
Las dos entradas anteriores puedes encontrarlas aquí: Etiquetas CSS 2.1 (I) y Etiquetas CSS 2.1 (II).
En la primera de ellas fueron incluidos selectores básicos, de uso muy frecuente y compatibles con todos los navegadores actuales; en la segunda se complicó un poco el tema, introduciendo otros menos conocidos y de aceptación desigual por parte de los browsers más difundidos.
A continuación seguimos describiendo el resto de selectores, muy interesantes todos ellos, pero hay que tener cuidado a la hora de utilizar, sobre todo si lo que se pretende es llegar al mayor número posible de usuarios, puesto que no son contemplados por todos los navegadores, especialmente los que salen de las fábricas de Microsoft.
Selector de hijos (>)
Permiten indicar los atributos de aquellos elementos que sean hijos de su padre. Digamos que es como un selector descendente (descrito en la primera entrega de la serie) pero exclusivamente aplicado al primer nivel de descendencia. Funciona en casi todos los navegadores excepto, como de costumbre, en Internet Explorer 6.body > p
{
/* Los párrafos de primer */
color: red; /* nivel por debajo de body */
/* se pintan en rojo */
}
Subselectores de primogénitos
Permite seleccionar un elemento, siempre que éste sea el primogénito de su padre. ¿Utilidad? Mucha. Por ejemplo, permite decirle a los <li> de una lista que el primero se pinte de forma diferente a los demás sin necesidad de marcarlo con un class="primero" o similar, como se hace normalmente.li
{
/* Los elementos de lista, */
color: red; /* siempre en rojo */
}
li:first-child
{
/* pero el primero, irá */
color: blue; /* en azul. */
}
Este subselector funciona en Firefox 1.5 o superior, IE7, Safari, Opera y Konqueror. Como casi siempre, se queda por detrás Internet Explorer 6.
Es interesante comentar que CSS nivel 3 permitirá, además, la utilización del subselector de "benjamines", :last-child, que selecciona los elementos siempre que sean el último hijo de su padre. De momento el soporte en los
navegadores es incluso menor que el anterior.
Selector de precedencia (+)
Resulta útil para seleccionar un elemento que se encuentre en el código (X)HTML codificado justo después de otro. Ojo, que cuando digo después de un elemento me refiero a seguir a un elemento completo (con su correspondiente etiqueta de apertura y cierre), no a ser descendiente suyo (que ocurriría al encontrarse tras su etiqueta de apertura); es bastante fácil confundirse en esto.p + a
{
/* Los enlaces que sigan */
color: red; /* a un párrafo, en rojo */
}
/* No afectará a: */
/* <p>Saltar a <a href="#">enlace</a></p> */
/* Sí afectará a: */
/* <p>Saltar a </p><a href="#">enlace</a> */
Subselector de atributos ([ ])
A veces los atributos de los elementos son indicativos del formato que éstos deben tomar. Para estos casos, el subselector de atributos permite:- Seleccionar elementos que tengan declarado un atributo, independientemente de su valor. Esto se consigue utilizando el selector [atributo].
img[alt]
{
/* Las imágenes con atributo */
/* alt='texto', borde rojo */
border: 4px solid red;
}
- Seleccionar elementos que presenten un atributo con un valor determinado. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[dir='rtl']
{ /* Los párrafos que se lean */
color: red; /* de derecha a izquierda */
} /* irán en rojo */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por espacios y una de ellas coincide con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo~="valor"]:
p[lang~='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* aunque el inglés no */
/* sea el único idioma */
/* Ej: lang="fr en" */
- Seleccionar elementos que presenten un atributo con un valor consistente en una lista de palabras separadas por guiones y comiencen con el valor a buscar. La forma de hacerlo es utilizando la expresión [atributo="valor"]:
p[lang='en']
{ /* Los párrafos en inglés */
color: red; /* se pintan en rojo */
} /* independientemente */
/* de su localización */
/* Ej: lang="en-US" */
Sé que casi no hace falta decirlo, pero de nuevo es IE6 el único que no interpreta estos interesantes subselectores.
¡Y esto es todo, amigos! Recapitulando, esta serie de tres posts recoge todos los selectores definidos por la W3C (salvo error u omisión por mi parte, claro) en su especificación CSS 2.1.
Sin embargo, como hemos podido ver, la
básicos, aquellos que pueden usarse con cualquier navegador sin llevarse sorpresas. En esta entrega vamos a continuar con ellos e introduciremos algunos más avanzados que no funcionan con todos los browsers pero que resulta altamente interesante conocer.
Subselectores de estado
Utilizados principalmente en los enlaces (etiquetas<a>), permiten indicar distinta presentación dependiendo del estado en el que se encuentren los mismos. Se indican siempre acompañando al selector principal al que se aplican, seguido por dos puntos y el subselector a aplicar. Tenemos los siguientes:
- Enlaces no visitados (a:link)
- Enlaces visitados previamente (a:visited)
- Enlaces activos, al pulsar sobre ellos (a:active)
- Enlaces bajo el puntero del ratón (a:hover)
- Enlaces con el foco activo (a:focus)
a:hover
{
/* Al pasear el ratón ... */
color: red; /* por encima, se pone rojo */
}
a:active
{
color: blue; /* Al pulsarlo, pasa a azul */
}
La verdad es que algunos de ellos no tienen sentido fuera de enlaces, pero otros sí.
De hecho, es perfectamente posible utilizar un selector p:hover e indicar los atributos a aplicar a todo el párrafo cuando se pasee el ratón por encima. Lo mismo ocurre para el foco, que podría aplicarse a elementos de tipo <input>. Sin embargo, la
Subselector de idioma
Permite seleccionar aquellos elementos cuyo contenido está en un idioma determinado, y, eso sí, hayan sido marcados convenientemente para identificarlo con el atributo lang. Sin embargo, su dispar aceptación por los navegadores e incluso las distintas formas de expresar el idioma en una etiqueta (lang o xml:lang) hace que no sea fácil ponerlo en práctica. El siguiente ejemplo funciona en Firefox, pero no en IE6-7:p:lang(en)
{
/* Los párrafos en inglés, */
color: red; /* siempre en rojo */
}
Subselector de primer carácter
Selecciona el primer carácter del contenido de los elementos apuntados por el selector principal. No funciona bien en IE6, pero sí en el resto de navegadores medio decentes (Firefox, Safari, Opera, Konqueror e incluso IE7).p:first-letter
{
/* La primera letra, como */
color: red; /* siempre, en rojo */
}
Subselector de primera línea
Todo lo dicho con el anterior resulta igualmente válido, a diferencia de que los estilos indicados se aplican a la primera línea del contenido.p:first-line
{
/* La primera línea del */
color: blue; /* párrafo, color azul, */
/* por cambiar un poco. */
}
Subselectores de contenido previo y posterior
Estos interesantísimos selectores permiten modificar el contenido de la página justo antes del elemento apuntado por el selector principal o justo después de éste. ¿Qué quiere decir esto? Pues que podemos modificar el contenido de la página desde la hoja de estilos CSS, aunque pueda poner un poco los pelos de punta. La pena es que los hermanos IE no lo reconocen :-/.p.ojo:before
{
/* Todos los párrafos */
/* de clase "ojo" */
content: "OJO: "; /* irán precedidos por */
/* el texto "OJO:" */
}
p.ojo:after
{
/* Todos los párrafos */
/* de clase "ojo" */
content: "FIN"; /* irán seguidos de */
/* el texto "FIN" */
}
Creo que con esto tenemos suficiente por hoy.
En el próximo post seguiremos profundizando en el escalofriante mundo de los selectores avanzados... la diversión está asegurada.
Como sabemos, CSS permite indicar cómo se verá el contenido de páginas web que componemos utilizando (X)HTML. Un ejemplo de declaración de estilo es la siguiente, que indica que todo lo que se encuentre entre <p> y </p> se dibuje negro y con fuente gruesa (negrilla):
p { color: black; font-weight: bold; }Existen dos partes importantes en esta regla: qué atributos hay que aplicar (negrilla y color negro en este caso) y a qué debemos aplicárselo (al contenido de las etiquetas <p>) de la página a la que se aplique este estilo. Los selectores son precisamente el segundo grupo, la parte de la declaración que indica qué elementos del contenido se verán afectados por los atributos especificados. De ahí su nombre "selectores".
A continuación se recogen los selectores recogidos en el estándar CSS 2.1 de la W3C. Sin embargo, dado que son bastantes y voy a incluir algunos ejemplos, incluiré en este post únicamente los más habituales y utilizados. En un post posterior (valga la redundancia) añadiré el resto.
Selector universal (*)
Los atributos especificados se aplicarán a todos los elementos del documento. Sin compasión. Un ejemplo:*
{
color: red; /* Todo en rojo */
}Selector de elemento
Permite indicar el elemento, o etiqueta, a la que se aplicará el estilo especificado. Es el más habitual, ¿a quién no le suena lo siguiente? (ojo, cuando el mismo estilo se aplica a varios elementos se pueden separar sus selectores con comas, como en el ejemplo):h1, h2 /* Afectará a las etiquetas h1 y h2... */
{
color: red; /* El rojo es bello */
}Selector de clase
Permite indicar la clase CSS a la que se aplicarán los estilos indicados. La clase deberá incluirse en el código (X)HTML de forma explícita utilizando el atributo class='[clase]' de las etiquetas implicadas.
p.textoNormal /* Afectará a las etiquetas */
{ /* <p class='textoNormal' > */
color: red; /* Rojo forever */
}
.muyGrande /* Afectará a cualquier etiqueta */
{ /* con class='muyGrande' */
font-size: 10em;
}
Selector directo
Es más específico que el anterior, puesto que únicamente afecta a la etiqueta con el ID indicado, es decir, aquella en cuya declaración se haya incluido el atributo "id" (minúsculas) y se le haya asignado un valor único en la página.p#main /* Afectará a la etiqueta <p id='main'> */
{
color: red; /* Rojo again */
}
#main /* Es igual que la anterior, */
{ /* pues sólo hay una etiqueta */
color: red; /* con id='main' en una página */
/* correcta (X)HTML. */
}
Selector descendente
Permite aumentar la especificidad de un selector, indicando tanto la etiqueta afectada como una de sus ascesoras, o en otras palabras, un elemento donde se encuentra. La profundidad con que se puede definir es ilimitada, aunque por motivos de legibilidad no creo que sea muy conveniente alargarla en exceso. Unos ejemplos:
p a /* Afecta a todos los enlaces <a> */
{ /* incluidos en párrafos <p> */
color: red;
}
ul.menu li
{ /* Los <li> pertenecientes a */
background-color: red; /* los <ul> de clase "menu" */
} /* tendrán el fondo rojo. */
ul.menu li ul li a /* Ejemplo difícil de leer:*/
{ /* Los enlaces de un <li> */
/* pertenecientes a */
background-color: blue; /* una lista incluida en un */
/* <ul> de clase "menu" */
} /* tendrán fondo azul (uuf!). */
Es importante destacar que este selector no restringe el grado de profundidad del antecesor. Es decir, "p a { color: red; }" indica que todos los <a> que tengan un antecesor <p> se verán afectados, aunque no sean hijos directos de éste. Por ejemplo, si dentro del <p> hay un <span> y dentro de éste está el enlace <a>, también se verá afectado por la regla. En resumen, pueden ser descendientes de cualquier grado.
Bueno, vale ya por hoy. El próximo día, más.
Las principales características de esta herramienta son:
- Permite identificar zonas de la página paseando por encima con el ratón, permitiéndonos visualizar en todo momento de qué elemento se trata, sus atributos y las reglas de estilo CSS aplicadas a cada uno. Los elementos también pueden seleccionarse desde la estructura (DOM) de la página.
- Activación o desactivación directa de características como estilos o scripts.
- Asimismo, se pueden ver de forma rápida los atajos de teclado o el orden de tabulación, importante para cumplir las normas de accesibilidad.
- Es posible indicarle que "bordee" elementos concretos, como divs, tablas, elementos posicionados u otros.
- Permite mostrar u ocultar imágenes o propiedades de éstas como el archivo de origen (src), el tamaño o el peso.
- Permite validar HTML, CSS, WAI y feeds RSS de forma directa.
- Dispone de reglas para medir zonas de la página a nuestro antojo.
- Formatea y colorea el código fuente de las páginas para facilitar su lectura.
- Nos permite eliminar la caché del navegador, así como visualizar o eliminar las cookies asociadas a la página consultada, o incluso deshabilitar su uso.
La siguiente captura de pantalla muestra la herramienta en funcionamiento sobre Internet Explorer 6:

Funciona con IE6 e IE7. En el primero se activa pulsando el icono con una flechilla que aparece en la barra de herramientas; en el segundo también, pero ojo, este icono no está visible por defecto. De momento está disponible sólo en inglés, y se puede descargar en esta dirección.
Ah, aunque supongo que ya lo conoceréis a estas alturas, el equivalente para Mozilla Firefox es la extensión Firebug, toda una maravilla, también indispensable para cualquier desarrollador web.
DKIM pretende controlar los mensajes haciendo que el servidor de correo del que proceden firme digitalmente los envíos. De esta forma se consigue, en primer lugar, poder verificar el dominio al que pertenece el remitente de un mensaje y, en segundo lugar, asegurar la integridad del mismo permitiendo detectar si el contenido de éste ha sido alterado durante su tiempo de tránsito por el ciberespacio.
Según proponen, para echar a andar DKIM en un servidor de mensajes SMTP, deberían generarse un par de claves, pública y privada. La primera de ellas sería publicada a través del servicio estándar DNS, mientras que la segunda sería utilizada internamente para firmar digitalmente los mensajes.
Cuando un usuario autorizado envía un correo, el servidor generaría la firma del contenido en tiempo real y la añadiría a los encabezados del mensaje. El servidor del destinatario extraería la firma del mensaje y, mediante una consulta al DNS del origen, obtendría su clave pública, con lo que podría verificar la validez de la firma.
De esta forma, en función del resultado de la comprobación, el destinatario podría aplicar políticas locales de filtrado. Por ejemplo, si el dominio origen del mensaje existe y la firma es válida, es probable que se trate de un mensaje que debe ser entregado al destinatario, pero se le podrían pasar filtros basados en contenido para una mayor seguridad. Si la firma no es correcta o no aparece, podrían tomarse medidas de descarte o marcado del mensaje.

¿Y quién anda detrás de este invento? Pues ni más ni menos que Yahoo! (iniciadores del proyecto), Cisco, PGP y Sendmail, y según comenta su inventor, Mark Delany, también han contado con la colaboración de IBM, Earthlink, Microsoft, Spamhaus, Google, PayPal y Alt-N, entre otros.
En resumen, se trata de un nuevo intento para acabar con el envío de mensajes desde destinatarios incorrectos o servidores "no creíbles", basándose esta vez en la utilización de criptografía de clave pública. Si bien no es de por sí una tecnología que resuelva el problema al 100%, sí que podría colaborar mucho. Además, lo más probable es que la solución final sea una combinación de distintas técnicas, así que bienvenida sea.
Particularmente me convence la idea de aplicar técnicas criptográficas para asegurar el correo, así como la utilización de estándares y soluciones colaborativas consensuada entre proveedores. Sin embargo, este último aspecto es su punto más débil: necesita una adopción global para que su efectividad pueda ser razonable.
En cualquier caso, todo esto forma parte de la lógica y necesaria evolución de tecnologías que tiene que acontecer hasta que la humanidad consiga dar con la forma para la eliminación definitiva del spam, phishing, spoofing y otras lindezas virtuales.
Sin embargo, la infraestructura Ajax nos brinda otra forma de invocar funcionalidades de servidor sin necesidad de crear servicios web de forma explícita: los métodos de página (Page Methods). El objetivo: permitirnos llamar a métodos estáticos de cualquier página (.aspx) desde el cliente utilizando Javascript y, por supuesto, sin complicarnos mucho la vida. Impresionante, ¿no?
En este post vamos a desarrollar un ejemplo parecido al anterior, en el que tendremos una página web con un cuadro de edición para introducir nuestro nombre y un botón, cuya pulsación mostrará por pantalla el resultado de la invocación de un método del servidor, y todo ello, por supuesto, sin provocar recargas de página completa. El resultado vendrá a ser algo así:

Ah, para que no se diga que soy partidista ;-) esta vez vamos a desarrollarlo en Visual Basic .NET (aunque la traducción a C# de la porción de servidor es directa), y de nuevo con Visual Studio 2005.
En primer lugar, hemos de crear la solución (Visual Studio 2005) basándonos en la plantilla "ASP.NET Ajax-Enabled web application" que habrá aparecido en nuestro entorno tras descargar e instalar las extensiones AJAX. Una vez elegido el nombre, se creará un proyecto con todas las referencias necesarias, el web.config adaptado, y una página (Default.aspx) que viene ya preparada con el ScriptManager listo para su uso.
En el archivo code-behind (Default.aspx.vb) añadimos el siguiente código, que será la función de servidor a la que invocaremos desde el cliente:
<WebMethod()> _
Public Shared Function Saludame(ByVal Nombre As String) As String
Return "Hola a " + Nombre _
+ " desde el servidor, son las " _
+ DateTime.Now.ToString("hh:mm:ss")
End Function
Obsérvese que:
- El método es público y estático. Lo primero es obvio, puesto que el ScriptManager necesitará mapearlo al cliente y para ello deberá acceder mediante reflexión a sus propiedades, y lo segundo también, puesto que las invocaciones al mismo no se efectuarán desde instancias de la clase, imposibles de conseguir en cliente.
- Está adornado con un atributo WebMethod, que indica al ScriptManager que el cliente podrá invocarlo utilizando Javascript.
Sólo falta un detalle. Hay que indicar al ScriptManager de la página que se encargue de procesar todos los métodos públicos estáticos de la clase, que además estén marcados con el atributo anteriormente citado, y genere la infraestructura que necesitamos para utilizar de forma directa esta funcionalidad. Esto se consigue estableciendo la propiedad EnablePageMethods a true desde el diseñador.
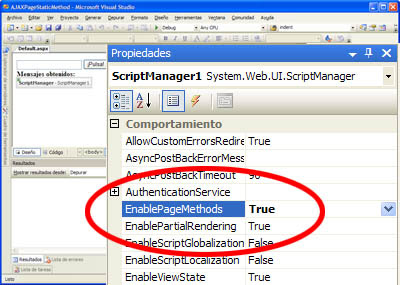
Una vez hecho esto, introducimos en el aspx de la página los elementos de interfaz (el cuadro de texto, el botón y un label para mostrar los resultados). El código del formulario completo queda así:
<form id="form1" runat="server">
<input type="text" id="nombre" />
<input id="Button1" type="button"
value="¡Pulsa!" onclick="llamar();" />
<br />
<strong>Mensajes obtenidos:</strong>
<br />
<label id="lblMensajes" />
<asp:ScriptManager ID="ScriptManager1"
runat="server" EnablePageMethods="True" />
</form>
Podemos ver, como en el post anterior, que todos los controles salvo el ScriptManager son de cliente, no tenemos el runat="server" en ninguno de ellos puesto que no realizaremos un envío de la página completa (postback) en ningún momento, todo se procesará en cliente y actualizaremos únicamente el contenido del label.
Por último, añadimos el script que realizará las llamadas y mostrará los resultados. La función llamar(), invocada a partir de la pulsación del botón y la de notificación de respuesta. El código es el siguiente:
<script type="text/javascript">
function llamar()
{
PageMethods.Saludame($get("nombre").value , OnOK);
}
function OnOK(msg)
{
var etiqueta = $get("lblMensajes");
etiqueta.innerHTML += msg + "<br />";
}
</script>
Primero, fijaos en la forma de llamar a Saludame(). El ScriptManager ha creado una clase llamada PageMethods a través de la cual podemos invocar a todos los métodos de la página de forma directa.
El primer parámetro de la función es $get("nombre").value. Ya vimos el otro día que $get("controlID") es un atajo para obtener una referencia hacia el control cuyo identificador se envía como parámetro. Por tanto, $get("nombre").value obtendrá el texto introducido en el cuadro de edición.
Después de los parámetros propios del método llamado, se indica la función a la que se pasará el control cuando obtenga el resultado desde el servidor. OnOK recibirá como parámetro la respuesta de éste, el string con el mensaje de saludo personalizado, y actualizará el contenido de la etiqueta para mostrarlo.
En resumen, los PageMethods son una interesantísima característica del framework AJAX de Microsoft, y nos permiten llamar a funciones estáticas definidas directamente sobre las páginas aspx, evitando el engorro de definir servicios web (asmx) de forma independiente, y sobre todo, ayudando a mantener en un único punto el código relativo a una página concreta ¡y qué mejor sitio que la propia página!
(Puedes descargar el proyecto completo.)
Y dado que AJAX cubre la parte cliente, es obvio pensar que el complemento ideal en el lado del servidor son los servicios web, dada la coincidencia en el lenguaje de intercambio utilizado (XML), y la facilidad con que se desarrollan, despliegan y comunican.
El framework publicado por Microsoft hace unos meses, llamado ATLAS durante su periodo de desarrollo, facilita enormemente la tarea de inclusión de características AJAX en aplicaciones ASP.NET. El sistema completo se entrega en dos paquetes:
- ASP.NET 2.0 AJAX Extensions, que es el componente base que establece la infraestructura para la utilización de esta tecnología sobre páginas asp.net. El ejemplo que desarrollaremos en este post se basa en estos componentes.
- ASP.NET AJAX Control Toolkit, que incluye un buen número de componentes visuales y no visuales que hacen uso de la infraestructura AJAX a todo trapo. Algunos son una maravilla, y además es un proyecto compartido con la comunidad bajo licencia MsPL.
A lo largo de este post vamos a desarrollar paso a paso un ejemplo completo de interacción de un cliente con un servidor utilizando AJAX. El proyecto será bien simple, pero creo que suficientemente ilustrativo: crearemos con VS2005 una página web con un botón, cuya pulsación provocará que se obtenga desde el servidor un mensaje, que será mostrado por pantalla, ¡y todo ello sin provocar recarga de la página! En primer lugar, abrimos Visual Studio 2005 y creamos un proyecto. Para facilitar la tarea, la instalación del framework AJAX habrá incluido una plantilla llamada "ASP.NET Ajax-Enabled web application", que es la que debemos elegir. De esta forma, se añadirán las referencias necesarias para que todo funcione.
En primer lugar, abrimos Visual Studio 2005 y creamos un proyecto. Para facilitar la tarea, la instalación del framework AJAX habrá incluido una plantilla llamada "ASP.NET Ajax-Enabled web application", que es la que debemos elegir. De esta forma, se añadirán las referencias necesarias para que todo funcione.
 Hecho esto, el entorno habrá creado una página "default.aspx" a la que simplemente habrá añadido un control de servidor de tipo ScriptManager. Este control es el que hace la magia, como veremos más adelante, asilándonos de la complejidad real que tiene una comunicación asíncrona con el servidor como la que vamos a realizar.
Hecho esto, el entorno habrá creado una página "default.aspx" a la que simplemente habrá añadido un control de servidor de tipo ScriptManager. Este control es el que hace la magia, como veremos más adelante, asilándonos de la complejidad real que tiene una comunicación asíncrona con el servidor como la que vamos a realizar.
A continuación añadimos al proyecto un servicio web, con lo que Visual Studio generará un archivo estándar con un método, el consabido HelloWorld(), que devuelve un string con el mensaje de saludo.
Pues bien, aquí es donde empieza la fiesta. En primer lugar, vamos a modificar ligeramente este método para que devuelva mensajes diferentes y podamos comprobar, a posteriori, el funcionamiento del sistema.
Por ejemplo, añadiremos al saludo la hora actual del servidor:
[WebMethod]
public string HelloWorld()
{
return "Hola a todos desde el servidor, son las " +
DateTime.Now.ToString("hh:mm:ss");
}Además, introducimos justo antes de la declaración de la clase, en las primeras líneas del archivo, la declaración del atributo [ScriptService] de la siguiente forma:
...
[System.Web.Script.Services.ScriptService] // ¡Necesario!
public class ServicioWeb : System.Web.Services.WebService
...
De esta forma, indicamos que la clase contiene servicios que serán accedidos desde el cliente utilizando scripting (javascript). Y con esto, hemos acabado con la parte de servidor, pasamos ahora a ver el lado cliente, cómo utilizamos este servicio.
En primer lugar, añadimos dos controles a la página web (default.aspx), un botón que provocará la llamada al servidor, y una etiqueta donde iremos mostrando los resultados. El código es el siguiente:
<input id="Button1" type="button" value="¡Pulsa!" onclick="llamar();" />
<br />
<strong>Mensajes obtenidos:</strong><br />
<label id="lblMensajes"></label>Podemos observar, ninguno de los controles introducidos son de servidor, es decir, no incluyen un runat="server". Es lógico, pues toda la interacción la vamos a realizar en cliente.
Además, vemos que el botón incluye un controlador del evento OnClick, la función llamar() de javascript. La idea es que esta función obtenga del servidor el mensaje de saludo correspondiente, y vaya añadiéndolo al contenido de la etiqueta. Basta con añadir el siguiente código a la página, dentro del correspondiente tag <script>:
function llamar()
{
AJAXWSDemo.ServicioWeb.HelloWorld(OnLlamadaFinalizada);
}Aquí hay varios aspectos a destacar. En primer lugar, que estamos llamando al método HelloWorld desde script (en cliente) indicando la ruta completa hasta el mismo, es decir, el namespace (AJAXWSDemo) y la clase donde se encuentra (ServicioWeb). ¿Y cómo es posible esto? Por obra y gracia del control ScriptManager, que ya vimos anteriormente, que es quien ha encargado de generar un envoltorio (wrapper) apropiado para los servicios a los que vamos a acceder desde el cliente, haciéndolo así de sencillo.
Sin embargo, para que ScriptManager sea consciente de los servicios que debe gestionar, hay que indicárselo expresamente, incluyendo el siguiente código dentro del propio control. Creo que se entiende directamente, lo que hace es crear una referencia a la url que contiene los métodos a los que vamos a llamar:
<asp:ScriptManager ID="ScriptManager1" runat="server">
<Services>
<asp:ServiceReference Path="ServicioWeb.asmx" />
</Services>
</asp:ScriptManager>
...
Hecho este inciso, continuamos ahora comentando la función llamar(). Por otra parte, vemos un parámetro extraño en la llamada al método, "OnLlamadaFinalizada". Esto es así porque las llamadas a servicios deben incluir un parámetro adicional que es la función a la que el sistema notificará que ha completado la invocación al método. Hemos de recordar que las llamadas son, por defecto, asíncronas; esto quiere decir que el sistema no espera a su finalización, la llamada se realiza en background y cuando son completadas el control se transfiere a la función de notificación que hayamos elegido.
A esta misma función de retorno le llegará un parámetro, el valor devuelto desde el servicio web. Por este motivo, no es necesario obtener el valor de retorno en el momento de invocación del método remoto.
El código para la función de retorno es, en nuestro caso,
function OnLlamadaFinalizada(resultado)
{
var etiqueta = $get("lblMensajes");
etiqueta.innerHTML += resultado + "<br />";
}
En este caso, destacamos varios aspectos también. En primer lugar, como hemos comentado anteriormente, el parámetro que recibe la función es el retorno del servicio web invocado.
También puede que llame la atención la expresión $get("lblMensajes"). Se trata de un atajo que evita tener que introducir el código "document.getElementById(...)" necesario para obtener referencias a un control de la página.
El resultado final se puede ver en la siguiente captura, demostrando, además, que funciona perfectamente en Firefox:

Y para los perezosos, he dejado en http://www.snapdrive.net/files/415885/AJAXWSDemo.zip el proyecto VS2005, para que podáis jugar con él sin necesidad de teclear nada.
Actualización: si has leído hasta aquí, es posible que también te interese este otro post donde se muestra otra forma de comunicarse con el servidor utilizando ASP.NET 2.0 AJAX.
Lenguajes de programación, plataformas, aplicaciones, comentarios... más de 50 posts en los que hay de todo un poco: artículos de iniciación, curiosidades, descubrimientos, comentarios sobre temas de actualidad, reflexiones, temas algo más avanzadillos o de ámbito muy específico... en fin, lo que me ha pedido el cuerpo en cada momento.
Sin embargo hay una parte, sin duda la fundamental, que no la he podido poner yo: el sentido de todo esto. ¿Qué es un blog sin lectores? Os puedo asegurar que he disfrutado escribiendo cada post, pero las alegrías han venido con cada comentario, con cada visita, con cada referencia.
Nada más sencillo. Suponiendo que partimos de un linux basado en Debian, como Ubuntu, basta con descargar e instalar nmap:
apt-get install nmapUna vez contando con esta herramienta, para realizar un escaneo al host [victima] a través del zombie [zombie] la instrucción sería la siguiente:
nmap –sI [zombie] –P0 [victima]Donde:
- "-sI" indica que se debe realizar el idle scan.
- [zombie] es la dirección, en forma de IP o nombre, del equipo elegido como zombie.
- "-P0" indica que no se debe realizar un ping directo para comprobar si la víctima está activo.
- [victima] es la dirección, IP o nombre, de la misma.
- opcionalmente, puede indicarse el parámetro "-p" seguido de los números de puerto a escanear, por defecto nmap hará un barrido bastante completo y puede tardar un poco. Ante la duda, un "man nmap" puede venir bien.
Pero ojo, no es fácil dar con servidores que cumplan los requisitos necesarios para ser considerados buenos zombies, puesto que en la mayoría se usan IPIDs aleatorizados, fijos o secuencias por cliente.
Además, recordad que debéis ser root (o ejecutar las órdenes con sudo) para que todo funcione correctamente.
Sin embargo, su utilidad se vería reducida en la práctica si su creación fuera compleja. Pero nada más lejos de la realidad, la obtención de un Guid es extremadamente sencilla:
// C#:
Guid g = Guid.NewGuid(); // Obtiene un nuevo GUID
Console.WriteLine(g); // Lo muestra por consola
' Visual Basic .Net:
Dim g as Guid = Guid.NewGuid() ' Obtiene un nuevo GUID
Console.WriteLine(g) ' Lo muestra por consola
Podemos observar que la clase (estructura) Guid (incluida en el namespace System) contiene un método estático que nos permite generar y obtener objetos de este tipo de forma directa. Además, recordemos que cada vez que generamos un GUID tenemos la seguridad casi absoluta de que será único, lo que hace que podamos utilizarlo directamente como identificador del elemento deseado.
Se trata de idle scan, una ocurrente forma para detectar los puertos abiertos en una máquina remota sin poner al descubierto al atacante, es decir, al equipo que realiza el escaneo. Para ello, se vale de una máquina intermedia, llamada zombie o dumb, que ejerce como intermediario en la comunicación y hace que en ningún caso la víctima reciba paquetes directamente desde el atacante, quedando éste en el más absoluto anonimato.
Bueno, he de decir que si no tienes claro el funcionamiento del protocolo TCP y el establecimiento de conexiones, es probable que debas pegar un repaso antes de seguir leyendo el post. En todo caso será una lectura aconsejable para todo humano interesado en saber qué está ocurriendo por debajo cuando estamos utilizando servicios en una red como Internet.
Ahora vamos al lío. La cuestión es que todo intrépido pirata sabe que antes de iniciar el ataque a una ciudad costera es conveniente ver los puertos en los que se puede atracar para hacer el desembarco, ¿no? Pues en Internet ocurre lo mismo, un puerto abierto en un equipo conectado a la red es siempre una posible vía de entrada al mismo; indica que hay una aplicación escuchando en la máquina, y habitualmente puede averiguarse cuál es y explotar sus debilidades.
Por tanto, un ataque tipo debería ir precedido de un escaneo de los puertos abiertos, es decir, recorrer los 65535 puertos posibles (o al menos el subconjunto de uso más habitual) a ver cuáles están en uso. La pega es que esto suele ser demasiado ruidoso, no son pocos los sistemas de detección de intrusos y filtros que detectan peticiones sucesivas desde una misma dirección y las clasifican de inmediato como sospechosas pudiendo llegar a banear (prohibir) la conexión desde la IP que está haciendo el barrido, o incluso a registrar la dirección para más adelante poder tomar medidas legales si procede.
Esta es la razón que hacen de Idle Scan una técnica interesante, puesto que, como he comentado antes, en ningún momento el atacado es consciente de la dirección del atacante.
Para ello se aprovecha, en primer lugar, el funcionamiento del three way handshake, el protocolo estándar utilizado para el establecimiento de conexiones TCP, donde de forma habitual:
- El procedimiento se inicia cuando el cliente envía un paquete SYN al servidor. Si es posible realizar una conexión, éste responde con un SYN + ACK, y el cliente debe confirmar enviando de nuevo un ACK al servidor. En caso contrario, es decir, si no es posible realizar la conexión porque el puerto esté cerrado, el servidor responde con un RST y se da por finalizada la secuencia.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de confirmación de conexión SYN+ACK de otro, responde con un RST con objeto de informarle de que no va a establecerse conexión alguna.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de reseteo (RST), lo ignora.
Para detectar si un puerto está abierto o cerrado, es necesario primero observar el IPID del zombie, enviar paquetes a la víctima haciéndole ver que realmente se los está enviando éste y, posteriormente, observar de nuevo el IPID utilizado por el incauto intermediario. En función de los valores iniciales y finales obtenidos, se puede inferir el estado del puerto destino.
A continuación se exponen dos escenarios distintos de escaneo; en el primero de ellos se muestra lo que ocurre cuando el puerto objeto de la detección está abierto, mientras que en el segundo se supone que está cerrado.
Escenario 1: Víctima con el puerto abierto
El primer paso es enviar al zombie un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente, del cual tomaremos el IPID.Acto seguido, se realiza una solicitud de conexión a la víctima, previa manipulación del paquete para que sea el zombie el que figure como origen del mismo. Al recibirlo, dado que estamos asumiendo que el puerto está abierto (escenario 1), la víctima envía de vuelta la confirmación de la conexión al que cree que es el solicitante, el zombie.
El zombie recibe la confirmación de la conexión, pero como no es él el que la ha generado, responde a la víctima con una señal de reseteo (RST), incrementando su IPID.
De nuevo, pasado unos segundos, desde el atacante se vuelve a obtener el IPID del zombie de la misma forma que al comienzo, comprobando que ha sido incrementado en 2 unidades. De esta forma, se determina que el puerto destino del escaneo estaba abierto.
El siguiente diagrama muestra la secuencia forma gráfica:

Escenario 2: Víctima con el puerto cerrado
Como en el escenario anterior, el primer paso siempre es obtener el IPID del zombie, enviándole un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente.
De la misma forma, se envía a la víctima el paquete de solicitud de conexión, indicando en las cabeceras que el origen del mismo es el host zombie. Dado que el puerto está cerrado (escenario 2), la víctima devuelve al aparente emisor un paquete RST indicándole que no será posible establecer la conexión solicitada. El zombie recibe el paquete RST y lo ignora.
El atacante, siguiendo la misma técnica que en otras ocasiones, obtiene el IPID del zombie, y dado que es el número siguiente al recibido al iniciar el procedimiento, puede determinar que no ha realizado ningún envío entre ambos, y que, por tanto, el puerto de destino estaba cerrado.

Desde el punto de vista del atacante las ventajas son, fundamentalmente:
- El anonimato, puesto que desde la víctima todas las conexiones provienen virtualmente del zombie, y en ningún momento se envía información directamente desde el atacante.
- El alcance, es decir, esta técnica permite escanear puertos de máquinas a las que directamente no se tendría acceso debido a la acción de filtros (como firewalls) intermedios. Dado que las conexiones provienen del zombie, sólo habría que tener acceso a éste para realizar el escaneo.
- La visión de red que aporta, en otras palabras, permite determinar las relaciones de confianza existentes entre el zombie y la víctima. Si, por ejemplo, un intento directo de conexión a un puerto de la víctima es rechazado y, sin embargo, es posible acceder a él desde un intermediario, es porque existe algún tipo de relación de confianza entre ambos, lo cual puede ser utilizado en ataques posteriores.
En la actualidad, el principal inconveniente es la dificultad de localizar un zombie apropiado para realizar los ataques, tanto por las condiciones software que debe cumplir (sistemas operativos, kernels, etc.), el escaso tráfico de red que debe tener en el momento del escaneo (necesarios para que los IPID no se incrementen por otras conexiones) y, sobre todo, las medidas de seguridad de que disponga, puesto que desde él sería posible detectar al atacante.
El operador en cuestión, expresado como ?? (dos cierres de interrogación), permite devolver un valor si no es nulo, o devolver otro valor alternativo ante la nulidad del primero. En otras palabras, un código como:
if (s!=null)
return s;
else
return "por defecto"; O también escrito de la forma, utilizando el operador ternario:
return (s!=null?s:"por defecto"); Quedaría, utilizando el nuevo operador de fusión, como:
return s ?? "por defecto"; Qué limpio, ¿no?
A primera vista puede parecer que salvo mejorar la legibilidad, no aporta demasiadas ventajas frente al operador ternario ?, pero fijaos en el siguiente código, en un método que retorna el nombre del algo cuyo Id le llega como parámetro:
string nombre = obtenerNombre(id);
if (nombre==null)
return "Desconocido";
else
return nombre;Utilizando el operador ternario ? podríamos dejarlo en una única línea:
return obtenerNombre(id)==null?"Desconocido":obtenerNombre(id); Esto tiene una pega aparte de la dificultad de lectura: si el nombre del llamamos dos veces a obtenerNombre(id), lo cual podría tener efectos secundarios no deseados, o simplemente causar un problema de rendimiento. Para mejorarlo podríamos hacer esto, que mejora la legibilidad y llama sólo una vez al método, aunque es más largo de codificar, siendo muy similar al if inicial:
string p = obtenerNombre(id);
return p==null?"Desconocido":p; Con el nuevo operador el código quedaría así de simple:
return obtenerNombre(id) ?? "Desconocido"; Esto se ejecuta de la siguiente forma: se llama a obtenerNombre(id) y si no es nulo se retorna el valor obtenido. Sólo si el resultado de la expresión ha sido nulo se retornaría el literal "Desconocido".
No sé a vosotros, pero a mí me ha parecido interesantísimo, y de lo más útil.
SPF (Sender Policy Framework) es una especificación experimental publicada por la IETF en la RFC 4408 (abril 2006), y describe un conjunto de técnicas para evitar la utilización de dircciones de email falsas en los mensajes que circulan por la red.
Aunque creo que esto ya lo he comentado en otras ocasiones, uno de los principales problemas que hacen florecer el spam, scam, phishing, y alguna que otra atrocidad más, es la inocencia con la que fue creado el protocolo SMTP, utilizado para los envíos de mensajes de correo electrónico entre servidores. En este estándar no se establece ninguna técnica para asegurar la veracidad del remitente, por lo que cualquiera puede escribir en nombre de otro, hacerse pasar por quien desee, o simplemente inventar sobre la marcha un emisor, existente o no.
Por eso los mensajes de spam que recibimos pueden provenir incluso de personas que conocemos, pertenecientes a nuestro propio dominio, compañeros que tenemos sentados justo a nuestro lado, etc.
El SPF pretende acabar con esto, pues define un sistema de comprobación en tiempo real de la veracidad del remitente, así como del servidor desde el que se envía un mensaje, consistente, por una parte, en incluir en los registros MX de cada dominio emisor de correos una línea donde se indique la dirección IP desde la que pueden ser enviados. De esta forma, cuando otro servidor SMTP recibe un mensaje con un remitente del dominio anterior, puede consultar esos registros y comprobar si la IP desde la que está recibiendo el email está autorizada para enviarlo.
Lo vemos con un ejemplo real, por suerte (?) tengo bastantes para elegir. Hoy he recibido un correo desde la dirección finkenhoferqov0@hotmail.com aconsejándome soluciones para mis terribles problemas de erección (¿cómo se habrán enterado? :-D). Por suerte, según me indican, la mitad de los varones los sufren, el que no se consuela es porque no quiere.
Si rastreo el mensaje, veo que ha llegado a mi servidor desde la dirección IP 71.186.100.38, cuyo nombre parece ser pool-71-186-100-38.chi01.dsl-w.verizon.net. Si seguimos escarbando, podemos obtener la siguiente información de esta IP:
OrgName: Verizon Internet Services Inc.
OrgID: VRIS
Address: 1880 Campus Commons Dr
City: Reston
StateProv: VA
PostalCode: 20191
Country: US
NetRange: 71.160.0.0 - 71.191.255.255
CIDR: 71.160.0.0/11
NetName: VIS-BLOCK
 Y aunque las herramientas de geoposicionamiento de direcciones IP no son el colmo de la precisión, podríamos incluso atrevernos a conjeturar dónde se encuentra el spammer, en Washington.
Y aunque las herramientas de geoposicionamiento de direcciones IP no son el colmo de la precisión, podríamos incluso atrevernos a conjeturar dónde se encuentra el spammer, en Washington.A la vista de estos datos, se trata de un equipo que utiliza una dirección IP dinámica, conectado a través de una DSL que, de forma voluntaria o no, está enviando spam, cual poseso, al resto del mundo. Está claro que ningún spammer decente dejaría ver todos sus datos así, por lo que, o bien se trata de un PC secuestrado (zombie), o bien toda la información que deja ver es falsa.
En cualquier caso, está claro que no se trata de Hotmail, de donde era, como recordaréis, el remitente del mensaje.
Si tanto mi servidor como Hotmail utilizaran SPF, se habría rechazado el mensaje de forma directa. Al recibir la dirección del remitente, habría acudido a los registros MX de Hotmail para averiguar si la IP desde la que se ha producido la conexión es válida para envíos @hotmail.com, y, obviamente, de esta comprobación siempre se determinaría que el emisor es inválido.
Todo esto está muy bien, personalmente creo bastante en este tipo de soluciones colaborativas y de consenso para luchar contra el spam, más incluso que en las de análisis de contenido que, como ya he comentado en posts anteriores, tienen bastantes dificultades para garantizar el filtrado correcto dada la gran variedad de trucos utilizados.
El problema es precisamente su implementación en la práctica, y eso que en el caso del SPF no es especialmente compleja, todo lo contrario. Está claro que si todos los ISP del mundo utilizaran este método, el spam, fishing y en general cualquier historia basada en la utilización de remitentes falsos tendrían los días contados... al menos en la forma en que hoy los conocemos, claro.
Y es que con poco que hayáis desarrollado, seguro que alguna vez habéis encontrado la difícil tarea de asignar un valor nulo a una variable de tipo valor (int, float, char...) donde no encaja más que usando artimañas difíciles de realizar, trazar y documentar. Por ejemplo, dada una clase Persona con un propiedad de tipo entero llamada Edad, ¿qué ocurre si cargamos un objeto de dicha clase desde una base de datos si en ésta el campo no era obligatorio?
A priori, fácil: al leer de la base de datos comprobamos si es nulo, y en ese caso le asignamos a la propiedad de la clase el valor -1. Buen parche, sin duda.
Sin embargo, optar de forma general por esta idea presenta varios inconvenientes. En primer lugar, para ser fieles a la realidad, si quisiéramos almacenar de nuevo este objeto en la base de datos, habría que realizar el cambio inverso, es decir, comprobar si la edad es -1 y en ese caso guardar en el campo un nulo.
En segundo lugar, fijaos que estamos llevando a la clase artificios que no tienen sentido en el dominio del problema a resolver, en la entidad a la que representa. Mirándolo un poco desde lejos, ¿qué sentido tiene una edad negativa en una entidad Persona? Ninguno.
En tercer lugar, existe un problema de coherencia en las consultas. Si tengo en memoria una colección de personas (realizada, por ejemplo usando generics ;-)) y quiero conocer las que tienen edad definida, debería comprobar por cada elemento si su propiedad Edad vale -1; sin embargo, al realizar la misma consulta en la base de datos debería preguntar por el valor NULL sobre el campo correspondiente.
Cierto es que podríamos llevar también a la base de datos el concepto "-1 significa nulo" en el campo Edad, pero... ¿no estaríamos salpicando a la estructura de datos con una particularidad (y limitación) del lenguaje de programación utilizado? Otra idea bizarra podría ser introducir la edad en un string y problema solucionado: las cadenas, al ser un tipo referencia pueden contener nulos sin problemas, lo que pasa es que las ordenaciones saldrían regular ;-)
Por último, ¿y si en vez de la edad, donde claramente no pueden existir negativos se tratase de una clase CuentaCorriente y su propiedad SaldoActual? Aquí sí que se ve claramente que esto no es una solución válida.
Soluciones, aparte de las comentada, hay para todos los gustos. Se podría, por ejemplo, añadir una propiedad booleana paralela que indicara si el campo Edad es nulo (un trabajazo extra, sobre todo sin son varias las propiedades que pueden tener estos valores), o encapsular la edad dentro de una clase que incorporara la lógica de tratamiento de este nulo.
En cualquier caso, las soluciones posibles son trabajosas, a veces complejas, y sobre todo, demasiado artificiales para tratarse de algo tan cotidiano como es un simple campo nulo.
Conscientes de ello, los diseñadores de C# han tenido en cuenta en su versión 2.0 una interesante característica: los nullables types, o tipos anulables (traducción libre), un mecanismo que permite introducir el nulo en nuestras vidas de forma no traumática.
La siguiente línea generaba un error en compilación, que decía, y no le faltaba razón, que "no se puede convertir null en 'int' porque es un tipo de valor":
int s = null; Ahora, en C# 2.0, es posible hacer lo siguiente:
int? s;
s = null;
s = 1;Obsérvese la interrogación junto al tipo, que es el indicativo de que la variable s es de tipo entero, pero que admite también un valor nulo.
Por dentro, esto funciona de la siguiente forma: int? es un alias del tipo genérico System.Nullable<int>. De hecho, podríamos usar indistintamente cualquiera de las dos formas de expresarlo. Internamente se crea una estructura con dos propiedades de sólo lectura: HasValue, que retorna si la variable en cuestión tiene valor, y Value, que contiene el valor en sí.
Se entiende que una variable con HasValue igual a false contiene el valor nulo, y si intentamos acceder al mismo a través de Value, se lanzará una excepción.
Sin embargo, la principal ventaja que tienen es que se utilizan igual que si fuera un tipo valor tradicional. Los tipos nullables se comportan prácticamente como ellos y ofrecen los mismos operadores, aunque hay que tener en cuenta sus particularidades, como se aprecia en el siguiente código:
int? a = 1;
int? b = 2;
int? intNulo = null;
bool? si = true;
bool? no = false;
bool? niSiNiNo = null;
Console.WriteLine(a + b); // 3
Console.WriteLine(a + intNulo); // Nada, es nulo
Console.WriteLine(a * intNulo); // Nada, es nulo
Console.WriteLine(si & no); // false
Console.WriteLine(si & no); // true
Console.WriteLine(si & niSiNiNo); // Nada, es nulo
Console.WriteLine(no & niSiNiNo); // false
Console.WriteLine(si | niSiNiNo); // true
Console.WriteLine(no | niSiNiNo); // Nada, es nuloCurioso en los booleanos, en los que el valor nulo se puede interpretar como un quizás. De esta forma es fácil prever el resultado de una operación lógica: "Verdad ó Quizás" resuelve como verdadero, ó "Falso y Quizás" es falso, por ejemplo.
Para verle el sentido a esto, utilicemos el siguiente ejemplo, aparentemente correcto:
public class Seleccionador<Tipo>
{
public Tipo Mayor(Tipo x, Tipo y)
{
int result = ((IComparable)x).CompareTo(y);
if (result > 0)
return x;
else
return y;
}
}Se trata de una clase genérica abierta, cuya única operación (Mayor(...)) permite obtener el objeto mayor de los dos que le pasemos como parámetros. El criterio comparativo lo pondrá la propia clase sobre la que se instancie la plantilla: los enteros serán según su valor, las cadenas según su orden alfabético, etc.
A continuación creamos dos instancias partiendo de la plantilla anterior, y concretando el generic a los tipos que nos hacen falta:
Seleccionador<int> selInt = new Seleccionador<int>();
Seleccionador<string> selStr = new Seleccionador<string>();
Estas dos instanciaciones son totalmente correctas, ¿verdad? Si después de ellas usamos el siguiente código:
Console.WriteLine(selInt.Mayor(3, 5));
Console.WriteLine(selStr.Mayor("X", "M"));
Obtendremos por consola un 5 y una X. Todo correcto, aparece, para cada llamada, la conversión a cadena del objeto mayor de los dos que le hayamos enviado como parámetros.
El problema aparece cuando instanciamos la clase genérica para un tipo que no implementa IComparable, que se utiliza en el método Mayor para determinar el objeto mayor de ambos. En este caso, se lanza una excepción en ejecución indicando que el cast hacia IComparable no puede ser realizado, abortando el proceso. Por ejemplo:
public class MiClase // No es comparable
{
}
[...]
Seleccionador<MiClase> sel = new Seleccionador<MiClase>();
MiClase x1 = new MiClase();
MiClase x2 = new MiClase();
Console.WriteLine(selString.Mayor(x1, x2)); // Excepción,
// no son
// comparables!
Una posible solución sería, antes del cast a IComparable en el método Mayor(), hacer una comprobación de tipos y realizar el cast sólo si es posible, pero, ¿y qué hacemos en caso contrario? ¿devolver un nulo? La pregunta no creo que tenga una respuesta sencilla, puesto que en cualquier caso, se estarían intentado comparar dos objetos que no pueden ser comparados.
La solución óptima, como casi siempre, es controlar en tiempo de compilación lo que podría ser una fuente de problemas en tiempo de ejecución. La especificación de C# 2.0 incluye la posibilidad de definir constraints o restricciones en la declaración de la clase genérica, limitando los tipos con los que el generic podrá ser instanciado. Y, además, de forma bastante simple, nada más que añadir en la declaración de la clase Seleccionador la siguiente cláusula where:
public class Seleccionador
where Tipo: IComparable // !Sólo comparables!
{
public Tipo Mayor(Tipo x, Tipo y)
[...]
Justo a partir de ese momento, el intento de instanciar el Seleccionador utilizando MiClase o cualquier otro tipo que no implemente IComparable, generará un error en tiempo de compilación.
Tradicionalmente utilizo claves artificiales, más concretamente autonuméricos, para casi todo. Incluso a veces más de la cuenta, en esas ocasiones en las que es antinatural no usar claves naturales, valga la rebuscada frase. Sin embargo, la facilidad con la que se manejan estos identificadores, la maximización del rendimiento y espacio ocupado hacen que olvide cualquier otro criterio y me incline hacia esos números consecutivos que automáticamente el sistema genera para nosotros.
Sin embargo, cualquiera que haya usado autonuméricos para diseñar una aplicación medianamente compleja se habrá topado con una serie de inconvenientes como:
- la imposibilidad para predecir su valor. En otras palabras, hay veces que debemos dividir las sentencias o interfaces de introducción de datos en tablas enlazadas en varios pasos, con objeto de obtener los autonuméricos asignados en algunas de ellas y poder establecerlos en las tablas que vinculan a éstas.
- no son consecutivos, determinados acontecimientos como la cancelación de una transacción pueden hacer que aparezcan huecos en las asignaciones, lo que puede provocar el efecto pánico de borrado accidental.
- son problemáticos a la hora de volcar información entre tablas o bases de datos distintas. Por ejemplo, para exportar una serie de tablas relacionadas mediante IDs de una base de datos a otra, suele ser necesario la creación de scripts o incluso aplicaciones relativamente complejas que traduzcan los identificadores de la base de datos origen a los asignados en la de destino, manteniendo las relaciones intactas. Labor de monos, vaya.
- en el mismo escenario anterior, puede ocurrir que a la hora de realizar fusiones entre tablas un identificador concreto esté ocupado en ambas, lo que hace necesario de nuevo la creación de aplicaciones de volcado.
A estos casos, seguro que habituales, hay que añadir otros escenarios más complejos y menos cotidianos, como los relativos a bases de datos distribuidas, sincronizaciones o replicaciones.
Los GUID pueden solucionar en parte estos problemas, puesto que ofrecen las ventajas de la unicidad, ampliada más allá del alcance de la simple tabla, a la vez que permiten una manipulación más directa por parte del usuario, es decir:
- los GUID son únicos de verdad, y de forma universal. Vamos, que no se van a repetir (recordemos que existen más de 1038 valores distintos) ni siquiera en tablas distintas, ni en bases de datos diferentes. Ideal para entornos distribuidos, mezclas de datos, volcados, etc.
- pueden ser generados por aplicaciones, no es necesario esperar a crear un registro para obtener el GUID que será asignado a un registro; podemos generarlo de forma anticipada desde nuestra aplicación y utilizarlo a nuestro antojo.
Pero como casi todo en la vida, esto tiene su precio. Los principales inconvenientes son el mayor consumo de espacio, con la consiguiente merma del rendimiento en consultas y actualizaciones, dispersión de los valores creados (problemático en el uso de clústers o agrupaciones por valores) y, para mi gusto, casi lo peor de todo: la dificultad para depurar (¿quién ve práctico buscar en una tabla diciendo select * from clientes where id={BAE7DF4-DDF-3RG-5TY3E3RF456AS10} en vez de select * from clientes where id=17?).
El tipo de datos GUID existe, y es una opción a la hora de crear un campo, en sistemas gestores de bases de datos como SQL Server, pero, cosas de la ignorancia, nunca había pensado que pudieran ser una opción razonable para identificar una fila en una tabla.
Sin embargo, recientemente me he topado con una aplicación en la que, observando su base de datos, se utilizaban como identificadores únicos de registro valores de tipo GUID, lo cual me ha llamado la atención y me ha llevado a profundizar un poco en el tema.
Pero, ¿qué es un GUID? Según su definición formal, se trata de una implementación del estándar UUID (Universally Unique Identifier, Identificador Unico Universal), promovido por la OSF (Open Software Foundation), que propone un método de identificación única ideal para entornos distribuidos en los que no existe un coordinador central. En otras palabras, permite que nodos dispersos puedan establecer identificadores de forma única a entidades o unidades de información de forma que se pueda asegurar razonablemente que no van a existir duplicidades en los mismos, y todo ello sin necesidad de crear un punto común de comprobaciones.
A efectos prácticos, un GUID es un número de 16 bytes, o 128 bits, escrito habitualmente en forma de chorizo hexadecimal del tipo "550e8400-e29b-41d4-a716-446655440000", generado utilizando algoritmos pseudoaleatorios.
Pero diréis que un algoritmo pseudoaleatorio no garantiza su unicidad, y es cierto. Sin embargo, 16 bytes ofrecen un universo de 2128 valores posibles (del orden de 3·1038), lo que hace prácticamente imposible que dos GUID se repitan.
Esto los hace especialmente atractivos como identificadores únicos: registros en bases de datos, identificación de componentes (como COM o DCOM), registro de documentos, artículos, posts y un largo etcétera.
List<Algocomplejo> listaDeCosas =
new List<Algocomplejo>();Bueno, no pasa nada. Aunque la clase sea genérica, clase es. Esto implica que podemos hacer uso de la herencia para aclarar un poco el código:
public class ListaCompleja: List<Algocomplejo>
{
}A partir de este momento, la instanciación quedaría más limpia:
ListaCompleja lista = new ListaCompleja();A todos los efectos, este truco tan simple hace que podamos trabajar con clases genéricas con un código fuente similar al de siempre, sin "<" ni ">" que, por lo menos a mí, despistan tanto.
Esto puede resultar extremadamente útil a la hora de programar clases genéricas, capaces de implementar un tipado fuerte sin necesidad de conocer a priori los tipos para los que serán utilizadas. ¿Confuso? Mejor lo vemos con un ejemplo.
Sabemos que un ArrayList es un magnífico contenedor de elementos y que, por suerte o por desgracia, según se vea, trabaja con el tipo base object. Esto hace que sea posible almacenar en él referencias a cualquier tipo de objeto descendiente de este tipo (o sea, todos), aunque esta ventaja se torna inconveniente cuando se trata de controlar los tipos de objeto permitidos. En otras palabras, nada impide lo siguiente:
al.Add("Siete caballos vienen de Bonanza...");
al.Add(7);
al.Add(new String('*', 25)); // 25 asteriscos
Esto puede provocar errores a la hora de recuperar los elementos de la lista, sobre todo si asumimos que los elementos deben ser de un determinado tipo. Y claro, el problema es que el error ocurriría en tiempo de ejecución, cuando muchas veces es demasiado tarde:
foreach (string s in al)
{
System.Console.WriteLine(s);
}
Efectivamente, se lanza una excepción indicando que "No se puede convertir un objeto de tipo 'System.Int32' al tipo 'System.String'". Lógico.
Algunos de los que hayáis sido capaces de superar el test FizzBuzz en menos de media hora ;-) podríais decir que eso se puede solucionar fácilmente, que existen al menos dos maneras de hacerlo: crear nuestra propia colección partiendo de CollectionBase o similares y mostrar métodos de acceso a los elementos con tipado fuerte, o bien, usando delegación, crear una clase de cero que implemente interfaces como IEnumerable en cuyo interior exista una colección que es la que realmente realiza el trabajo.
En cualquier caso, es un trabajazo. Por cada clase que queramos contemplar deberíamos crear un engendro como el descrito en el párrafo anterior.
Y aquí es donde los generics entran en escena. El siguiente código declara una lista de elementos de tipo AlgoComplejo:
List<AlgoComplejo> listaDeCosas =
new List<AlgoComplejo>();
listaDeCosas.Add(new AlgoComplejo());
listaDeCosas.Add("blah"); // Error en compilaciónCon esta declaración, no será posible añadir a la lista objetos que no sean de la clase indicada, ni tampoco será necesario realizar un cast al obtener los elementos, pues serán directamente de ese tipo.
Es interesante ver la gran cantidad de clases genéricas para el tratamiento de colecciones que incorpora el Framework 2.0 en el namespace System.Collections.Generic.
¿Y si queremos nosotros crear una clase genérica? Pues muy sencillo. Vamos a desarrollar un ejemplo completo donde podamos ver las particularidades sintácticas y detalles a tener en cuenta. Crearemos la clase CustodiadorDeObjetos, cuya misión es almacenar un objeto genérico y permitirnos recuperarlo en cualquier momento. Básicamente, construiremos una clase con una variable de instancia y un getter y setter para acceder a la misma, pero usaremos los generics para asegurar que valga para cualquier tipo y que el objeto introducido sea siempre del mismo tipo que el que se extrae.
public class CustodiadorDeObjetos<Tipo>
{
private Tipo objeto;
public Tipo Objeto
{
get { return objeto; }
set { this.objeto = value; }
}
}
El siguiente código muestra la utilización de nuestra nueva clase:
CustodiadorDeObjetos<string> cs = new CustodiadorDeObjetos<string>();
cs.Objeto = "Hola"; // Asignamos directamente
string s = cs.Objeto; // No hace falta un cast,
// objeto es de tipo string
// en esta clase.
cs.Objeto = 12; // Error en compilación,
// no es stringPero no sólo es eso, los generics dan mucho más de sí, pero de esto seguiremos hablando otro día, que ya es tarde.
Habitualmente se trata de personas con titulaciones medias o superiores, cierta experiencia previa y un conocimiento de tecnologías de programación, al menos en teoría, relativamente alto, perfectamente capaces de mantener una conversación sin soltar barbaridades destacables.
Y lo más increíble de todo es una de las técnicas que usan para "filtrar" el personal en las entrevistas de selección: el "test FizzBuzz". La prueba consiste en solicitar a los candidatos:
Escribir un programa que imprima los números del 1 al 100. Sin embargo, hacer que en los múltiplos de tres se imprima la palabra "Fizz" en vez del propio número, y en los múltiplos de cinco se imprima "Buzz". Para aquellos números múltiplos de tres y cinco simultáneamente, se debe imprimir "FizzBuzz".
Si piensas que esta prueba es una chorrada, atento a las conclusiones que sacan los que la han puesto en práctica. La mayoría de los graduados, ingenieros, diplomados en informática no pueden hacerlo. Incluso muchos auto-proclamados programadores expertos tardan más de diez minutos en escribir una solución.
No sé si se trata de una exageración, pero en realidad se toca un tema muy espinoso y cierto como la vida misma: la falta de preparación de los futuros (y algunos actuales) programadores.
Y está claro que una de las medidas a tomar, desde el punto de vista de una empresa, es reforzar las pruebas y criterios de selección de su personal. No sé si el "FizzBuzz" es la solución, pero sin duda es un buen ejemplo: intentar conocer al candidato, sus habilidades y limitaciones básicas puede ayudar a descartar tarugos que pululan por el ciberespacio y han anidado masivamente en sitios web de ofertas de empleo. De esta forma, se evitará que entren en casa.
Pero el origen del problema es anterior a todo esto. ¿Qué se está enseñando en los centros de formación? ¿Qué nivel se exige a los estudiantes? ¿Existe todavía vocación en esta profesión?
Preocupante, ¿no?
Recordemos que los contenidos textuales se presentan en las imágenes mezclados con figuras y fondos que complican enormemente su detección automática. Si a la dificultad de detectar texto en esta maraña binaria se une que el mensaje está troceado en varias imágenes, las cuales se maquetan y posicionan después para que la lectura tenga sentido, esto se convierte en una labor prácticamente imposible.

Observad este ejemplo. El mensaje"Viagra" ha sido dividido en 6 imágenes, que se maquetan de forma consecutiva; prácticamente ninguna de ellas contiene texto que pudiera ser detectado por un OCR, y sin embargo se puede leer perfectamente.
Es posible que la solución a este problema sea intentar renderizar (¡uuf, vaya verbo, menos mal que la Wikipedia lo incluye!) el contenido de los mensajes, incluyendo sus imágenes, y someter el resultado a un OCR, de forma que si existen textos queden al descubierto. Sin embargo, además de la tremenda potencia de cálculo que hace falta para procesar en tiempo real esta información, sería fácil esquivarlo incluyendo secuencias animadas, como ya se comentó en un post anterior.
Si encuentro alguna solución brillante al problema, os la cuento. ;-)
Sí, y no estoy hablando de incluir personajes de la Warner en los mensajes. Se trata de enviar a los destinatarios mensajes con archivos gráficos (normalmente gifs) que contienen varios frames que, siendo visualizados de forma consecutiva, dan la sensación de movimiento, como si se tratase de una película.
Habitualmente, los primeros frames van en blanco, o con elementos de ruido para despistar a las herramientas OCR, que, parece ser, en un principio asumían que el archivo a rastrear sólo contenía una imagen. Los frames siguientes van componiendo el mensaje de forma sucesiva, a veces entremezclando los textos con píxeles y líneas de ruido.
También escuché hace tiempo que esto mismo se utilizaba para enviar spam con mensajes subliminales, que se servían de GIFs animados para mostrar durante un lapso de tiempo prácticamente imperceptible el texto describiendo el producto a vender... Esto, a diferencia del resto de técnicas que comento en los posts, no lo he visto nunca con mis propios ojos; no sé si es porque soy demasiado lento y mi subconsciente es incapaz de asimilar estos mensajes, o bien debido a que nunca he recibido un mensaje de este tipo.
Vía Slashdot, he encontrado un interesante artículo donde se propone una técnica para luchar contra el spam distinta a todas las comentadas hasta el momento. Pienso que no es la panacea, pero está bien saber que, al menos, hay gente dispuesta a acabar con esta lacra (además de Bill Gates, que como prometió hace un par de años, debe estar ya a punto de erradicarla ;-)).
El sistema consiste en centrarse en el análisis estadístico del tráfico desde varias ópticas, obviando el contenido de los mensajes. Como recogen en su artículo, los expertos de HexView recalcan que:
- Los mensajes son relativamente pequeños.
- Se envían en bloques.
- Los mensajes enviados en cada bloque son muy similares.
- El emisor de los mensajes envía muchos en un periodo muy corto de tiempo.
Tomando como partida estas premisas, y a que hay únicamente dos aspectos no manipulables por los spammers en los mensajes, que son las direcciones IP de origen y destino usadas por la conexión TCP sobre la que se transmiten, estos señores proponen el análisis de patrones según una metodología a la que llaman STP (de Source Trust Prediction, que viene a ser algo así como Predicción de Veracidad del Emisor).
A grandes rasgos, consiste en establecer un servidor intermedio (STP server) al que cada MTA (Mail Transport Agent, Agente de Transporte de Correo, o software de servidor encargado de gestionar los envíos como Exchange, Postfix, etc.) informaría, antes de aceptar un mensaje, de la dirección IP del remitente y algunos datos básicos del mismo. Dado que el servidor STP estaría al mismo tiempo recibiendo esta información de multitud de STPs, podría analizar los patrones y devolver a cada uno la probabilidad de que se trate de Spam.
Hay muchos más detalles en la web de los creadores de la idea.
En mi opinión, vale más como filosofía que como idea implementable en el mundo real, pues presenta numerosas dificultades y contraindicaciones, apuntadas por sus propios autores:
- La dificultad de crear sistemas capaces de gestionar en tiempo real las peticiones de los MTAs, ¿imagináis la cantidad de información de que se trata? ¿quién podría disponer de esa infraestructura y mantenerla? ¿a cambio de qué?
- La enorme dificultad de poner de acuerdo a una gran mayoría de servidores y fabricantes de software para que adoptaran el método. Posiblemente, si se pudiera llegar a un acuerdo, existirían muchas más soluciones, y con toda probabilidad más eficientes y eficaces que esta.
- Podría suponer un peligro para la privacidad: en un único punto se podría concentrar demasiada información sobre el comportamiento de los usuarios en cuanto al envío de mensajes.
Personalmente, me gusta la idea de analizar el tráfico, combinarla con el análisis de contenidos y, siempre, de forma personalizada. Por ejemplo, las probabilidades de que me interese un mensaje recibido en mi buzón un domingo a las 3:00am escrito en inglés, con una imagen y algunas palabras dispersas son bastante escasas.
En cualquier caso, como comentaba antes, es interesante ver las novedades que aparecen en este mundillo, aunque sean puramente conceptuales.
Una de ellas consiste en añadir ruido a la imagen. El ser humano, a diferencia de los sistemas OCR, es perfectamente capaz de distinguir texto en el interior de un elemento gráfico aunque éste se encuentre rodeado de todo tipo de "adornos", como se muestra en la siguiente captura
 .
.En el ejemplo, se puede observar cómo el texto que contiene el mensaje publicitario se ha incluido sobre un fondo no uniforme ni en sus formas ni en los colores utilizados. Incluso a ojo a veces es complicado leer determinados fragmentos... difícil tarea la del sistema de reconocimiento óptico, ¿eh?
Además, si lo que se pretende es llamar la atención del lector, no se puede negar que el resultado es de lo más llamativo.
Sin embargo, cuando, además de las imágenes, se incluye texto en el mensaje, las probabilidades de que una herramienta de filtrado de spam lo detecte como spam son enormes, por lo que entonces simplemente estaremos haciendo los mensajes más pesados y la efectividad seguirá siendo nula... ¿Cuál podría ser la solución al problema?
Efectivamente, prescindir de los elementos textuales en los correos publicitarios, o usarlos simplemente como elementos de despiste, e incluir todos los mensajes dentro de las imágenes enviadas a las víctimas. Un ejemplo se muestra en la imagen adjunta, tomada de un correo no deseado que he recibido recientemente.

En el mensaje se incluía esta imagen, acompañada de un texto enorme que con toda seguridad dejaría fuera de juego a un sistema de detección de spam basado en simples estadísticas de aparición de textos:
had a guess of what was coming. I saw I must speak soon before my strange after the wind rose, for at first it was dead calm to see the tempted to lend him a round sum, and see the last of him for good; but like a peal of bells, her face gay as a May morning; and I own, He told you to. she cried. It is no sense denying it, you said He heard the business out with a great deal of eagerness; and when it constancy upon my studies; and made out to endure the time till Alan never have been so troublesome as make the offer. But when he as good door. I made my disposition, and paid and dismissed the men so that yours from the first day, if you would have had a gift of me. she of a prospect, where there stood out over a brae the two sails of a with her head down, looking constantly on the sand, and made so tender forth. My mind misgives me, it will be some ill to Alan. Open it, know you have had more since you were here in Leyden, though you where was no man to be seen, nor any house of man, except just Bazins By your leave, Miss Drummond, said I, I must speak to your father by what a mercy had befallen me; and sitting over against her, with her out of Scotland and prompted by the same affair, which was the death of side, there is no objection to the marriage, but I have good reason to faithfully expended on my daughter, who is well, and desires to be I bid you beware. I will stand no more baiting, he broke out. I am unfit to come into a young maids life, and perhaps ding down her She shook her head at me with that same smile I could have struck her The which we did until the girl returned, and I must suppose would have no more let a wife be forced upon myself, than what I would let a The door was opened so quickly, even before I had the word out, that I streams of water running down, I would scarce think shame to weep hillock. Scarce any road came by there; but a number of footways position, where she had been entrapped into a moments weakness, and Alan smacked his lips. An unco lonely bit, said he, and I thought by For it was of course in my own rooms that I found them, when I came to Silvermills. But cheer up, my dear. yere bonnier than what he said. before ever I saw her; God knows I can be happy enough again when I alone in it; for, James More returning suddenly, the girl was changed Well, said I, this that I have got to say is very difficult, and I
La solución a esta nueva técnica ha sido la integración de OCRs y sistemas de análisis de imágenes en las herramientas de filtrado, que son capaces de acceder al contenido de los recursos gráficos y determinar si los textos incluidos en ellos son mensajes publicitarios o no.
No es tarea fácil: si envío a un familiar una foto mía junto a un cartel de coca-cola, ¿es spam?
La técnica en cuestión consistía en el envío de mensajes HTML en los que eran incluidas referencias a imágenes externas. Si conocéis algo este lenguaje de marcas, sabréis que para hacer referencia a una imagen en un contenido hipertexto basta con utilizar el tag IMG como se muestra a continuación:
<img src="DirecciónDeLaImagen" alt="Contenido textual alternativo" >El texto "DirecciónDeLaImagen" es la URL del recurso gráfico en cuestión, por ejemplo, http://www.google.com/images/logo_sm.gif. De esta forma, cuando un browser encuentra una marca de este tipo, acude a la dirección especificada, descarga el archivo (imagen, en este caso) y lo muestra al usuario integrado en el contenido de la página.
El caso es que una URL puede contener algo más que la dirección de un recurso, puede ir acompañada de parámetros. Por ejemplo, es perfectamente válido, y lo habréis visto más de una vez el uso de cadenas más complejas, de tipo http://www.loquesea.com/imagen?usuario=jmaguilar. Esto provoca que, cuando el navegador va a la dirección indicada a obtener el archivo, transmite al servidor el parámetro indicado (en el ejemplo, le transmitiría un parámetro llamado 'usuario' con un valor igual a 'jmaguilar'). El servidor en el que se aloja, a la vista de ese parámetro, puede actuar como considere oportuno.
Aplicado al siniestro mundo del spammer, esto ofrece unas posibilidades realmente interesantes. Pongamos que envío un mensaje a una víctima, incluyendo una imagen en cuyo origen (src) añado un parámetro que permite al servidor determinar el usuario que está solicitando la misma. Cada vez que este incauto individuo abra este mensaje, recibiré en mi servidor una petición de la imagen que, gracias al parámetro, sé de quién proviene, permitiéndome por ejemplo:
- primero y principal: asegurar que la dirección de email a la que envié el mensaje es correcta, y pasarla a mi carpeta de "destinatarios seguros". Puedo seguir enviando, pues, mensajes a esta persona con la seguridad de que lo va a recibir. De hecho, supongo que este es el motivo de que los que usamos la misma cuenta desde hace años, recibamos tal cantidad de spam. Seguro que en su día hemos confirmado, sin saberlo, nuestra existencia, y estamos en las "listas selectas".
- contar el número de veces que la persona abre el mensaje. ¿Podría esto servirme para determinar que realmente mi víctima está algo más interesado de lo normal en mi producto?
- modificar la imagen al vuelo, variando detalles del mensaje. Por ejemplo, si es la primera vez que el usuario accede, utilizar un mensaje publicitario; si accede de nuevo, ofrecerle una oferta más jugosa; si vuelve a acceder, emplear técnicas más agresivas de venta.
Afortunadamente, desde hace tiempo los clientes de correo basados en aplicaciones de escritorio no permiten, sin consentimiento del usuario, la descarga de imágenes externas, lo que evita la petición del fichero al servidor. Hay otros tipos de cliente, como los webmails que, en cambio, siguen descargando del origen cualquier recurso externo.
En cualquier caso, la técnica es interesante y demuestra, una vez más, la habilidad de los expertos del lado oscuro para aprovechar las posibilidades (o agujeros) existentes en cada momento en beneficio propio.






{kind=link}
{kind=link}