implementaremos el interfaz IEnumerable
partial class PersonaParcial: IEnumerable
{
public IEnumerator GetEnumerator()
{
throw new NotImplementedException();
}
}
// *** Archivo PersonaParcial.Metodos.cs ***
// Aquí implementaremos los métodos que necesitemos
partial class PersonaParcial
{
public override string ToString()
{
return Nombre + " " + Apellidos;
}
}
Y efectivamente, el resultado de compilar ambas clases, según se puede observar con ILDASM es idéntico:

A la hora de crear clases parciales es conveniente tener los siguientes aspectos en cuenta:
- Los atributos de la clase resultante serán la combinación de los atributos definidos en cada una de las partes.
- El tipo base de los distintos fragmentos debe ser el mismo, o aparecer sólo en una de las declaraciones parciales.
- Si se trata de una clase genérica, los parámetros deben coincidir en todas las partes.
- Los interfaces que implemente la clase resultante será la unión de todos los implementados por las distintas secciones.
- De la misma forma, los miembros (métodos, propiedades, campos...) de la clase final será la unión de todos los definidos en las distintas partes.
Vale, ya hemos visto qué son y cómo se usan, pero, ¿para qué sirven? ¿cuándo es conveniente utilizarlas? Pues bien, son varios los motivos de su existencia, algunos discutibles y otros realmente interesantes.
En primer lugar, no era sencillo que varios desarrolladores trabajaran sobre una misma clase de forma concurrente. Incluso utilizando sistemas de control de versiones (como Sourcesafe o Subversion), la unidad mínima de trabajo es el archivo de código fuente, y la edición simultánea podía generar problemas a la hora de realizar fusiones de las porciones modificadas por cada usuario.
En segundo lugar, permite que clases realmente extensas puedan ser troceadas para facilitar su comprensión y mantenimiento. Igualmente, puede utilizarse para separar código en base a distintos criterios:
- por ejemplo, separar la interfaz (los miembros visibles desde el exterior de la clase) y por otra los miembros privados a la misma
- o bien separar las porciones que implementan interfaces, o sobreescriben miembros de clases antecesoras de los pertenecientes a la propia clase
- o separar temas concernientes a distintos dominios o aspectos
Así, es posible que un desarrollador y un generador estén introduciendo cambios sobre la misma clase sin molestarse, cada uno jugando con su propia porción de la clase; el primero puede introducir funcionalidades sin preocuparse de que una nueva generación automática de código pueda machacar su trabajo. Visual Studio y otros entornos de desarrollo hacen uso intensivo de esta capacidad, por ejemplo, en los diseñadores visuales de Windows Forms, WPF, ASP.Net e incluso el generador de modelos de LinqToSql.
Publicado en: http://www.variablenotfound.com/.
domingo, 9 de marzo de 2008
 Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.
Hace unos meses hablaba sobre la posibilidad de manipular la forma en la que el framework almacena por defecto la información para obtener enumeraciones de campos de bits, algo que es muy habitual en programación a bajo nivel. Siguiendo en la misma línea, hoy voy a comentar cómo conseguir uniones en .Net, al más puro estilo C.Una unión es muy similar a una estructura de datos (
struct en C# o Structure en VB.Net), salvo en un detalle: sus componentes se almacenan sobre las mismas posiciones de memoria. O visto desde el ángulo opuesto, una unión podríamos definirla como una porción de memoria donde se guardan varias variables, habitualmente de tipos diferentes. Veamos un ejemplo clásico que nos ayudará a entender el concepto, en un lenguaje cualquiera:union Ejemplo
{
char caracter; // suponiendo char de 8 bits
byte octeto; // un byte ocupa 8 bits
};Si declaramos una variable x del tipo Ejemplo, estaremos reservando un espacio de 8 bits al que accederemos desde cualquiera de sus miembros, como vemos a continuación:
x.caracter = 'A';
x.octeto ++;
escribir_char (x.caracter); // mostraría 'B'
escribir_byte (x.octeto); // mostraría 66
Pero espera... ¿memoria?... ¿almacenamiento de variables?... ¿pero existe eso en .Net?... Pues sí, aunque lo más normal es que no nos tengamos que enfrentar nunca a ello pues el framework realiza estas tareas por nosotros, hay escenarios en los que es necesario controlar la forma en que la información es almacenada en memoria, como cuando se esté operando a bajo nivel, por ejemplo creando estructuras específicas para llamar al API de Windows, o para facilitar el acceso a posiciones concretas de la información.
Desde la versión 1.1 de la plataforma .Net, disponemos del atributo StructLayout, que nos permite indicar en estructuras y clases cómo queremos representar en memoria la información de sus miembros. Básicamente, podemos indicar que:
- la información se almacene como el framework considere oportuno (
LayoutKind.Auto) - que se almacene de forma secuencial, en el mismo orden en el que han sido declarados (
LayoutKind.Sequential). - que se almacene donde le indiquemos de forma explícita (
LayoutKind.Explicit). En este caso, necesitaremos especificar en cada miembro la posición exacta de memoria donde será guardado, utilizando el atributoFieldOffset.
Es este último método el que nos interesa para nuestros propósitos. Si adornamos una estructura con
StructLayout(LayoutKind.Explicit) e indicamos en cada uno de sus miembros su desplazamiento (en bytes) dentro del espacio de memoria asignado a la misma, podemos conseguir uniones haciendo que todos ellos comiencen en la misma dirección.Pasemos a vamos a verlo con un ejemplo en C#. Se trata de una unión a la que podemos acceder tratándola como un carácter unicode, o bien como un entero de 16 bits con signo. Los dos miembros, llamados
Caracter y Valor están definidos sobre la misma posición de memoria (desplazamiento cero) en el interior de la estructura:using System.Runtime.InteropServices;
using System;
namespace PruebaUniones
{
[StructLayout(LayoutKind.Explicit)]
public struct UnionTest
{
[FieldOffset(0)] public char Caracter;
[FieldOffset(0)] public short Valor;
}
class Program
{
public static void Main()
{
UnionTest ut = new UnionTest();
ut.Caracter = 'A';
ut.Valor ++;
Console.WriteLine(ut.Caracter); // Muestra "B"
Console.ReadKey();
return;
}
}
}Ahora usaremos VB.NET para mostrar otro ejemplo un poco más complejo que el anterior, donde usamos una unión para descomponer una palabra de 16 bits en los dos bytes que la componen, permitiendo la manipulación de forma directa e independiente de cada una de las dos visiones del valor almacenado en memoria. Para el ejemplo utilizo una unión dentro de otra, aunque no era estrictamente necesario, para que veáis que esto es posible.
Imports System.Runtime.InteropServices
<StructLayout(LayoutKind.Explicit)> _
Public Structure Union16
<FieldOffset(0)> Dim Word As Int16
<FieldOffset(0)> Dim Bytes As Bytes
End Structure
<StructLayout(LayoutKind.Explicit)> _
Public Structure Bytes
<FieldOffset(0)> Dim Bajo As Byte
<FieldOffset(1)> Dim Alto As Byte
End Structure
Public Class Program
Public Shared Sub main()
Dim u As New Union16
u.Word = 513 ' 513 = 256*1 (Byte alto) + 1 (byte bajo)
u.Bytes.Alto += 1
Console.WriteLine("Word: " & u.Word) ' Muestra 769 (3*256+1)
Console.WriteLine("Byte alto: " & u.Bytes.Alto) ' Muestra 3
Console.WriteLine("Byte bajo: " & u.Bytes.Bajo) ' Muestra 1
Console.ReadKey()
Console.ReadKey()
End Sub
End Class
He encontrado un uso muy interesante para esta técnica en Xtreme .Net Talk, donde se muestra un ejemplo de cómo acceder a los componentes de color de un pixel de forma muy eficiente a través de una unión entre el valor ARGB (32 bits) y cada uno de los bytes que lo componen (alfa, rojo, verde y azul).
En cualquier caso no se recomienda el uso de uniones salvo en casos muy concretos, y siempre conociendo bien las implicaciones que puede tener en la estabilidad y mantenibilidad del sistema.
Pero bueno, ¡está bien al menos saber que existen!
Publicado en: http://www.variablenotfound.com/.
miércoles, 5 de marzo de 2008
 Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?
Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?Por ejemplo, dado el siguiente código en el interior de una página ASP.NET, ¿cuál sería la forma correcta de comentarlo?
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
Una primera opción podría ser utilizar la sintaxis Javascript de la siguiente forma:
<script>
/*
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
*/
</script>
Sin embargo, aunque podría valer en muchas ocasiones, también puede introducir unos efectos laterales considerables. Nótese que aunque el código Javascript (cliente) esté comentado, la función
borrarRegistros() sería invocada en el lado del servidor, y su retorno introducido dentro del comentario. De hecho, la página enviada a cliente mostraría un código fuente similar al siguiente (imaginando que el retorno de la función fuera el valor 99):<script>
/*
var count = 99;
alert("Borrados: " + count + " registros");
*/
</script>
Tampoco valdría para nada incluir todo el bloque de script dentro de un comentario HTML (<!-- y -->), por la misma razón que antes. Además, en cualquiera de estos dos casos, estaríamos enviando al cliente la información aunque sea éste el que la ignora a la hora de mostrarla o ejecutarla y, por supuesto, estaríamos ejecutando la función en servidor, lo cual podría causar otros efectos no deseados, como, en nuestro ejemplo, eliminar los registros de una base de datos.
Afortunadamente, ASP.NET dispone de un mecanismo, denominado Server Side Comments (comentarios en el lado del servidor), que permite marcar zonas y hacer que se ignore todo su contenido, sea del tipo que sea, a la hora de procesar la página:
<%--
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
--%>
En este caso ni sería ejecutada la función del servidor ni tampoco enviado a cliente el código HTML/Script incluido.
Publicado en: http://www.variablenotfound.com/.
lunes, 3 de marzo de 2008
 Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.
Como ya venimos comentando hace tiempo, la nueva versión de ambos lenguajes viene repleta de novedades y mejoras pensadas para hacernos la vida más fácil y, por tanto, aumentar la productividad de los desarrolladoradores. Bueno, no sé si fue así o en realidad es que simplemente eran necesarias para Linq y por eso fueron incluidas ;-), pero el caso es que a partir de las versiones 3.0 y 9.0 de C# y VB.NET respectivamente, tenemos a nuestra disposición interesantísimas herramientas que deberíamos conocer para sacar el máximo provecho a nuestro tiempo.En esta ocasión vamos a centrarnos en los inicializadores de objetos, una nueva característica destinada, entre otras cosas, a ahorrarnos tiempo a la hora de establecer los valores iniciales de los objetos que creemos desde código.
Y es que, hasta ahora, podíamos utilizar dos patrones básicos de inicialización de propiedades al instanciar una clase:
- que fuera la clase la que realizara esta tarea, ofreciendo al usuario de la misma constructores con distintas sobrecargas cuyos parámetros corresponden con las propiedades a inicializar.
// Constructor de la clase Persona:
public Persona(string nombre, string apellidos, int edad, ...)
{
this.Nombre = nombre;
this.Apellidos = apellidos;
this.Edad = edad;
...
}
// Uso:
Persona p = new Persona("Juan", "López", 32, ...); - o bien dejar esta responsabilidad al usuario, permitiéndole el acceso directo a propiedades o campos del objeto creado.
// Uso:
Persona p = new Persona();
p.Nombre = "Juan";
p.Apellidos = "López";
p.Edad = 32;
...
Los inicializadores de objetos permiten, en C# y VB.Net, realizar esta tarea de forma más sencilla, indicando en la llamada al constructor el valor de las propiedades o campos que deseemos establecer:
// C#:
Persona p = new Persona { Nombre="Juan", Apellidos="López", Edad=32 };
' VB.NET:
Dim p = New Persona With {.Nombre="Luis", .Apellidos="López", .Edad=32 }
Los ejemplos anteriores son válidos para clases que admitan constructores sin parámetros, pero, ¿qué ocurre con los demás? Imaginando que el constructor de la clase
Persona recibe obligatoriamente dos parámetros, su nombre y apellidos, podríamos instanciar así:
// C#:
Persona p = new Persona ("Luis", "López") { Edad = 32 };
' VB.NET:
Dim p = New Persona ("Luis", "López") With { .Edad = 32 }
Aunque es obvio, es importante tener en cuenta que las inicializaciones (la porción de código entre llaves "{" y "}") se ejecutan después del constructor:
// C#:
Persona p = new Persona ("Juan", "Pérez") { Nombre="Luis" };
Console.WriteLine(p.Nombre); // Escribe "Luis"
' VB.NET:
Dim p = New Persona ("Juan", "Pérez") With { .Nombre="Luis" }
Console.WriteLine(p.Nombre); ' Escribe "Luis"
Y un último apunte: ¿cómo inicializaríamos propiedades de objetos que a su vez sean objetos que también queremos inicializar? Suponiendo que en nuestra clase
Persona hemos incluido una propiedad llamada Domicilio que de tipo Localizacion, podríamos inicializar el bloque completo así:
// C#:
// Se han cortado las líneas para facilitar la lectura
Persona p = new Persona()
{
Nombre = "Juan",
Apellidos = "López",
Edad = 55,
Domicilio = new Localizacion
{
Direccion = "Callejas, 34",
Localidad = "Sevilla",
Provincia = "Sevilla"
}
};
' VB.NET:
' Se han cortado las líneas para facilitar la lectura
Dim p = New Persona() With { _
.Nombre = "Juan", _
.Apellidos = "López", _
.Edad = 55, _
.Domicilio = New Localizacion With { _
.Direccion = "Callejas, 23", _
.Localidad = "Sevilla", _
.Provincia = "Sevilla" _
} _
}
En fin, que de nuevo tenemos ante nosotros una característica de estos lenguajes que resulta interesante por sí misma, aunque toda su potencia y utilidad podremos percibirla cuando profundicemos en otras novedades, como los tipos anónimos y Linq... aunque eso será otra historia.
Publicado en: http://www.variablenotfound.com/.
domingo, 24 de febrero de 2008
 Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático
Hace unos meses comentaba las distintas opciones para saber si una cadena está vacía en C#, y la conclusión era la recomendación del uso del método estático string.IsNullOrEmpty, sobre todo si podemos asegurar que no aparecerá el famoso bug del mismo (que al final no es para tanto, todo sea dicho).Los métodos de extensión nos brindan la posibilidad de hacer lo mismo pero de una forma más elegante e intuitiva, impensable hasta la llegada de C# 3.0: extendiendo la clase
string con un método que compruebe su contenido.La forma de conseguirlo es bien sencilla. Declaramos en una clase estática el método de extensión sobre el tipo
string:public static class MyExtensions
{
public static bool IsNullOrEmpty(this string s)
{
return s == null || s.Length == 0;
}
}Y listo, ya tenemos el nuevo método listo para ser utilizado:
string name = getCurrentUserName();
if (!name.IsNullOrEmpty())
...De todas formas, hay un par de reflexiones que considero interesante comentar.
En primer lugar, fijaos en el ejemplo anterior que aunque la variable
name contenga un nulo, se ejecutará la llamada a IsNullOrEmpty() sin provocar error, algo imposible si se tratara de un método de instancia. Obviamente, se debe a que en realidad se está enmascarando una llamada a un método estático al que le llegará como parámetro un null.Como consecuencia de lo anterior, y dado que no se puede distinguir a simple vista en una llamada a un método si éste es de instancia o de extensión, es posible que un desarrollador considerara esta invocación incorrecta. Esto forma parte de los inconvenientes de los métodos de extensión que ya cité en un post anterior.
En segundo lugar, visto lo visto cabría preguntarse, ¿por qué podemos extender una clase añadiéndole nuevos métodos pero no es posible incluir otro tipo de elementos, como eventos o propiedades? En el caso anterior podría quedar más fino que
IsNullOrEmpty fuera una propiedad de string, ¿no? Sin embargo, esto no es posible de momento. Según comentó ScottGu hace tiempo, se estaba considerando añadir la posibilidad de extender las clases también con nuevas propiedades. Supongo que el hecho de no haberla incluido en esta versión se deberá a que no era necesario para LINQ, la estrella de esta entrega... ¡y para dejar algo por hacer para C# 4.0, claro! ;-)
En cualquier caso, se trata principalmente de una cuestión de estética del código. Todo lo que conseguimos con las propiedades se puede realizar a base de métodos; de hecho, las propiedades no son sino interfaces más agradables a métodos getters y setters, al más puro estilo Java, subyacentes.
Por último, todo lo dicho es válido para VB.NET 9, salvo las obvias diferencias. El código equivalente al anterior sería:
Imports System.Runtime.CompilerServices
Module MyExtensions
<Extension()> _
Public Function IsNullOrEmtpy(ByVal s As String) As String
Return (s = Nothing) OrElse (s.Length = 0)
End Function
End Module
[...]
' Forma de invocar el método:
If s.IsNullOrEmtpy() Then
[...]
Publicado en: http://www.variablenotfound.com/.
miércoles, 9 de enero de 2008
 Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil.
Visual Basic .NET 9.0, disponible con Visual Studio 2008, incluye, al igual que C# 3.0, multitud de novedades y mejoras que sin duda nos harán la vida más fácil. Una de ellas es la posibilidad de declarar variables sin necesidad de indicar de forma explícita su tipo, cediendo al compilador la tarea de determinar cuál es en función del tipo de dato obtenido al evaluar su expresión de inicialización. El tipado implícito o inferencia de tipos también existe en C# y ya escribí sobre ello hace unos días, pero me parecía interesante también publicar la visión para el programador Visual Basic y las particularidades que presenta.
Gracias a esta nueva característica, en lugar de escribir:
Dim x As XmlDateTimeSerializationMode = XmlDateTimeSerializationMode.Local
Dim i As Integer = 1
Dim d As Double = 1.8 Dim x = XmlDateTimeSerializationMode.Local
Dim i = 1
Dim d = 1.8El resultado en ambos casos será idéntico, ganando en comodidad y eficiencia a la hora de la codificación y sin sacrificar los beneficios propios del tipado fuerte.
Hay un detalle importante que los veteranos habrán observado: Visual Basic ya permitía (y de hecho permite) la declaración de variables sin especificar el tipo, de la forma
Dim i = 1 (con Option Strict Off), por lo que podría parecer que el tipado implícito no sería necesario. Sin embargo, en este caso los compiladores asumían que la variable era de tipo Object, por lo que nos veíamos obligados a realizar castings o conversiones en tiempo de ejecución, penalizando el rendimiento y aumentando el riesgo de aparición de errores imposibles de detectar en compilación. Tampoco tiene nada que ver con tipados dinámicos (como los presentes en javascript), o con el famoso tipo Variant que estaba presente en Visual Basic 6; el tipo asignado a la variable es fijo e inamovible, como si lo hubiésemos declarado explícitamente.En Visual Basic 9, siempre que no se desactive esta característica incluyendo la directiva
Option Infer Off en el código, el tipo de la variable será fijado justo en el momento de su declaración, deduciéndolo a partir del tipo devuelto por la expresión de inicialización. Por este motivo, la declaración y la inicialización deberán hacerse en el mismo momento:
Dim i = 1 ' La variable "i" es Integer desde este momento
Dim j ' La variable "j" es Object, como siempre,
j = 1 ' ... si Option Scrict está en Off.
' En caso contrario aparecerá un error de compilación.
El tipado implícito puede ser asimismo utilizado en las variables de control de bucles For o For Each, haciendo su escritura mucho más cómoda:
Dim suma = 0
For i = 1 To 10 ' i se está declarando ahí mismo como Integer,
suma += i ' no existía con anterioridad
Next
Dim str = "abcdefg"
For Each ch In str ' ch se declara automáticamente como char,
Console.Write(ch) ' que es el tipo de los elementos de "str"
Next
Y también puede resultar bastante útil a la hora de obtener objetos de tipos anónimos, es decir, aquellos cuya clase se define en el mismo momento de su instanciación, como en el siguiente ejemplo:
Dim point = New With {.X = 1, .Y = 5}
point.X += 1
point.Y += 1
Por último, es interesante comentar que, a diferencia de C#, Visual Basic permite declarar en la misma línea distintas variables de tipo implícito, por lo que es posible escribir
Dim k=1, j=4.8, str="Hola" sin temor a un error en compilación, asignándose a cada una de ellas el tipo apropiado en función de su inicialización (en el ejemplo, Integer, Double y String respectivamente).Coinciden, sin embargo, en que en ambos lenguajes esta forma de declaración de variables se aplica exclusivamente a las locales, es decir, aquellas cuyo ámbito es un método, función o bloque de código. No pueden ser propiedades ni variables de instancia; en el siguiente ejemplo, x será declarada de forma implícita como Object, mientras que el tipo de la variable y será inferido como Integer:
Public Class Class1
Dim x = 2 ' Es una variable de instancia
Public Sub New()
Dim y = 2 ' Es una variable local
End Sub
End ClassEn resumen, se trata de una característica muy útil que, además de permitirnos programar más rápidamente al ahorrarnos teclear los tipos de las variables locales, actúa como soporte de nuevas características del lenguaje y la plataforma .NET, como el interesantísimo Linq.
Es conveniente, sin embargo, utilizar esta característica con cordura y siendo siempre conscientes de que su uso puede dar lugar a un código menos legible y generar errores difíciles de depurar. De hecho, Microsoft recomienda usarlas "sólo cuando sea conveniente".
Publicado en: Variable Not Found.
miércoles, 3 de octubre de 2007
Hasta hoy pensaba que la página maestra (MasterPage) de un .aspx era una propiedad que se definía en tiempo de diseño, concretamente en las directivas de página, y no era posible modificarlo de forma programática al encontrarse la declaración a un nivel tan bajo:
Nada más lejos de la realidad. Aunque con algunas restricciones, es perfectamente posible alterar en tiempo de ejecución la MasterPage de la página, haciendo posible cosas como, por ejemplo, modificar completamente la apariencia y disposición de los elementos sobre la marcha.
Por ejemplo, el siguiente código hace que una página .aspx utilice una maestra u otra en función de si la hora actual del servidor es par:
Las restricciones a las que me refería antes están plasmadas en esta porción de código: sólo puede cambiarse en el evento PreInit o antes. A efectos prácticos, sobreescribir OnPreInit (como en el ejemplo anterior) es una buena solución.
<%@ Page Language="C#" MasterPageFile="~/Site1.Master"
AutoEventWireup="true" CodeBehind="WebForm1.aspx.cs"
Inherits="PruebasVariadas.WebForm1"
Title="Página sin título" %>
Nada más lejos de la realidad. Aunque con algunas restricciones, es perfectamente posible alterar en tiempo de ejecución la MasterPage de la página, haciendo posible cosas como, por ejemplo, modificar completamente la apariencia y disposición de los elementos sobre la marcha.
Por ejemplo, el siguiente código hace que una página .aspx utilice una maestra u otra en función de si la hora actual del servidor es par:
// C#:
protected override void OnPreInit(EventArgs e)
{
if (DateTime.Now.Hour % 2 == 0)
this.MasterPageFile = "~/Maestra1.master";
else
this.MasterPageFile = "~/Maestra2.master";
base.OnPreInit(e);
}
' VB.NET:
Protected Overrides Sub OnPreInit(ByVal e As System.EventArgs)
If DateTime.Now.Second Mod 2 = 0 Then
Me.MasterPageFile = "~/Maestra1.master"
Else
Me.MasterPageFile = "~/Maestra2.master"
End If
MyBase.OnPreInit(e)
End Sub
Las restricciones a las que me refería antes están plasmadas en esta porción de código: sólo puede cambiarse en el evento PreInit o antes. A efectos prácticos, sobreescribir OnPreInit (como en el ejemplo anterior) es una buena solución.
jueves, 27 de septiembre de 2007
Los que vamos evolucionando a la vez que lo hace la plataforma .Net (bueno, unos cuantos pasos por detrás ;-)), a veces se nos hace difícil superar nuestras costumbres y adaptarnos a nuevos métodos o utilidades que, sin duda, vienen para facilitarnos la vida y ofrecen mejores soluciones a problemas comunes que las que utilizamos de forma habitual.
Un ejemplo lo tenemos con los métodos estáticos xxx.Parse(), útiles para convertir de un string a un tipo valor, como puede ser int32 o boolean. Desde el principio de los tiempos usamos, para obtener un entero desde su representación como cadena, construcciones de tipo:
Sin embargo, la llegada de .NET Framework 2.0 supuso la inclusión del método estático TryParse() en la práctica totalidad de tipos primitivos numéricos (en la versión 1.1 sólo existe en el tipo double), cuya forma más simple de utilización (y también más usual) dejaría el bloque try/catch anterior en uno más compacto y legible:
El método TryParse devuelve true si se ha podido realizar la transformación con éxito, dejando en la variable de salida que le indiquemos el valor parseado, en este caso un int.
Sin embargo, además de para evitarnos dolores en las articulaciones de los dedos, existen otros motivos para utilizar xxx.TryParse() en vez de xxx.Parse(): el rendimiento, sobre todo si se prevé que el número de fallos de conversión será relativamente alto en un proceso. De hecho es el método recomendado en la actualidad para realizar estas conversiones.
 Según la prueba de rendimiento de TryParse publicada Microsoft, ejecutada sobre su propia plataforma, la utilización de este método aventaja de forma considerable al modelo try-parse-catch. Por ejemplo, realizando varias simulaciones de parsing de enteros sobre un conjunto de 100 cadenas de las cuales 5 son erróneas, el tiempo de proceso llegar a ser mil veces superior usando este último patrón; si asumimos 20 incorrectas (80% de cadenas correctas), el modelo tradicional puede tardar 4.000 veces más que usando TryParse.
Según la prueba de rendimiento de TryParse publicada Microsoft, ejecutada sobre su propia plataforma, la utilización de este método aventaja de forma considerable al modelo try-parse-catch. Por ejemplo, realizando varias simulaciones de parsing de enteros sobre un conjunto de 100 cadenas de las cuales 5 son erróneas, el tiempo de proceso llegar a ser mil veces superior usando este último patrón; si asumimos 20 incorrectas (80% de cadenas correctas), el modelo tradicional puede tardar 4.000 veces más que usando TryParse.
Aunque lo normal no es efectuar un gran número de transformaciones de este tipo y esta diferencia de rendimiento podría entenderse despreciable, podría ser un factor a tener en cuenta cuando estas operaciones se realicen en contextos de gran carga de usuarios o concurrencia, como en sitios web de alto tráfico. Ojo pues a esas aplicaciones (o componentes) que hemos tomado de .NET 1.x y estamos reutilizando en las versiones superiores.
Por cierto, todo lo dicho, aunque los ejemplos están codificados en C#, es válido para Visual Basic .NET y cualquier otro lenguaje que compile sobre la plaforma .NET de Microsoft. A ver si un día tengo un rato y compruebo si el comportamiento en Mono es el mismo.
Un ejemplo lo tenemos con los métodos estáticos xxx.Parse(), útiles para convertir de un string a un tipo valor, como puede ser int32 o boolean. Desde el principio de los tiempos usamos, para obtener un entero desde su representación como cadena, construcciones de tipo:
string num = "123";
int i = 0;
try
{
i = int.Parse(num);
}
catch (Exception ex)
{
// TODO: hacer algo...
}Sin embargo, la llegada de .NET Framework 2.0 supuso la inclusión del método estático TryParse() en la práctica totalidad de tipos primitivos numéricos (en la versión 1.1 sólo existe en el tipo double), cuya forma más simple de utilización (y también más usual) dejaría el bloque try/catch anterior en uno más compacto y legible:
if (!int.TryParse(num, out i))
// TODO: hacer algo...El método TryParse devuelve true si se ha podido realizar la transformación con éxito, dejando en la variable de salida que le indiquemos el valor parseado, en este caso un int.
Sin embargo, además de para evitarnos dolores en las articulaciones de los dedos, existen otros motivos para utilizar xxx.TryParse() en vez de xxx.Parse(): el rendimiento, sobre todo si se prevé que el número de fallos de conversión será relativamente alto en un proceso. De hecho es el método recomendado en la actualidad para realizar estas conversiones.
 Según la prueba de rendimiento de TryParse publicada Microsoft, ejecutada sobre su propia plataforma, la utilización de este método aventaja de forma considerable al modelo try-parse-catch. Por ejemplo, realizando varias simulaciones de parsing de enteros sobre un conjunto de 100 cadenas de las cuales 5 son erróneas, el tiempo de proceso llegar a ser mil veces superior usando este último patrón; si asumimos 20 incorrectas (80% de cadenas correctas), el modelo tradicional puede tardar 4.000 veces más que usando TryParse.
Según la prueba de rendimiento de TryParse publicada Microsoft, ejecutada sobre su propia plataforma, la utilización de este método aventaja de forma considerable al modelo try-parse-catch. Por ejemplo, realizando varias simulaciones de parsing de enteros sobre un conjunto de 100 cadenas de las cuales 5 son erróneas, el tiempo de proceso llegar a ser mil veces superior usando este último patrón; si asumimos 20 incorrectas (80% de cadenas correctas), el modelo tradicional puede tardar 4.000 veces más que usando TryParse.Aunque lo normal no es efectuar un gran número de transformaciones de este tipo y esta diferencia de rendimiento podría entenderse despreciable, podría ser un factor a tener en cuenta cuando estas operaciones se realicen en contextos de gran carga de usuarios o concurrencia, como en sitios web de alto tráfico. Ojo pues a esas aplicaciones (o componentes) que hemos tomado de .NET 1.x y estamos reutilizando en las versiones superiores.
Por cierto, todo lo dicho, aunque los ejemplos están codificados en C#, es válido para Visual Basic .NET y cualquier otro lenguaje que compile sobre la plaforma .NET de Microsoft. A ver si un día tengo un rato y compruebo si el comportamiento en Mono es el mismo.
martes, 18 de septiembre de 2007
 A raíz de los posts sobre los tipos anulables en .NET (introducción a los nullables y uso tipos anulables con enumeraciones), mi amigo Javi me hizo una pregunta que sólo un friki como él sería capaz de formular ;-): ¿cómo afecta el uso de tipos anulables a la serialización de clases?
A raíz de los posts sobre los tipos anulables en .NET (introducción a los nullables y uso tipos anulables con enumeraciones), mi amigo Javi me hizo una pregunta que sólo un friki como él sería capaz de formular ;-): ¿cómo afecta el uso de tipos anulables a la serialización de clases?Aunque sospechaba la respuesta, he hecho un par de pruebas a través de las cuales, ahora sí, puedo asegurar que no afectan en nada, es decir, el sistema controla perfectamente la forma en que se serializan y deserializan este tipo de valores.
El comportamiento es el siguiente: cuando el tipo anulable contiene un valor no nulo, la serialización la delega en el tipo subyacente. Si es un int?, se realizará la serialización por defecto para el int. Usando un serializador XML, un ejemplo de salida sería:
<?xml version="1.0" encoding="utf-16"?>
<int>10</int>
En cambio, cuando se trata de serializar el valor null, el sistema genera una etiqueta que indica este hecho, de la misma forma que lo haría si estuviéramos haciéndolo para un tipo referencia. Un ejemplo de salida XML sería:
<?xml version="1.0" encoding="utf-16"?>
<int xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xsi:nil="true" />
En fin, que hoy hemos aprendido una cosa más. Y que no falte. :-)
viernes, 14 de septiembre de 2007
 De todos es sabido que las enumeraciones son un tipo valor, y se representan internamente como Byte, Int32 u otros tipos primitivos de la plataforma, lo que hace imposible la asignación de valores como null, concebido para los tipos referencia.
De todos es sabido que las enumeraciones son un tipo valor, y se representan internamente como Byte, Int32 u otros tipos primitivos de la plataforma, lo que hace imposible la asignación de valores como null, concebido para los tipos referencia.Así, en el siguiente ejemplo en C#:
Estado estado1 = Estado.Correcto;
Estado estado2 = null;La segunda línea provoca el error en compilación "No se puede convertir null en 'ConsoleApplication1.Program.Estado' porque es un tipo de valor". Lógico, es igual que que si intentáramos asignar el maldito valor nulo a un integer.
Esto puede causar ligeras molestias para la gestión de valores "indeterminados", puesto que estaríamos obligados, por ejemplo, a utilizar otro miembro de la enumeración para representar este valor, como en el siguiente código en Visual Basic .Net:
Public Enum Estado
Indeterminado = 0
Correcto = 1
Incorrecto = 2
End EnumSin embargo, hay ocasiones en la que resulta más interesante poder disponer del valor nulo como una opción para las variables del tipo de nuestra enumeración. Por ejemplo, si estamos desarrollando componentes que leen de una base de datos donde la indeterminación se representa por un nulo, sería más natural poder trasladar esta particularidad al modelo de objetos.
Y para esto inventaros los tipos anulables, de los que ya publiqué un post hace tiempo (Nullable Types, o cómo convivir con los nulos). Dado que las enumeraciones son tipos valor, nada impide crear tipos anulables de enumeraciones:
' VB.NET
Dim estado1 As Nullable(Of Estado)
Dim estado2 As Nullable(Of Estado)
estado1 = Estado.Correcto
estado2 = Nothing
// C#
Estado? estado1 = Estado.Correcto;
Estado? estado2 = null;
miércoles, 12 de septiembre de 2007
Javascript, ese lenguaje tan de moda, nos permite manipular en cliente algunas propiedades de los utilísimos validadores de ASP.Net.
La función ValidatorEnable, proporcionada por la plataforma .Net en cliente y utilizable mediante scripting, nos permite habilitar o deshabilitar validadores de nuestros Webforms sin necesidad de hacer un postback. Un ejemplo de uso sería el siguiente:
El segundo parámetro sería el booleano (true o false) que indica si se desea activar o desactivar el validador. El primer parámetro es el ID en cliente del mismo, y podemos obtenerlo usando la propiedad ClientID del control; por ejemplo, imaginando que tenemos un validador de tipo RequiredFieldValidator llamado Rfv en nuestro Webform, una llamada a la función anterior sería algo así como:
La función ValidatorEnable, proporcionada por la plataforma .Net en cliente y utilizable mediante scripting, nos permite habilitar o deshabilitar validadores de nuestros Webforms sin necesidad de hacer un postback. Un ejemplo de uso sería el siguiente:
function onOff(validatorId, activar)
{
var validator =
document.getElementById(validatorId);
ValidatorEnable(validator, activar);
}El segundo parámetro sería el booleano (true o false) que indica si se desea activar o desactivar el validador. El primer parámetro es el ID en cliente del mismo, y podemos obtenerlo usando la propiedad ClientID del control; por ejemplo, imaginando que tenemos un validador de tipo RequiredFieldValidator llamado Rfv en nuestro Webform, una llamada a la función anterior sería algo así como:
function algo( )
{
onOff("<%= Rfv.ClientID %>", true);
}
domingo, 20 de mayo de 2007
Hace unos días publicaba un paso a paso donde mostraba cómo invocar servicios web desde el cliente utilizando Javascript y las magníficas extensiones ASP.NET 2.0 AJAX, y pudimos ver lo sencillo que resultaba introducir en nuestras páginas web interacciones con el servidor impensables utilizando el modelo tradicional petición-respuesta de página completa.
Sin embargo, la infraestructura Ajax nos brinda otra forma de invocar funcionalidades de servidor sin necesidad de crear servicios web de forma explícita: los métodos de página (Page Methods). El objetivo: permitirnos llamar a métodos estáticos de cualquier página (.aspx) desde el cliente utilizando Javascript y, por supuesto, sin complicarnos mucho la vida. Impresionante, ¿no?
En este post vamos a desarrollar un ejemplo parecido al anterior, en el que tendremos una página web con un cuadro de edición para introducir nuestro nombre y un botón, cuya pulsación mostrará por pantalla el resultado de la invocación de un método del servidor, y todo ello, por supuesto, sin provocar recargas de página completa. El resultado vendrá a ser algo así:

Ah, para que no se diga que soy partidista ;-) esta vez vamos a desarrollarlo en Visual Basic .NET (aunque la traducción a C# de la porción de servidor es directa), y de nuevo con Visual Studio 2005.
En primer lugar, hemos de crear la solución (Visual Studio 2005) basándonos en la plantilla "ASP.NET Ajax-Enabled web application" que habrá aparecido en nuestro entorno tras descargar e instalar las extensiones AJAX. Una vez elegido el nombre, se creará un proyecto con todas las referencias necesarias, el web.config adaptado, y una página (Default.aspx) que viene ya preparada con el ScriptManager listo para su uso.
En el archivo code-behind (Default.aspx.vb) añadimos el siguiente código, que será la función de servidor a la que invocaremos desde el cliente:
Obsérvese que:
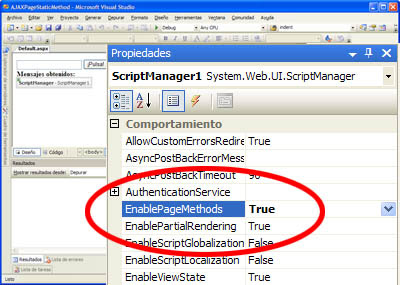
Sólo falta un detalle. Hay que indicar al ScriptManager de la página que se encargue de procesar todos los métodos públicos estáticos de la clase, que además estén marcados con el atributo anteriormente citado, y genere la infraestructura que necesitamos para utilizar de forma directa esta funcionalidad. Esto se consigue estableciendo la propiedad EnablePageMethods a true desde el diseñador.
Una vez hecho esto, introducimos en el aspx de la página los elementos de interfaz (el cuadro de texto, el botón y un label para mostrar los resultados). El código del formulario completo queda así:
Podemos ver, como en el post anterior, que todos los controles salvo el ScriptManager son de cliente, no tenemos el runat="server" en ninguno de ellos puesto que no realizaremos un envío de la página completa (postback) en ningún momento, todo se procesará en cliente y actualizaremos únicamente el contenido del label.
Por último, añadimos el script que realizará las llamadas y mostrará los resultados. La función llamar(), invocada a partir de la pulsación del botón y la de notificación de respuesta. El código es el siguiente:
Primero, fijaos en la forma de llamar a Saludame(). El ScriptManager ha creado una clase llamada PageMethods a través de la cual podemos invocar a todos los métodos de la página de forma directa.
El primer parámetro de la función es $get("nombre").value. Ya vimos el otro día que $get("controlID") es un atajo para obtener una referencia hacia el control cuyo identificador se envía como parámetro. Por tanto, $get("nombre").value obtendrá el texto introducido en el cuadro de edición.
Después de los parámetros propios del método llamado, se indica la función a la que se pasará el control cuando obtenga el resultado desde el servidor. OnOK recibirá como parámetro la respuesta de éste, el string con el mensaje de saludo personalizado, y actualizará el contenido de la etiqueta para mostrarlo.
En resumen, los PageMethods son una interesantísima característica del framework AJAX de Microsoft, y nos permiten llamar a funciones estáticas definidas directamente sobre las páginas aspx, evitando el engorro de definir servicios web (asmx) de forma independiente, y sobre todo, ayudando a mantener en un único punto el código relativo a una página concreta ¡y qué mejor sitio que la propia página!
(Puedes descargar el proyecto completo.)
Sin embargo, la infraestructura Ajax nos brinda otra forma de invocar funcionalidades de servidor sin necesidad de crear servicios web de forma explícita: los métodos de página (Page Methods). El objetivo: permitirnos llamar a métodos estáticos de cualquier página (.aspx) desde el cliente utilizando Javascript y, por supuesto, sin complicarnos mucho la vida. Impresionante, ¿no?
En este post vamos a desarrollar un ejemplo parecido al anterior, en el que tendremos una página web con un cuadro de edición para introducir nuestro nombre y un botón, cuya pulsación mostrará por pantalla el resultado de la invocación de un método del servidor, y todo ello, por supuesto, sin provocar recargas de página completa. El resultado vendrá a ser algo así:
Ah, para que no se diga que soy partidista ;-) esta vez vamos a desarrollarlo en Visual Basic .NET (aunque la traducción a C# de la porción de servidor es directa), y de nuevo con Visual Studio 2005.
En primer lugar, hemos de crear la solución (Visual Studio 2005) basándonos en la plantilla "ASP.NET Ajax-Enabled web application" que habrá aparecido en nuestro entorno tras descargar e instalar las extensiones AJAX. Una vez elegido el nombre, se creará un proyecto con todas las referencias necesarias, el web.config adaptado, y una página (Default.aspx) que viene ya preparada con el ScriptManager listo para su uso.
En el archivo code-behind (Default.aspx.vb) añadimos el siguiente código, que será la función de servidor a la que invocaremos desde el cliente:
<WebMethod()> _
Public Shared Function Saludame(ByVal Nombre As String) As String
Return "Hola a " + Nombre _
+ " desde el servidor, son las " _
+ DateTime.Now.ToString("hh:mm:ss")
End Function
Obsérvese que:
- El método es público y estático. Lo primero es obvio, puesto que el ScriptManager necesitará mapearlo al cliente y para ello deberá acceder mediante reflexión a sus propiedades, y lo segundo también, puesto que las invocaciones al mismo no se efectuarán desde instancias de la clase, imposibles de conseguir en cliente.
- Está adornado con un atributo WebMethod, que indica al ScriptManager que el cliente podrá invocarlo utilizando Javascript.
Sólo falta un detalle. Hay que indicar al ScriptManager de la página que se encargue de procesar todos los métodos públicos estáticos de la clase, que además estén marcados con el atributo anteriormente citado, y genere la infraestructura que necesitamos para utilizar de forma directa esta funcionalidad. Esto se consigue estableciendo la propiedad EnablePageMethods a true desde el diseñador.
Una vez hecho esto, introducimos en el aspx de la página los elementos de interfaz (el cuadro de texto, el botón y un label para mostrar los resultados). El código del formulario completo queda así:
<form id="form1" runat="server">
<input type="text" id="nombre" />
<input id="Button1" type="button"
value="¡Pulsa!" onclick="llamar();" />
<br />
<strong>Mensajes obtenidos:</strong>
<br />
<label id="lblMensajes" />
<asp:ScriptManager ID="ScriptManager1"
runat="server" EnablePageMethods="True" />
</form>
Podemos ver, como en el post anterior, que todos los controles salvo el ScriptManager son de cliente, no tenemos el runat="server" en ninguno de ellos puesto que no realizaremos un envío de la página completa (postback) en ningún momento, todo se procesará en cliente y actualizaremos únicamente el contenido del label.
Por último, añadimos el script que realizará las llamadas y mostrará los resultados. La función llamar(), invocada a partir de la pulsación del botón y la de notificación de respuesta. El código es el siguiente:
<script type="text/javascript">
function llamar()
{
PageMethods.Saludame($get("nombre").value , OnOK);
}
function OnOK(msg)
{
var etiqueta = $get("lblMensajes");
etiqueta.innerHTML += msg + "<br />";
}
</script>
Primero, fijaos en la forma de llamar a Saludame(). El ScriptManager ha creado una clase llamada PageMethods a través de la cual podemos invocar a todos los métodos de la página de forma directa.
El primer parámetro de la función es $get("nombre").value. Ya vimos el otro día que $get("controlID") es un atajo para obtener una referencia hacia el control cuyo identificador se envía como parámetro. Por tanto, $get("nombre").value obtendrá el texto introducido en el cuadro de edición.
Después de los parámetros propios del método llamado, se indica la función a la que se pasará el control cuando obtenga el resultado desde el servidor. OnOK recibirá como parámetro la respuesta de éste, el string con el mensaje de saludo personalizado, y actualizará el contenido de la etiqueta para mostrarlo.
En resumen, los PageMethods son una interesantísima característica del framework AJAX de Microsoft, y nos permiten llamar a funciones estáticas definidas directamente sobre las páginas aspx, evitando el engorro de definir servicios web (asmx) de forma independiente, y sobre todo, ayudando a mantener en un único punto el código relativo a una página concreta ¡y qué mejor sitio que la propia página!
(Puedes descargar el proyecto completo.)
lunes, 30 de abril de 2007
Ya comentaba en otros posts (como este y este otro) qué eran los GUID (Globally Unique IDentifiers), y lo buenos que podían resultar como identificadores de elementos de forma única y universal.
Sin embargo, su utilidad se vería reducida en la práctica si su creación fuera compleja. Pero nada más lejos de la realidad, la obtención de un Guid es extremadamente sencilla:
Podemos observar que la clase (estructura) Guid (incluida en el namespace System) contiene un método estático que nos permite generar y obtener objetos de este tipo de forma directa. Además, recordemos que cada vez que generamos un GUID tenemos la seguridad casi absoluta de que será único, lo que hace que podamos utilizarlo directamente como identificador del elemento deseado.
Sin embargo, su utilidad se vería reducida en la práctica si su creación fuera compleja. Pero nada más lejos de la realidad, la obtención de un Guid es extremadamente sencilla:
// C#:
Guid g = Guid.NewGuid(); // Obtiene un nuevo GUID
Console.WriteLine(g); // Lo muestra por consola
' Visual Basic .Net:
Dim g as Guid = Guid.NewGuid() ' Obtiene un nuevo GUID
Console.WriteLine(g) ' Lo muestra por consola
Podemos observar que la clase (estructura) Guid (incluida en el namespace System) contiene un método estático que nos permite generar y obtener objetos de este tipo de forma directa. Además, recordemos que cada vez que generamos un GUID tenemos la seguridad casi absoluta de que será único, lo que hace que podamos utilizarlo directamente como identificador del elemento deseado.












