

Aunque el código fuente de la plataforma estaba disponible en CodePlex prácticamente desde que empezaron a publicarse las primeras previews de la plataforma, es ahora cuando, en palabras de Scott Hanselman, ha pasado de ser “source opened” a “open source”.
Muchas de las grandes figuras implicadas en el proyecto han publicado ya en sus respectivos blogs el esperado anuncio, felicitándose por el logro conseguido, una nueva demostración del cambio de rumbo de Microsoft respecto al código abierto.
También Miguel de Icaza, quien por cierto recientemente anunciaba la disponibilidad de Mono 2.4 y MonoDevelop 2.0, ya ha comentado que se trata de una magnífica noticia no sólo para el equipo del Proyecto Mono, sino para toda la comunidad de desarrolladores ASP.NET.
Enlaces (en inglés):
- ASP.NET MVC 1.0 (ScottGu)
- Microsoft ASP.NET MVC 1.0 is now Open Source MS-PL (Hanselman)
- Open Source License For System.Web.Mvc (Haack)
- Rolling a Bubble – ASP.NET MVC is Ms-PL (Connery)
- Microsoft releases ASP.NET under the MS-PL License (Miguel de Icaza)
- Download ASP.NET MVC 1.0
Publicado en: www.variablenotfound.com
 En el primer post intentamos describir qué eran las expresiones lambda, resumiendo muy brevemente su utilidad, así como los aspectos sintácticos de este tipo de construcciones del lenguaje. El segundo lo enfocamos a explicar el papel de las lambda como funciones anónimas, su estrecha relación con los delegados, y su forma de utilización.
En el primer post intentamos describir qué eran las expresiones lambda, resumiendo muy brevemente su utilidad, así como los aspectos sintácticos de este tipo de construcciones del lenguaje. El segundo lo enfocamos a explicar el papel de las lambda como funciones anónimas, su estrecha relación con los delegados, y su forma de utilización.En esta tercera y última entrega de la serie, vamos a centrarnos en otra de las grandes utilidades de las expresiones lambda en .NET framework: la definición de árboles de expresión.
Las lambda como árboles de expresión
 Los compiladores de C# y VB.NET pueden, bajo determinadas circunstancias, utilizar las lambdas para crear un árbol de expresión, una estructura en memoria que representa en forma de árbol las operaciones a realizar, y en el orden que hay que hacerlo, para lograr un objetivo. Si lo queréis ver más claro, observad el diagrama adjunto, en el que se muestra el árbol de expresión correspondiente a una función lambda que obtiene la media de dos números.
Los compiladores de C# y VB.NET pueden, bajo determinadas circunstancias, utilizar las lambdas para crear un árbol de expresión, una estructura en memoria que representa en forma de árbol las operaciones a realizar, y en el orden que hay que hacerlo, para lograr un objetivo. Si lo queréis ver más claro, observad el diagrama adjunto, en el que se muestra el árbol de expresión correspondiente a una función lambda que obtiene la media de dos números.Esto es muy diferente al caso anterior, donde hablábamos de las lambda como funciones ejecutables que podían ser referenciadas por delegados e invocadas de forma directa. Entonces las expresiones lambda eran transformadas en tiempo de compilación en código ejecutable (de hecho, en métodos estáticos que pueden ser consultados usando Reflector u otros desensambladores), y por ello podíamos utilizarlas de forma directa.
En el caso de los árboles de expresión, la compilación no genera código ejecutable correspondiente a las instrucciones definidas en la lambda, sino el código para crear y llenar el árbol con dicha expresión. Después, en tiempo de ejecución, será posible recorrer dicho árbol, analizarlo, seriarlo para almacenarlo o moverlo a otras capas, e incluso compilarlo para poder lanzar su ejecución.
Pero paremos aquí un momento... según lo dicho, cuando el compilador se encuentra con una expresión lambda, por ejemplo
x => x * 2, puede optar por generar una función anónima o por generar el código de llenado del árbol, ¿cómo sabe lo que debe hacer?Pues bien, el compilador elegirá la opción adecuada dependiendo del tipo de la referencia a la expresión lambda. Si se trata de un tipo de delegado como
Func o Action, generará código ejecutable y las referencias a la función serán tratados como delegados; si se usa el tipo Expression, que veremos más adelante, se generará el árbol de expresión y las referencias no se considerarán delegados, sino objetos de este tipo. Por este motivo no podemos utilizar para declarar lambdas variables locales de tipo implícito: el compilador no sabría qué hacer.
var dobla = a => a * 2; // Error: no se puede asignar
// una expresión lambda a una variable
// local de tipo implícito.
Definición de árboles con expresiones lambda
Para definir un árbol de expresión a partir de una lambda debemos utilizar el tipo genéricoExpression<TipoDelegado>, siendo TipoDelegado un delegado como Action o Func de los descritos en el post anterior. ¿Que esto os parece confuso? Pues esperad a ver el ejemplo... ;-) Expression<Func<int, int, int>> media = (a, b) => (a + b) / 2;
En realidad, aparte de lo difícil de leer que es una declaración de este tipo, la idea es bastante sencilla. Lo que estamos indicando al compilador es que queremos montar un árbol de una expresión de la que conocemos el tipo de los parámetros de entrada y del valor de retorno, datos que indicamos mediante el delegado que utilizamos como argumento genérico de la clase
Expression, la porción que he marcado de amarillo en el ejemplo anterior. Además, este delegado lo utilizaremos cuando queramos convertir el árbol de expresión en código ejecutable, más adelante veremos cómo.Para que quede claro, ahí van algunos ejemplos más:
// Árbol de expresión de una función que determina
// si el parámetro que le llega es par
Expression<Func<int, bool>> esPar = a => a%2==0;
// Árbol de expresión de una función
// que retorna el máximo de dos números.
Expression<Func<int, int, int>> maximo =
(a, b) => a > b ? a:b;
// Árbol de expresión de una función que
// retorna un string transformado
Expression<Func<string, string>> TrimMays =
a => a.Trim().ToUpper();
// Árbol de expresión de una acción
// sin parámetros que escribe por consola la fecha y hora.
Expression<Action> accion =
() => Console.WriteLine(DateTime.Now);
Fijaos que el tipo de delegado
Action o Func, que son los parámetros genéricos de la expresión, son los que definen los tipos de parámetros y retornos de la lambda. En el primer caso, el Func<int, bool> define que la función recibe un entero y retorna un booleano; en el último caso, ni se envía ni se recibe nada, de ahí que utilicemos un delegado Action.Un detalle importante, antes de que se me olvide comentarlo. Los árboles de expresión sirven, como su nombre indica, para almacenar expresiones. Esto limita el tipo de construcciones de código que podemos usar en las lambdas que los definen: no está permitido utilizar asignaciones, bloques con llaves { }, ni bucles... debe tratarse de una expresión que pueda representarse en una jerarquía de árbol. Si intentamos saltarnos estas restricciones, el compilador generará un error, aunque el tipo de delegado sea correcto y la función lambda también, como en el siguiente ejemplo:
// Suma los n primeros naturales
Expression<Func<int, int>> expr =
n => {
int t = 0;
for (int i = 1; i <= n; t += i++) ;
return t;
};
// Error CS0834: Una expresión lambda con cuerpo no puede ser
// convertida a árbol de expresión
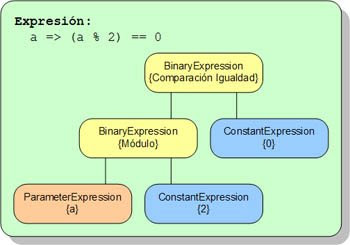 Volvemos un poco atrás ahora para recordar cuando comentaba que la compilación de una lambda no genera código ejecutable correspondiente a las instrucciones definidas en la expresión, sino el código para llenar el árbol de expresión que la representa.
Volvemos un poco atrás ahora para recordar cuando comentaba que la compilación de una lambda no genera código ejecutable correspondiente a las instrucciones definidas en la expresión, sino el código para llenar el árbol de expresión que la representa. ¿Y cómo hace eso? Muy sencillo. El compilador analiza la expresión, genera la secuencia de instrucciones que compone el árbol, las compila, e introduce el resultado en el ensamblado. El siguiente ejemplo muestra cómo crear un árbol de expresión usando una lambda, y una aproximación al código equivalente que genera el compilador, para que nos podamos hacer una idea del trabajo que nos ahorra esta característica del lenguaje:
// Árbol definido con una lambda:
Expression<Func<int, bool>> esPar = a => a % 2 == 0;
// Y el mismo árbol definido a mano,
// lo que genera el compilador automáticamente:
ParameterExpression param = Expression.Parameter(typeof(int), "a");
ConstantExpression dos = Expression.Constant(2, typeof(int));
ConstantExpression cero = Expression.Constant(0, typeof(int));
BinaryExpression modulo = Expression.Modulo(param, dos);
BinaryExpression comparacion = Expression.Equal(modulo, cero);
Expression<Func<int, bool>> esPar2 =
Expression.Lambda<Func<int, bool>>(comparacion, param);
Uso de los árboles de expresión
Ya sabemos qué son los árboles de expresión y cómo podemos definirlos, pero aún no le hemos visto sentido a su existencia. Pero lo tiene, vaya si lo tiene ;-)En primer lugar, el hecho de poder definir el árbol partiendo de una expresión lambda, además de comodidad a la hora de codificar, nos permite aprovechar el tipado fuerte y la potencia del intellisense para evitar errores. En el ejemplo anterior, las probabilidades de que nos equivoquemos creando el árbol de forma manual son muy superiores a que ocurra si utilizamos la sintaxis lambda.
Segundo, fijaos que en ningún momento se está generando código IL o compilando la expresión representada por la lambda. Estamos creando una estructura en memoria. Esto quiere decir que después podemos procesar esta información como estimemos conveniente; podemos, por ejemplo, analizar su contenido, recorrerlo, seriarlo, o transformarlo, en función de nuestras necesidades. Es ideal, por tanto, cuando tengamos interés en interpretar una expresión para realizar alguna acción con ella.
Vamos a ver ahora varios ejemplos para ilustrar el uso de las lambdas y árboles de expresión en el mundo real.
Linq
En el caso de Linq aplicado a un proveedor externo de datos relacional (por ejemplo, las tecnologías Linq to SQL, o Entity Framework), no tiene interés alguno el código ejecutable asociado a una expresión, sino su estructura, pues al final va a ser traducida al lenguaje o tecnología del almacén de información. Supongamos la siguiente consulta para obtener los productos que comienzan por "S": // Usando una consulta Linq:
var datos = from p in productos
where p.Nombre.StartsWith("S")
select p;
// O su equivalente usando
// operadores de consulta:
var datos = productos.Where(p=>p.Nombre.StartsWith("S"));
La lambda resaltada servirá para crear un árbol de expresión con las condiciones indicadas, pues el método de extensión
Where aplicado acepta un predicado de tipo Expression. No se genera ningún método anónimo para la expresión lambda, ni se traduce a IL su contenido: sólo interesa para definir la expresión que será introducida en el árbol. Más adelante, en el momento de extraer realmente la información desde el almacén correspondiente, el componente proveedor de datos recorrerá y analizará la estructura en memoria, generando su equivalente en SQL, que es lo que lanzará al SGBD para obtener los datos.Por cierto, existen en la actualidad una gran cantidad de proveedores de Linq, capaces de transformar los árboles de expresión en consultas a casi cualquier tipo de almacén. Fijaos que la posibilidad de separar la codificación lambda de la interpretación de la expresión hace posible su utilización en una gran variedad de ámbitos.
Cálculo simbólico
Otro ejemplo que ilustra muy bien las posibilidades de los árboles de expresión, de mano del maestro Octavio Hernández. Se trata del artículo Cálculo simbólico en C# 3.0, publicado en la web de El Guille a principios de 2007.A lo largo del artículo se realiza la implementación básica de un sistema de cálculo de derivadas de funciones matemáticas partiendo de un árbol de expresiones. El proceso, que el autor va explicando paso a paso, consiste en analizar el árbol, e ir generando otro árbol con el resultado de la derivación de cada expresión encontrada. A continuación se muestra la porción de código donde se realiza la derivación de una operación de suma, utilizando recursividad para derivar además cada uno de los sumandos:
private static Expression Derive(this Expression e, string paramName)
{
switch (e.NodeType)
{
[...]
// sum rule
case ExpressionType.Add:
{
Expression dleft =
((BinaryExpression) e).Left.Derive(paramName);
Expression dright =
((BinaryExpression) e).Right.Derive(paramName);
return Expression.Add(dleft, dright);
}
[...]
}
}
Al final, fijaos que de nuevo no nos interesa en absoluto la lambda como función anónima ni delegado, sino la estructura de la propia expresión, de forma que podamos recorrerla y transformarla en otra expresión, en este caso la función derivada de la original. El siguiente ejemplo muestra el uso de esta clase:
Expression<Func<double, double>>
funcion = x => x*x; // f(x)=x^2
Expression<Func<double, double>>
derivada = funcion.Derive(); // f'(x)=2*x
Console.WriteLine(derivada); // Muestra la función derivada:
// x => ((x * 1) + (1 * x))
Creedme, vale la pena echarle un vistazo.
ASP.NET MVC
Un último ejemplo, que demuestra la versatilidad del uso de lambdas y árboles de expresión en multitud de escenarios. En el framework ASP.NET MVC, es posible crear enlaces hacia acciones desde dentro de las vistas (páginas .ASPX), que no son sino métodos dentro de unas clases concretas llamadas "controladores". El caso es que para hacer referencia a un método del controlador, pueden utilizarse estas dos vías, de resultado idéntico: // Obtiene un enlace al método "ChangePassword"
// de la clase "AccountController":
Html.ActionLink("Cambiar clave", "ChangePassword", "Account")
// Lo mismo, pero usando un árbol de expresión:
Html.ActionLink<AccountController>
(acc=>acc.ChangePassword(), "Cambiar clave")
Aunque el resultado es el mismo, la segunda usa un árbol de expresión para realizar la referencia al método
ChangePassword de la clase AccountController. La implementación del método ActionLink recorre el árbol generado desde la expresión lambda para obtener el nombre del controlador y del método, por lo que es equivalente a primera fórmula, pero beneficiándose de las ventajas del tipado fuerte y del intellisense en la edición.Los árboles de expresión como código ejecutable
Hasta ahora siempre me he referido a los árboles de expresión como entidades de almacenamiento. De alguna u otra forma, estaba equiparando su utilidad a la cualquier estructura de datos que permitiera guardar y procesar información, lo cual es cierto pero sólo parcialmente.Los árboles de expresión aportan una característica adicional: se pueden convertir en código ejecutable. Es decir, es posible compilar un árbol de expresión en tiempo de ejecución, dando lugar a una función anónima a la que podemos tener acceso, es decir, invocarla, a través de sus delegados.
Veámoslo con un caso concreto. Retomando el ejemplo de obtención de derivadas, sería perfectamente posible obtener el valor de la función derivada en un punto ampliando ligeramente el código visto anteriormente:
Expression<Func<double, double>>
funcion = x => x*x; // f(x)=x^2
Expression<Func<double, double>>
derivada = funcion.Derive(); // f'(x)=2*x
// Compilamos la función derivada
// y obtenemos un delegado a la misma:
Func<double, double> funcDerivada = derivada.Compile();
double result = funcDerivada(6); // Obtenemos el valor de la función
// invocando al delegado con x=6
Console.WriteLine(result); // Muestra "12"
Como se puede observar en el código, la llamada al método
Compile() devuelve un delegado del tipo Func indicado en el parámetro genérico de la expresión, que apunta hacia la función anónima creada "al vuelo" a partir de las expresiones contenidas en el árbol. Es decir, desde la definición simbólica contenida en el árbol ¡obtenemos código ejecutable!Aunque espectacular, en realidad no hay nada mágico en esta característica: se trata de ir recorriendo el árbol y emitiendo el código IL correspondiente a cada expresión, que está perfectamente tipificada y definida. En el namespace
System.Linq.Expressions existe una bonita clase interna llamada ExpressionCompiler que se dedica exclusivamente a ello, utilizando herramientas suministradas por System.Reflection.Emit, como los generadores de lenguaje intermedio ILGenerator.¡Y hasta aquí hemos llegado!
A lo largo de estos tres posts hemos recorrido las principales características y utilidades de las expresiones lambda. Obviamente, han quedado cosas por detrás; no era objetivo de esta serie profundizar demasiado, sino ofrecer una visión suficiente para animar a los desarrolladores a utilizar esta potente característica que nos ofrece C# (y VB.NET).Espero que os haya sido una lectura útil, al menos tanto como me ha resultado a mí su escritura. Ah, y para consultas, sugerencias o puntualizaciones, por aquí me tenéis.
Publicado en: www.variablenotfound.com.
En el post anterior intentamos realizar una primera aproximación a las expresiones lambda, centrándonos en obtener una definición lo suficientemente cercana, que nos permitiera conocer a grandes rasgos qué son, así como en describir su forma general y sus particularidades sintácticas.En esta segunda entrega vamos a profundizar un poco en el papel de las expresiones lambda como vía para definir muy rápidamente funciones anónimas y los tipos de delegados con los que podemos referenciarlas, y por tanto, invocarlas.
Ya en el tercer post describiremos el papel de las expresiones lambda como herramienta de generación de árboles de expresión.
Las lambdas como funciones anónimas
Como habíamos insinuado anteriormente, uno de los usos de las expresiones lambda es permitir la definición "en línea" de funciones anónimas. De hecho, en tiempo de compilación las expresiones lambda son convertidas en métodos a los que el compilador establece un nombre único autogenerado, como los ejemplos mostrados a continuación:
Las referencias a estas funciones anónimas son transformadas en delegados (punteros) a las mismas, lo que nos permitirá, por ejemplo, invocarlas desde el código. En la práctica esto quiere decir que podemos asignar una lambda a una variable y ejecutarla como muestra el siguiente pseudocódigo:
delegado duplica = x => x * 2;
escribe duplica(2); // Escribe un 4En este primer acercamiento, fijaos que
duplica es el nombre del delegado, la función definida en forma de expresión lambda no tiene nombre, será el compilador el que se asigne uno. Veamos cómo se concreta esta idea en C#. En el siguiente código, la variable
duplica apunta hacia una función anónima definida a través de la expresión lambda en cuya implementación lo único que se hace es retornar el doble del valor que le llega como parámetro. Vemos también cómo podemos utilizarla de forma directa: Func<int, int> duplica = x => x * 2;
int result = duplica(7); // result vale 14Sólo con objeto de que podáis entender el código anterior, os adelantaré que la porción
Func<int, int> es una forma rápida de tipificar el delegado, indicando que duplica apunta a una función que espera un entero como parámetro de entrada, y que su valor de retorno será otro entero. Esto lo veremos dentro de un momento.De la misma forma que asignamos la expresión lambda a una variable, podemos hacerlo también para indicar el valor de un parámetro a un método que acepte un delegado concreto. Por ejemplo, el siguiente código muestra un método llamado
calcula que recibe un valor entero y una referencia a una función, retornando el resultado de efectuar dicha operación sobre el entero proporcionado: // Es método ejecuta la función indicada por
// el parámetro operacion, enviándole el valor especificado,
// y retorna el resultado obtenido de la misma.
public int calcula(int valor, Func<int, int> operacion)
{
return operacion(valor); // retorna el resultado de aplicar la
// expresión indicada al valor.
}
// Usos posibles:
int i = calcula(4, x => x / 2); // Le pasamos una referencia a la
// función que estamos definiendo sobre
// la marcha. El resultado es que i=2.
int j = calcula(4, duplica); // Le pasamos la variable "duplica",
// que es una referencia a la lambda
// definida anteriormente. J valdrá 8.
Seguro que a los más viejos del lugar esto le recuerda a los Codeblocks que utilizábamos en Clipper a principios de los 90 (uuf, cómo pasa el tiempo...). ¿Todavía reconocéis el siguiente código?
bDuplica := { |n| n*2 }
? EVAL(bDuplica, 7) // Muestra un 14Una consecuencia directa de que las expresiones lambdas sean referenciadas a través de delegados es que podemos utilizarlas en cualquier sitio donde se acepte un delegado, con la única precaución de escribirla teniendo en cuenta el tipo de su retorno y los parámetros que recibe. Un ejemplo claro lo tenemos en la suscripción a eventos, donde la técnica habitual consiste en utilizar un delegado a un método en el que se implementa la lógica del tratamiento de los mismos, algo como:
// Nos suscribimos al evento MouseMove:
this.MouseMove += new MouseEventHandler(this.Form1_MouseMove);
[...]
// Tratamiento del evento MouseMove:
private void Form1_MouseMove(object sender, MouseEventArgs e)
{
this.Text = e.X + "," + e.Y;
}Como sabemos, podemos suscribirnos al evento
MouseMove añadiéndole delegados del tipo MouseEventHandler, definido en System.Windows.Forms, cuya firma indica que recibe un parámetro de tipo object, otro de tipo MouseEventArgs y no retorna ningún valor, exactamente igual que sería un delegado anónimo (C# 2.0) escrito así: this.MouseMove += delegate(object sender, MouseEventArgs args)
{
this.Text = args.X + "," + args.Y;
};
Y dado que las lambdas pueden sustituir de forma directa a cualquier delegado, podemos utilizarlas para conseguir un código más compacto:
this.MouseMove += (sender, args) => {
this.Text = args.X + "," + args.Y;
};
Llegados a este punto es conveniente aclarar que las expresiones lambda son características introducidas en los lenguajes, y por tanto en sus compiladores, pero no en la plataforma de ejecución (CLR) en sí. Por tanto, todo lo descrito hasta el momento era posible realizarlo antes que las lambda aparecieran por el horizonte, aunque de forma un poco más tediosa, utilizando mecanismos que la versión 2.0 del framework ponía a nuestra disposición, como los delegados y métodos anónimos. En este sentido, el uso de expresiones lambda aportan mucha simplicidad, elegancia y legibilidad al código.
Esto explica, además, que Visual Studio 2008 sea capaz de generar código para .NET 2.0 a partir de código fuente C# 3.0.
Tipos de delegados de expresiones lambda
Antes ya había adelantado que la definiciónFunc<int, int> era simplemente una forma de indicar el tipo del parámetro que recibía la función lambda, así como el tipo del valor de retorno. En realidad, lo único que estábamos haciendo era definir, de forma muy sencilla y rápida, el delegado hacia la función. Vamos a concretar esto un poco más, pero antes de continuar, una cosa: si para tí un genérico es un tipo de medicamento, mejor que leas algo sobre el tema antes de continuar, pues en caso contrario es posible que te pierdas un poco ;-). Pues probar leyendo una introducción a los generics en c#, o la Guía de programación de C#.
.NET Framework ofrece en el espacio de nombres
System un conjunto de definiciones de genéricas de delegados para que podamos utilizarlos para "apuntar" hacia las funciones definidas mediante expresiones lambda, llamados Action y Func.Utilizaremos los tipos
Func para definir referencias a expresiones lambda que retornen un valor, o sea, funciones. De ahí su nombre. Los tipos Action, en cambio, están destinados a referenciar a lambdas que realicen acciones y que no retornen ningún valor. De ahí su nombre también. ;-)Una de estas definiciones es la que habíamos usado en un ejemplo anterior:
Func<int, int> duplica = x => x * 2;Como se puede observar, al tratarse de una referencia a una función que retorna un valor, hemos utilizado un tipo
Func con dos parámetros genéricos, que corresponde con la siguiente declaración existente en el espacio de nombres System: public delegate TResult Func<T, TResult>(T arg);Por ello, cuando declarábamos que la variable
duplica era del tipo Func<int, int>, lo que indicábamos era, en primer lugar que el parámetro que necesitaba la lambda era un int, y que ésta nos devolvería también un int, es decir, lo mismo que si hubiéramos definido duplica así, utilizando métodos anónimos de C# 2.0: // En el área de declaraciones:
public delegate int Duplicador(int arg);
...
// En el código:
Duplicador duplica = delegate(int k) { return k*2 };
Obviamente, la sintaxis lambda es mucho más compacta y expresiva.
En la práctica, lo único que tenemos que tener claro a la hora de referenciar una función lambda es el tipo de cada uno de los parámetros que usa, y el tipo de retorno. Estos se introducen, en ese orden, en los parámetros genéricos de la clase
Func y listo. Como esto debe quedar claro, ahí van unos ejemplos de definición y uso: // Recibe un entero y retorna un booleano:
Func<int, bool> esPar = x => x%2==0;
Console.WriteLine(esPar(2)); // Muestra "True"
// Recibe dos enteros, retorna otro entero:
Func<int, int, int> suma = (a,b) => a+b;
Console.WriteLine(suma(2,3)); // Muestra "5"
// No recibe nada, retorna un texto:
Func<string> hora = () => "Son las "
+ DateTime.Now.ToShortTimeString();
Console.WriteLine(hora()); // Muestra "Son las 14:21:10"
Es importante saber que en el framework están definidos los delegados
Func<tipo1, tipo2..., tipoResult> para funciones de hasta cuatro parámetros. Si necesitamos más deberemos definir los delegados a mano, aunque esto es realmente sencillo utilizando una de las declaraciones existentes y añadiéndole el número de parámetros que deseemos. Por ejemplo, para seis parámetros la definición del genérico sería algo así como: public delegate
TResult Func<T1, T2, T3, T4, T5, T6, TResult>
(T1 p1, T2 p2, T3 p3, T4 p4, T5 p5, T6 p6);Pero ahora aparece un pequeño problema: las funciones sin retorno no pueden referenciarse con delegados de tipo
Func, puesto que el framework .NET no soporta la instanciación de tipos genéricos utilizando parámetros void (ECMA 335, sección 9.4, pág. 153). Por tanto, no podríamos declarar un delegado como Func<int, void> para apuntar hacia una función que recibe un entero y no devuelve nada. Si lo pensáis un poco, este es el motivo de que no exista ninguna sobrecarga de la clase Func sin parámetros genéricos, pues como mínimo debemos indicar el tipo del valor de retorno.La clave para cubrir estos casos se encuentra en el tipo
Action. Como comentaba unas líneas más arriba, el objeto de estos tipos de delegados es apuntar a expresiones lambda que realicen acciones y que no retornen ningún valor, por lo que sus parámetros genéricos describirán exclusivamente los tipos de los parámetros de la función. En este caso, como es obvio, sí existe una clase no parametrizada Action para apuntar a funciones sin parámetros, además de disponer de genéricos que cubren las acciones de hasta cuatro parámetros. Veamos unos ejemplos: // Acción sin parámetros (no genérica):
Action saluda = () => Console.WriteLine("hola");
saluda(); // Muestra "hola";
// Acción que recibe un string
Action<string> apaga = motivo => {
log(motivo);
shutdown();
};
apaga("mantenimiento"); // Apaga el sistema
Por último, me parece interesante recordar algo que había comentado en el post anterior, que en las expresiones lambda no era necesario indicar el tipo de los parámetros ni del retorno porque el compilador los infería del contexto. Como podemos ver, lo tiene bastante fácil, puesto que simplemente debe tomar la definición del delegado para conocerlos; por eso no es necesario introducir redundancias como las siguientes:
Func<int, int> duplica = (int a) => (int)(a * 2); // ¡Redundante!
// Forma más cómoda:
Func<int, int> duplica = a => a * 2; // Ok!En cualquier caso, si por algún motivo es necesario utilizar la forma explícita, sabed que no se permite hacerlo de forma parcial, es decir, o le ponéis los tipos a todo, o no se los ponéis a nada.
Y hasta aquí esta segunda entrega. En el siguiente post, el último de la serie, estudiaremos el uso de las lambda como herramientas de definición de árboles de expresión.
Por supuesto, para cualquier duda o sugerencia, ya sabéis dónde encontrarme. :-)
Publicado en: www.variablenotfound.com.
Entre las múltiples novedades aparecidas con C# 3.0 y VB.NET 9.0, las expresiones lambda son sin duda una de las que en principio pueden parecer más complejas, probablemente por su relación con conceptos no demasiado asimilables como los delegados, inferencia de tipado, métodos anónimos, o tipos genéricos, entre otros.Sin embargo, esa aparente dificultad desaparece en cuanto se les presta un poco de atención, y una vez comprendidas aportan a los desarrolladores una potencia y agilidad difíciles de lograr con las herramientas disponibles hasta el momento. Sólo hay que ver su amplia utilización dentro del propio .NET framework, LINQ, y nuevas plataformas como ASP.NET MVC, para darse cuenta de su importancia. Y por si fuera poco, según cuentan los expertos, su uso "engancha".
A lo largo de esta serie de tres posts intentaré describir las expresiones lambda desde un punto de vista práctico, con la única pretensión de aportar algo de luz a los que todavía no han sucumbido a su poder. ;-)
El objetivo de este primer post es puramente introductorio, y trataré conceptos y nociones básicas para poder abordar los siguientes. En el segundo post de la serie trataremos las expresiones lambda como funciones anónimas, dejando para el tercero los misteriosos árboles de expresión.
Introducción a las lambda
Según la definición en la Referencia del lenguaje C# de MSDN:"Una expresión lambda es una función anónima que puede contener expresiones e instrucciones y se puede utilizar para crear delegados o tipos de árboles de expresión"En la Guía de programación de Visual Basic 9 encontramos otra definición, muy simple y pragmática:
"Una expresión lambda es una función sin nombre que calcula y devuelve un solo valor. Se pueden utilizar las expresiones lambda dondequiera que un tipo de delegado sea válido"ScottGu también aportó su granito de arena para hacer el concepto más cercano a los desarrolladores; como siempre, al grano:
"Las Expresiones Lambda aportan una sintaxis más concisa y funcional para escribir métodos anónimos."Partiendo de estas definiciones, y de otras muchas aportadas por Google ;-), está claro que las lambda son funciones, es decir, un conjunto de intrucciones capaces de retornar un valor partiendo de los parámetros que se les suministra, aunque en determinados casos es posible que no reciba ningún parámetro, o que realicen una acción sin retornar nada. Igual que una función tradicional, vaya. Y de hecho, en el cuerpo de una expresión lambda puede haber casi de todo: llamadas a otras funciones, expresiones, bucles, declaraciones de variables...
[...]
"La forma más sencilla para conceptualizar las expresiones lambda es pensar en ellas como formas de escribir métodos breves en una línea."
Sin embargo, a diferencia de los métodos o funciones habituales, las lambdas no necesitan de un identificador, puesto que se declaran in situ, justo en el momento en que van a asignarse a una variable o a utilizarse como parámetro de una función, pasando el destinatario de esta asignación a actuar como delegado, o puntero, hacia la misma, o a ser el contenedor del árbol de expresión que la representa. Ein? Chino, eh? No pasa nada, dentro de poco estudiaremos estos dos usos en profundidad, pero antes vamos a ver cómo se definen las expresiones lambda a nivel de código.
Forma de las expresiones lambda
Las expresiones lambda en C# se escriben según el patrón descrito a continuación, al que le siguen algunos ejemplos que lo ilustran e introducen algunas particularidades.Forma general: parámetros => expresión, donde:
- parámetros: lista de parámetros separados por comas
- "=>" : separador.
- expresión: implementación de las operaciones a realizar
num => num * 2 // Lambda con un parámetro que retorna
// el doble del valor que se le pasa.
(a, b) => a + b // Lambda con dos parámetros que retorna
// la suma de ambos.
num => { // Lambda con cuerpo que recibe un
int x = new Random().Next(); // entero, y retorna la suma de éste
return num+x; // con un número aleatorio.
}
() => DateTime.Now // Lambda que no recibe parámetros
// y retorna la fecha y hora del sistema.
msg => Console.WriteLine(msg); // Recibe un parámetro, realiza una
// acción y no retorna nada.
Como se puede observar, cuando sólo existe un parámetro no es necesario utilizar paréntesis en el lado izquierdo de la expresión, mientras que hay que hacerlo en todos los demás casos. También es interesante destacar que las lambda con cuerpo deben utilizar
return para retornar el valor deseado, cuando esto sea necesario.Y un último dato: fijaos que ni los parámetros ni el retorno de la función tienen indicado un tipo. Aunque puede hacerse, normalmente no será necesario puesto que el compilador podrá inferir (deducir) el tipo a partir de su contexto, más adelante veremos cómo es esto posible. Por tanto, no es necesario escribir código tan extenso como:
(int a, int b) => (int)(a+b)Y hasta aquí este primer post introductorio. En el siguiente trataremos de explicar el papel de las expresiones lambda como funciones anónimas y facilitadoras del trabajo con delegados.
Publicado en: www.variablenotfound.com.

Live Writer es una fantástica aplicación de escritorio desarrollada por Microsoft en el contexto de su iniciativa Live, cuyo objetivo es facilitar la edición y publicación de entradas en blogs y, lo más curioso, compatible con los motores más difundidos del mercado: Blogger, WordPress, LiveSpaces, LiveJournal, TypePad, y un largo etcétera. Y cuando digo compatible, al menos con Blogger, me refiero a realmente compatible, una integración casi perfecta, que hace que la edición de entradas sea una gozada.

El editor sobre el que escribimos es muy ligero, tiene las opciones justas para poder escribir y dar formato a los textos, siempre de forma visual (el famoso WYSIWYG). Aunque a primera vista puede parecer que se quedará corto, nada más lejos de la realidad; no he echado en falta prácticamente ninguna característica que realmente pudiera hacerme falta durante la escritura: formatos estándar (negritas-cursivas-tachados, subrayados), colores, tablas, alineados, listas, citas,… y siempre generando un código XHTML realmente limpio y muy bien estructurado, a diferencia de otros editores basados en web (como el de Blogger, por ejemplo).
Sólo en casos especiales (por ejemplo, la inclusión de una etiqueta <acronym> para mostrar ayuda sobre el significado de WYSIWYG, o la inclusión de código fuente marcado con <code> son los únicos casos en los que he tenido que salirme del editor visual y acceder a la vista de código fuente XHTML para introducir las etiquetas.
Otro aspecto muy importante es su extensibilidad. Existen un gran número de complementos que pueden instalarse sobre este software para dotarlo de nuevas capacidades no contempladas en el producto base. Por aunque la galería de complementos de Microsoft todavía está a cero no está muy transitada, es fácil encontrar muchos sitios web donde se ofrecen plugins de todo tipo. Por ejemplo, he encontrado uno que a priori puede resultar muy útil, Steve’s Dunn Code Formatter, que permite incluir fácilmente porciones de código formateadas como la siguiente:
try
{
calculate(); // Hard work!
}
catch (Exception ex)
{
Logger.Log(ex.Message);
throw;
}
Pero lo que sin duda más ha llamado mi atención es la gran facilidad para insertar contenidos multimedia, como álbumes de fotos, vídeos, mapas interactivos, y especialmente imágenes, que es lo que más suelo utilizar en mis posts. En este último caso, es sorprendentemente útil la capacidad de Live Writer para abrir imágenes del equipo local o pegarlas directamente desde el portapapeles (por ejemplo capturas de pantalla), ajustarlas al tamaño indicado e incluso agregarle sobre la marcha efectos como sombreados o reflejos (podéis ver ejemplos más arriba). Por fin se acabó el retoque con aplicaciones externas, tener que subir la imagen al servidor, ver cómo queda, retocarla de nuevo, volver a subirla…
Por último, el hecho de tratarse de una herramienta off-line aporta mucha agilidad, y nos brinda la posibilidad de trabajar en modo desconectado, aunque a costa de perder algunas funcionalidades para las que obviamente es necesario disponer de conexión a internet, como la edición de posts ya publicados, almacenados en el blog, o el envío directo de las entradas. En estos casos, el sistema almacena toda la información en local, para que más adelante podamos enviar los cambios realizados.
Ni que decir tiene que este post está completamente escrito sobre Live Writer, e incluso las imágenes las he generado desde la propia herramienta.
En resumen: una maravilla, imprescindible.
Descarga: Microsoft Live Writer
Publicado en: www.variablenotfound.com.
 Es bastante habitual encontrar código que captura una excepción y la vuelve a relanzar tras realizar algún tipo de operación. Sin embargo, habréis observado que existen varias fórmulas para hacerlo, y no necesariamente equivalentes:
Es bastante habitual encontrar código que captura una excepción y la vuelve a relanzar tras realizar algún tipo de operación. Sin embargo, habréis observado que existen varias fórmulas para hacerlo, y no necesariamente equivalentes:- crear y lanzar una nueva excepción partiendo de la original
- relanzar la excepción original
- dejar que la excepción original siga su camino
catch instanciamos y lanzamos otra excepción distinta a la original. Esto permite elevar excepciones a niveles superiores del sistema con la abstracción que necesita, ocultando detalles innecesarios y con una semántica más apropiada para su dominio. El siguiente ejemplo muestra una porción de código donde se están controlando distintos errores que pueden darse a la hora de realizar una transmisión de datos. Por cada uno de ellos se llevan a cabo tareas específicas, pero se elevan al nivel superior de forma más genérica, como
TransmissionException, pues éste sólo necesita conocer que hubo un error en la transmisión, independientemente del problema concreto: ...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw new TransmissionException("Host no encontrado", ex);
}
catch (TimeOutException ex)
{
increaseTimeOutValue(); // Ajusta el timeout para próximos envíos
throw new TransmissionException("Fuera de tiempo", ex);
}
...
Es importante, en este caso, incluir la excepción original en la excepción lanzada, para lo que debemos llenar la propiedad
InnerException (en el ejemplo anterior es el segundo parámetro del constructor). De esta forma, si niveles superiores quieren indagar sobre el origen concreto del problema, podrán hacerlo a través de ella.Otra posibilidad que tenemos es relanzar la misma excepción que nos ha llegado. Se trata de un mecanismo de uso muy frecuente, utilizado cuando deseamos realizar ciertas tareas locales, y elevar a niveles superiores la misma excepción. Siguiendo con el ejemplo anterior sería algo como:
...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw ex;
}
...
Este modelo es conceptualmente correcto si la excepción que hemos capturado tiene sentido más allá del nivel actual, aunque estamos perdiendo una información que puede ser muy valiosa a la hora de depurar: la traza de ejecución, o lo que es lo mismo, información sobre el punto concreto donde se ha generado la excepción.
Si en otro nivel superior de la aplicación se capturara esta excepción, o se examina desde el depurador, la propiedad
StackTrace de la misma indicaría el punto donde ésta ha sido lanzada (el código anterior), pero no donde se ha producido el problema original, en el interior del método transmitir(). Además, a diferencia del primer caso tratado, como la propiedad InnerException no está establecida no será posible conocer el punto exacto donde se lanzó la excepción inicial, lo que seguramente hará la depuración algo más ardua.La forma de solucionar este inconveniente es utilizar el tercer método de los enumerados al principio del post: dejar que la excepción original siga su camino, conservando los valores originales de la traza:
...
try
{
transmitir(datos);
}
catch (HostNotFoundException ex)
{
sendToAdmin(ex.Message); // Avisa al administrador
throw;// Eleva la excepción al siguiente nivel
}
...
En esta ocasión, si se produce la excepción
HostNotFoundException, los niveles superiores podrán examinar su propiedad StackTrace para conocer el origen concreto del problema.Publicado en: www.variablenotfound.com.












