
Sin embargo, la infraestructura Ajax nos brinda otra forma de invocar funcionalidades de servidor sin necesidad de crear servicios web de forma explícita: los métodos de página (Page Methods). El objetivo: permitirnos llamar a métodos estáticos de cualquier página (.aspx) desde el cliente utilizando Javascript y, por supuesto, sin complicarnos mucho la vida. Impresionante, ¿no?
En este post vamos a desarrollar un ejemplo parecido al anterior, en el que tendremos una página web con un cuadro de edición para introducir nuestro nombre y un botón, cuya pulsación mostrará por pantalla el resultado de la invocación de un método del servidor, y todo ello, por supuesto, sin provocar recargas de página completa. El resultado vendrá a ser algo así:

Ah, para que no se diga que soy partidista ;-) esta vez vamos a desarrollarlo en Visual Basic .NET (aunque la traducción a C# de la porción de servidor es directa), y de nuevo con Visual Studio 2005.
En primer lugar, hemos de crear la solución (Visual Studio 2005) basándonos en la plantilla "ASP.NET Ajax-Enabled web application" que habrá aparecido en nuestro entorno tras descargar e instalar las extensiones AJAX. Una vez elegido el nombre, se creará un proyecto con todas las referencias necesarias, el web.config adaptado, y una página (Default.aspx) que viene ya preparada con el ScriptManager listo para su uso.
En el archivo code-behind (Default.aspx.vb) añadimos el siguiente código, que será la función de servidor a la que invocaremos desde el cliente:
<WebMethod()> _
Public Shared Function Saludame(ByVal Nombre As String) As String
Return "Hola a " + Nombre _
+ " desde el servidor, son las " _
+ DateTime.Now.ToString("hh:mm:ss")
End Function
Obsérvese que:
- El método es público y estático. Lo primero es obvio, puesto que el ScriptManager necesitará mapearlo al cliente y para ello deberá acceder mediante reflexión a sus propiedades, y lo segundo también, puesto que las invocaciones al mismo no se efectuarán desde instancias de la clase, imposibles de conseguir en cliente.
- Está adornado con un atributo WebMethod, que indica al ScriptManager que el cliente podrá invocarlo utilizando Javascript.
Sólo falta un detalle. Hay que indicar al ScriptManager de la página que se encargue de procesar todos los métodos públicos estáticos de la clase, que además estén marcados con el atributo anteriormente citado, y genere la infraestructura que necesitamos para utilizar de forma directa esta funcionalidad. Esto se consigue estableciendo la propiedad EnablePageMethods a true desde el diseñador.
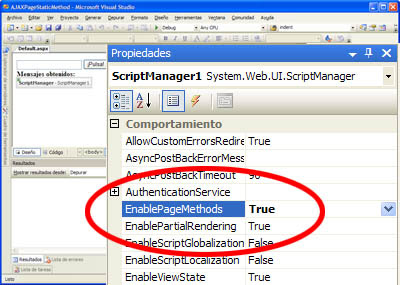
Una vez hecho esto, introducimos en el aspx de la página los elementos de interfaz (el cuadro de texto, el botón y un label para mostrar los resultados). El código del formulario completo queda así:
<form id="form1" runat="server">
<input type="text" id="nombre" />
<input id="Button1" type="button"
value="¡Pulsa!" onclick="llamar();" />
<br />
<strong>Mensajes obtenidos:</strong>
<br />
<label id="lblMensajes" />
<asp:ScriptManager ID="ScriptManager1"
runat="server" EnablePageMethods="True" />
</form>
Podemos ver, como en el post anterior, que todos los controles salvo el ScriptManager son de cliente, no tenemos el runat="server" en ninguno de ellos puesto que no realizaremos un envío de la página completa (postback) en ningún momento, todo se procesará en cliente y actualizaremos únicamente el contenido del label.
Por último, añadimos el script que realizará las llamadas y mostrará los resultados. La función llamar(), invocada a partir de la pulsación del botón y la de notificación de respuesta. El código es el siguiente:
<script type="text/javascript">
function llamar()
{
PageMethods.Saludame($get("nombre").value , OnOK);
}
function OnOK(msg)
{
var etiqueta = $get("lblMensajes");
etiqueta.innerHTML += msg + "<br />";
}
</script>
Primero, fijaos en la forma de llamar a Saludame(). El ScriptManager ha creado una clase llamada PageMethods a través de la cual podemos invocar a todos los métodos de la página de forma directa.
El primer parámetro de la función es $get("nombre").value. Ya vimos el otro día que $get("controlID") es un atajo para obtener una referencia hacia el control cuyo identificador se envía como parámetro. Por tanto, $get("nombre").value obtendrá el texto introducido en el cuadro de edición.
Después de los parámetros propios del método llamado, se indica la función a la que se pasará el control cuando obtenga el resultado desde el servidor. OnOK recibirá como parámetro la respuesta de éste, el string con el mensaje de saludo personalizado, y actualizará el contenido de la etiqueta para mostrarlo.
En resumen, los PageMethods son una interesantísima característica del framework AJAX de Microsoft, y nos permiten llamar a funciones estáticas definidas directamente sobre las páginas aspx, evitando el engorro de definir servicios web (asmx) de forma independiente, y sobre todo, ayudando a mantener en un único punto el código relativo a una página concreta ¡y qué mejor sitio que la propia página!
(Puedes descargar el proyecto completo.)
Y dado que AJAX cubre la parte cliente, es obvio pensar que el complemento ideal en el lado del servidor son los servicios web, dada la coincidencia en el lenguaje de intercambio utilizado (XML), y la facilidad con que se desarrollan, despliegan y comunican.
El framework publicado por Microsoft hace unos meses, llamado ATLAS durante su periodo de desarrollo, facilita enormemente la tarea de inclusión de características AJAX en aplicaciones ASP.NET. El sistema completo se entrega en dos paquetes:
- ASP.NET 2.0 AJAX Extensions, que es el componente base que establece la infraestructura para la utilización de esta tecnología sobre páginas asp.net. El ejemplo que desarrollaremos en este post se basa en estos componentes.
- ASP.NET AJAX Control Toolkit, que incluye un buen número de componentes visuales y no visuales que hacen uso de la infraestructura AJAX a todo trapo. Algunos son una maravilla, y además es un proyecto compartido con la comunidad bajo licencia MsPL.
A lo largo de este post vamos a desarrollar paso a paso un ejemplo completo de interacción de un cliente con un servidor utilizando AJAX. El proyecto será bien simple, pero creo que suficientemente ilustrativo: crearemos con VS2005 una página web con un botón, cuya pulsación provocará que se obtenga desde el servidor un mensaje, que será mostrado por pantalla, ¡y todo ello sin provocar recarga de la página! En primer lugar, abrimos Visual Studio 2005 y creamos un proyecto. Para facilitar la tarea, la instalación del framework AJAX habrá incluido una plantilla llamada "ASP.NET Ajax-Enabled web application", que es la que debemos elegir. De esta forma, se añadirán las referencias necesarias para que todo funcione.
En primer lugar, abrimos Visual Studio 2005 y creamos un proyecto. Para facilitar la tarea, la instalación del framework AJAX habrá incluido una plantilla llamada "ASP.NET Ajax-Enabled web application", que es la que debemos elegir. De esta forma, se añadirán las referencias necesarias para que todo funcione.
 Hecho esto, el entorno habrá creado una página "default.aspx" a la que simplemente habrá añadido un control de servidor de tipo ScriptManager. Este control es el que hace la magia, como veremos más adelante, asilándonos de la complejidad real que tiene una comunicación asíncrona con el servidor como la que vamos a realizar.
Hecho esto, el entorno habrá creado una página "default.aspx" a la que simplemente habrá añadido un control de servidor de tipo ScriptManager. Este control es el que hace la magia, como veremos más adelante, asilándonos de la complejidad real que tiene una comunicación asíncrona con el servidor como la que vamos a realizar.
A continuación añadimos al proyecto un servicio web, con lo que Visual Studio generará un archivo estándar con un método, el consabido HelloWorld(), que devuelve un string con el mensaje de saludo.
Pues bien, aquí es donde empieza la fiesta. En primer lugar, vamos a modificar ligeramente este método para que devuelva mensajes diferentes y podamos comprobar, a posteriori, el funcionamiento del sistema.
Por ejemplo, añadiremos al saludo la hora actual del servidor:
[WebMethod]
public string HelloWorld()
{
return "Hola a todos desde el servidor, son las " +
DateTime.Now.ToString("hh:mm:ss");
}Además, introducimos justo antes de la declaración de la clase, en las primeras líneas del archivo, la declaración del atributo [ScriptService] de la siguiente forma:
...
[System.Web.Script.Services.ScriptService] // ¡Necesario!
public class ServicioWeb : System.Web.Services.WebService
...
De esta forma, indicamos que la clase contiene servicios que serán accedidos desde el cliente utilizando scripting (javascript). Y con esto, hemos acabado con la parte de servidor, pasamos ahora a ver el lado cliente, cómo utilizamos este servicio.
En primer lugar, añadimos dos controles a la página web (default.aspx), un botón que provocará la llamada al servidor, y una etiqueta donde iremos mostrando los resultados. El código es el siguiente:
<input id="Button1" type="button" value="¡Pulsa!" onclick="llamar();" />
<br />
<strong>Mensajes obtenidos:</strong><br />
<label id="lblMensajes"></label>Podemos observar, ninguno de los controles introducidos son de servidor, es decir, no incluyen un runat="server". Es lógico, pues toda la interacción la vamos a realizar en cliente.
Además, vemos que el botón incluye un controlador del evento OnClick, la función llamar() de javascript. La idea es que esta función obtenga del servidor el mensaje de saludo correspondiente, y vaya añadiéndolo al contenido de la etiqueta. Basta con añadir el siguiente código a la página, dentro del correspondiente tag <script>:
function llamar()
{
AJAXWSDemo.ServicioWeb.HelloWorld(OnLlamadaFinalizada);
}Aquí hay varios aspectos a destacar. En primer lugar, que estamos llamando al método HelloWorld desde script (en cliente) indicando la ruta completa hasta el mismo, es decir, el namespace (AJAXWSDemo) y la clase donde se encuentra (ServicioWeb). ¿Y cómo es posible esto? Por obra y gracia del control ScriptManager, que ya vimos anteriormente, que es quien ha encargado de generar un envoltorio (wrapper) apropiado para los servicios a los que vamos a acceder desde el cliente, haciéndolo así de sencillo.
Sin embargo, para que ScriptManager sea consciente de los servicios que debe gestionar, hay que indicárselo expresamente, incluyendo el siguiente código dentro del propio control. Creo que se entiende directamente, lo que hace es crear una referencia a la url que contiene los métodos a los que vamos a llamar:
<asp:ScriptManager ID="ScriptManager1" runat="server">
<Services>
<asp:ServiceReference Path="ServicioWeb.asmx" />
</Services>
</asp:ScriptManager>
...
Hecho este inciso, continuamos ahora comentando la función llamar(). Por otra parte, vemos un parámetro extraño en la llamada al método, "OnLlamadaFinalizada". Esto es así porque las llamadas a servicios deben incluir un parámetro adicional que es la función a la que el sistema notificará que ha completado la invocación al método. Hemos de recordar que las llamadas son, por defecto, asíncronas; esto quiere decir que el sistema no espera a su finalización, la llamada se realiza en background y cuando son completadas el control se transfiere a la función de notificación que hayamos elegido.
A esta misma función de retorno le llegará un parámetro, el valor devuelto desde el servicio web. Por este motivo, no es necesario obtener el valor de retorno en el momento de invocación del método remoto.
El código para la función de retorno es, en nuestro caso,
function OnLlamadaFinalizada(resultado)
{
var etiqueta = $get("lblMensajes");
etiqueta.innerHTML += resultado + "<br />";
}
En este caso, destacamos varios aspectos también. En primer lugar, como hemos comentado anteriormente, el parámetro que recibe la función es el retorno del servicio web invocado.
También puede que llame la atención la expresión $get("lblMensajes"). Se trata de un atajo que evita tener que introducir el código "document.getElementById(...)" necesario para obtener referencias a un control de la página.
El resultado final se puede ver en la siguiente captura, demostrando, además, que funciona perfectamente en Firefox:

Y para los perezosos, he dejado en http://www.snapdrive.net/files/415885/AJAXWSDemo.zip el proyecto VS2005, para que podáis jugar con él sin necesidad de teclear nada.
Actualización: si has leído hasta aquí, es posible que también te interese este otro post donde se muestra otra forma de comunicarse con el servidor utilizando ASP.NET 2.0 AJAX.
Lenguajes de programación, plataformas, aplicaciones, comentarios... más de 50 posts en los que hay de todo un poco: artículos de iniciación, curiosidades, descubrimientos, comentarios sobre temas de actualidad, reflexiones, temas algo más avanzadillos o de ámbito muy específico... en fin, lo que me ha pedido el cuerpo en cada momento.
Sin embargo hay una parte, sin duda la fundamental, que no la he podido poner yo: el sentido de todo esto. ¿Qué es un blog sin lectores? Os puedo asegurar que he disfrutado escribiendo cada post, pero las alegrías han venido con cada comentario, con cada visita, con cada referencia.
Nada más sencillo. Suponiendo que partimos de un linux basado en Debian, como Ubuntu, basta con descargar e instalar nmap:
apt-get install nmapUna vez contando con esta herramienta, para realizar un escaneo al host [victima] a través del zombie [zombie] la instrucción sería la siguiente:
nmap –sI [zombie] –P0 [victima]Donde:
- "-sI" indica que se debe realizar el idle scan.
- [zombie] es la dirección, en forma de IP o nombre, del equipo elegido como zombie.
- "-P0" indica que no se debe realizar un ping directo para comprobar si la víctima está activo.
- [victima] es la dirección, IP o nombre, de la misma.
- opcionalmente, puede indicarse el parámetro "-p" seguido de los números de puerto a escanear, por defecto nmap hará un barrido bastante completo y puede tardar un poco. Ante la duda, un "man nmap" puede venir bien.
Pero ojo, no es fácil dar con servidores que cumplan los requisitos necesarios para ser considerados buenos zombies, puesto que en la mayoría se usan IPIDs aleatorizados, fijos o secuencias por cliente.
Además, recordad que debéis ser root (o ejecutar las órdenes con sudo) para que todo funcione correctamente.
Sin embargo, su utilidad se vería reducida en la práctica si su creación fuera compleja. Pero nada más lejos de la realidad, la obtención de un Guid es extremadamente sencilla:
// C#:
Guid g = Guid.NewGuid(); // Obtiene un nuevo GUID
Console.WriteLine(g); // Lo muestra por consola
' Visual Basic .Net:
Dim g as Guid = Guid.NewGuid() ' Obtiene un nuevo GUID
Console.WriteLine(g) ' Lo muestra por consola
Podemos observar que la clase (estructura) Guid (incluida en el namespace System) contiene un método estático que nos permite generar y obtener objetos de este tipo de forma directa. Además, recordemos que cada vez que generamos un GUID tenemos la seguridad casi absoluta de que será único, lo que hace que podamos utilizarlo directamente como identificador del elemento deseado.
Se trata de idle scan, una ocurrente forma para detectar los puertos abiertos en una máquina remota sin poner al descubierto al atacante, es decir, al equipo que realiza el escaneo. Para ello, se vale de una máquina intermedia, llamada zombie o dumb, que ejerce como intermediario en la comunicación y hace que en ningún caso la víctima reciba paquetes directamente desde el atacante, quedando éste en el más absoluto anonimato.
Bueno, he de decir que si no tienes claro el funcionamiento del protocolo TCP y el establecimiento de conexiones, es probable que debas pegar un repaso antes de seguir leyendo el post. En todo caso será una lectura aconsejable para todo humano interesado en saber qué está ocurriendo por debajo cuando estamos utilizando servicios en una red como Internet.
Ahora vamos al lío. La cuestión es que todo intrépido pirata sabe que antes de iniciar el ataque a una ciudad costera es conveniente ver los puertos en los que se puede atracar para hacer el desembarco, ¿no? Pues en Internet ocurre lo mismo, un puerto abierto en un equipo conectado a la red es siempre una posible vía de entrada al mismo; indica que hay una aplicación escuchando en la máquina, y habitualmente puede averiguarse cuál es y explotar sus debilidades.
Por tanto, un ataque tipo debería ir precedido de un escaneo de los puertos abiertos, es decir, recorrer los 65535 puertos posibles (o al menos el subconjunto de uso más habitual) a ver cuáles están en uso. La pega es que esto suele ser demasiado ruidoso, no son pocos los sistemas de detección de intrusos y filtros que detectan peticiones sucesivas desde una misma dirección y las clasifican de inmediato como sospechosas pudiendo llegar a banear (prohibir) la conexión desde la IP que está haciendo el barrido, o incluso a registrar la dirección para más adelante poder tomar medidas legales si procede.
Esta es la razón que hacen de Idle Scan una técnica interesante, puesto que, como he comentado antes, en ningún momento el atacado es consciente de la dirección del atacante.
Para ello se aprovecha, en primer lugar, el funcionamiento del three way handshake, el protocolo estándar utilizado para el establecimiento de conexiones TCP, donde de forma habitual:
- El procedimiento se inicia cuando el cliente envía un paquete SYN al servidor. Si es posible realizar una conexión, éste responde con un SYN + ACK, y el cliente debe confirmar enviando de nuevo un ACK al servidor. En caso contrario, es decir, si no es posible realizar la conexión porque el puerto esté cerrado, el servidor responde con un RST y se da por finalizada la secuencia.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de confirmación de conexión SYN+ACK de otro, responde con un RST con objeto de informarle de que no va a establecerse conexión alguna.
- Si un host, sin haberlo solicitado previamente, recibe un paquete de reseteo (RST), lo ignora.
Para detectar si un puerto está abierto o cerrado, es necesario primero observar el IPID del zombie, enviar paquetes a la víctima haciéndole ver que realmente se los está enviando éste y, posteriormente, observar de nuevo el IPID utilizado por el incauto intermediario. En función de los valores iniciales y finales obtenidos, se puede inferir el estado del puerto destino.
A continuación se exponen dos escenarios distintos de escaneo; en el primero de ellos se muestra lo que ocurre cuando el puerto objeto de la detección está abierto, mientras que en el segundo se supone que está cerrado.
Escenario 1: Víctima con el puerto abierto
El primer paso es enviar al zombie un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente, del cual tomaremos el IPID.Acto seguido, se realiza una solicitud de conexión a la víctima, previa manipulación del paquete para que sea el zombie el que figure como origen del mismo. Al recibirlo, dado que estamos asumiendo que el puerto está abierto (escenario 1), la víctima envía de vuelta la confirmación de la conexión al que cree que es el solicitante, el zombie.
El zombie recibe la confirmación de la conexión, pero como no es él el que la ha generado, responde a la víctima con una señal de reseteo (RST), incrementando su IPID.
De nuevo, pasado unos segundos, desde el atacante se vuelve a obtener el IPID del zombie de la misma forma que al comienzo, comprobando que ha sido incrementado en 2 unidades. De esta forma, se determina que el puerto destino del escaneo estaba abierto.
El siguiente diagrama muestra la secuencia forma gráfica:

Escenario 2: Víctima con el puerto cerrado
Como en el escenario anterior, el primer paso siempre es obtener el IPID del zombie, enviándole un paquete SYN+ACK, con objeto de que éste nos devuelva el paquete RST correspondiente.
De la misma forma, se envía a la víctima el paquete de solicitud de conexión, indicando en las cabeceras que el origen del mismo es el host zombie. Dado que el puerto está cerrado (escenario 2), la víctima devuelve al aparente emisor un paquete RST indicándole que no será posible establecer la conexión solicitada. El zombie recibe el paquete RST y lo ignora.
El atacante, siguiendo la misma técnica que en otras ocasiones, obtiene el IPID del zombie, y dado que es el número siguiente al recibido al iniciar el procedimiento, puede determinar que no ha realizado ningún envío entre ambos, y que, por tanto, el puerto de destino estaba cerrado.

Desde el punto de vista del atacante las ventajas son, fundamentalmente:
- El anonimato, puesto que desde la víctima todas las conexiones provienen virtualmente del zombie, y en ningún momento se envía información directamente desde el atacante.
- El alcance, es decir, esta técnica permite escanear puertos de máquinas a las que directamente no se tendría acceso debido a la acción de filtros (como firewalls) intermedios. Dado que las conexiones provienen del zombie, sólo habría que tener acceso a éste para realizar el escaneo.
- La visión de red que aporta, en otras palabras, permite determinar las relaciones de confianza existentes entre el zombie y la víctima. Si, por ejemplo, un intento directo de conexión a un puerto de la víctima es rechazado y, sin embargo, es posible acceder a él desde un intermediario, es porque existe algún tipo de relación de confianza entre ambos, lo cual puede ser utilizado en ataques posteriores.
En la actualidad, el principal inconveniente es la dificultad de localizar un zombie apropiado para realizar los ataques, tanto por las condiciones software que debe cumplir (sistemas operativos, kernels, etc.), el escaso tráfico de red que debe tener en el momento del escaneo (necesarios para que los IPID no se incrementen por otras conexiones) y, sobre todo, las medidas de seguridad de que disponga, puesto que desde él sería posible detectar al atacante.






{kind=link}