
miércoles, 15 de noviembre de 2006
Pero no, no vengo de Marruecos. Al final se canceló el viaje, y la salida está programada para el próximo lunes 20 de Noviembre.
De momento acabo de librarme de atravesar el estrecho con un temporal de narices, climatológicamente hablando. Todo un alivio para alguien al que no suelen sentar demasiado bien los viajes movidos.
En los pronósticos para el lunes hay diversidad de opiniones, aunque parece que son más los que estiman que será un día nuboso, aunque no apunta lluvia. Todo se verá.
De momento acabo de librarme de atravesar el estrecho con un temporal de narices, climatológicamente hablando. Todo un alivio para alguien al que no suelen sentar demasiado bien los viajes movidos.
En los pronósticos para el lunes hay diversidad de opiniones, aunque parece que son más los que estiman que será un día nuboso, aunque no apunta lluvia. Todo se verá.
domingo, 12 de noviembre de 2006
Pues parece ser que el próximo miércoles salgo para Marruecos en misión especial.
Asistiré a una serie de reuniones técnicas donde se decidirá el juego de datos, los procedimientos y los formatos de intercambio de información entre dos sistemas informáticos que están siendo desarrollados, uno por parte del cliente al que representaré en las reuniones y otro por parte de las autoridades Marroquíes. Seguro que va a ser divertido: no hablo nada de Francés y supongo que ellos tampoco hablarán castellano, así que tendremos que recurrir a intérpretes (humanos) o, si se dejan, intentaremos comunicarnos en inglés, en c#, java o como sea.
En cuanto al viaje en sí, la verdad es que a priori no es un lugar por el que sienta especial interés. De hecho, ni siquiera aparecería en mi imaginaria lista de sitios a los que querría ir en vacaciones. Esto hace que sienta cierta inquietud ante la excursión, que supongo que estará motivada por mi desconocimiento total sobre la zona. En otras ocasiones en las que, también por trabajo, he salido del país a Portugal, Holanda o el Reino Unido, más o menos sabía a donde me dirigía; en este caso, sin embargo, no tengo ni idea de cómo será aquello.
En fin, vamos a darle una oportunidad al reino vecino. A la vuelta contaré lo que me ha parecido.
Hasta entonces.
Asistiré a una serie de reuniones técnicas donde se decidirá el juego de datos, los procedimientos y los formatos de intercambio de información entre dos sistemas informáticos que están siendo desarrollados, uno por parte del cliente al que representaré en las reuniones y otro por parte de las autoridades Marroquíes. Seguro que va a ser divertido: no hablo nada de Francés y supongo que ellos tampoco hablarán castellano, así que tendremos que recurrir a intérpretes (humanos) o, si se dejan, intentaremos comunicarnos en inglés, en c#, java o como sea.
En cuanto al viaje en sí, la verdad es que a priori no es un lugar por el que sienta especial interés. De hecho, ni siquiera aparecería en mi imaginaria lista de sitios a los que querría ir en vacaciones. Esto hace que sienta cierta inquietud ante la excursión, que supongo que estará motivada por mi desconocimiento total sobre la zona. En otras ocasiones en las que, también por trabajo, he salido del país a Portugal, Holanda o el Reino Unido, más o menos sabía a donde me dirigía; en este caso, sin embargo, no tengo ni idea de cómo será aquello.
En fin, vamos a darle una oportunidad al reino vecino. A la vuelta contaré lo que me ha parecido.
Hasta entonces.
domingo, 5 de noviembre de 2006
En la línea del post anterior, en el que comentaba distintas técnicas que he observado para camuflar ciertas palabras clave y que no fueran fácilmente detectables por procesos que examinan el texto de los mensajes, he encontrado otra, bastante simple también, que se basa en enviar mensajes en formato HTML en los que se sustituyen los caracteres reales de las palabras a ocultar por sus correspondientes entidades de código numérico.
Es decir, la V mayúscula sería sustituída por V, dado que el 86 es el código ASCII de este carácter. Aplicando esta técnica a la palabra VIAGRA, cuya secuencia ASCII equivalente es {82, 73, 65, 71, 82, 65}, obtendríamos en el cuerpo del mensaje:
Es decir, la V mayúscula sería sustituída por V, dado que el 86 es el código ASCII de este carácter. Aplicando esta técnica a la palabra VIAGRA, cuya secuencia ASCII equivalente es {82, 73, 65, 71, 82, 65}, obtendríamos en el cuerpo del mensaje:
VIAGRA
Lo cual es algo más difícil de detectar (aunque no mucho, todo sea dicho de paso) por parte de las herramientas de filtrado.
domingo, 29 de octubre de 2006
Hoy he encontrado otro buscador de esos que parecen ir evolucionando hacia la humanización del servicio, Ms. Dewey.
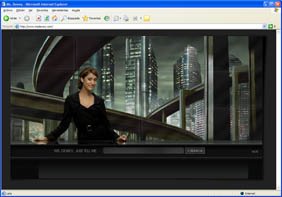 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
 Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.
Este, a diferencia de Chacha, del que ya hablaba en un post anterior, no introduce el factor humano en la 'maquinaria' del proceso de búsqueda, sino en el interfaz, y de forma muy espectacular.Como puede apreciarse en la captura de pantalla, la idea consiste en utilizar a una atractiva señorita como acompañante durante nuestra búsqueda. Pero no, no se trata de una imagen estática: Ms. Dewey se mueve, habla, gasta bromas, se enfada y comenta los resultados de la búsqueda.
Por cierto, algunos truquillos: si se introduce "clone yourself" como criterio de búsqueda, aparecen dos señoritas y charlan un poco. También es curioso ver las cosas que hace y dice cuando esperas un rato sin teclear nada en el buscador. Y está claro que el interfaz se presta bastante a gracias de este tipo (podéis probar a buscar "spam", "video", "soccer"...).
Como curiosidad, aportar que esta muchacha, indio-alemana ella, se llama Janina Gavankar, es actriz, pianista, percusionista y no sé cuántas cosas más.
En fin, la verdad es que como curiosidad no está mal. Demuestra que todavía hay gente por ahí (parece ser que la mismísima Microsoft) intentando aportar algo a este segmento, aparentemente tan trillado, como es el de los buscadores.
martes, 24 de octubre de 2006
Otra técnica ampliamente utilizada es camuflar en el mensaje las palabras susceptibles de ser interceptadas por filtros antispam en cliente o servidor. Esto viene debido a la aparición de software capaz de determinar, en función del contenido del mensaje, cuándo se trataba de spam.
Conceptualmente es bastante simple: si en el cuerpo de un mensaje aparece la palabra "viagra", ya hay bastantes probabilidades de que se trate de un correo basura; si, además, en el cuerpo aparecen otras expresiones ("barato", "compre ahora", etc.), las probabilidades crecen bastante, ¿está claro, no?
Obviamente, los spammers debieron darse cuenta de este detalle, así que rápidamente dieron con una técnica, simple donde las haya, para esquivar este contratiempo: separar las letras que componen las palabras conflictivas con espacios o caracteres invisibles, de forma que los parsers no pudieran encontrar esas cadenas en el cuerpo de los mensajes.
Así, he encontrado distintas variantes de esta técnica; la primera de ellas se utiliza tanto en mensajes HTML como en texto plano, mientras que las dos siguientes son propias de los mensajes enriquecidos:
Conceptualmente es bastante simple: si en el cuerpo de un mensaje aparece la palabra "viagra", ya hay bastantes probabilidades de que se trate de un correo basura; si, además, en el cuerpo aparecen otras expresiones ("barato", "compre ahora", etc.), las probabilidades crecen bastante, ¿está claro, no?
Obviamente, los spammers debieron darse cuenta de este detalle, así que rápidamente dieron con una técnica, simple donde las haya, para esquivar este contratiempo: separar las letras que componen las palabras conflictivas con espacios o caracteres invisibles, de forma que los parsers no pudieran encontrar esas cadenas en el cuerpo de los mensajes.
Así, he encontrado distintas variantes de esta técnica; la primera de ellas se utiliza tanto en mensajes HTML como en texto plano, mientras que las dos siguientes son propias de los mensajes enriquecidos:
- separar con espacios, es decir, utilizar "V I A G R A" en vez de "viagra", por ejemplo.
- separar con entidades, como , que generará en pantalla el mismo efecto que el punto anterior, pero con la diferencia de que no puede ser eliminado realizando trimming a los textos. El ejemplo anterior quedaría codificado como "V I A G R A". Obviamente, es bastante más difícil encontrar así un texto que si está incluido directamente en el contenido. Existen gran cantidad de entidades a utilizar cuya visualización no afecta a la lectura del texto, por lo que las posibilidades son muchas.
- separar con tags, aprovechando que los navegadores o visores de HTML ignorarán las etiquetas desconocidas. Por ejemplo, podríamos usar "V<xx />I<xx />A<xx />G<xx />R<xx />A", lo que complica un poco su detección.
- separar con otros caracteres, que aunque dificultan algo la lectura por parte del cliente potencial, más la complican para los sistemas de búsqueda de cadenas de texto. Supongamos algo así: V-I-A-G-R-A. Seguimos leyendo Viagra, ¿verdad? ¿Y si decimos V_I_A_G_R_A? ¿O V.I.A.G.R.A? ¿A que hay cientos (miles) de combinaciones?
miércoles, 11 de octubre de 2006
Toda técnica utilizada por los spammers viene precedida por alguna innovación en las herramientas antispam que dificulta la recepción del mensaje por parte de la víctima.
Por ello, estamos contemplando una auténtica competición entre ambos bandos, similar a la existente entre los creadores de virus y los fabricantes de antivirus. Si el spammer utiliza una técnica X para colar los mensajes, la técnica Y de los filtradores la contrarresta, lo que hace que los primeros desarrollen el método X+1, que a su vez, será compensado por la tecnología Y+1 de los segundos, y así sucesivamente.
En esta primera entrega veremos la forma más simple de evitar la detección, que, como en la vida misma, es tirar la piedra y esconder la mano.
Desde el principio de los tiempos, el correo basura se envía falseando las direcciones de correo del remitente y la razón es obvia: no descubrir a quien realmente envía los mensajes, acto que, en determinados países, incluso es constitutivo de delito.
¿Y es esto evitable? Difícilmente.
Gracias a la inocencia con que fue diseñado el protocolo SMTP, es perfectamente posible la suplantación del remitente de una forma increíblemente sencilla. Esto es fácilmente comprobable simplemente modificando las propiedades de la cuenta de correo de nuestro cliente favorito (Outlook, Thunderbird...).
Esta característica es aprovechada por los spammers para evitar ser detectados por filtros de tipo 'lista negra', utilizando orígenes de lo más pintorescos: remitentes en blanco, nombres y dominios generados de forma aleatoria, nombres reales pertenecientes a dominios inexistentes, o nombres auténticos dentro de dominios existentes. De esta forma, es absolutamente inviable determinar si un mensaje es spam o no a partir del remitente.
Una variante curiosa es el uso de direcciones pertenecientes al mismo dominio en el que nos encontramos. De hecho, de vez en cuando me llega un email publicitario de uno de mis compañeros de trabajo. En otras palabras, si mi buzón de correo es xxx@yyy.com, puedo recibir spam con un remitente del tipo zzz@yyy.com. Ahora bien, el nombre zzz puede ser real y pertenecer a un usuario que también tienen en sus listas de destinatarios, o bien ser totalmente falso. Hace unos años este pequeño truco hacía que los filtros fueran más compasivos con estos mensajes, sin embargo, hoy en día, que el remitente sea del propio dominio no es tomado como un criterio de veracidad.
Todo eso hace que en los sistemas actuales de filtrado el remitente se tome como un criterio de rechazo, pero nunca de aceptación incondicional de un mensaje.
Por tanto, los métodos actuales de detección de spam están basados, fundamentalmente, en el contenido de los mensajes. El próximo día que postee comentaré unas técnicas básicas para evitar ser detectados.
Por ello, estamos contemplando una auténtica competición entre ambos bandos, similar a la existente entre los creadores de virus y los fabricantes de antivirus. Si el spammer utiliza una técnica X para colar los mensajes, la técnica Y de los filtradores la contrarresta, lo que hace que los primeros desarrollen el método X+1, que a su vez, será compensado por la tecnología Y+1 de los segundos, y así sucesivamente.
En esta primera entrega veremos la forma más simple de evitar la detección, que, como en la vida misma, es tirar la piedra y esconder la mano.
Desde el principio de los tiempos, el correo basura se envía falseando las direcciones de correo del remitente y la razón es obvia: no descubrir a quien realmente envía los mensajes, acto que, en determinados países, incluso es constitutivo de delito.
¿Y es esto evitable? Difícilmente.
Gracias a la inocencia con que fue diseñado el protocolo SMTP, es perfectamente posible la suplantación del remitente de una forma increíblemente sencilla. Esto es fácilmente comprobable simplemente modificando las propiedades de la cuenta de correo de nuestro cliente favorito (Outlook, Thunderbird...).
Esta característica es aprovechada por los spammers para evitar ser detectados por filtros de tipo 'lista negra', utilizando orígenes de lo más pintorescos: remitentes en blanco, nombres y dominios generados de forma aleatoria, nombres reales pertenecientes a dominios inexistentes, o nombres auténticos dentro de dominios existentes. De esta forma, es absolutamente inviable determinar si un mensaje es spam o no a partir del remitente.
Una variante curiosa es el uso de direcciones pertenecientes al mismo dominio en el que nos encontramos. De hecho, de vez en cuando me llega un email publicitario de uno de mis compañeros de trabajo. En otras palabras, si mi buzón de correo es xxx@yyy.com, puedo recibir spam con un remitente del tipo zzz@yyy.com. Ahora bien, el nombre zzz puede ser real y pertenecer a un usuario que también tienen en sus listas de destinatarios, o bien ser totalmente falso. Hace unos años este pequeño truco hacía que los filtros fueran más compasivos con estos mensajes, sin embargo, hoy en día, que el remitente sea del propio dominio no es tomado como un criterio de veracidad.
Todo eso hace que en los sistemas actuales de filtrado el remitente se tome como un criterio de rechazo, pero nunca de aceptación incondicional de un mensaje.
Por tanto, los métodos actuales de detección de spam están basados, fundamentalmente, en el contenido de los mensajes. El próximo día que postee comentaré unas técnicas básicas para evitar ser detectados.





