
Mostrando entradas con la etiqueta programación. Mostrar todas las entradas
Mostrando entradas con la etiqueta programación. Mostrar todas las entradas
domingo, 25 de enero de 2009
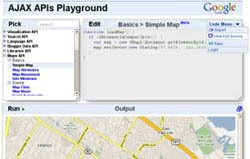 El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.
El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.Se trata de un sitio web interactivo en el que se encuentran un total de 170 ejemplos de uso de las siguientes API de Google:
- API de visualización, que permite a los desarrolladores acceder a datos estructurados y mostrarlos en una gran variedad de formatos, como tablas o gráficos estadísticos.
- API Ajax para búsquedas, que facilita la incorporación de capacidades de búsqueda de cualquier tipo (páginas, direcciones, multimedia, etc.) en sitios web utilizando javascript.
- API Ajax de idioma, que nos permite acceder mediante javascript a las herramientas de detección de idioma, traducción y transliteración de Google.
- API de datos de Blogger, que permite el acceso con Ajax a información sobre blogs, posts y comentarios de esta plataforma de publicación.
- API de bibliotecas Ajax, la red de distribución de librerías estándar como jQuery, jQuery UI, Prototype, script.aculo.us, MooTools o Dojo.
- API de Google Maps, con el que podremos integrar Google Maps en nuestras webs y utilizar los servicios de localización y posicionamiento que nos ofrece.
- API de Google Earth, el cual nos facilita la inclusión del sistema Google Earth en webs, así como la interacción con ellos vía javascript.
- API Ajax para feeds, un conjunto de funciones que nos permiten obtener feeds de otras páginas sin necesidad de crear proxies de servidor.
- API de Google Calendar, el interfaz a través del cual podemos crear aplicaciones totalmente integradas con Google Calendar.
Pero, al menos para mí, lo mejor viene ahora: dispone de un editor de código fuente en el que podemos modificar dichos ejemplos, ejecutarlos sobre la marcha e incluso guardar o exportar los cambios que realicemos, por lo que resulta de lo más didáctico y efectivo para hacernos con el manejo de estas potentes herramientas.
Enlace: Ajax API Playground.
Publicado en: www.variablenotfound.com.
domingo, 11 de enero de 2009

Un detalle que llama la atención al añadir una página maestra a un proyecto ASP.NET desde Visual Studio 2008 es que, por defecto, añade dos secciones de contenido (
ContentPlaceHolder) a la estructura de la página. Una de ellas es la habitual, en el cuerpo de
<form runat="server">, que es donde las páginas basadas en esa MasterPage introducirán sus contenidos y controles. La otra, sin embargo, es una novedad respecto a versiones anteriores del IDE: en la sección <head> del documento:<head runat="server">
<title></title>
<asp:ContentPlaceHolder ID="head" runat="server">
</asp:ContentPlaceHolder>
</head>
<body>
<form id="form1" runat="server">
<div>
<asp:ContentPlaceHolder ID="ContentPlaceHolder1" runat="server">
</asp:ContentPlaceHolder>
</div>
</form>
</body>
</html>
Como habréis deducido, esto nos permite introducir contenidos personalizados en la sección
<head> de una página concreto, como meta tags, o referencias a scripts que deseamos que se carguen con la página, evitando tener que incluirlos mediante programación. Así, si por ejemplo deseamos introducir una referencia a la librería jQuery en una página, la implementación de ésta incluiría los dos placeholders, tal y como sigue:<asp:Content ID="Content1" ContentPlaceHolderID="head" runat="server">
<script type="text/javascript" src="/scripts/jquery.js"></script>
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="ContentPlaceHolder1" runat="server">
<!-- contenidos del webform -->
</asp:Content>La buena noticia para los que todavía trabajamos con Visual Studio 2005 es que podemos aplicar esta misma técnica desde esta versión. Aunque por defecto el IDE no incluye el
ContentPlaceHolder en el encabezado, podemos añadirlo a mano para que quede como en el código mostrado anteriormente, y el efecto será idéntico. Eso sí, a cambio tendremos que aguantar que el entorno nos avise de que la etiqueta no es correcta en ese punto, puesto que sólo VS2008 es capaz de interpretarlo correctamente, pero se trata sólo de un molesto aviso, que no influirá en la compilación o ejecución de las páginas.
Publicado en: www.variablenotfound.com.
domingo, 28 de diciembre de 2008
 Tras algunos días de intenso debate, ayer quedó constituida SVBNet, la plataforma pro-salvación de Visual Basic, como movimiento independiente de la comunidad de desarrolladores de habla hispana aupa.net, cuyo objetivo es apoyar la continuidad del lenguaje y hacer presión para forzar un replanteamiento de su estrategia comercial.
Tras algunos días de intenso debate, ayer quedó constituida SVBNet, la plataforma pro-salvación de Visual Basic, como movimiento independiente de la comunidad de desarrolladores de habla hispana aupa.net, cuyo objetivo es apoyar la continuidad del lenguaje y hacer presión para forzar un replanteamiento de su estrategia comercial. Para el que todavía no esté al tanto de la historia, durante la segunda semana de diciembre ha tenido lugar en Dallas el encuentro de desarrolladores DevConn4, en el que Matt Gretz, destacado miembro del equipo de VB.NET, hacía público el Roadmap que Microsoft tiene previsto para este producto, que no trae buenas noticias para la gran comunidad de desarrolladores en Visual Basic, y que provocó un revuelo impresionante tanto en la sala del evento como en la blogosfera y medios especializados.
Resumidamente, el Roadmap prevé la progresiva desaparición de Visual Basic, mediante un plan de migración que facilitará los desarrolladores pasar a C# en un plazo de tres años. A partir de 2012 no se publicarán nuevas versiones de VB, por lo que, dado que el lenguaje no evolucionará para reflejar los cambios que sean introducidos a nivel de framework, lo llevará irremediablemente a su desaparición en no más de cinco años.
En líneas generales, el contexto actual y el panorama que nos espera, si nadie lo impide, es el siguiente:
- Primero, durante años se han ido introduciendo mejoras en Visual Basic .NET hasta cubrir la mayoría de características del framework e igualarlo en potencia a C#, con objeto de hacer más suave el salto de un lenguaje a otro. Por ejemplo, la inclusión en el actual VB.NET 9 de tal cantidad de novedades y cambios respecto a versiones anteriores, responden claramente a estas necesidades.
Hasta aquí, todo es correcto y aporta exclusivamente ventajas. El problema viene ahora.
- La segunda gran acción podremos verla con el próximo Visual Studio 2010 y .Net 4.0, de los cuales ya es posible descargar previews. Para entonces, Visual Basic aparecerá con el nombre comercial VB# (VB Sharp), dando a entender que se trata de una versión de transición a C#, y en el que podremos encontrar el giro hacia una sintaxis más cercana a este lenguaje, como el uso de llaves en bloques (
if, blucleswhileyfor, etc.), estructuras compactas (como la sintaxis lambda o declaraciones menos verbosas), comentarios tipo C "/*", y otras lindezas que seguro que dejarán nuestro código VB bastante diferente al actual. Eso sí, para facilitarnos la vida, será el propio IDE el que nos ayude a acostumbrarnos a las particularidades sintácticas, sustituyendo sobre la marcha el código VB.NET tradicional por VB#.
En esta fase también encontraremos los cambios que se van a producir en C# para dotarlo de algunas de las ventajas de Visual Basic, como los parámetros opcionales, con objeto de lograr una mayor confluencia y hacer más fácil la adopción del lenguaje por esta comunidad de desarrolladores.
- La última parte del plan se llevará a cabo en 2012 con Visual Studio (codename Moonwalker), que se distribuirá con .NET framework 5.0 (aka Greengarden) y no vendrá acompañado de una nueva versión de Visual Basic, sino de un asistente de migración a C#. Para esas fechas, además, se prevé que la mayoría de desarrolladores de Visual Basic haya adoptado VB#, por lo que el salto será, en palabras de Matt, "no traumático".

Finalmente, comentar que también hemos acordado el emblema de la plataforma pro-salvación de Visual Basic que podemos ir utilizando en nuestras páginas para dar difusión al movimiento hasta que tengamos lista la web oficial, que se prevé finalizada para primeros de año.
 Si eres simpatizante de la causa, programas o has programado en alguna versión de Visual Basic, y tienes blog o una página relacionada con el desarrollo, descárgate esta imagen (¡por favor, no hagas hotlinking!) y colócala en un lugar visible apuntando al futuro sitio web de la plataforma. Si el diseño no encaja en tu web, no te preocupes: en breve tendremos a nuestra disposición nuevos botones en tamaños menores (125 y 250 píxeles de ancho) y con ciertas variaciones estéticas y nuevos colores, e incluso versiones en Flash y Silverlight, según Raúl Mondo, el diseñador que está realizando este excelente trabajo.
Si eres simpatizante de la causa, programas o has programado en alguna versión de Visual Basic, y tienes blog o una página relacionada con el desarrollo, descárgate esta imagen (¡por favor, no hagas hotlinking!) y colócala en un lugar visible apuntando al futuro sitio web de la plataforma. Si el diseño no encaja en tu web, no te preocupes: en breve tendremos a nuestra disposición nuevos botones en tamaños menores (125 y 250 píxeles de ancho) y con ciertas variaciones estéticas y nuevos colores, e incluso versiones en Flash y Silverlight, según Raúl Mondo, el diseñador que está realizando este excelente trabajo.Y no olvides que cuanto más difundamos esta iniciativa, más fuerza tendremos ante la multinacional para hacer que se replantee su estrategia.
¡Larga vida a VB.NET!
[Actualizado 29/12]
Obviamente la noticia no es real, se trata simplemente de una broma del Día de los Inocentes, pero en cualquier caso... ¡Larga vida a VB! :-D
Obviamente la noticia no es real, se trata simplemente de una broma del Día de los Inocentes, pero en cualquier caso... ¡Larga vida a VB! :-D
Publicado en: www.variablenotfound.com.
martes, 2 de diciembre de 2008
 Al escribir el post "Métodos genéricos en C#", estuve pensando en tratar este tema también en VB.NET de forma simultánea, pero al final preferí limitarme a C# para no hacer la entrada más extensa de lo que ya iba a resultar de por sí.
Al escribir el post "Métodos genéricos en C#", estuve pensando en tratar este tema también en VB.NET de forma simultánea, pero al final preferí limitarme a C# para no hacer la entrada más extensa de lo que ya iba a resultar de por sí.Esto, unido a un comentario de Julio sobre el propio post en el que preguntaba si existía algo parecido en Visual Basic .NET, ha hecho que reedite el mismo, pero centrándome esta vez en dicho lenguaje.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores Integer y retorna un valor del mismo tipo: Function Maximo(ByVal uno As Integer, ByVal otro As Integer) _
As Integer
If uno > otro Then Return uno
Return otro
End FunctionHasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
Function Maximo(ByVal uno As Integer, ByVal otro As Integer) _
As Integer
' ...
End Function
Function Maximo(ByVal uno As Long, ByVal otro As Long) _
As Long
' ...
End Function
Function Maximo(ByVal uno As Decimal, ByVal otro As Decimal) _
As Decimal
' ...
End Function
' Y así hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
Object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos Object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: Function Maximo(ByVal uno As IComparable, ByVal otro As Object) As Object
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionPero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
Object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un String y un Integer, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: Function Maximo(Of T As IComparable) _
(ByVal uno As T, ByVal otro As T) As T
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionEn el código anterior, podemos distinguir una porción de código que aparece resaltada justo después del nombre del método, y antes de comenzar a definir sus parámetros. Es la forma de indicar que
Maximo es un método genérico y operará sobre un tipo cualquiera al que llamaremos T, y mediante una restricción estamos indicando que deberá implementar obligatoriamenter el interfaz IComparable (más adelante trataremos esto en profundidad).A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
Integer (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo. Observad que la palabra clave
Of sólo se indica al principio: Function MiMetodo(Of T1, T2, TResult) _
(ByVal par1 As T1, ByVal par2 As T2) As TResult
Y una aclaración antes de continuar: lo de usar la letra
T para identificar el tipo es pura convención, podríamos llamarlo de cualquier forma (por ejemplo Maximo(Of MiTipo)(ByVal uno as MiTipo, ByVal otro as MiTipo) As MiTipo), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genérico: Function Maximo(Of T As IComparable) _
(ByVal uno As T, ByVal otro As T) As T
If uno.CompareTo(otro) > 0 Then Return uno
Return otro
End FunctionAntes había comentado que en este caso estabamos creando un método que podría actuar sobre cualquier tipo, aunque mediante una restricción forzábamos a que éste implementara, obligatoriamente, el interfaz
IComparable, lo que nos permitiría realizar la operación de comparación que necesitamos.Obviamente, las restricciones no son obligatorias; de hecho, sólo debemos utilizarlas cuando necesitemos limitar de alguna forma los tipos permitidos como parámetros genéricos, como en el ejemplo anterior. Está permitida la utilización de las siguientes reglas:
As Structure, indica que el argumento debe ser un tipo valor.As Class, indica que T debe ser un tipo referencia.As New, fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.As nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.As nombredeinterfaz, el argumento deberá implementar el interfaz indicado.As nombredetipogenérico, indica que el argumento al que se aplica debe ser igual o heredar del tipo, también argumento del método, indicado por nombredetipogenérico (observad en el siguiente ejemplo el parámetro T2).
Function MiMetodo(Of T1 As {Class, IEnumerable}, _
T2 As {T1, New}, _
TResult As New) _
(ByVal par1 As T1, ByVal par2 As T2) As TResult
' ... Cuerpo del método
End Function
Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: Dim mazinger As String = Maximo(Of String)("Mazinger", "Afrodita")
Dim i99 As Integer = Maximo(Of Integer)(2, 99)
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
Dim mazinger As String = Maximo("Mazinger", "Afrodita")
Dim i99 As Integer = Maximo(2, 99)
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
String, puede llegar a la conclusión de que el método tiene una signatura que coincide con la definición del genérico, utilizando String como tipo parametrizado.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List(Of T)) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: Function CreaLista(Of T)(ByVal ParamArray pars() As T) As List(Of T)
Dim list As New List(Of T)
For Each elem As T In pars
list.Add(elem)
Next
Return list
End Function
' ...
' Uso:
Dim nums = CreaLista(Of Integer)(1, 2, 3, 4, 5, 6, 7)
Dim noms = CreaLista(Of String)("Pepe", "Juan", "Luis")Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
Dim nums = CreaLista(1, 2, 3, 4, 5, 6, 7)
Dim noms = CreaLista("Pepe", "Juan", "Luis")
' Incluso con tipos anónimos de VB.NET 9
Dim v = CreaLista( _
New With {.X = 1, .Y = 2}, _
New With {.X = 3, .Y = 4} _
)
Console.WriteLine(v(1).Y) ' Muestra "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
martes, 18 de noviembre de 2008
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
lunes, 13 de octubre de 2008
 Me ha parecido muy interesante y divertido el post de Kevin Pang, "Top 10 Things That Annoy Programmers", en el que obtiene los factores más irritantes para los desarrolladores combinando su propia experiencia con los resultados de una pregunta realizada en StackOverflow, la famosa comunidad de desarrolladores promovida por los populares Joel Spolsky y Jeff Atwood.
Me ha parecido muy interesante y divertido el post de Kevin Pang, "Top 10 Things That Annoy Programmers", en el que obtiene los factores más irritantes para los desarrolladores combinando su propia experiencia con los resultados de una pregunta realizada en StackOverflow, la famosa comunidad de desarrolladores promovida por los populares Joel Spolsky y Jeff Atwood.Además de estar casi totalmente de acuerdo con los puntos expuestos en su post, que enumero y comento a continuación, añadiré algunos más de propia cosecha de agentes irritantes.
- 10. Comentarios que explican el "cómo" y no el "qué". Tan importante es incluir comentarios en el código como hacerlo bien. Es terrible encontrar comentarios que son una simple traducción literal al español del código fuente, pues no aportan información extra, en lugar de una explicación de lo que se pretende hacer. Muy bueno el ejemplo de Kevin en el post original... ¿eres capaz de decir qué hace este código, por muy comentado que esté?
r = n / 2; // Set r to n divided by 2
// Loop while r - (n/r) is greater than t
while ( abs( r - (n/r) ) > t ) {
r = 0.5 * ( r + (n/r) ); // Set r to half of r + (n/r)
} - 9. Las interrupciones. Sin duda, el trabajo de desarrollador requiere concentración y continuidad, y las interrupciones son las grandes enemigas de estos dos aspectos. Una jornada de trabajo llena de llamadas, mensajes o consultas de clientes, proveedores, jefes o compañeros puede resultar realmente frustrante, a la vez que la distracción que introduce suele ser una fuente importante de errores en las aplicaciones.
- 8. Ampliación del ámbito. Una auténtica pesadilla, sobre todo cuando se produce durante el desarrollo, consistente en el aumento desproporcionado del alcance de determinadas funcionalidades o características del software a crear. Es especialmente desmotivador si, además, no viene acompañado por el aumento del tiempo o recursos necesarios para su realización.
Kevin incluye en su artículo un ejemplo, algo exagerado pero ilustrativo, de sucesivas ampliaciones de ámbito que convierten un requisito factible en un infierno para el desarrollador; seguro que os recuerda algún caso que habéis sufrido en vuestras propias carnes:- Versión 1: Mostrar un mapa de localización
-- Bah, fácil, sólo tengo que crear una imagen; incluso puedo basarme en algún mapa existente que encuentre por ahí - Versión 2: Mostrar un mapa 3D de localización
-- Uff, esto ya no es lo que hablamos; tendré que currarme bastante más el diseño, y ya no será tan fácil partir de alguno existente... - Versión 3: Mostrar un mapa 3D de localización, por el que el usuario pueda desplazarse volando
-- ¡!
- Versión 1: Mostrar un mapa de localización
- 7. Gestores que no entienden de programación. Otro motivo común de irritación entre los desarrolladores es la incapacidad de gestores para comprender las particularidades de la industria del software en la que trabajan. Este desconocimiento genera problemas de todo tipo en una empresa y suponen un estrés terrible para el desarrollador.
- 6. Documentar nuestras aplicaciones. Lamentablemente, en nuestro trabajo no todo es desarrollar utilizando lenguajes y tecnologías que nos divierten mucho. Una vez terminado un producto es necesario crear guías, manuales y, en general, documentación destinada al usuario final que, admitámoslo, nos fastidia bastante escribir.
- 5. Aplicaciones sin documentación. A pesar de que entendamos y compartamos el punto anterior, también nos fastidia enormemente tener que trabajar con componentes o librerías partiendo de una documentación escasa o nula. Si lo habéis sufrido, entenderéis lo desesperante que resulta ir aprendiendo el significado de las funciones de un API usando el método de prueba y error.
- 4. Hardware. Especialmente los errores de hardware que el usuario percibe como un fallo de la aplicación son normalmente muy difíciles de detectar: fallos de red, discos, problemas en la memoria... por desgracia, hay un amplio abanico de opciones. Y lo peor es que por ser desarrolladores de software se nos presupone el dominio y control absoluto en asuntos hardware, lo que no siempre es así.
- 3. Imprecisiones. Aunque Kevin lo orienta al soporte al usuario, el concepto es igualmente molesto en fases de diseño y desarrollo del software. Las descripciones vagas y confusas son una causa segura de problemas, sea en el momento que sea.
Son irritantes las especificaciones imprecisas, del tipo "esta calculadora permitirá al usuario realizar sumas, restas, multiplicaciones y otras operaciones"... ¿qué operaciones? ¿divisiones? ¿resolver ecuaciones diferenciales?
Tampoco es fácil encajar un mensaje de un usuario tal que "me falla el ERP, arréglalo pronto"... A ver. El ERP tiene cientos de módulos, ¿fallan todos? ¿podríamos ser más concretos? - 2. Otros programadores. Como comenta Kevin, el malestar que provoca a veces la relación entre programadores bien merecería un post independiente, pero ha adelantado aspectos que, en su opinión, hace que a veces el trato con los compañeros sea insoportable:
- Personalidad gruñona, hostilidad
- Problemas para comprender que hay que dejar de debatir la arquitectura del sistema y pasar a realizar las tareas
- Falta de habilidad para mantener una comunicación efectiva
- Falta de empuje
- Apatía hacia el código y el proyecto
- 1. Tu propio código, 6 meses después. Sí, es frustrante estar delante de un código aberrante y darte cuenta de que tú eres el autor de semejante desastre. Y tras ello llega la fase de flagelación: ¿en qué estaba pensando cuando hice esto? ¿cómo fui tan estúpido? uff...
Este hecho, sin embargo, forma parte de la evolución tecnológica, personal y profesional; todos estos factores están en continuo cambio, lo que hace que nuestra forma de atacar los problemas sea distinta casi cada día.
 Y hasta aquí la lista de Kevin en su post, ni que decir tiene que comparto sus reflexiones en la mayoría de los puntos. Por mi parte, añadiría los siguientes agentes irritantes que conozco por experiencia propia o de conocidos:
Y hasta aquí la lista de Kevin en su post, ni que decir tiene que comparto sus reflexiones en la mayoría de los puntos. Por mi parte, añadiría los siguientes agentes irritantes que conozco por experiencia propia o de conocidos:- Extra 1. Requisitos evolutivos, como una ampliación del ámbito del punto 8 ;-), que son aquellos que van cambiando conforme el desarrollo avanza y que obligan a realizar refactorizaciones, descartar código escrito, e introducir peligrosas modificaciones, afectando a veces por debajo de la línea de flotación del software. Más rabia produce, además, cuando se atribuyen una mala interpretación por parte del desarrollador de una especificación imprecisa.
- Extra 2. Problemas en el entorno. Nada más frustrante que cortes en el suministro eléctrico, cuelgues, problemas en el hardware, lentitud en los equipos de trabajo o de acceso a información... a veces parece que tenemos que construir software luchando contra los elementos.
- Extra 3. El "experto" en desarrollo de software. Clientes, gestores y otros individuos que utilizan frecuentemente, y sin conocimiento alguno de causa, expresiones como "Esto es fácil", "Una cosa muy sencilla", "¿Eso vas a tardar en hacer esta tontería?".... A veces no es fácil hacer entender que la percepción externa de la complejidad es absolutamente irreal, y suele ser una causa frecuente de desesperación para los desarrolladores.
- Extra 4. Usuarios corrosivos, que lejos de colaborar durante el desarrollo o la implantación de un sistema, aprovechan la ocasión para arremeter contra la aplicación, organización, jefes, compañeros, el gobierno, o lo que se ponga por delante. Es de justicia decir que muchas veces este comportamiento es debido a una mala gestión interna del proyecto, pero desde el punto de vista del profesional del sofware que sólo quiere realizar lo mejor posible su trabajo son una auténtica pesadilla.
En fin, que ya a estas alturas es fácil ver que hay bastantes cosas que fastidian a los desarrolladores, y seguro que podríamos añadir muchas más; algunas son evitables, otras son inherentes a la profesión y hay que aprender a convivir con ellas, pero en cualquier caso son un interesante motivo de reflexión.
¿Y a tí, qué es lo que más te fastidia?
Enlace: Top 10 Things That Annoy Programmers
Publicado en: www.variablenotfound.com.
martes, 23 de septiembre de 2008
 Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.
Siguiendo con el tema que comenzaba hace ya unos meses, hoy os traigo otra demo de otro motor de física, esta vez para desarrollos realizados en C++, Bullet Physics Library. Se trata de un potente motor de física en tres dimensiones para una gran variedad de plataformas, Win32, Linux, Mac, XBox, Wii, e incluso la PS3.Las demostraciones de este motor son ejecutables, por lo que hay que descargarlas y ejecutarlas en el equipo local. Si utilizáis Windows, os recomiendo echar un vistazo al paquete de demostraciones [~3MB], con el que se puede comprobar la potencia de la librería. No es necesario instalar nada, sólo descomprimir el contenido en una carpeta y ejecutar la demo.
La revisión actual, 2.71 se publicó hace tan sólo unos días. El código fuente del proyecto está alojado en Google Code, y su modelo de licencia (MIT) permite su utilización en proyectos comerciales.
Y por cierto, existe un port para Java, jBullet, cuyas demostraciones pueden descargarse y ejecutarse a través de Java Webstart, por lo que resulta mucho más cómodo. Incluso aunque el rendimiento es muy inferior al real al usar renderizado por software, puede ejecutarse en un applet, que incrusto a continuación.
Debéis elegir una demo en el desplegable (hay cinco disponibles, os recomiendo que comencéis por la primera), en las que podéis usar las teclas "Z" y "X" para acercaros y alejaros de la escena, las flechas de dirección para girar, y con el ratón podéis aplicar impulsos a los cubos (arrastrando con el botón izquierdo) y lanzar cubos (con el bótón derecho).
Como observaréis, dentro del mismo applet aparecen instrucciones de otras teclas, incluso algunas para demos concretas. Especialmente interesante e improductivo es lanzarle piezas al cubo gigante (basic demo), intentar hacer caminar la araña (dynamic control demo), o dedicarse a transportar mesas de un lado a otro con una carretilla (forklift demo).
Que lo disfrutéis.
Publicado en: www.variablenotfound.com.
domingo, 21 de septiembre de 2008
 Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.
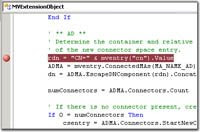
Todos sabemos crear puntos de ruptura (breakpoints) desde Visual Studio, y lo indispensables que resultan para depurar nuestras aplicaciones. Y si la cosa está complicada, los puntos de ruptura condicionales pueden ayudarnos a lanzar el depurador justo cuando se cumpla la expresión que indiquemos.Lo que no conocía era la posibilidad de establecerlos por código desde la propia aplicación que estamos depurando, que puede resultar útil en momentos en que nos sea incómodo crearlos desde el entorno de desarrollo. Es tan sencillo como incluir el siguiente fragmento en el punto donde deseemos que la ejecución de detenga y salte el entorno:
// C#
if (System.Diagnostics.Debugger.IsAttached)
{
System.Diagnostics.Debugger.Break();
}
' VB.NET:
If System.Diagnostics.Debugger.IsAttached Then
System.Diagnostics.Debugger.Break()
End If
Como ya habréis adivinado, el
if lo único que hace es asegurar que la aplicación se esté ejecutando enlazada a un depurador, o lo que es lo mismo, desde dentro del entorno de desarrollo; si se ejecuta fuera del IDE no ocurrirá nada.Si eliminamos esta protección, la llamada a
Debugger.Break() desde fuera del entorno generará un cuadro de diálogo que dará la oportunidad al usuario de abrir el depurador:
De todas formas lo mejor es usarlo con precaución, que eso de dejar el código con residuos de la depuración no parece muy elegante...
Publicado en: www.variablenotfound.com.
lunes, 15 de septiembre de 2008
 Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como "las cinco fases del duelo".
Cuando Elisabeth Kübler-Ross, eminente médica psiquiatra suizo-americana, enunció su famoso modelo Kübler-Ross en 1969, seguro que no andaba pensando en el mundo del desarrollo de software. De hecho, este modelo describe las cinco fases por las que pasa un enfermo terminal, o cualquier persona afectada por una situación de gravedad extrema: negación, ira, negociación, depresión y aceptación, también conocidas como "las cinco fases del duelo".El genial Kevin Pang ha publicado un divertido artículo en Datamation, Debugging and The Five Stages of Grief, utilizándolas para describir los sentimientos del desarrollador ante la aparición de un bug en su aplicación:
- Negación. En esta fase, ante el descubrimiento de un posible fallo, nos ponemos en actitud defensiva e intentamos echarle la culpa a todo menos a nuestros desarrollos. Nosotros no fallamos nunca... ¿o tal vez sí?
- Ira. Acto seguido, una vez demostrado que existe un problema, comienzan los bufidos, resoplidos y voces airadas del tipo ¿cómo no se ha detectado esto antes?, ¡vaya mierda de aplicación!, o ¡¡joder, justo ahora, con lo ocupado que estoy!!
- Negociación. Vale, asumimos que hay un error y ya hemos despotricado durante un rato. El siguiente paso es negociar (habitualmente con nosotros mismos) sobre el tipo de solución a dar: ¿apuntalamos lo suficiente como para que siga funcionando, u optamos por solucionar de forma definitiva el problema? Difícil decisión a veces.
- Depresión. Ahora lo que toca es la depresiva tarea de la depuración. A nadie le gusta escudriñar en el código en busca de un error, ¡hemos nacido para crear software espectacular, no para corregirlo! Es un buen momento para compadecernos de nosotros mismos.
- Aceptación. Hemos asimilado la realidad de que nuestro código falla, hemos maldecido la situación, decidido que vamos a corregirlo como auténticos profesionales, e incluso hemos llorado un rato sobre nuestra mala suerte. Sin embargo, esto es así y hay que aceptarlo, forma parte de la pesada mochila que los desarrolladores llevamos a las espaldas. Eso sí, sólo otro desarrollador puede entenderlo, no intentes explicárselo a tu esposa, madre, jefe, o vecino.
Si tienes un rato, no te pierdas el artículo original.
Publicado en: www.variablenotfound.com.
domingo, 14 de septiembre de 2008
Hace unos días, el nueve de septiembre, se cumplían 61 años desde la primera aparición "documentada" de un bug informático. Y como en todos los cumpleaños, ahí va la foto del protagonista, literalmente:

Se trata de la polilla que provocó problemas de funcionamento en el primitivo ordenador Mark II el martes 9 de septiembre de 1947, al colarse y quedarse atrapada en el relé número 70 del Panel F (que debe venir a ser algo así como la línea X del archivo Y del código fuente de los de ahora). La incidencia fue reflejada en el cuaderno de bitácora (log) del sistema, al que pertenece la fotografía superior, adjuntando el insecto como prueba del delito.
El término "bug" ya se utilizaba entonces como sinónimo de error en otros ámbitos, como en telegrafía, telefonía o sistemas eléctricos, de ahí la frase que registró el operador debajo del animalito, haciendo referencia a que era la primera vez que se encontraba un auténtico bug (=bicho):
Fuente: The first computer bug
Publicado en: www.variablenotfound.com.

Se trata de la polilla que provocó problemas de funcionamento en el primitivo ordenador Mark II el martes 9 de septiembre de 1947, al colarse y quedarse atrapada en el relé número 70 del Panel F (que debe venir a ser algo así como la línea X del archivo Y del código fuente de los de ahora). La incidencia fue reflejada en el cuaderno de bitácora (log) del sistema, al que pertenece la fotografía superior, adjuntando el insecto como prueba del delito.
El término "bug" ya se utilizaba entonces como sinónimo de error en otros ámbitos, como en telegrafía, telefonía o sistemas eléctricos, de ahí la frase que registró el operador debajo del animalito, haciendo referencia a que era la primera vez que se encontraba un auténtico bug (=bicho):
"First actual case of bug being found"
Fuente: The first computer bug
Publicado en: www.variablenotfound.com.
miércoles, 11 de junio de 2008
 Aunque es lo que más mola, los desarrolladores no siempre podemos trabajar con los últimos lenguajes y tecnologías. De hecho, solemos pasar gran parte de nuestro tiempo manteniendo y mejorando sistemas basados en plataformas que consideramos obsoletas o de menor potencia que las habituales, lo que nos lleva a tener que dar respuesta "artesana" a problemas que usando tecnologías más apropiadas estarían solucionados.
Aunque es lo que más mola, los desarrolladores no siempre podemos trabajar con los últimos lenguajes y tecnologías. De hecho, solemos pasar gran parte de nuestro tiempo manteniendo y mejorando sistemas basados en plataformas que consideramos obsoletas o de menor potencia que las habituales, lo que nos lleva a tener que dar respuesta "artesana" a problemas que usando tecnologías más apropiadas estarían solucionados.Hoy por ejemplo, desarrollando con VbScript en un entorno propietario embebido en un sistema de gestión empresarial hemos necesitado crear GUIDs y hemos visto que el lenguaje no dispone de esta capacidad, a diferencia de .Net o Java, que proporcionan vías para conseguirlo de forma muy sencilla.
Preguntándole a Google, que todo lo sabe, he encontrado varias soluciones aplicables de forma directa.
La primera, es usar funciones propias del motor de base de datos. En nuestro caso concreto, la solución está conectada a un SQL Server, que afortunadamente dispone desde la versión 2000 de una función integrada de generación de GUIDs. Así pues, podríamos utilizar un código como el siguiente:
' Obtiene un nuevo GUID
' Parámetro: una conexión abierta
function ObtenerGUID(conn)
dim rs
set rs = conn.Execute("Select NEWID()")
if (not rs.eof) then
ObtenerGUID = rs(0)
end if
end functionPero, ¿y si no usas SQL Server? No pasa nada, prácticamente todos los motores de bases de datos incorporan algún mecanismo equivalente, como MySQL ("
UUID()") y Oracle ("SYS_GUID()").En este momento podríamos decir que tenemos una buena solución... siempre que tengamos a mano una conexión a una base de datos capaz de generar un GUID. ¿Y si no fuera este el caso? Aquí va otro código que utilizando un objeto
Scriptlet.TypeLib, utilizado por Windows como soporte a los lenguajes de scripting:' Obtiene un nuevo GUID
Function ObtenerGUID()
dim typeLib, guid
set typeLib = CreateObject("Scriptlet.TypeLib")
guid = typeLib.Guid
ObtenerGUID= left(guid, len(guid)-2)
set typeLib = Nothing
End FunctionTambién hay quien utiliza llamadas a UUIDGEN.EXE, una utilidad proporcionada normalmente con kits de desarrollo de .NET y los entornos Visual Studio, generando el GUID sobre un archivo de texto para más tarde leerlo desde el script, pero me ha parecido una solución demasiado compleja para el problema.
Por último he encontrado unos ejemplos de código en el centro de soporte de Microsoft que muestran varias maneras de crear identificadores únicos, aunque me quedo con la más completa, consistente en generar la secuencia de caracteres aleatorios:
' Obtiene un GUID tipo Windows
' 8+4+4+4+12 caracteres A-Z y 0-9
Function CreateWindowsGUID()
CreateWindowsGUID = CreateGUID(8) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(4) & "-" & _
CreateGUID(12)
End Function
' Obtiene un GUID del tamaño indicado
' Parámetro: longitud del GUID
Function CreateGUID(tmpLength)
Randomize Timer
Dim tmpCounter,tmpGUID
Const strValid = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"
For tmpCounter = 1 To tmpLength
tmpGUID = tmpGUID & Mid(strValid, Int(Rnd(1) * Len(strValid)) + 1, 1)
Next
CreateGUID = tmpGUID
End FunctionPublicado en: www.variablenotfound.com.
domingo, 25 de mayo de 2008
 Algunos dirán que a nada, como las nubes ;-) Sin embargo, el olor que desprende tu código, el llamado "code smell", término acuñado por Kent Beck (uno de los padres del Extreme Programming), puede darte pistas sobre problemas existentes en el mismo y alertarte ante situaciones no deseadas.
Algunos dirán que a nada, como las nubes ;-) Sin embargo, el olor que desprende tu código, el llamado "code smell", término acuñado por Kent Beck (uno de los padres del Extreme Programming), puede darte pistas sobre problemas existentes en el mismo y alertarte ante situaciones no deseadas.El concepto es parecido a los antipatrones de programación, aunque funcionan a un nivel todavía más sutil, pues no describe situaciones completas sino indicios. De hecho, el uso de esta metáfora sensorial respecto a un código, es decir, que éste desprenda cierto tufillo, indica que sería conveniente realizar una revisión en profundidad para ver si hay que refactorizar, pero no implica que necesariamente haya algo incorrecto. Además, dado que trata de algo tan personal y específico como el código fuente, a veces las señales son bastante subjetivas y dependientes de lenguajes y tecnologías concretas.
Existen multitud de listas y clasificaciones, aunque es muy interesante la realizada por Mika Mäntylä, investigador de la universidad de Helsinki, ha creado una taxonomía que agrupa code smells relacionados en cinco categorías en función del efecto que pueden provocar:
- The bloaters (los infladores), que agrupa 'aromas' que indican el crecimiento excesivo de algún aspecto que hacen incontrolable el código.
- Long method (método extenso) que precisa de su reducción para ser más legible y mantenible.
- Large class (clase larga), con síntomas y consecuencias muy similares al caso anterior.
- Primitive obsession (obsesión por tipos primitivos), cuyo síntoma es la utilización de tipos primitivos para almacenar datos de entidades pequeñas (por ejemplo, usar un long para guardar un número de teléfono).
- Long parameter list (lista de parámetros larga), que incrementan la complejidad de un método de forma considerable.
- Dataclumps (grupos de datos), o uso de un cunjunto de variables o propiedades de tipos primitivos en lugar de crear una clase apropiada para almacenar los datos, lo que a su vez provoca el incremento de parámetros en métodos y clases.
- The Object-Orientation Abusers (los maltratadores de la orientación a objetos), que aglutina code smells que indican que no se está aprovechando la potencia de este paradigma:
- Switch statements (sentencias Switch), que podrían indicar una falta de utilización de mecanismos de herencia.
- Temporary field (campo temporal), que se salta el principio de encapsulamiento y ocultación de variables haciendo que éstas pertenezcan a la clase cuando su ámbito debería ser exclusivamente el método que las usa.
- Refused bequest (rechazo del legado), cuando una subclase 'rechaza' métodos o propiedades heredadas, atentando directamente contra uno de los principales pilares de la OOP.
- Alternative Classes with Different Interfaces (clases alternativas con distintos interfaces) indica la ausencia de interfaces comunes entre clases similares.
- The change preventers (los impedidores de cambios)
- Divergent Change (cambio divergente), que hace que sean implementadas dentro de la misma clase funcionalidades sin ninguna relación entre ellas, lo que sugiere extraerlas a una nueva clase.
- Shotgun surgery (cirujía de escopeta), ocurre cuando un cambio en una clase implica modificar varias clases relacionadas.
- Parallel Inheritance Hierarchies (jerarquías de herencia paralelas), paralelismo que aparece cuando cada vez que se crea una instancia de una clase es necesario crear una instancia de otra clase, evitable uniendo ambas en una úncia clase final.
- The Dispensables (los prescindibles), pistas aportadas por porciones de código innecesarias que podrían y deberían ser eliminadas:
- Lazy class (clase holgazana), una clase sin apenas responsabilidades que hay que dotar de sentido, o bien eliminar.
- Data class (clase de datos), cuando una clase sólo se utiliza para almacenar datos, pero no dispone de métodos asociados a éstos.
- Duplicate code (código duplicado), presencia de código duplicado que dificulta enormemente el mantenimiento.
- Dead code (código muerto), aparición de código que no se utiliza, probablemente procedente de versiones anteriores, prototipos o pruebas.
- Speculative generality (generalización especulativa), ocurre cuando un código intenta solucionar problemas más allá de sus necesidades actuales.
- The couplers (Los emparejadores), son code smells que alertan sobre problemas de acoplamiento componentes, a veces excesivo y otras demasiado escaso.
- Features envy (envidia de características), que aparece cuando existe un método de una clase que utiliza extensivamente métodos de otra clase y podría sugerir la necesidad de moverlo a ésta.
- Inappropriate intimacy (intimidad inapropiada), ocurre cuando dos clases de conocen demasiado y usan con demasiada confianza, y a veces de forma inapropiada, sus miembros (en la acepción POO del término ;-))
- Message Chains (cadenas de mensajes), aroma desprendido por código que realiza una cadena de llamadas a métodos de clases distintas utilizando como parámetros el retorno de las llamadas anteriores, como
A.getB().getC().getD().getTheNeededData(), que dejan entrever un acoplamiento excesivo de la primera clase con la última. - Middle man (intermediario), que cuestiona la necesidad de tener clases cuyo único objetivo es actuar de intermediaria entre otras dos clases.
Aunque agrupadas bajo otros criterios, existe una interesante relación de code smells y la refactorización a aplicar en cada caso, que ayuda a determinar las acciones correctivas oportunas una vez se haya comprobado que hay algo que no va bien.
Y ahora, ¿piensas que tu código no huele a nada? ;-P
Publicado en: http://www.variablenotfound.com/.
domingo, 11 de mayo de 2008
 Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.
Scott Guthrie, en el anuncio de la publicación en Codeplex de la actualización del código del framework MVC del pasado mes de abril, comentó que uno de los cambios en los que estaban trabajando era en la modificación de las acciones de un controlador, haciendo que éstas pasaran a retornar un objeto del tipo ActionResult.Como recordaréis, hasta ese momento las acciones no tenían tipo de retorno, pero han replanteado el diseño para hacerlo más flexible, testable y potente. Así, pasamos de definir las acciones de esta forma:
public void Index()
{
RenderView("Index");
}a esta otra:
public ActionResult Index()
{
return RenderView();
}En el código anterior destacan dos aspectos. En primer lugar que la llamada a
RenderView() no tiene parámetros; el sistema mostrará la vista cuyo nombre coincida con el de la acción que se está ejecutando (Index, en este caso). En segundo lugar, que la llamada a RenderView() retorna un objeto ActionResult (o más concretamente un descendiente, RenderViewResult), que será el devuelto por la acción.De la misma forma, existen tipos de ActionResult concretos para retornar el resultado de las acciones más habituales:
RenderViewResult, retornado cuando se llama desde el controlador aRenderView().ActionRedirectResult, retornado al llamar aRedirectToAction()HttpRedirectResult, que será la respuesta a unRedirect()EmptyResult, que intuyo que será para casos en los que no hay que hacer nada (!), aunque todavía no le he visto mucho el sentido...
Además de las citadas anteriormente, una de las ventajas de retornar estos objetos desde los controladores es que podemos crear nuestra clase, siempre heredando de
ActionResult, e implementar comportamientos personalizados.Esto es lo que ha hecho el genial Phil Haack en dos ejemplos recientemente publicados en su blog.
El primero de ellos, publicado en el post "Writing A Custom File Download Action Result For ASP.NET MVC" muestra una implementación de una acción cuya invocación hace que el cliente descargue, mediante un download, el archivo indicado, en su ejemplo, el archivo CSS de su sitio web:
public ActionResult Download()
{
return new DownloadResult
{ VirtualPath="~/content/site.css",
FileDownloadName = "TheSiteCss.css"
};
}
La clase
DownloadResult una descendiente de ActionResult, en cuya implementación encontraremos, además de la definición de las propiedades VirtualPath y FileDownloadName, la implementación del método ExecuteResult, que será invocado por el framework al finalizar la ejecución de la acción, y donde realmente se realiza el envío al cliente del archivo, con parámetro content-disposition convenientemente establecido:public class DownloadResult : ActionResult
{
public DownloadResult()
{
}
public DownloadResult(string virtualPath)
{
this.VirtualPath = virtualPath;
}
public string VirtualPath { get; set; }
public string FileDownloadName { get; set; }
public override void ExecuteResult(ControllerContext context)
{
if (!String.IsNullOrEmpty(FileDownloadName)) {
context.HttpContext.Response.AddHeader("content-disposition",
"attachment; filename=" + this.FileDownloadName)
}
string filePath = context.HttpContext.Server.MapPath(this.VirtualPath);
context.HttpContext.Response.TransmitFile(filePath);
}
}
El segundo ejemplo, publicado en el post "Delegating Action Result", vuelve a demostrar otro posible uso de los ActionResults creando un nuevo descendiente,
DelegatingResult, que puede ser retornado desde las acciones para indicar qué operaciones deben llevarse a cabo por el framework.El siguiente código muestra cómo retornamos un objeto de este tipo, inicializado con una lambda:
public ActionResult Hello()
{
return new DelegatingResult(context =>
{
context.HttpContext.Response.AddHeader("something", "something");
context.HttpContext.Response.Write("Hello World!");
});
}Como veremos a continuación, el constructor de este nuevo tipo recibe un parámetro de tipo
Action<ControllerContext> y lo almacenará de forma local en la propiedad Command, postergando su ejecución hasta más adelante; será la sobreescritura del método ExecuteResult la que ejecutará el comando:public class DelegatingResult : ActionResult
{
public Action<ControllerContext> Command { get; private set; }
public DelegatingResult(Action<ControllerContext> command)
{
this.Command = command;
}
public override void ExecuteResult(ControllerContext context)
{
if (context == null)
throw new ArgumentNullException("context");
Command(context);
}
}
Puedes ver el código completo de ambos ejemplos, así como descargar proyectos de prueba en los artículos originales de Phil Haack:
Por último, recordar que todos estos detalles son relativos a la última actualización de la preview de esta tecnología y podrían variar en futuras revisiones.
Publicado en: www.variablenotfound.com.
domingo, 4 de mayo de 2008
 Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.
Me he encontrado en el blog de Fresh Logic Studios con un post donde describen una técnica interesante para obtener descripciones textuales de los elementos de una enumeración. De hecho, ya la había visto hace tiempo en I know the answer como una aplicación de los métodos de extensión para mejorar una solución que aportaba en un post anterior.Como sabemos, si desde una aplicación queremos obtener una descripción comprensible de un elemento de una enumeración, normalmente no podemos realizar una conversión directa (
elemento.ToString()) del mismo, pues obtenemos los nombres de los identificadores usados a nivel de código. La solución habitual, hasta la llegada de C# 3.0 consistía en incluir dentro de alguna clase de utilidad un conversor estático que recibiera como parámetro en elemento de la enumeración y retornara un string, algo así como:
public static string EstadoProyecto2String(EstadoProyecto e)
{
switch (e)
{
case EstadoProyecto.PendienteDeAceptacion:
return "Pendiente de aceptación";
case EstadoProyecto.EnRealizacion:
return "En realización";
case EstadoProyecto.Finalizado:
return "Finalizado";
default:
throw
new ArgumentOutOfRangeException("Error: " + e);
}
}
Este método, sin embargo, presenta algunos inconvenientes. En primer lugar, dado el tipado fuerte del parámetro de entrada del método, es necesario crear una función similar para cada enumeración sobre la que queramos realizar la operación.
También puede resultar peligroso separar la definición de la enumeración del método que transforma sus elementos a cadena de caracteres, puesto que puede perderse la sincronización entre ambos cuando, por ejemplo, se introduzca un nuevo elemento en ella y no se actualice el método con la descripción asociada.
La solución, que como he comentado me pareció muy interesante, consiste en decorar cada elemento de la enumeración con un atributo que describa al mismo, e implementar un método de extensión sobre la clase base
System.Enum para obtener estos valores. Veamos cómo.Ah, una cosa más. Aunque los ejemplos están escritos en C#, se puede conseguir exactamente el mismo resultado en VB.NET simplemente realizando las correspondientes adaptaciones sintácticas. Podrás encontrarlo al final del post.
1. Declaración de la enumeración
Vamos a usar el atributoSystem.ComponentModel.DescriptionAttribute, aunque podríamos usar cualquier otro que nos interese, o incluso crear nuestro propio atributo personalizado. El código de definición de la enumeración sería así:
using System.ComponentModel;
public enum EstadoProyecto
{
[Description("Pendiente de aceptación")] PendienteDeAceptacion,
[Description("En realización")] EnRealizacion,
[Description("Finalizado")] Finalizado,
[Description("Facturado y cerrado")] FacturadoYCerrado
}
2. Implementación del método de extensión
Ahora vamos a crear el método de extensión (¿qué son los métodos de extensión?) que se aplicará a todas las enumeraciones.Fijaos que el parámetro de entrada del método está precedido por la palabra reservada
this y el tipo es System.Enum, por lo que será aplicable a cualquier enumeración.
using System;
using System.ComponentModel;
using System.Reflection;
public static class Utils
{
public static string GetDescription(this Enum e)
{
FieldInfo field = e.GetType().GetField(e.ToString());
if (field != null)
{
object[] attribs =
field.GetCustomAttributes(typeof(DescriptionAttribute), false);
if (attribs.Length > 0)
return (attribs[0] as DescriptionAttribute).Description;
}
return e.ToString();
}
}
 Y voila! A partir de este momento tendremos a nuestra disposición el método
Y voila! A partir de este momento tendremos a nuestra disposición el método GetDescription(), que nos devolverá el texto asociado al elemento de la enumeración; si éste no existe, es decir, si no se ha decorado el elemento con el atributo apropiado, nos devolverá el identificador utilizado.De esta forma eliminamos de un plumazo los dos inconvenientes citados anteriormente: la separación entre la definición de la enumeración y los textos descriptivos, y la necesidad de crear un conversor a texto por cada enumeración que usemos en nuestra aplicación.
Y por cierto, el equivalente en VB.NET completo sería:
Imports System.ComponentModel
Imports System.Reflection
Imports System.Runtime.CompilerServices
Module Module1
Public Enum EstadoProyecto
<Description("Pendiente de aceptación")> PendienteDeAceptacion
<Description("En realización")> EnRealizacion
<Description("Finalizado")> Finalizado
<Description("Facturado y cerrado")> FacturadoYCerrado
End Enum
<Extension()> _
Public Function GetDescription(ByVal e As System.Enum) As String
Dim field As FieldInfo = e.GetType().GetField(e.ToString())
If Not (field Is Nothing) Then
Dim attribs() As Object = _
field.GetCustomAttributes(GetType(DescriptionAttribute), False)
If attribs.Length > 0 Then
Return CType(attribs(0), DescriptionAttribute).Description
End If
End If
Return e.ToString()
End Function
End Module
Publicado en: www.variablenotfound.com.
martes, 29 de abril de 2008
De nuevo en ASP.NET Resources encuentro una magnífica recopilación, en forma de chuletas de consulta rápida, de las librerías javascript disponibles en cliente usando ASP.NET Ajax. Puedes descargar el archivo pulsando sobre la imagen:

El archivo distribuido, un zip, contiene siete chuletas en formato PDF:
Publicado en: www.variablenotfound.com.
El archivo distribuido, un zip, contiene siete chuletas en formato PDF:
- Extensiones a los tipos
StringyObject - Extensiones a los tipos
NumberyError - Referencia del tipo
DomEvent - Extensiones al tipo
DomElement - Extensiones a los tipos
DateyBoolean - Eventos del ciclo de vida en cliente
- Extensiones al tipo
Array
Publicado en: www.variablenotfound.com.
domingo, 27 de abril de 2008
 Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.
Días atrás hablaba de las formas de inicialización de objetos que nos proporcionaban las últimas versiones de C# y VB.Net, que permitían asignar valores a miembros de instancia de forma muy compacta, legible y cómoda.C# 3.0 nos trae otra sorpresa, también relacionada con el establecimiento de valores iniciales de elementos: los inicializadores de colecciones. Aunque esta característica también estaba prevista para VB.Net 9.0, al final fue desplazada a futuras versiones por problemas de tiempo.
Para inicializar una colección, hasta ahora era necesario en primer lugar crear la clase correspondiente para, a continuación, realizar sucesivas invocaciones al método
Add() con cada uno de los elementos a añadir: List<string> ls = new List<string>();
ls.Add("Uno");
ls.Add("Dos");
ls.Add("Tres");
C# 3.0 permite una alternativa mucho más elegante y rápida de codificar, simplemente se introducen los elementos a añadir a la colección entre llaves (como se hacía con los inicializadores de arrays o los nuevos inicializadores de objetos), separados por comas, como en el siguiente ejemplo:
List<string> ls =
new List<string>() { "Uno", "Dos", "Tres" };
Si desensamblamos el ejecutable resultante, podremos ver que es el compilador el que ha añadido por nosotros los
Add() de cada uno de los elementos después de instanciar la colección:
newobj instance void class
[mscorlib]System.Collections.Generic.List`1<string>::.ctor()
stloc.s '<>g__initLocal0'
ldloc.s '<>g__initLocal0'
ldstr "Uno"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
ldloc.s '<>g__initLocal0'
ldstr "Dos"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
ldloc.s '<>g__initLocal0'
ldstr "Tres"
callvirt instance void class
[mscorlib]System.Collections.Generic.List`1<string>::Add(!0)
nop
Uniendo esto ahora con los inicializadores de objetos que ya tratamos un post anterior, fijaos en la potencia del resultado:
List<Persona> lp = new List<Persona>
{
new Persona { Nombre="Juan", Edad=34 },
new Persona { Nombre="Luis", Edad=53 },
new Persona { Nombre="José", Edad=23 }
};
Efectivamente, cada elemento es una nueva instancia de la clase Persona, con las propiedades que nos interesan inicializadas de forma directa. De hacerlo con los métodos tradicionales, para conseguir el mismo resultado deberíamos utilizar muuuchas más líneas de código.
Otro ejemplo que demuestra aún más la potencia de esta característica:
var nums = new SortedList
{
{ 34, "Treinta y cuatro" },
{ 12, "Doce" },
{ 3, "Tres" }
};
foreach (var e in nums)
Console.WriteLine(e.Key + " " + e.Value);
En el código anterior podemos ver, primero, el uso de variables locales de tipo implícito, para ahorrarnos tener que escribir más de la cuenta. En segundo lugar, se muestra cómo se inicializa una colección cuyo método
Add() requiere dos parámetros. En el caso de un SortedList<TKey, TValue>, su método Add() requiere la clave de ordenación y el valor del elemento.(Obviamente, el resultado de la ejecución del código anterior será la lista ordenada por su valor numérico (Key))
En conclusión, se trata de otra de las innumerables ventajas que nos ofrece la nueva versión de C# destinadas a evitarnos pulsaciones innecesarias, y a la que seguro le daremos uso.
Publicado en: www.variablenotfound.com.





