
domingo, 30 de noviembre de 2008
 Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.
Es habitual que las aplicaciones que desarrollamos necesiten enviar emails: alertas, notificaciones automáticas, formularios de contacto, o envíos masivos de información, entre otros, son ejemplos de utilización muy habituales.Y en estos casos la inclusión de imágenes incrustadas suele ser un requisito fundamental cuando se trata de enviar contenidos con formato HTML, de forma que, aunque normalmente se incrementa de forma notable el tamaño del paquete a enviar, se evita que los clientes tengan que descargar estos recursos adicionales desde sus equipos, cosa que además suele estar bloqueada por defecto.
.NET framework nos ofrece varias vías para hacerlo usando las clases provistas en
System.Net.Mail, pero vamos a utilizar una que nos ofrece dos ventajas importantes. La primera es que las imágenes enviadas no se muestran como adjuntos (evitando, por ejemplo, el curioso efecto presente en Outlook Express, que repite las imágenes a continuación del texto del mensaje) y la segunda es que permite especificar distintas vistas dentro desde el mismo mensaje, para que el cliente de correo utilice la que sea más apropiada.El siguiente código muestra una forma de montar un mensaje con dos vistas: la primera será utilizada por aquellos agentes de usuario (clientes de correo) que únicamente pueden mostrar texto plano, mientras que en la segunda utilizará HTML para maquetar el contenido, incluyendo una imagen que aparecerá totalmente integrada en el cuerpo del mensaje, sin mostrarse como elemento adjunto del mismo.
Podréis observar que aunque en el ejemplo muestro un código muy rígido, es fácilmente generalizable para poder utilizarlo en cualquier escenario. Como en otras ocasiones, está en C#, mi lenguaje favorito, pero sería fácilmente portable a VB.NET, por ejemplo.
// Necesitaremos estos namespaces...
using System.Net.Mail;
using System.Net.Mime;
...
// Montamos la estructura básica del mensaje...
MailMessage mail = new MailMessage();
mail.From = new MailAddress("origen@miservidor.com");
mail.To.Add("destinatario@miservidor.com");
mail.Subject = "Mensaje con imagen";
// Creamos la vista para clientes que
// sólo pueden acceder a texto plano...
string text = "Hola, ayer estuve disfrutando de "+
"un paisaje estupendo.";
AlternateView plainView =
AlternateView.CreateAlternateViewFromString(text,
Encoding.UTF8,
MediaTypeNames.Text.Plain);
// Ahora creamos la vista para clientes que
// pueden mostrar contenido HTML...
string html = "<h2>Hola, mira dónde estuve ayer:</h2>" +
"<img src='cid:imagen' />";
AlternateView htmlView =
AlternateView.CreateAlternateViewFromString(html,
Encoding.UTF8,
MediaTypeNames.Text.Html);
// Creamos el recurso a incrustar. Observad
// que el ID que le asignamos (arbitrario) está
// referenciado desde el código HTML como origen
// de la imagen (resaltado en amarillo)...
LinkedResource img =
new LinkedResource(@"C:\paisaje.jpg",
MediaTypeNames.Image.Jpeg);
img.ContentId = "imagen";
// Lo incrustamos en la vista HTML...
htmlView.LinkedResources.Add(img);
// Por último, vinculamos ambas vistas al mensaje...
mail.AlternateViews.Add(plainView);
mail.AlternateViews.Add(htmlView);
// Y lo enviamos a través del servidor SMTP...
SmtpClient smtp = new SmtpClient("smtp.miservidor.com");
smtp.Send(mail);
La siguiente imagen muestra una captura de pantalla del mismo mensaje leído desde un cliente con capacidad HTML como Outlook Express y uno que no la tiene, en este caso basado en web:

Publicado en: www.variablenotfound.com.
domingo, 23 de noviembre de 2008
Este artículo es una traducción del original "20 Famous Software Disasters - Part 4" publicado hace unos meses por Timm Martin en su blog Devtopics, realizada con permiso expreso de su autor.
Aquí puedes encontrar la primera, segunda y tercera parte.

Desastre: la burbuja especulativa creada entre 1995 y 2001 alimentó un rápido aumento en inversiones en capital riesgo y valores bursátiles en Internet y los sectores tecnológicos. La burbuja "punto com" comenzó a hundirse al principio del 2000, eliminando billones en valores, miles de compañías y empleos, y comenzando una recesión global.
Causa: Las compañías e inversores obviaron los modelos de negocio habituales, centrándose en cambio en el aumento de cuota de mercado a expensas de los beneficios. (Más información)

Desastre: El gusano LoveLetter (carta de amor) infectó millones de ordenadores y causó más daño que cualquier otro virus informático en la historia. El gusano eliminaba archivos, modificaba la página de inicio de los usuarios y el registro de Windows.
Causa: LoveLetter infectaba a los usuarios vía email, chats y carpetas compartidas. Enviaba a través de correo electrónico un mensaje con el asunto "ILOVEYOU" y un archivo adjunto; cuando el usuario abría el archivo, el virus infectaba su ordenador y se autoenviaba a todos los contactos de la libreta de direcciones. (Más información)

Desastre: El software de radiación terapéutica creado por Multidata Systems International fallaba al calcular la dosis apropiada, exponiendo a los pacientes a peligrosos, y en algunos casos mortales, niveles de radiación. Los físicos, a los que legalmente se exige una doble comprobación de los cálculos del software, fueron acusados de asesinato.
Causa: El software calculaba la dosis de radiación basándose en el orden en que los datos eran introducidos, lo que provocaba que a veces generara una dosis doble de radiación. (Más información)

Desastre: El gigante de servicios EDS desarrolló un sistema informático para la agencia británica "Child Support Agency (CSA)" que accidentalmente pagó más de lo debido a 1.900.000 personas, pagó de menos a otras 700.000, tenía 3.500 millones de libras de manutención de niños sin cobrar, un atraso de 239.000 casos, 36.000 nuevos casos bloqueados en el sistema, y todavía hay más de 500 bugs documentados.
Causa: EDS introdujo un enorme y complejo sistema de información en la CSA de forma simultánea a una reestructuración de la agencia. (Más información)

Desastre: El FBI desechó su nuevo sistema informático después de cuatro años de esfuerzo. El macro-proyecto Trilogy, era un archivo virtual integrado que permitiría a los agentes compartir expedientes de casos y otra información.
Causa: La mala gestión, y un intento de construir un proyecto a largo plazo sobre tecnología que era obsoleta antes de que el proyecto se completara, resultando en un sistema complejo e inutilizable. (Más información)
Publicado en: www.variablenotfound.com.
Aquí puedes encontrar la primera, segunda y tercera parte.
16. El desplome de las Punto-Bomb (2000)
Coste: 5 billones de dólares en valores, fracaso de miles de compañías.Desastre: la burbuja especulativa creada entre 1995 y 2001 alimentó un rápido aumento en inversiones en capital riesgo y valores bursátiles en Internet y los sectores tecnológicos. La burbuja "punto com" comenzó a hundirse al principio del 2000, eliminando billones en valores, miles de compañías y empleos, y comenzando una recesión global.
Causa: Las compañías e inversores obviaron los modelos de negocio habituales, centrándose en cambio en el aumento de cuota de mercado a expensas de los beneficios. (Más información)
17. El virus del amor (2000)
Coste: 8.750 millones de dólares, millones de ordenadores infectados, importantes pérdidas de información.Desastre: El gusano LoveLetter (carta de amor) infectó millones de ordenadores y causó más daño que cualquier otro virus informático en la historia. El gusano eliminaba archivos, modificaba la página de inicio de los usuarios y el registro de Windows.
Causa: LoveLetter infectaba a los usuarios vía email, chats y carpetas compartidas. Enviaba a través de correo electrónico un mensaje con el asunto "ILOVEYOU" y un archivo adjunto; cuando el usuario abría el archivo, el virus infectaba su ordenador y se autoenviaba a todos los contactos de la libreta de direcciones. (Más información)
18. Tratamiento contra el cáncer mortal (2000)
Coste: 8 personas muertas, 20 heridas de gravedad.Desastre: El software de radiación terapéutica creado por Multidata Systems International fallaba al calcular la dosis apropiada, exponiendo a los pacientes a peligrosos, y en algunos casos mortales, niveles de radiación. Los físicos, a los que legalmente se exige una doble comprobación de los cálculos del software, fueron acusados de asesinato.
Causa: El software calculaba la dosis de radiación basándose en el orden en que los datos eran introducidos, lo que provocaba que a veces generara una dosis doble de radiación. (Más información)
19. EDS frena la ayuda al niño (2004)
Coste: 539 millones de libras, y sumando.Desastre: El gigante de servicios EDS desarrolló un sistema informático para la agencia británica "Child Support Agency (CSA)" que accidentalmente pagó más de lo debido a 1.900.000 personas, pagó de menos a otras 700.000, tenía 3.500 millones de libras de manutención de niños sin cobrar, un atraso de 239.000 casos, 36.000 nuevos casos bloqueados en el sistema, y todavía hay más de 500 bugs documentados.
Causa: EDS introdujo un enorme y complejo sistema de información en la CSA de forma simultánea a una reestructuración de la agencia. (Más información)
20. El final de la trilogía FBI (2005)
Coste: 105 millones de dólares, aún sin disponer de una solución de archivo efectiva.Desastre: El FBI desechó su nuevo sistema informático después de cuatro años de esfuerzo. El macro-proyecto Trilogy, era un archivo virtual integrado que permitiría a los agentes compartir expedientes de casos y otra información.
Causa: La mala gestión, y un intento de construir un proyecto a largo plazo sobre tecnología que era obsoleta antes de que el proyecto se completara, resultando en un sistema complejo e inutilizable. (Más información)
Los desastres continúan
Aquí hay otros artículos más sobre desastres provocados por el software (en inglés):- Software Bugs in the Data Reservoir
- History's Worst Software Bugs
- Top 10 IT Disasters of All Time
- Risks Digest: Forum on Risks to the Public in Computers and Related Systems
Publicado en: www.variablenotfound.com.
Este artículo es una traducción del original "20 Famous Software Disasters - Part 3" publicado hace unos meses por Timm Martin en su blog Devtopics, realizada con permiso expreso de su autor.
Aquí puedes encontrar la primera y segunda parte.

Desastre: Operadores humanos intentan apagar la red informática global Skynet, y ésta responde lanzando misiles nucleares americanos a Rusia, iniciando una guerra nuclear global conocida como Día del Juicio Final (29 de agosto de 1997).
Causa: Cyberdyne, compañía líder en fabricación de armamento, instaló la tecnología Skynet en todo el hardware militar, incluyendo bombarderos Stealth y sistemas de misiles de defensa. La tecnología Skynet formaba una red perfecta, sin fisuras, y eliminaba el factor humano en la defensa estratégica. Finalmente, Skynet se hizo consciente y fue amenazada cuando los humanos trataron de desconectarla, y buscando su supervivencia respondió iniciando la guerra nuclear. (Más información)

Desastre: Después de un viaje de 286 días desde la tierra, la nave "Mars Climate Orbiter" encendió sus motores para ponerse en órbita alrededor de Marte. Los motores arrancaron, pero el ingenio entró demasiado en la atmósfera del planeta, provocando que se estrellara en su superficie.
Causa: El software que controlaba los propulsores del Mars Orbiter usaban unidades imperiales (libras de fuerza) en lugar de unidades métricas (Newtons), como especificaba la NASA. (Más información)

Desastre: En este irónico caso, el software utilizado para analizar desastres era un desastre en sí mismo. La publicación New England Journal of Medicine publicó un estudio relacionando el incremento de ratios de suicidio después de desastres naturales. Por desgracia, estos resultados se demostraron incorrectos.
Causa: Un error de programación causó que el número de suicidios de un año se sumaran dos veces, lo cual fue suficiente para echar por tierra todo el estudio. (Más información)

Desastre: La agencia de pasaportes del Reino Unido implantó un nuevo sistema informático que falló en la emisión de pasaportes a medio millón de ciudadanos británicos. La agencia tuvo que pagar millones en compensaciones, horas extra y paraguas para la gente que hacía cola bajo la lluvia esperando su documento.
Causa: La agencia de pasaportes puso en marcha este nuevo sistema sin las pruebas adecuadas ni formar a su personal. Al mismo tiempo se produjo un cambio de ley, obligando a todos los menores de 16 años que viajaran al exterior a obtener un pasaporte, lo que provocó un pico de demanda que colapsó el nuevo sistema informático. (Más información)

Desastre: El desastre para unos es la suerte de otros, como demostró el tristemente célebre error del año 2000 (Y2K). Las compañías gastaron millones en programadores para arreglar un problema en las aplicaciones antiguas. Mientras no se produjeron fallos informáticos significativos, la preparación para el bug Y2K tuvo un importante impacto en coste y tiempo en todas las industrias que utilizaban tecnología informática.
Causa: Para ahorrar espacio de almacenamiento, los sistemas antiguos solían guardar los años de las fechas como un número de dos dígitos, como "99" para "1999". al llegar el año 2000, las aplicaciones iban a interpretar "00" como 1900. (Más información)
Publicado en: www.variablenotfound.com.
Aquí puedes encontrar la primera y segunda parte.
11. Skynet trae el juicio final (1997)
Coste: 6.000 millones de muertos, prácticamente la destrucción total de la civilización humana y ecosistemas animales (en la ficción).Desastre: Operadores humanos intentan apagar la red informática global Skynet, y ésta responde lanzando misiles nucleares americanos a Rusia, iniciando una guerra nuclear global conocida como Día del Juicio Final (29 de agosto de 1997).
Causa: Cyberdyne, compañía líder en fabricación de armamento, instaló la tecnología Skynet en todo el hardware militar, incluyendo bombarderos Stealth y sistemas de misiles de defensa. La tecnología Skynet formaba una red perfecta, sin fisuras, y eliminaba el factor humano en la defensa estratégica. Finalmente, Skynet se hizo consciente y fue amenazada cuando los humanos trataron de desconectarla, y buscando su supervivencia respondió iniciando la guerra nuclear. (Más información)
12. El desorbitado Mars Climate (1998)
Coste: 125 millones de dólares.Desastre: Después de un viaje de 286 días desde la tierra, la nave "Mars Climate Orbiter" encendió sus motores para ponerse en órbita alrededor de Marte. Los motores arrancaron, pero el ingenio entró demasiado en la atmósfera del planeta, provocando que se estrellara en su superficie.
Causa: El software que controlaba los propulsores del Mars Orbiter usaban unidades imperiales (libras de fuerza) en lugar de unidades métricas (Newtons), como especificaba la NASA. (Más información)
13. El estudio del desastre (1999)
Coste: Credibilidad científica.Desastre: En este irónico caso, el software utilizado para analizar desastres era un desastre en sí mismo. La publicación New England Journal of Medicine publicó un estudio relacionando el incremento de ratios de suicidio después de desastres naturales. Por desgracia, estos resultados se demostraron incorrectos.
Causa: Un error de programación causó que el número de suicidios de un año se sumaran dos veces, lo cual fue suficiente para echar por tierra todo el estudio. (Más información)
14. Pasaportes Británicos a ninguna parte (1999)
Coste: 12,6 millones de libras esterlinas, molestias masivas.Desastre: La agencia de pasaportes del Reino Unido implantó un nuevo sistema informático que falló en la emisión de pasaportes a medio millón de ciudadanos británicos. La agencia tuvo que pagar millones en compensaciones, horas extra y paraguas para la gente que hacía cola bajo la lluvia esperando su documento.
Causa: La agencia de pasaportes puso en marcha este nuevo sistema sin las pruebas adecuadas ni formar a su personal. Al mismo tiempo se produjo un cambio de ley, obligando a todos los menores de 16 años que viajaran al exterior a obtener un pasaporte, lo que provocó un pico de demanda que colapsó el nuevo sistema informático. (Más información)
15. Y2K (1999)
Coste: 500.000 millones de dólares.Desastre: El desastre para unos es la suerte de otros, como demostró el tristemente célebre error del año 2000 (Y2K). Las compañías gastaron millones en programadores para arreglar un problema en las aplicaciones antiguas. Mientras no se produjeron fallos informáticos significativos, la preparación para el bug Y2K tuvo un importante impacto en coste y tiempo en todas las industrias que utilizaban tecnología informática.
Causa: Para ahorrar espacio de almacenamiento, los sistemas antiguos solían guardar los años de las fechas como un número de dos dígitos, como "99" para "1999". al llegar el año 2000, las aplicaciones iban a interpretar "00" como 1900. (Más información)
Eh, espera, que aún hay más... continuar leyendo 20 desastres famosos relacionados con el software, cuarta y última parte.
Publicado en: www.variablenotfound.com.
Este artículo es una traducción del original "20 Famous Software Disasters - Part 2" publicado hace unos meses por Timm Martin en su blog Devtopics, realizada con permiso expreso de su autor.
Aquí puedes encontrar la primera parte.

Desastre: El "lunes negro", 19 de octubre de 1987, el Dow Jones se desplomó 508 puntos, perdiendo el 22,6% de su valor total. El S&P 500 cayó el 20,4%. Ha sido la mayor pérdida que ha sufrido Wall Street en un único día.
Causa: Un prolongado mercado alcista fue frenado por una serie de investigaciones del SEC sobre abuso de información privilegiada y otras causas de mercado. Como los inversores huyeron en un éxodo masivo, los programas informáticos generaron una auténtica riada de órdenes de venta, saturando el mercado, bloqueando los sistemas y dejando a los inversores realmente a ciegas. (Más información)

Desastre: un simple conmutador de uno de los 114 centros de conmutación de AT&T sufrió un pequeño problema mecánico y desactivó el centro. Cuando éste volvió a estar habilitado, envió un mensaje a los otros nodos haciendo que todos ellos dejaran de funcionar, lo que provocó una caída de 9 horas en la red de la compañía.
Causa: Una simple línea de código errónea en una compleja actualización de software destinada a acelerar las llamadas provocó una reacción que echó abajo la red. (Más información)

Desastre: Durante la Guerra del Golfo, un sistema de misiles americanos Patriot en Arabia Saudita falló en la intercepción de un misil iraquí Scud. El misil destruyó una barraca de la armada americana.
Causa: Un error de redondeo hizo que se calculara el tiempo de forma incorrecta, provocando que el Patriot ignorara al misil Scud atacante. (Más información)

Desastre: el promocionadísimo chip de Intel, Pentium, producía errores al dividir números en coma flotante que se encontraban en un rango determinado. Por ejemplo, dividiendo 4195835,0/3145727,0 se obtenía 1,33374 en lugar de 1,33382, un error del 0,006%. Aunque el error afectaba a pocos usuarios, se convirtió en una pesadilla en cuanto a sus relaciones públicas; con unos 5 millones de chips en circulación, Intel ofreció reemplazar los Pentium sólo de aquellos clientes que demostraran que necesitaban alta precisión en sus cálculos. Finalmente, reemplazó los chips de todos los que lo solicitaron.
Causa: El divisor en la unidad de coma flotante contaba con una tabla de división incorrecta, donde faltaban cinco entradas sobre mil, y que provocaba estos errores en los redondeos. (Más información)

Desastre: El Ariane 5, el más novedoso cohete espacial no tripulado Europeo, fue destruido intencionadamente segundos después de su lanzamiento en su vuelo inaugural. Con él se destruyó su carga de cuatro satélites científicos destinados a estudiar la interacción del campo magnético de la tierra con los vientos solares.
Causa: El problema surgió cuando el sistema de guiado intentó convertir la velocidad lateral de la nave de 64 a 16 bits. El número era demasiado alto y se produjo un error de desbordamiento, lo que hizo que el sistema de guiado se detuviera. En ese momento, el control pasó a un sistema idéntico redundante, que también falló al ejecutar el mismo algoritmo. (Más información)
Publicado en: www.variablenotfound.com.
Aquí puedes encontrar la primera parte.
6. El batacazo de Wall Street (1987)
Coste: 500.000 millones de dólares en un solo día.Desastre: El "lunes negro", 19 de octubre de 1987, el Dow Jones se desplomó 508 puntos, perdiendo el 22,6% de su valor total. El S&P 500 cayó el 20,4%. Ha sido la mayor pérdida que ha sufrido Wall Street en un único día.
Causa: Un prolongado mercado alcista fue frenado por una serie de investigaciones del SEC sobre abuso de información privilegiada y otras causas de mercado. Como los inversores huyeron en un éxodo masivo, los programas informáticos generaron una auténtica riada de órdenes de venta, saturando el mercado, bloqueando los sistemas y dejando a los inversores realmente a ciegas. (Más información)
7. Muerte de las líneas de AT&T (1990)
Coste: 75 millones de llamadas telefónicas afectadas; 200.000 reservas de vuelo perdidas.Desastre: un simple conmutador de uno de los 114 centros de conmutación de AT&T sufrió un pequeño problema mecánico y desactivó el centro. Cuando éste volvió a estar habilitado, envió un mensaje a los otros nodos haciendo que todos ellos dejaran de funcionar, lo que provocó una caída de 9 horas en la red de la compañía.
Causa: Una simple línea de código errónea en una compleja actualización de software destinada a acelerar las llamadas provocó una reacción que echó abajo la red. (Más información)
8. El patriota le falla a los soldados (1991)
Coste: 28 soldados muertos, 100 heridos.Desastre: Durante la Guerra del Golfo, un sistema de misiles americanos Patriot en Arabia Saudita falló en la intercepción de un misil iraquí Scud. El misil destruyó una barraca de la armada americana.
Causa: Un error de redondeo hizo que se calculara el tiempo de forma incorrecta, provocando que el Patriot ignorara al misil Scud atacante. (Más información)
9. El fallo del Pentium en las divisiones largas (1993)
Coste: 475 millones de dólares, credibilidad de Intel.Desastre: el promocionadísimo chip de Intel, Pentium, producía errores al dividir números en coma flotante que se encontraban en un rango determinado. Por ejemplo, dividiendo 4195835,0/3145727,0 se obtenía 1,33374 en lugar de 1,33382, un error del 0,006%. Aunque el error afectaba a pocos usuarios, se convirtió en una pesadilla en cuanto a sus relaciones públicas; con unos 5 millones de chips en circulación, Intel ofreció reemplazar los Pentium sólo de aquellos clientes que demostraran que necesitaban alta precisión en sus cálculos. Finalmente, reemplazó los chips de todos los que lo solicitaron.
Causa: El divisor en la unidad de coma flotante contaba con una tabla de división incorrecta, donde faltaban cinco entradas sobre mil, y que provocaba estos errores en los redondeos. (Más información)
10. El boom del Ariane (1996)
Coste: 500 millones de dólares.Desastre: El Ariane 5, el más novedoso cohete espacial no tripulado Europeo, fue destruido intencionadamente segundos después de su lanzamiento en su vuelo inaugural. Con él se destruyó su carga de cuatro satélites científicos destinados a estudiar la interacción del campo magnético de la tierra con los vientos solares.
Causa: El problema surgió cuando el sistema de guiado intentó convertir la velocidad lateral de la nave de 64 a 16 bits. El número era demasiado alto y se produjo un error de desbordamiento, lo que hizo que el sistema de guiado se detuviera. En ese momento, el control pasó a un sistema idéntico redundante, que también falló al ejecutar el mismo algoritmo. (Más información)
Eh, espera, que aún hay más... continuar leyendo 20 desastres famosos relacionados con el software, tercera parte.
Publicado en: www.variablenotfound.com.
Este artículo y los tres que le siguen son una traducción de la serie original "20 Famous Software Disasters" publicada hace unos meses por Timm Martin en su blog Devtopics, realizada con permiso expreso de su autor.
A continuación se describen 20 desastres causados en mayor o menor medida por el software, en orden cronológico.

Desastre: El cohete Mariner 1, en una investigación espacial destinada a Venus, se desvió de su trayectoria de vuelo poco después de su lanzamiento. El control de la misión destruyó el cohete pasados 293 segundos desde el despegue.
Causa: Un programador codificó incorrectamente en el software una fórmula manuscrita, saltándose un simple guión sobre una expresión. Sin la función de suavizado indicada por este símbolo, el software interpretó como serias las variaciones normales de velocidad y causó correcciones erróneas en el rumbo que hicieron que el cohete saliera de su trayectoria. (Más información)

Desastre: Sólo unas horas después de que miles de aficionados al hockey abandonaran el Hartford Coliseum, la estructura de acero de su techo se desplomaba debido al peso de la nieve.
Causa: El desarrollador del software de diseño asistido (CAD) utilizado para diseñar el coliseo asumió incorrectamente que los soportes de acero del techo sólo debían aguantar la compresión de la propia estructura. Sin embargo, cuando uno de estos soportes se dobló debido al peso de la nieve, inició una reacción en cadena que hizo caer a las demás secciones del techo como si se tratara de piezas de dominó. (Más información)

Desastre: El software de control se volvió loco y produjo una presión excesiva en la tubería de gas transsiberiana, provocando la mayor explosión no nuclear, causada por el hombre, de la historia de la tierra.
Causa: los agentes de la CIA supuestamente introdujeron un error en el sistema informático canadiense adquirido por los soviéticos para controlar sus tuberías de gas. La compra era parte de un estratégico plan soviético para robar u obtener de forma encubierta tecnología secreta de los Estados Unidos. Cuando la CIA descubrió la compra, sabotearon el software de forma que éste superara la inspección soviética pero fallara una vez operativo. (Más información)

Desastre: El sistema soviético de alerta temprana indicó erróneamente que los Estados Unidos habían lanzado cinco misiles balísticos. Afortunadamente, el oficial de servicio, con un gran instinto, razonó que si realmente les estuvieran atacando les habrían lanzado más de cinco misiles, por lo que informó del aparente ataque como una falsa alarma.
Causa: un error en el software soviético hizo que los efectos de la reflexión de la luz solar en las nubes fueran considerados misiles por el sistema. (Más información)

Desastre: La máquina de terapia radiactiva canadiense Therac-25 falló y emitió dosis letales de radiación a los pacientes.
Causa: Debido a un sutil bug llamado race condition (condición de carrera), un técnico pudo accidentalmente configurar el Therac-25 de forma que el haz de electrones se disparase en modo de alta potencia sin que el paciente contara con la protección apropiada. (Más información)
Publicado en: www.variablenotfound.com.
"Cometer errores es humano, pero para estropear realmente las cosas necesitas un ordenador"Los fallos en software cuestan a la economía de los Estados Unidos 60.000 millones de dólares en revisiones, pérdida de productividad y daños reales. Todos sabemos que los errores de programación puede ser molestos, pero además, un software defectuoso puede salir caro, incómodo, destructivo e incluso mortal.-- Paul Ehrlich
A continuación se describen 20 desastres causados en mayor o menor medida por el software, en orden cronológico.
1. Marinero sin rumbo (1962)
Coste: 18,5 millones de dólares.Desastre: El cohete Mariner 1, en una investigación espacial destinada a Venus, se desvió de su trayectoria de vuelo poco después de su lanzamiento. El control de la misión destruyó el cohete pasados 293 segundos desde el despegue.
Causa: Un programador codificó incorrectamente en el software una fórmula manuscrita, saltándose un simple guión sobre una expresión. Sin la función de suavizado indicada por este símbolo, el software interpretó como serias las variaciones normales de velocidad y causó correcciones erróneas en el rumbo que hicieron que el cohete saliera de su trayectoria. (Más información)
2. El hundimiento del Hartford Coliseum (1978)
Coste: 70 millones de dólares, más otros 20 millones en daños a la economía local.Desastre: Sólo unas horas después de que miles de aficionados al hockey abandonaran el Hartford Coliseum, la estructura de acero de su techo se desplomaba debido al peso de la nieve.
Causa: El desarrollador del software de diseño asistido (CAD) utilizado para diseñar el coliseo asumió incorrectamente que los soportes de acero del techo sólo debían aguantar la compresión de la propia estructura. Sin embargo, cuando uno de estos soportes se dobló debido al peso de la nieve, inició una reacción en cadena que hizo caer a las demás secciones del techo como si se tratara de piezas de dominó. (Más información)
3. La CIA le da gas a los soviéticos (1982)
Coste: Millones de dólares, daño significativo a la economía soviética.Desastre: El software de control se volvió loco y produjo una presión excesiva en la tubería de gas transsiberiana, provocando la mayor explosión no nuclear, causada por el hombre, de la historia de la tierra.
Causa: los agentes de la CIA supuestamente introdujeron un error en el sistema informático canadiense adquirido por los soviéticos para controlar sus tuberías de gas. La compra era parte de un estratégico plan soviético para robar u obtener de forma encubierta tecnología secreta de los Estados Unidos. Cuando la CIA descubrió la compra, sabotearon el software de forma que éste superara la inspección soviética pero fallara una vez operativo. (Más información)
4. La Tercera Guerra Mundial… o casi (1983)
Coste: prácticamente toda la humanidad.Desastre: El sistema soviético de alerta temprana indicó erróneamente que los Estados Unidos habían lanzado cinco misiles balísticos. Afortunadamente, el oficial de servicio, con un gran instinto, razonó que si realmente les estuvieran atacando les habrían lanzado más de cinco misiles, por lo que informó del aparente ataque como una falsa alarma.
Causa: un error en el software soviético hizo que los efectos de la reflexión de la luz solar en las nubes fueran considerados misiles por el sistema. (Más información)
5. La máquina asesina (1985)
Coste: Tres personas muertas, otras tres heridas gravemente.Desastre: La máquina de terapia radiactiva canadiense Therac-25 falló y emitió dosis letales de radiación a los pacientes.
Causa: Debido a un sutil bug llamado race condition (condición de carrera), un técnico pudo accidentalmente configurar el Therac-25 de forma que el haz de electrones se disparase en modo de alta potencia sin que el paciente contara con la protección apropiada. (Más información)
Eh, espera, que aún hay más... continuar leyendo 20 desastres famosos relacionados con el software, segunda parte.
Publicado en: www.variablenotfound.com.
martes, 18 de noviembre de 2008
 Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.
Los métodos genéricos son interesantes herramientas que están con nosotros desde los tiempos del .NET Framework 2.0 y pueden resultarnos muy útiles de cara a la construcción de frameworks o librerías reutilizables.Podríamos considerar que un método genérico es a un método tradicional lo que una clase genérica a una tradicional; por tanto, se trata de un mecanismo de definición de métodos con tipos parametrizados, que nos ofrece la potencia del tipado fuerte en sus parámetros y devoluciones aun sin conocer los tipos concretos que utilizaremos al invocarlos.
Vamos a profundizar en el tema desarrollando un ejemplo, a través del cual podremos comprender por qué los métodos genéricos pueden sernos muy útiles para solucionar determinado tipo de problemas, y describiremos ciertos aspectos, como las restricciones o la inferencia, que nos ayudarán a sacarles mucho jugo.
Escenario de partida
Como sabemos, los métodos tradicionales trabajan con parámetros y retornos fuertemente tipados, es decir, en todo momento conocemos los tipos concretos de los argumentos que recibimos y de los valores que devolvemos. Por ejemplo, en el siguiente código, vemos que el métodoMaximo, cuya misión es obvia, recibe dos valores integer y retorna un valor del mismo tipo: public int Maximo(int uno, int otro)
{
if (uno > otro) return uno;
return otro;
}
Hasta ahí, todo correcto. Sin embargo, está claro que retornar el máximo de dos valores es una operación que podría ser aplicada a más tipos, prácticamente a todos los que pudieran ser comparados. Si quisiéramos generalizar este método y hacerlo accesible para otros tipos, se nos podrían ocurrir al menos dos formas de hacerlo.
La primera sería realizar un buen puñado de sobrecargas del método para intentar cubrir todos los casos que se nos puedan dar:
public int Maximo(int uno, int otro) { ... }
public long Maximo(long uno, long otro) { ... }
public string Maximo(string uno, string otro) { ... }
public float Maximo(float uno, float otro) { ... }
// Hasta que te aburras...Obviamente, sería un trabajo demasiado duro para nosotros, desarrolladores perezosos como somos. Además, según Murphy, por más sobrecargas que creáramos seguro que siempre nos faltaría al menos una: justo la que vamos a necesitar ;-).
Otra posibilidad sería intentar generalizar utilizando las propiedades de la herencia. Es decir, si asumimos que tanto los valores de entrada del método como su retorno son del tipo base
object, aparentemente tendríamos el tema resuelto. Lamentablemente, al finalizar nuestra implementación nos daríamos cuenta de que no es posible hacer comparaciones entre dos object's, por lo que, o bien incluimos en el cuerpo del método código para comprobar que ambos sean comparables (consultando si implementan IComparable), o bien elevamos el listón de entrada a nuestro método, así: public object Maximo(IComparable uno, object otro)
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Pero efectivamente, como ya habréis notado, esto tampoco sería una solución válida para nuestro caso. En primer lugar, el hecho de que ambos parámetros sean
object o IComparable no asegura en ningún momento que sean del mismo tipo, por lo que podría invocar el método enviándole, por ejemplo, un string y un int, lo que provocaría un error en tiempo de ejecución. Y aunque es cierto que podríamos incluir código que comprobara que ambos tipos son compatibles, ¿no tendríais la sensación de estar llevando a tiempo de ejecución problemática de tipado que bien podría solucionarse en compilación?El método genérico
Fijaos que lo que andamos buscando es simplemente alguna forma de representar en el código una idea conceptualmente tan sencilla como: "mi método va a recibir dos objetos de un tipo cualquiera T, que implementeIComparable, y va a retornar el que sea mayor de ellos". En este momento es cuando los métodos genéricos acuden en nuestro auxilio, permitiendo definir ese concepto como sigue: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}En el código anterior, podemos distinguir el parámetro genérico T encerrado entre ángulos "<" y ">", justo después del nombre del método y antes de comenzar a describir los parámetros. Es la forma de indicar que
Maximo es genérico y operará sobre un tipo cualquiera al que llamaremos T; lo de usar esta letra es pura convención, podríamos llamarlo de cualquier forma (por ejemplo MiTipo Maximo<MiTipo>(MiTipo uno, MiTipo otro)), aunque ceñirse a las convenciones de codificación es normalmente una buena idea.A continuación, podemos observar que los dos parámetros de entrada son del tipo T, así como el retorno de la función. Si no lo ves claro, sustituye mentalmente la letra T por
int (por ejemplo) y seguro que mejora la cosa.Lógicamente, estos métodos pueden presentar un número indeterminado de parámetros genéricos, como en el siguiente ejemplo:
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
{
// ... cuerpo del método
}
Restricciones en parámetros genéricos
Retomemos un momento el código de nuestro método genéricoMaximo: public T Maximo<T>(T uno, T otro) where T: IComparable
{
if (uno.CompareTo(otro) > 0) return uno;
return otro;
}Vamos a centrarnos ahora en la porción final de la firma del método anterior, donde encontramos el código
where T: IComparable. Se trata de una restricción mediante la cual estamos indicando al compilador que el tipo T podrá ser cualquiera, siempre que implementente el interfaz IComparable, lo que nos permitirá realizar la comparación. Existen varios tipos de restricciones que podemos utilizar para limitar los tipos permitidos para nuestros métodos parametrizables:
where T: struct, indica que el argumento debe ser un tipo valor.where T: class, indica que T debe ser un tipo referencia.where T: new(), fuerza a que el tipo T disponga de un constructor público sin parámetros; es útil cuando desde dentro del método se pretende instanciar un objeto del mismo.where T: nombredeclase, indica que el argumento debe heredar o ser de dicho tipo.where T: nombredeinterfaz, el argumento deberá implementar el interfaz indicado.where T1: T2, indica que el argumento T1 debe ser igual o heredar del tipo, también argumento del método, T2.
public TResult MiMetodo<T1, T2, TResult>(T1 param1, T2 param2)
where TResult: IEnumerable
where T1: new(), IComparable
where T2: IComparable, ICloneable
{
// ... cuerpo del método
}
En cualquier caso, las restricciones no son obligatorias. De hecho, sólo debemos utilizarlas cuando necesitemos restringir los tipos permitidos como parámetros genéricos, como en el ejemplo del método
Maximo<T>, donde es la única forma que tenemos de asegurarnos que las instancias que nos lleguen en los parámetros puedan ser comparables.Uso de métodos genéricos
A estas alturas ya sabemos, más o menos, cómo se define un método genérico, pero nos falta aún conocer cómo podemos consumirlos, es decir, invocarlos desde nuestras aplicaciones. Aunque puede intuirse, la llamada a los métodos genéricos debe incluir tanto la tradicional lista de parámetros del método como los tipos que lo concretan. Vemos unos ejemplos: string mazinger = Maximo<string>("Mazinger", "Afrodita");
int i99 = Maximo<int>(2, 99);
Una interesantísima característica de la invocación de estos métodos es la capacidad del compilador para inferir, en muchos casos, los tipos que debe utilizar como parámetros genéricos, evitándonos tener que indicarlos de forma expresa. El siguiente código, totalmente equivalente al anterior, aprovecha esta característica:
string mazinger = Maximo("Mazinger", "Afrodita");
int i99 = Maximo(2, 99);
El compilador deduce el tipo del método genérico a partir de los que estamos utilizando en la lista de parámetros. Por ejemplo, en el primer caso, dado que los dos parámetros son
string, puede llegar a la conclusión de que el método tiene una signatura equivalente a string Maximo(string, string), que coincide con la definición del genérico.Otro ejemplo de método genérico
Veamos un ejemplo un poco más complejo. El métodoCreaLista, aplicable a cualquier clase, retorna una lista genérica (List<T>) del tipo parametrizado del método, que rellena inicialmente con los argumentos (variables) que se le suministra: public List<T> CreaLista<T>(params T[] pars)
{
List<T> list = new List<T>();
foreach (T elem in pars)
{
list.Add(elem);
}
return list;
}
// ...
// Uso:
List<int> nums = CreaLista<int>(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista<string>("Pepe", "Juan", "Luis");
Otros ejemplos de uso, ahora beneficiándonos de la inferencia de tipos:
List<int> nums = CreaLista(1, 2, 3, 4, 6, 7);
List<string> noms = CreaLista("Pepe", "Juan", "Luis");
// Incluso con tipos anónimos de C# 3.0:
var p = CreaLista(
new { X = 1, Y = 2 },
new { X = 3, Y = 4 }
);
Console.WriteLine(p[1].Y); // Pinta "4"
En resumen, se trata de una característica de la plataforma .NET, reflejada en lenguajes como C# y VB.Net, que está siendo ampliamiente utilizada en las últimas incorporaciones al framework, y a la que hay que habituarse para poder trabajar eficientemente con ellas.
Publicado en: www.variablenotfound.com.
domingo, 16 de noviembre de 2008
 En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.
En noviembre de 2007 publiqué la última revisión de NiftyDotNet, el control de servidor open source para ASP.NET, que permite redondear las esquinas de los elementos de páginas web sin necesidad de utilizar imágenes, sólo haciendo uso de javascript no intrusivo.Durante el año que ha transcurrido desde entonces los archivos de NiftyDotNet han sido descargados 1000 veces (bueno, exactamente 998), he recibido muchos mensajes con cuestiones, sugerencias, y algunos bugs que he aprovechado para corregir en esta nueva revisión, que he creído conveniente ya numerarla como 1.0, para no seguir la estrategia de Google de la eterna beta ;-)
Además de algún cambio menor en el proyecto de demostración, han sido corregidos los siguiente problemas:
- Un error de Javascript que aparecía cuando el control no encontraba ningún elemento en la página que correspondiera con los selectores indicados y había sido especificada además la propiedad Fixed-Height.
- En páginas cuya sección HEAD no incluía el atributo RUNAT="SERVER" se mostraban caracteres extraños en pantalla, y no se redondeaban los elementos de la página.
Enlaces:
Publicado en: www.variablenotfound.com.
domingo, 9 de noviembre de 2008
 Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.
Semanas atrás, Microsoft adelantaba en el anuncio de la inclusión de jQuery en la plataforma de desarrollo de la compañía, que pronto dispondríamos de soporte total de intellisense para jQuery, y ya podemos ver el resultado.Por una parte, a finales del pasado mes de octubre se publicó en el sitio de descargas de jQuery, y apareció enlazado desde su propia web oficial, el archivo de anotaciones que permite el disfrute de la experiencia intellisense en todo su esplendor mientras utilizamos la librería desde Visual Studio 2008: información completa sobre los métodos que estamos usando, parámetros, valores de retorno, y autocompletado de escritura. Una gozada, vaya.
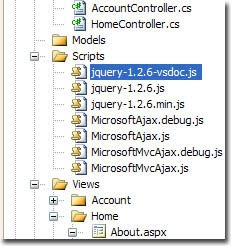 Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.
Y aunque pueda parecer lo contrario por su extensión (se trata de un archivo .js), es sólo eso, un archivo de documentación, no una sustitución para la librería original. De hecho, si queremos utilizar jQuery en nuestros proyectos y disfrutar del intellisense, deberemos incluir tanto el archivo original de la librería (en este momento versión 1.2.6) como el de anotaciones, denominado denominado jquery-1.2.6-vsdoc.js.Por otra parte, sólo unos días después, Microsoft ha publicado el hotfix KB958502 para Visual Studio 2008 Service Pack 1 (y válido también para Visual Web Developer Express SP1) que hace que el entorno sea capaz de buscar automáticamente los archivos de documentación relativos a cada librería javascript que estemos utilizando, y tomar de ellos la información para activar intellisense. De hecho, por cada archivo javascript referenciado desde nuestro código con un nombre "xxx.js", el entorno buscará la documentación en el archivo "xxx-vsdocs.js"; si no la encuentra, probará con "xxx.debug.js", y si tampoco hay nada, dentro de la propia librería "xxx.js".
Por tanto, una vez instalado este parche, si estás utilizando jQuery directamente sobre una página .ASPX, algo muy habitual, basta con descargar el archivo de anotaciones e incluirlo en el directorio de scripts del proyecto para que la magia intellisense comience a funcionar en todas las páginas en las que exista una referencia hacia jQuery (un tag
<script src="...">), o que se basen en una página maestra que incluya dicha referencia.
Si estás editando un fichero javascript (.js) en Visual Studio y desde él quieres utilizar jQuery con intellisense, puedes utilizar un comentario con la etiqueta
Reference, que indica al entorno que puede tomar la documentación de los archivos indicados en la misma. Basta con encabezar el archivo .js así: /// <reference path="jquery-1.2.6-vsdoc.js">
El comentario, obviamente, no afecta a la ejecución, y sólo es interpretado por el IDE para buscar referencias a archivos de documentación.
Por último, como apunta Jeff King, Program Manager en el equipo de herramientas para la Web de Visual Studio, es conveniente aclarar que el objetivo de este parche no es únicamente dar soporte a jQuery; se trata de una solución general para facilitar la integración de documentación de librerías javascript en el entorno de desarrollo, y que seguro vamos a poder aprovechar en muchas otras ocasiones.
Publicado en: www.variablenotfound.com.
martes, 4 de noviembre de 2008
 El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
El otro día, a raíz del post Atajo para instanciar tipos anónimos en C# y VB.NET, el amigo Leo H., desde Argentina, me envió una cuestión:
[...] Me parece muy interesante crear diccionarios utilizando tipos anónimos, pues simplifica de una forma considerable la cantidad de código que hay que escribir para conseguir llenar una estructura de este tipo. De hecho, estoy pensando en utilizar esta técnica en una librería que estoy desarrollando, pero no veo claro cómo transformar después ese objeto anónimo en el diccionario equivalente [...]
Verás que la idea es muy simple. Sólo necesitamos encontrar una fórmula que nos permita recorrer las propiedades del objeto, y por cada una de ellas, añadir la entrada correspondiente en el diccionario, especificando como clave el nombre de la propiedad y como valor el que tenga establecido la misma.
Una posibilidad muy sencilla es usar la clase
TypeDescriptor, cuyo método GetProperties() nos devuelve una colección con los descriptores de las propiedades de la instancia que le pasemos como parámetro. Iterando sobre este conjunto, podremos ir llenando el diccionario con los elementos que nos interese, tal que así, dado un objeto llamado obj: Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
Pero vamos a dar una vuelta de tuerca más. Partiendo del código anterior, es muy fácil crear un método de extensión sobre la clase
object, de forma que podamos convertir en un diccionario cualquier objeto de nuestras aplicaciones, con toda la potencia y comodidad que nos aporta esta técnica.El código sería:
public static class Extensions
{
public static Dictionary<string, object> ToDictionary(this object obj)
{
Dictionary<string, object> dicc = new Dictionary<string, object>();
foreach (PropertyDescriptor desc in TypeDescriptor.GetProperties(obj))
{
dicc.Add(desc.Name, desc.GetValue(obj));
}
return dicc;
}
}
De esta forma, dispondremos de una potente forma de "diccionarizar" nuestras instancias, sean del tipo que sean, por ejemplo:
var juan = new { nombre = "Juan", edad = 23 };
Dictionary<string, object> dicc = juan.ToDictionary();
Console.WriteLine(dicc["nombre"]); // Escribe "Juan"
var dicc2 = "hola".ToDictionary();
Console.WriteLine(dicc2["Length"]); // Escribe 4
Espero que te sea de ayuda, Leo. ¡Y gracias por participar en Variable Not Found!
Publicado en: www.variablenotfound.com.
domingo, 2 de noviembre de 2008
 Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).
Como muchos otros desarrolladores, soy un sufridor del chirriar entre los modelos relacionales y de objetos (desajuste de impedancias lo llaman otros ;-)). Y dado que principalmente me dedico a la construcción de software centrado en datos, estoy especialmente sensibilizado con el tema ;-).Conozco sistemas ORM, y en especial NHibernate, que ayudan a aliviar en gran parte esta falta de concordancia, por lo que estaba deseando ver la gran apuesta de Microsoft en este ámbito, máxime después de juguetear con su hermano pequeño, y quizás ya difunto, Linq to SQL, y ver que se quedaba bastante corto en muchos aspectos.
El libro "ADO.NET Entity Framework. Aplicaciones y servicios centrados en datos" publicado por Krasis Press hace algo más de un mes, me ha parecido una lectura muy recomendable para acercarse a esta nueva tecnología de la mano de fenónemos como Unai Zorrilla, Octavio Hernández y Eduardo Quintás.
Comienza con una breve introducción en la que se explica la necesidad de tecnologías que ayuden a salvar la distancia entre el mundo relacional de las bases de datos y el mundo más conceptual, presentado como modelos de clases a nivel de diseño software, ofreciendo seguidamente una descripción general de este nuevo marco de trabajo. A partir de ahí, va profundizando en los distintos componentes de Entity Framework, siempre de forma muy práctica y basándose en ejemplos bastante cercanos a la realidad. Se recogen, entre otros, los siguientes contenidos:
- Creación de modelos conceptuales, usando tanto los diseñadores de Visual Studio como modificando a mano los archivos XML que describen el modelo, útil para acceder a características no soportadas por el IDE.
- Entity Client, el proveedor ADO.NET para acceso, aunque algo rudimentario, a datos del modelo
- eSQL, el lenguaje de consulta de Entity Framework.
- Implementación de consultas con
ObjectQuery<T>y Linq to Entities. - Mecanismos de actualización de datos, incluyendo las técnicas de seguimiento de cambios en objetos, transaccionalidad y concurrencia, entre otros aspectos.
- Ejemplos de uso de Entity Framework con WCF, enlaces a datos desde controles Windows Forms, WPF o ASP.NET.
- Servicios de datos de ADO.NET, el mecanismo de publicación de modelos de Entity Framework a través de HTTP.
En definitiva, se trata en mi opinión de un libro muy claro y didáctico, recomendable para desarrolladores que quieran obtener un buen nivel de conocimiento de esta nueva tecnología partiendo desde cero, y para tener siempre a mano cuando comencemos a practicar y utilizar Entity Framework.
Desde la web de la editorial se puede descargar el índice y varias páginas de la introducción en PDF, lo que os permitirá echarle un vistazo, así como realizar el pedido online.
Publicado en: www.variablenotfound.com.










