
Estas barreras, ciertamente frenan un 90% de los mensajes basura que recibo, esto es un hecho. Pero no es menos cierto que, a pesar de ello, una vez al día tengo que perder mi
Seguro que a todos los tenemos direcciones de correo algo añejas nos ocurre lo mismo. Como en otros aspectos de la vida, a principios de los noventa podíamos relacionarnos con otros sin precauciones. Recuerdo cómo podía participar alegremente en foros utilizando mi nombre y dirección email habitual. Eso en la actualidad esto es impensable, y seguro que todos tomamos precauciones; en general, la mejor opción es la difusión racional de las direcciones de correo, y para ello se pueden encontrar algunas ayudas, como la que ya comenté hace algún tiempo, el uso de buzones temporales.
A pesar de todo, es interesante observar el talento y la creatividad que existe a veces detrás de estos mensajes. Como en el caso de los creadores de virus, troyanos y similares, me resulta admirable cómo los creadores de estos engendros evolucionan con el tiempo, adaptándose a los cambios y modificando su forma de actuar para estar siempre por delante de aquellos que intentan detenerlos.
Por ello, me he decidido a iniciar esta serie de artículos en los que iré comentando distintas técnicas que emplean estos individuos para conseguir transmitirnos un mensaje sin ser detectados por los complejos sistemas de filtro existentes en la actualidad.
Y sí, la verdad es que llevo tiempo viéndolos, pero hasta este momento no me he preguntado para qué servían. ¡Cómo se nota que todavía soy muy nuevo en esto!
Como no podía ser de otra forma, he acudido raudo a ver de qué se trataba y, efectivamente, he encontrado descrito, en un correcto inglés, qué son, para qué sirven y cómo se usan.
En pocas palabras, los tags se usan en los blogs para "etiquetar" el contenido, de forma que puedan ser indexados de forma correcta por motores de búsqueda especializados (como el propio technorati). Al etiquetar una página, aseguramos que cuando sea visitada por los robots de estos sistemas, será catalogada justo donde creamos que debe serlo.
Bueno, pues decidido está. A partir de ahora, para no ser menos que nadie, yo también usaré el tagging. Además, voy a actualizar algunos posts anteriores para incluírselos, aunque después de ser publicados no sé si servirá para algo.
Chacha es un buscador de reciente aparición que aporta una nueva forma de búsqueda, un nuevo modelo de interacción, ya conocido por todos en otros entornos como el telefónico: la búsqueda guiada. Chacha pone a nuestra disposición una persona humana (valga la redundancia ;-)) que nos ayuda a localizar lo que andemos buscando, de la misma forma que, en vez de usar las guías amarillas podemos llamar a un servicio de atención telefónica y preguntarlo a los teleoperadores.
Esta mañana he estado conversando con un guía de Chacha. Más o menos la secuencia ha sido la siguiente (traducida del inglés):
Entro en chacha, tecleo la palabra "Zope" y pulso el botón "Búsqueda asistida".
(Collin): "Hola, soy tu asistente. Intentaré ayudarte a buscar lo que necesitas"
(YO): "Hola"
(Collin): "Hola. ¿En qué puedo ayudarte?"
(YO): "Es la primera vez que uso este servicio. ¿Es real?"
(Collin): "Sí, totalmente real. :-D"
(YO): "Entonces, ¿no eres un bot?"
(Collin): "Pues no, me llamo Collin y vivo en Washington"
(YO): "Impresionante. Yo soy de España"
(Collin): "Y ¿qué tal? ¿Te gusta el servicio?"
(YO): "Pues sí, me parece increíble que Internet nos siga sorprendiendo con este tipo de ideas"
(Collin): "Estupendo."
(YO): "¿Atiendes a mucha gente?"
(Collin): "Depende del momento. Ahora mismo está la cosa tranquila, pues es ya bastante tarde"
(Collin): "¿Puedo ayudarte en algo?"
(YO): "Busco información sobre Zope"
(Collin): "Un momento, a ver qué puedo encontrar"
Aparece el resultado de la búsqueda, un enlace a la definición "Zope" de la Wikipedia.
(Collin): "¿Te vale el resultado?"
(YO): "Bueno, buscaba algo menos básico, como información sobre programación con Zope".
(Collin): "Un momento..."
Aparecen varios resultados más, esta vez algo más afinados
(Collin): "Voy a seguir buscando, avísame cuando creas que es suficiente."
(YO): "Creo que me valen con esos, Collin."
(Collin): "Estupendo. ¿Puedo ayudarte en algo más?"
(YO): "De momento no, muchas gracias."
(Collin): "Hasta la vista."
(YO): "Bye"
Al finalizar la sesión, una página recoge los resultados ofrecidos por el asistente, los recursos utilizados para encontrarlos (Google en este caso) y un cuadro en el que puedo valorar el servicio ofrecido por mi amigo Collin. De hecho, si entráis en Cacha y realizáis la consulta "Zope", el resultado que aparece a día de hoy es el que me ha dado este asistente.
Desde luego, no se puede negar la humanidad que aporta este servicio a algo tan cotidiano y tremendamente automatizado como es la búsqueda por Internet. En cuanto a los resultados, obviamente mejorables, puesto que una persona no necesariamente experta en el ámbito de nuestra búsqueda puede enviarnos a sitios insospechados y de dudosa calidad, pero bueno, al menos lo intentan. Además, se supone que las búsquedas son almacenadas e irán, con el tiempo, refinándose gracias a las valoraciones de los usuarios y, por qué no, a la experiencia de sus operadores.
En resumen, no creo que cambie mi buscador habitual por este, pero sí que es verdad que puede resultar interesante para lobos solitarios y personas que, en general, prefieran la conversación a la introducción de criterios, lo humano a lo electrónico, aún asumiendo las imperfecciones en las respuestas inherentes a la primera opción.
Etiquetado como: chacha::buscadores::interacción::servicios on-line::ayuda
Una opción bastante razonable es, sin duda, OpenCMS. Este veterano gestor de contenidos está basado en Java y XML, utilizando como almacén de datos el celebérrimo MySQL, lo cual contribuye al carácter multiplataforma del producto. Por cambiar un poco, vamos a instalarlo sobre un Windows XP Professional limpio, a ver qué tal resulta la experiencia, y en este post iré reflejando cada paso a dar hasta ponerlo en marcha.
Antes de comenzar: cumplir los requisitos
Es una buena costumbre antes de iniciar una instalación de este tipo repasar la lista de requisitos, normalmente disponible en el sitio web de los desarrolladores del producto. En este caso encontramos que OpenCMS necesita:- Java 2 SDK. Curiosamente, no es suficiente con la JRE, es necesario instalar el kit de desarrollo completo, señal de que se realizarán compilaciones al vuelo. Las notas de revisión recomiendan la versión 1.4 o superior; para ir a la última nos decantaremos por la 1.5, la más reciente, disponible para descargar en http://java.sun.com/javase/downloads.
- Contenedor de servlets que responda a los estándares Servlet 2.3 / JSP 1.2. Vamos a instalar Tomcat, que es la implementación de referencia oficial para dichas tecnologías. La descarga de la versión 5.5 podemos realizarla desde la dirección http://tomcat.apache.org/download-55.cgi.
- MySQL como sistema gestor de bases de datos, que podemos obtener desde http://dev.mysql.com/downloads/index.html.
La instalación de Java no supone ninguna dificultad, simplemente la habitual serie de clics sobre el botón "Aceptar" en un asistente de instalación típico.
Tomcat, por su parte, ofrece también un sencillo asistente que nos permitirá poner en funcionamiento este software en pocos segundos. He dejado todos los parámetros como aparecen en el instalador (concretamente el directorio de instalación, puerto de acceso http, y el nombre de usuario y contraseña del administrador), y tras el par de clics de rigor, podemos observar en el área de notificación el icono indicando que Tomcat está en ejecución.
MySQL, como no podía ser de otra forma, proporciona también un instalador que hace que su puesta en marcha sea un juego de niños. Tras finalizar la copia de archivos, se inicia de forma automática el "Instance Configuration Wizard", que permite realizar ajustes en la instancia de la base de datos antes de ponerla en marcha. Existen multitud de opciones a elegir, sin embargo, en este caso, he seleccionado las propuestas por el sistema salvo en el juego de caracteres, donde he optado por UTF-8, para dar soporte a lenguas no occidentales. Dado que esto es una máquina para hacer pruebas, no he tenido en cuenta nada relacionado con la optimización del espacio a ocupar, el rendimiento o aspectos parecidos. Eso lo dejamos para máquinas que vayan a entrar en producción, que no es nuestro caso. 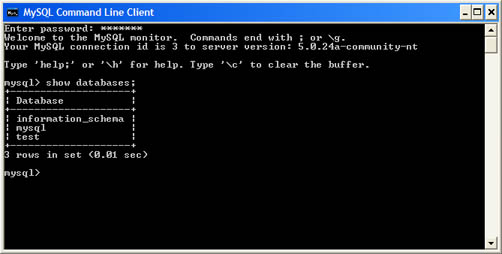
Para comprobar que el motor está instalado y en funcionamiento, podemos ejecutar el cliente de línea de comandos que podemos encontrar en el menú Inicio > Programas > MySQL. Una vez introducida la contraseña de administrador que le hemos suministrado con anterioridad, estaremos conectados al SGBD.
Pero ojo, según recomiendan, es conveniente modificar el archivo de configuración, "My.ini", disponible en el directorio donde se haya instalado MySQL y modificar el parámetro max_allowed_packet asignándole el valor "16M". Sin embargo, en instalaciones simples del motor de datos, esta variable ni siquiera existe, por lo que es necesario crearla a mano en el fichero de configuración. Es sencillo, basta con localizar la sección [mysqld] (en mi caso se encuentra sobre la línea 75) y añadir una nueva línea tal y como se recoge en el siguiente recorte:
[...]
# SERVER SECTION
# -----------------------------------------------
# The following options will be read by the MySQL
# Server. Make sure that you have installed the
# server correctly (see above) so it reads this
# file.
#
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
max_allowed_packet = 16M # Nueva línea !!!!
#Path to installation directory. All paths
# are usually resolved relative to this.
[...]
Al grano: instalando OpenCMS.
Ya tenemos la infraestructura necesaria para comenzar la instalación de OpenCMS. En primer lugar, descargamos la versión más reciente del software, dispensada en un archivo .zip descargable desde la web oficial. La actual, numerada como 6.2.2, pesa unos 27Mb.En su interior podremos encontrar un archivo llamado "opencms.war" que debe ser copiado la carpeta "Webapps" existente en el directorio donde se haya instalado Tomcat. En mi caso la ruta completa es C:\Archivos de programa\Apache Software Foundation\Tomcat 5.5\webapps.
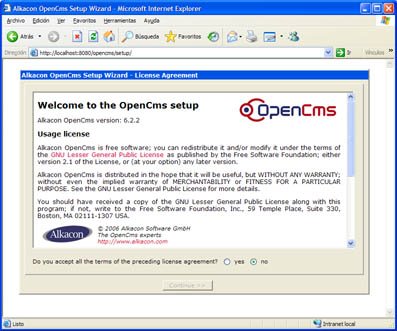
Acto seguido, reiniciamos Tomcat. Esto puede hacerse de varias formas, pero lo recomendable en este momento es pulsar con el botón derecho del ratón sobre el icono del servicio (junto al reloj), deterner el servicio y volver a iniciarlo. Esto provocará que OpenCms entre a formar parte de las aplicaciones instaladas en Tomcat y podamos acceder con el navegador al asistente de instalación utilizando la url http://localhost:8080/opencms/setup.
Una vez aceptado el texto de licencia, que por otra parte no recuerdo haber leído nunca ;-P, el asistente mostrará el resultado de una evaluación del equipo. Como hemos hecho perfectamente los deberes, todos los indicadores aparecen en verde indicando que cumplimos con los requisitos exigidos para correr OpenCms.
Acto seguido, el sistema nos preguntará sobre aspectos relacionados con la base de datos: motor y versión instalado, datos del usuario de acceso general, usuario de acceso para OpenCms y nombre de la BD a crear. En mi caso sólo ha sido necesario retocar los passwords de acceso para los usuarios, el resto lo he dejado todo con los valores por defecto.
El resto de pasos del asistente consisten en la consabida serie de clics siguiente... siguiente... siguiente..., mientras vamos desfilando por pantallas donde se nos pregunta qué módulos queremos instalar (¡vaya pregunta! ¡pues todos, por supuesto! ;-D) o el nombre del servidor, entre otros detalles.
Tras una espera de varios minutos mientras se instalan los módulos
A partir de este momento, podemos acceder al portal OpenCms a través del enlace que el propio asistente de instalación nos muestra, donde aparecerá una página inicial de bienvenida, así como información para acceder al Workplace, o en otras palabras, a la aplicación de administración de la plataforma, también basada en Web y que tiene muy buena pinta.

Ea, pues misión cumplida, esto está en funcionamiento.
Etiquetado como: opencms::cms::portal::instalación
Haloscan commenting and trackback
have been added to this blog.
En fin, a ver si alguien se anima y estrena el nuevo sistema haciendo un comentario, un trackback o lo que sea. Bueno, o mejor, para no esperar, los haré yo mismo.
La pena es que los comentarios que tenía hasta el momento, aunque eran escasos, todavía no sé muy bien dónde han ido a parar... tendré que investigar un poco.
Se trata de un juego bastante entretenido, programado con AJAX a tope (como de costumbre en la casa), que está accesible a través de la dirección http://images.google.com/imagelabeler/, aunque de momento sólo en inglés. La mecánica es muy simple: el sistema selecciona al azar un usuario que en ese momento esté conectado, que será nuestro compañero de juego, y a partir de ese momento, irán apareciendo, tanto a él como a nosotros, imágenes que debemos describir sugiriendo etiquetas (labels) que las describirían; cuando alguna de las palabras que enviamos coincide con una de las aportadas por nuestro partner, obtendremos puntos y el sistema pasará a la siguiente imagen. Y así durante 90 segundos.
Esto no pasaría de ser una pequeña curiosidad sin demasiada relevancia, si no fuera por el verdadero objeto del sistema: llenar las bases de datos de información sobre las imágenes, y parece ser que con el único fin de entrenar sus sistemas expertos de reconocimiento automático, los que, según comentan, revolucionarán los motores de búsqueda de imágenes en un plazo relativamente breve.
La idea del etiquetado humano de imágenes no es nueva, ha sido y está siendo utilizada en otros proyectos como el ESP Game, donde a día de hoy se han recogido cerca de 18 millones de etiquetas que son utilizadas en su propio buscador. Sin embargo, esto presenta una importante limitación: la actualización. Cada vez que se registra una nueva imagen es necesario que alguien la etiquete, lo cual no siempre es factible.
Conscientes de este inconveniente, los chicos de Google han debido llegar a la conclusión de que la catalogación de imágenes para facilitar las búsquedas debe ser resuelta en su totalidad de forma automática, es decir, utilizando software. Por ello están adquiriendo compañías especializadas en tratamiento digital de imágenes, haciéndose de aplicaciones existentes y, a veces, desarrollando sus propios sistemas, con objeto de disponer de software capaz de reconocer patrones en imágenes, detectar elementos, textos (no olvidemos el famoso proyecto de OCR en el que también están trabajando), personas u otros objetos en imágenes y siempre sin intervención humana.
La originalidad está en utilizar las palabras obtenidas con el juego simplemente para hacer baterías de pruebas automatizadas que les permitan afinar este software. Genial, ¿no?
Habrá quien se pregunte que cómo de fiables pueden ser las etiquetas teniendo en cuenta la diversidad y anonimato de los jugadores/colaboradores. Y, sin duda, cabe cierto margen de error, aunque pensándolo un poco, el juego está ideado para minimizar estos problemas: la elección aleatoria del compañero o el puntuar (y almacenar) las palabras coincidentes son muestras de ello.










{kind=link}
{kind=link}