
 El gran K. Scott Allen comentaba hace unas semanas en OdeToCode un pequeño truco que puede resultar de utilidad cuando tengamos un código jQuery que no funcione correctamente.
El gran K. Scott Allen comentaba hace unas semanas en OdeToCode un pequeño truco que puede resultar de utilidad cuando tengamos un código jQuery que no funcione correctamente.
Como comenta el autor, la mayoría de los problemas con jQuery se deben a un uso incorrecto de los potentes selectores, así que lo que propone es el uso de la consola javascript incluida en algunas herramientas como Firebug (para Firefox) o las propias herramientas de desarrollo incluidas en Internet Explorer 8 (geniales, por cierto).
 Esta consola permite en ambos casos introducir instrucciones javascript de forma directa, que serán ejecutadas en el contexto de la página actual como si formaran parte del código de las mismas. Por tanto, en aquellas páginas en las que se incluido jQuery, será posible ejecutar llamadas y selecciones a lo largo del DOM y observar el resultado de forma interactiva.
Esta consola permite en ambos casos introducir instrucciones javascript de forma directa, que serán ejecutadas en el contexto de la página actual como si formaran parte del código de las mismas. Por tanto, en aquellas páginas en las que se incluido jQuery, será posible ejecutar llamadas y selecciones a lo largo del DOM y observar el resultado de forma interactiva.
En la imagen adjunta se ve cómo podemos ir realizando consultas con selectores e ir observando sus resultados con Firebug. Hay que tener en cuenta que la mayoría de operaciones de selección con jQuery retornan una colección con los elementos encontrados, por eso podemos utilizar length para obtener el número de coincidencias. Pero no sólo eso, podríamos utilizar expresiones como la siguiente para mostrar por consola el texto contenido en las etiquetas que cumplan el criterio:
$("div > a").each(function() { console.log($(this).text()) })Y más aún, si lo que queremos es obtener una representación visual sobre la propia página, podemos alterar los elementos o destacarlos con cualquiera de los métodos de manipulación disponibles en jQuery, por ejemplo:
$("a:contains['sex']").css("background-color", "yellow")
La siguiente captura muestra el resultado de una consulta realizada con las herramientas de desarrollo incluidas en Internet Explorer 8: 
En fin, un pequeño truco para facilitarnos un poco la vida.
 Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.
Una posibilidad interesante que ofrece Google a los desarrolladores es utilizarlo como CDN (red de difusión de contenidos) para las librerías javascript open source más populares. En la práctica, esto quiere decir es que en tus desarrollos web, en lugar de subir a tu servidor las librerías que utilices para scripting, puedes referenciar y usar directamente las que te ofrece esta compañía en sus servidores.Esto aporta varias ventajas nada despreciables:
- primero, la descarga de estas librerías será, para el cliente, probablemente más rápida que si las tiene que obtener desde tu servidor a través de internet. Se trata de infraestructura de red de Google, y eso implica unas garantías.
- segundo, y relacionada con la anterior, si se trata de un sitio web de alto tráfico, la concurrencia permitida seguramente será infinitamente mayor que la que puedas ofrecer en otro servidor.
- tercero, si el usuario ha visitado previamente otro sitio web que use también la misma librería, se beneficiará del cacheado local de la misma, puesto que su navegador no la descargaría de nuevo. Y en cualquier caso, se estarían aprovechando las optimizaciones de caché de Google.
- cuarto, no consumes ancho de banda de tu proveedor, aunque éste sea despreciable. Y con despreciable me refiero al ancho de banda, no al proveedor ;-)
- quinto, puedes utilizar las librerías desde webs alojadas en algún sitio donde no se pueda, o no sea sencillo, subir archivos de scripts, como la plataforma Blogger desde la que escribo.
En este momento se contemplan los siguientes frameworks, en todas las versiones disponibles:
- jQuery
- jQuery UI
- Prototype
- script_aculo_us
- MooTools
- Dojo
- SWFObject
- Yahoo! User Interface Library (YUI)
Si ya estás utilizando librerías Ajax de Google (como el API de visualización, o el de Google Maps), y las obtienes mediante el cargador google.load(), también puedes utilizarlo para descargar estos frameworks. Asimismo, puedes hacerlo mediante una referencia directa, del tipo:
<script
src="http://ajax.googleapis.com/ajax/libs/prototype/1.6.0.2/prototype.js">
</script>
Ah, y no hay que preocuparse por los cambios de versiones, ni nada parecido. Google se compromete a alojar indefinidamente todas las distribuciones que vayan publicando, así como de incluir actualizaciones conforme aparezcan.
Por último, y para aportar una visión negativa, hay quien opina que se trata de una estrategia más de Google para obtener información sobre la navegación de los usuarios; la ejecución de código procedente de sus servidores posibilitaría la lectura de cookies y datos que podrían ser utilizados para fines distintos de los previstos en tu web. También hay quienes piensan que podría ser una fuente de difusión de código malicioso si alguien consiguiera hackear estos repositorios. Obviamente, tampoco es buena idea utilizar esta opción si vas a trabajar en modo local, sin conexión.
Para más información sobre las formas de descarga y las librerías disponibles, puedes visitar la guía del desarrollador de las Ajax libraries API.
Publicado en: www.variablenotfound.com.
 El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.
El pasado miércoles, Ben Lisbakken descubría en el Blog de Google Code el proyecto al que había dedicado el famoso (¿y difunto?) 20% de la jornada laboral en esta compañía: AJAX APIs Playground.Se trata de un sitio web interactivo en el que se encuentran un total de 170 ejemplos de uso de las siguientes API de Google:
- API de visualización, que permite a los desarrolladores acceder a datos estructurados y mostrarlos en una gran variedad de formatos, como tablas o gráficos estadísticos.
- API Ajax para búsquedas, que facilita la incorporación de capacidades de búsqueda de cualquier tipo (páginas, direcciones, multimedia, etc.) en sitios web utilizando javascript.
- API Ajax de idioma, que nos permite acceder mediante javascript a las herramientas de detección de idioma, traducción y transliteración de Google.
- API de datos de Blogger, que permite el acceso con Ajax a información sobre blogs, posts y comentarios de esta plataforma de publicación.
- API de bibliotecas Ajax, la red de distribución de librerías estándar como jQuery, jQuery UI, Prototype, script.aculo.us, MooTools o Dojo.
- API de Google Maps, con el que podremos integrar Google Maps en nuestras webs y utilizar los servicios de localización y posicionamiento que nos ofrece.
- API de Google Earth, el cual nos facilita la inclusión del sistema Google Earth en webs, así como la interacción con ellos vía javascript.
- API Ajax para feeds, un conjunto de funciones que nos permiten obtener feeds de otras páginas sin necesidad de crear proxies de servidor.
- API de Google Calendar, el interfaz a través del cual podemos crear aplicaciones totalmente integradas con Google Calendar.
Pero, al menos para mí, lo mejor viene ahora: dispone de un editor de código fuente en el que podemos modificar dichos ejemplos, ejecutarlos sobre la marcha e incluso guardar o exportar los cambios que realicemos, por lo que resulta de lo más didáctico y efectivo para hacernos con el manejo de estas potentes herramientas.
Enlace: Ajax API Playground.
Publicado en: www.variablenotfound.com.
 Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.
Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.Por una parte, a finales del pasado mes de octubre se publicó en el sitio de descargas de jQuery, y apareció enlazado desde su propia web oficial, el archivo de anotaciones que permite el disfrute de la experiencia intellisense en todo su esplendor mientras utilizamos la librería desde Visual Studio 2008: información completa sobre los métodos que estamos usando, parámetros, valores de retorno, y autocompletado de escritura. Una gozada, vaya.
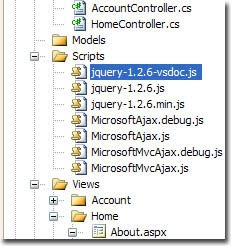 Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.
Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.Por otra parte, sólo unos días después, Microsoft ha publicado el hotfix KB958502 para Visual Studio 2008 Service Pack 1 (y válido también para Visual Web Developer Express SP1) que hace que el entorno sea capaz de buscar automáticamente los archivos de documentación relativos a cada librería javascript que estemos utilizando, y tomar de ellos la información para activar intellisense. De hecho, por cada archivo javascript referenciado desde nuestro código con un nombre "xxx.js", el entorno buscará la documentación en el archivo "xxx-vsdocs.js"; si no la encuentra, probará con "xxx.debug.js", y si tampoco hay nada, dentro de la propia librería "xxx.js".
Por tanto, una vez instalado este parche, si estás utilizando jQuery directamente sobre una página .ASPX, algo muy habitual, basta con descargar el archivo de anotaciones e incluirlo en el directorio de scripts del proyecto para que la magia intellisense comience a funcionar en todas las páginas en las que exista una referencia hacia jQuery (un tag
<script src="...">), o que se basen en una página maestra que incluya dicha referencia.
Si estás editando un fichero javascript (.js) en Visual Studio y desde él quieres utilizar jQuery con intellisense, puedes utilizar un comentario con la etiqueta
Reference, que indica al entorno que puede tomar la documentación de los archivos indicados en la misma. Basta con encabezar el archivo .js así: /// <reference path="jquery-1.2.6-vsdoc.js">
El comentario, obviamente, no afecta a la ejecución, y sólo es interpretado por el IDE para buscar referencias a archivos de documentación.
Por último, como apunta Jeff King, Program Manager en el equipo de herramientas para la Web de Visual Studio, es conveniente aclarar que el objetivo de este parche no es únicamente dar soporte a jQuery; se trata de una solución general para facilitar la integración de documentación de librerías javascript en el entorno de desarrollo, y que seguro vamos a poder aprovechar en muchas otras ocasiones.
Publicado en: www.variablenotfound.com.
 Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.
Todos sabemos que los spammers utilizan aplicaciones (llamadas robots, bots, spambots, o arañas) que, de forma automática, rastrean Internet buscando y almacenando direcciones de correo electrónico. Para ello recorren páginas, analizan su contenido en busca de series de caracteres que puedan parecer una dirección de correo (normalmente localizando la arroba -@- u otros patrones presentes en ellas), y siguen sus enlaces en busca de otras páginas no visitadas para iniciar de nuevo este procedimiento.Esta técnica es tan antigua como la Web, y por este motivo (y no por otros ;-)) estamos en las listas de vendedores de viagra y alargadores de miembros todos aquellos que aún conservamos buzones desde los tiempos en que Internet era un lugar cándido y apacible. Años atrás, poner tu email real en una web, foro o tablón era lo más normal y seguro.
Pero los tiempos han cambiado. Hoy en día, publicar la dirección de email en una web es condenarla a sufrir la maldición del spam diario, y sin embargo, sigue siendo un dato a incluir en cualquier sitio donde se desee facilitar el contacto vía correo electrónico tradicional. Y justo por esa razón existen las técnicas de ofuscación: permiten, o al menos intentan, que las direcciones email sean visibles y accesibles para los usuarios de un sitio web, y al mismo tiempo sean indetectables para los robots, utilizando para ello diversas técnicas de camuflaje en el código fuente de las páginas.
Desafortunadamente, ninguna técnica de ofuscación es perfecta. Algunas usan javascript, lo cual impide su uso en aquellos usuarios que navegan sin esta capacidad (hay estadísticas que estiman que son sobre el 5%); otras presentan problemas de accesibilidad, compatibilidad con algunos navegadores o impiden ciertas funcionalidades, como que el sistema abra el cliente de correo predeterminado al pulsar sobre el enlace; otras, simplemente, son esquivables por los spammers de forma muy sencilla.
En el fondo se trata de un problema similar al que encontramos en la tradicional guerra virus vs. antivirus: cada medida de protección viene seguida de una acción en sentido contrario por parte de los spammers. Una auténtica carrera, vaya, que por la pinta que tiene va a durar bastante tiempo.
En 2006, Silvan Mühlemann comenzó un interesante experimento. Creó una página Web en la que introdujo nueve direcciones de correo distintas, y cada una utilizando un sistema de ofuscación diferente:
- Texto plano, es decir, introduciendo un enlace del tipo:
<a href="mailto:user@myserver.xx">email me</a> - Sustituyendo las arrobas por "AT" y los puntos por "DOT", de forma que una dirección queda de la forma:
<a href="mailto:userATserverDOTxx">email me</a> - Sustituyendo las arrobas y puntos por sus correspondientes entidades HTML:
<a href="mailto:user@server.xx">email me</a> - Introduciendo la dirección con los códigos de los caracteres que la componen:
<a href="mailto:%73%69%6c%76%61%6e%66%6f%6f%62%61%72%34%40%74%69%6c%6c%6c%61%74%65%65%65%65%65">email me</a> - Mostrando la dirección de correo sin enlace y troceándola con comentarios HTML, que el usuario podrá ver sin problema como user@myserver.com aunque los bots se encontrarán con algo como:
user<!-- -->@<!--- @ -->my<!-- -->server.<!--- . -->com - Construyendo el enlace desde javascript en tiempo de ejecución con un código como el siguiente:
var string1 = "user";
var string2 = "@";
var string3 = "myserver.xx";
var string4 = string1 + string2 + string3;
document.write("<a href=" + "mail" + "to:" + string1 +
string2 + string3 + ">" + string4 + "</a>"); - Escribiendo la dirección al revés en el código fuente y cambiando desde CSS la dirección de presentación del texto, así:
<style type="text/css">
span.codedirection { unicode-bidi:bidi-override; direction: rtl; }
</style>
<span class="codedirection">moc.revresym@resu</span> - Introduciendo texto incorrecto en la dirección y ocultándolo después desde CSS:
<style type="text/css">
span.displaynone { display:none; }
</style>
Email me: user@<span class="displaynone">goaway</span>myserver.net - Generando el enlace desde javascript partiendo de una cadena codificada en ROT13, según una idea original de Christoph Burgdorfer:
<script type="text/javascript">
document.write('<n uers=\"znvygb:fvyinasbbone10@gvyyyngr.pbz\" ery=\"absbyybj\">'.replace(/[a-zA-Z]/g, function(c){return String.fromCharCode((c<="Z"?90:122)>=(cc=c.charCodeAt(0)+13)?c:c-26);}));
</script>silvanfoobar's Mail</a>
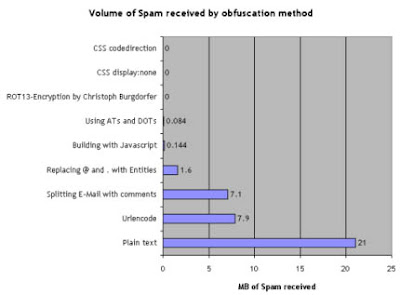 Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.
Las conclusiones que obtuvo son las siguientes: incluir la dirección de correo en texto plano y sin protección (opción 1) generó 21 Megabytes de spam; las peores técnicas, la codificación URL (4) y el troceado de la dirección con comentarios (5) lo redujeron a 7-8Mb; ya la sustitución de la arroba y puntos por las entidades HTML (3) dejó el spam en 1.6 Mb, lo que implica una reducción mayor al 90% sobre la primera alternativa. El uso de AT y DOT (2), así como la generación por javascript (6) dieron como resultado la práctica ausencia de spam, que ya con los tres métodos restantes se redujo a cero absoluto.Por tanto, atendiendo al resultado de este experimento, si estamos desarrollando una página que asume la existencia de javascript podríamos utilizar el método del ROT13 (9) para generar los enlaces
mailto: con ciertas garantías de éxito frente al spam. Podéis usar el código anterior, cambiando el texto codificado (en negrita) por el que generéis desde esta herramienta (ojo: hay que codificar la etiqueta de apertura completa, como <a href="mailto:loquesea">, incluidos los caracteres de inicio "<" y fin ">", pero sin introducir el texto del enlace ni el cierre </a> de la misma).También podemos utilizar alternativas realmente ofuscadoras, como la ofrecida por el Enkoder de Hivelogic, una herramienta on-line que nos permite generar código javascript listo para copiar y pegar, cuya ejecución nos proporcionará un enlace
mailto: completo en nuestras páginas.Pero atención, que el uso de javascript no asegura el camuflaje total y de por vida de la dirección de correo por muy codificada que esté en el interior del código fuente. Un robot que incluya un intérprete de este lenguaje y sea capaz de ejecutarlo podría obtener el email finalmente mostrado, aunque esta opción, por su complejidad y coste de proceso, no es todavía muy utilizada; sí que es cierto que algunos recolectores realizan un análisis del código javascript para detectar determinadas técnicas, por lo que cuando más ofuscada y personalizada sea la generación, mucho mejor.
En caso contrario, si no podemos usar javascript, lo tenemos algo más complicado. Con cualquiera de las soluciones CSS descritas en los puntos 7 y 8 (ambas han conseguido aguantar el tiempo del experimento sin recibir ningún spam), incluso una combinación de ambas, es cierto que el usuario de la página podrá leer la dirección de correo, mientras que para los robots será un texto incomprensible. Sin embargo, estaremos eliminando la posibilidad de que se abra el gestor de correo del usuario al cliquear sobre el enlace, así como añadiendo un importante problema de accesibilidad en la página. Por ejemplo, si el usuario decide copiar la dirección para pegarla en la casilla de destinatario de su cliente, se llevará la sorpresa de que estará al revés o contendrá caracteres extraños. Por tanto, aunque pueda ser útil en un momento dado, no es una solución demasiado buena.
La introducción de "AT" y "DOT", o equivalentes en nuestro idioma como "EN" y "PUNTO", con adornos como corchetes, llaves o paréntesis podrían prestar una protección razonable, pero son un incordio para el usuario y una aberración desde el punto de vista de la accesibilidad. Además, el hecho de que se haya recibido algún mensaje en el buzón que utilizaba esta técnica ya implica que hay spambots que la contemplan y, por tanto, en poco tiempo podría estar bastante popularizada, por lo que habría que buscar combinaciones surrealistas, más difíciles de detectar, como "juanARROBICAservidorPUNTICOcom", o "juanCAMBIA_ESTO_POR_UNA_ARROBAservidorPON_AQUI_UN_PUNTOcom". Pero lo dicho, una incomodidad para el usuario en cualquier caso.
Hay otras técnicas que pueden resultar también válidas, como introducir las direcciones en imágenes, applets java u objetos flash incrustados, redirecciones y manipulaciones desde servidor, el uso de captchas, y un largo etcétera que de hecho se usan en multitud de sitios web, pero siempre nos encontramos con problemas similares: requiere disponer de algún software (como flash, o una JVM), una característica activa (por ejemplo scripts o CSS), o atentan contra la usabilidad y accesibilidad del sitio web.
Como comentaba al principio, ninguna técnica es perfecta ni válida eternamente, por lo que queda al criterio de cada uno elegir la más apropiada en función del contexto del sitio web, del tipo de usuario potencial y de las tecnologías aplicables en cada caso.
La mejor protección es, sin duda, evitar la inclusión de una direcciones de email en páginas que puedan ser accedidas por los rastreadores de los spammers. El uso de formularios de contacto, convenientemente protegidos por sistemas de captcha gráficos (¡los odio!) o similares, pueden ser un buen sustituto para facilitar la comunicación entre partes sin publicar direcciones de correo electrónico.
Publicado en: www.variablenotfound.com.

El archivo distribuido, un zip, contiene siete chuletas en formato PDF:
- Extensiones a los tipos
StringyObject - Extensiones a los tipos
NumberyError - Referencia del tipo
DomEvent - Extensiones al tipo
DomElement - Extensiones a los tipos
DateyBoolean - Eventos del ciclo de vida en cliente
- Extensiones al tipo
Array
Publicado en: www.variablenotfound.com.
jQuery, para que el no haya oído hablar de ella, es una librería Javascript destinada a facilitar enormemente la vida a los desarrolladores simplificando y unificando el manejo de eventos, la manipulación del contenido (DOM), estilos, el uso de Ajax, la creación de animaciones y efectos gráficos, y un larguísimo etcétera propiciado por la facilidad para añadirle plugins que extienden sus funcionalidades iniciales. Y todo ello de forma muy rápida, sin excesivas complicaciones, y sin añadir demasiado peso a las páginas.
En este post vamos a ver un ejemplo de integración de jQuery con ASP.NET MVC framework realizando una aplicación muy sencilla e ilustrativa que nos enseñará cómo enviar información desde el cliente al servidor y actualizar porciones de página completas con el retorno de éste, respetando en todo momento la filosofía MVC.
El funcionamiento será realmente simple: el usuario introduce su nombre y edad, y al pulsar el botón se enviará esta información al servidor, que la utiliza para componer una respuesta y mandarla de vuelta al cliente. Cuando éste la recibe, la mostrará (con un poco de 'magia' visual de jQuery) y transcurridos unos segundos, desaparecerá de forma automática. La siguiente captura muestra el sistema que vamos a construir en ejecución:

Pero antes de entrar en faena, unos comentarios. En primer lugar, sólo voy a explicar los aspectos de interés para la realización del ejemplo, partiendo de las plantillas adaptadas para Web Developer Express 2008. Si prefieres antes una introducción sobre el framework, puedes visitar las magníficas traducciones de Thinking in .Net de los tutoriales de Scott Guthrië sobre MVC. Se refieren a la primera preview, pero los fundamentos son igualmente válidos.
Segundo, supongo que funcionará con versiones superiores de Visual Studio, pero no he podido comprobarlo. Está creado y comprobado con Visual Web Developer Express, y la Preview 2 del framework MVC.
Y por último, decir que el ejemplo completo podrás descargarlo usando el enlace que encontrarás al final del post. :-)
Primero: Estructuramos la solución
En líneas generales, nuestra aplicación tendrá los siguientes componentes:- Tendremos un controlador principal, llamado Home. En él crearemos dos acciones, las dos únicas que permite nuestra aplicación: una, llamada Index, que se encargará de mostrar la página inicial del sistema, y otra llamada Welcome, que a partir de los datos introducidos por el usuario maquetará el interfaz del mensaje de saludo.
- Como consecuencia del punto anterior, dispondremos de dos vistas. La primera, Index compondrá la interfaz principal con el formulario, y la segunda, que llamaremos Welcome, que define la interfaz del saludo al usuario (el recuadro de color amarillo chillón ;-)).
Esta última vista necesitará los datos de la persona (nombre y edad) para poder mostrar correctamente su mensaje, por lo que el controlador deberá enviárselos después de obtenerlos de los parámetros de la petición.
Fijaos que respetamos en todo momento el patrón MVC haciendo que el cliente invoque a la acción Welcome del controlador usando Ajax, y que la composición del interfaz (HTML) se realice a través de la vista correspondiente. Utilizaremos, por tanto, toda la infraestructura del framework MVC, sin modificaciones. - También, para añadir algo de emoción, he incluido una página maestra, que definirá el interfaz general de las páginas del sistema y realizará la inclusión de los archivos adicionales necesarios, como las hojas de estilo y scripts como jQuery.
Segundo: implementamos el controlador
El controlador de nuestra aplicación va a ser bien simple. Lo vemos y comentamos seguidamente:public class HomeController : Controller
{
public void Index()
{
RenderView("Index");
}
public void Welcome(string name, int age)
{
Person person =
new Person { Age = age, Name = name };
RenderView("Welcome", person);
}
}
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}Podemos observar la clase
HomeController que implementa las acciones del controlador Home. La acción Index provoca la visualización de la vista de su mismo nombre. La acción Welcome, es algo más compleja; en primer lugar, se observa que recibe dos parámetros, en nombre y edad del usuario, que utiliza para montar un objeto de tipo
Person, definido algo más abajo, que posteriormente envía a la vista a la hora de renderizarla. Habréis observado aquí la utilización de inicializadores de objetos en la instanciación, y de propiedades automáticas en la definición del tipo.Tercero: implementamos las vistas
Recordemos que vamos a implementar dos vistas, una para la página principal (llamada Index), que mostrará el formulario de entrada de datos, y otra (que llamaremos Welcome) que definirá el interfaz de la respuesta del servidor. Comenzaremos describiendo cómo incluir jQuery en nuestras páginas, y pasaremos después a ellas.3.1. Inclusión de jQuery
Para implementar las vistas necesitamos antes preparar la infraestructura. En primer lugar, descargamos jQuery desde la web oficial del proyecto, y la introducimos en nuestro proyecto. Si vas a descargar la solución completa desde aquí, en ella ya viene incluido el archivo.A continuación, es un buen momento para modificar la página maestra e incluir en ella la referencia a esta librería:
<script type="text/javascript"
src="/scripts/jquery-1.2.3.min.js">
</script>Un inciso importante aquí. Hace unas semanas se publicó un HotFix para Visual Studio 2008 y Web Developer Express que corrije, entre otras, deficiencias en el intellisense y hacen posible el uso de esta magnífica ayuda cuando escribimos código jQuery. Altamente recomendable, pues, instalarse esta actualización.
Sin embargo, el hecho de introducir en la página maestra la referencia a la librería jQuery hace que el intellisense no funcione como debe. Por tanto, aunque no es la opción que he elegido en este proyecto, podríais incluir el script directamente en la vista Index en lugar de en la Master, y así disfrutaréis del soporte a la codificación.
3.2. La vista "Index"
Esta vista será la encargada de mostrar el formulario e implementar la lógica de cliente necesaria para obtener los datos del usuario, enviarlos al servidor y actualizar el interfaz con el retorno. Su implementación se encuentra en el archivo Index.aspx.Desde el punto de vista del interfaz de usuario es bastante simple, lo justo para mostrar un par de inputs con sus correspondientes etiquetas y el botón que iniciará la fiesta llamando a la función
send():<form action="" id="myForm">
<label for="name">Name: </label><input type="text" id="name" />
<br />
<label for="age">Age: </label><input type="text" id="age" size="2" />
<br />
<button id="btn" onclick="send(); return false;">Send!</button>
</form>
<hr />
<div id="result" style="display: none; width: 400px"></div>Observad que no es necesario establecer un action en el formulario, ni otros de los atributos habituales, pues éste no se enviará (de hecho, el formulario incluso sería innecesario). Fijaos también que el evento
onclick del botón retorna false, para evitar que se produzca un postback (¡aaargh, palabra maldita! ;-)) del formulario completo.Puede verse también un
div llamado "result", inicialmente invisible, que se utilizará de contenedor para mostrar las respuestas obtenidas desde el servidor.Pasemos ahora al script. La función
send() invocada como consecuencia de la pulsación del botón pinta así: function send()
{
var name = document.getElementById("name").value;
var age = document.getElementById("age").value;
updateServerText(name, age);
}En realidad no hace gran cosa: obtiene el valor de los textboxes y llama a la función que realmente hace el trabajo duro. Este hubiera sido un buen sitio para poner validadores, pero eso os lo dejo de deberes ;-).
El código de la función
updateServerText() es el siguiente: function updateServerText(name, age)
{
document.getElementById("btn").disabled = true;
$.ajax({
cache: false,
url: '<%= Url.Action("Welcome", "Home") %>',
data: {
Name: name,
Age: age
},
success: function(msg) {
$("#result").html(msg).show("slow");
},
error: function(msg) {
$("#result").html("Bad parameters!").show("slow");
}
});
setTimeout(function () {
document.getElementById("btn").disabled = false;
$("#result").hide("slow");
}, 3000);
}En primer lugar, se desactiva el botón de envío para evitar nuevas pulsaciones hasta que nos interese. He utilizado un método habitual del DOM,
getElementById() para conseguirlo, no encontré una alternativa mejor en jQuery.A continuación se utiliza el método
ajax de jQuery para realizar la llamada al servidor. Aunque existen otras alternativas de más alto nivel y por tanto más fáciles de utilizar, elegí esta para tener más control sobre lo que envío, la forma de hacerlo y la respuesta. Los parámetros utilizados en la llamada a
$.ajax son:cache, con el que forzamos la anulación de caché, obligando a que cada llamada se ejecute totalmente, sin utilizar el contenido almacenado en cliente. Internamente, jQuery añade al querystring un parámetro aleatorio, con lo que consigue que cada llamada sea única.url, la dirección de invocación de la acción, que se genera utilizando el método de ayudaUrl.Action(), pasándole como parámetros el controlador y la acción, lo que retornará la URL asociada en el sistema de rutas definido. En condiciones normales, si la aplicación se ejecuta sobre el raíz del servidor web, se traducirá por '/Home/Welcome'.data, los datos a enviar, que se establecen en formato JSON, donde cada propiedad va seguida de su valor. jQuery tomará estos valores y los transformará en los parámetros que necesita la acción Welcome, por lo que el nombre de las propiedades deberá corresponder con los parámetros que espera esta acción (Name y Age).sucessdefine la función de retorno exitoso, que mostrará los datos recibidos del servidor introduciéndolos en el contenedor "result". Y ya que estamos, gracias a la magia de jQuery, se mostrará con un efecto visual muy majo.error, define una función de captura de errores para casos extraños, por si todo falla. Por ejemplo, dado que no estamos validando la entrada del usuario, si éste introduce texto en la edad, el framework no será capaz de realizar la conversión para pasarle los parámetros al controlador y fallará estrepitosamente; en este caso simplemente mostraremos un mensaje de error en cliente.
Fijaos que la llamada a la acción (Welcome) del controlador (Home) es capturada por el framework y dirigida al método correspondiente sin necesidad de hacer nada más, dado que se trata de una llamada HTTP normal. De hecho, si sobre el navegador se introduce la dirección "http://localhost:[tupuerto]/Home/Welcome?Name=Peter&Age=12" podremos ver en pantalla el mismo resultado que recibirá la llamada Ajax.

Obviamente, este efecto podría ser controlado y hacer que sólo se respondieran peticiones originadas a través de Ajax y similares.
Por último, continando con el código anterior, dejamos programado un timer para que unos segundos más tarde, el mensaje mostrado, sea cual sea el resultado de la llamada Ajax, desaparezca lentamente y, de paso, se active de nuevo el botón de envío. El efecto, ya lo veréis si ejecutáis la solución, es de lo más vistoso, creando una sensación de interactividad y dinamismo muy a lo 2.0 que está tan de moda.
3.3. La vista "Welcome"
En esta vista definiremos el interfaz del mensaje que mostraremos al usuario cuando introduzca su información y pulse el botón de envío. Dado que estamos usando MVC, la llamada Ajax descrita anteriormente llegará al controlador y éste hará que la vista cree el interfaz que será devuelto al cliente.La vista, por tanto, es como cualquier otra, salvo algunas diferencias interesantes. Por ejemplo, no tiene página maestra, no la necesita; de hecho ni siquiera tiene la estructura de una página HTML completa, sólo de la porción que necesita para montar su representación. El código de Welcome.aspx, salvo las obligatorias directivas iniciales, es:
<div style="background-color: Yellow; border: 1px solid black;">
<em>Message from server (<%=DateTime.Now %>):</em><br />
Hi, <%= ViewData.Name %>, your age is <%= ViewData.Age %>
</div>Pero aún queda un detalle que afinar. En el archivo code-behind (o codefile) donde se define la clase
Welcome hay que indicar expresamente que la clase es una vista de un tipo concreto de la siguiente forma: public partial class Views_WebParts_Welcome : ViewPage<Person>
{
}De esta forma indicamos que los datos de la vista son del tipo
Person, lo que nos permite beneficiarnos del tipado fuerte en la composición de la misma; de hecho, esto es lo que permite que podamos usar tan alegremente una expresión como ViewData.Age a la hora de componer el interfaz.Fijaos que aunque en este ejemplo no hemos hecho ninguna composición compleja y los datos que hemos usado, contenidos en
ViewData, han sido obtenidos por el Controlador directamente de la vista, sería exactamente igual si se tratara de algo menos simple, como una página concreta de datos obtenidos desde el Modelo, por ejemplo con Linq, y mostrados en forma de grid. Cuarto: recapitulamos
Hemos visto, paso a paso, un ejemplo de cómo podemos utilizar el framework MVC de Microsoft para el desarrollo de aplicaciones web que hacen uso de Ajax, utilizando para ello la excelente librería de scripting jQuery.Para ello hemos creado una vista que es la página Web con el formulario principal, y otra vista parcial con el fragmento compuesto por el servidor con la información recibida. El controlador, por su parte, incluye acciones para responder a las peticiones del cliente independientemente de si se originan a través de Ajax o mediante la navegación del usuario, mostrando la vista oportuna.
La modificación dinámica del interfaz, así como las llamadas asíncronas al servidor, encajan perfectamente en la filosofía MVC teniendo en cuenta algunas reglas básicas, como el respeto a las responsabilidades de cada capa.
Y ahora, lo prometido:
 Descargar proyecto (Visual Web Developer Express 2008).
Descargar proyecto (Visual Web Developer Express 2008).Publicado en: www.variablenotfound.com.
 Pablo ha lanzado una pregunta en el post Deshabilitar y habilitar un validador ASP.Net desde Javascript publicado hace unos meses, que creo interesante responder en una entrada en exclusiva, por si puede ayudar a alguien más.
Pablo ha lanzado una pregunta en el post Deshabilitar y habilitar un validador ASP.Net desde Javascript publicado hace unos meses, que creo interesante responder en una entrada en exclusiva, por si puede ayudar a alguien más."Al utilizar la funcion ValidatorEnable para habilitar un validador, me activa automaticamente la validacion, y me muestra el texto que pongo para cuando la validacion no se cumpla, como puedo evitar esto"
Recordemos que el post trataba sobre cómo conseguir, desde Javascript, habilitar o deshabilitar validadores de controles incluidos en un webform utilizando la función
ValidatorEnable(), que pone a nuestra disposición ASP.Net.El problema, como comenta Pablo, es que al habilitar la validación desde script se muestran de forma automática los mensajes de error en todos aquellos controles que no sean válidos, provocando un efecto que puede resultar desconcertante para el usuario.
Indagando un poco, he comprobado que el problema se debe a que
ValidatorEnable(), después de habilitar el validator, comprueba si los valores del control son correctos, mostrando el error en caso contrario.Existen al menos dos formas de solucionar este problema.
La primera consiste en jugar con la visibilidad del mensaje de error. Como se observa en el siguiente código, al llamar a la función
HabilitaValidador(), ésta llamará a ValidatorEnable y acto seguido, si el control no es válido, oculta el mensaje de error:
function HabilitaValidador(validator, habilitar)
{
ValidatorEnable(validator, habilitar);
if (habilitar && !validator.isvalid)
validator.style.visibility = "hidden";
}
La segunda forma consiste en simular el comportamiento interno de
ValidatorEnable, pero eliminando la llamada a la comprobación de la validez del control.
function HabilitaValidador(validator, habilitar)
{
validator.enabled = habilitar;
}
Como se puede ver, simplemente se está estableciendo la propiedad
enabled del validador, sin realizar ninguna comprobación posterior.En ambos casos, la forma de utilizar esta función desde script sería la misma:
function activar()
{
HabilitaValidador("<%= RequiredFieldValidator1.ClientID %>", true);
}
Para mi gusto la opción más limpia, aunque sea jugando con la visibilidad de los elementos, es la primera de las mostradas, pues se respeta el ciclo completo de validación. En el segundo método nos estamos saltando las validaciones y el seguimiento de la validez global de la página, que la función original
ValidatorEnable sí contempla.Espero que esto resuelva la duda.
Publicado en: www.variablenotfound.com.
 Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.
Vía Dirson me entero de que Google ha publicado recientemente el API que permite, a base de Ajax, realizar traducciones de textos entre los idiomas contemplados por la herramienta, más de una decena.Google nos tiene acostumbrados a implementar APIs muy sencillas de usar, y en este caso no podía ser menos. Para demostrarlo, vamos a crear una página web con un sencillo traductor en Javascript, comentando paso por paso lo que hay que hacer para que podáis adaptarlo a vuestras necesidades.
Paso 1: Incluir el API
La inclusión de las funciones necesarias para realizar la traducción es muy sencilla. Basta con incluir el siguiente código, por ejemplo, en la sección HEAD de la página: <script type="text/javascript"
src="http://www.google.com/jsapi">
</script>
<script type="text/javascript">
google.load("language", "1");
</script>
El primer bloque descarga a cliente la librería javascript Ajax API Loader, el cargador genérico de librerías Ajax utilizado por Google. Éste se usa en el segundo bloque script para cargar, llamando a la función
google.load el API "language" (traductor), en su versión 1 (el segundo parámetro).Paso 2: Creamos el interfaz
Nuestro traductor será realmente simple. Además, vamos a contemplar un pequeño subconjunto de los idiomas permitidos para no complicar mucho el código, aunque podéis añadir todos los que consideréis necesarios.El resultado será como el mostrado en la siguiente imagen.

El código fuente completo lo encontraréis al final del post, por lo que no voy a repetirlo aquí. Simplemente indicar que tendremos un
TextArea donde el usuario introducirá el texto a traducir, dos desplegables con los idiomas origen y destino de la traducción, y un botón que iniciará la acción a través del evento onclick. Por último, se reservará una zona en la que insertaremos el resultado de la traducción.Ah, un detalle interesante: en el desplegable de idiomas de origen se ha creado un elemento en el desplegable "Auto", cuyo valor es un string vacío; esto indicará al motor de traducción que infiera el idioma a partir del texto enviado.
Paso 3: ¡Traducimos!
La pulsación del botón provocará la llamada a la funciónOnclick(), desde donde se realizará la traducción del texto introducido en el TextArea.Como podréis observar en el código, en primer lugar obtendremos los valores de los distintos parámetros, el texto a traducir y los idiomas origen y destino, y lo introducimos en variables para facilitar su tratamiento.
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
Acto seguido, realizamos la llamada al traductor. El primer parámetro será el texto a traducir, seguido de los idiomas (origen y destino), y por último se introduce la función callback que será invocada cuando finalice la operación; hay que tener en cuenta que la traducción es realizada a través de una llamada asíncrona a los servidores de Google:
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
Como podéis observar, y es quizás lo único extraño que tiene esta instrucción, el callback se ha definido como una función anónima definida en el espacio del mismo parámetro (podéis ver otro ejemplo de este tipo de funciones cuando explicaba cómo añadir funciones con parámetros al evento OnLoad).
Para los queráis jugar con esto directamente, ahí va el código listo para un copiar y pegar.
<html>
<head>
<title>Traductor</title>
<script type="text/javascript" src="http://www.google.com/jsapi"></script>
<script type="text/javascript">
google.load("language", "1");
</script>
</head>
<body>
<textarea id="text" rows="8" cols="40">Hi, how are you?</textarea>
<br />
<button onclick="onClick()">
Traducir</button>
Del idioma
<select id="srcLang">
<option value="">(Auto)</option>
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
Al
<select id="dstLang">
<option value="es">Español</option>
<option value="en">Inglés</option>
<option value="fr">Francés</option>
</select>
<h3>Traducción:</h3>
<div id="result">
(Introduce un texto)
</div>
</body>
<script type="text/javascript">
function onClick()
{
// obtenemos el texto y los idiomas origen y destino
var text = document.getElementById("text").value;
var srcLang = document.getElementById("srcLang").value;
var dstLang = document.getElementById("dstLang").value;
// llamada al traductor
google.language.translate(text, srcLang, dstLang, function(result)
{
if (!result.error)
{
var resultado = document.getElementById("result");
resultado.innerHTML = result.translation;
}
else alert(result.error.message);
}
);
}
</script>
</html>
Enlaces: Página oficial de documentación del API
Publicado en: www.variablenotfound.com.
 Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?
Cuando estamos desarrollando es habitual que tengamos que comentar porciones de código para realizar pruebas. Esto resulta de lo más sencillo cuando programamos en un lenguaje de los habituales como Javascript, C#, Visual Basic o incluso (X)HTML, pues todos ellos disponen de marcadores que hacen que el compilador o intérprete ignore determinadas líneas de código... pero, ¿cómo logramos este efecto si se trata de un archivo .ASPX, donde pueden encontrarse varios de ellos a la vez?Por ejemplo, dado el siguiente código en el interior de una página ASP.NET, ¿cuál sería la forma correcta de comentarlo?
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
Una primera opción podría ser utilizar la sintaxis Javascript de la siguiente forma:
<script>
/*
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
*/
</script>
Sin embargo, aunque podría valer en muchas ocasiones, también puede introducir unos efectos laterales considerables. Nótese que aunque el código Javascript (cliente) esté comentado, la función
borrarRegistros() sería invocada en el lado del servidor, y su retorno introducido dentro del comentario. De hecho, la página enviada a cliente mostraría un código fuente similar al siguiente (imaginando que el retorno de la función fuera el valor 99):<script>
/*
var count = 99;
alert("Borrados: " + count + " registros");
*/
</script>
Tampoco valdría para nada incluir todo el bloque de script dentro de un comentario HTML (<!-- y -->), por la misma razón que antes. Además, en cualquiera de estos dos casos, estaríamos enviando al cliente la información aunque sea éste el que la ignora a la hora de mostrarla o ejecutarla y, por supuesto, estaríamos ejecutando la función en servidor, lo cual podría causar otros efectos no deseados, como, en nuestro ejemplo, eliminar los registros de una base de datos.
Afortunadamente, ASP.NET dispone de un mecanismo, denominado Server Side Comments (comentarios en el lado del servidor), que permite marcar zonas y hacer que se ignore todo su contenido, sea del tipo que sea, a la hora de procesar la página:
<%--
<script>
var count = <%= borrarRegistros() %>
alert("Borrados: " + count + " registros");
</script>
--%>
En este caso ni sería ejecutada la función del servidor ni tampoco enviado a cliente el código HTML/Script incluido.
Publicado en: http://www.variablenotfound.com/.
Recordemos que los métodos estáticos de página son una interesante capacidad que nos ofrece este framework para poder invocar desde cliente (javascript) funciones de servidor (codebehind) de una forma realmente sencilla. Además, gracias a los mecanismos de seriación incluidos, y como ya vimos en el post "Usando ASP.NET AJAX para el intercambio de entidades de datos", es perfectamente posible devolver desde servidor entidades o estructuras de datos complejas, y obtenerlas y procesarlas directamente desde cliente utilizando javascript, y viceversa.
Es es ahí donde reside el problema con los DataSets: precisamente este tipo de datos no está soportado directamente por el seriador JSON incorporado, que es el utilizado por defecto, de ahí que se genere una excepción como la que sigue:
System.InvalidOperationException
A circular reference was detected while serializing an object of type 'System.Globalization.CultureInfo'.
en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValueInternal(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat serializationFormat)\r\n en System.Web.Script.Serialization.JavaScriptSerializer.SerializeValue(Object o, StringBuilder sb, Int32 depth, Hashtable objectsInUse, SerializationFormat [...]
Pero antes de nada, un inciso. Dado que la excepción se produce en el momento de la seriación, justo antes de enviar los datos de vuelta al cliente, debe ser capturada en cliente vía la función callback especificada como último parámetro en la llamada al método del servidor:
// Llamada a nuestro PageMethod
PageMethods.GetData(param, OnOK, OnError);
[...]
function OnError(msg)
{
// msg es de la clase WebServiceError.
alert("Error: " + msg.get_message());
}
Aclarado esto, continuamos con el tema. La buena noticia es que el soporte para DataSets estará incluido en futuras versiones de la plataforma. De hecho, es perfectamente posible utilizar las librerías disponibles en previews disponibles en la actualidad. Existen multitud de ejemplos en la red sobre cómo es posible realizar esto, aunque será necesario instalar alguna CTP y referenciar librerías en el Web.config. Podéis echar un vistazo a lo descrito en este foro.
Esta solución sin embargo no es muy recomendable en estos momentos, puesto que estaríamos introduciendo en un proyecto librerías y componentes que, en primer lugar, están ideados sólo para probar y tomar contacto con las nuevas tecnologías, y, en segundo lugar, las características presentadas en ellos pueden modificarse o incluso eliminarse de las futuras versiones.
Existen otras formas de hacerlo, como la descrita en siderite, que consiste en crear un conversor justo a la medida de nuestras necesidades extendiendo la clase
JavaScriptConverter, aunque aún me parecía una salida demasiado compleja al problema.Sin embargo, la solución que he visto más simple es utilizar XML para la seriación de estas entidades, lo que se puede lograr de una forma muy sencilla añadiendo al método a utilizar un atributo modificando el formato de respuesta utilizado por defecto, de JSON a XML.
He creado un proyecto de demostración para VS2005, esta vez en VB.NET aunque la traducción a C# es directa, con una página llamada DataSetPageMethods.aspx en el que se establece un PageMethod en el lado del servidor, con la siguiente signatura:
<WebMethod()> _
<Script.Services.ScriptMethod(ResponseFormat:=ResponseFormat.Xml)> _
Public Shared Function ObtenerClientes(ByVal ciudad As String) As DataSet
 Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.
Este método estático obtendrá de la tradicional base de datos NorthWind (en italiano, eso sí, no tenía otra a mano O:-)) un DataSet con los clientes asociados a la ciudad cuyo nombre se recibe como parámetro.Como podréis observar, el método está precedido por la declaración de dos atributos. El primero de ellos,
WebMethod(), lo define como un PageMethod y lo hará visible desde cliente de forma directa. El segundo de ellos redefine su mecanismo de seriación por defecto, pasándolo a XML. Si queréis ver el error al que hacía referencia al principio, podéis modificar el valor del ResponseFormat a JSON, su valor por defecto.Desde cliente, al cargar la página rellenamos un desplegable con las distintas ciudades. Cuando el usuario selecciona un elemento y pulsa el botón "¡Pulsa!", se realizará una llamada asíncrona al PageMethod, según el código:
function llamar()
{
PageMethods.ObtenerClientes($get("<%= DropDownList1.ClientID %>").value , OnOK, OnError);
}
La función callback de notificación de finalización de la operación,
OnOk, recibirá el DataSet del servidor y mostrará en la página dos resúmenes de los datos obtenidos que describiré a continuación. He querido hacerlo así para demostrar dos posibles alternativas a la hora de procesar desde cliente los datos recibidos, el DataSet, desde servidor.En el primer ejemplo, se crea en cliente una lista sin orden con los nombres de las personas de contacto de los clientes (valga la redundancia ;-)), donde muestro cómo es posible utilizar el DOM para realizar recorridos sobre el conjunto de datos:
var nds = data.documentElement.getElementsByTagName("NewDataSet");
var rows = nds[0].getElementsByTagName("Table");
var st = rows.length + " filas. Personas: br />";
st += "<ul>";
for(var i = 0; i < rows.length; i++)
{
st += "<li>" + getText(rows[i].getElementsByTagName("Contatto")[0])+ "</li>";
}
st += "</ul>";
etiqueta.innerHTML = st;
En el segundo ejemplo se muestra otra posibilidad, la utilización de DOM para crear una función recursiva que recorra en profundidad la estructura XML mostrando la información contenida. La función javascript que realiza esta tarea se llama
procesaXml.Como se puede comprobar analizando el código, utilizar la información del
DataSet en cliente es necesario, en cualquier caso, un conocimiento de la estructura interna de est tipo de datos, lo cual no es sencillo, por lo que recomendaría enviar y gestionar los DataSets en cliente sólo cuando no haya más remedio.Una alternativa que además de resultar menos pesada en términos de ancho de banda y proceso requerido para su tratamiento es bastante más sencilla de implementar sería enviar a cliente la información incluida un un array, donde cada elemento sería del tipo de datos apropiado (por ejemplo, un array de Personas, Facturas, o lo que sea). La seriación será JSON, mucho más optimizada, además de resultar simplísimo su tratamiento en javascript.
El proyecto de demostración también incluye una página (ArrayPageMethods.aspx) donde está implementado un método que devuelve un array del tipo
Datos, cuya representación se lleva también a cliente y hace muy sencillo su uso, como se puede observar en esta versión de la función de retorno OnOk:
function OnOK(datos)
{
var etiqueta = $get("lblMensajes");
var s = "<ul>";
for (var i = 0; i < datos.length; i++)
{
s += "<li>" + datos[i].Contacto;
s += ". Tel: " + datos[i].Telefono;
s += "</li>";
}
s += "</ul>";
etiqueta.innerHTML = s;
}
Por último, comentar que el proyecto de ejemplo funciona también con VS2008 (Web Developer Express), aunque hay que abrirlo como una web existente.
Publicado en: www.variablenotfound.com.
Enlace: Descargar proyecto VS2005.
Concretamente, gerardo pregunta cómo podría añadir varios controladores con parámetros al evento OnLoad de la página, como él mismo dice,
La funcion de script que usas para añadir varias funciones al evento onload esta bien si son llamadas sin parametros. La duda es cómo podría hacer lo mismo si la función que tiene que correr en el inicio recibiera un parametro de entrada.Siguiendo tu ejemplo, me gustaria usar algo como:
addOnLoad(init1(3));
addOnLoad(init2(4));
Efectivamente, la fórmula que propone este amigo no es válida; de hecho, estaríamos añadiendo al evento OnLoad el retorno de la llamada a
init1(3), lo cual sólo funcionaría si esta función devolviera una referencia a una función capaz de ser invocada por el sistema.Para hacerlo de forma correcta, como casi siempre en este mundo, hay varias formas. Comentaré algunas de ellas.
La obvia
Ni que decir tiene que el método más sencillo es sin duda introducir las llamadas en el atributo onload del elemento body de la página, es decir,
<body onload="alert('hola 1'); alert('hola 2');">
Por desgracia no siempre es posible modificar el atributo onload del cuerpo de la página, así que lo mejor será estudiar otras maneras.
La fácil
También podríamos utilizar un modelo bastante parecido al indicado en el post inicial, vinculando al OnLoad una función que, a su vez, llamará a las distintas funciones (con los parámetros oportunos) de forma secuencial:
// Asociamos las funciones al
// evento OnLoad:
addOnLoad(miFuncion1);
addOnLoad(miFuncion2);
function miFuncion1() {
alert('hola 11');
alert('hola 12');
}
function miFuncion2() {
alert('hola 2');
}
La "pro"
Aunque cualquiera de los dos métodos comentados hasta el momento son válidos y funcionan perfectamente, vamos a ver otra en la que se utiliza una característica de javascript (y otros lenguajes, of course), las funciones anónimas.Las funciones anónimas son como las de toda la vida, pero con un detalle que la diferencia de éstas: no tienen nombre. Se definen sus parámetros y su cuerpo de forma directa en un contexto en el que pueden ser utilizados sin necesidad de indicar qué nombre vamos a darle.
En el caso que nos ocupa, y tomando como base el ejemplo anterior, en vez de invocar a la función addOnLoad() pasándole como parámetro el nombre de la función que contiene lo que queremos hacer, le enviaríamos una función anónima indicando exactamente lo que queremos hacer:
// En este código se hace lo mismo que
// el ejemplo anterior:
addOnLoad(
function() {
alert('hola 11');
alert('hola 12');
}
);
addOnLoad( function() { alert('hola 2'); } );
De esta forma la llamada a la función addOnLoad se realiza utilizando como parámetro la referencia a la función anónima, y todo puede funcionar correctamente.
 Inicializaciones de librerías, llamadas a servidor mediante Ajax para obtener datos o porciones de la página, efectos gráficos... son sólo algunos de los escenarios donde resulta interesante utilizar scripts de arranque o (startup scripts), que se ejecuten en cliente en cuanto le llegue la página web.
Inicializaciones de librerías, llamadas a servidor mediante Ajax para obtener datos o porciones de la página, efectos gráficos... son sólo algunos de los escenarios donde resulta interesante utilizar scripts de arranque o (startup scripts), que se ejecuten en cliente en cuanto le llegue la página web.Esto hay al menos dos formas de hacerlo: llamar a la función deseada desde el evento
onload() del cuerpo de la página o bien hacerlo en un bloque de scripts fuera de cualquier función, bien sea dentro del propio (X)HTML o bien en un recurso .js externo. Pero hace tiempo que tenía una curiosidad: ¿qué diferencia hay entre una u otra? ¿cuándo deben usarse? ¿tienen contraindicaciones?Para averiguarlo, he creado la siguiente página:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head>
<title>Prueba de scripting</title>
</head>
<body onload="alert('OnLoad()');">
<h1>Prueba Scripting</h1>
</body>
<script type="text/javascript">
alert('Script en HTML');
</script>
<script type="text/javascript" src="script.js"></script>
</html>Como se puede observar:
- en el elemento <body> he incluido un atributo onload="alert('onload');".
- he añadido un bloque script con una única instrucción alert('script HTML');
- he añadido también una referencia a un archivo script externo, en el que sólo hay una instrucción alert('archivo .js');
- Se ejecuta en primer lugar el código incluido en los bloques <script> .
- Si hay varios bloques de script, se ejecuta el código incluido en cada uno de ellos, siguiendo del orden en el que están declarados.
- No importa si son scripts incrustados en la página o si se encuentran en un archivo .js externo, se ejecutan cuando le llega el turno según el orden en el que han sido definidos en la página, es decir, la posición del tag <script> correspondiente.
- Por último, se ejecuta el código del evento onload del cuerpo de la página. De hecho, este evento se ejecuta una vez se ha cargado y mostrado la página al usuario, es el último en tomar el control.
Debemos usar onload() si queremos que nuestro código se ejecute al final, cuando podemos asegurar que todo lo que tenía que pasar ya ha pasado; eso sí, mucho ojo, que onload() es un recurso limitado (de hecho, sólo hay uno ;-)), y si no se tiene cuidado podemos hacer que una asignación nuestra haga que no se ejecute la función anteriormente definida para el evento. Esto se evita normalmente incluyendo en el atributo onload de la etiqueda body las sucesivas llamadas a las distintas funciones de inicialización requeridas (
<body onload="init1(); init2();"...), o bien desde script utilizando el siguiente código, todo un clásico:
function addOnLoad(nuevoOnLoad) {
var prevOnload = window.onload;
if (typeof window.onload != 'function') {
window.onload = nuevoOnLoad;
}
else {
window.onload = function() {
prevOnload();
nuevoOnLoad();
}
}
}
// Las siguientes llamadas enlazan las
// funciones init1() e init2() al evento
// OnLoad:
addOnLoad(init1);
addOnLoad(init2);
En cambio, la introducción de código de inicialización directamente en scripts se ejecutará al principio, incluso antes de renderizar el contenido de la página en el navegador, por lo que es bastante apropiada para realizar modificaciones del propio marcado (por ejemplo a través del DOM) o realizar operaciones muy independientes del estado de carga de la página. Como ventaja adicional, destacar su facilidad para convivir con otros scripts similares o asociados al evento OnLoad().
 Si eres de los que, como yo, piensan que la moda de los bordes redondeados la ha impuesto gente que odia a los programadores y diseñadores de webs, nunca te ha convencido introducir (X)HTML sin carga semántica sólo para poder incluir estas filigranas en las esquinas de los DIVS o elementos de bloque similares, o no soportas crear imágenes redondeadas para las esquinas, es posible que te interese Nifty Corners Cube.
Si eres de los que, como yo, piensan que la moda de los bordes redondeados la ha impuesto gente que odia a los programadores y diseñadores de webs, nunca te ha convencido introducir (X)HTML sin carga semántica sólo para poder incluir estas filigranas en las esquinas de los DIVS o elementos de bloque similares, o no soportas crear imágenes redondeadas para las esquinas, es posible que te interese Nifty Corners Cube.Se trata de una librería Javascript para redondear los bordes de elementos de bloque sin necesidad de crear imágenes ni nada parecido, sólo usando CSS y scripting. Además, no es intrusiva: si un navegador no soporta scripts o se trata de una versión no contemplada, el usuario simplemente verá sus bordes como siempre. Buena pinta, eh?
Y la forma de usarlo, fácil. En primer lugar, una vez descargado el archivo .zip y extraído en un directorio de la web, se coloca la referencia al script sobre la página (X)HTML como siempre:
<script type="text/javascript" src="niftycube.js"></script>
Desde ese momento ya podemos invocar desde Javascript a las funciones de la librería para que actúen sobre los elementos cuya presentación queremos modificar, por ejemplo así:
// Esto hace que al div con id="box"
// se le redondeen los bordes con
// esquinas grandes (10px):
Nifty("div#box","big");
Esta llamada, o mejor dicho, todas las llamadas que necesitemos para ajustar los efectos de nuestra página, pueden situarse en el evento onload de la misma, como se muestra a continuación. De todas formas, la propia librería ofrece un método alternativo, a través de la función NiftyLoad(), para cuando esto no sea posible.
<script type="text/javascript">
window.onload=function(){
Nifty("div.redondeadoGrande","big");
Nifty("div.redondeadoPeque","small");
}
</script>
En la función Nifty, el primer parámetro es el selector CSS al que se aplicará el borde (o efecto) deseado. Si no tienes claro qué es un selector, podrías echarle un vistazo a este post (selectores CSS), este (selectores CSS-II-), y este otro (selectores CSS-III).
 Así, si indicamos el selector "div.redondeado" estaremos aplicando el efecto a todos aquellos divs cuya clase sea la indicada (class="redondeado").
Así, si indicamos el selector "div.redondeado" estaremos aplicando el efecto a todos aquellos divs cuya clase sea la indicada (class="redondeado").El segundo parámetro es una palabra clave, a elegir entre una larga lista de opciones, algunas de ellas combinables. Aunque en la web del autor viene muy bien explicado con ejemplos, :
| Palabra | Significado |
|---|---|
| tl | esquina superior izquierda |
| tr | esquina superior derecha |
| bl | esquina inferior izquierda |
| br | esquina inferior derecha |
| top | esquinas superiores |
| bottom | esquinas inferiores |
| left | esquinas izquierdas |
| right | esquinas derechas |
| all (default) | las cuatro esquinas |
| none | no redondear las esquinas (útil para usar las nifty columns |
| small | esquinas pequeñas (2px) |
| normal (default) | esquinas normales (5px) |
| big | esquinas grandes (10px) |
| transparent | permite crear esquinas transparentes con alias. Se aplica automáticamente cuando el elemento no tiene un color de fondo especificado. |
| fixed-height | se aplica cuando el elemento tiene un alto fijo especificado en su CSS |
| same-height | Parámetro para nifty columns: todos los elementos identificados por el selector CSS tienen el mismo alto. Si el efecto se utiliza sin bordes redondeados, este parámetro se puede usar en conjunción con la palabra clave none. |
En la web del autor hay multitud de ejemplos de uso que demuestran lo fácil que puede llegar a hacernos la vida. Por cierto, también he encontrado una versión en español.
Por último, comentar que la librería se distribuye bajo licencia GNU GPL, y lo podéis descargar en esta dirección.
Hala, a disfrutarlo.





